




What’s New with Data Mobility and Non-Disruptive Migration with Unisphere 10.1

Unisphere 10.1 and PowerMax OS 10.1 provide new features for consumers of our Data Mobility suite for array migrations on PowerMax. Data Mobility suite for PowerMax provides customers with a comprehensive set of tools for migrating workloads between Dell VMAX and PowerMax arrays non-disruptively with Non-Disruptively Migration (NDM) also with minimal disruption using Minimally Disruptive Migration (MDM) workflows, both NDM and MDM utilize SRDF technology to provide this functionality. For an in-depth look and walkthrough procedures, check out the white paper on the Info Hub: Dell PowerMax and VMAX: Non-Disruptive and Minimally Disruptive Migration Best Practices and Operational Guide.
With the 10.1 release of Unisphere for PowerMax and PowerMax OS 10.1, two new features provide new options for customers:
- Automatic cleanup of migrated resources on the source array
- Ability to migrate devices that are SRDF Metro supported, replacing one leg of the SRDF Metro configuration
Automatic clean up of the source array
Unisphere 10.1 and Solutions Enabler 10.1 provide a new cleanup operation that can be tagged to the commit of a Non-Disruptive Migration. This functionality helps to eliminate manual cleanup tasks for already migrated components on the source array. This feature is strictly orchestration in the management software stack, so all arrays that support Non-Disruptive Migration can use it.
You can specify the cleanup as part of the commit operation either with Unisphere or the symdm command with solutions enabler. The following figure shows the operation in the Unisphere Data Migration Wizard. (Note: there is no microcode requirement for this operation, It is a feature of the management software version 10.1 rather than of the array operating environment.)
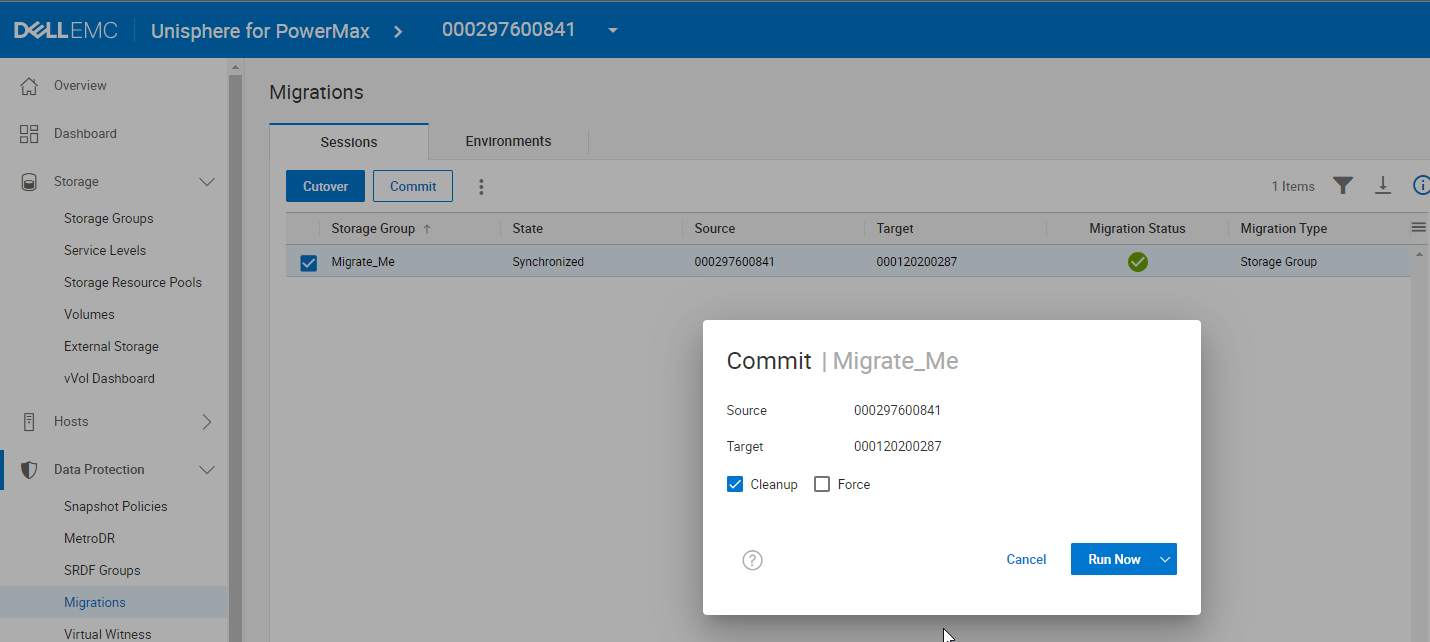
By selecting Cleanup, providing there are no gating factors, when the migration commit completes, the orchestration will delete:
- All snapshots including clone relationships on the devices. It will also unlink any linked snapshots.
- All Storage Groups that were migrated.
- All devices that were migrated.
- All Hosts/Initiator Groups and Port Groups that were migrated if they are not used by other masking views.
- Hosts/Initiator Groups will be removed from any parents before deletion if the parent is not deleted.
Conditions that can block the commit operation with cleanup on the source array are:
- Presence of secure snapshots
- Presence of Snapshot Policies or Cloud Policy snapshots.
- SRDF relationship on the source devices to a Disaster Recovery Array
- If Devices are in Multiple Storage Groups
- If a Migrated Storage Group contains Gatekeeper Devices.
You can also specify the force option to bypass this behavior to allow as many migrated objects as possible to be deleted.
The cleanup operation is intended to reduce any remaining manual steps that have been present following successful migrations of applications between arrays, freeing up resources for reuse and enabling maximum flexibility for workloads running on PowerMax arrays.
