




CloudPools Supported Cloud Providers
Thu, 07 Dec 2023 20:43:11 -0000
|Read Time: 0 minutes
Related Blog Posts

CloudPools Operation Workflows
Fri, 12 Jan 2024 21:01:01 -0000
|Read Time: 0 minutes
The Dell PowerScale CloudPools feature of OneFS allows tiering cold or infrequently accessed data to move to lower-cost cloud storage. CloudPools extends the PowerScale namespace to the private cloud, or the public cloud. For CloudPools supported cloud providers, see the CloudPools Supported Cloud Providers blog.
This blog focuses on the following CloudPools operation workflows:
- Archive
- Recall
- Read
- Update
Archive
The archive operation is the CloudPools process of moving file data from the local PowerScale cluster to cloud storage. Files are archived either using the SmartPools Job or from the command line. The CloudPools archive process can be paused or resumed.
The following figure shows the workflow of the CloudPools archive.
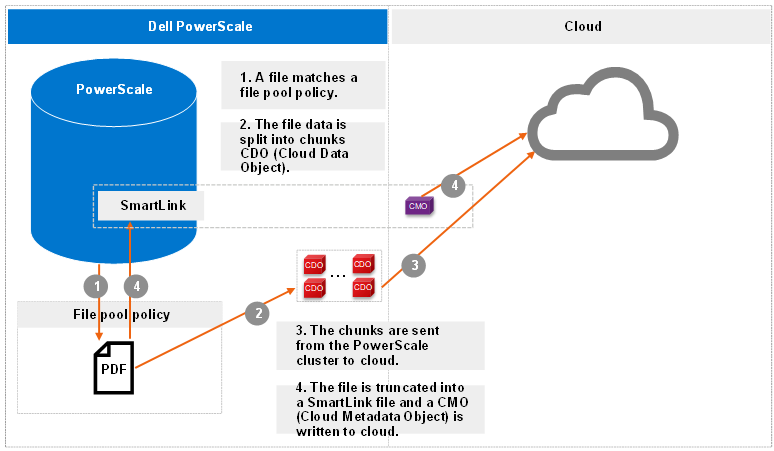
Figure 1. Archive workflow
More workflow details include:
- The file pool policy in Step 1 specifies a cloud target and cloud-specific parameters. Policy examples include:
- Encryption: CloudPools provides an option to encrypt data before the data is sent to the cloud storage. It uses the PowerScale key management module for data encryption and uses AES-256 as the encryption algorithm. The benefit of encryption is that only encrypted data is being sent over the network.
- Compression: CloudPools provides an option to compress data before the data is sent to the cloud storage. It implements block-level compression using the zlib compression library. CloudPools does not compress data that is already compressed.
- Local data cache: Caching is used to support local reading and writing of SmartLink files. To optimize performance, it reduces bandwidth costs by eliminating repeated fetching of file data for repeated reads and writes. The data cache is used for temporarily caching file data from the cloud storage on PowerScale disk storage for files that have been moved off cluster by CloudPools.
- Data retention: Data retention is a concept used to determine how long to keep cloud objects on the cloud storage.
- When chunks are sent from the PowerScale cluster to cloud in Step 3, a checksum is applied for each chunk to ensure data integrity.
Recall
The recall operation is the CloudPools process of reversing the archive process. It replaces the SmartLink file by restoring the original file data on the PowerScale cluster and removing the cloud objects in cloud. The recall process can only be performed using the command line. The CloudPools recall process can be paused or resumed.
The following figure shows the workflow of CloudPools recall.
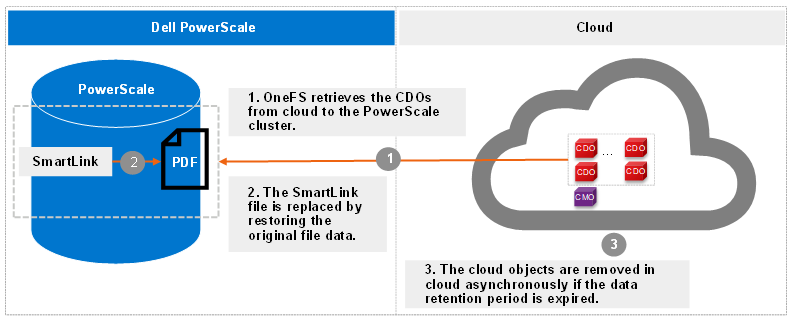
Figure 2. Recall workflow
Read
The read operation is the CloudPools process of client data access, known as inline access. When a client opens a file for read, the blocks are added to the cache in the associated SmartLink file by default. The cache can be disabled by setting the accessibility in the file pool policy for CloudPools. The accessibility setting is used to specify how data is cached in SmartLink files when a user or application accesses a SmartLink file on the PowerScale cluster. Values are cached (default) and no cache.
