




OpenShift Virtualization with NVIDIA virtual GPU - Part 2

OpenShift Virtualization with NVIDIA virtual GPU
This blog describes how to set up OpenShift Virtualization on OpenShift Container Platform clusters using nodes that are equipped with different NVIDIA GPU (Graphics Processing Unit) cards. The tables at the end of this blog show component versions and combinations of GPU workloads that the Dell OpenShift team validated across nodes in OpenShift cluster versions 4.14 and 4.12. NVIDIA and CUDA (Compute Unified Device Architecture) drivers are installed on RHEL8 operating system VMs, and a sample Spark application is created to consume the GPU/vGPU resource.
For a comprehensive overview of NVIDIA vGPU, GPU Operator, and OpenShift Virtualization, as well as the architecture of our validated environment, see OpenShift Virtualization with NVIDIA virtual GPU - Part 1.
Before you start
- Install Dell PowerStore drivers on the cluster to provision NFS volumes. For more information about deploying Dell CSI drivers on OpenShift, see the Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide.
- Enable SR-IOV on the OpenShift nodes to give the VMs direct hardware access to network resources.
- Install OpenShift Virtualization operator and create HyperConverged CR on the cluster.
- Optionally, configure a dedicated network for virtual machines using Kubernetes NMState.
- Install the Node Feature Discovery operator and create a NodeFeatureDiscovery CR.
- Install the NVIDIA GPU operator from Operator Hub.
- Create a MachineConfig resource to enable Input-Output Memory Management Unit (IOMMU) driver on the nodes, before configuring mediated devices.
Steps
- Add the GPU workload configuration label to the node:
oc label node <node-name> --overwrite nvidia.com/gpu.workload.config=vm-vgpu
You can assign the following values to the label: container, vm-passthrough, and vm-vgpu. The GPU operator uses the value of this label when determining which operands to deploy to support the workload type.
2. Annotate the HyperConverged CR to enable mediated devices:
oc annotate --overwrite -n openshift-cnv hco kubevirt-hyperconverged kubevirt.kubevirt.io/jsonpatch='[{"op": "add", "path": "/spec/configuration/developerConfiguration/featureGates/-", "value": "DisableMDEVConfiguration" }]'
3. Build the vGPU manager image:
a. Download the vGPU Software from Software Downloads in the NVIDIA Licensing Portal for the platform, platform version, and vGPU product version you want.
The vGPU software bundle is packaged as NVIDIA-GRID-Linux-KVM-<version>.zip.
b. Extract the bundle to obtain the NVIDIA vGPU Manager for Linux (NVIDIA-Linux-x86_64-<version>-vgpu-kvm.run file) in the Host_Drivers folder.
4. On your administration node, clone the driver container image repository, and change to the vgpu-manager/rhel8 directory:
git clone https://gitlab.com/nvidia/container-images/driver
cd driver/vgpu-manager/rhel8
5. Export the variables with the name of your private registry, where the driver image is pushed into the NVIDIA vGPU manager version, Red Hat CoreOS version (in the format rhcos4.x, where x is the supported minor OCP version), and the CUDA base image version for building the driver image. Build the image using Docker or Podman and push the image to the private registry:
export PRIVATE_REGISTRY=docker.io/indira0408 VERSION=525.125.06 OS_TAG=rhcos4.14 CUDA_VERSION=12.0
docker build --build-arg DRIVER_VERSION=${VERSION} --build-arg CUDA_VERSION=${CUDA_VERSION} -t ${PRIVATE_REGISTRY}/vgpu-manager:${VERSION}-${OS_TAG} .
podman push docker.io/indira0408/vgpu-manager:525.125.06-rhcos4.14
6. Create an imagePullSecret with user credentials for authenticating to the private registry in the nvidia-gpu-operator namespace. Create a clusterPolicy CR with the following custom configuration, and pass the vGPU manager image you created in the previous step in the clusterPolicy:
sandboxWorloads.enabled=true
vgpuManager.enabled=true
vgpuManager.repository=docker.io/indira0408
vgpuManager.image=vgpu-manager
vgpuManager.version=525.125.06
vgpuManager.imagePullSecrets=private-registry-secret
7. After the ClusterPolicy status changes to “Ready,” edit the HyperConverged CR to allow PCI/mediated devices. For examples of HyperConverged CRs for different PCI and mediated devices, see the Dell ISG OpenShift-bare-metal git page.
8. Create a RHEL 8.6 VM and assign the vGPU device. For instructions on how to create a VM on OpenShift, see Creating virtual machines.
