




Demystifying CSI plug-in for PowerFlex (persistent volumes) with Red Hat OpenShift
Tue, 20 Oct 2020 12:16:04 -0000
|Read Time: 0 minutes
Raghvendra Tripathi
SunilKumar HS
The Container Storage Interface (CSI) is a standard for exposing file and block storage to containerized workloads on Kubernetes, OpenShift and so on. CSI helps third-party storage providers (for example PowerFlex) to write plugins for OpenShift to consume storage from backends as persistent storage.
CSI architecture
CSI driver for Dell EMC VxFlex OS can be installed using Dell EMC Storage CSI Operator. It is a community operator and can be deployed using OperatorHub.io.
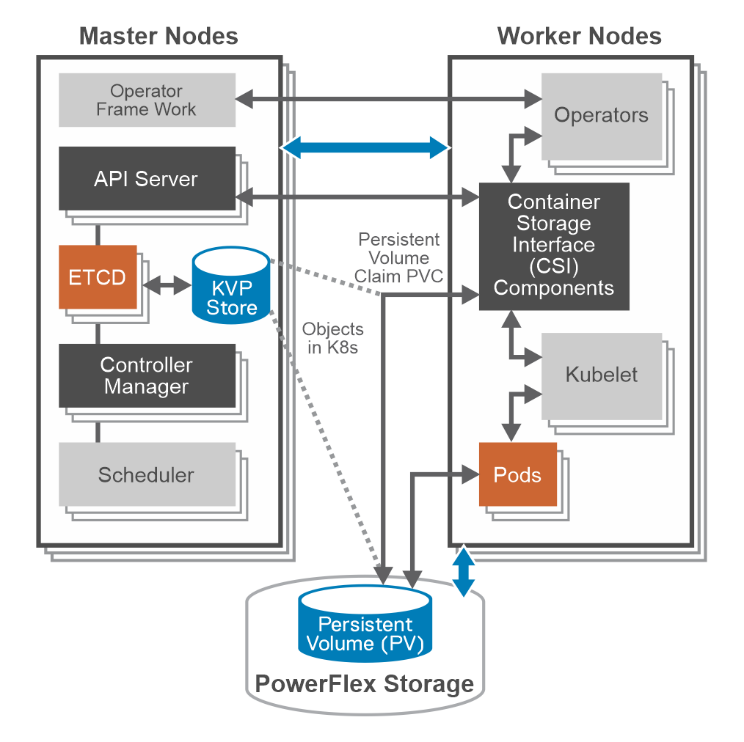
Master nodes components do not communicate directly with CSI driver. It interacts only with API server on Master nodes. It MUST watch the Kubernetes API and trigger the appropriate CSI operations against it. Kubelet discovers CSI drivers using kubelet plug-in registration mechanism. It directly issues calls to CSI driver.
CSI components
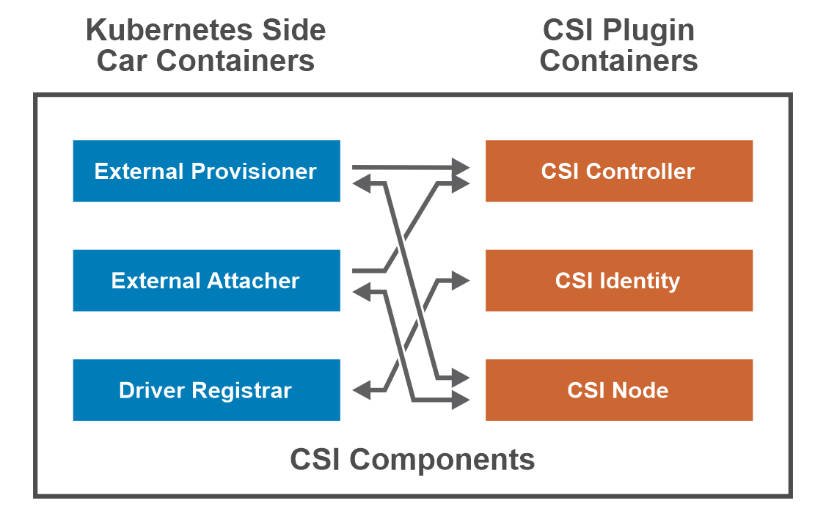
External Provisioner –The CSI external provisioner is a sidecar container that watches the k8s API server for PersistentVolumeClaim objects. It calls CreateVolume against the specified CSI endpoint to provision a volume.
External Attacher – The CSI external attacher is a sidecar container that watches the API server for VolumeAttachment objects and triggers controller [Publish|Unpublish] volume operations against a CSI endpoint.