The following figure shows the workflow of CloudPools read by default.
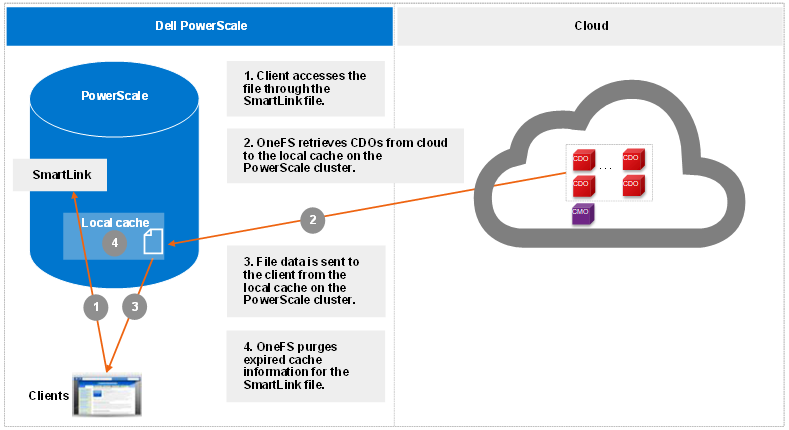
Figure 3. Read workflow
Starting from OneFS 9.1.0.0, cloud object cache is introduced to enhance CloudPools functions for communicating with cloud. In Step 1, OneFS looks for data in the object cache first and OneFS retrieves data from the object cache if the data is already in the object cache. Cloud object cache reduces the number of requests to cloud when reading a file.
Prior to OneFS 9.1.0.0, in Step 1, OneFS looks for data in the local data cache first. It moves to Step 3 if the data is already in the local data cache.
Note: Cloud object cache is per node. Each node maintains its own object cache on the cluster.
Update
The update operation is the CloudPools process that occurs when clients update data. When clients change to a SmartLink file, CloudPools first writes the changes in the data local cache and then periodically sends the updated file data to cloud. The space used by the cache is temporary and configurable.
The following figure shows the workflow of CloudPools update.
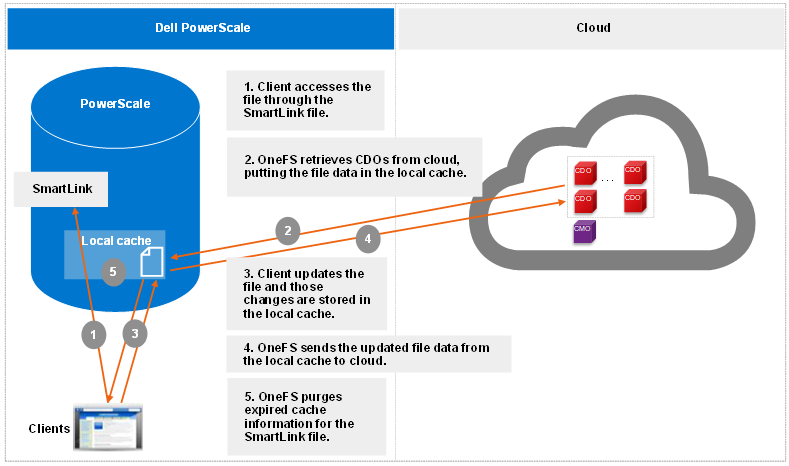
Figure 4. Update workflow
Thank you for taking the time to read this blog, and congratulations on gaining a clear understanding of how the OneFS CloudPools operation works!
