




Next-Generation Dell PowerEdge Servers: Designed with PCIe Gen 5 to Deliver Future-Ready Bandwidth
Download PDFFri, 03 Mar 2023 17:38:40 -0000
|Read Time: 0 minutes
Summary
This Direct from Development tech note describes PCIe Gen 5 for next-generation Dell PowerEdge servers. This document provides a high-level overview of PCIe Gen 5 and information about its performance improvement over Gen 4.
PCIe Gen 4 and Gen 5
PCIe (Peripheral Component Interconnect Express) is a high-speed bus standard interface for connecting various peripherals to the CPU. This standard is maintained and developed by the PCI Special Interest Group (PCI-SIG), a group of more than 900 companies. In today’s world of servers, PCIe is the primary interface for connecting peripherals. It has numerous advantages over the earlier standards, being faster, more robust, and very flexible. These advantages have cemented the importance of PCIe.
PCIe Gen 4, which was the fourth major iteration of this standard, can carry data at the speed of 16 gigatransfers per second (GT/s). GT/s is the rate of bits (0’s and 1’s) transferred per second from the host to the end device or endpoint. After considering the overhead of the encoding scheme, Gen 4’s 16 GT/s works out to an effective delivery of 2 GB/s per lane in each direction. A PCIe Gen 4 slot with x16 lanes can have a total bandwidth of 64 GB/s.
The fifth major iteration of the PCIe standard, PCIe Gen 5, doubles the data transfer rate to 32 GT/s. This works out to an effective throughput of 4 GB/s per lane in each direction and 128 GB/s for an x16 PCIe Gen5 slot.
PCIe generations feature forward and backward compatibility. That means that you can connect a PCIe 4.0 SSD or a PCIe 5.0 SSD to a PCIe 5.0 slot, although speed is limited to the lowest generation. There are no pinout changes to from PCIe 4.0 for x16, x8, x4 packages.
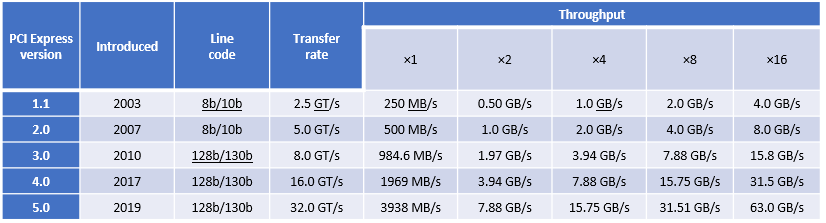
Figure 1. PCIe bandwidth over time
Advantages of increased bandwidth
With the increased bandwidth of PCIe 5.0, devices might be able to achieve the same throughput while using fewer lanes, which means freeing up more lanes. For example, a graphics card that requires x16 bandwidth to run at full speed might now run at the same speed with x8, making an additional eight lanes available. Using fewer lanes is important because CPUs only provide a limited number of lanes, which need to be distributed among devices.
PCIe bandwidth improvements bring opportunities for high-bandwidth accelerators (FPGA, for example). The number of storage-attached and server-attached SSDs using PCIe continues to grow. PCIe 5.0 provides foundational bandwidth, electricals, and CEM slots for Compute Express Link (CXL) devices such as SmartNICs and accelerators. The new standard will be much more useful for machine learning and artificial intelligence, data centers, and other high performance computing environments, thanks to the increase in speeds and bandwidth. In addition, a single 200 Gb network is expected to saturate a PCIe 4.0 link in certain conditions, creating opportunities for PCIe 5.0 connectivity adapters. This unlocks opportunities for 400 Gb networking. The Intel PCIe 5.0 test chip is heavily utilized for interoperability testing.
Next-generation PowerEdge servers and PCIe Gen 5
Next-generation Dell PowerEdge servers with 4th Gen Intel® Scalable processors are designed for PCIe Gen 5. The 4th Gen Intel® Xeon® series processors support the PCIe Gen 5 standard, allowing for the maximum utilization of this available bandwidth with the resulting advantages.
Single-socket 4th Gen Intel® Scalable processors have 80 PCIe Gen 5 lanes available for use, which allows for great flexibility in design. Eighty lanes also give plenty of bandwidth for many peripherals to take advantage of the high-core-count CPUs.
Conclusion
PowerEdge servers continue to deliver the latest technology. Support for PCIe Gen 5 provides increased bandwidth and improvements to make new applications possible.
Related Documents

Intel 4th Gen Xeon featuring QAT 2.0 Technology Delivers Massive Performance Uplift in Common Cipher Suites
Sat, 27 Apr 2024 15:07:09 -0000
|Read Time: 0 minutes
Intel QAT Hardware v2.0 acceleration running on 16G PowerEdge delivers on performance for ISPs - Lab Tested and Proven
Introduction
The Internet as we know it would simply not be possible without encryption technologies. This technology lets us perform secure communication and information exchange over public networks. If you buy a pair of shoes from an online retailer, the payment information you provide is encrypted with such a high level of security that extracting your credit card information from ciphertext would be nearly an impossible task for even a supercomputer. The shoes might not end up fitting, but if the requisite encryption and secure communication tech is properly implemented, your payment information remains a secret known only to you and the entity receiving payment.
This domain of security requires hardware that is up to the task of performing handshakes, key exchanges, and other algorithmic tasks at an expeditious speed.
As we’ll demonstrate through extensive testing and proven results in our lab, Intel’s QAT 2.0 Hardware Accelerator featured on Gen4 Xeon processors is a performant and dev friendly choice to supercharge your encryption workloads. This feature is readily available on our current products across the PowerEdge Server portfolio.
What is QAT?
QAT, or “Quick Assist Technology” is an Intel technology that accelerates two common use cases: encryption acceleration and compression/decompression acceleration. In this tech note, we look at the encryption side of the QAT Accelerator feature set and explore leveraging QAT to speed up cipher suites used in deployments of OpenSSL–a common software library used by a vast array of websites and applications to secure their communications.
But before we start, let’s briefly touch on the lineage and history of QAT. QAT was introduced back in 2007, initially available as a discrete add-in PCIe card. A little further on in its evolution, QAT found a home in Intel Chipsets. Now, with the introduction of the 4th Gen Xeon processor, the silicon required to enable QAT acceleration has been added to the SOC. The hardware being this close to the processor has increased performance and reduced the logistical complexity of having to source and manage an external device.
For a complete list of the QAT Hardware v2.0’s cryptosystem and algorithms support, see: https://github.com/intel/QAT_Engine/blob/master/docs/features.md#qat_hw-features
QAT hardware acceleration may not be the fastest method to accelerate all ciphers or algorithms. With this in mind, QAT Hardware Acceleration (also called QAT_HW) can peacefully co-exist with QAT Software Acceleration (or QAT_SW). This configuration, while somewhat complex, is well supported by clear documentation. Fundamentally, this configuration relies on a method to ensure that the maximum performance is extracted for all inputs given what resources are available on the system. Allowing for use of an algorithm bitmap to dynamically choose between and prioritize the use of QAT_HW and QAT_SW based on hardware availability and which method offers the best performance.
Next we'll look at setting up QATlib and see what the performance looks like using OpenSSL Speed and a few common cipher suites.
Lab Test Setup and Notes
For this test we use a Dell PowerEdge R760. This is Dell’s mainstream 2U dual socket 4th Gen Xeon offering and features support for nearly all of Intel’s QAT enabled CPUs. Xeon gen4 CPUs that feature on-chip QAT HW 2.0 will have 1, 2 or 4 QAT endpoints per socket. We selected the Intel(R) Xeon(R) Gold 5420+ CPU that features 1 QAT endpoint for our testing. All else being equal, more endpoints allow for more QAT Hardware acceleration work to be done and allow greater performance in QAT HW accelerated use cases per socket.
