




OneFS Job Execution and Node Exclusion

Up through OneFS 9.2, a job engine job was an all or nothing entity. Whenever a job ran, it involved the entire cluster – regardless of individual node type, load, or condition. As such, any nodes that were overloaded or in a degraded state could still impact the execution ability of the job at large.
To address this, OneFS 9.3 provides the capability to exclude one or more nodes from participating in running a job. This allows the temporary removal of any nodes with high load, or other issues, from the job execution pool so that jobs do not become stuck.
The majority of the OneFS job engine’s jobs have no default schedule and are typically manually started by a cluster administrator or process. Other jobs such as FSAnalyze, MediaScan, ShadowStoreDelete, and SmartPools, are normally started via a schedule. The job engine can also initiate certain jobs on its own. For example, if the SnapshotIQ process detects that a snapshot has been marked for deletion, it will automatically queue a SnapshotDelete job.
The Job Engine will also execute jobs in response to certain system event triggers. In the case of a cluster group change, for example the addition or subtraction of a node or drive, OneFS automatically informs the job engine, which responds by starting a FlexProtect job. The coordinator notices that the group change includes a newly-smart-failed device and then initiates a FlexProtect job in response.
Job administration and execution can be controlled via the WebUI, CLI, or platform API. A job can be started, stopped, paused and resumed, and this is managed via the job engines’ check-pointing system. For each of these control methods, additional administrative security can be configured using roles-based access control (RBAC).
The job engine’s impact control and work throttling mechanism can limit the rate at which individual jobs can run. Throttling is employed at a per-manager process level, so job impact can be managed both granularly and gracefully.
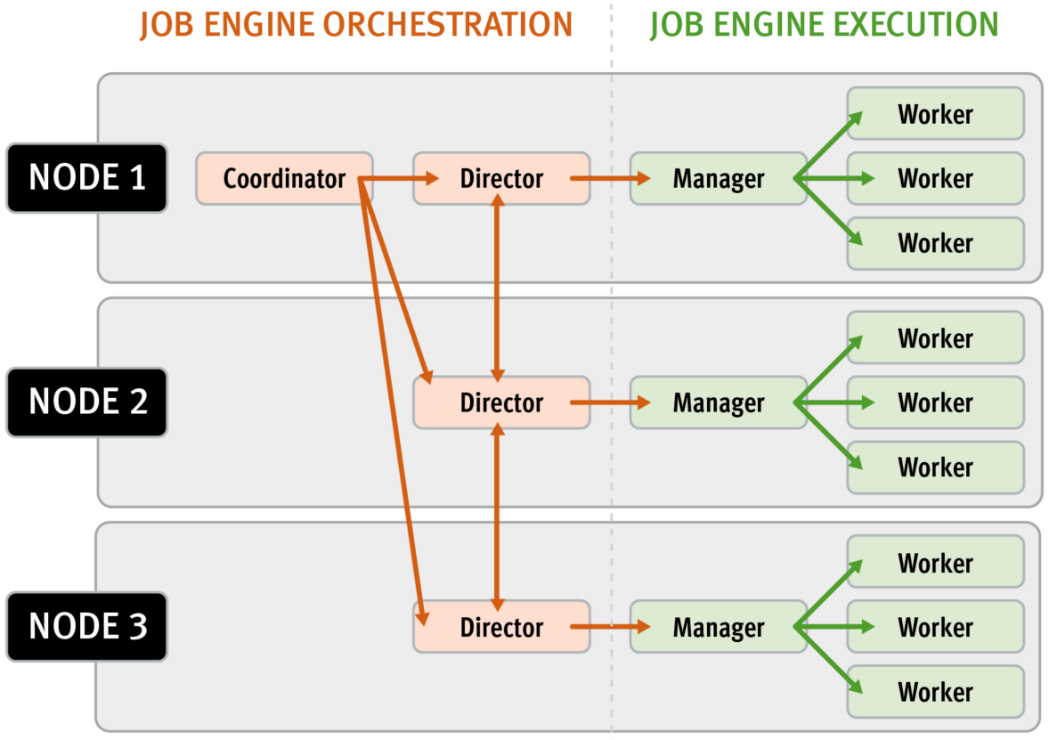
Every twenty seconds, the coordinator process gathers cluster CPU and individual disk I/O load data from all the nodes across the cluster. The coordinator uses this information, in combination with the job impact configuration, to decide how many threads can run on each cluster node to service each running job. This can be a fractional number, and fractional thread counts are achieved by having a thread sleep for a given percentage of each second.