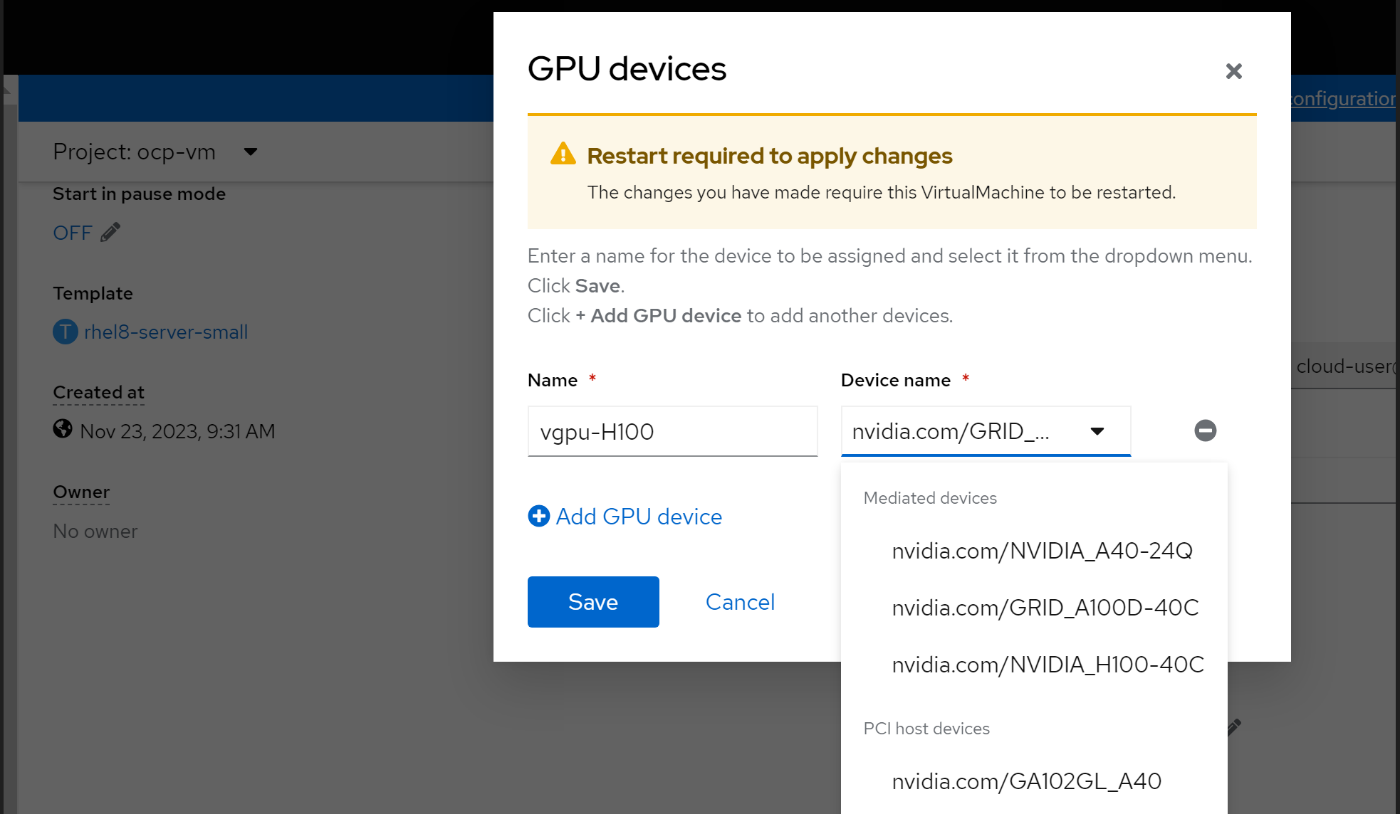
9. Optionally, you can change the vGPU profile by labeling the node with a vGPU profile name.
The GPU operator re-creates the vGPU manager drivers. Update the PCI Devices and mediated devices in the HyperConverged CR:
oc label node cnv-vgpu1 nvidia.com/vgpu.config=A40-8Q
Installing NVIDIA drivers on an RHEL 8.6 VM
Note: A vGPU-assigned VM must have the vGPU driver installed. The vGPU software's "Guest_Drivers" folder contains the package and runfile installers for drivers. You can install either the data center driver or the vGPU driver on a VM that has been assigned a single physical GPU through GPU Passthrough mode. Get the data center drivers for the operating system, architecture, and version that you want from NVIDIA Unix Drivers.
- Register the VM to the Red Hat subscription server using subscription-manager:
sudo subscription-manager register –username <username> --password <password>
2. Install make and compilation tools on the VM:
yum install -y make
yum group install ”Development Tools” -y
3. Disable the Nouveau kernel:
echo ’blacklist nouveau’ | sudo tee -a /etc/modprobe.d/blacklist.conf
4. Reboot the VM to apply the change:
reboot
5. Install Kernel headers:
yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
The NVIDIA driver requires that the kernel headers and development packages for the running version of the kernel be installed at the time of the driver installation.
6. Install the NVIDIA drivers using the runfile installer. Copy the NVIDIA-Linux-x86_64-525.125.06-grid.run file in Guest drivers folder in the downloaded vGPU software to the VM.