As this is not a deployment guide, we’re going to use a RHEL 9.2 install as our operating system and run bare metal for our tests. Our primary resource for setting up QAT Hardware Version 2.0 Acceleration is the excellent QAT documentation found on Intel’s github here: https://intel.github.io/quickassist/index.html
Following the guide, we can simply install from RPM sources, ensure kernel drivers are loaded and we’re about ready to go.
Performance
First up, we’ll take a look at probably the most common public key asymmetric cipher suite, RSA. On the Internet RSA finds its home as a key exchange and signature method used to secure communication and confirm identities. In these graphs we’re comparing the speed of the RSA Sign and Verify algorithm using symmetric QAT_HW vs symmetric QAT off (using OpenSSLs default engine).
The following graphic shows a representation of a TLS handshake. This provides a bit of context concerning the role of the server in key exchange and handshakes.
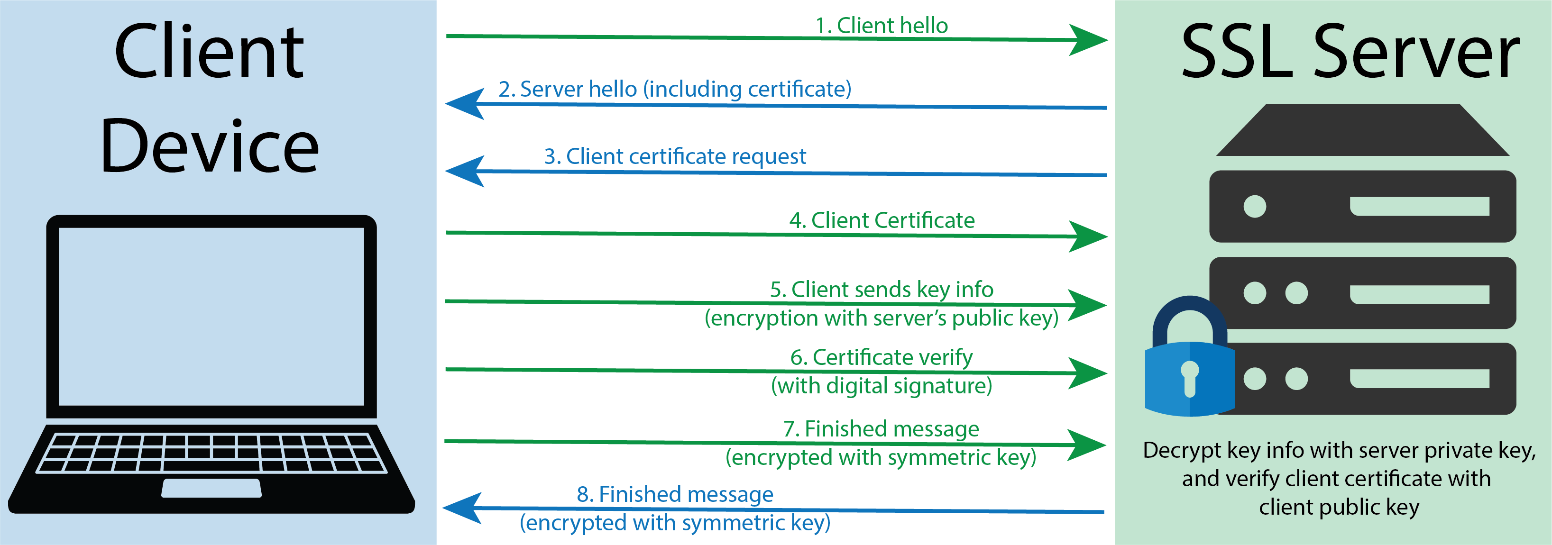 TLS handshake representation
TLS handshake representation
 OpenSSL Speen RSA2048 Verify comparison
OpenSSL Speen RSA2048 Verify comparison
 OpenSSL Speed RSA2048 Sign comparison
OpenSSL Speed RSA2048 Sign comparison
 Greater than 240% performance increase in OpenSSL RSA Verify using QAT Hardware Acceleration Engine vs Default Open SSL Engine.(1)
Greater than 240% performance increase in OpenSSL RSA Verify using QAT Hardware Acceleration Engine vs Default Open SSL Engine.(1)
Testing in our labs shows that enabling QAT offers 240% greater algorithmic operations. The result for this performance improvement could be the implementation of greater security capacity per node without the risk of negative impact on QoS.
Next we’ll look at the industry standard elliptical curve digital signature algorithm (ECDSA), specifically P-384. QAT HW supports both P-256 and P-384, with both offering exceptional performance vs the default OpenSSL engine. ECDSA is a commonly used as a key agreement protocol by many Internet messaging apps.
ECDSA example
 OpenSSL Speed ECDSA P384 Verify comparison
OpenSSL Speed ECDSA P384 Verify comparison OpenSSL Speed ECDSA P384 Sign comparison
OpenSSL Speed ECDSA P384 Sign comparison Over 30x improvement in ECDSA P384 Sign-in OpenSSL using QAT Hardware Acceleration Engine vs Default OpenSSL Engine(2)
Over 30x improvement in ECDSA P384 Sign-in OpenSSL using QAT Hardware Acceleration Engine vs Default OpenSSL Engine(2)
Both of these algorithms provide the level of protection that today’s server security specialists require. However, both are quite different in many aspects.
This vast performance improvement in secure key exchange offers more secure and uncompromised communication without degrading performance.
Conclusion
Intel’s QAT 2.0 Hardware acceleration offers substantial performance improvements for algorithms found in commonly used cipher suites. Also, QAT’s ample documentation and long history of use coupled with these new findings on performance should remove any reservations that a customer might have in deploying these security accelerators. Security at the server silicon level is critical to a modern and uncompromised data center. There is definite value in deploying QAT and a clear path towards realizing accelerated performance in their data center environments.
Legal disclosures
- Based on August 2023 Dell labs testing subjecting the PowerEdge R760 to OpenSSL Speed test running synchronously with default engine vs asynchronous with QAT Hardware Engine. Actual results will vary.
- Based on August 2023 Dell labs testing subjecting the PowerEdge R760 to OpenSSL Speed test running synchronously with default engine vs asynchronous with QAT Hardware Engine. Actual results will vary.

Unlock the Power of PowerEdge Servers for AI Workloads: Experience Up to 177% Performance Boost!
Fri, 11 Aug 2023 16:23:55 -0000
|Read Time: 0 minutes
Executive summary
As the digital revolution accelerates, the vision of an AI-powered future becomes increasingly tangible. Envision a world where AI comprehends and caters to our needs before we express them, where data centers pulsate at the heart of innovation, and where every industry is being reshaped by AI's transformative touch. Yet, this burgeoning AI landscape brings an insatiable demand for computational resources. TIRIAS Research estimates that 95% or more of all current AI data processed is through inference processing, which means that understanding and optimizing inference workloads has become paramount. As the adoption of AI grows exponentially, its immense potential lies in the realm of inference processing, where customers reap the benefits of advanced data analysis to unlock valuable insights. Harnessing the power of AI inference, which is faster and less computationally intensive than training, opens the door to diverse applications—from image generation to video processing and beyond.
Unveiling the pivotal role of Intel® Xeon® CPUs, which account for a staggering 70% of the installed inferencing capacity, this paper ventures into a comprehensive exploration, offering simple guidance to fine-tune BIOS on your PowerEdge servers for achieving optimal performance for CPU based AI workloads for their workload. We discuss available server BIOS configurations, AI workloads, and value propositions, explaining which server settings are best suited for specific AI workloads. Drawing upon the results of running 12 diverse workloads across two industry-standard benchmarks and one custom benchmark, our goal is simple: To equip you with the knowledge needed to turbocharge your servers and conquer the AI revolution.