Migrating SRDF Metro Protected Devices with NDM
The second new feature removes a restriction on Migrating SRDF Devices. With PowerMax OS 10.1 and Management Software version 10.1 it is now possible for PowerMax storage administrators to migrate devices that are already protected with SRDF Metro.
The workflow for this operation is essentially the same as for a standard migration with Metro based NDM, as described in the previous section. However, because key changes in the microcode on the Target array make this feature possible, it is critical to ensure prior to migration that source and target arrays are running supported microcode to support the features. Any PowerMax 8500/2500 or higher model array involved in the migration must be running PowerMax OS 10.1 (6079.225) or higher. Both source arrays (existing Metro arrays) will need to be on 5978.711.711 minimum plus ePack. For details, see SRDF and NDM Interfamily Connectivity Information Guide for details on ePack and latest compatibility information.
The following figure shows three supported configurations in which source devices are protected with SRDF/Metro.
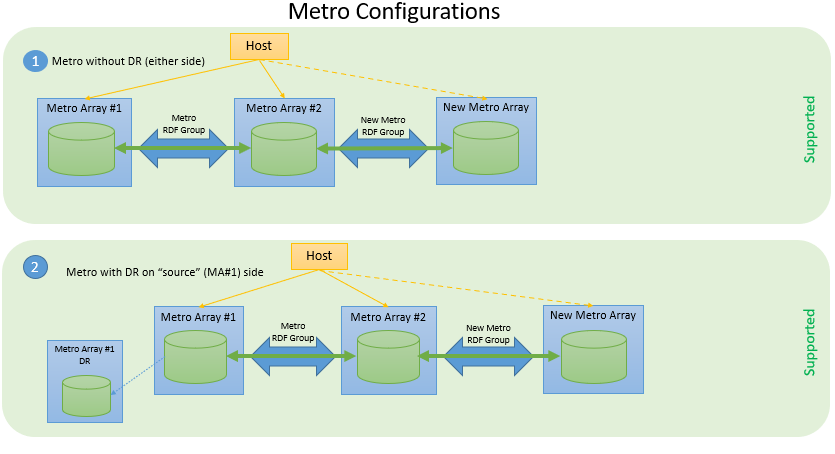
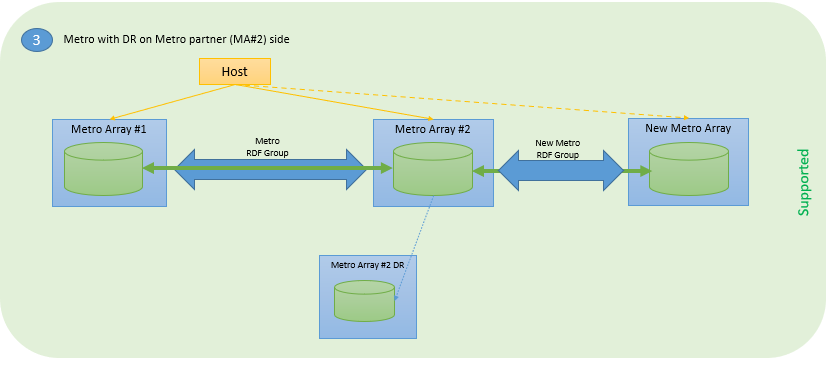
Figure 1. Supported SRDF Metro configurations for application mobility with NDM
The new mobility feature is built on existing NDM and SRDF technologies, using a workflow similar to that for NDM, the same support for easily recovering failed operations, and the same support for easily canceling an ongoing migration.
- Familiar NDM commands: Create, Commit, Cancel, List with SG based unit of migration
- Existing DR will be maintained through migration without interruption
- Supports Metro Sessions in either Witness or Bias mode
- Metro sessions can contain any combination of FBA and iBMI D910 devices
- SRDF/Metro License is required on the target array because SRDF Metro will continue to run following the migration
- iSCSI connectivity is not supported
If you are migrating a Metro Session using a witness, you must configure the witnesses on the target array before performing migrations. Both physical and virtual witnesses are supported on the existing and the new Metro Sessions and the type of witness between the two can be different.
Both of these new features add to the already rich set of migration options and are a direct result of customer enhancement requests. This new functionality will help our PowerMax customers with migration operations and increase productivity and flexibility by reducing cleanup operations and by providing the ability to migrate devices with metro protection.
Author: Paul Martin
Related Blog Posts

Elevate your operations: Mastering PowerMax Enhanced API Calls for Peak Efficiency
Wed, 22 Nov 2023 21:06:50 -0000
|Read Time: 0 minutes
Elevate your Operations: Mastering PowerMax Enhanced API Calls for Peak Efficiency
In today's fast-paced digital landscape, businesses rely heavily on APIs (Application Programming Interfaces) to manage and provision their IT environments which includes storage. While APIs are powerful tools, inefficient use can lead to increased server load on management appliances and unsatisfactory user experiences.
With PowerMax APIs new enhanced API calls, developers can: optimize workflows, reduce server load, and boost efficiency by reducing the amount of code needed to maintain and gather information about storage systems.
This article explores the New Enhanced API calls available with Unisphere for PowerMax 10.1 and best practices for working with these calls to create: seamless, responsive, and efficient applications using the PowerMax REST APIs.
In my previous post what’s new in the PowerMax API version 10.1, I summarise these enhancements at a high level. In this post, I will dive deeper into how to use these calls efficiently and provide inspiration where they can replace traditional API calls reducing the amount of code which needs to be maintained and getting the most out of your API calls.
