
Architecture
Architecture
-
OneFS writable snapshots enable the creation and management of a space- and time-efficient, modifiable copy of a regular OneFS snapshot. As such, the snapshots present a writable copy of a source snapshot that is accessible at a directory path within the /ifs namespace. You can access and edit the snapshot through any of the cluster’s file and object protocols, including NFS, SMB, and S3.
The writable snapshot architecture provides an overlay to a read-only source snapshot. This overlay allows a cluster administrator to create a lightweight copy of a production dataset using a simple CLI command, and present and use it as a separate writable namespace.
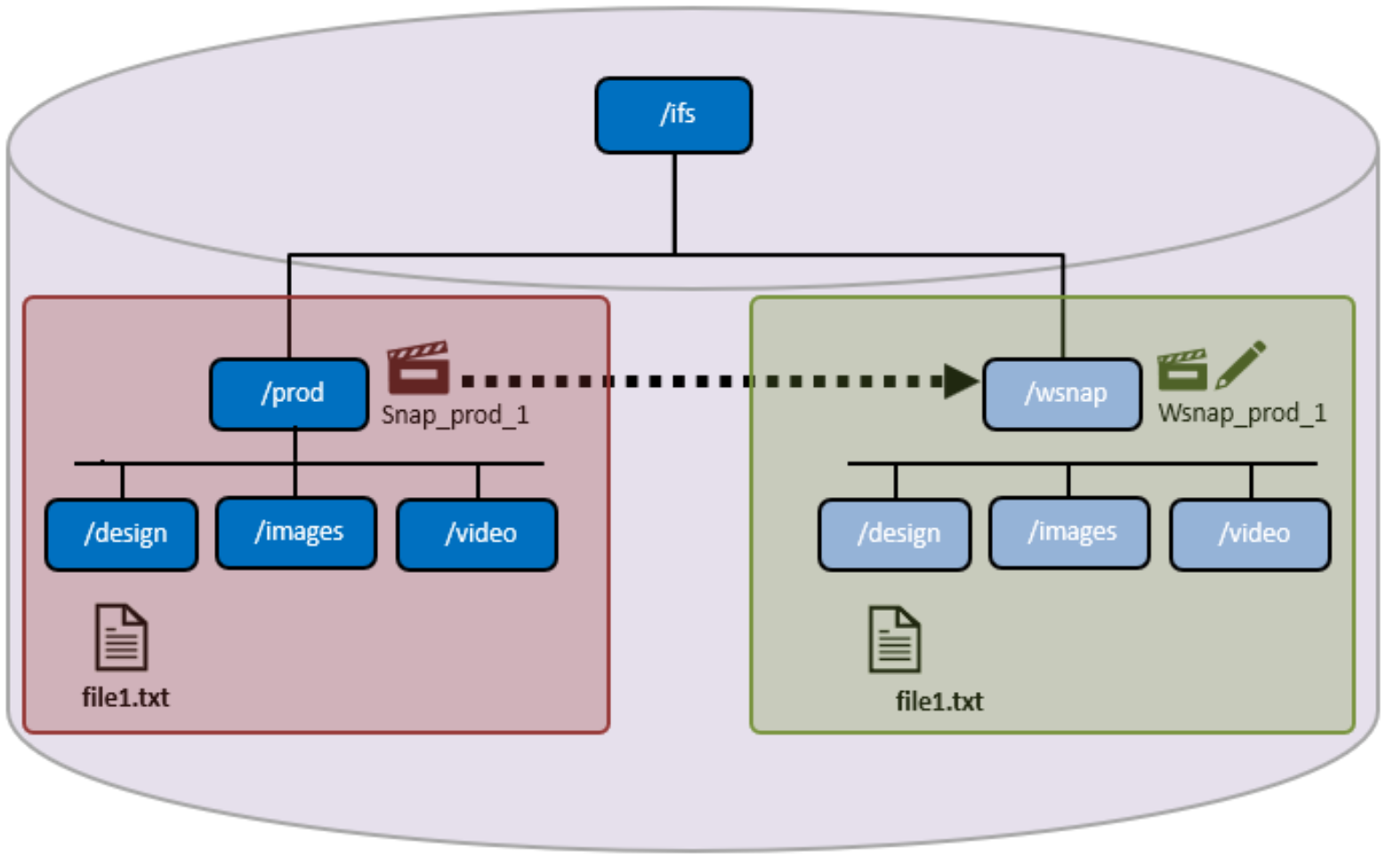
Figure 1. OneFS writable snapshot architecture
In the scenario above, a SnapshotIQ snapshot (snap_prod_1) is taken of the /ifs/prod directory. The read-only ‘snap_prod_1’ snapshot is then used as the backing for a writable snapshot created at /ifs/wsnap. This writable snapshot contains the same subdirectory and file structure as the original ‘prod’ directory, but without the added data capacity footprint.
Internally, OneFS 9.3 and later support a new protection group data structure, ‘PG_WSNAP’. This structure provides an overlay that allows unmodified file data to be read directly from the source snapshot, while storing only the changes in the writable snapshot tree.