Through extensive testing on Dell PowerEdge servers using industry-standard AI benchmarks, results showed:
 Up to 140% increase in TensorFlow inferencing benchmark performance
Up to 140% increase in TensorFlow inferencing benchmark performance
 Up to 46% increase in OpenVINO inferencing benchmark performance
Up to 46% increase in OpenVINO inferencing benchmark performance
 Up to 177% increase in raw performance for high-CPU-utilization AI workloads
Up to 177% increase in raw performance for high-CPU-utilization AI workloads
 Up to 9% decrease in latency and up to 10% increase in efficiency with no significant increase in power consumption
Up to 9% decrease in latency and up to 10% increase in efficiency with no significant increase in power consumption
The AI performance benchmarks focus on the activity that forms the main stage of the AI life cycle: inference. The benchmarks used here measure the time spent on inference (excluding any preprocessing or post-processing) and then report on the inferences per second (or frames per second or millisecond).
Performance analysis and process
We conducted iterative testing and data analysis on the PowerEdge R760 with 4th Gen Intel Xeon processors to identify optimal BIOS setting recommendations. We studied the impacts of various BIOS settings, power management settings, and different workload profile settings on throughput and latency performance for popular inference AI workloads such as Intel’s OpenVINO, TensorFlow, and customer-specific computer-vision-based workloads.
Dell PowerEdge servers with 4th Gen Intel Xeon processors and Intel delivered!
So what are these AI performance benchmarks?
We used a centralized testing ecosystem where the testing-related tasks, tools, resources, and data were integrated into a unified location, our Dell Labs, to streamline and optimize the testing process. We used various AI computer vision applications useful for person detection, vehicle detection, age and gender recognition, crowd counting, parking spaces detection, suspicious object recognition, and traffic safety analysis, and the following performance benchmarks:
- OpenVINO: A cross-platform deep learning and AI inferencing toolkit, developed by Intel, which has moderate CPU utilization.
- TensorFlow: An open-source deep learning and AI inferencing framework used to benchmark performance and characterized as a high CPU utilization workload.
- Computer-vision-based workload: A customer-specific workload. Scalers AI is a CPU-based smart city solution that uses AI and computer vision to monitor traffic safety in real time and takes advantage of the Intel AMX instructions. The solution identifies potential safety hazards, such as illegal lane changes on freeway on-ramps, reckless driving, and vehicle collisions, by analyzing video footage from cameras positioned at key locations. It is characterized as a high CPU utilization workload.
PowerEdge server BIOS settings
To improve out-of-the-box performance, we used the following server settings to achieve the optimal BIOS configurations for running AI inference workloads:
- Logical Processor: This option controls whether Hyper-Threading (HT) Technology is enabled or disabled for the server processors (see Figure 1 and Figure 2). The default setting is Enabled to potentially increase CPU utilization and overall system performance. However, disabling it may be beneficial for tasks that do not benefit from parallel execution. Disabling HT allows each core to fully dedicate its resources to a single task, often leading to improved performance and reduced resource contention in these cases.
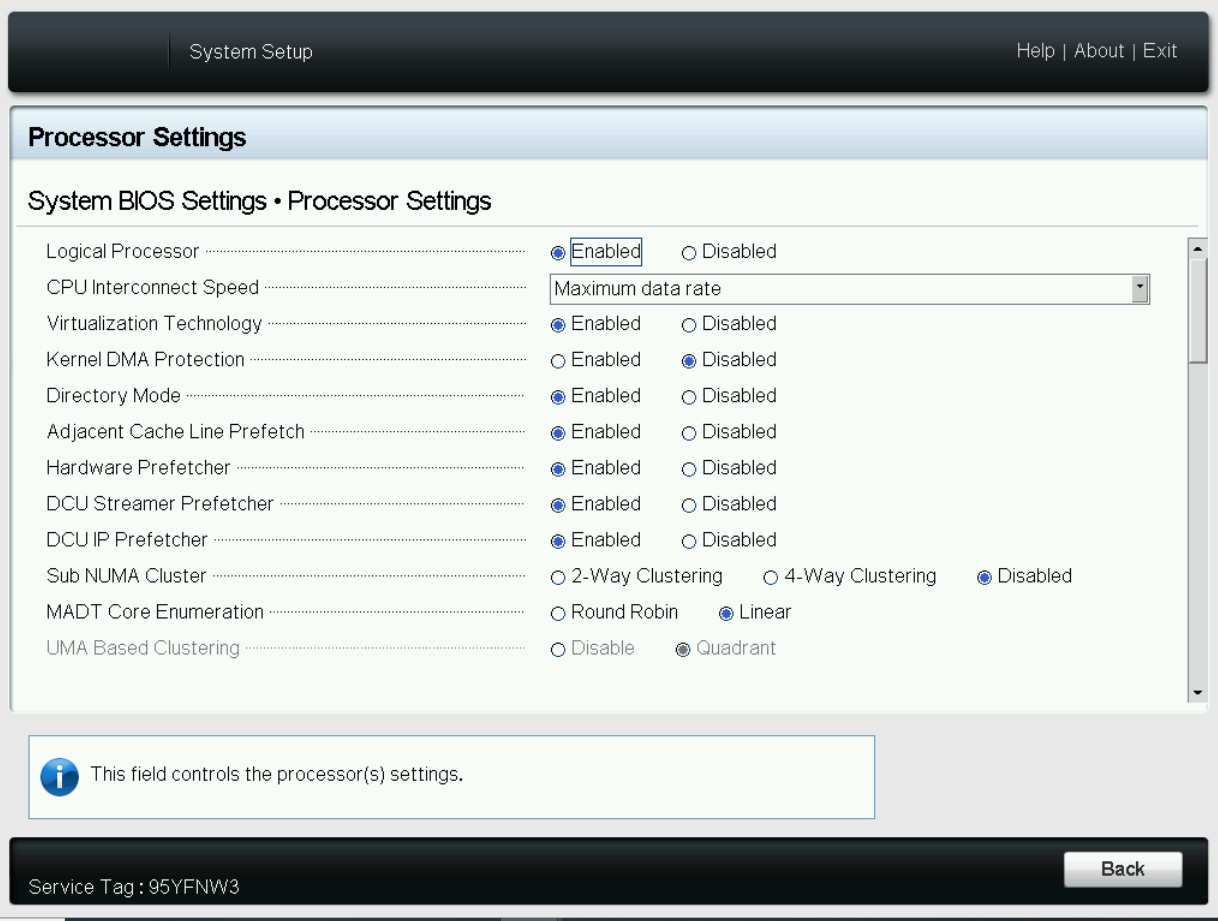
Figure 1. BIOS settings for Logical Processor on Dell server
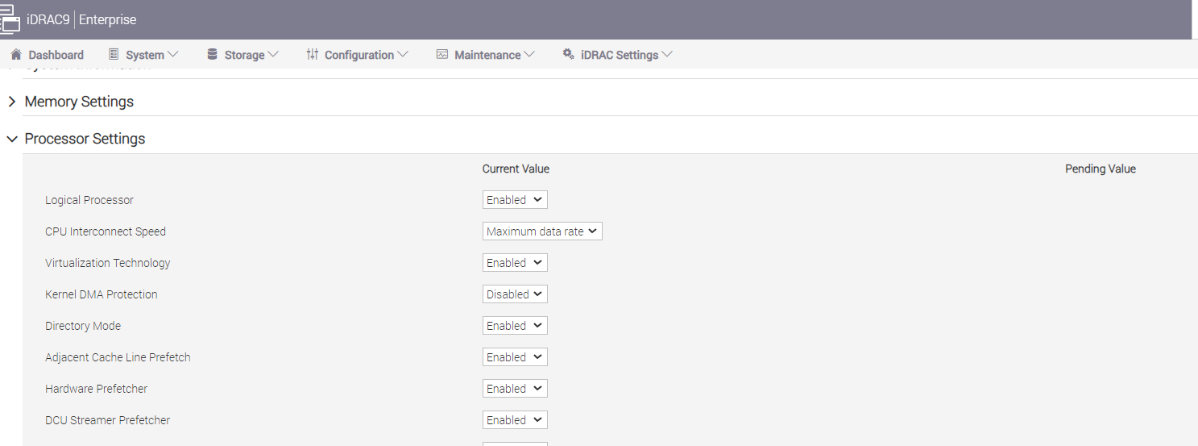
Figure 2. BIOS settings for Logical Processor on Dell iDRAC
- System Profile: This setting specifies options to change the processor power management settings, memory, and frequency. These five profiles (see Figure 1) can have a significant impact on both power efficiency and performance. The System Profile is set to Performance Per Watt (DAPC) as the default profile, and changes can be made through the BIOS setting on the server or by using iDRAC (See Figure 3 and Figure 4). We focused on the default and Performance options for System Profile because our goal was to optimize performance.