Common challenges driving the need for enhanced API calls
One challenge is gathering detailed data on a large set of array objects with the existing API. It often requires multiple API calls. PowerMax Arrays support tens of thousands of devices and thousands of other objects like storage groups and snapshots. Another challenge is that large data mining often drives a high number of API calls and with multiple Arrays managed by a single server, the number of calls increases further. Taming this scale issue has always been a challenge and this created a need for batching and finding a different way of getting the data collections from the API.
With the newly enhanced API calls, developers can access a deeper level of data in bulk and select subsets or supersets of information filtered to their exact requirements.
With this release, we have introduced enhanced API calls for Performance and Data Collection for Storage Groups and Volumes. These improvements are designed to increase the overall performance of the API when used with the new calls and simplify the developer experience.
Versioning on Enhanced API calls.
The enhanced endpoints use a new URL. The base URL for traditional PowerMax API endpoints is:
https://unipowermax_ip:port/univmax/restapi/{version}
The new enhanced endpoints use:
https://unipowermax_ip:port/univmax/rest/v1
The key difference here is subtle but powerful from a developer perspective. The calls are versioned by attributes accessible. When new APIs become available or new attributes on existing API calls, the developer needs can simply select them via query path on the URL when the management server is at a version that supports them. More on this later.`
Authentication is still the same, API calls use basic authentication, so username and password required.
With that, there are 4 new API calls in the new format.
GET /systems/{id}/performance-categories
GET /systems/{id}/performance-categories/{id}
GET /systems/{id}/volumes
GET /systems/{id}/storage-groups
Enhanced Performance API calls and Usage
The performance related calls are GET calls as opposed to POST calls on the legacy performance calls and require little input from the developer.
Note: these calls work for all arrays supported by Unipshere not just the latest and greatest, but you do need Unisphere 10.1 minimum to take advantage.
https://ipaddress:8443/univmax/rest/v1/systems/{id}/performance-categories (GET)
Returns supported Performance Categories and Valid metrics based on an array model of supplied id/serial number.
https://ipaddress:8443/univmax/rest/v1/systems/{id}/performance-categories/{category} (GET)
Returns latest available diagnostic data for the specified performance category for all Key Performance Indicator Metrics (KPI)
With these enhanced performance calls there are no additional lookup calls needed to find out what components need to be queried, no keys to enter and no timestamps to generate. These reduce the number of calls being made to the system reducing overall load on the management servers and providing information with minimal effort for developers.
Below is an example requesting metrics for Front End Ports, note the call returns metrics for each port ID on the system without having to build any payload.
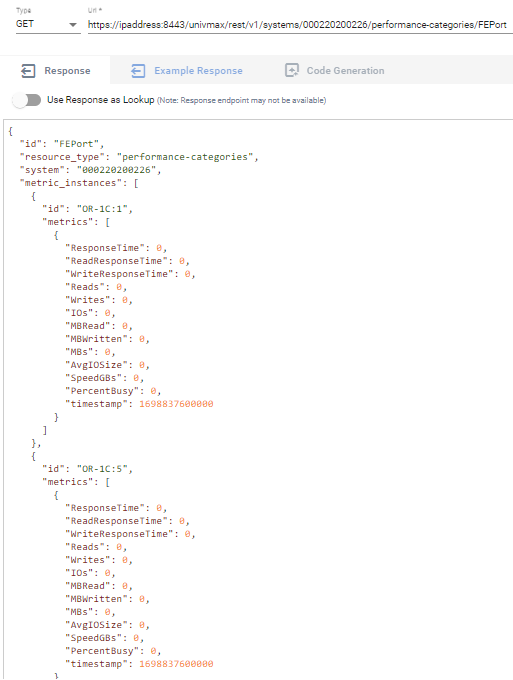
The new enhanced performance calls are ideal for customers building dashboards or exporting to time series databases (for use with tools like Grafana or Splunk as well as general use).
Storage Groups and Volumes Enhanced calls
For customers wishing to gather configuration information there are 2 new enhanced calls to help with this. By default, only the id of queried objects are returned for all objects on the system, however using select and filter options, the responses can be customized to return exactly the information they need in a single API call. With a single call you can get information on all storage groups or volumes on the array along with the specified attributes selected, and optionally filtered to your choice criteria.
https://ipaddress:8443/univmax/rest/v1/systems/{id}/storage-groups (GET)
https://ipaddress:8443/univmax/rest/v1/systems/{id}/volumes (GET)
In the following section I’ll dive into options for selecting and filtering to achieve great things with minimal effort.
Optimizing Data Filtering and Selection for Storage Groups and Volumes
To retrieve large amounts of data on all managed objects on an array with the traditional API calls requires multiple API calls for each object to get detailed level of information. When running against multiple arrays the number of calls increases with the number of managed objects being queried. With the new API calls the select and filter operations enable developers to get the same level or greater of information with just a couple of API calls.
By default, running the GET call for storage-groups will return only the ID of every storage group on the array, this is to minimize the overhead the call will generate. The ID is the identifying object name for every attribute in these new API calls. The Object itself has a lot more optional attributes that are selectable and filterable to customize the return. The optional attributes for filtering and selection are documented in the developer docs here. The documentation is also available as OpenApi.json for easier and programmatic review.
The image below shows a snippet of the list of potential return parameters for the storage-groups get call as seen from the imported JSON in PostMan. The full list of attributes is too large to fit in a screenshot.
