




AI and Model Development Performance
Thu, 31 Aug 2023 20:47:58 -0000
|Read Time: 0 minutes
There has been a tremendous surge of information about artificial intelligence (AI), and generative AI (GenAI) has taken center stage as a key use case. Companies are looking to learn more about how to build architectures to successfully run AI infrastructures. In most cases, creating a GenAI solution involves fine-tuning a pretrained foundational model and deploying it as an inference service. Dell recently published a design guide – Generative AI in the Enterprise – Inferencing, that provides an outline of the overall process.
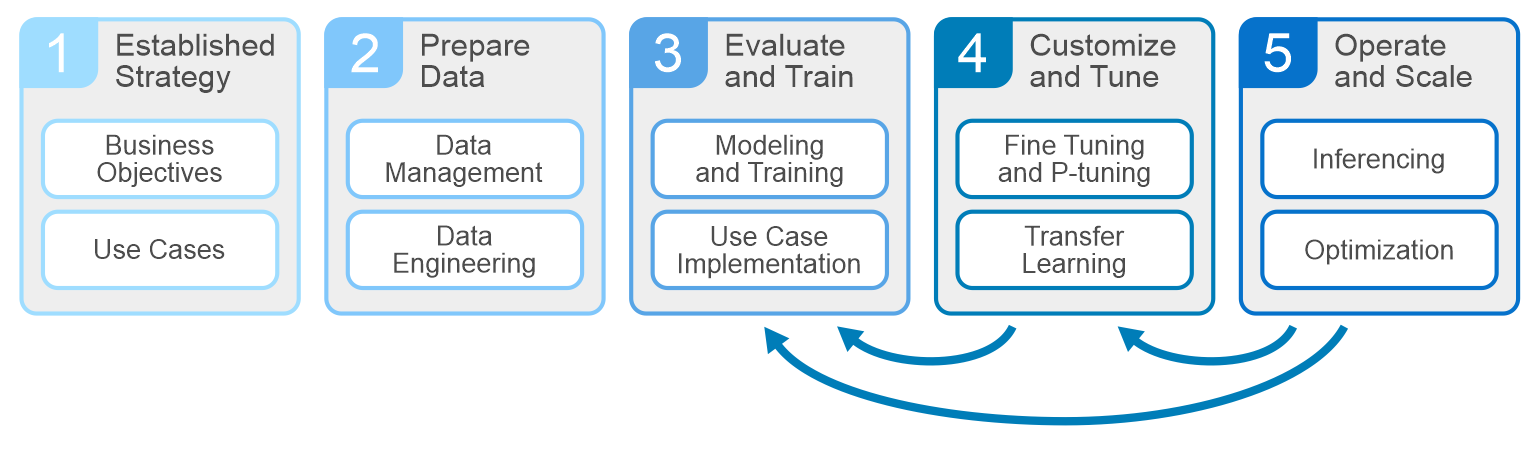
All AI projects should start with understanding the business objectives and key performance indicators. Planning, data prep, and training make up the other phases of the cycle. At the core of the development are the systems that drive these phases – servers, GPUs, storage, and networking infrastructures. Dell is well equipped to deliver everything an enterprise needs to build, develop, and maintain analytic models that serve business needs.
GPUs and accelerators have become common practice within AI infrastructures. They pull in data and training/fine-tune models within the computational capabilities of the GPU. As GPUs have evolved, their ability to handle larger models and parallel development cycles has evolved. This has left a lot of us wondering - how do we build an architecture that will support the model development that my business needs? It helps to understand a few parameters.
Defining business objectives and use cases will help shape your architecture requirements.
- The size and location of the training data set
- Model size in number of parameters and type of model being trained/fine-tuned
- Training parallelism and time to complete the training/fine-tuning.
Answering these questions helps determine how many GPUs are needed to train/fine-tune the model. Consider two main factors in GPU sizing. First is the amount of GPU memory needed to store model parameters and optimizer state. Second is the number of floating-point operations (FLOPs) needed to execute the model. Both generally scale with model size. Large models often exceed the resources of a single GPU and require spreading a single model over multiple GPUs.