Additionally, we could see improvements in performance (throughput in FPS) and latency (in ms) for no significant increase in power.
- Performance-per-watt (DAPC) is the default profile and represents an excellent mix of performance balanced with power consumption reduction. Dell Active Power Control (DAPC) relies on a BIOS-centric power control mechanism that offers excellent power efficiency advantages with minimal performance impact in most environments and is the CPU Power Management choice for this overall System Profile.
- Performance profile provides potentially increased performance by maximizing processor frequency and disabling certain power-saving features such as C-states. Although not optimal for all environments, this profile is an excellent starting point for performance optimization baseline comparisons.
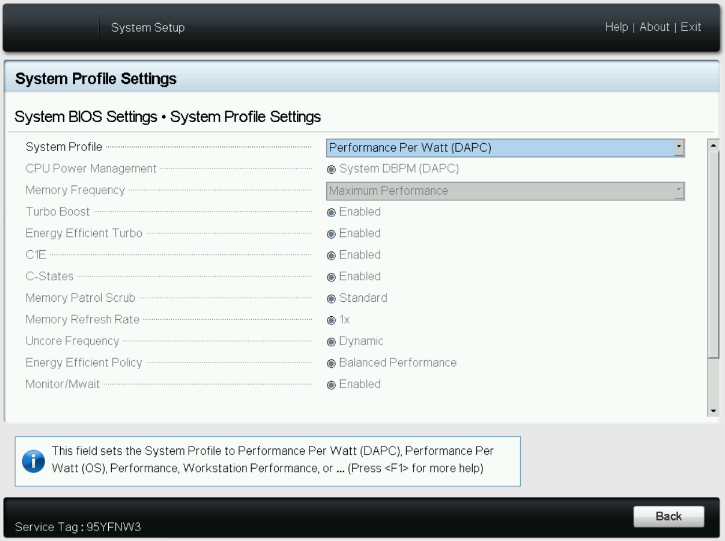

Figure 3. System BIOS settings—System Profiles Settings server screen
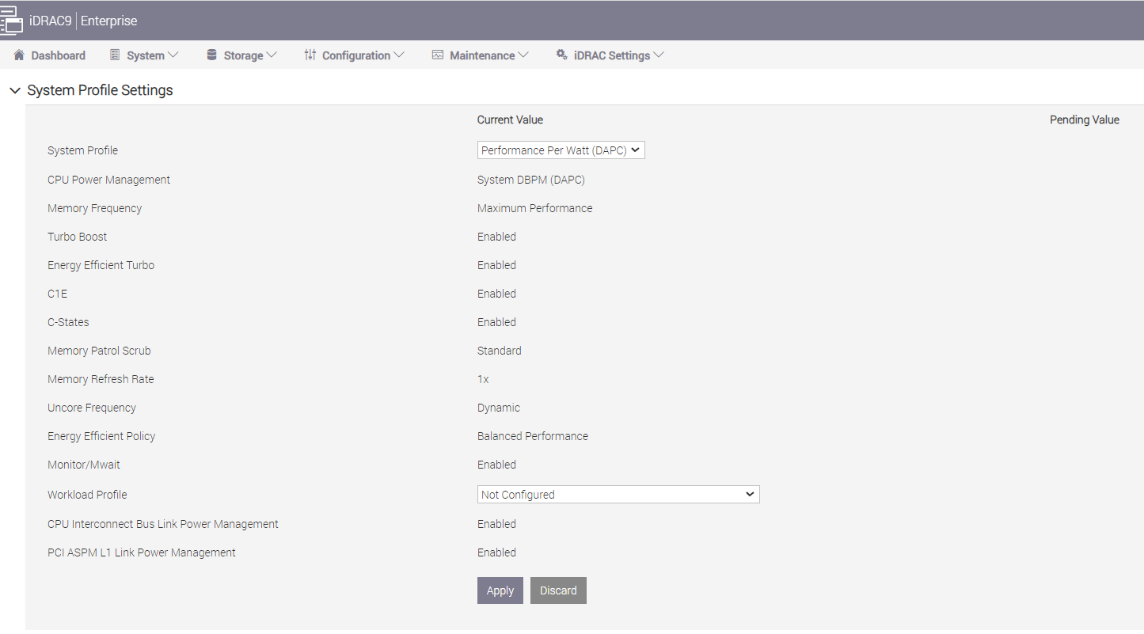
Figure 4. BIOS settings for System Profile and Workload Profile on Dell iDRAC
- Workload Profile: This setting allows the user to specify the targeted workload of a server to optimize performance based on the workload type. It is set to Not Configured as the default profile, and changes can be made through the BIOS setting on the server or by using iDRAC (see Figure 4 and Figure 5).
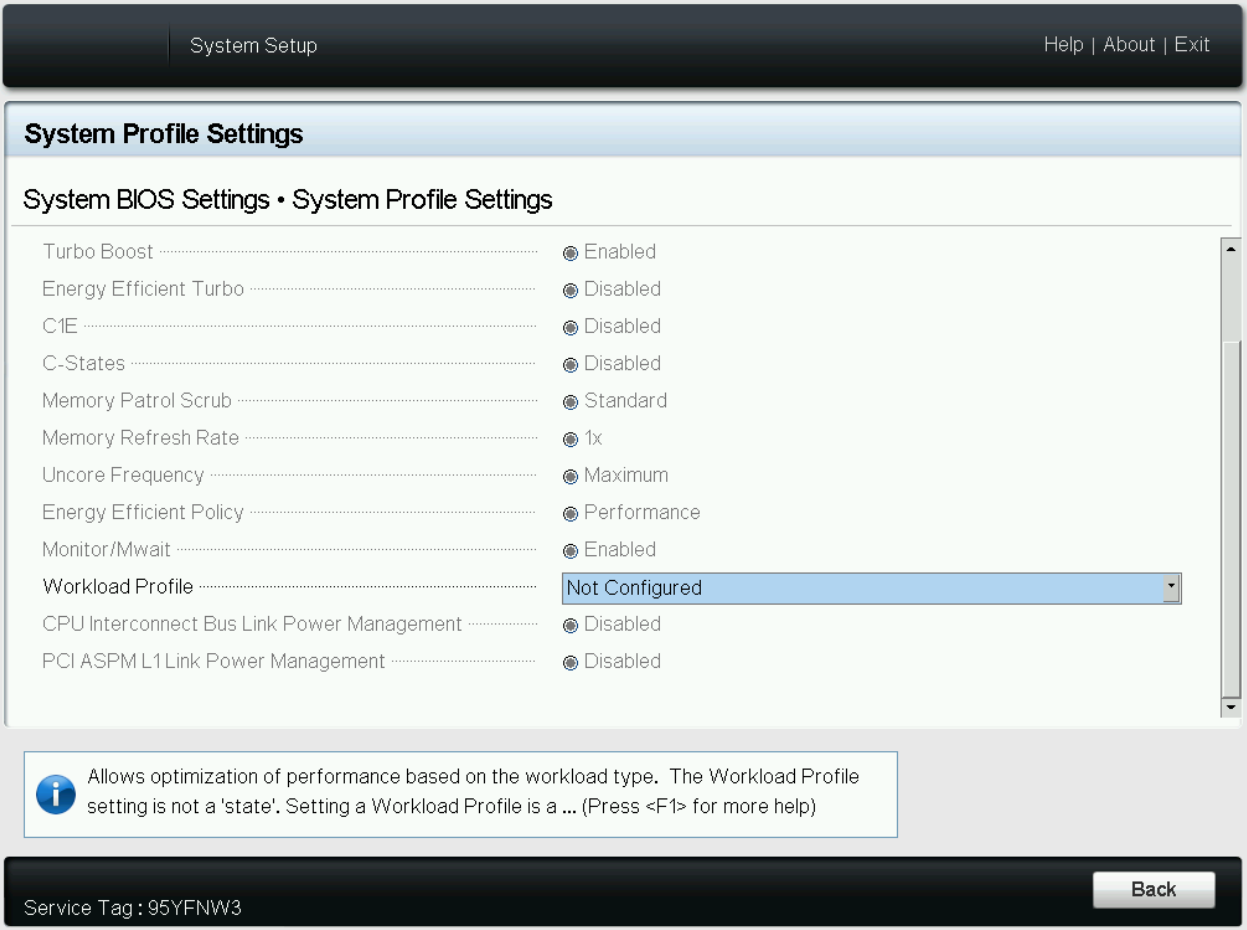
 Figure 5. BIOS settings for Workload Profile on Dell iDRAC
Figure 5. BIOS settings for Workload Profile on Dell iDRAC
Now the question is, does the type of workload influence CPU optimization strategies?