chmod +x NVIDIA-Linux-x86_64-525.125.06-grid.run
sh NVIDIA-Linux-x86_64-525.125.06-grid.run
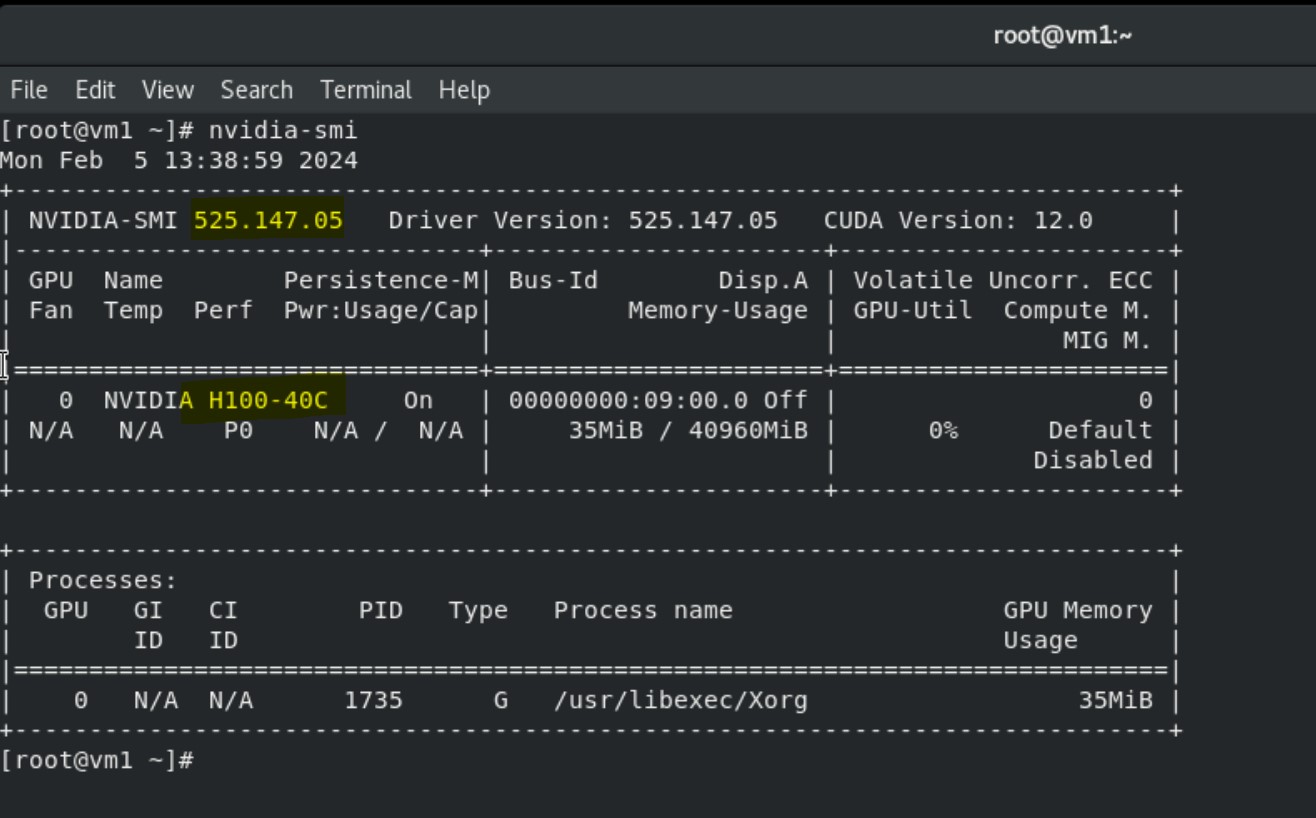
7. Select the options you require and install the drivers.
8. Run the nvidia-smi command to view the GPU device, NVIDIA, and CUDA drivers.
Installing Spark application on VMs to consume vGPU
Prerequisites
NVIDIA and CUDA drivers are installed on the VM.
Steps
1. Install the Open-JDK package on the VM:
yum install java-1.8.0-openjdk -y
2. Choose the required version of Spark tarball from Downloads | Apache Spark.
3. Unpack the tar file into the /opt directory:
tar -xvf spark-3.5.0-bin-hadoop3.tgz
mv spark-3.5.0-bin-hadoop3 /opt/
mv /opt/spark-3.5.0-bin-hadoop3/ /opt/spark
4. Choose the Spark release you want, and then download the NVIDIA RAPIDS Accelerator for Apache Spark plug-in jar file into the /opt/spark/jars directory from Spark Rapids Download:
wget https://repo1.maven.org/maven2/com/nvidia/rapids-4-spark_2.12/23.10.0/rapids-4-spark_2.12-23.10.0.jar
5. Export variables for the Spark home and Java home directories inside bash_profile and reload the bash_profile:
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-4.el8.x86_64/jre/"
export PATH=$JAVA_HOME/bin:$PATH
source .bash_profile
6. Download the GPU discovery script from the following GitHub link and save the script locally (/root/getGpusResources.sh):
wget https://github.com/apache/spark/blob/master/examples/src/main/scripts/getGpusResources.sh
7. Launch the spark shell with the following configuration settings and run a small compute program to use the vGPU device:
/opt/spark/bin/spark-shell --jars /opt/spark/jars/rapids-4-spark_2.12-23.10.0.jar --conf spark.plugins=com.nvidia.spark.SQLPlugin --conf spark.executor.resource.gpu.discoveryScript=/root/getGpusResources.sh --conf spark.executor.resource.gpu.vendor=nvidia.com --conf spark.rapids.sql.enabled=true --conf spark.executor.resource.gpu.amount=1
scala> val df = sc.makeRDD(1 to 1000000000, 6).toDF
scala> val df2 = sc.makeRDD(1 to 1000000000, 6).toDF
scala> df.select( $"value" as "a").join(df2.select($"value" as "b"), $"a" === $"b").count
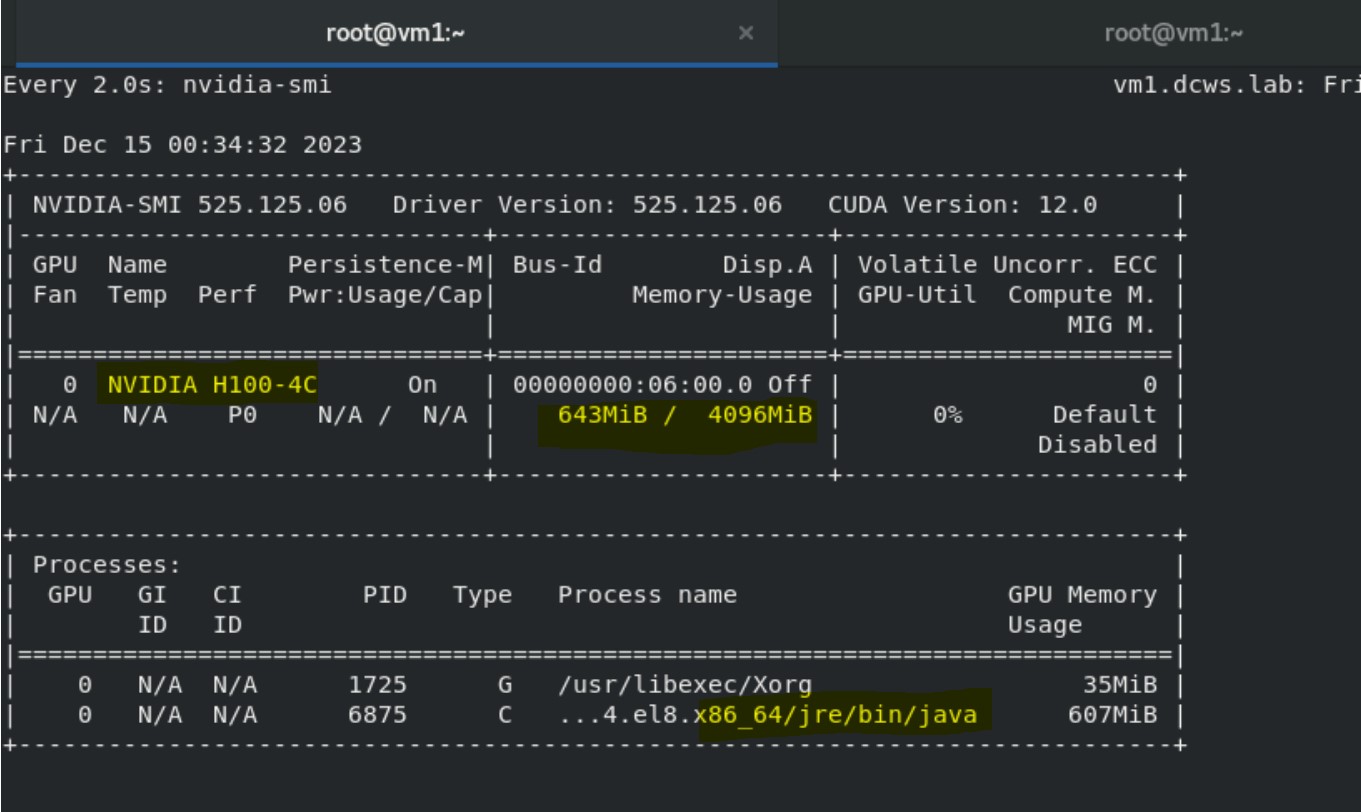
8. Run nvidia-smi in the other terminal to monitor vGPU utilization:
watch nvidia-smi
The output shows the Java process and Volatile GPU-utilization percentage.