Estimating the number of GPUs needed to train/fine-tune the model helps determine the server technologies to choose. When sizing servers, it’s important to balance the right GPU density and interconnect, power consumption, PCI bus technology, external port capacity, memory, and CPU. Dell PowerEdge servers include a variety of options for GPU types and density. PowerEdge XE Servers can host up to 8 NVIDIA H100 GPUs in a single server GenAI on PowerEdge XE9680, as well as the latest technologies, including NVLink, NVIDIA GPUDirect, PCIe 5.0, and NVMe disks. PowerEdge mainstream servers range from two to four GPU configurations, offering a variety of GPUs from different manufacturers. PowerEdge servers provide outstanding performance for all phases of model development. Visit Dell.com for more on PowerEdge Servers.
Now that we understand how many GPUs are needed and the servers to host them, it’s time to tackle storage. At a minimum, the storage should have capacity to host the training data set, the checkpoints during the model training, and any other data that relates to the pruning/preparing phase. The storage also needs to deliver the data at a rate the GPUs request it. The rate of delivery is multiplied by model parallelism, or the number of models being trained in parallel, and subsequently the number of GPUs requesting the data simultaneously (concurrently). Ideally, every GPU is running at 90% or better to maximize our investment, and a storage system that supports high concurrency is suited for these types of workloads.
Tools such as FIO or its cousin GDSIO (used to understand speeds and feeds of the storage system) are great for gaining hero numbers or theoretical maximums for reads/writes, but they are not representative of performance requirements for the AI development cycles. Data prep and stage shows up on the storage as random R/W, while during the training/fine-tuning phase, the GPUs are concurrently streaming reads from the storage system. Checkpoints throughout training are handled as writes back to the storage. These different points during the AI lifecycle require storage that can successfully handle these workloads at the scale determined by our model calculations and parallel development cycles.
Data scientists at Dell take great effort in understanding how different model development affects server and storage requirements. For example, language models like BERT and GPT have little effect on storage performance and resources, whereas image sequencing and DLRM models have significant or show worst case storage performance and resource demand. For this, the Dell storage teams focus testing and benchmarking on AI Deep Learning workflows based on popular image models like ResNet with real GPUs to understand the performance requirements needed to deliver data to the GPU during model training. The following image shows an architecture designed with Dell PowerEdge servers and networking with PowerScale scale-out storage.
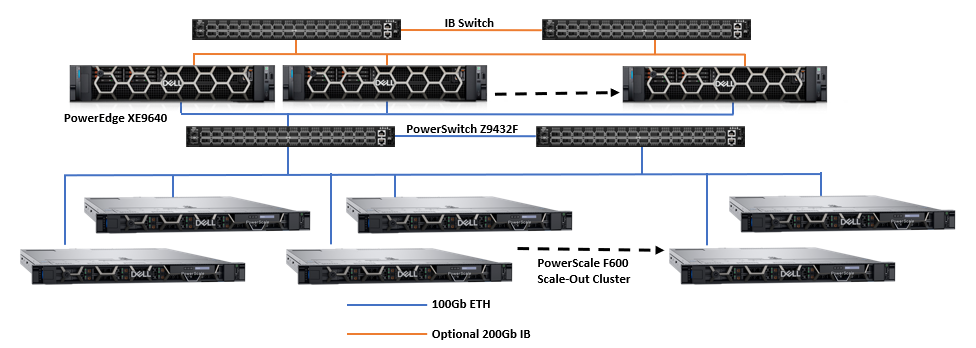
Dell PowerScale scale-out file storage is especially suited for these workloads. Each node in a PowerScale cluster delivers equivalent performance as the cluster and workloads scale. The following images show how PowerScale performance scales linearly as GPUs are increased, while the performance of each individual GPU remains constant. The scale-out architecture of PowerScale file storage easily supports AI workflows from small to large.