When a CPU is used dedicatedly for AI workloads, the computational demands can be quite distinct compared to more general tasks. AI workloads often involve extensive mathematical calculations and data processing, typically in the form of machine learning algorithms or neural networks. These tasks can be highly parallelizable, leveraging multiple cores or even GPUs to accelerate computations. For instance, AI inference tasks involve applying trained models to new data, requiring rapid computations, often in real time. In such cases, specialized BIOS settings, such as disabling hyperthreading for inference tasks or using dedicated AI optimization profiles, can significantly boost performance.
On the other hand, a more typical use case involves a CPU running a mix of AI and other workloads, depending on demand. In such scenarios, the CPU might be tasked with running web servers, database queries, or file system operations alongside AI tasks. For example, a server environment might need to balance AI inference tasks (for real-time data analysis or recommendation systems) with more traditional web hosting or database management tasks. In this case, the optimal configuration might be different, because these other tasks may benefit from features such as hyperthreading to effectively handle multiple concurrent requests. As such, the server's BIOS settings and workload profiles might need to balance AI-optimized settings with configurations designed to enhance general multitasking or specific non-AI tasks.
PowerEdge server BIOS tuning
In the pursuit of identifying optimal BIOS settings for enhancing AI inference performance through a deep dive into BIOS settings and workload profiles, we uncover key strategies for enhancing efficiency across varied scenarios.
Disabling hyperthreading
We determined that disabling the logical processor (hyperthreading) on the BIOS is another simple yet effective means of increasing performance up to 2.8 times for high CPU utilization workloads such as TensorFlow and computer-vision-based workload (Scalers AI), which run AI inferencing object detection use cases.
But why does disabling hyperthreading have such extensive impact on performance?
Disabling hyperthreading proves to be a valuable technique for optimizing AI inference workloads for several reasons. Hyperthreading enables each physical CPU core to run two threads simultaneously, which benefits overall system multitasking. However, AI inference tasks often excel in parallelization, rendering hyperthreading less impactful in this context. With hyperthreading disabled, each core can fully dedicate its resources to a single AI inference task, leading to improved performance and reduced contention for shared resources.
The nature of AI inference workloads involves intensive mathematical computations and frequent memory access. Enabling hyperthreading might result in the two threads on a single core competing for cache and memory resources, introducing potential delays and cache thrashing. In contrast, disabling hyperthreading allows each core to operate independently, enabling AI inference workloads to make more efficient use of the entire cache and memory bandwidth. This enhancement leads to increased overall throughput and reduced latency, significantly boosting the efficiency of AI inference processing.
Moreover, disabling hyperthreading offers advantages in terms of avoiding thread contention and context switching issues. In real-time or near-real-time AI inference scenarios, hyperthreading can introduce additional context switching overhead, causing interruptions and compromising predictability in task execution. When you opt for one thread per core with hyperthreading disabled, AI inference workloads experience minimal context switching and ensure continuous dedicated runtime. As a result, this approach achieves improved performance and delivers more consistent processing times, thereby streamlining the overall AI inference process.
The following charts represent what we learned.
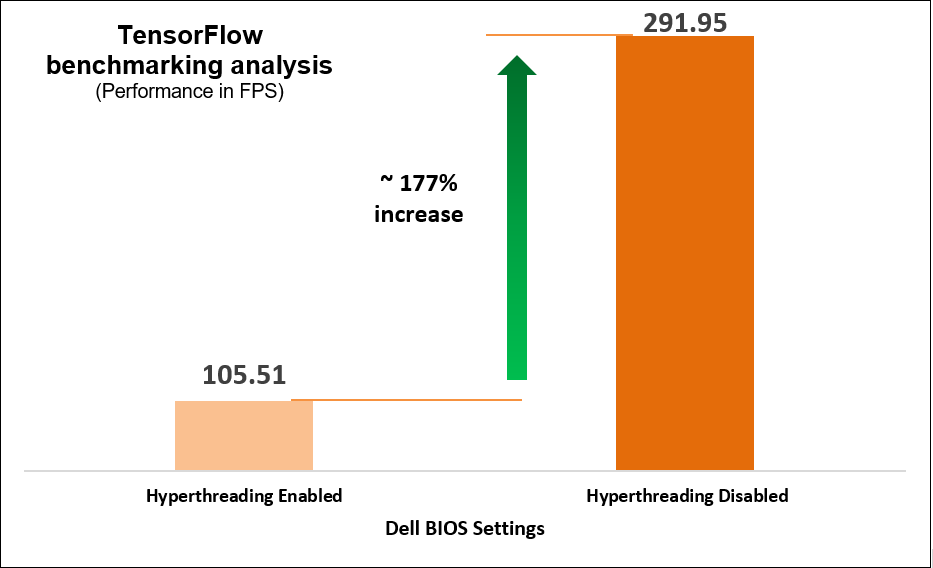
Figure 6. TensorFlow benchmarking results
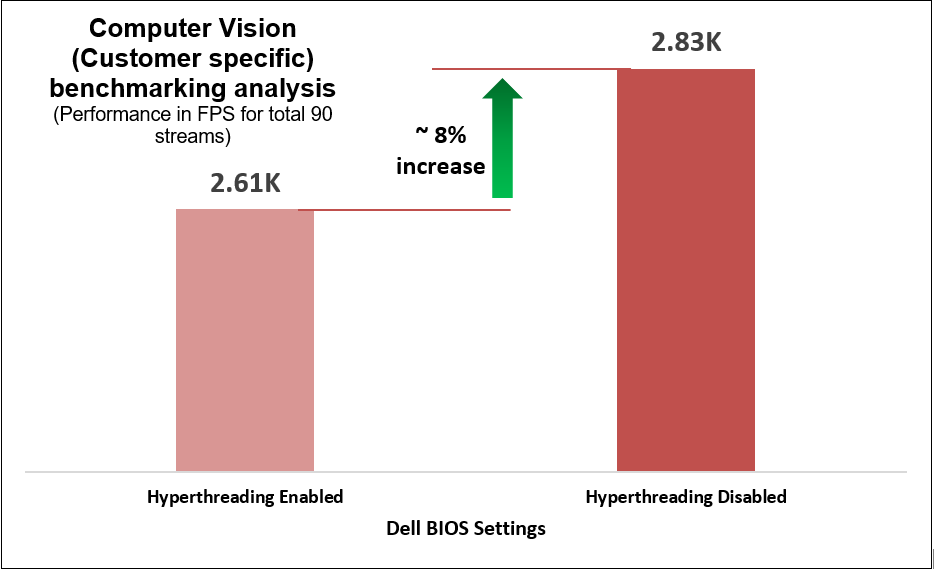
Figure 7. Customer-specific computer-vision-based workload benchmarking results
Identifying optimal System Profile
We began with selecting a baseline System Profile by analyzing the changes in performance and latency for the average power consumed when changing the System Profile from the default Performance per Watt (DAPC) to the Performance setting. The following graphs show the improvements in out-of-the-box performance after we tuned the System Profile.