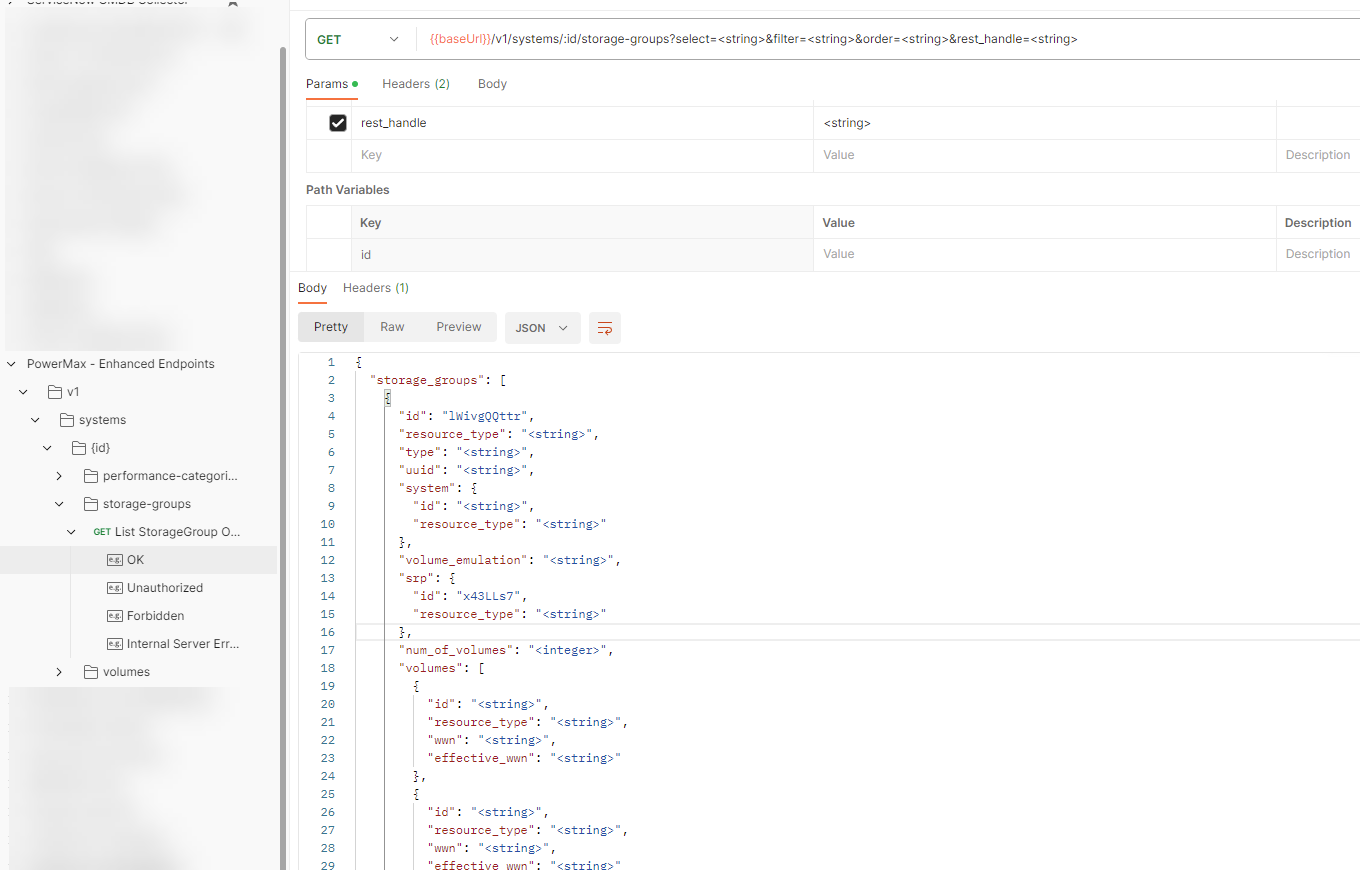
Let’s take an example call to build a return payload
- gathers data on all storage groups on a PowerMax array
- Select details on storage group capacity, the volume ids contained in the storage group with their effective_wwn
- Restrict the call to only return data only on storage groups with more than one snapshot
- Provide details on each snapshot including expiry data, link status and if it’s a secure snapshot.
To achieve this simply enter: append ?select= to the end of the URL for the API call followed by a comma separated list of attributes.
From the example, return in POSTMAN we can identify the following parameters will give the information
num_of_volumes, cap_gb, num_of_masking_views, masking_views.id, volumes.id, volumes.effective_wwn, volumes.resource_type, snapshots.id, snapshots.name, snapshots.timestamp_ms, snapshots.linked, snapshots.secured, snapshots.expired
Note: some of the attributes are noted with dot notation, this is necessary to select nested attributes so you will need to pay attention to this.

I generally recommend reviewing the JSON output in the examples, it’s easier to decipher for me than reading the tabular online documentation as the indentation makes it easier to identify sub attributes for the dot notation.
If I want to restrict the query only to storage groups that have at least one snapshot, I filter only storage groups with snapshots. To avoid unnecessary returned data,I can append a filter to the URL for the GET call &filter=num_of_snapshots gt 0.
You can also combine multiple filters, adding as many as you need on the URL for any attribute or sub attribute separated by comma. When specifying multiple filters, they are applied in an AND fashion.
Full details on all the operators for filters are documentation here.
After applying the attribute selection criteria and the filters of the API call, the URL look like the following:
https://ipaddress:8443/univmax/rest/v1/systems/000220200226/storage-groups?select=num_of_volumes,cap_gb,num_of_masking_views,masking_views.id,volumes.id,volumes.effective_wwn,volumes.resource_type,snapshots.id,snapshots.name,snapshots.timestamp_ms,snapshots.linked,snapshots.secured,snapshots.expired&filter=num_of_snapshots gt 0
When the call is executed, it returns a single response with the requested data for all storage groups matching the filter criteria. It displays all the selected attributes and sub-attributes. The resultant JSON return is shown below.