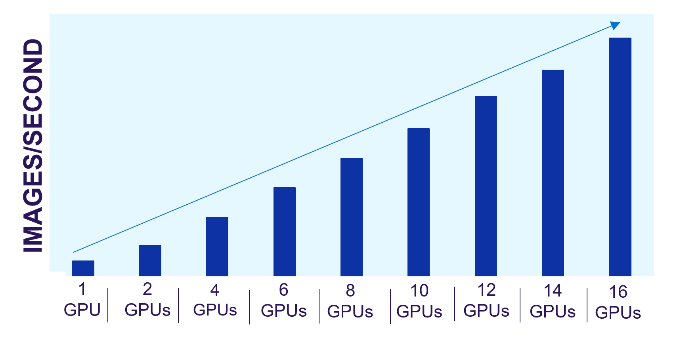
Figure 1. PowerScale linear performance
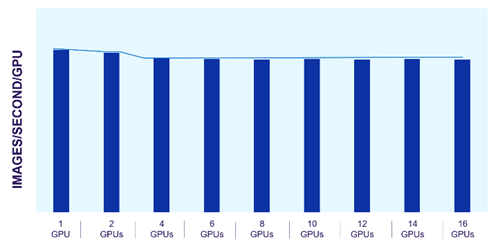
Figure 2. Consistent GPU performance with scale
The predictability of PowerScale allows us to estimate the storage resources needed for model training and fine-tuning. We can easily scale these architectures based on the model type and size along with the number and type of GPUs required.
Architecting for small and large AI workloads is challenging and takes planning. Understanding performance needs and how the components in the architecture will perform as the AI workload demand scales is critical.
Author: Darren Miller
Related Blog Posts

Accelerating Distributed Training in a Multinode Virtualized Environment
Fri, 13 May 2022 13:57:13 -0000
|Read Time: 0 minutes
Introduction
In the age of deep learning (DL), with complex models, it is vital to have a system that allows faster distributed training. Depending on the application, some DL models require more frequent retraining and fine-tuning of the hyperparameters to be deployed in the production environment. It is important to understand the best practices to improve multinode distributed training performance.
Networking is critical in a distributed training setup as there are numerous gradients exchanged between the nodes. The complexity increases as we increase the number of nodes. In the past, we have seen the benefits of using:
- Direct Memory Access (DMA), which enables a device to access host memory without the intervention of CPUs
- Remote Direct Memory Access (RDMA), which enables access to memory on a remote machine without interrupting the CPU processes on that system
This blog examines performance when direct communication is established between the GPUs in multinode training experiments run on Dell PowerEdge servers with NVIDIA GPUs and VMware vSphere.
GPUDirect RDMA
Introduced as part of Kepler class GPUs and CUDA 5.0, GPUDirect RDMA enables a direct communication path between NVIDIA GPUs and third-party devices such as network interfaces. By establishing direct communication between the GPUs, we can eliminate the critical bottleneck where data needs to be moved into the host system memory before it can be sent over the network, as shown in the following figure:
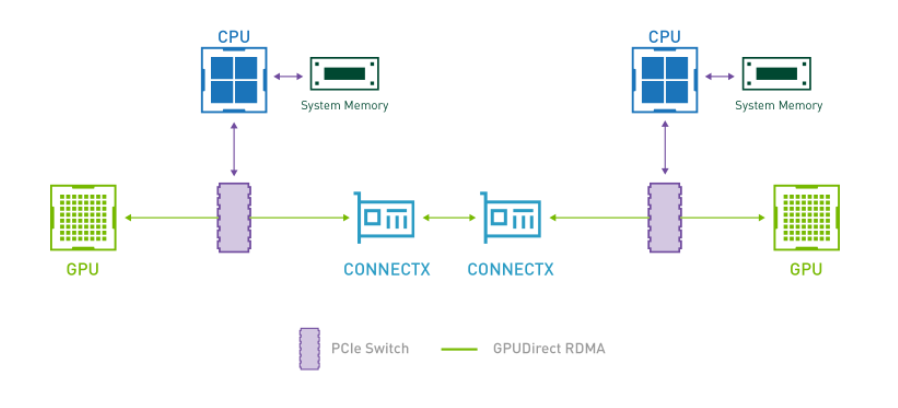
Figure 1: Direct Communication – GPUDirect RDMA
For more information, see:
System details
The following table provides the system details:
Table 1: System details
Component | Details |
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe |
Network adapters | Mellanox ConnectX-6 Dual port 100 GbE and 25 GbE |
Storage | Dell PowerScale |
ESXi version | 7.0.3 |
BIOS version | 1.1.3 |
GPU driver version | 470.82.01 |
CUDA Version | 11.4 |
Setup
The setup for multinode training in a virtualized environment is outlined in our previous blog.