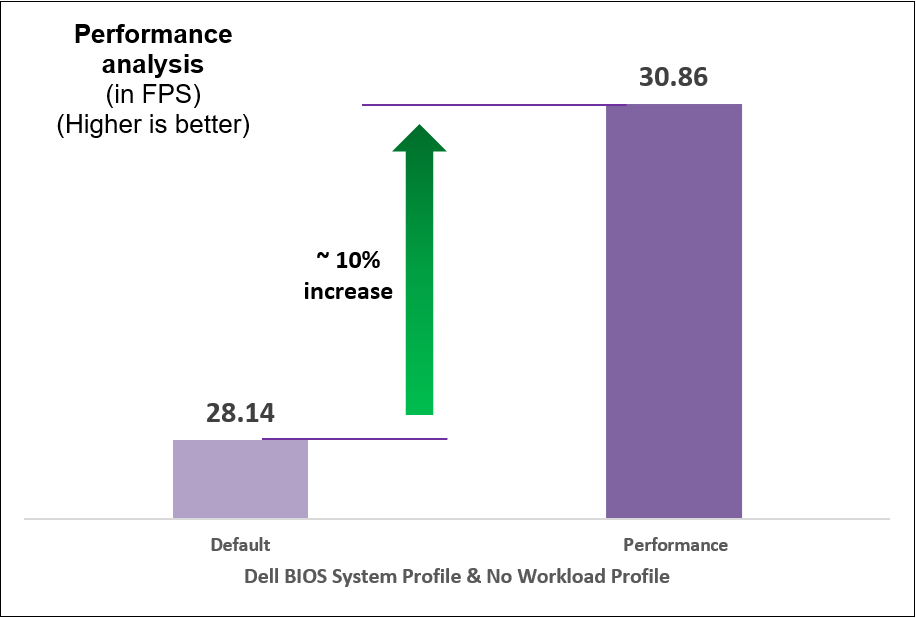
Figure 8. Comparison of default and Performance settings: Performance analysis
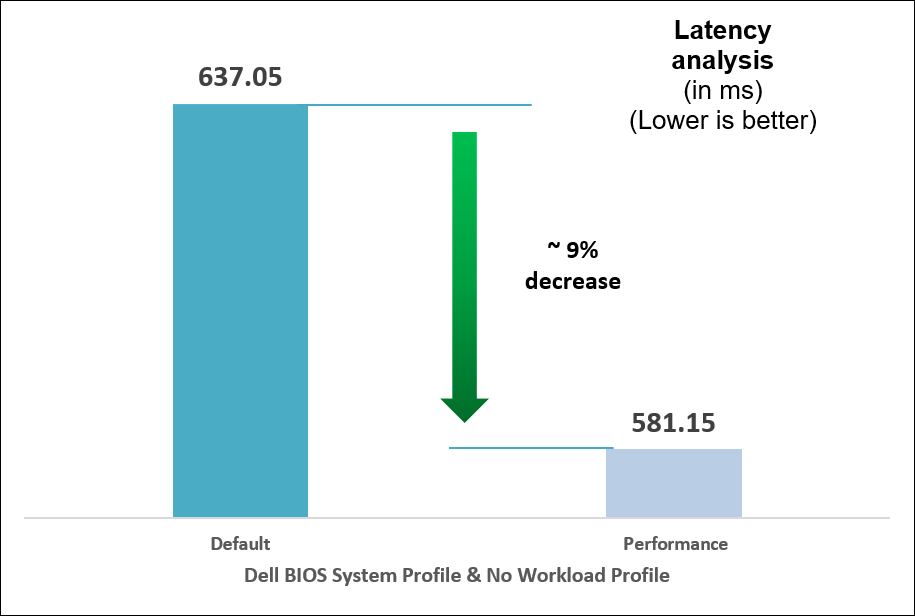
Figure 9. Comparison of default and Performance settings: Latency analysis
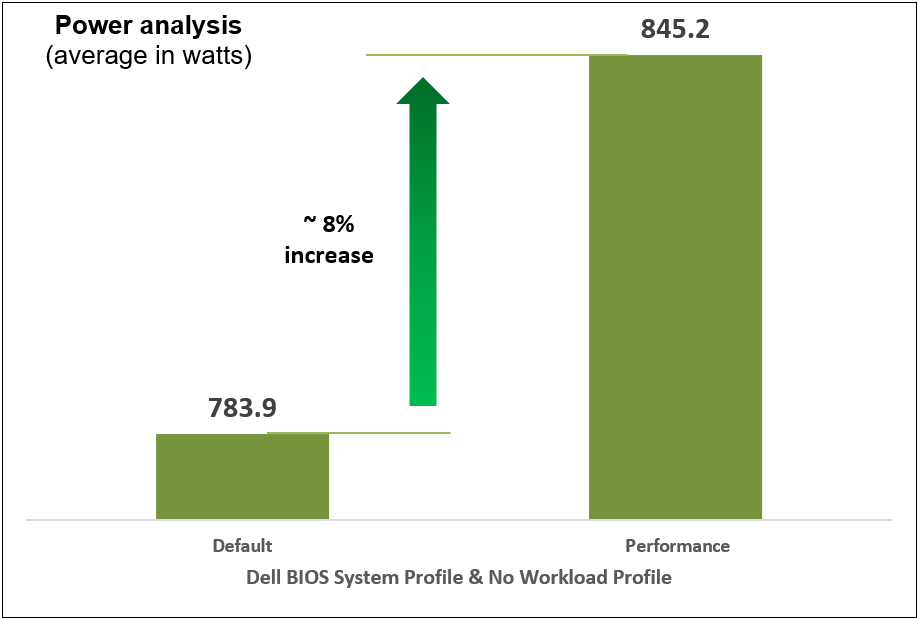
Figure 10. Comparison of default and Performance settings: Power analysis
Identifying optimal workload profile
We performed iterative testing on all current workload profile options on the PowerEdge R760 server for all three performance benchmarks. We found that the optimal, most efficient workload profile to run an AI inference workload is NFVI FP Energy-Balance Turbo Profile, based on improvements in metrics such as performance (throughput in FPS).
Why does this profile perform the best of the existing workload profiles?
The NFVI FP Energy-Balance Turbo Profile (Network Functions Virtualization Infrastructure with Float-Point) is a BIOS setting tailored for NFVI workloads that involve floating-point operations. Building upon the NFVI FP Optimized Turbo Profile, this profile optimizes the system's performance for NFVI tasks that require low-precision math operations, such as AI inference workloads. AI inference tasks often involve performing numerous calculations on large datasets, and some AI models can use lower-precision datatypes to achieve faster processing without sacrificing accuracy.