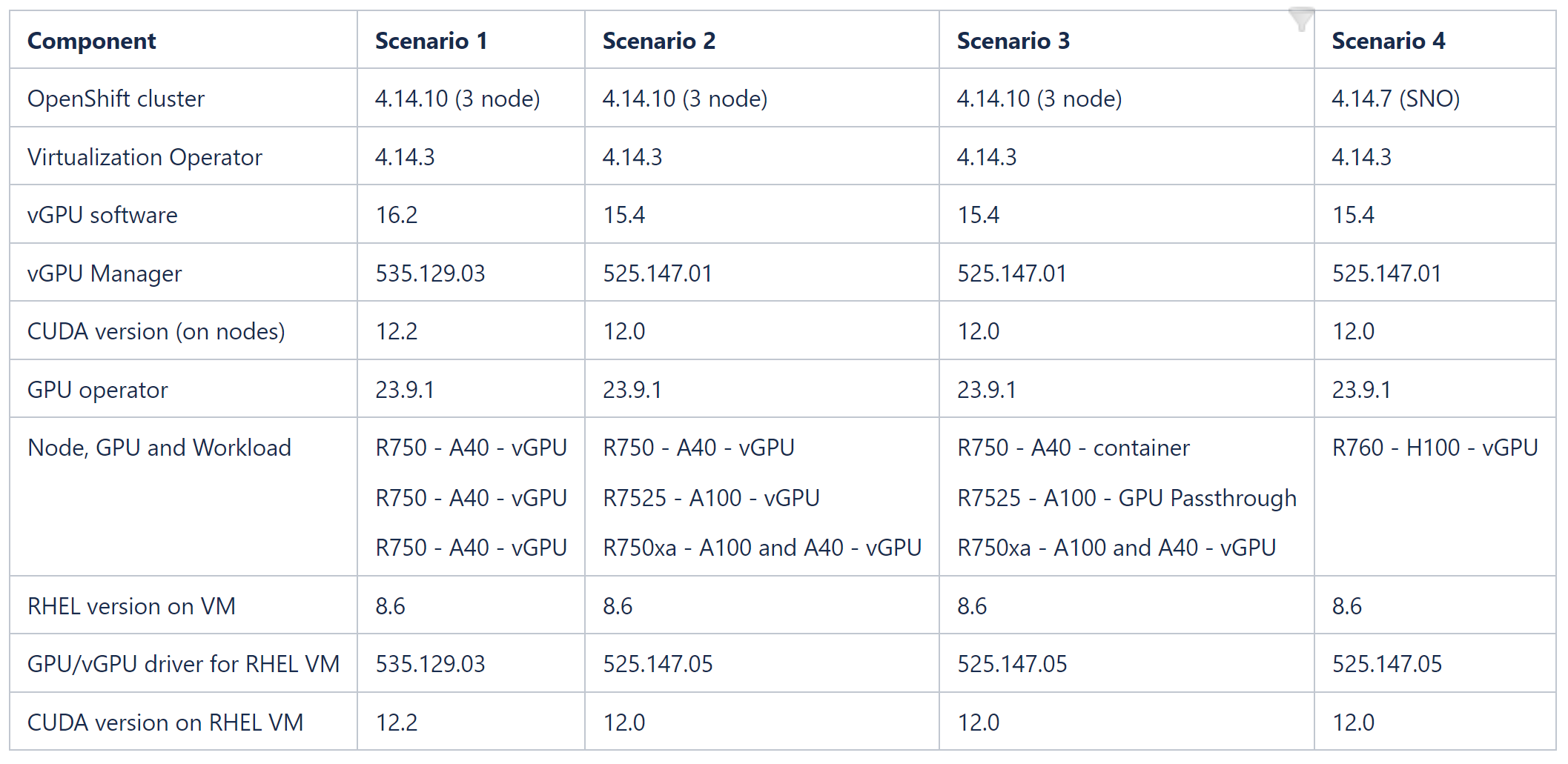
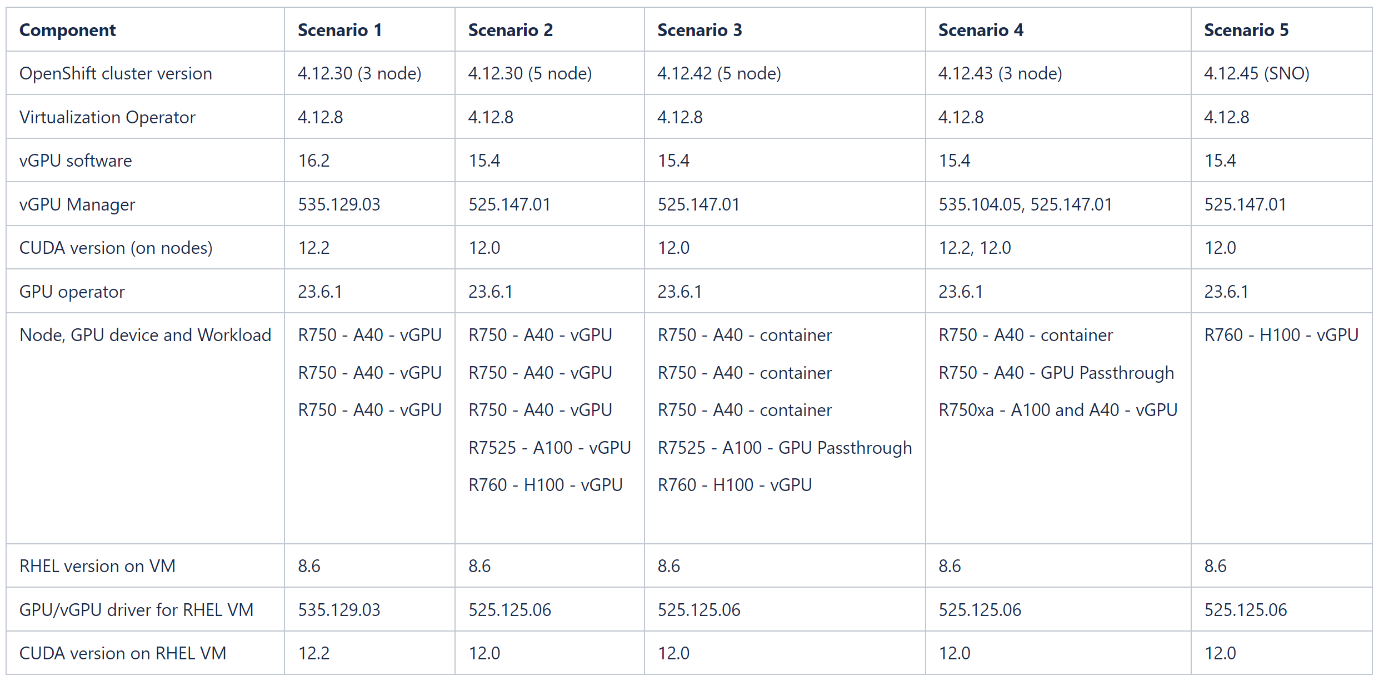
Validated scenarios and versions
References
- NVIDIA GPU Operator with OpenShift Virtualization
- NVIDIA Virtual GPU (vGPU) Software Documentation
- Configuring virtual GPUs - Virtual machines | Virtualization | OpenShift Container Platform 4.14
- GPU Operator Component Matrix
- NVIDIA Virtual GPU Software Documentation
- NVIDIA® Virtual GPU Software Supported GPUs
Related Blog Posts

OpenShift Virtualization with NVIDIA virtual GPU - Part 1
Thu, 15 Feb 2024 08:55:16 -0000
|Read Time: 0 minutes
OpenShift Virtualization with NVIDIA virtual GPU
Red Hat OpenShift Virtualization enables users to run virtual machines (VMs) alongside containers on the same platform, simplifying management and reducing the complexity of maintaining separate infrastructures and management tools. OpenShift Virtualization unifies the operations and management of VMs and containers on the same platform, helping organizations to benefit from their existing virtualization investments. The seamless deployment of OpenShift Virtualization makes configuration quick and easy for administrators. An enhanced web console provides a graphical portal to manage these virtualized resources. For more information, see OpenShift Virtualization.
NVIDIA virtual GPU
NVIDIA virtual GPU (vGPU) products leverage NVIDIA GPU capabilities to accelerate compute-intensive workloads, Artificial Intelligence/Machine Learning (AI/ML), data processing, scientific computing, and professional workstations across on-premises, hybrid, and multicloud environments.
NVIDIA vGPU technology enables multiple VMs to access and share the resources of a single physical GPU through virtualization capabilities. You can install the NVIDIA vGPU software in data centers, cloud platforms, and virtual desktop infrastructure (VDI). The vGPU software stack divides the GPU, enabling efficient GPU resource sharing, improved performance for graphics-intensive applications within virtualized environments, and flexibility in allocating GPU resources to different VMs based on workload demands.