Driver Registrar
- Node-driver-registrar – The CSI node driver registrar is a sidecar container that fetches driver information from a CSI endpoint and registers it with the kubelet on that node.
- Cluster-driver-registrar – The CSI cluster driver registrar is a sidecar container that registers a CSI driver with a k8s cluster by creating a CSIDriver object.
CSI Controller plug-in – The controller component can be deployed as a Deployment or StatefulSet on any node in the cluster. It consists of the CSI driver that implements the CSI Controller service.
CSI Identity – It enables k8s components and CSI containers to identify the driver.
CSI Node Plugin –The node component should be deployed on every node in the cluster through a DaemonSet. It consists of the CSI driver that implements the CSI Node service and the node driver registrar sidecar container.
CSI and Persistent Storage
Storage within OpenShift Container Platform 4.x is managed from worker nodes. The CSI API uses two new resources: PersistentVolume (PV) and PersistentVolumeClaim (PVC) objects.
Persistent Volumes – Kubernetes provides physical storage devices to the cluster in the form of objects called Persistent Volumes.
apiVersion: v1 kind: PersistentVolume spec: accessModes: - ReadWriteOnce capacity: storage: 104Gi claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: test-vol namespace: powerflex . . csi: driver: csi-vxflexos.dellemc.com fsType: ext4
persistentVolumeReclaimPolicy: Delete storageClassName: powerflex-vxflexos volumeMode: Filesystem status: phase: Bound |
Persistent Volume Claim – This object lets pods use storage from Persistent Volumes.
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: test-vol namespace: powerflex spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 100Gi storageClassName: powerflex-vxflexos |
Storage Class – This object helps you create PV/PVC pair for pods. It stores information about creating a persistent volume.
apiVersion: storage.dell.com/v1 kind: CSIVXFlexOS spec: storageClass: - name: powerflexos - key: csi-vxflexos.dellemc.com/X_CSI_VXFLEXOS_SYSTEMNAME values: - csi-vxflexos.dellemc.com . . . - name: powerflex-xfs parameters: storagepool: pool2 FsType: xfs allowedTopologies: - matchLabelExpressions: - key: csi-vxflexos.dellemc.com/X_CSI_VXFLEXOS_SYSTEMNAME values: - csi-vxflexos.dellemc.com |
CSI driver capabilities
Static Provisioning – This allows you to manually make existing PowerFlex storage available to the cluster.
Dynamic Provisioning - Storage volumes can be created on-demand. Storage resources are dynamically provisioned using the provisioner that is specified by the StorageClass object.
Retain Reclaiming – Once PersistentVolumeClaim is deleted, the corresponding PersistentVolume is not deleted rather moved to Released state and its data can be manually recovered.
Delete Reclaiming – It is the default reclaim policy and unlike Retain policy persistent volume is deleted.
Access Mode - ReadWriteOnce -- the volume can be mounted as read/write by a single node.
Supported FS - ext4/xfs.
Raw Block Volumes: Using Raw block option, PV can be attached to pod or app directly without formatting with ext4 or xfs file system.
Related Blog Posts

CSM 1.8 Release is Here!
Fri, 22 Sep 2023 21:29:12 -0000
|Read Time: 0 minutes
Introduction
This is already the third release of Dell Container Storage Modules (CSM)!
The official changelog is available in the CHANGELOG directory of the CSM repository.
CSI Features
Supported Kubernetes distributions
The newly supported Kubernetes distributions are :
- Kubernetes 1.28
- OpenShift 4.13
SD-NAS support for PowerMax and PowerFlex
Historically, PowerMax and PowerFlex are Dell’s high-end and SDS for block storage. Both of these backends recently introduced support for software defined NAS.
This means that the respective CSI drivers can now provision PVC with the ReadWriteMany access mode for the volume type file. In other words, thanks to the NFS protocol different nodes from the Kubernetes cluster can access the same volume concurrently. This feature is particularly useful for applications, such as log management tools like Splunk or Elastic Search, that need to process logs coming from multiple Pods.
CSI Specification compliance
Storage capacity tracking
Like PowerScale in v1.7.0, PowerMax and Dell Unity allow you to check the storage capacity on a node before deploying storage to that node. This isn't that relevant in the case of shared storage, because shared storage generally will always show the same capacity to each node in the cluster. However, it could prove useful if the array lacks available storage.
Using this feature, an object from the CSIStorageCapacity type is created by the CSI driver in the same namespace as the CSI driver, one for each storageClass.
An example:
kubectl get csistoragecapacities -n unity # This shows one object per storageClass.
Volume Limits
The Volume Limits feature is added to both PowerStore and PowerFlex. All Dell storage platforms now implement this feature.