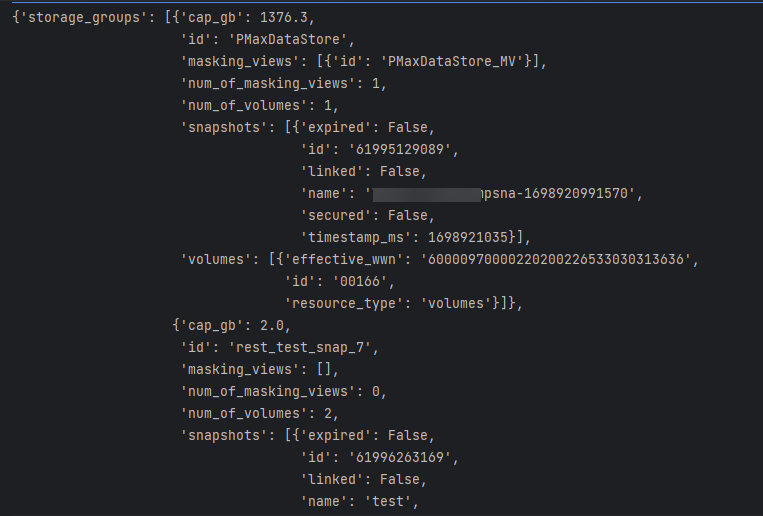
PyU4V our Python SDK for PowerMax API has support for the new enhanced API calls with version 10.1 available from PyPi and is fully documented on ReadTheDocs. New function libraries volumes, storage_groups, and performance_enhanced have been added. Functionality has been added to the volumes and storage_groups modules to return the attributes available for selection in JSON format so that the meta data is easier to access. The same query executed by python script is shown below.
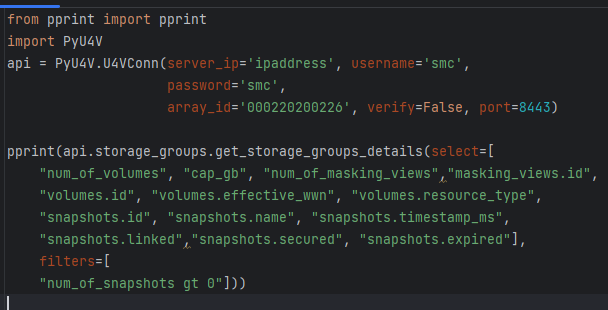
The short Python script is easily readable, executing a single API call to get all this information for all volumes matching the criteria. There are hundreds of attributes available to you for selection and filtering. It’s worth spending a little time up front to define the reports you need and create functions to capture the information in a repeatable way.
Remember if you don’t need information, don’t request it as it will create less load on the management server and the client application. The API is explicit in this way. PyU4V functions for volume and storage group by default will select to return to the top-level attributes for both storage groups and volumes, excluding rdf_infos and snapshot.
In summary, the new enhanced API calls give access to an SQL like interface for selecting, filtering and ordering data on your storage objects via the API, meaning you can effectively design API calls for yourself to give you the data you want and need.
Hopefully this post was informative and gave you some inspiration into how you can reduce the number of API calls needed to get large datasets on your storage groups and volumes for your PowerMax and VMAX arrays.
Check out this space for more about the PowerMax API. If there are topics that are of interest to you and you would like to learn more, send a request to @rawstorage on Twitter, and I’ll try to accommodate your request!
Be sure to provide feedback through your account team for any enhancement requests or start a discussion on https://www.dell.com/community/en/topics/automation. Our product managers will take your requests and bring them to the development team.
Author: Paul Martin

RESTing on our Laurels - What’s New with the PowerMax API and Unisphere 10.1
Tue, 17 Oct 2023 13:12:28 -0000
|Read Time: 0 minutes
Unisphere 10.1 has just been released! Although the internal code name was Laurel, we are doing a lot in the API, so we definitely haven’t been RESTing on our laurels!
With this release the Unisphere for PowerMax team focused on what could be done better in the PowerMax API, to make things easier for developers and to reduce the amount of code people must maintain to work with the PowerMax API. Personally, I think they have knocked it out of the park with some new features. These features lay the groundwork for more of the same in the future. As always, there is a full change log for the API published along with updated OpenAPI documents available on https://developer.dell.com. In this blog I provide my own take and highlight some areas that I think will help you as a customer.
Let’s start with the traditional Unisphere for PowerMax API. With this new version of Unisphere there is a new version of the API and simpler versioning referencing throughout the API. For example, the following GET version API call returns the api_version (in this case, 101), and the currently supported API versions with this release (101, 100, and 92). As always, the previous two versions are supported. Here, the supported_api_versions key takes any guesswork out of the equation. If you are using PyU4V, a new version (10.1) is available, which supports all of the new functionality mentioned here.
https://Unisphere:8443/univmax/restapi/version (GET) { "version": "T10.1.0.468", "api_version": "101", "supported_api_versions": [ "101", "100", "92" ] }
I’ll break the other changes down by functional resource so you can skip any that you’re not using:
- Serviceability API calls
- Replication Call Enhancements
- Sloprovisioning Call Enhancements
- System Call Enhancements
- Performance API Call Enhancements
- The All New Enhanced PowerMax API – Bulk API calls
Serviceability API calls
For embedded Unisphere for PowerMax users, when the system is updated to the latest version of Unipshere, a new Serviceability API Resource becomes available.