Using this CPU and disk I/O load data, every sixty seconds the coordinator evaluates how busy the various nodes are and makes a job throttling decision, instructing the various job engine processes as to the action they need to take. This enables throttling to be sensitive to workloads in which CPU and disk I/O load metrics yield different results. There are also separate load thresholds tailored to the different classes of drives used in OneFS powered clusters, from capacity optimized SATA disks to flash-based SSDs.
Configuration is via the OneFS CLI and gconfig and is global, such that it applies to all jobs on startup. However, the exclusion configuration is not dynamic, and once a job is started with the final node set, there is no further reconfiguration permitted. So if a participant node is excluded, it will remain excluded until the job has completed. Similarly, if a participant needs to be excluded, the current job will have to be cancelled and a new job started. Any nodes can be excluded, including the node running the job engine’s coordinator process. The coordinator will still monitor the job, it just won’t spawn a manager for the job.
The list of participating nodes for a job are computed in three phases:
- Query the cluster’s GMP group.
- Call to job.get_participating_nodes to get a subset from the gmp group.
- Remove the nodes listed in core.excluded_participants from the subset.
The CLI syntax for configuring an excluded nodes list on a cluster is as follows (in this example, excluding nodes one through three):
# isi_gconfig –t job-config core.excluded_participants="{1,2,3}"The ‘excluded_participants’ are entered as a comma-separated devid value list with no spaces, specified within parentheses and double quotes. All excluded nodes must be specified in full, since there’s no aggregation. Note that, while the excluded participant configuration will be displayed via gconfig, it is not reported as part of the ‘sysctl efs.gmp.group’ output.
A job engine node exclusion configuration can be easily reset to avoid excluding any nodes by assigning the “{}” value.
# isi_gconfig –t job-config core.excluded_participants="{}"
A ‘core.excluded_participant_percent_warn’ parameter defines the maximum percentage of removed nodes.
# isi_gconfig -t job-config core.excluded_participant_percent_warn
core.excluded_participant_percent_warn (uint) = 10This parameter defaults to 10%, above which a CELOG event warning is generated.
As many nodes as desired can be removed from the job group. CELOG informational event will notify of removed nodes. If too many nodes have been removed (the gconfig parameter sets too many node thresholds), CELOG will fire a warning event. If some nodes are removed but they’re not part of the GMP group, a different warning event will trigger.
If all nodes are removed, a CLI/pAPI error will be returned, the job will fail, and a CELOG warning will fire. For example:
# isi job jobs start LinCount Job operation failed: The job had no participants left. Check core.excluded_participants setting and make sure there is at least one node to run the job: Invalid argument # isi job status 10 LinCount Failed 2021-10-24T:20:45:23 ------------------------------------------------------------------ Total: 9
Note, however, that the following core system maintenance jobs will continue to run across all nodes in a cluster even if a node exclusion has been configured:
- AutoBalance
- Collect
- FlexProtect
- MediaScan
- MultiScan
Author: Nick Trimbee
Related Blog Posts

OneFS and HTTP Security
Mon, 22 Apr 2024 20:35:30 -0000
|Read Time: 0 minutes
To enable granular HTTP security configuration, OneFS provides an option to disable nonessential HTTP components selectively. This can help reduce the overall attack surface of your infrastructure. Disabling a specific component’s service still allows other essential services on the cluster to continue to run unimpeded. In OneFS 9.4 and later, you can disable the following nonessential HTTP services:
Service | Description |
PowerScaleUI | The OneFS WebUI configuration interface. |
Platform-API-External | External access to the OneFS platform API endpoints. |
Rest Access to Namespace (RAN) | REST-ful access by HTTP to a cluster’s /ifs namespace. |
RemoteService | Remote Support and In-Product Activation. |
SWIFT (deprecated) | Deprecated object access to the cluster using the SWIFT protocol. This has been replaced by the S3 protocol in OneFS. |
You can enable or disable each of these services independently, using the CLI or platform API, if you have a user account with the ISI_PRIV_HTTP RBAC privilege.