This option limits the maximum number of volumes to which a Kubernetes worker node can connect. This can be configured on a per-node basis, or cluster-wide. Setting this variable to zero disables the limit.
Here are some PowerStore examples.
Per node:
kubectl label node <node name> max-powerstore-volumes-per-node=<volume_limit>
For the entire cluster (all worker nodes):
Specify maxPowerstoreVolumesPerNode or maxVxflexVolumesPerNode in the values.yaml file upon Helm installation.
If you opted-in for the CSP Operator deployment, you can control it by specifying X_CSI_MAX_VOLUMES_PER_NODES in the CRD.
Useful links
Stay informed of the latest updates of the Dell CSM eco-system by subscribing to:
- The Dell CSM Github repository
- Our DevOps & Automation Youtube playlist
- Slack (under the Dell Infrastructure namespace)
- Live streaming on Twitch
Author: Florian Coulombel

CSM 1.7 Release is Here!
Fri, 30 Jun 2023 13:42:36 -0000
|Read Time: 0 minutes
Introduction
The second release of 2023 for Kubernetes CSI Driver & Dell Container Storage Modules (CSM) is here!
The official changelog is available in the CHANGELOG directory of the CSM repository.
As you may know, Dell Container Storage Modules (CSM) bring powerful enterprise storage features and functionality to your Kubernetes workloads running on Dell primary storage arrays, and provide easier adoption of cloud native workloads, improved productivity, and scalable operations. Read on to learn more about what’s in this latest release.
CSI features
Supported Kubernetes distributions
The newly supported Kubernetes distributions are:
- Kubernetes 1.27
- OpenShift 4.12
- Amazon EKS Anywhere
- k3s on Debian
CSI PowerMax
For the last couple of versions, the CSI PowerMax reverseproxy is enabled by default. The TLS certificate secret creation is now pre-packaged using cert-manager, to avoid manual steps for the administrator.
A volume can be mounted to a Pod as `readOnly`. This is the default behavior for a `configMap` or `secret`. That option is now also supported for RawBlock devices.
apiVersion: v1 kind: Pod metadata: name: task-pv-pod spec: volumes: - name: task-pv-storage persistentVolumeClaim: claimName: task-pv-claim # What ever is the accessMode it will be read-only for the Pod readOnly: true ...
CSM v1.5 introduced the capacity to provision Fibre Channel LUNs to Kubernetes worker nodes through VMware Raw Device Mapping. One limitation of the RDM/LUN was that it was sticky to a single ESXi host, meaning that the Pod could not move to another worker node.
The auto-RDM feature works at the HostGroup level in PowerMax and therefore supports clusters with multiple ESXi hosts.
We are exposing the host I/O limits on the storage groups parameter using the StorageClass. The Host I/O limit is here to implement QoS at the worker node level and to prevent any noisy neighbor behavior.
CSI PowerScale
Storage Capacity Tracking is used by the Kubernetes scheduler to make sure that the node and backend storage have enough capacity for Pod/PVC.
The user can now set Quota limit parameters from the PVC and StorageClass requests. This allows the user to have better control of the quota parameters (including Soft Limit, AdvisoryLimit, Softgrace period) attached to each PVC
The PVC settings take precedence if quota limit values are specified in both StorageClass and PVC.
CSM features
CSM Operator
One can now use the CSM Operator to install Dell Unity and PowerMax CSI drivers and affiliated modules.
The CSM Operator now provides CSM resiliency and CSM-Replication for CSI-PowerFlex.
A detailed matrix of supported CSM components is available here.
CSM Installation Wizard
The CSM Installation Wizard is the easiest and most straight forward way to install the Dell CSI drivers and Container Storage Modules.
In this release, we are adding support for Dell Unity, PowerScale, and PowerFlex.
To keep it simple, we removed the option to install the driver and modules in separate namespaces.
CSM Authorization
In this release of CSM, Secrets Encryption is enabled by default.
- All secrets are encrypted by default, using the AES-CBC key type.
- After installation/upgrade, all secrets will be encrypted.
- AES-CBC is the default key type.
- AES-CBC is the only supported key type.
CSM Replication
When you use CSM replication, two volumes are created: the active volume and the replica. Prior to CSM v1.7, if you removed the two PVs, the physical replica wasn't deleted.
Now on PV deletion, we cascade the removal to all objects, including the replica block volumes in PowerStore, PowerMax, and PowerFlex, so that there are no more orphan volumes.
Useful links
Stay informed of the latest updates of the Dell CSM eco-system by subscribing to:
- The Dell CSM Github repository
- Our DevOps & Automation Youtube playlist
- Slack (under the Dell Infrastructure namespace)
Author: Florian Coulombel