




OneFS SmartPools Transfer Limits Configuration and Management

In the first article in this series, we looked at the architecture and considerations of the new SmartPools transfer limits in OneFS 9.5. Now, we turn our attention to the configuration and management of this feature.
From the control plane side, OneFS 9.5 contains several WebUI and CLI enhancements to reflect the new SmartPools transfer limits functionality. Probably the most obvious change is in the Local storage usage status histogram, where tiers and their child node pools have been aggregated for a more logical grouping. Also, blue limit-lines have been added above each of the storage pools, and a red warning status is displayed for any pools that have exceeded the transfer limit.
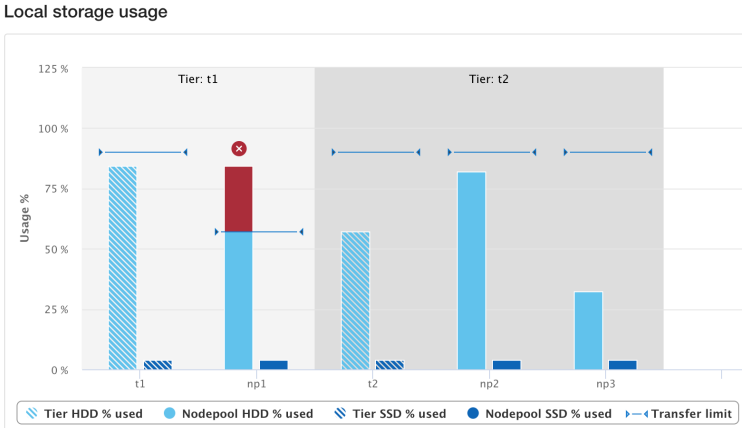
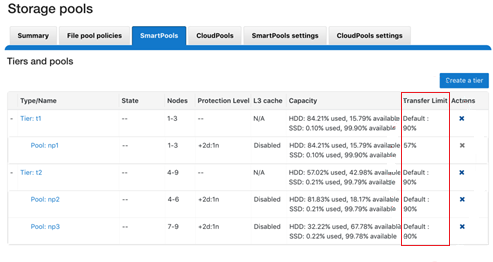
Similarly, the storage pools status page now includes transfer limit details, with the 90% limit displayed for any storage pools using the default setting.
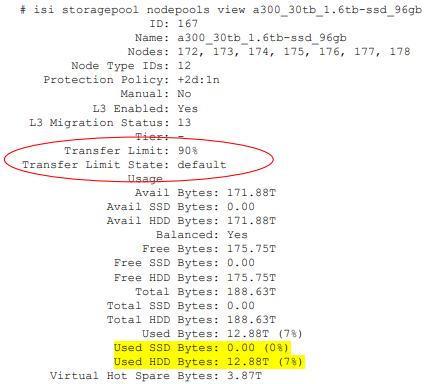
From the CLI, the isi storagepool nodepools view command reports the transfer limit status and percentage for a pool. The used SSD and HDD bytes percentages in the command output indicate where the pool utilization is relative to the transfer limit.
The storage transfer limit can be easily configured from the CLI as either for a specific pool, as a default, or disabled, using the new –transfer-limit and –default-transfer-limit flags.
The following CLI command can be used to set the transfer limit for a specific storage pool:
# isi storagepool nodepools/tier modify --transfer-limit={0-100, default, disabled} For example, to set a limit of 80% on an A200 nodepool:
# isi storagepool a200_30tb_1.6tb-ssd_96gb modify --transfer-limit=80
Or to set the default limit of 90% on tier perf1:
# isi storagepool perf1 --transfer-limit=default
Note that setting the transfer limit of a tier automatically applies to all its child node pools, regardless of any prior child limit configurations.
The global isi storage settings view CLI command output shows the default transfer limit, which is 90%, but it can be configured between 0 to 100%.
