




Accelerate Your Journey to AI Success with MLOps and AutoML
Tue, 07 Feb 2023 22:05:15 -0000
|Read Time: 0 minutes
Artifical Intelligence (AI) and Machine Learning (ML) helps organizations make intelligent data driven business decisions and are critical components to help businesses thrive in a digitally transforming world. While the total annual corporate AI investment has increased substantially since 2019, many organizations are still experiencing barriers to successfully adopt AI. Organizations move along the AI and analytics maturity curve at different rates. Automation methodologies such as Machine Learning Operations (MLOps) and Automatic Machine Learning (AutoML) can serve as the backbone for tools and processes that allow organizations to experiment and deploy models with the speed and scale of a highly efficient, AI-first enterprise. MLOps and AutoML are associated with distinct and important components of AI/ML work streams. This blog introduces how software platfoms like cnvrg.io and H2O Driverless AI make it easy for organizations to adopt these automation methodologies into their AI environment.
This blog is intended to serve as a reference for Dell’s position on MLOps solutions that help organizations scale their AI and ML practices. MLOps and AutoML provide a powerful combination that brings business value out of AI projects quicker and in a secure and scalable way. Dell Validated Designs provides the Reference Architecture that combines the software and Dell hardware to bring these solutions to life.
Importance of automation methodologies
Deploying models to a production environment is an important component to getting the most business value from an AI/ML project. While there are numerous tasks to get a project into production, from Exploratory Data Analysis to model training and tuning, successfully deployed models require additional sets of tasks and procedures, such as runtime model management, model observability and retraining, and inferencing reliability and cost optimization. The lifeycle of a AI/ML project involves disciplines of data engineering, data science, DevOps engineering and roles with differing skillsets across these teams. With all the steps listed above for just a single AI/ML project, it’s not difficult to see the challenges organizations have when faced with wanting to rapidly grow the number of projects across different business units within the organization. Organizations that prioritize ROI, consistency, reusability, traceability, reliability and automation in their AI/ML projects through sets of procedures and tools described in this paper are set up to scale in AI and meet the demand of AI for its business.
Components of an AI/ML project
A typical AI/ML project has many distinct tasks which can flow in a cascading, yet circular manner. This means that while tasks may have dependencies on completion of previous tasks, the continuous learning nature of ML projects create an iterative feedback loop throughout the project.
The following list describes steps that a typical AI/ML project will run through.
- Objective Specification
- Exploratory Data Analysis (EDA)
- Model Training
- Model Implementation
- Model Optimization and Cross Validation
- Testing
- Model Deployment
- Inference
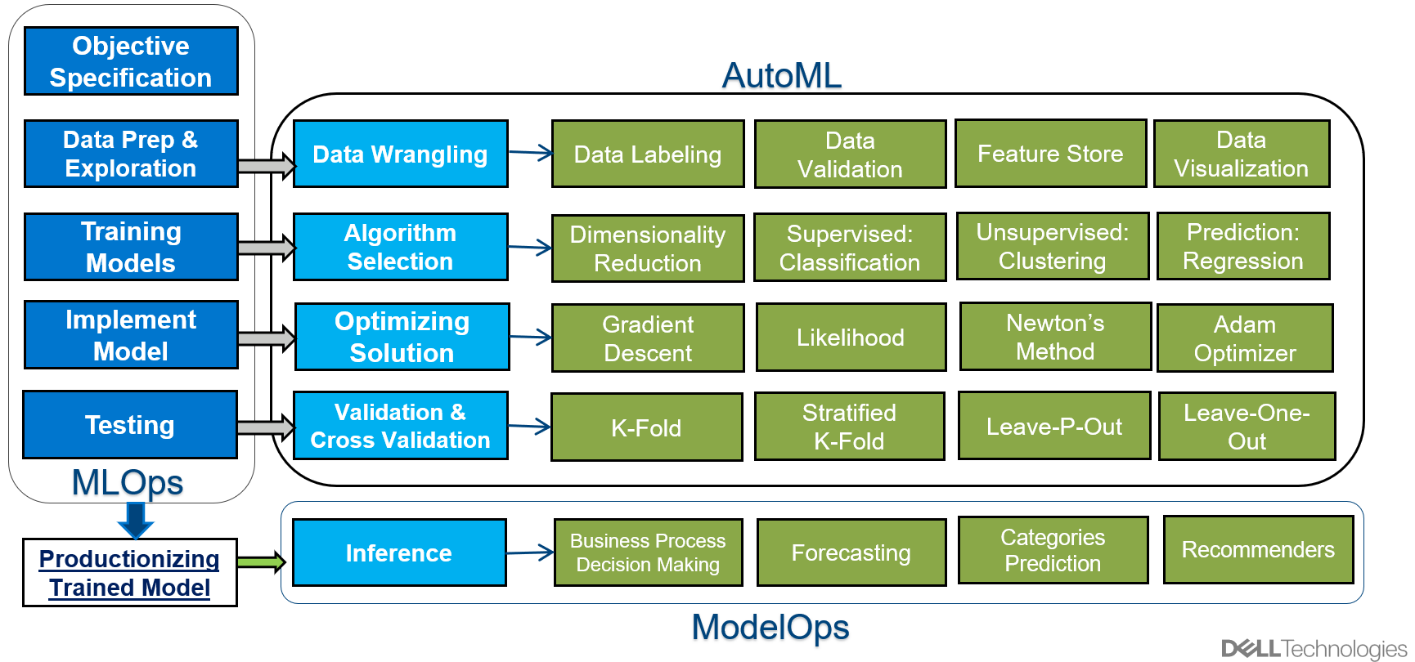
Figure 1. Distinct Tasks in an AI/ML Project
Each task serves an important role in the project and can be grouped at a high level by defining the problem statement, the data and modeling work, and productionizing the final model for inference. Because these groups of tasks have different objectives, there are different automation methodologies that have been developed to streamline and scale projects. The concept of Automated Machine Learning (AutoML) was developed to make the data and modeling work as efficient as possible. AutoML is a set of proven and optimized solutions in data modeling. The practice of ModelOps was developed to deploy models faster and more scalable. While AutoML and ModelOps automate specific tasks within a project, the practice of MLOps serves as an umbrella automation methodology that contains guiding principles for all AI/ML projects.