At a high level, after Address Translation Services (ATS) is enabled on VMware ESXi, the VMs, and ConnectX-6 NIC:
- Enable mapping between logical and physical ports.
- Create a Docker container with Mellanox OFED drivers, Open MPI Library, and NVIDIA-optimized TensorFlow.
- Set up a keyless SSH login between VMs
Performance evaluation
For evaluation, we use tf_cnn_benchmarks using the ResNet50 model and synthetic data with a local batch size of 1024. Each VM is configured with 32 vCPUs, 64 GB of memory, and one NVIDIA A100 PCIE 80 GB GPU. The experiments are performed by using a data parallelism approach in a distributed training setup, scaling up to four nodes. The results are based on averaging three experiment runs. Single-node experiments are only for comparison as there is no internode communication.
Note: Use the ibdev2netdev utility to display the installed Mellanox ConnectX-6 card along with the mapping of ports. In the following figures, ON and OFF indicate if the mapping is enabled between logical and physical ports.
The following figure shows performance when scaling up to four nodes using Mellanox ConnectX-6 Dual Port 100 GbE. It is clear that the throughput increases significantly when the mapping is enabled (ON), providing direct communication between NVIDIA GPUs. The two-node experiments show an improvement in throughput of 18.7 percent while the four node experiments improve throughput by 26.7 percent.
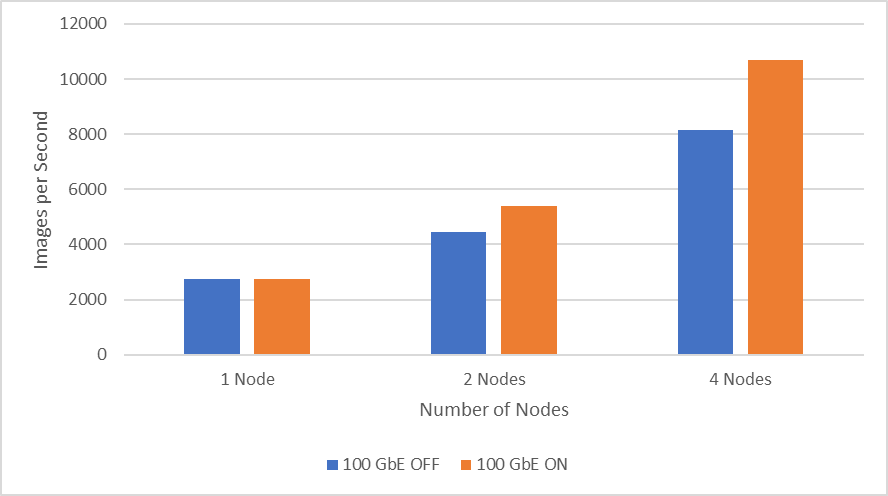
Figure 2: 100 GbE network performance
The following figure shows the scaling performance comparison between Mellanox ConnectX-6 Dual Port 100 GbE and Mellanox ConnectX-6 Dual Port 25 GbE while performing distributed training of the ResNet50 model. Using 100 GbE, two-node experiment results show an improved throughput of six percent while four-node experiments show an improved performance of 11.6 percent compared to 25 GbE.