This profile leverages hardware capabilities to accelerate these low-precision math operations, resulting in improved speed and efficiency for AI inference workloads. With this profile setting, the NFVI platform can take full advantage of specialized instructions and hardware units that are optimized for handling low-precision datatypes, thereby boosting the performance of AI inference tasks. Additionally, the profile's emphasis on energy efficiency is also beneficial for AI inference workloads. Even though AI inference tasks can be computationally intensive, the use of lower-precision math operations consumes less power compared to higher-precision operations. The NFVI FP Energy-Balance Turbo Profile strikes a balance between maximizing performance and optimizing power consumption, making it particularly suitable for achieving energy-efficient NFVI deployments in data centers and cloud environments.
The following table shows the BIOS settings that we tested.
Table 1. BIOS settings for AI benchmarks
Setting | Default | Optimized |
System Profile | Performance Per Watt (DAPC) | Performance |
Workload Profile | No Configured | NFVI FP Energy-Balance Turbo Profile |
The following charts show the results of multiple iterative and exhaustive tests that we ran after tuning the BIOS settings.
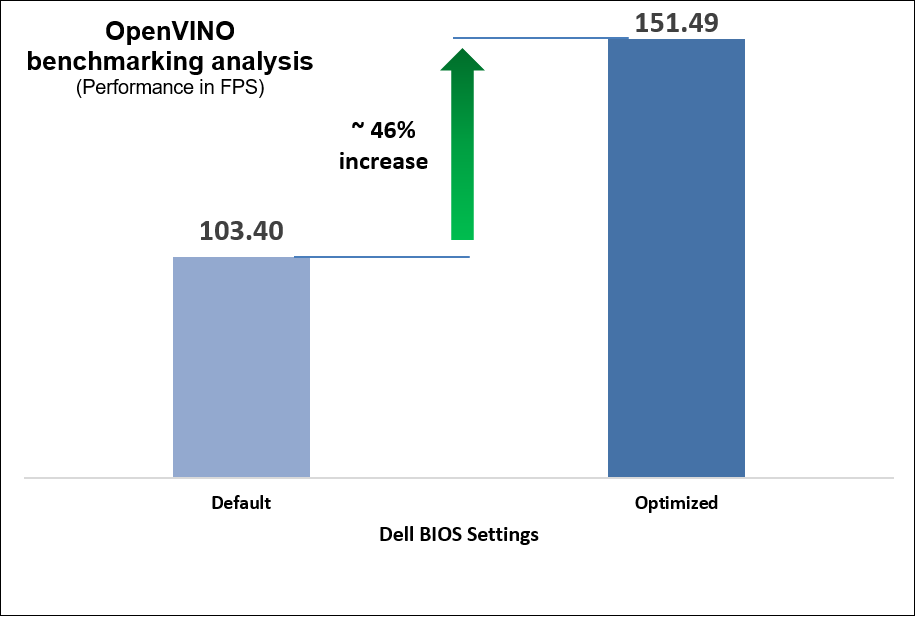
Figure 11. OpenVINO benchmark results
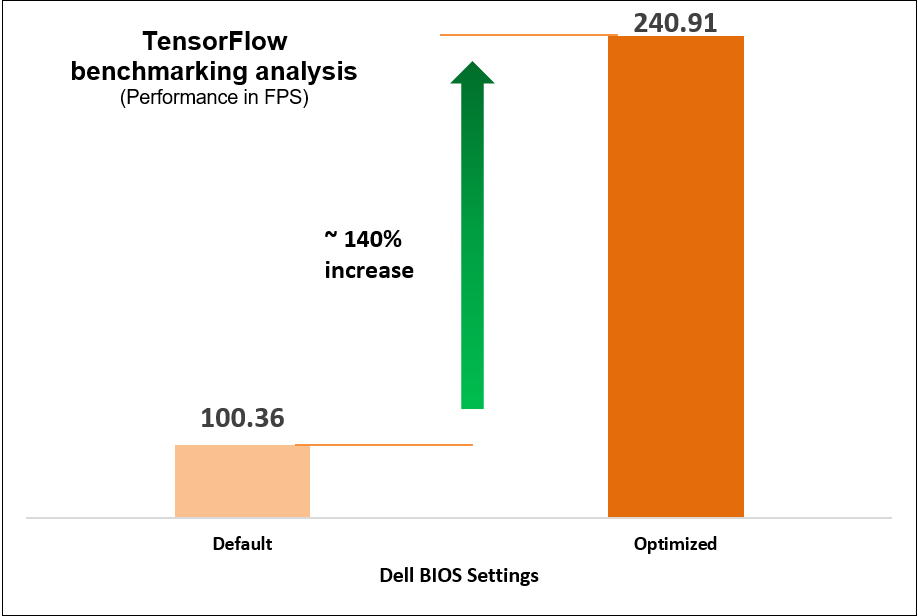
Figure 12. TensorFlow benchmark results
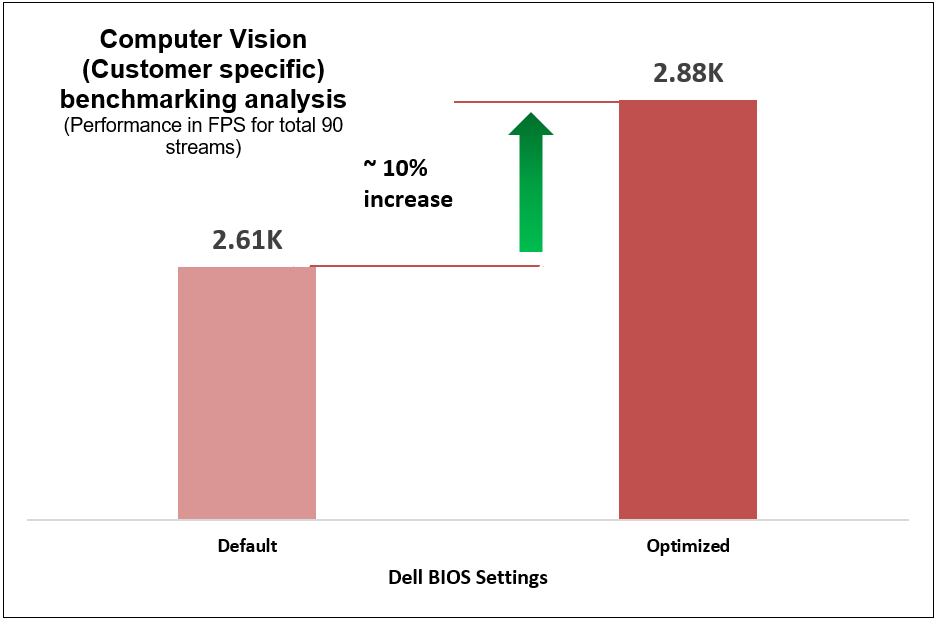
Figure 13. Computer-vision-based (customer-specific) workload benchmark results
These performance improvements reflect a significant impact on AI workload performance resulting from two simple configuration changes on the System Profile and Workload Profile BIOS settings, as compared to out-of-the-box performance.
Performance, latency, and power
We compared power consumption data with performance and latency data when changing the System Profile in the BIOS from the default Performance Per Watt (DAPC) setting to the Performance setting and using a moderate CPU utilization AI inference. Our results reflect that for an increase of up to 8% on average power consumed, the system displayed a 10% increase in performance and 9% decrease in latency with one simple BIOS setting change.