MLOpsThe key to navigating the challenges of inconsistent data, labor constraints, model complexity, and model deployment to operate efficiently and maximize the business value of AI is through the adoption of MLOps. MLOps, at a high level, is the practice of applying software engineering principles of Continuous Improvement and Continuous Delivery (CI/CD) to Machine Learning projects. It is a set of practices that provide the framework for consistencty and reusability that leads to quicker model deployments and scalability.
MLOps tools are the software based applications that help organizations put the MLOps principles into practice in an automated fashion.
The complexities stemming from ever-changing business environments that affect underlying data, inference needs, etc mean that MLOps in AI/ML projects need to have quicker iteratons than typical DevOps software projects.
AutoML
At the heart of a AI/ML project is the quest for business insights, and the tasks that lead to these insights can be done at a scalable and efficient manner with AutoML. AutoML is the process of automating exploratory data analysis (EDA), algorithm selection, training and optimizations of models.
AutoML tools are low-code or no-code platforms that begin with the ingestion of data. Summary statistics, data visualizations, outlier detection, feature interaction, and other tasks associated with EDA are then automatically completed. For model training, AutoML tools can detect what type of algorthms are appopriate for the data and business question and proceed to test each model. AutoML also itierates over hundreds of versions of the models by tweaking the parameters to find the optimal settings. After cross-validation and further testing of the model, a model package is created which includes the data transformations and scoring pipelines for easy deployment into a production environment.
ModelOps
Oncea trained model is ready for deployment in a production environment, a whole new set of tasks and processes begin. ModelOps is the set of practices and processes that support fast and scalable deployment of models to production. Model performance degrades over time for reasons such as underlying trends in the data changing or introduction of new data, so models need to be monitored closely and be updated to keep peak business value throughout its lifecycle.
Model monitoring and management are key components of ModelOps, but there are many other aspects to consider as part of a ModelOps strategy. Managing infrastructure for proper resource allocation (e.g how and when to include accelerators), automatic model re-training in near real time, and integrating with advanced network sevurity solutions, versioning, and migration are other elements that must be considered when thinking about scaling an AI environment.
Dell solution for automation methodologies
Dell offers solutions that bring together the infrastructure and software partnerships to capitalize on the benefits of AutoML, MLOps and ModelOps. Through jointly engineered and tested solutions with Dell Validated Designs, organizations can provide their AI/ML teams with predictable and configurable ML environments and with their operational AI goals.
Dell has partnered with cnvrg.io and H2O to provide the software platforms to pair with the compute, storage, and networking infrastructure from Dell to complete the AI/ML solutions.