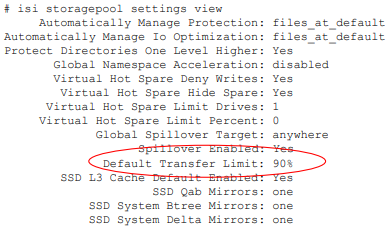
This default limit can be reconfigured from the CLI with the following syntax:
# isi storagepool settings modify --default-transfer-limit={0-100, disabled}For example, to set a new default transfer limit of 85%:
# isi storagepool settings modify --default-transfer-limit=85
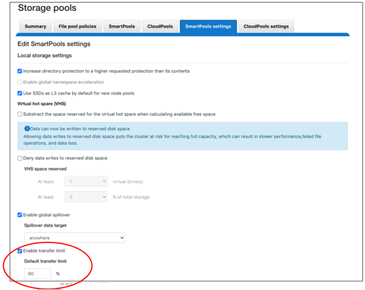
And the same changes can be made from the SmartPools WebUI, by navigating to Storage pools > SmartPools settings:
Once a SmartPools job has been completed in OneFS 9.5, the job report contains a new field, files not moved due to transfer limit exceeded.
# isi job reports view 1056 ... ... Policy/testpolicy/Access changes skipped 0 Policy/testpolicy/ADS containers matched 'head’ 0 Policy/testpolicy/ADS containers matched 'snapshot’ 0 Policy/testpolicy/ADS streams matched 'head’ 0 Policy/testpolicy/ADS streams matched 'snapshot’ 0 Policy/testpolicy/Directories matched 'head’ 0 Policy/testpolicy/Directories matched 'snapshot’ 0 Policy/testpolicy/File creation templates matched 0 Policy/testpolicy/Files matched 'head’ 0 Policy/testpolicy/Files matched 'snapshot’ 0 Policy/testpolicy/Files not moved due to transfer limit exceeded 0 Policy/testpolicy/Files packed 0 Policy/testpolicy/Files repacked 0 Policy/testpolicy/Files unpacked 0 Policy/testpolicy/Packing changes skipped 0 Policy/testpolicy/Protection changes skipped 0 Policy/testpolicy/Skipped files already in containers 0 Policy/testpolicy/Skipped packing non-regular files 0 Policy/testpolicy/Skipped packing regular files 0
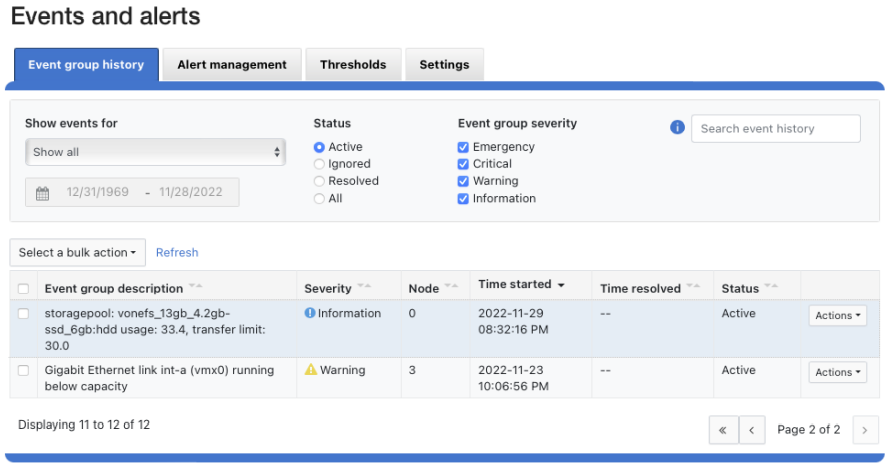
Additionally, the SYS STORAGEPOOL FILL LIMIT EXCEEDED alert is triggered at the Info level when a storage pool’s usage has exceeded its transfer limit. Each hour, CELOG fires off a monitor helper script that measures how full each storage pool is relative to its transfer limit. The usage is gathered by reading from the disk pool database, and the transfer limits are stored in gconfig. If a node pool has a transfer limit of 50% and usage of 75%, the monitor helper would report a measurement of 150%, triggering an alert.
# isi event view 126 ID: 126 Started: 11/29 20:32 Causes Long: storagepool: vonefs_13gb_4.2gb-ssd_6gb:hdd usage: 33.4, transfer limit: 30.0 Lnn: 0 Devid: 0 Last Event: 2022-11-29T20:32:16 Ignore: No Ignore Time: Never Resolved: No Resolve Time: Never Ended: -- Events: 1 Severity: information
And from the WebUI:
And there you have it: Transfer limits, and the first step in the evolution toward a smarter SmartPools.