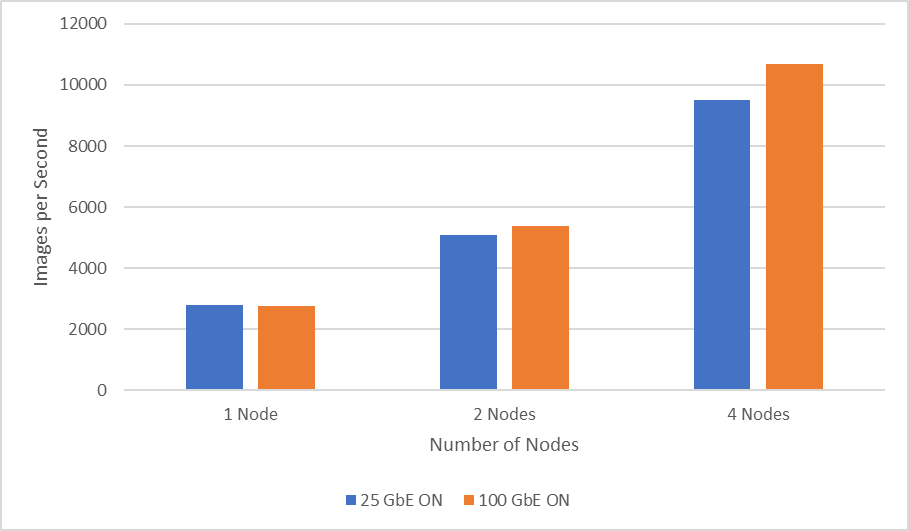
Figure 3: 25 GbE compared to 100 GbE network performance
Conclusion
In this blog, we considered GPUDirect RDMA and a few required steps to setup multinode experiments in the virtualized environment. The results showed that scaling to a larger number of nodes boosts throughput significantly when establishing direct communication between GPUs in a distributed training setup. The blog also showcased the performance comparison between Mellanox ConnectX-6 Dual Port 100 GbE and 25 GbE network adapters used for distributed training of a ResNet50 model.
Dell PowerEdge Servers Unleash Another Round of Excellent Results with MLPerf™ v4.0 Inference
Wed, 27 Mar 2024 15:12:53 -0000
|Read Time: 0 minutes
Today marks the unveiling of MLPerf v4.0 Inference results, which have emerged as an industry benchmark for AI systems. These benchmarks are responsible for assessing the system-level performance consisting of state-of-the-art hardware and software stacks. The benchmarking suite contains image classification, object detection, natural language processing, speech recognition, recommenders, medical image segmentation, LLM 6B and LLM 70B question answering, and text to image benchmarks that aim to replicate different deployment scenarios such as the data center and edge.
Dell Technologies is a founding member of MLCommons™ and has been actively making submissions since the inception of the Inference and Training benchmarks. See our MLPerf™ Inference v2.1 with NVIDIA GPU-Based Benchmarks on Dell PowerEdge Servers white paper that introduces the MLCommons Inference benchmark.
Our performance results are outstanding, serving as a clear indicator of our resolve to deliver outstanding system performance. These improvements enable higher system performance when it is most needed, for example, for demanding generative AI (GenAI) workloads.
What is new with Inference 4.0?
Inference 4.0 and Dell’s submission include the following:
- Newly introduced Llama 2 question answering and text to image stable diffusion benchmarks, and submission across different Dell PowerEdge XE platforms.
- Improved GPT-J (225 percent improvement) and DLRM-DCNv2 (100 percent improvement) performance. Improved throughput performance of the GPTJ and DLRM-DCNv2 workload means faster natural language processing tasks like summarization and faster relevant recommendations that allow a boost to revenue respectively.
- First-time submission of server results with the recently released PowerEdge R7615 and PowerEdge XR8620t servers with NVIDIA accelerators.
- Besides accelerator-based results, Intel-based CPU-only results.
- Results for PowerEdge servers with Qualcomm accelerators.
- Power results showing high performance/watt scores for the submissions.
- Virtualized results on Dell servers with Broadcom.
