




Dell Technologies Automates Your Infrastructure
Mon, 14 Nov 2022 18:07:42 -0000
|Read Time: 0 minutes
Overview
What is infrastructure automation all about? Today’s IT infrastructures, data centers, and Telco are continually challenged to evolve and grow to keep up with the demands of this digital world. To quickly and successfully bring high-quality products and services into production, you need a scalable approach.
Dell Technologies - Four pillars of automation
The Dell networking automation feature set integrates industry-standard open-source tools and open-source scripting APIs. These APIs allow your datacenter network fabric to ease configuration and automation of network devices and functions. With these improvements, you can transform your virtualized data center infrastructure to become more agile, flexible, and efficient even as you develop new ways to deliver applications and services.
For deployment, Dell network automation can help boost your IT infrastructure's ability to scale, help minimize configuration errors, reduce time to production, lower operational costs, avoid network downtime, and also enhance network resiliency. It allows speedy rollout of new services, devices, and applications based on established and reusable processes.
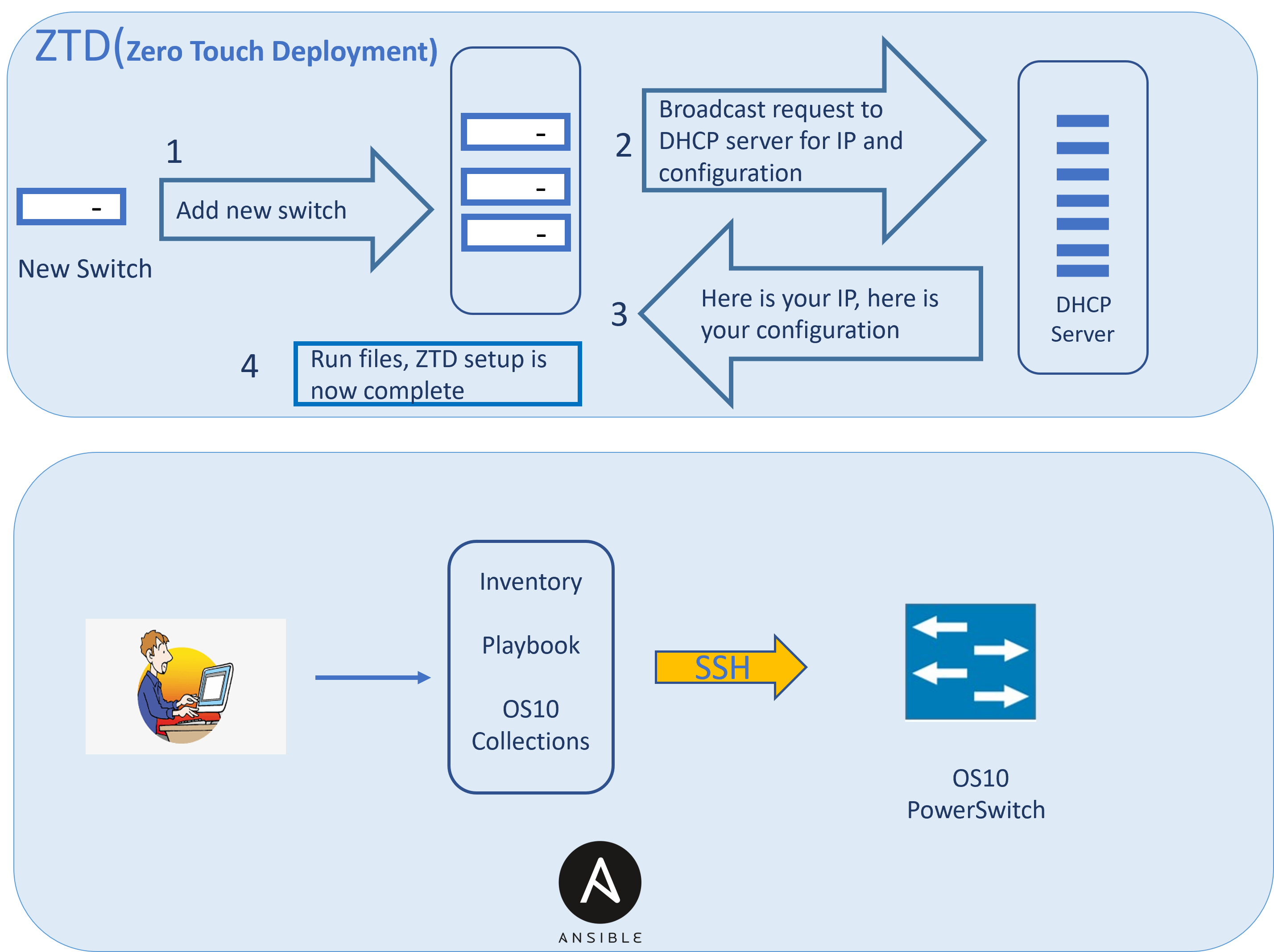
Dell networking automation feature set includes Zero Touch Deployment (ZTD), Ansible, Bare Metal Provisioning (BMP), and Fabric Design Center (FDC):
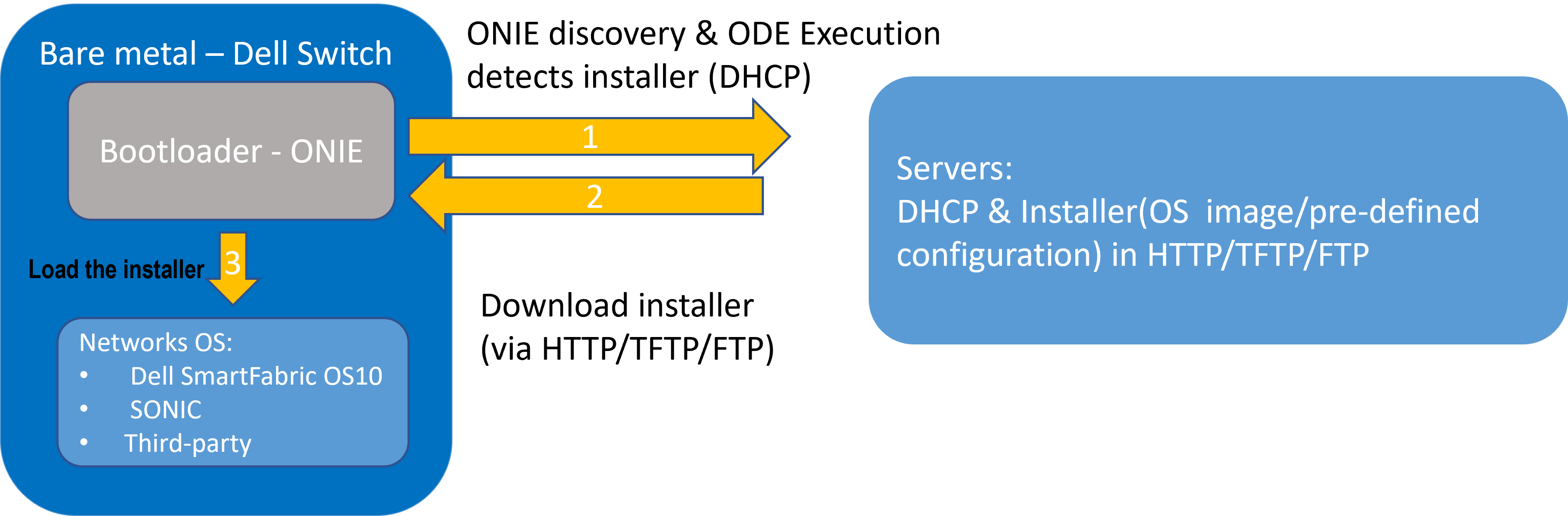
- Zero Touch Deployment (ZTD) is a Dell SmartFabric OS10 feature that greatly reduces the manual configuration task involved in setting up a PowerSwitch device out of the box.
- Ansible is a simple agentless automation framework that can configure Dell SmartFabric OS10 switches, deploy software, monitor network, and orchestrate DevOps/NetOps tasks.