MLOps – cnvrg.io
cnvrg.io is a machine learning platform built by data scientists that makes implementation of MLOps and the process of taking models from experimentation to deployment efficient and scalable. cnvrg.io provides the platform to manage all aspects of the ML life cycle, from data pipelines, to experimentation, to model deployment. It is a Kubernetes-based application that allows users to work in any compute environment, whether it be in the cloud or on-premises and have access to any programming language.
The management layer of cnvrg.io is powered by a control plane that leverages Kubernetes to manage the containers and pods that are needed to orchestrate the tasks of a project. Users can view the state and health and resource statistics of the environment and each task using the cnvrg.io dashboard.
cnvrg.io makes it easy to access the algorithms and data components, whether they are pre-trained models or models built from scratch, with Git interaction through the AI Library. Data pre-processing logic or any customized models can be stored and implemented for tasks across any project by using the drag-and-drop interface for end-to-end management called cnvrg.io Pipelines.
The orchestration and scheduling features use Kubernetes-based meta-scheduler, which makes jobs portable across environments and can scale resources up or down on demand. Cnvrg.io facilitates job scheduling across clusters in the cloud and on-premises to navigate through resource contention and bottlenecks. The ability to intelligently deploy and manage compute resources, from CPU, GPU, and other specialized AI accelerators to the tasks where they can be best used is important to achieving operational goals in AI.
cnvrg.io solution architecture
The cnvrg.io software can be installed directly on your data center, or it can be accessed through the cnvrg.io Metacloud offering. Both versions allow users to configure the organization’s own infrastructure into compute templates. For installations into an on-premises data center, cnvrg.io can be deployed on various Kubernetes infrastructures, including bare metal, but the Dell Validated Design for AI uses VMware and NVIDIA to provide a powerful combination of composability and performance.
Dell’s PowerEdge servers that can be equipped with NVIDIA GPUs provide the compute resources required to run any algorithm in machine learning packages like scikit learn to deep learning algorithms in frameworks like TensorFlow and PyTorch. For storage, Dell’s PowerScale appliance with all-flash, scale out NAS storage deliver the concurrency performance to support data heavy neural networks. VMware vSphere with Tanzu allows for the Tanzu Kubernetes clusters, which are managed by Tanzu Mission Control. The servers running VMware vSAN provide a storage repository for the VM and pods. PowerSwitch network switches with a 25 GbE-based design or 100 GbE-based design allow for neural network training jobs than can run on a single node. Finally, the NVIDIA AI Enterprise comes with the software support for GPUs such as fractionalizing GPU resources with the MIG capability.
Dell provides recommendations for sizing of the different worker node configurations, such as the number of CPUs/GPUs and amount of memory, that users can deploy for the various types of algorithms different AI/ML projects may use.
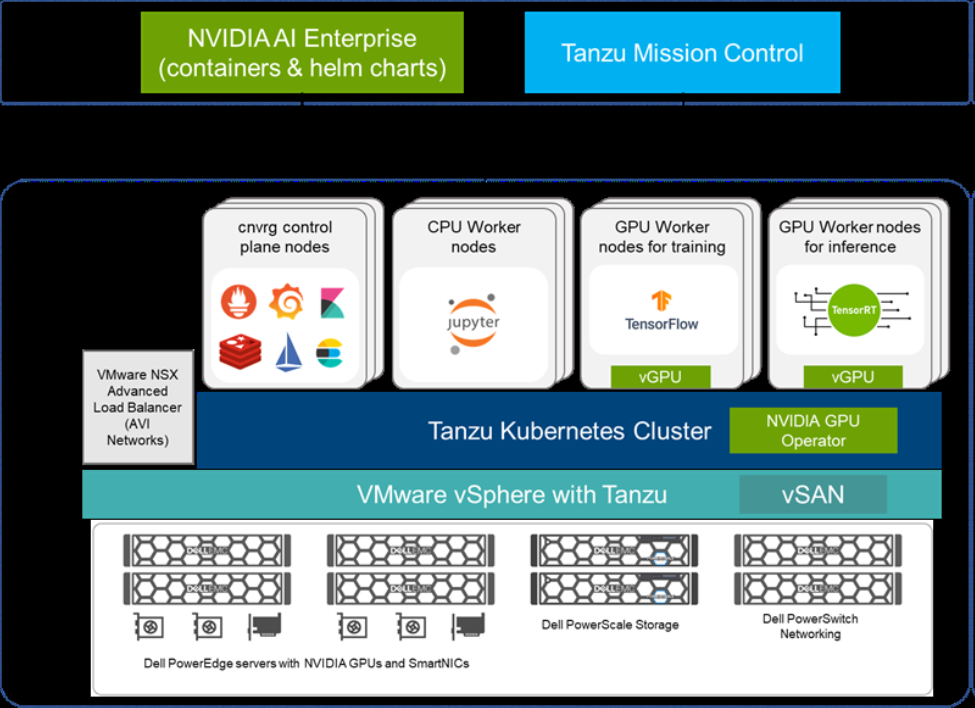
Figure 2. Dell/cnvrg.io Solution Architecture
For more information, see the Design Guide—Optimize Machine Learning Through MLOps with Dell Technologies cnvrg.io.