Related Blog Posts

OneFS SmartPools Transfer Limits
Wed, 15 Feb 2023 22:53:09 -0000
|Read Time: 0 minutes
The new OneFS 9.5 release introduces the first phase of engineering’s Smarter SmartPools initiative, and delivers a new feature called SmartPools transfer limits.
The goal of SmartPools Transfer Limits is to address spill over. Previously, when file pool policies were executed, OneFS had no guardrails to protect against overfilling the destination or target storage pool. So if a pool was overfilled, data would unexpectedly spill over into other storage pools.
An overflow would result in storagepool usage exceeding 100%, and cause the SmartPools job itself to do a considerable amount of unnecessary work, trying to send files to a given storagepool. But because the pool was full, it would then have to send those files off to another storage pool that was below capacity. This would result in data going where it wasn’t intended, and the potential for individual files to end up getting split between pools. Also, if the full pool was on the most highly performing storage in the cluster, all subsequent newly created data would now land on slower storage, affecting its throughput and latency. The recovery from a spillover can be fairly cumbersome because it’s tough for the cluster to regain balance, and urgent system administration may be required to free space on the affected tier.
In order to address this, SmartPools Transfer Limits allows a cluster admin to configure a storagepool capacity-usage threshold, expressed as a percentage, and beyond which file pool policies stop moving data to that particular storage pool.
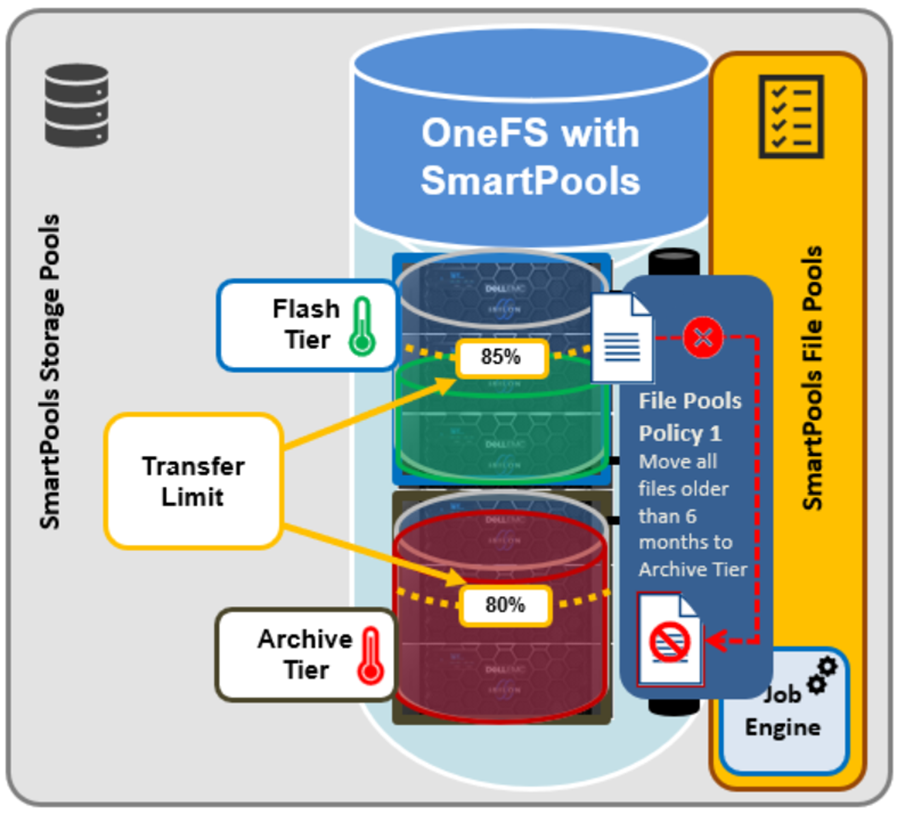
These transfer limits only take effect when running jobs that apply filepool policies, such as SmartPools, SmartPoolsTree, and FilePolicy.
The main benefits of this feature are two-fold:
- Safety, in that OneFS avoids undesirable actions, so the customer is prevented from getting into escalation situations, because SmartPools won’t overfill storage pools.
- Performance, because transfer limits avoid unnecessary work, and allow the SmartPools job to finish sooner.