Overview of results
Dell Technologies delivered 187 data center, 28 data center power, 42 edge, and 24 edge power results. Some of the more impressive results were generated by our:
- Dell PowerEdge XE9680, XE9640, XE8640, and servers with NVIDIA H100 Tensor Core GPUs
- Dell PowerEdge R7515, R750xa, and R760xa servers with NVIDIA L40S and A100 Tensor Core GPUs
- Dell PowerEdge XR7620 and XR8620t servers with NVIDIA L4 Tensor Core GPUs
- Dell PowerEdge R760 server with Intel Emerald Rapids CPUs
- Dell PowerEdge R760 with Qualcomm QAIC100 Ultra accelerators
NVIDIA-based results include the following GPUs:
- Eight-way NVIDIA H100 GPU (SXM)
- Four-way NVIDIA H100 GPU (SXM)
- Four-way NVIDIA A100 GPU (PCIe)
- Four-way NVIDIA L40S GPU (PCIe)
- NVIDIA L4 GPU
These accelerators were benchmarked on different servers such as PowerEdge XE9680, XE8640, XE9640, R760xa, XR7620, and XR8620t servers across data center and edge suites.
Dell contributed to about 1/4th of the closed data center and edge submissions. The large number of result choices offers end users an opportunity to make data-driven purchase decisions and set performance and data center design expectations.
Interesting Dell data points
The most interesting data points include:
- Performance results across different benchmarks are excellent and show that Dell servers meet the increasing need to serve different workload types.
- Among 20 submitters, Dell Technologies was one of the few companies that covered all benchmarks in the closed division for data center suites.
- The PowerEdge XE8640 and PowerEdge XE9640 servers compared to other four-way systems procured winning titles across all the benchmarks including the newly launched stable diffusion and Llama 2 benchmark.
- The PowerEdge XE9680 server compared to other eight-way systems procured several winning titles for benchmarks such as ResNet Server, 3D-Unet, BERT-99, and BERT-99.9 Server.
- The PowerEdge XE9680 server delivers the highest performance/watt compared to other submitters with 8-way NVIDIA H100 GPUs for ResNet Server, GPTJ Server, and Llama 2 Offline
- The Dell XR8620t server for edge benchmarks with NVIDIA L4 GPUs outperformed other submissions.
- The PowerEdge R750xa server with NVIDIA A100 PCIe GPUs outperformed other submissions on the ResNet, RetinaNet, 3D-Unet, RNN-T, BERT 99.9, and BERT 99 benchmarks.
- The PowerEdge R760xa server with NVIDIA L40S GPUs outperformed other submissions on the ResNet Server, RetinaNet Server, RetinaNet Offline, 3D-UNet 99, RNN-T, BERT-99, BERT-99.9, DLRM-v2-99, DLRM-v2-99.9, GPTJ-99, GPTJ-99.9, Stable Diffusion XL Server, and Stable Diffusion XL Offline benchmarks.
Highlights
The following figure shows the different Offline and Server performance scenarios in the data center suite. These results provide an overview; follow-up blogs will provide more details about the results.