AutoML – H2O.ai Driverless AI
Dell has partnered with H2O and its flagship product, Driverless AI, to give organizations a comprehensive AutoML platform to empower both data scientists and non-technical folks to unlock insights efficiently and effectively. Driverless AI has several features that help optimize the model development portion of an AI/ML workflow, from data ingestion to model selection, as organizations look to gain faster and higher quality insights to business stakeholders. It is a true no-code solution with a drag and drop type interface that opens the door for citizen data scientists.
Starting with data ingestion, Driverless AI can connect to datasets in various formats and file systems, no matter where the data resides, from on-premises to a clould provider. Once ingested, Driverless AI runs EDA, provides data visualization, outlier detection, and summary statistics on your data. The tool also automatically suggests data transformations based on the shape of your data and performs a comprehensive feature engineering process that search for high-value predictors against the target variable. A summary of the auto-created features is displayed in an easy to digest dashboard.
For model development, Driverless AI automatically trains multiple in-built models, with numerous iterations for hyper parameter tuning. The tool applies a genetic algorithm that creates an ensemble, ‘survival of the fittest’ final model. The user also has the ability to set the priority on factors of accuracy, time, and interpretability. If the user wishes to arrive at a model that needs to be presented to a less technical busines audience, for example, the tool will focus on algorithms that have more explainable features rather than black box type models that may achieve better accuracy with a longer training time. While the Driverless AI tool may be run as a no-code solution, the bring your own recipe feature empowers more seasoned data scientists to bring custom data transformations and algorithms into the tools as part of the experimenting process.
The final output of Driverless AI, after a champion model is crowned, will include a scoring pipeline file that makes it easy to deploy to a production environment for inference. The scoring pipeline can be saved in Python or a MOJO and includes components like data transformations, scripts, runtime, etc.
Driverless AI solution architecture
The H2O Driverless AI platform can be deployed either in Kubernetes as pods or as a stand-alone container. The Dell Validated Design of Driverless AI highlights the flexibility VMware vSphere with Tanzu for the Kubernetes layer works with H2O’s Enterprise Steam to provide resource control and monitoring, access control, and security out of the box.
Dell PowerEdge servers, with optional NVIDIA GPUs, and the NVIDIA AI Enterprise make building containers easy for different sets of users. For use cases that are heavy on EDA or employ traditional machine learning algorithms, Driverless AI containers with CPUs only may be appropriate, while containers with GPUs are best suited for training deep learning models usually associated with natural language processing and computer vision. Dell PowerScale storage and Dell PowerSwitch network adapters provide concurrency at scale to train the data intensive algorithms found within Driverless AI.
Dell provides sizing deployments recommendations specific to an organization’s requirements and capabilities. For organizations starting their AI journey, a deployment with 5 Driverless AI instances, 40 CPU cores, 3.2 TB of memory, and 5 TB storage is recommended for workloads and projects that perform classic machine learning or statistical modeling. For a mainstream deployment with more users and heavier workloads that would benefit from GPU acceleration, 10 Driverless AI instances with 100 CPU cores and 5 NVIDIA A100 GPUs, 8 TB of memory, and 10 TB of storage is recommended. Finally, for high performance deployments for organizations that want to deploy AI models at scale, 20 Driverless AI instances, 200 CPU cores and 10 A100 GPUs, 16 TB of memory, and 20 TB of storage provides the infrastructure for a full-service AI environment.