The new serviceability API calls (as shown in the following figure) give control over the embedded Unisphere, providing access to solutions enabler settings, and Unisphere settings that up until now have only been accessible in the UI, such as:
- Setting up the nethosts file for client/server access from CLI hosts running Solutions Enabler
- Host based access control
- Certificate Management of the Solutions Enabler Guest OS
- And more
Here’s the tree of the Serviceability API resource:

Note: When executing API calls to update the Unisphere application, the server will restart as a result of these changes. You must wait for these to complete before you can issue more API calls. Also, as a reminder, if you are changing the IP address of the Unisphere server you must update your API connection for future calls.
Replication call enhancements
Good news for customers using snapshots and snapshot policies. New replication calls and keys will make the management workflows easier for anyone automating snapshot control and using policies.
An updated API call adds keys for directly associated policies vs inherited policies:
101/replication/symmetrix/{symmetrixId}/storagegroup/{storageGroupId} (GET)In the API, identifying and tracking back linked snapshots has been time consuming in the past. Based on valued customer feedback, our product management and developers have implemented key changes that will help.
The ability to list storage groups that are linked targets has been there for a while, with query parameters in the following GET call:
101/replication/symmetrix/{symmetrixId}/storagegroup?is_link_target=trueHowever, finding out which snapshot was linked, and which source storage group owned that snapshot was a challenge. To make this easier, new keys now appear:
101/replication/symmetrix/{symmetrixId}/storagegroup/{storageGroupId} (GET)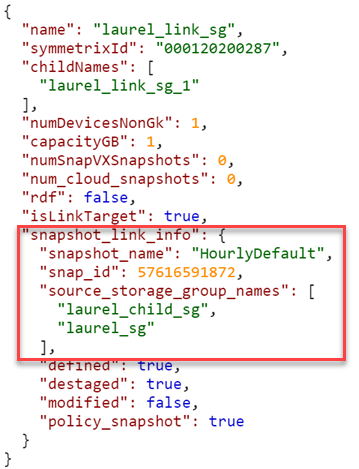
As you can see, the 10.1 API call returns a new key (snapshot_link_info) that includes all the information you need to be able to manipulate the linked snapshots, without having to engineer any trickery yourself.
Sloprovisioning call enhancements
Probably the single biggest change to the Provisioning API calls is the ability to Validate and return a Bad Request when the performance_impact_validation_option is set for sloprovisoning the /maskingview POST call. This gives the developer a way to check, at the time of provisioning, whether a workload is suited to run on the supplied PowerMax serial number. This call uses performance data from the workload planner database and can help create enhanced provisioning workloads with performance and zoning in mind.
The Payload can now accept a new key (performance_impact_validation_option) which can be set to:
- IfRecommended – Run performance impact tests. If no performance capacity threshold is breached, run the requested configuration change.
- Preview – Run performance impact tests and return performance impact scores for the requested operation. Return the input object (with generated fields, if applicable) for relevant follow up API calls.
In addition, the payload has a “portGroupSelection” key that can automatically create a new port group or use an existing port group based. If automatic selection is used, selection can be either UtilizationBased or ZoningBased. (Note: Automatic port selection is only available for Fibre (SCSI FC))
If you choose to use an existing port group, existing port groups are evaluated by the workload planner algorithms examining port groups that are already configured on the system. The algorithm will select the least loaded port group for the provisioning and ignore zoning. Users have the Option to restrict selection to a supplied list of port groups using the API keys. See documentation for details of the various keys.
Note: When using the performance impact selection, you can’t specify an existing storage group because it’s assumed that they are already provisioned. Full documentation for the API call mentioned is here with the supported parameters.
The provisioning API calls include other additions:
- Update POST for Create Masking View, to allow the specifying of a Starting LUN Address. This was a customer enhancement to make it easier to configure boot from SAN.
- Update PUT for Modify SG, to allow the specifying of a Starting LUN Address when adding volumes. .
- Update PUT for Modify SG, to allow terminating snapshots associated with volumes being removed from a SG in a single call. This is very useful because it prevents stranded snapshots from consuming space on the array.
System call enhancements
We have added system calls to enable the refresh of Unisphere. This is useful to customers who are working in a distributed environment and who want to ensure that Unisphere data is up to the second with the latest information. This should be the case, but in the event that there were changes made on a remote system, it could take a minute or so before these are reflected in the object model. The new refresh call has some guardrails, in that you can only run it once every five minutes. If you try to execute too soon, status code 429 will return with message telling you to wait for it to come back:
“Bad or unexpected response from the storage volume backend API: Error POST None resource. The status code received is 429 and the message is {'retry_after_ms': 285417}.”The documentation for this API call (/101/system/symmetrix/{array_serial}/refresh) is here.
Getting information about REST API resources and server utilization was previously only ever available in the user interface. It made sense to make this information available through the REST API because the information pertains to REST. The new GET call to obtain this information (/101/system/management_server_resources) is available, documentation is here.
Along the same lines, we have also added the following calls:
- Change Log Level - /101/system/logging (PUT/GET)
- Configure/Check SNMP Destination - /101/system/snmp (GET/POST/PUT/DELETE)
- Server Cert management - /101/system/snmp/server_cert (POST)
- Configure SNMPv3 with TLS - /101/system/snmp/v3_tls (POST)
- Manage PowerMax Licensing via API
Performance API call enhancements
There is only one minor change in the traditional API for performance with this release. We are adding the ability to register a list of storage groups for real time performance and also bring file metrics for SDNAS onto the Unisphere for PowerMax array for monitoring. The POST call /performance/Array/register has been updated to take new keys, selectedSGs, and a file.
The new payload would look something like this:
{
"symmetrixId": "01234568779",
"selectedSGs": "sg1,sg2,sg3",
"diagnostic": "true",
"realtime": "true",
"file": "true"
}There are some additional changes for mainframe and also Workload Planner which are covered in the changelog documentation. I just want to highlight here what I think most customers will be interested in and give some background.