NVIDIA vGPU technology on OpenShift accelerates both containerized and VM-based workloads through the use of GPU devices. vGPU creates a mediated device (mdev) that represents a virtual GPU instance. The performance of the physical GPU is divided among these virtual devices and made available on OpenShift Container Platform. Although you can assign multiple vGPU devices to VMs, you can only allocate a vGPU device to one VM at a time.
Common use cases in OpenShift environments include AI/ML model training and inference, data processing, and complex simulations. Scalable and efficient GPU resource utilization can significantly improve performance.
NVIDIA GPU operator for OpenShift
The NVIDIA GPU operator for OpenShift is a Kubernetes operator that automates the deployment and management of the components of GPU-enabled workloads, including device drivers, container runtimes, and monitoring tools. The operator enables OpenShift Virtualization to attach GPUs or virtual GPUs to workloads running on OpenShift Container Platform. Users can easily provision and manage GPU-enabled VMs that run complex AI/ML workloads, and the operator can work in tandem with vGPU technology to streamline the management of GPU resources.
The GPU operator is responsible for configuring every node in the cluster with the required components to support GPU devices in Red Hat OpenShift. It is flexible enough to support heterogenous clusters that may contain multiple GPU device types.
The GPU operator uses the Kubernetes operator framework to automate the deployment and management of all the NVIDIA software components on worker nodes depending on what GPU workload is configured to run on those nodes. These components include the NVIDIA drivers (to enable CUDA), the Kubernetes device plug-in for GPUs, the NVIDIA Container Toolkit, and automatic node labeling using GPU Feature Discovery, DGCM-based monitoring, and more.