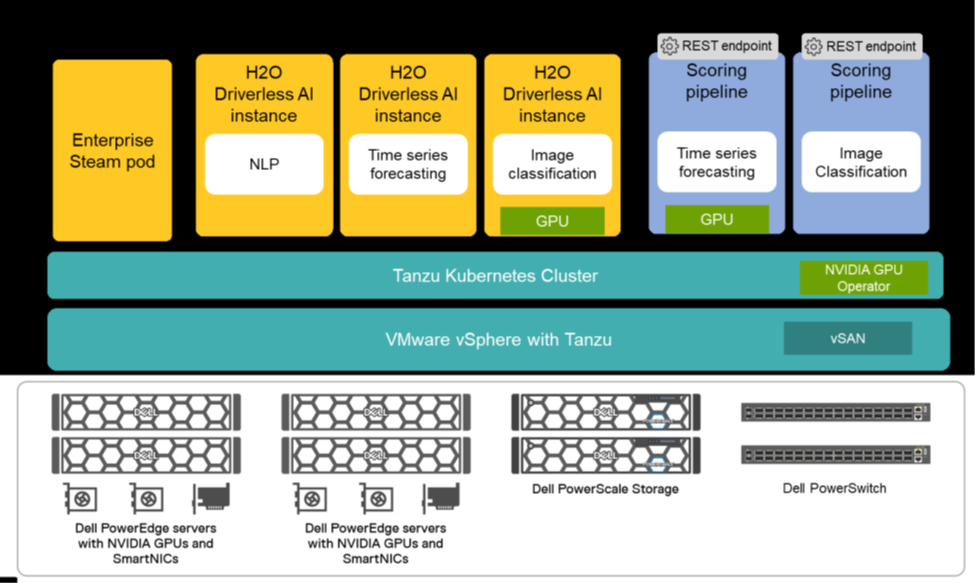
Figure 3. Dell/H2O Driverless AI Solution Architecture
For more information, see Automate Machine Learning with H2O Driverless AI.
Dell is your partner in your AI Journey
AI is constantly evolving, and many organizations do not have the AI expertise to keep up with designing, developing, deploying, and managing solution stacks at the competitive pace. Dell Technologies is your trusted partner and offers solutions that empower your organization in its AI journey. For over the past decade, Dell has been a proven leader in the advanced computing space that includes industry leading products, solutions, and expertise. We have a specialized team of AI, High Performance Computing (HPC), and Data Analytics experts dedicated to helping you keep pace on your AI journey.
AI Professional Services
Regardless of your AI needs, you can rest assured that your deployments will be backed up by Dell’s world class technology services. Our expert consulting services for AI help you plan, implement, and optimize AI solutions, while more than 35,000 services experts can meet you where you are on your AI journey.
- Consulting Services
- Deployment Services
- Support Services
- Payment Solutions
- Managed Services
- Residency Services
Customer Solution Center
The Customer Solution Center is a team of experienced professionals equipped to provide expert advice, recommendations, and demonstrations of the cutting-edge technologies and platforms essential for successful AI implementation. Our staff maintains a thorough understanding of the diverse needs and challenges of our customers and offers valuable insights garnered from extensive engagement with a broad range of clients. By leveraging our extensive knowledge and expertise, you gain a competitive advantage in your pursuit of AI solutions.
AI and HPC Innovation Lab
The AI and HPC Innovation Lab is a premier infrastructure, equipped with a highly skilled team of computer scientists, engineers, and Ph.D. level experts. This team actively engages with customers and members of the AI and HPC community, fostering partnerships and collaborations to drive innovation. With early access to cutting-edge technologies, the Lab is equipped to integrate and optimize clusters, benchmark applications, establish best practices, and publish insightful white papers. By working directly with Dell's subject matter experts, customers can expect tailored solutions for their specific AI and HPC requirements.
Conclusion
MLOps and AutoML play a critical role in fostering the successful integration of AI/ML into organizations. MLOps provides a standardized framework for ensuring consistency, reusability, and scalability in AI/ML initiatives, while AutoML streamlines the data and modeling process. This synergistic approach enables organizations to make data-driven decisions and derive maximum business value from their AI/ML endeavors. Dell Validated Designs offer a blueprint for implementing MLOps, thereby bringing these concepts to fruition. The dynamic nature of AI/ML projects necessitates rapid iterations and automation to tackle challenges such as data inconsistency and resource limitations. MLOps and AutoML serve as crucial enablers in driving digital transformation and establishing an AI-centric enterprise.