Under the hood, a cluster’s storagepool SSD and HDD usage is calculated using the same algorithm as reported by the ‘isi storagepools list’ CLI command. This means that a pool’s VHS (virtual hot spare) reserved capacity is respected by SmartPools transfer limits. When a SmartPools job is running, there is at least one worker on each node processing a single LIN at any given time. In order to calculate the current HDD and SSD usage per storagepool, the worker must read from the diskpool database. To circumvent this potential bottleneck, the filepool policy algorithm caches the diskpool database contents in memory for up to 10 seconds.
Transfer limits are stored in gconfig, and a separate entry is stored within the ‘smartpools.storagepools’ hierarchy for each explicitly defined transfer limit.
Note that in the SmartPools lexicon, ‘storage pool’ is a generic term denoting either a tier or nodepool. Additionally, SmartPools tiers comprise one or more constituent nodepools.
Each gconfig transfer limit entry stores a limit value and the diskpool database identifier of the storagepool to which the transfer limit applies. Additionally, a ‘transfer limit state’ field specifies which of three states the limit is in:
Limit state | Description |
Default | Fallback to the default transfer limit. |
Disabled | Ignore transfer limit. |
Enabled | The corresponding transfer limit value is valid. |
A SmartPools transfer limit does not affect the general ingress, restriping, or reprotection of files, regardless of how full the storage pool is where that file is located. So if you’re creating or modifying a file on the cluster, it will be created there anyway. This will continue up until the pool reaches 100% capacity, at which point it will then spill over.
The default transfer limit is 90% of a pool’s capacity. This applies to all storage pools where the cluster admin hasn’t explicitly set a threshold. Note also that the default limit doesn’t get set until a cluster upgrade to OneFS 9.5 has been committed. So if you’re running a SmartPools policy job during an upgrade, you’ll have the preexisting behavior, which is to send the file to wherever the file pool policy instructs it to go. It’s also worth noting that, even though the default transfer limit is set on commit, if a job was running over that commit edge, you’d have to pause and resume it for the new limit behavior to take effect. This is because the new configuration is loaded lazily when the job workers are started up, so even though the configuration changes, a pause and resume is needed to pick up those changes.
SmartPools itself needs to be licensed on a cluster in order for transfer limits to work. And limits can be configured at the tier or nodepool level. But if you change the limit of a tier, it automatically applies to all of its child nodepools, regardless of any prior child limit configurations. The transfer limit feature can also be disabled, which results in the same spillover behavior OneFS always displayed, and any configured limits will not be respected.
Note that a filepool policy’s transfer limits algorithm does not consider the size of the file when deciding whether to move it to the policy’s target storagepool, regardless of whether the file is empty, or a large file. Similarly, a target storagepool’s usage must exceed its transfer limit before the filepool policy will stop moving data to that target pool. The assumption here is that any storagepool usage overshoot is insignificant in scale compared to the capacity of a cluster’s storagepool.
A SmartPools file pool policy allows you to send snapshot or HEAD data blocks to different targets, if so desired.

Because the transfer limit applies to the storagepool itself, and not to the file pool policy, it’s important to note that, if you’ve got varying storagepool targets and one file pool policy, you may have a situation where the head data blocks do get moved. But if the snapshot is pointing at a storage pool that has exceeded its transfer limit, its blocks will not be moved.
File pool policies also allow you to specify how a mixed node’s SSDs are used: either as L3 cache, or as an SSD strategy for head and snapshot blocks. If the SSDs in a node are configured for L3, they are not being used for storage, so any transfer limits are irrelevant to it. As an alternative to L3 cache, SmartPools offers three main categories of SSD strategy:
- Avoid, which means send all blocks to HDD
- Data, which means send everything to SSD
- Metadata Read or Write, which sends varying numbers of metadata mirrors to SSD, and data blocks to hard disk.

To reflect this, SmartPools transfer limits are slightly nuanced when it comes to SSD strategies. That is, if the storagepool target contains both HDD and SSD, the usage capacity of both mediums needs to be below the transfer limit in order for the file to be moved to that target. For example, take two node pools, NP1 and NP2.