Architecture
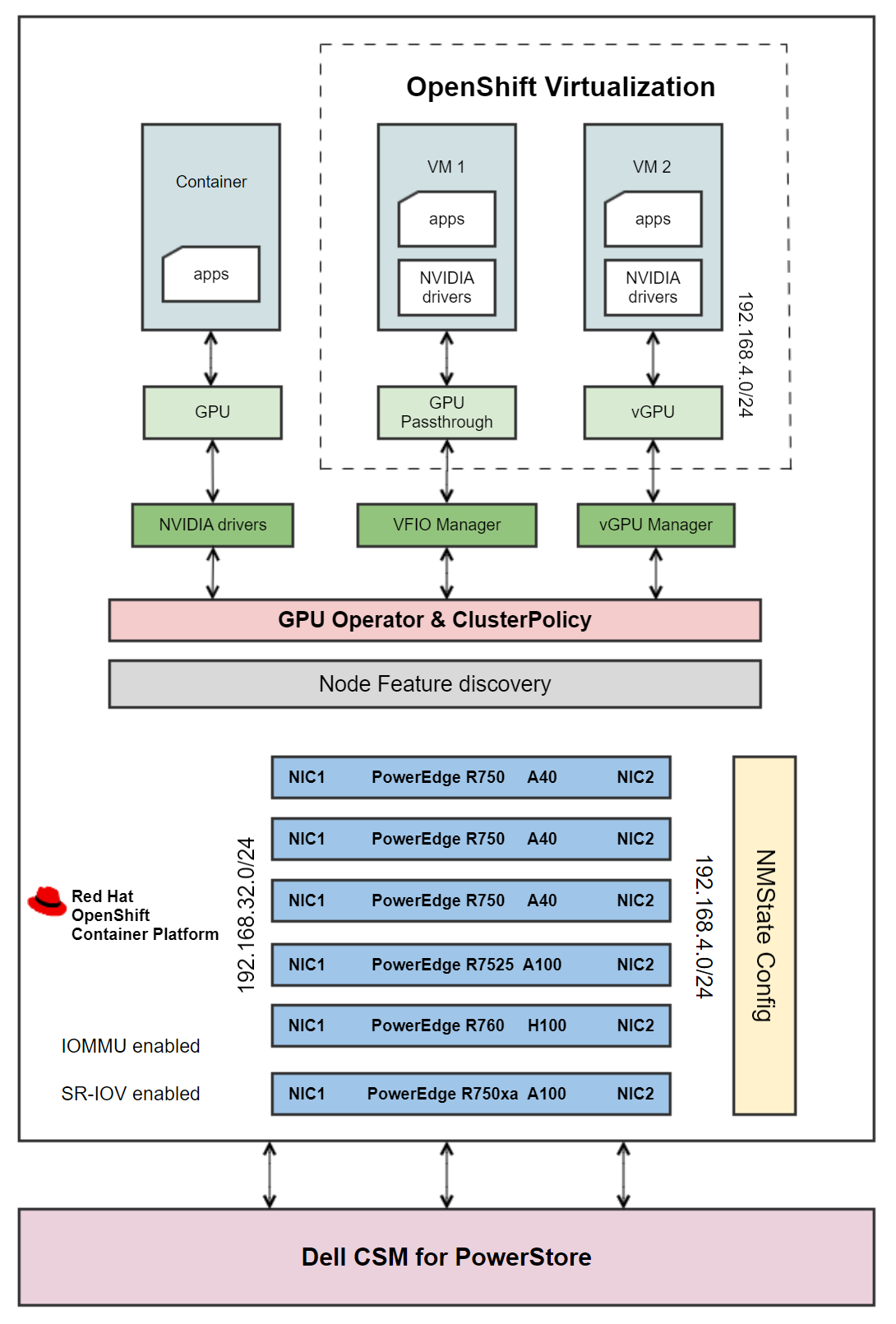 Figure 1 - Architecture diagram
Figure 1 - Architecture diagram
A CSI-enabled storage provider is configured on the cluster to provision storage for VMs. The PowerStore 5000T standard deployment model provides organizations with all the benefits of a unified storage platform for block, file, and NFS storage, while also enabling flexible growth with the intelligent scale-up and scale-out capability of appliance clusters.
Dell Container Storage Modules (CSMs) enable simple and consistent integration and automation experiences, extending enterprise storage capabilities. Storage modules for Dell PowerStore expose enterprise features of storage arrays to Kubernetes, enabling developers to effortlessly leverage these features in their deployments, making PowerStore an ideal candidate for a VM storage solution. For information about deploying Dell CSI drivers on OpenShift, see Dell CSM.
OpenShift VMs are configured to use a separate network with a VLAN that is different from the MachineNetwork that is configured in the OpenShift cluster. To achieve isolation and security, create a network for VMs on a dedicated network interface on OpenShift nodes using an IP address range that does not overlap with the cluster’s MachineNetwork. The nodes are configured with a second network, and VMs are built on this network using the Kubernetes NMState operator. For more information, see OpenShift Virtualization Networking.
Further, the OpenShift worker nodes are enabled with:
- Single Root Input/Output Virtualization (SR-IOV): SR-IOV allows for more efficient use of network resources and improves the overall performance of network traffic in virtualized environments by enhancing how physical network devices are shared.
- Input/Output Memory Management Unit (IOMMU): IOMMU isolates and protects the memory spaces of devices such as network cards or GPUs and VMs. This isolation ensures that a malfunctioning or malicious device driver cannot access or corrupt the memory that is allocated to other devices or VMs. IOMMU is essential for SR-IOV, which allows a single physical device to appear as multiple virtual devices to different VMs, providing direct and isolated access to the VMs.
An OpenShift worker node can run either GPU-accelerated container VMs with GPU passthrough, or GPU-accelerated VMs with vGPU, but not a combination. The prerequisites for running containers and VMs with GPUs vary, with the primary difference being the required drivers. During the GPU operator deployment, OpenShift worker nodes are labeled with the details of the detected GPU devices. The labels are used for scheduling pods to be deployed by the GPU operator. The ClusterPolicy custom resource (CR) that is included with the GPU operator installs the required drivers and components as determined by the node labels. For example, the data center driver is needed for containers, the vfio-pci driver is needed for GPU passthrough, and the NVIDIA vGPU Manager is needed for creating vGPU devices. For more information, see NVIDIA GPU Operator with OpenShift Virtualization.
The architecture diagram shows how the GPU operator is configured to deploy different software components on worker nodes depending on what GPU workload is configured to run on those nodes:
- Containers: The GPU operator creates the NVIDIA GPU device drivers, and a container is assigned a whole GPU. The GPU operator also installs components such as the NVIDIA Container Toolkit, NVIDIA device plug-in, CUDA validator, DCGM exporter, and operator validator.
- VMs with Passthrough GPU: The VFIO driver that is created by the GPU operator gives the VM direct and exclusive access to the GPU resources, dedicating an entire physical GPU to a VM. This configuration is commonly used in scenarios where a VM requires direct access to the full capabilities of a GPU, such as high-performance computing (HPC) workloads, gaming VMs, or applications that demand GPU acceleration.
- VMs with vGPU: The vGPU manager enables virtualization of a physical GPU. A single GPU is sliced into multiple vGPU instances, allowing VMs to share the GPU resources.
For containerized workloads that do not require the capability of an entire GPU, you can configure an OpenShift cluster with Multi Instance GPU (MIG). By allowing the partitioning of a single physical GPU into multiple smaller instances, NVIDIA MIG technology enables each instance to be allocated to different containers, providing isolation and resource allocation for different tasks. MIG is different from vGPU in that the isolation is implemented by the device firmware. Also, MIGuses hardware boundaries, whereas vGPU is a higher-level, software-only approach.