The all new enhanced PowerMax API – Bulk API calls
I’ve been looking forward to being able to announce some very nice enhancements to the PowerMax API. The API provides new calls with resources accessible under a different Base URI. Rather than https:// {server_ip}:{port}/univmax/restapi/, the new API calls are under https://{server_ip}:{port}/univmax/rest/v1.
The difference between the two entry points will become apparent as you get used to these calls and the versioning will be arguably simpler going forward. Documentation is here.
- GET - /systems/{id}/volumes
- GET - /systems/{id}/storage-groups
- GET - /systems/{id}/performance-categories
- GET - /systems/{id}/performance-categories/{id}
For complete details about these endpoints, see:
- The API documentation marked "POWERMAX - ENHANCED ENDPOINTS"
- The Unisphere for PowerMax 10.1 REST API Changelog
“Ok” I hear you say, “so what’s the big deal?”. Well, these endpoints behave differently from our existing API calls. The provide more information faster so that developers don’t have to maintain a lot of code to get the information they need.
The volumes GET call returns details about every volume on a system in a single call. There is no pagination required and you don’t need to worry about iterators or have to deal with anything fancy. The API just gives you back one big JSON response with all the information you need. This eliminates the need to loop on calls and will dramatically cut down the number of API calls you need to issue to the server.
The same is true for the storage groups calls. With a single call, you can get information on all storage groups on the system, their attributes, and which volumes are in those groups.
But wait, there’s more…
We have implemented a modified form of filtering of the response. You can now filter on all attributes and nested attributes that are returned in the response:
../storage-groups?filter=cap_gb eq 100 ../storage-groups?filter=volumes.wwn like 12345678
The available filter options are:
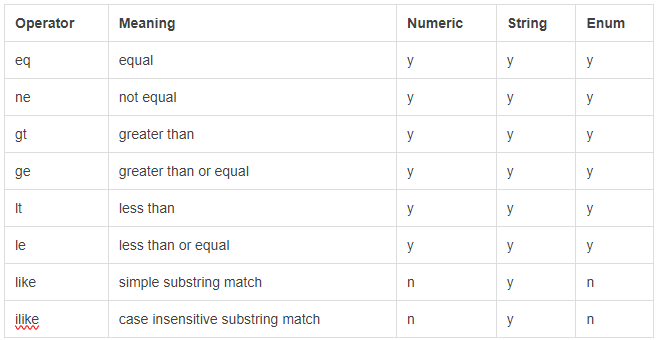 The endpoints require you to “select” the desired attributes instead of returning everything up front. By doing so, you can control how server-intensive each request is by omitting or including only the relevant info:
The endpoints require you to “select” the desired attributes instead of returning everything up front. By doing so, you can control how server-intensive each request is by omitting or including only the relevant info:
…/storage-groups?select=cap_gb,uuid,type,num_of_volumes
This returns only the cap_gb,uuid, type and num_of_volumes for each storage group.
This also applies to nested attributes (a full stop is used to define child attributes):
…/storage-groups?select=volumes.wwn,volumes.effective_wwn,snapshots.timestamp_ms
If no attributes are defined in the “select”, only the default values, such as “id”, are returned. The list of attributes that can be selected is available in the documentation here.
Functions are also available for this in PyU4V. Currently multiple filter options are combined in an AND pattern and select can be applied to the data to reduce the output to only what you are interested in. The following is an example of this functionality as executed through PyU4V 10.1:
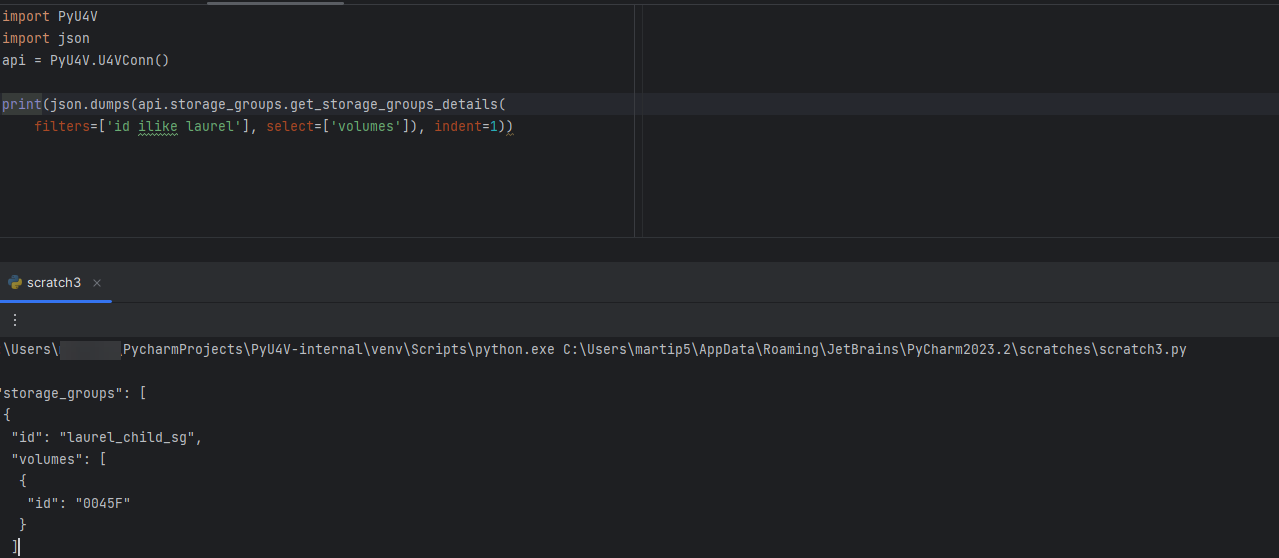
With this new functionality you can get all details for your volumes and storage groups in two calls per array, reduced from tens of thousands of calls on larger systems.