The following figure shows that these servers delivered excellent performance for all models in the benchmark such as ResNet, RetinaNet, 3D-UNet, RNN-T, BERT, DLRM-v2, GPT-J, Stable Diffusion XL, and Llama 2. Note that different benchmarks operate on varied scales. They have all been showcased in an exponentially scaled y-axis in the following figure:
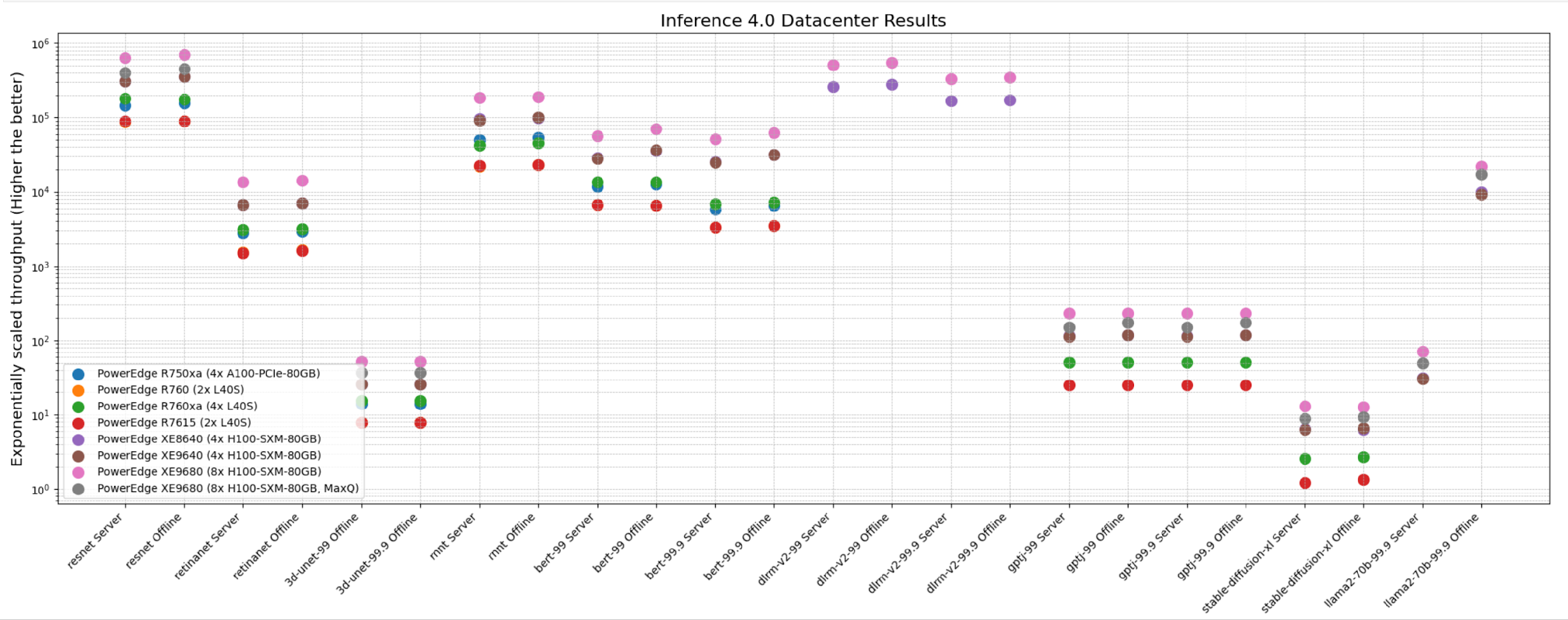
Figure 1: System throughput for submitted systems for the data center suite.
The following figure shows single-stream and multistream scenario results for the edge for ResNet, RetinaNet, 3D-Unet, RNN-T, BERT 99, GPTJ, and Stable Diffusion XL benchmarks. The lower the latency, the better the results and for Offline scenario, higher the better.