You can use the isi http services CLI command set to view and modify the nonessential HTTP services:
# isi http services list ID Enabled ------------------------------ Platform-API-External Yes PowerScaleUI Yes RAN Yes RemoteService Yes SWIFT No ------------------------------ Total: 5
For example, you can easily disable remote HTTP access to the OneFS /ifs namespace as follows:
# isi http services modify RAN --enabled=0
You are about to modify the service RAN. Are you sure? (yes/[no]): yes
Similarly, you can also use the WebUI to view and edit a subset of the HTTP configuration settings, by navigating to Protocols > HTTP settings:
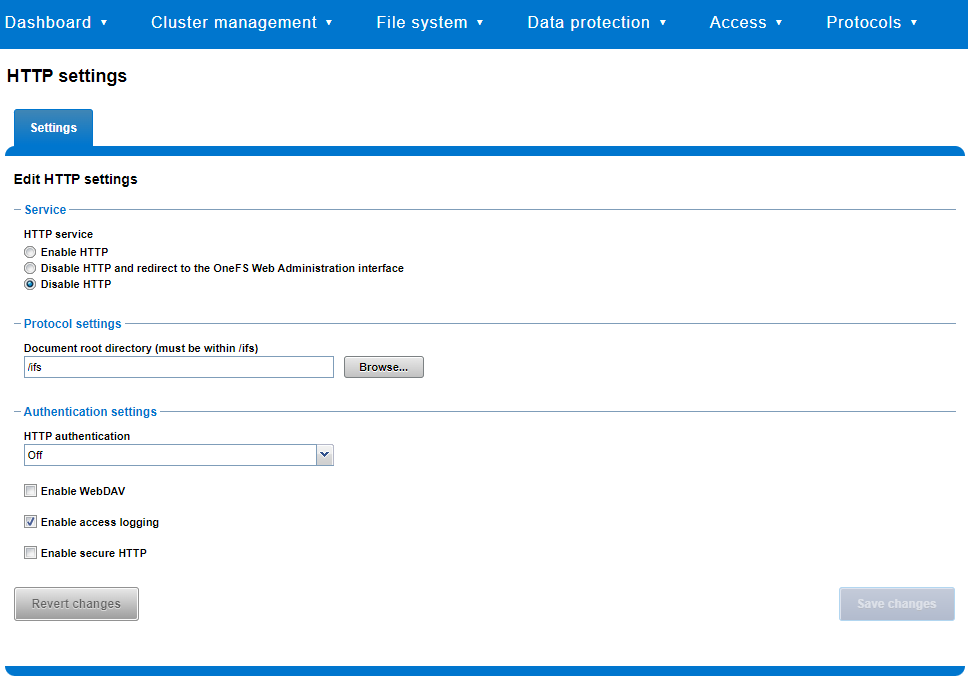
That said, the implications and impact of disabling each of the services is as follows:
Service | Disabling impacts |
WebUI | The WebUI is completely disabled, and access attempts (default TCP port 8080) are denied with the warning Service Unavailable. Please contact Administrator. If the WebUI is re-enabled, the external platform API service (Platform-API-External) is also started if it is not running. Note that disabling the WebUI does not affect the PlatformAPI service. |
Platform API | External API requests to the cluster are denied, and the WebUI is disabled, because it uses the Platform-API-External service. Note that the Platform-API-Internal service is not impacted if/when the Platform-API-External is disabled, and internal pAPI services continue to function as expected. If the Platform-API-External service is re-enabled, the WebUI will remain inactive until the PowerScaleUI service is also enabled. |
RAN | If RAN is disabled, the WebUI components for File System Explorer and File Browser are also automatically disabled. From the WebUI, attempts to access the OneFS file system explorer (File System > File System Explorer) fail with the warning message Browse is disabled as RAN service is not running. Contact your administrator to enable the service. This same warning also appears when attempting to access any other WebUI components that require directory selection. |
RemoteService | If RemoteService is disabled, the WebUI components for Remote Support and In-Product Activation are disabled. In the WebUI, going to Cluster Management > General Settings and selecting the Remote Support tab displays the message The service required for the feature is disabled. Contact your administrator to enable the service. In the WebUI, going to Cluster Management > Licensing and scrolling to the License Activation section displays the message The service required for the feature is disabled. Contact your administrator to enable the service. |
SWIFT | Deprecated object protocol and disabled by default. |
You can use the CLI command isi http settings view to display the OneFS HTTP configuration:
# isi http settings view Access Control: No Basic Authentication: No WebHDFS Ran HTTPS Port: 8443 Dav: No Enable Access Log: Yes HTTPS: No Integrated Authentication: No Server Root: /ifs Service: disabled Service Timeout: 8m20s Inactive Timeout: 15m Session Max Age: 4H Httpd Controlpath Redirect: No
Similarly, you can manage and change the HTTP configuration using the isi http settings modify CLI command.