- Bare Metal Provisioning (BMP) is another Open Automation framework which streamlines the network fabric’s ability to participate in automated, policy-driven, real-time workload allocation in response to changing application and service demands.
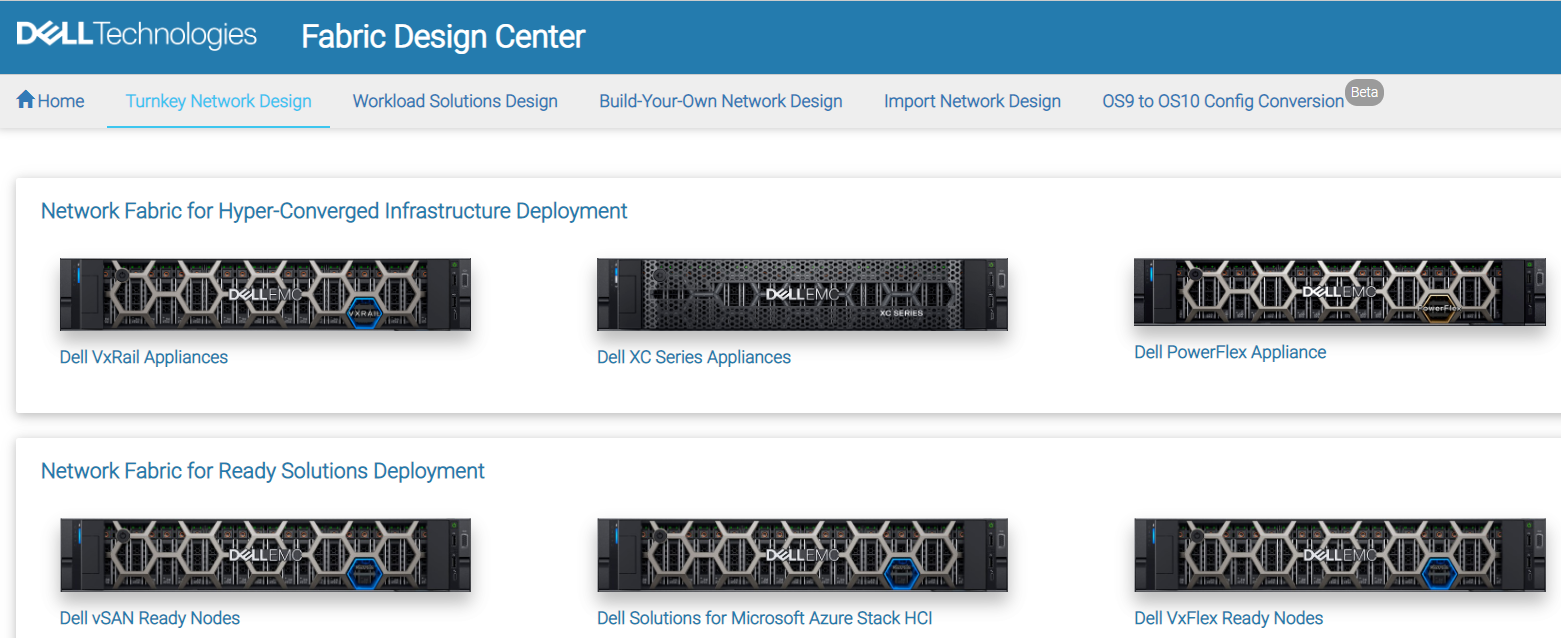
- Fabric Data Center( FDC) is an easy-to-use, hands-on, web-based tool that automates the network fabric design process.
Conclusion
Realizing a return on virtualization investments means deploying effective automation techniques that can simplify the deployment of virtualized environment and allow a policy-based fabric orchestration model.
While many network vendors have chosen a proprietary path to automation resulting in lock-in, Dell’s approach is to utilize open and industry-standard technologies based on an extensible and modular operating system across the range of the heterogeneous Dell switch portfolio.