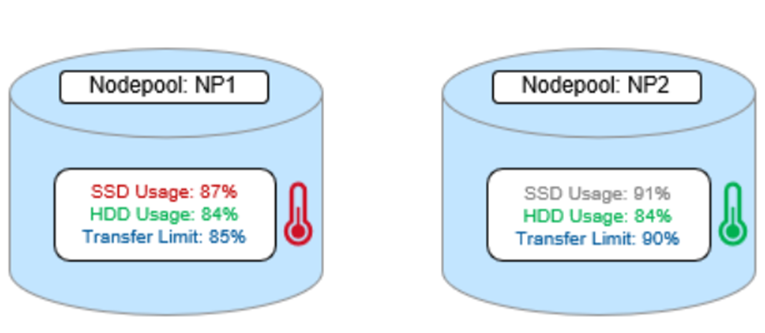
A file pool policy, Pol1, is configured and which matches all files under /ifs/dir1, with an SSD strategy of Metadata Write, and pool NP1 as the target for HEAD’s data blocks. For snapshots, the target is NP2, with an ‘avoid’ SSD strategy, so just writing to hard disk for both snapshot data and metadata.
When a SmartPools job runs and attempts to apply this file pool policy, it sees that SSD usage is above the 85% configured transfer limit for NP1. So, even though the hard disk capacity usage is below the limit, neither HEAD data nor metadata will be sent to NP1.
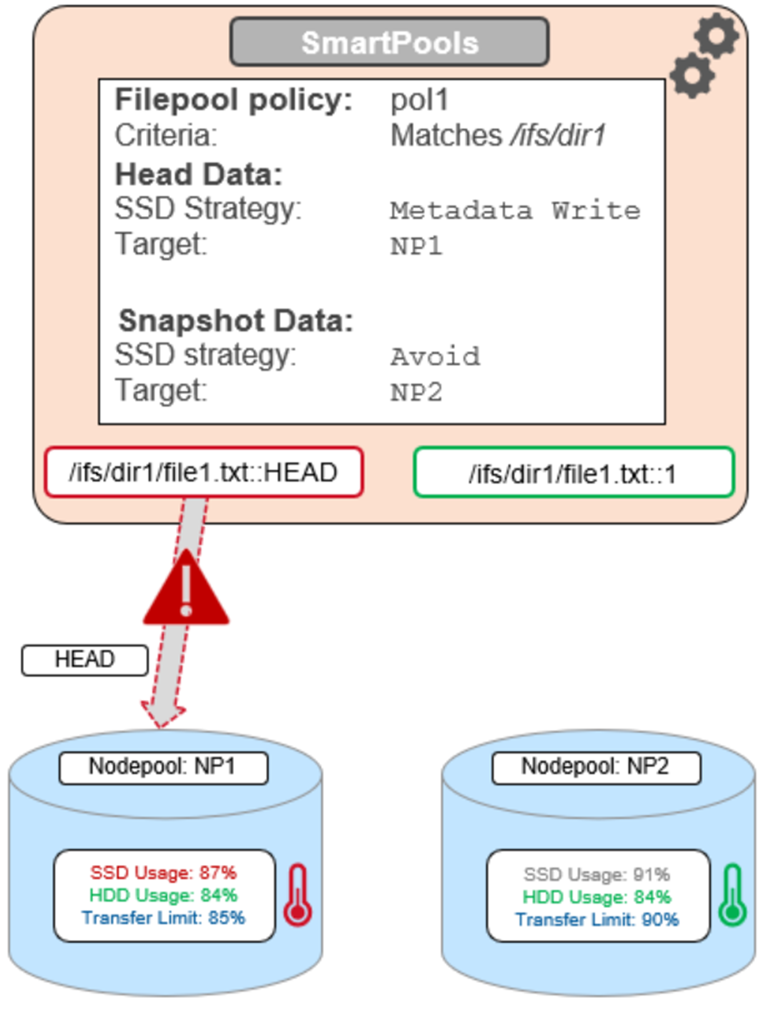
For the snapshot, the SSD usage is also above the NP2 pool’s transfer limit of 90%.