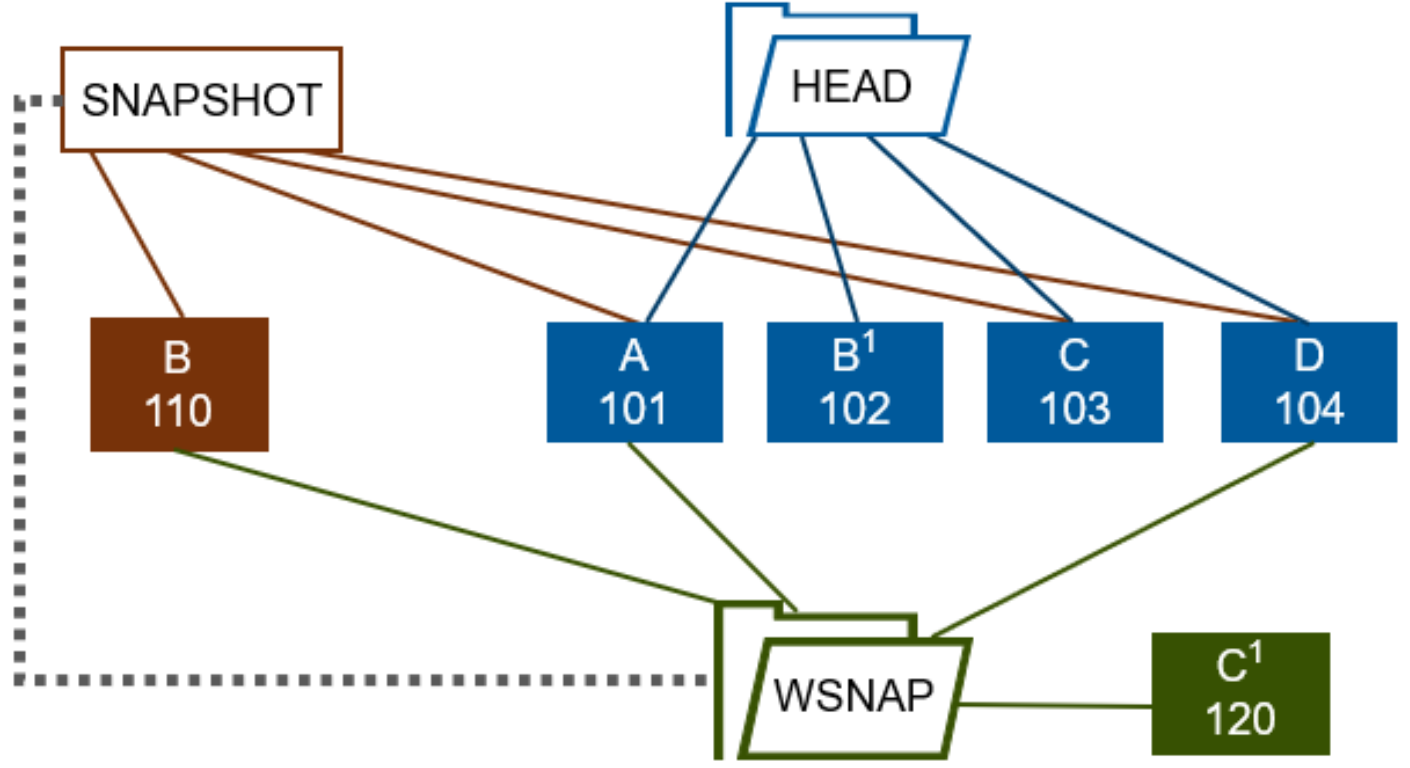
Figure 2. OneFS writable snapshot block overlay and redirection
In this example, a file (Head) consists of four data blocks, A through D. A read-only snapshot is taken of the directory containing the Head file. This file is then modified through a copy-on-write operation. As a result, the new Head data, B1, is written to block 102, and the original data block ‘B’ is copied to a new physical block (110). The snapshot pointer now references block 110 and the new location for the original data ‘B’, so the snapshot has its own copy of that block.
Next, a writable snapshot is created using the read-only snapshot as its source. This writable snapshot is then modified, so its updated version of block C is stored in its own protection group (PG_WSNAP). A client then issues a read request for the writable snapshot version of the file. This read request is directed, through the read-only snapshot, to the Head versions of blocks A and D, the read-only snapshot version for block B, and the writable snapshot file’s own version of block C (C1 in block 120).
OneFS directory quotas provide the writable snapshots accounting and reporting infrastructure, allowing users to easily view the space utilization of a writable snapshot. Also, IFS domains are also used to bound and manage writable snapshot membership. In OneFS, a domain defines a set of behaviors for a collection of files under a specified directory tree. If a directory has a protection domain applied to it, that domain will also affect all the files and subdirectories under that top-level directory.
When files within a newly created writable snapshot are first accessed, data is read from the source snapshot, populating the files’ metadata, in a process known as copy-on-read (CoR). Unmodified data is read from the source snapshot and any changes are stored in the writable snapshot’s namespace data structure (PG_WSNAP).
Since a new writable snapshot is not copy-on-read up front, its creation is extremely rapid. As files are accessed later, they are enumerated and begin to consume metadata space.
On accessing a writable snapshot file for the first time, a read is triggered from the source snapshot and the file’s data is accessed directly from the read-only snapshot. At this point, the MD5 checksums for both the source file and writable snapshot file are identical. If, for example, the first block of file is overwritten, only that single block is written to the writable snapshot. Then, the remaining unmodified blocks are still read from the source snapshot. At this point, the source and writable snapshot files are now different, so their MD5 checksums will also differ.