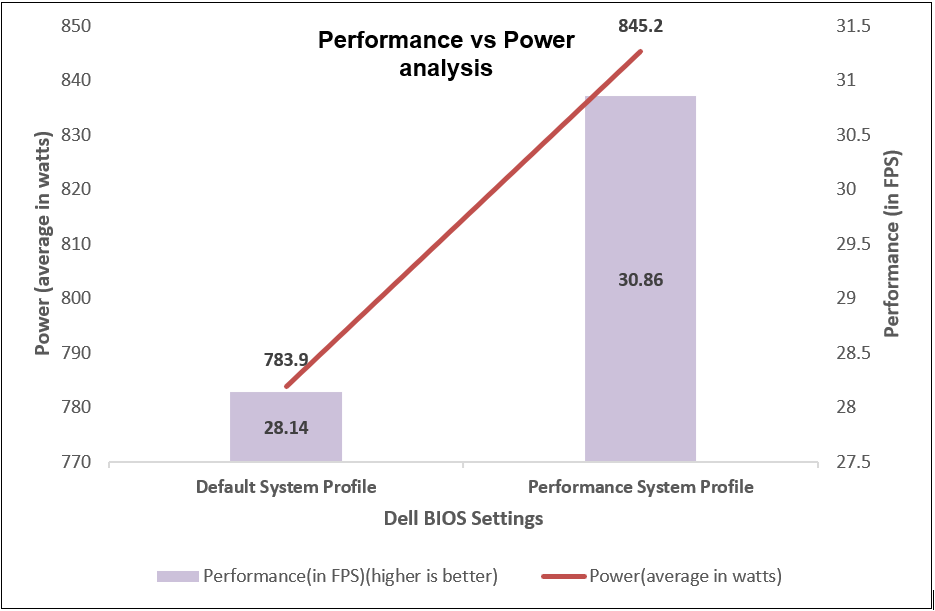
Figure 14. Comparing performance per average power consumed
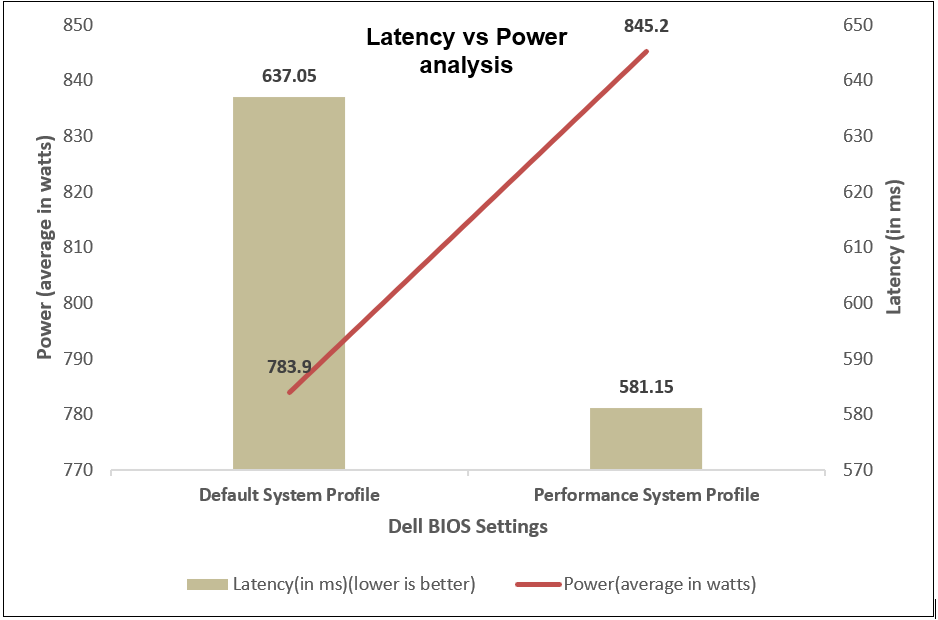
Figure 15. Comparing latency per average power consumed
Comprehensive details of benchmarks
We used the OpenVINO, TensorFlow, and computer-vision-based workload (Scalers AI) benchmarks and their specific use cases that measure the time spent on inference (excluding any preprocessing or post-processing) and then report on the inferences per second (or frames per second or millisecond).
What type of applications do these benchmarks support?
The benchmarks support multiple real-time AI applications such as person detection, vehicle detection, age and gender recognition, crowd counting, suspicious object recognition, parking spaces identification, traffic safety analysis, smart cities, and retail.
Table 2. OpenVINO test cases
Use case | Description |
Face detection | Measures the frames per second (FPS) and time taken (ms) for face detection using FP16 model on CPU |
Person detection
| Evaluates the performance of person detection using FP16 model on CPU in terms of FPS and time taken (ms) |
Vehicle detection | Assesses the CPU performance for vehicle detection using FP16 model, measured in FPS and time taken (ms) |
Person vehicle bike detection | Measures the performance of person vehicle bike detection on CPU using FP16-INT8 model, quantified in FPS and time taken (ms) |
Age and gender recognition | Evaluates the performance of age and gender detection on CPU using FP16 model, measured in FPS and time taken (ms) |
Machine translation | Assesses the CPU performance for machine translation from English using FP16 model, quantified in FPS and time taken |
Table 3. TensorFlow test cases
Use case | Description |
VGG-16 (Visual Geometry Group – 16 layers) | A deep convolutional neural network architecture with 16 layers, known for its uniform structure and use of 3x3 convolutional filters, achieving strong performance in image recognition tasks. This batch includes five different test cases of running the VGG-16 model on TensorFlow using a CPU, with various batch sizes ranging from 16 to 512. The images per second (images/sec) metric is used to measure the performance. |
AlexNet
| A pioneering convolutional neural network with five convolutional layers and three fully connected layers, instrumental in popularizing deep learning and inferencing. This batch includes five test cases of running the AlexNet model on TensorFlow using a CPU, with different batch sizes from 16 to 512. The images per second (images/sec) metric is used to assess the performance. |
GoogLeNet | An innovative CNN architecture using "Inception" modules with multiple filter sizes in parallel, reducing complexity while achieving high accuracy. This batch includes different test cases of running the GoogLeNet model on TensorFlow using a CPU, with varying batch sizes from 16 to 512. The images per second (images/sec) metric is used to evaluate the performance. |
ResNet-50 (Residual Network) | Part of the ResNet family, a deep CNN architecture featuring skip connections to tackle vanishing gradients, enabling training of very deep models. This batch consists of various test cases of running the ResNet-50 model on TensorFlow using a CPU, with different batch sizes ranging from 16 to 512. The images per second (images/sec) metric is used to measure the performance. |
Table 4. Computer-vision-based workload (Scalers AI) test case
Use case | Description |
Scalers AI | YOLOv4 Tiny from the Intel Model Zoo and computation was in int8 format. The tests were run using 90 vstreams in parallel, with a source video resolution of 1080p and a bit rate of 8624 kb/s. |
Conclusion
Using the PowerEdge server, we conducted iterative and exhaustive tests by fine-tuning BIOS settings against industry standard AI inferencing benchmarks to determine optimal BIOS settings that customers can configure with minimum efforts to maximize performance of AI workloads.
Our recommendations are:
 Disable Logical Processor for up to 177% increase in performance for high CPU utilization AI inference workloads.
Disable Logical Processor for up to 177% increase in performance for high CPU utilization AI inference workloads.
 Select Performance as the System Profile BIOS setting to achieve up to 10% increase in performance.
Select Performance as the System Profile BIOS setting to achieve up to 10% increase in performance.
 Select the NFVI FP Energy-Balance Turbo Profile BIOS setting to achieve up to 140 percent increase in performance for high CPU utilization workloads and 46% increase for moderate CPU utilization workload.
Select the NFVI FP Energy-Balance Turbo Profile BIOS setting to achieve up to 140 percent increase in performance for high CPU utilization workloads and 46% increase for moderate CPU utilization workload.
References
- Dell PowerEdge R760 with 4th Gen Intel Xeon Scalable Processors in AI
- Optimize Inference with Intel CPU Technology
Legal disclosures
Based on July 2023 Dell labs testing subjecting the PowerEdge R760 2x Intel Xeon Platinum 8452Y configuration with a 1.2.1 BIOS testing to AI inference benchmarks – OpenVINO and TensorFlow via the Phoronix Test Suite. Actual results will vary.