For example, to reduce the maximum session age from four to two hours:
# isi http settings view | grep -i age Session Max Age: 4H # isi http settings modify --session-max-age=2H # isi http settings view | grep -i age Session Max Age: 2H
The full set of configuration options for isi http settings includes:
Option | Description |
--access-control <boolean> | Enable Access Control Authentication for the HTTP service. Access Control Authentication requires at least one type of authentication to be enabled. |
--basic-authentication <boolean> | Enable Basic Authentication for the HTTP service. |
--webhdfs-ran-https-port <integer> | Configure Data Services Port for the HTTP service. |
--revert-webhdfs-ran-https-port | Set value to system default for --webhdfs-ran-https-port. |
--dav <boolean> | Comply with Class 1 and 2 of the DAV specification (RFC 2518) for the HTTP service. All DAV clients must go through a single node. DAV compliance is NOT met if you go through SmartConnect, or using 2 or more node IPs. |
--enable-access-log <boolean> | Enable writing to a log when the HTTP server is accessed for the HTTP service. |
--https <boolean> | Enable the HTTPS transport protocol for the HTTP service. |
--https <boolean> | Enable the HTTPS transport protocol for the HTTP service. |
--integrated-authentication <boolean> | Enable Integrated Authentication for the HTTP service. |
--server-root <path> | Document root directory for the HTTP service. Must be within /ifs. |
--service (enabled | disabled | redirect | disabled_basicfile) | Enable/disable the HTTP Service or redirect to WebUI or disabled BasicFileAccess. |
--service-timeout <duration> | The amount of time (in seconds) that the server will wait for certain events before failing a request. A value of 0 indicates that the service timeout value is the Apache default. |
--revert-service-timeout | Set value to system default for --service-timeout. |
--inactive-timeout <duration> | Get the HTTP RequestReadTimeout directive from both the WebUI and the HTTP service. |
--revert-inactive-timeout | Set value to system default for --inactive-timeout. |
--session-max-age <duration> | Get the HTTP SessionMaxAge directive from both WebUI and HTTP service. |
--revert-session-max-age | Set value to system default for --session-max-age. |
--httpd-controlpath-redirect <boolean> | Enable or disable WebUI redirection to the HTTP service. |
Note that while the OneFS S3 service uses HTTP, it is considered a tier-1 protocol, and as such is managed using its own isi s3 CLI command set and corresponding WebUI area. For example, the following CLI command forces the cluster to only accept encrypted HTTPS/SSL traffic on TCP port 9999 (rather than the default TCP port 9021):
# isi s3 settings global modify --https-only 1 –https-port 9921 # isi s3 settings global view HTTP Port: 9020 HTTPS Port: 9999 HTTPS only: Yes S3 Service Enabled: Yes
Additionally, you can entirely disable the S3 service with the following CLI command:
# isi services s3 disable The service 's3' has been disabled.
Or from the WebUI, under Protocols > S3 > Global settings:
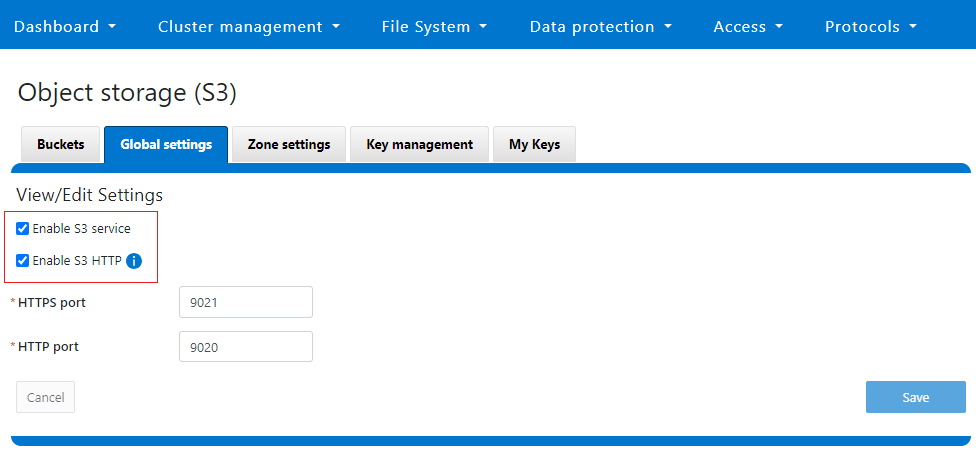
Author: Nick Trimbee

OneFS and PowerScale F-series Management Ports
Mon, 22 Apr 2024 20:12:20 -0000
|Read Time: 0 minutes
Another security enhancement that OneFS 9.5 and later releases brings to the table is the ability to configure 1GbE NIC ports dedicated to cluster management on the PowerScale F900, F710, F600, F210, and F200 all-flash storage nodes and P100 and B100 accelerators. Since these platforms were released, customers have been requesting the ability to activate the 1GbE NIC ports so that the node management activity and front end protocol traffic can be separated on physically distinct interfaces.
For background, since their introduction, the F600 and F900 have shipped with a quad port 1GbE rNDC (rack Converged Network Daughter Card) adapter. However, these 1GbE ports were non-functional and unsupported in OneFS releases prior to 9.5. As such, the node management and front-end traffic was co-mingled on the front-end interface.
In OneFS 9.5 and later, 1GbE network ports are now supported on all of the PowerScale PowerEdge based platforms for the purposes of node management, and are physically separate from the other network interfaces. Specifically, this enhancement applies to the F900, F600, F200 all-flash nodes, and P100 and B100 accelerators.
Under the hood, OneFS has been updated to recognize the 1GbE rNDC NIC ports as usable for a management interface. Note that the focus of this enhancement is on factory enablement and support for existing F600 customers that have the unused 1GbE rNDC hardware. This functionality has also been back-ported to OneFS 9.4.0.3 and later RUPs. Since the introduction of this feature, there have been several requests raised about field upgrades, but that use case is separate and will be addressed in a later release through scripts, updates of node receipts, procedures, and so on.