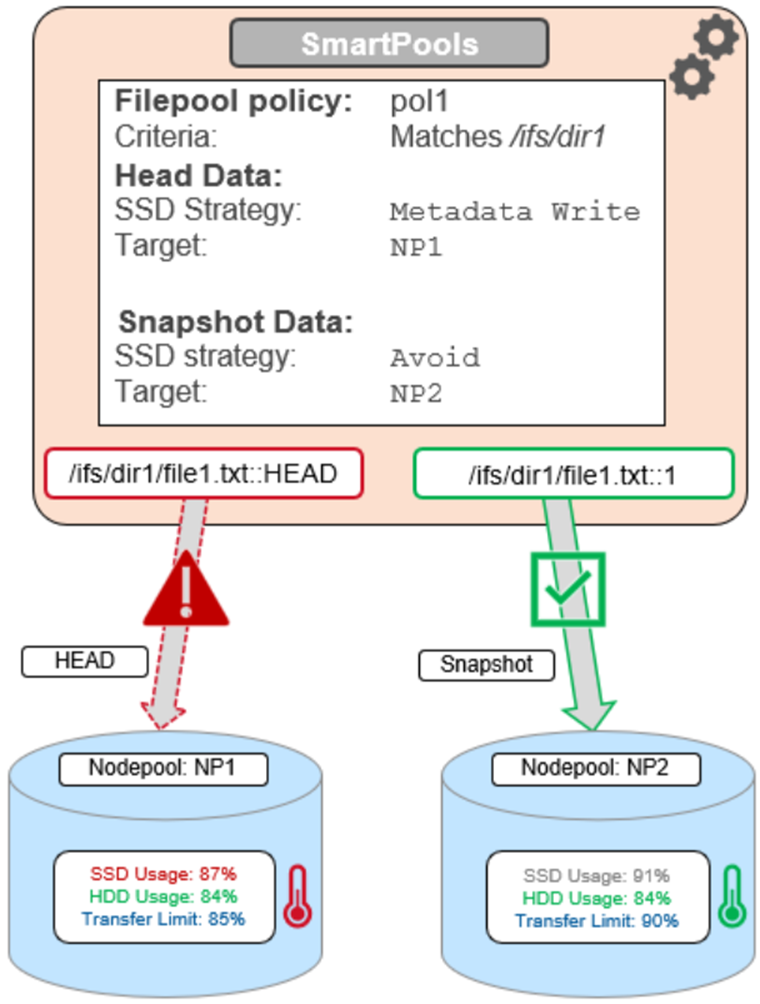
However, because the SSD strategy is ‘avoid’, and because the hard disk usage is below the limit, the snapshot’s data and metadata get successfully sent to the NP2 HDDs.
Author: Nick Trimbee

OneFS SmartPools and the FilePolicy Job
Fri, 24 Jun 2022 18:22:15 -0000
|Read Time: 0 minutes
Traditionally, OneFS has used the SmartPools jobs to apply its file pool policies. To accomplish this, the SmartPools job visits every file, and the SmartPoolsTree job visits a tree of files. However, the scanning portion of these jobs can result in significant random impact to the cluster and lengthy execution times, particularly in the case of the SmartPools job. To address this, OneFS also provides the FilePolicy job, which offers a faster, lower impact method for applying file pool policies than the full-blown SmartPools job.
But first, a quick Job Engine refresher…
As we know, the Job Engine is OneFS’ parallel task scheduling framework, and is responsible for the distribution, execution, and impact management of critical jobs and operations across the entire cluster.
The OneFS Job Engine schedules and manages all data protection and background cluster tasks: creating jobs for each task, prioritizing them, and ensuring that inter-node communication and cluster wide capacity utilization and performance are balanced and optimized. Job Engine ensures that core cluster functions have priority over less important work and gives applications integrated with OneFS – Isilon add-on software or applications integrating to OneFS by means of the OneFS API – the ability to control the priority of their various functions to ensure the best resource utilization.
Each job, such as the SmartPools job, has an “Impact Profile” comprising a configurable policy and a schedule that characterizes how much of the system’s resources the job will take – plus an Impact Policy and an Impact Schedule. The amount of work a job has to do is fixed, but the resources dedicated to that work can be tuned to minimize the impact to other cluster functions, like serving client data.
Here’s a list of the specific jobs that are directly associated with OneFS SmartPools:
Job | Description |
SmartPools | Job that runs and moves data between the tiers of nodes within the same cluster. Also executes the CloudPools functionality if licensed and configured. |
SmartPoolsTree | Enforces SmartPools file policies on a subtree. |
FilePolicy | Efficient changelist-based SmartPools file pool policy job. |
IndexUpdate | Creates and updates an efficient file system index for FilePolicy job. |
SetProtectPlus | Applies the default file policy. This job is disabled if SmartPools is activated on the cluster. |
In conjunction with the IndexUpdate job, FilePolicy improves job scan performance by using a ‘file system index’, or changelist, to find files needing policy changes, rather than a full tree scan.