Related Blog Posts

PowerProtect Data Manager Deployment Automation – Deploy PowerProtect Data Manager in Minutes
Mon, 18 Sep 2023 22:34:52 -0000
|Read Time: 0 minutes
In the spirit of automating EVERYTHING, this blog will showcase the complete deployment of PowerProtect Data Manager (PPDM).
In the PPDM universe, we have auto-policy creation and ad-hoc VM backup solutions, use-case driven tasks, and so on -- all available in the official PowerProtect Data Manager GitHub repository. And now, I am proud to present to you the complete PPDM deployment automation solution.
Without further ado, let’s get started.
What does the solution do?
The PowerProtect Data Manager automated deployment solution boasts a wide array of functionality, including:
- Automatically provisioning PPDM from OVA
- Automatically deploying and configuring PPDM based on a JSON configuration file
- Adding PowerProtect DD (optional)
- Registering vCenter (optional)
- Registering remote PPDM systems (optional)
- Configuring bi-directional replication between two PPDM systems (optional)
What is the solution?
It’s a Python-based script that operates in conjunction with the PPDM REST API and vCenter.
Here is the list of prerequisites:
- Python 3.x (The script supports every platform Python is supported on)
- Python requests module, which can be installed using pip with the command: “pip install requests” or “python -m pip install requests”
- PowerProtect Data Manager 19.14 and later
- Connectivity from the host running the script to vCenter and PPDM
- PowerProtect Data Manager OVA image located on the host that is running the script
- Ovftool installed on the same host the script is running on
- Connectivity to remote PPDM system from the host running the script (only if the -ppdm parameter is provided)
How do I use the script?
The script accepts one mandatory parameter, -configfile or --config-file, and six optional parameters:
- (1) justova to deploy only the PPDM OVA or (2) skipova to skip OVA deployment
- (3) vc and (4) dd to register vCenter and PowerProtect DD respectively
- (5) ppdm and (6) cross to configure a remote PPDM system and bi-directional communication between the two PPDM systems respectively
- -cross / --bi-directional requires the argument -ppdm / --connect-ppdm to be specified as well
Here is the full script syntax:
# ppdm_deploy.py -h
usage: ppdm_deploy.py [-h] -configfile CONFIGFILE [-skipova] [-justova] [-vc] [-dd] [-ppdm] [-cross]
Script to automate PowerProtect Data Manager deployment
options:
-h, --help show this help message and exit
-configfile CONFIGFILE, --config-file CONFIGFILE
Full path to the JSON config file
-skipova, --skip-ova Optionally skips OVA deployment
-justova, --just-ova Optionally stops after OVA deployment
-vc, --register-vcenter
Optionally registers vCenter in PPDM
-dd, --add-dd Optionally adds PowerProtect DD to PPDM
-ppdm, --connect-ppdm
Optionally connects remote PPDM system
-cross, --bi-directional
Optionally configures bi-directional communication between the two PPDM hosts
Use Cases
Let’s look at some common use cases for PPDM deployment:
1. Greenfield deployment of PPDM including registration of PowerProtect DD and vCenter:
# python ppdm_deploy.py -configfile ppdm_prod.json -vc -dd2. PPDM deployment including registration of vCenter and DD as well as a remote PPDM system:
# python ppdm_deploy.py -configfile ppdm_prod.json -vc -dd -ppdm3. Full deployment of two PPDM systems including configuration of the remote PPDM systems for bi-directional communication.