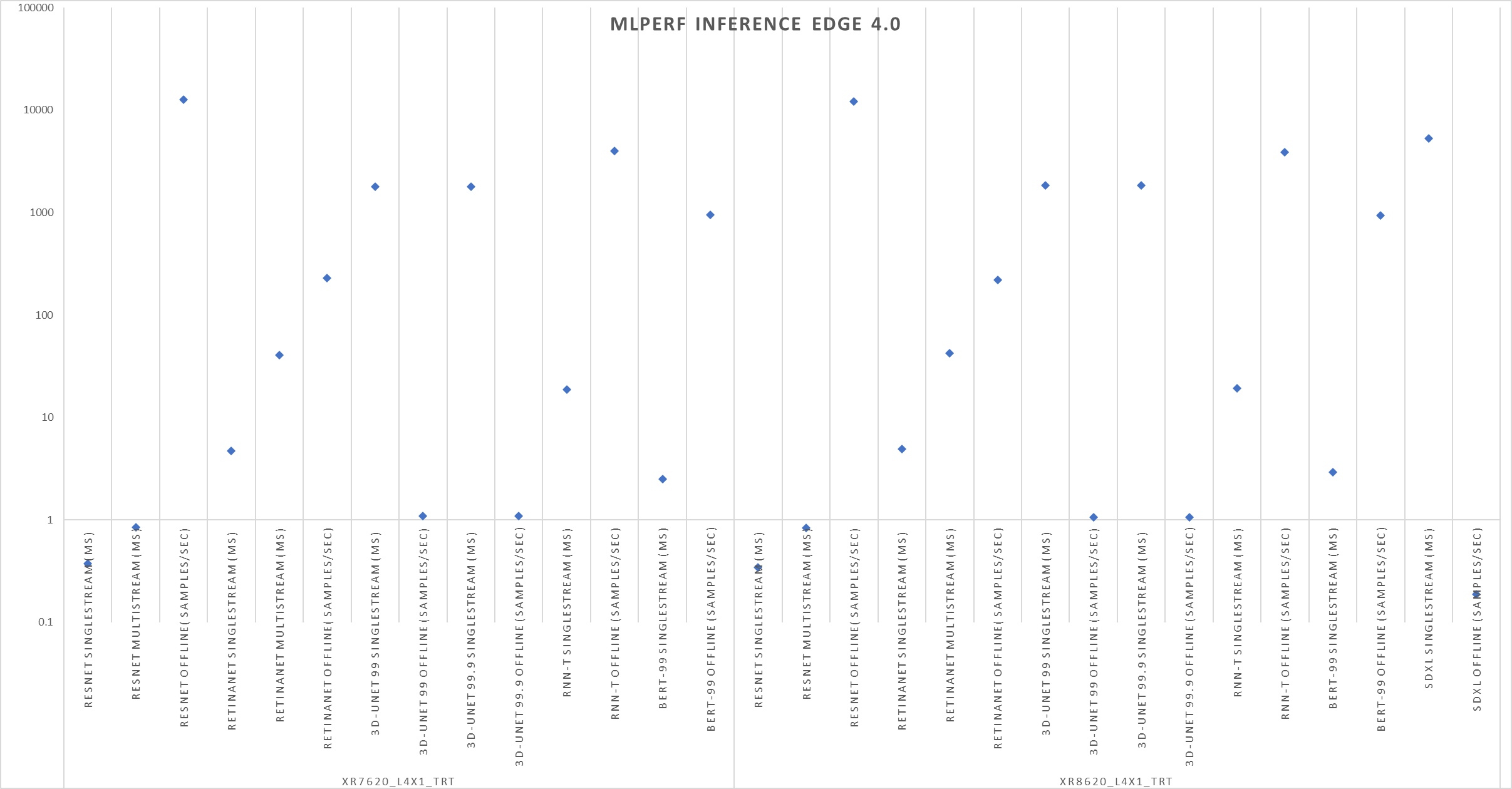
Figure 2: Edge results with PowerEdge XR7620 and XR8620t servers overview
Conclusion
The preceding results were officially submitted to MLCommons. They are MLPerf-compliant results for the Inference v4.0 benchmark across various benchmarks and suites for all the tasks in the benchmark such as image classification, object detection, natural language processing, speech recognition, recommenders, medical image segmentation, LLM 6B and LLM 70B question answering, and text to image. These results prove that Dell PowerEdge XE9680, XE8640, XE9640, and R760xa servers are capable of delivering high performance for inference workloads. Dell Technologies secured several #1 titles that make Dell PowerEdge servers an excellent choice for data center and edge inference deployments. End users can benefit from the plethora of submissions that help make server performance and sizing decisions, which ultimately deliver enterprises’ AI transformation and shows Dell’s commitment to deliver higher performance.
MLCommons Results
https://mlcommons.org/en/inference-datacenter-40/
https://mlcommons.org/en/inference-edge-40/
The preceding graphs are MLCommons results for MLPerf IDs from 4.0-0025 to 4.0-0035 on the closed datacenter, 4.0-0036 to 4.0-0038 on the closed edge, 4.0-0033 in the closed datacenter power, and 4.0-0037 in closed edge power.