When the driver installation is complete, OpenShift Virtualization automatically creates vGPUs and PCI Host devices based on GPU device configuration information that is provided in the HyperConverged CR. These devices are then assigned to VMs.
For detailed instructions for installing OpenShift Virtualization on the hardware depicted in Figure 1, as well as component versions and GPU workload combinations that have been validated across nodes, see OpenShift Virtualization with NVIDIA virtual GPU - Part 2.
References
- NVIDIA GPU Operator with OpenShift Virtualization
- NVIDIA Virtual GPU (vGPU) Software Documentation
- Configuring virtual GPUs
- GPU Operator Component Matrix
- NVIDIA Virtual GPU Software Documentation

NVIDIA AI Enterprise on Red Hat OpenShift
Wed, 15 Nov 2023 14:20:48 -0000
|Read Time: 0 minutes
NVIDIA AI Enterprise on Red Hat OpenShift
Red Hat OpenShift Container Platform is an enterprise-grade Kubernetes platform for deploying and managing secure and hardened Kubernetes clusters at scale. This Kubernetes distribution enables users to easily configure and use GPU resources to accelerate deep learning (DL) and machine learning (ML) workloads.
The NVIDIA H100 Tensor Core GPU, an integral part of the NVIDIA data center platform, is a high-performance GPU that is designed and optimized for AI workloads that are intended for data center and cloud-based applications. The GPU features major advances to accelerate AI, HPC, memory bandwidth, interconnect, and communication at data center scale. For more information, see NVIDIA H100 Tensor Core GPU.
NVIDIA AI Enterprise
NVIDIA AI Enterprise is an end-to-end, secure, cloud-native suite of AI software that enables organizations to solve new challenges while increasing operational efficiency. NVIDIA AI Enterprise accelerates the data science pipeline and streamlines development and deployment of production AI, including generative AI, computer vision, speech AI, and more. For more information, see NVIDIA AI Enterprise.
NVIDIA NGC catalog
The NVIDIA NGC catalog is a curated set of GPU-optimized software for AI, HPC, and Visualization. The NGC catalog simplifies building, customizing, and integrating GPU-optimized software into workflows on a variety of platforms, accelerating the time to solutions for users. The catalog includes containers, pre-trained models, Helm charts for Kubernetes deployments, and industry-specific AI toolkits. These toolkits consist of software development kits (SDKs) for NVDIA AI Enterprise that can be deployed on OpenShift Container Platform.
Prerequisites for installing NVIDIA AI Enterprise on OpenShift Container Platform
- An OpenShift cluster with a minimum of three nodes, at least one of which has an NVIDIA-supported GPU. For the list of supported GPUs, see the NVIDIA Product Support Matrix.
- A service instance for licenses. This blog briefly describes how to deploy a containerized DLS instance on OpenShift Container Platform that serves licenses to the clients.
NVIDIA license system
The NVIDIA license system is used to provide software licenses to licensed NVIDIA software products. The licenses are available from the NVIDIA Licensing Portal (access requires NVIDIA login credentials). The NVIDIA license system supports the following types of service instances: a Cloud License Service (CLS) instance that is hosted on the NVIDIA Licensing Portal, and a Delegated License Service (DLS) instance that is hosted on-premises at a location that is accessible from your private network, such as inside your data center.
A DLS instance is fully disconnected from the NVIDIA Licensing Portal. Licenses are downloaded from the portall and uploaded manually to the instance. The following figure depicts the flow:
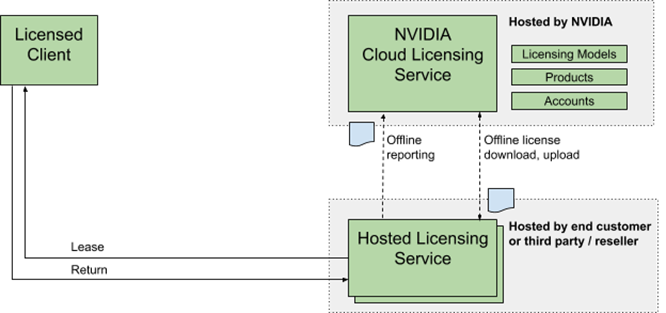 Figure 1. NVIDIA DLS instance license system workflow
Figure 1. NVIDIA DLS instance license system workflow
The following DLS software image types are available:
- A virtual appliance image to be installed in a virtual machine on a supported hypervisor.
- A containerized software image for bare-metal deployment on a supported container orchestration platform.
Setting up a DLS instance
1. Download the latest "NLS License Server (DLS) 2.1 for Container Platforms" software from the NVIDIA Licensing Portal.
2. To import DLS appliance and PostgreSQL, run the following commands:
podman load --input dls_appliance_2.1.0.tar.gz
podman load --input dls_pgsql_2.1.0.tar.gz
3. Upload the DLS appliance artifact and the PostgreSQL database artifact images to a private repository.
4. Edit the deployment files for the DLS appliance artifact, and then use the PostgreSQL database artifact to pull these artifacts from the private repository.
You must provide an IP address for DLS_PUBLIC_IP. Optionally, you can edit the DLS default ports in the nls-si-0-deployment.yaml and nls-si-0-service.yaml deployment files. If a registry secret is required to pull the images from the private repository, edit the deployment files for the DLS appliance and the PostgreSQL database to reference the secret.
5. Create a Postgres instance by running the following command:
oc create -f directory/postgres-nls-si-0-deployment.yaml
6. Fetch the IP address of the Postgres pod that you created in the previous step, and then set the DLS_DB_HOST environment variable in the nls-si-0-deployment.yaml file to the IP address of the postgres pod:
oc create -f directory/nls-si-0-deployment.yaml
7. Access the DLS instance at https://<worker-node-ip>:30001. Register the default admin user dls_admin with a new password during the first login.