Related Blog Posts

Accelerating and Optimizing AI Operations with Infrastructure as Code


Fri, 03 May 2024 12:00:00 -0000
|Read Time: 0 minutes
Accelerating and Optimizing AI Operations with Infrastructure as Code
Achieving maturity in a DevOps organization requires overcoming various barriers and following specific steps. The level of maturity attained depends on the short-term and long-term goals set for the infrastructure. In the short term, IT teams must focus on upskilling their resources and integrating tools for containerization and automation throughout the operating lifecycles, from Day 0 to Day 2. Any progress made in scaling up containerized environments and automating processes significantly enhances the long-term economic viability and sustainability of the company. Furthermore, in the long term, it involves deploying these solutions across multicloud, multisite landscapes and effectively balancing workloads.
The optimization of your AI applications, and by extension, other high-value workloads, hinges upon the velocity, scalability, and efficacy of your infrastructure, as well as the maturity of your DevOps processes. Prior to the explosion that is AI, recent survey results indicated the state of automation for infrastructure operations’ workflows was overall less than 50%; partner that with twofold the increase of application counts and organizations may struggle against the waves of change[1].
From compute capabilities to storage density and speed, spanning across unstructured, block, and file formats, there exists fundamental elements of automation ripe for swift integration to establish a robust foundation. By seamlessly layering pre-built integration tools and a complementary portfolio of products at each stage, the journey towards ramping up AI can be alleviated.
There are important considerations regarding the various hardware infrastructure components for a generative AI system, including high performance computing, highspeed networking, and scalable, high-capacity, and low-latency storage to name a few. The infrastructure requirements for AI/ML workloads are dynamic and dependent on several factors, including the nature of the task, the size of the dataset, the complexity of the model, and the desired performance levels. There is no one-size-fits-all solution when it comes to Gen AI infrastructure, as different tasks and projects may demand unique configurations. Central to the success of generative AI initiatives is the adoption of Infrastructure-as-Code (IaC) principles which facilitate the automation and orchestration of underlying infrastructure components. By leveraging IaC tools like RedHat Ansible and HashiCorp Terraform, organizations can streamline the deployment and management of hardware resources, ensuring seamless integration with Gen AI workloads.
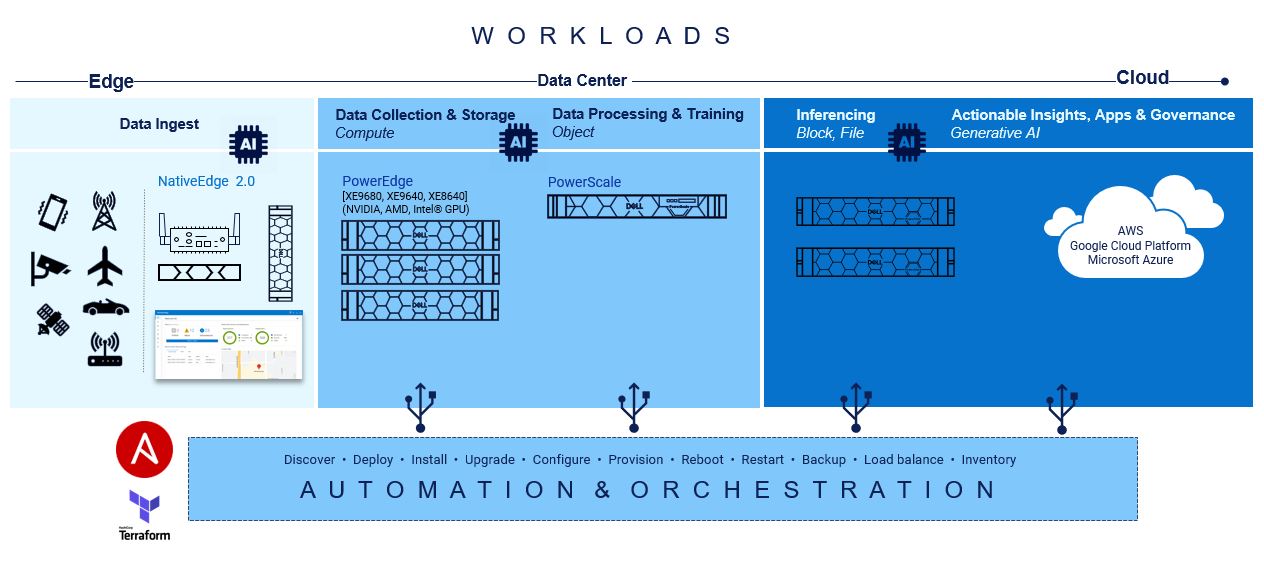 At the base of this foundation is Red Hat Ansible modules for Dell, and they speed up the provisioning of servers and storage for quick AI application workload mobility.