In this case, we would run the script twice in the following manner:
# python ppdm_deploy.py -configfile ppdm_siteA.json -vc -dd -ppdm -cross# python ppdm_deploy.py -configfile ppdm_siteB.json -vc -dd
4. In case of evaluation or test purposes, the script can stop right after the PPDM OVA deployment:
# python ppdm_deploy.py -configfile ppdm_test.json -justova5. In case of PPDM implementation where deployment needs to take place based on an existing PPDM VM or former OVA deployment:
# python ppdm_deploy.py -configfile ppdm_prod.json -skipova
Script output
# python ppdm_deploy.py -configfile ppdm_prod.json -vc -dd -ppdm -cross
-> Provisioning PPDM from OVA
Opening OVA source: C:\Users\idan\Downloads\dellemc-ppdm-sw-19.14.0-20.ova
Opening VI target: vi://idan%40vsphere.local@vcenter.hop.lab.dell.com:443/ProdDC/host/DC_HA1/
Deploying to VI: vi://idan%40vsphere.local@vcenter.hop.lab.dell.com:443/ProdDC/host/DC_HA1/
Transfer Completed
Powering on VM: PPDM_Prod_36
Task Completed
Completed successfully
---> OVA deployment completed successfully
-> Checking connectivity to PPDM
---> PPDM IP 10.0.0.36 is reachable
-> Checking PPDM API readiness
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is available
-> Obtaining PPDM configuration information
---> PPDM is deployment ready
-> Accepting PPDM EULA
---> PPDM EULA accepted
-> Applying license
-> Using Capacity license
-> Applying SMTP settings
-> Configuring encryption
-> Building PPDM deployment configuration
-> Time zone detected: Asia/Jerusalem
-> Name resolution completed successfully
-> Deploying PPDM
---> Deploying configuration 848a68bb-bd8e-4f91-8a63-f23cd079c905
---> Deployment status PROGRESS 2%
---> Deployment status PROGRESS 16%
---> Deployment status PROGRESS 20%
---> Deployment status PROGRESS 28%
---> Deployment status PROGRESS 28%
---> Deployment status PROGRESS 28%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 36%
---> Deployment status PROGRESS 40%
---> Deployment status PROGRESS 40%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 56%
---> Deployment status PROGRESS 56%
---> Deployment status PROGRESS 56%
---> Deployment status PROGRESS 60%
---> Deployment status PROGRESS 60%
---> Deployment status PROGRESS 72%
---> Deployment status PROGRESS 76%
---> Deployment status PROGRESS 76%
---> Deployment status PROGRESS 80%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status SUCCESS 100%
-> PPDM deployed successfully
-> Initiating post-install tasks
-> Accepting TELEMETRY EULA
---> TELEMETRY EULA accepted
-> AutoSupport configured successfully
-> vCenter registered successfully
--> Hosting vCenter configured successfully
-> PowerProtect DD registered successfully
-> Connecting peer PPDM host
---> Monitoring activity ID 01941a19-ce75-4227-9057-03f60eb78b38
---> Activity status RUNNING 0%
---> Activity status COMPLETED 100%
---> Peer PPDM registered successfully
-> Configuring bi-directional replication direction
---> Monitoring activity ID 8464f126-4f28-4799-9e25-37fe752d54cf
---> Activity status RUNNING 0%
---> Activity status COMPLETED 100%
---> Peer PPDM registered successfully
-> All tasks have been completed
Where can I find it?
You can find the script and the config file in the official PowerProtect GitHub repository:
https://github.com/dell/powerprotect-data-manager
Resources
Other than the official PPDM repo on GitHub, developer.dell.com provides comprehensive online API documentation, including the PPDM REST API.
How can I get help?
For additional support, you are more than welcome to raise an issue in GitHub or reach out to me by email:
Thanks for reading!
Idan
Author: Idan Kentor

RecoverPoint for VMs Automation – Advanced VM Protection
Wed, 21 Feb 2024 21:39:22 -0000
|Read Time: 0 minutes
In the spirit of automating everything, this blog will discuss a new automation solution in the RecoverPoint for VMs (RP4VMs) collection of automation solutions.
We have a variety of automation solutions for RP4VMs, including per-tag and per-cluster VM protection and use-case driven tasks, as well as a complete deployment automation solution. Now, I would like to present a new automation solution – Advanced VM Protection.
Let’s take a closer look at this exciting new solution.
What does the solution do?
The RecoverPoint for VMs advanced VM protection solution automates VM protection in RP4VMs with a wide variety of options:
- Automates VM protection based on pre-defined parameters in a JSON configuration file:
- VM name
- RP4VMs cluster name
- Plugin server IP or FQDN
- vCenter user/password or path to credentials file
- Production journal capacity (GB)
- Replica journal capacity (GB)
- Required RPO (sec)
- Failover networks per vNIC
- Performs and monitors mass VM protection
- Protects VMs for a specific RP4VMs cluster (optional)
- Performs VM protection operations on a specific plugin server (optional)
- Includes an option to skip the monitoring of VM protection preparation tasks
- Configures failover networks on a per network adapter basis as a post-protection operation
What is the solution?
It is a Python-based script that exclusively leverages the RP4VMs REST API.
Here is the list of prerequisites:
- Python 3.x (The script supports every platform Python is supported on)
- Python requests module, which can be installed using pip with the command:
pip install requests or python -m pip install requests
- RP4VMs 5.3.x and later
- Connectivity from the host running the script to the RP4VMs plugin server(s), specifically on tcp port 443
How do I use the script?
The script accepts the following parameters:
- One mandatory parameter, file, for a full path to the JSON configuration file.