Enhanced performance metrics with the new Bulk API
In addition to the new GET calls for Volumes and Storage groups, there are new calls for the performance metrics.
The /systems/{id}/performance-categories (GET) call returns a list of performance categories valid for the arrays you are querying.
When you query each category, the API returns the last interval of diagnostic performance data using the new /systems/{id}/performance-categories/{id} GET call. This returns all key performance indicator metrics at the diagnostic level for the category and all instances in that category for the last five minutes.
These new enhanced API calls reduce the amount of code that developers need to write and maintain. The API call is intentionally designed to provide only the latest information. This reduces the amount of code for which developers need to maintain performance data collection for dashboard type tools and data collectors.
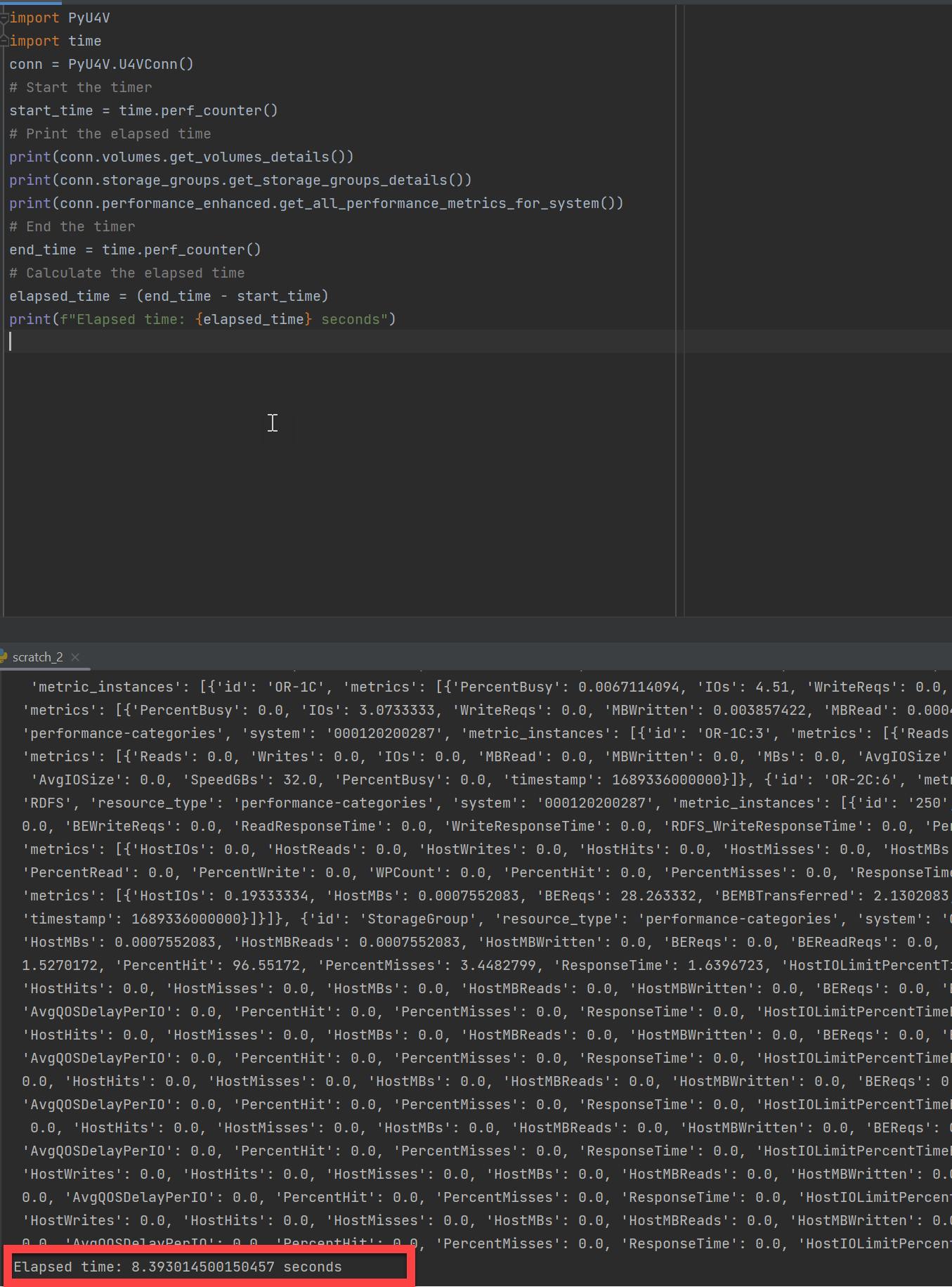
The following example shows a PyU4V script executing a few lines of code to gather all performance stats for every category on every component of a PowerMax array. It’s also gathering details on all volumes and all storage groups using the new Enhanced API calls. On my system, the code takes about eight seconds on average to gather all that information.
To wrap up
Hopefully this blog has provided some insight into the latest changes in the PowerMax REST API. As you can see, our developers have not been RESTing on their laurels!
Watch this space for more about the PowerMax API, and if there are topics that are of interest to you and you would like to learn more, send a request to @rawstorage on Twitter and I’ll try to accommodate your request!
Be sure to provide feedback through your account team for any enhancement requests or start a discussion on https://www.dell.com/community/en/topics/automation. Our product managers will take your requests and bring them to the development team.
Author: Paul Martin