At the base of this foundation is Red Hat Ansible modules for Dell, and they speed up the provisioning of servers and storage for quick AI application workload mobility.
Creating playbooks with Ansible to automate server configurations, provisioning, deployments, and updates are seamless while data is being collected. Due to the declarative and mutable nature of Ansible, the playbooks can be changed in real-time without interruption to processes or end users.
Compute
On the compute front, a lot goes into configuring servers for the different AI and ML operations:
GPU Drivers and CUDA toolkit Installation: Install appropriate GPU drivers for the server's GPU hardware. For example, installing CUDA Toolkit and drivers to enable GPU acceleration for deep learning frameworks such as TensorFlow and PyTorch.
Deep Learning Framework Installation: Install popular deep learning frameworks such as TensorFlow or PyTorch, along with their associated dependencies.
Containerization: Consider using containerization technologies such as Docker or Kubernetes to encapsulate AI workloads and their dependencies into portable and isolated containers. Containerization facilitates reproducibility, scalability, and resource isolation, making it easier to deploy and manage GenAI workloads across different environments.
Performance Optimization: Optimize server configurations, kernel parameters, and system settings to maximize performance and resource utilization for GenAI workloads. Tune CPU and GPU settings, memory allocation, disk I/O, and network configurations based on workload characteristics and hardware capabilities.
Monitoring and Management: Implement monitoring and management tools to track server performance metrics, resource utilization, and workload behavior in real-time.
Security Hardening: Ensure server security by applying security best practices, installing security patches and updates, configuring firewalls, and implementing access controls. Protect sensitive data and AI models from unauthorized access, tampering, or exploitation by following security guidelines and compliance standards.
Dell Openmanage Ansible collection offers modules and roles both at the iDRAC/Redfish interface level and at the OpenManage Enterprise level for server configurations such as PowerEdge XE 9860 designed to collect, develop, train, and deploy large machine learning models (LLMs).
The following is a summary of the OME and iDRAC modules and roles as part of the openmanage collection:


Storage
When it comes to AI and storage, during the data processing and training aspects, customers rely on scalable and simple access to file systems which increased data is trained on. With AI unstructured data storage is necessary for the bounty of rich context and nuance that will be accessed during the building phase. It also highly depends on user access to be variable, and Ansible automation playbooks can help change and adapt quickly.