- The optional parameters, rpvmcluster and server, limit script execution only for VM protection on a specified RP4VMs cluster and/or plugin server accordingly.
- The no-monitor parameter skips monitors of VM protection preparation task.
Here is the full script syntax:
# python advprotectvm.py -h usage: advprotectvm.py [-h] -file CONFIG_FILE [-cl RPVM_CLUSTER] [-s SERVER] [-nmonitor] Scripts advanced VM Protection in RecoverPoint for VMs options: -h, --help show this help message and exit -file CONFIG_FILE, --vm-config-file CONFIG_FILE Path to VM config file -cl RPVM_CLUSTER, --rpvmcluster RPVM_CLUSTER Optionally specify the RP4VMs cluster -s SERVER, --server SERVER Optionally specify RP4VMs Plugin Server DNS/IP -nmonitor, --no-monitor Optionally prevents protection monitoring
Use Cases and Examples
Let’s look at some common use cases for RP4VMs automated advanced VM protection:
- RP4VMs mass VM protection for onboarding of a new application:
# python advprotectvm.py -file idan-vms.json
- Batch VM protection only for a specific RP4VMs cluster:
# python advprotectvm.py -file idan-vms.json -cl Tel-Aviv
- Mass VM protection for a specific vCenter/ plugin or onboarding of a new datacenter:
# python advprotectvm.py -file vms.json -s pluginserver.idan.dell.com
Script output
# python advprotectvm.py -file vms.json -> Protecting VM prodwebsrv1 ---> Protection of VM prodwebsrv1 initiated -> Protecting VM prodappsrv1 ---> Protection of VM prodappsrv1 initiated -> Protecting VM proddbsrv1 ---> Protection of VM proddbsrv1 initiated -> VM protection initiated, monitoring ---> Protection of VM: prodwebsrv1, Transaction: d6783e2d-55be-47db-a082-de1d251c2375, Status: RUNNING ---> Protection of VM: prodappsrv1, Transaction: 808ab022-e79a-4ad1-a633-cc86e17644f2, Status: RUNNING ---> Protection of VM: proddbsrv1, Transaction: c7895dce-f3e6-4e70-872e-9d0b104d6273, Status: RUNNING ---> Protection of VM: prodwebsrv1, Transaction: d6783e2d-55be-47db-a082-de1d251c2375, Status: RUNNING ---> Protection of VM: prodappsrv1, Transaction: 808ab022-e79a-4ad1-a633-cc86e17644f2, Status: RUNNING ---> Protection of VM: proddbsrv1, Transaction: c7895dce-f3e6-4e70-872e-9d0b104d6273, Status: RUNNING ---> Protection of VM: prodwebsrv1, Transaction: d6783e2d-55be-47db-a082-de1d251c2375, Status: RUNNING ---> Protection of VM: prodappsrv1, Transaction: 808ab022-e79a-4ad1-a633-cc86e17644f2, Status: RUNNING ---> Protection of VM: proddbsrv1, Transaction: c7895dce-f3e6-4e70-872e-9d0b104d6273, Status: RUNNING ---> Protection of VM: prodwebsrv1, Transaction: d6783e2d-55be-47db-a082-de1d251c2375, Status: COMPLETED ---> Protection of VM: prodappsrv1, Transaction: 808ab022-e79a-4ad1-a633-cc86e17644f2, Status: COMPLETED ---> Protection of VM: proddbsrv1, Transaction: c7895dce-f3e6-4e70-872e-9d0b104d6273, Status: COMPLETED -> Configuring failover networks ---> Skipping failover network config for VM: prodwebsrv1 ---> Failover networks config is not required for VM: prodappsrv1 ---> Failover network config is successful for VM: proddbsrv1
Where can I find it?
The script and the config file can be found on GitHub: https://github.com/IdanKen/Dell-EMC-RecoverPoint4VMs.
Resources
- The Dell developer site provides comprehensive online API documentation, including full API references, tutorials, and use cases for the RP4VMs REST API.
- The RP4VMs REST API offers self-documentation – Swagger UI running on the plugin server itself – https://{plugin-server}/ui
- RecoverPoint for VMs GitHub repository
- RecoverPoint for VMs 5.3 – New RESTful API Demo
How can I get help?
For additional support, you are more than welcome to raise an issue in GitHub or reach out to me by email: Idan.kentor@dell.com
Thanks for reading!
Idan
Author: Idan Kentor