Author: Jason He, Principal Engineering Technologist

CloudPools Reporting
Fri, 12 Jan 2024 20:33:21 -0000
|Read Time: 0 minutes
This blog focuses on CloudPools reporting, specifically:
- CloudPools network stats
- The isi_fsa_pools_usage feature
CloudPools network stats
Dell PowerScale CloudPools network stats collect every network transaction and provide network activity statistics from CloudPools connections to the cloud storage.
Displaying network activity statistics
The network activity statistics include bytes In, bytes Out, and the number of GET, PUT, and DELETE operations. CloudPools network stats are available in two categories:
- Per CloudPools account
- Per file pool policy
Note: CloudPools network stats do not provide file statistics, such as the file list being archived or recalled.
Run the following command to check the CloudPools network stats by CloudPools account:
isi_test_cpool_stats -Q --accounts <account_name>
For example, the following command shows the current CloudPools network stats by CloudPools account:
isi_test_cpool_stats -Q --accounts testaccount Account Name Bytes In Bytes Out Num Reads Num Writes Num Deletes testaccount 4194896000 4194905034 4000 2001 8001
Similarly, you can run the following command to check the CloudPools network stats by file pool policy:
isi_test_cpool_stats -Q --policies <policy_name>
And here is an example of current CloudPools network stats by file pool policy:
isi_test_cpool_stats -Q --policies testpolicy Policy Name Bytes In Bytes Out Num Reads Num Writes testpolicy 4154896000 4154905034 4000 2001
Note: The command output does not include the number of deletes by file pool policy.
Run the following command to check the history for CloudPools network stats:
isi_test_cpool_stats -q –s <number of seconds in the past to start stat query>
Use the s parameter to define the number of seconds in the past. For example, set it as 86,400 to query CloudPools network stats over the last day, as in the following example:
isi_test_cpool_stats -q -s 86400 Account bytes-in bytes-out gets puts deletes testaccount | 4194896000 | 4194905034 | 4000 | 2001 | 8001
You can also run the following command to flush stats from memory to database and get the real-time CloudPools network stats:
isi_test_cpool_stats -f
Displaying stats for CloudPools activities
The cloud statistics namespace with CloudPools is added in OneFS 9.4.0.0. This feature leverages existing OneFS daemons and systems to track statistics about CloudPools activities. The statistics include bytes In, bytes Out, and the number of Reads, Writes, and Deletions. CloudPools statistics are available in two categories:
- Per CloudPools account
- Per file pool policy
Note: The cloud statistics namespace with CloudPools does not provide file statistics, such as the file list being archived or recalled.
You can run these isi statistics cloud commands to view statistics about CloudPools activities:
isi statistics cloud --account <account_name> isi statistics cloud --policy <policy_name>
The following command shows an example of current CloudPools statistics by CloudPools account:
isi statistics cloud --account s3 Account Policy In Out Reads Writes Deletions Cloud Node s3 218.5KB 218.7KB 1 2 0 AWS 3 s3 0.0B 0.0B 0 0 0 AWS 1 s3 0.0B 0.0B 0 0 0 AWS 2
The following command shows an example of current CloudPools statistics by file pool policy:
isi statistics cloud --policy s3policy Account Policy In Out Reads Writes Deletions Cloud Node s3 s3policy 218.5KB 218.7KB 1 2 0 AWS 3 s3 s3policy 0.0B 0.0B 0 0 0 AWS 1 s3 s3policy 0.0B 0.0B 0 0 0 AWS 2
The isi_fsa_pools_usage feature
Starting from OneFS 8.2.2, you can run the following command to list Logical Size and Physical Size of stubs in one directory. This feature leverages IndexUpdate and FSA (File System Analytics) jobs. To enable this feature, it requires:
- Scheduling the IndexUpdate job. It’s recommended to run it every four hours.
- Scheduling the FSA job. It’s recommended to run it every day, but not more often than the IndexUpdate job.
isi_fsa_pools_usage /ifs Node Pool Dirs Files Streams Logical Size Physical Size Cloud 0 1 0 338.91k 24.00k h500_30tb_3.2tb-ssd_128gb 42 300671 0 879.23G 1.20T
Now, you get how to use commands for CloudPools reporting. It’s simple and straightforward. Thanks for reading!
Author: Jason He, Principal Engineering Technologist