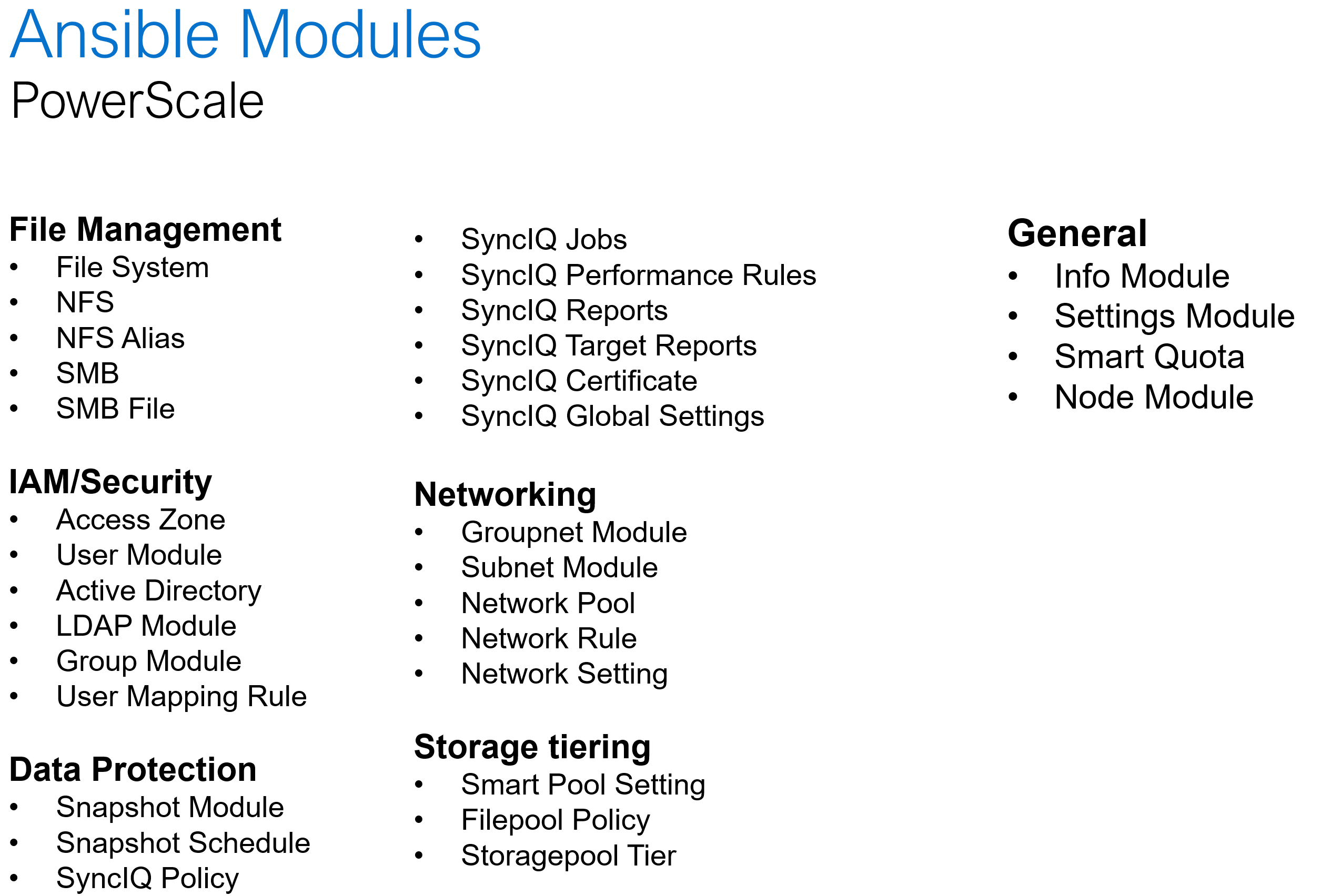
Dell PowerScale is the world’s leading scale-out NAS platform, and it recently became the first ethernet storage certified on NVIDIA SuperPod. When it comes to Ansible automation, PowerScale comes with an extensive set of modules that covers a wide range of platform operations:
Software defined storage
Hyper converged platforms like PowerFlex offer highly scalable and configurable compute and storage clusters. In addition to the common day-2 tasks like storage provisioning, data protection and user management, the Ansible collection for PowerFlex can be used for cluster deployment and expansion. Here is a summary of what Ansible collections for PowerFlex offers:

Conclusion
The one thing agreed upon is that Generative AI tools need the scale, repeatability, and reliability beyond anything created from the software and data center combined. This is precisely what building infrastructure-as-code practices into a multisite operation are designated to do. From PowerEdge to PowerScale, the level of capacity and performance is unmatched. This allows AI operations and Generative AI to absorb, grow and provide the intelligence that organizations need to be competitive and innovative.