Architecturally, aside from some device driver and accounting work, no substantial changes were required to the underlying OneFS or platform architecture to implement this feature. This means that in addition to activating the rNDC, OneFS now supports the relocated front-end NIC in PCI slots 2 or 3 for the F200, B100, and P100.
OneFS 9.5 and later recognizes the 1GbE rNDC as usable for the management interface in the OneFS Wizard, in the same way it always has for the H-series and A-series chassis-based nodes.
All four ports in the 1GbE NIC are active, and for the Broadcom board, the interfaces are initialized and reported as bge0, bge1, bge2, and bge3.
The pciconf CLI utility can be used to determine whether the rNDC NIC is present in a node. If it is, a variety of identification and configuration details are displayed. For example, let’s look at the following output from a Broadcom rNDC NIC in an F200 node:
# pciconf -lvV pci0:24:0:0
bge2@pci0:24:0:0: class=0x020000 card=0x1f5b1028 chip=0x165f14e4 rev=0x00 hdr=0x00 class = network subclass = ethernet VPD ident = ‘Broadcom NetXtreme Gigabit Ethernet’ VPD ro PN = ‘BCM95720’ VPD ro MN = ‘1028’ VPD ro V0 = ‘FFV7.2.14’ VPD ro V1 = ‘DSV1028VPDR.VER1.0’ VPD ro V2 = ‘NPY2’ VPD ro V3 = ‘PMT1’ VPD ro V4 = ‘NMVBroadcom Corp’ VPD ro V5 = ‘DTINIC’ VPD ro V6 = ‘DCM1001008d452101000d45’
We can use the ifconfig CLI utility to determine the specific IP/interface mapping on the Broadcom rNDC interface. For example:
# ifconfig bge0 TME-1: bge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500 TME-1: ether 00:60:16:9e:X:X TME-1: inet 10.11.12.13 netmask 0xffffff00 broadcast 10.11.12.255 zone 1 TME-1: inet 10.11.12.13 netmask 0xffffff00 broadcast 10.11.12.255 zone 0 TME-1: media: Ethernet autoselect (1000baseT <full-duplex>) TME-1: status: active
In this output, the first IP address of the management interface’s pool is bound to bge0, which is the first port on the Broadcom rNDC NIC.
We can use the isi network pools CLI command to determine the corresponding interface. Within the system zone, the management interface is allocated an address from the configured IP range within its associated interface pool. For example:
# isi network pools list ID SC Zone IP Ranges Allocation Method ---------------------------------------------------------------------------------------------- groupnet0.mgt.mgt cluster_mgt_isln.com 10.11.12.13-10.11.12.20 static # isi network pools view groupnet0.mgt.mgt | grep -i ifaces Ifaces: 1:mgmt-1, 2:mgmt-1, 3:mgmt-1, 4:mgmt-1, 5:mgmt-1
Or from the WebUI, under Network configuration > External network:
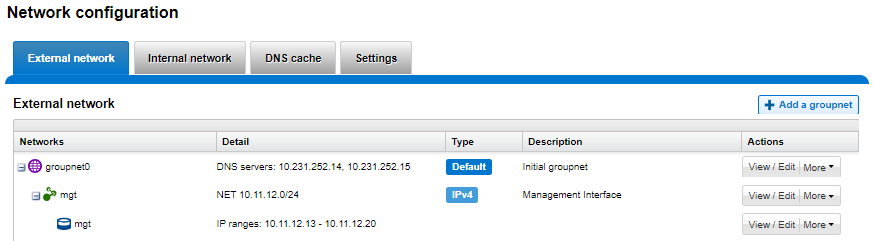
Drilling down into the mgt pool details shows the 1GbE management interfaces as the pool interface members:
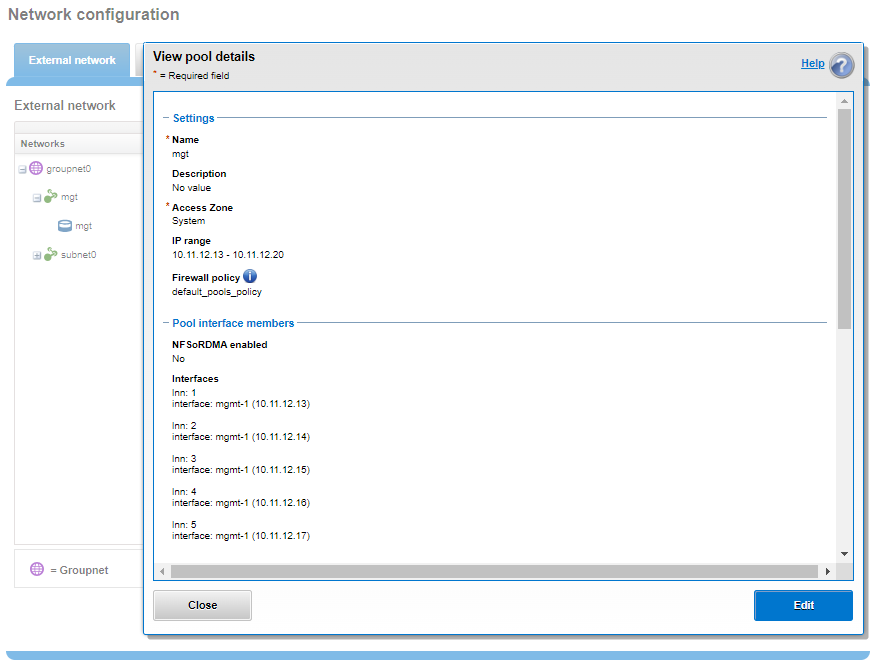
Note that the 1GbE rNDC network ports are solely intended as cluster management interfaces. As such, they are not supported for use with regular front-end data traffic.
The F900 and F600 nodes already ship with a four port 1GbE rNDC NIC installed. However, the F200, B100, and P100 platform configurations have also been updated to include a quad port 1GbE rNDC card. These new configurations have been shipping by default since January 2023. This required relocating the front end network’s 25GbE NIC (Mellanox CX4) to PCI slot 2 in the motherboard. Additionally, the OneFS updates needed for this feature have also now allowed the F200 platform to be offered with a 100GbE option too. The 100GbE option uses a Mellanox CX6 NIC in place of the CX4 in slot 2.
With this 1GbE management interface enhancement, the same quad-port rNDC card (typically the Broadcom 5720) that has been shipped in the F900 and F600 since their introduction, is now included in the F200, B100 and P100 nodes as well. All four 1GbE rNDC ports are enabled and active under OneFS 9.5 and later, too.
Node port ordering continues to follow the standard, increasing numerically from left to right. However, be aware that the port labels are not visible externally because they are obscured by the enclosure’s sheet metal.
The following back-of-chassis hardware images show the new placements of the NICs in the various F-series and accelerator platforms:
F600

F900

For both the F600 and F900, the NIC placement remains unchanged, because these nodes have always shipped with the 1GbE quad port in the rNDC slot since their launch.
F200

The F200 sees its front-end NIC moved to slot 3, freeing up the rNDC slot for the quad-port 1GbE Broadcom 5720.

Because the B100 backup accelerator has a fibre-channel card in slot 2, it sees its front-end NIC moved to slot 3, freeing up the rNDC slot for the quad-port 1GbE Broadcom 5720.

Finally, the P100 accelerator sees its front-end NIC moved to slot 3, freeing up the rNDC slot for the quad-port 1GbE Broadcom 5720.
Note that, while there is currently no field hardware upgrade process for adding rNDC cards to legacy F200 nodes or B100 and P100 accelerators, this will be addressed in a future release.
Author: Nick Trimbee