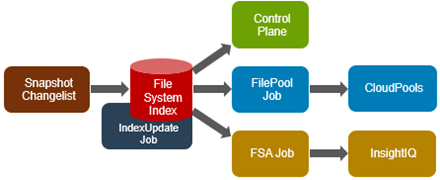
Avoiding a full treewalk dramatically decreases the amount of locking and metadata scanning work the job is required to perform, reducing impact on CPU and disk – albeit at the expense of not doing everything that SmartPools does. The FilePolicy job enforces just the SmartPools file pool policies, as opposed to the storage pool settings. For example, FilePolicy does not deal with changes to storage pools or storage pool settings, such as:
- Restriping activity due to adding, removing, or reorganizing node pools
- Changes to storage pool settings or defaults, including protection
However, most of the time, SmartPools and FilePolicy perform the same work. Disabled by default, FilePolicy supports the full range of file pool policy features, reports the same information, and provides the same configuration options as the SmartPools job. Because FilePolicy is a changelist-based job, it performs best when run frequently – once or multiple times a day, depending on the configured file pool policies, data size, and rate of change.
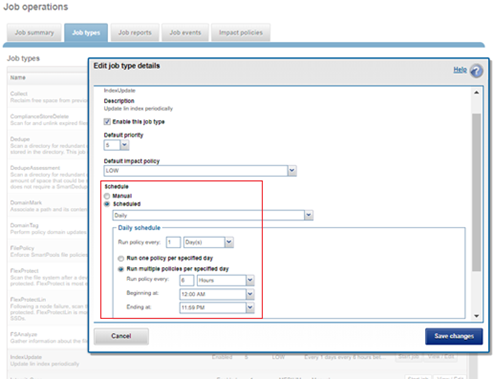
Job schedules can easily be configured from the OneFS WebUI by navigating to Cluster Management > Job Operations, highlighting the desired job, and selecting ‘View\Edit’. The following example illustrates configuring the IndexUpdate job to run every six hours at a LOW impact level with a priority value of 5:
When enabling and using the FilePolicy and IndexUpdate jobs, the recommendation is to continue running the SmartPools job as well, but at a reduced frequency (monthly).
In addition to running on a configured schedule, the FilePolicy job can also be executed manually.
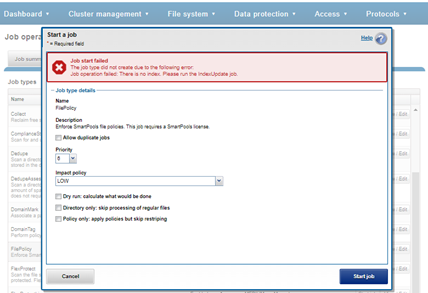
FilePolicy requires access to a current index. If the IndexUpdate job has not yet been run, attempting to start the FilePolicy job will fail with the error shown in the following figure. Instructions in the error message appear, prompting to run the IndexUpdate job first. When the index has been created, the FilePolicy job will run successfully. The IndexUpdate job can be run several times daily (that is, every six hours) to keep the index current and prevent the snapshots from getting large.
Consider using the FilePolicy job with the job schedules below for workflows and datasets with the following characteristics:
- Data with long retention times
- Large number of small files
- Path-based File Pool filters configured
- Where the FSAnalyze job is already running on the cluster (InsightIQ monitored clusters)
- There is already a SnapshotIQ schedule configured
- When the SmartPools job typically takes a day or more to run to completion at LOW impact
For clusters without the characteristics described above, the recommendation is to continue running the SmartPools job as usual and not to activate the FilePolicy job.
The following table provides a suggested job schedule when deploying FilePolicy:
Job | Schedule | Impact | Priority |
FilePolicy | Every day at 22:00 | LOW | 6 |
IndexUpdate | Every six hours, every day | LOW | 5 |
SmartPools | Monthly – Sunday at 23:00 | LOW | 6 |
Because no two clusters are the same, this suggested job schedule may require additional tuning to meet the needs of a specific environment.
Note that when clusters running older OneFS versions and the FSAnalyze job are upgraded to OneFS 8.2.x or later, the legacy FSAnalyze index and snapshots are removed and replaced by new snapshots the first time that IndexUpdate is run. The new index stores considerably more file and snapshot attributes than the old FSA index. Until the IndexUpdate job effects this change, FSA keeps running on the old index and snapshots.
Author: Nick Trimbee