[1] Infrastructure-as-code and DevOps Automation: The Keys to Unlocking Innovation and Resilience, September 2023
Other resources:
GenAI Acceleration Depends on Infrastructure as Code
Authors: Jennifer Aspesi, Parasar Kodati

Dell OpenManage Enterprise Operations with Ansible Part 3: Compliance, Reporting, and Remediation
Fri, 08 Dec 2023 15:37:49 -0000
|Read Time: 0 minutes
In case you missed it, check out the first post of this series for some background information on the openmanage Ansible collection by Dell and inventory management, as well as the second post to learn more about template-based deployment. In this blog, we’ll take a look at automating compliance and remediation workflows in Dell OpenManage Enterprise (OME) with Ansible.
Compliance baselines
Compliance baselines in OME are reports that show the ‘delta’ or difference between the specified desired configuration and the actual configuration of the various devices in the inventory. The desired configuration is specified as a compliance template, which can be cloned from either a deployment template or a device using the ome_template covered in the deployment section of this series. Following are task examples for creating compliance templates:
- name: Create a compliance template from deploy template
dellemc.openmanage.ome_template:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
validate_certs: no
command: "clone"
template_name: "email_deploy_template"
template_view_type: "Compliance"
attributes:
Name: "email_compliance_template"- name: Create a compliance template from reference device
dellemc.openmanage.ome_template:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
validate_certs: no
command: "create"
device_service_tag:
- "SVTG123"
template_view_type: "Compliance"
attributes:
Name: "Configuration Compliance"
Description: "Configuration Compliance Template"
Fqdds: "BIOS"Once we have the template ready, we can create the baseline, which is the main step where OME compares the template configuration to devices. Devices can be specified as a list or a device group. Depending on the number of devices, this step can be time-consuming. The following code uses a device group that has already been created, as shown in part 2 of this OME blog series:
- name: Create a configuration compliance baseline using an existing template
dellemc.openmanage.ome_configuration_compliance_baseline:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
validate_certs: no
command: create
template_name: "email_compliance_template"
description: "SNMP Email setting"
names: "baseline_email"
device_group_names: demo-group-allOnce the baseline task is run, we can retrieve the results, store them in a variable, and write the contents to a file for further analysis:
- name: Retrieve the compliance report of all of the devices in the specified configuration compliance baseline.
dellemc.openmanage.ome_configuration_compliance_info:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
validate_certs: no
baseline: "baseline_email"
register: compliance_report
delegate_to: localhost- name: store the variable to json
copy:
content: "{{ compliance_report | to_nice_json }}"
dest: "./output-json/compliance_report.json"
delegate_to: localhostOnce the compliance details are stored in a variable, we can always extract details from it, like the list of non-compliant devices shown here:
- name: Extract service tags of devices with highest level compliance status
set_fact:
non_compliant_devices: "{{ non_compliant_devices | default([]) + [device.Id] }}"
loop: "{{ compliance_report.compliance_info }}"
loop_control:
loop_var: device
when: device.ComplianceStatus > 1
no_log: trueRemediatation
The remediation task brings all devices to a desired template configuration, much like the template deployment job. For remediation, we use the same baseline module with command set to remediate and pass all devices we would like to remediate, as well as the list of devices that are non-compliant:
- name: Remediate a specified non-complaint devices to a configuration compliance baseline using device IDs # noqa: args[module]
dellemc.openmanage.ome_configuration_compliance_baseline:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
validate_certs: no
command: "remediate"
names: "baseline_email"
device_ids: "{{ non_compliant_devices }}"
when: "non_compliant_devices | length > 0"
delegate_to: localhostWatch the following video to see in-depth how the different steps of this workflow are run:
Conclusion
To recap, we’ve covered the creation of compliance templates and running baseline checks against your PowerEdge server inventory. We then saw how to retrieve detailed compliance reports and parse them in Ansible for further analysis. Finally, using the OME baseline Ansible, we ran a remediation job to correct any configuration drift in non-compliant devices. Don’t forget to check out the detailed documentation for openmanage Ansible modules including both OME and iDRAC/redfish modules and roles, as well as the complete code examples used here in this GitHub repository.
Author: Parasar Kodati, Engineering Technologist, Dell ISG