8. Create a license server on the NVIDIA Licensing Portal, and then add the licenses for the products that you want to allot to this license server. 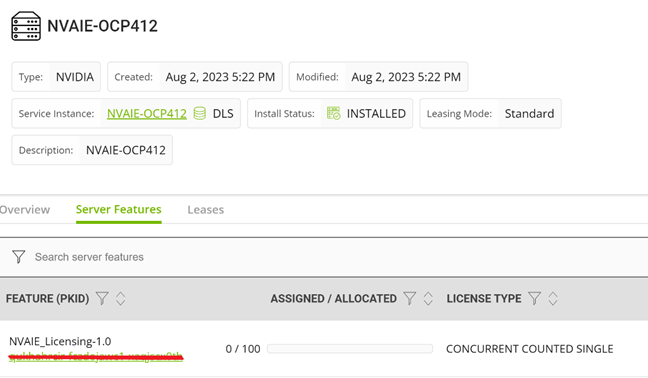 Figure 2. Adding a license to the DLS instance
Figure 2. Adding a license to the DLS instance
9. Register the on-premises DLS instance by uploading the DLS token file dls_instance_token_mm-dd-yyyy-hh-mm-ss.tok to the NVIDIA Licensing Portal. Bind the license server that you created in the preceding step to the registered service instance.
10. Download the license file license_mm-dd-yyyy-hh-mm-ss.bin from the license server on the portal and upload it to your on-premises DLS instance. The licenses on the server are made available to the DLS instance.
11. Generate the client configuration token file from the DLS instance. The client configuration token contains information about the service instance, license servers, and fulfillment conditions to be used to serve a license in response to a client request.
12. Copy the client configuration token to clients so that the service instance has the necessary information to serve licenses to clients.
Installing NVIDIA AI Enterprise on OpenShift
1. Install the Node Feature Discovery (NFD) operator.
Install the NFD operator from the embedded Red Hat OperatorHub. After the operator is installed, create an NFD API so that the NFD operator can label the cluster nodes that have GPUs.
2. Install the NVIDIA GPU operator.
Install the NVIDIA GPU operator from the embedded Red Hat OperatorHub. The GPU operator enables Kubernetes cluster engineers to manage GPU nodes just like CPU nodes in the cluster. The operator installs and manages the life cycle of software components so that GPU-accelerated applications can be run on Kubernetes. This operator is installed in the nvidia-gpu-operator namespace by default.
3. Create an NGC secret.
Create an image pull secret object n the nvidia-gpu-operator namespace. This object is for storing the NGC API key to authenticate your access to the NGC container registry. Generate the API key from the NGC catalog.
Use the following credentials for the NGC secret:
- Authentication type in the secret Image registry: the registry server address is nvcr.io/nvaie
- Username: $oauthtoken
- Password: the generated API key.
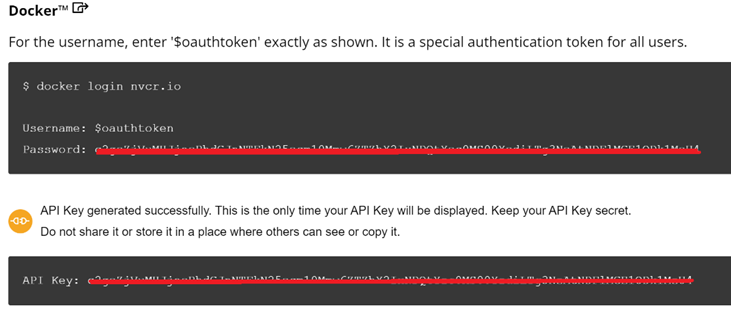 Figure 3. NGC secret
Figure 3. NGC secret
4. Create a ConfigMap with configuration data.
Create a configmap in the nvidia-gpu-operator namespace with the client configuration token as data.
kind: ConfigMap
apiVersion: v1
metadata:
name: licensing-config
data:
client_configuration_token.tok: >-
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiIwY2QxZ<...>
gridd.conf: '# empty file'
5. Create a Cluster Policy Custom Resource instance.
When you install the NVIDIA GPU operator in OpenShift Container Platform, a custom resource definition for a cluster policy is created. The policy configures the GPU stack that will be deployed, configuring the image names and repository, pod restrictions or credentials, and so on. When creating the cluster policy from the OpenShift web console, make the following customizations:
1. Enter the configmap containing the client configuration token that you created in the NVIDIA GPU/vGPU driver configuration file and enable the NLS.
2. Enable the deployment of the NVIDIA driver through the operator. The image repository is nvcr.io/nvaie.
3. Enter the NGC secret name in the driver configuration.
4. Specify the image name and NVIDIA vGPU driver version in the NVIDIA GPU/vGPU driver configuration section. Get this information from the NGC catalog, as shown in the following figure:
kind: ConfigMap
apiVersion: v1
metadata:
name: licensing-config
data:
client_configuration_token.tok: >-
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiIwY2QxZ<...>
gridd.conf: '# empty file'
Figure 4. Configmap with Client configuration token
For a cluster on OpenShift Container Platform version 4.12, the NVIDIA GPU driver image is vgpu-guest-driver-3-1 and the version is 525.105.17. The GPU operator installs all the components that are required to set up the NVIDIA GPUs in the OpenShift cluster.
Validation
Environment overview: The Dell OpenShift validation team used Dell PowerEdge servers hosting Red Hat OpenShift Platform 4.12 to validate the NVIDIA AI Enterprise on OpenShift. The validated environment consisted of three compute nodes hosted on PowerEdge R760, R750 and R7525 servers and equipped respectively with NVIDIA GPU H100, A40, and A100. For more information about deploying an OpenShift cluster on Dell-powered bare metal servers, see the Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide.
A containerized DLS instance is present on the same OpenShift cluster with all the required licenses.
The team created a TensorFlow pod using the "tensorflow-3-1" image from the nvcr.io/nvaie repository by running the following commands:
apiVersion: v1
kind: Pod
metadata:
name: gpu
spec:
nodeSelector:
nvidia.com/gpu.product: NVIDIA-H100-PCIe
containers:
- image: nvcr.io/nvaie/tensorflow-3-1:23.03-tf1-nvaie-3.1-py3
name: tensorflow
command: ["/bin/sh","-c"]
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
The ResNet-50 convolutional neural network with FP32 and FP16 precision from inside the TensorFlow pod ran successfully.
To run the test, the team used the following commands:
cd /workspace/nvidia-examples/cnn
python resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16
python resnet.py --layers 50 -b 64 -i 300 -u batch --precision fp32
References
Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide
OpenShift on Bare Metal Deployment Guide
NVIDIA License System v3.2.0
NVIDIA User Guide
NVIDIA AI Enterprise with OpenShift