




Elevate your operations: Mastering PowerMax Enhanced API Calls for Peak Efficiency

Elevate your Operations: Mastering PowerMax Enhanced API Calls for Peak Efficiency
In today's fast-paced digital landscape, businesses rely heavily on APIs (Application Programming Interfaces) to manage and provision their IT environments which includes storage. While APIs are powerful tools, inefficient use can lead to increased server load on management appliances and unsatisfactory user experiences.
With PowerMax APIs new enhanced API calls, developers can: optimize workflows, reduce server load, and boost efficiency by reducing the amount of code needed to maintain and gather information about storage systems.
This article explores the New Enhanced API calls available with Unisphere for PowerMax 10.1 and best practices for working with these calls to create: seamless, responsive, and efficient applications using the PowerMax REST APIs.
In my previous post what’s new in the PowerMax API version 10.1, I summarise these enhancements at a high level. In this post, I will dive deeper into how to use these calls efficiently and provide inspiration where they can replace traditional API calls reducing the amount of code which needs to be maintained and getting the most out of your API calls.
Common challenges driving the need for enhanced API calls
One challenge is gathering detailed data on a large set of array objects with the existing API. It often requires multiple API calls. PowerMax Arrays support tens of thousands of devices and thousands of other objects like storage groups and snapshots. Another challenge is that large data mining often drives a high number of API calls and with multiple Arrays managed by a single server, the number of calls increases further. Taming this scale issue has always been a challenge and this created a need for batching and finding a different way of getting the data collections from the API.
With the newly enhanced API calls, developers can access a deeper level of data in bulk and select subsets or supersets of information filtered to their exact requirements.
With this release, we have introduced enhanced API calls for Performance and Data Collection for Storage Groups and Volumes. These improvements are designed to increase the overall performance of the API when used with the new calls and simplify the developer experience.
Versioning on Enhanced API calls.
The enhanced endpoints use a new URL. The base URL for traditional PowerMax API endpoints is:
https://unipowermax_ip:port/univmax/restapi/{version}
The new enhanced endpoints use:
https://unipowermax_ip:port/univmax/rest/v1
The key difference here is subtle but powerful from a developer perspective. The calls are versioned by attributes accessible. When new APIs become available or new attributes on existing API calls, the developer needs can simply select them via query path on the URL when the management server is at a version that supports them. More on this later.`
Authentication is still the same, API calls use basic authentication, so username and password required.
With that, there are 4 new API calls in the new format.
GET /systems/{id}/performance-categories
GET /systems/{id}/performance-categories/{id}
GET /systems/{id}/volumes
GET /systems/{id}/storage-groups
Enhanced Performance API calls and Usage
The performance related calls are GET calls as opposed to POST calls on the legacy performance calls and require little input from the developer.
Note: these calls work for all arrays supported by Unipshere not just the latest and greatest, but you do need Unisphere 10.1 minimum to take advantage.
https://ipaddress:8443/univmax/rest/v1/systems/{id}/performance-categories (GET)
Returns supported Performance Categories and Valid metrics based on an array model of supplied id/serial number.
https://ipaddress:8443/univmax/rest/v1/systems/{id}/performance-categories/{category} (GET)
Returns latest available diagnostic data for the specified performance category for all Key Performance Indicator Metrics (KPI)
With these enhanced performance calls there are no additional lookup calls needed to find out what components need to be queried, no keys to enter and no timestamps to generate. These reduce the number of calls being made to the system reducing overall load on the management servers and providing information with minimal effort for developers.
Below is an example requesting metrics for Front End Ports, note the call returns metrics for each port ID on the system without having to build any payload.
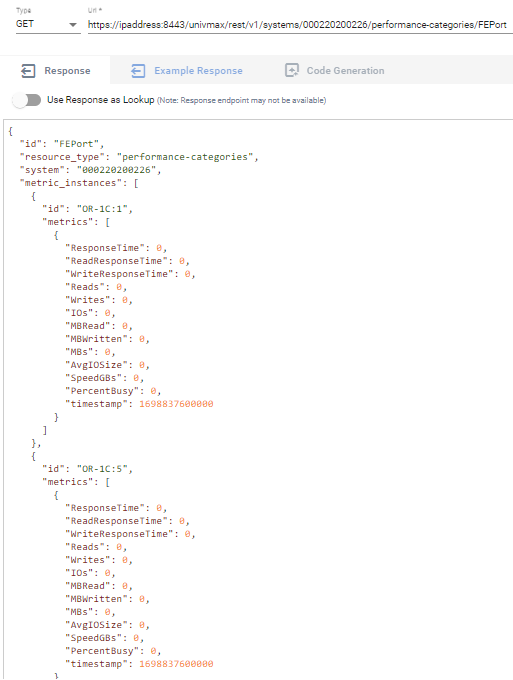
The new enhanced performance calls are ideal for customers building dashboards or exporting to time series databases (for use with tools like Grafana or Splunk as well as general use).
Storage Groups and Volumes Enhanced calls
For customers wishing to gather configuration information there are 2 new enhanced calls to help with this. By default, only the id of queried objects are returned for all objects on the system, however using select and filter options, the responses can be customized to return exactly the information they need in a single API call. With a single call you can get information on all storage groups or volumes on the array along with the specified attributes selected, and optionally filtered to your choice criteria.
https://ipaddress:8443/univmax/rest/v1/systems/{id}/storage-groups (GET)
https://ipaddress:8443/univmax/rest/v1/systems/{id}/volumes (GET)
In the following section I’ll dive into options for selecting and filtering to achieve great things with minimal effort.
Optimizing Data Filtering and Selection for Storage Groups and Volumes
To retrieve large amounts of data on all managed objects on an array with the traditional API calls requires multiple API calls for each object to get detailed level of information. When running against multiple arrays the number of calls increases with the number of managed objects being queried. With the new API calls the select and filter operations enable developers to get the same level or greater of information with just a couple of API calls.
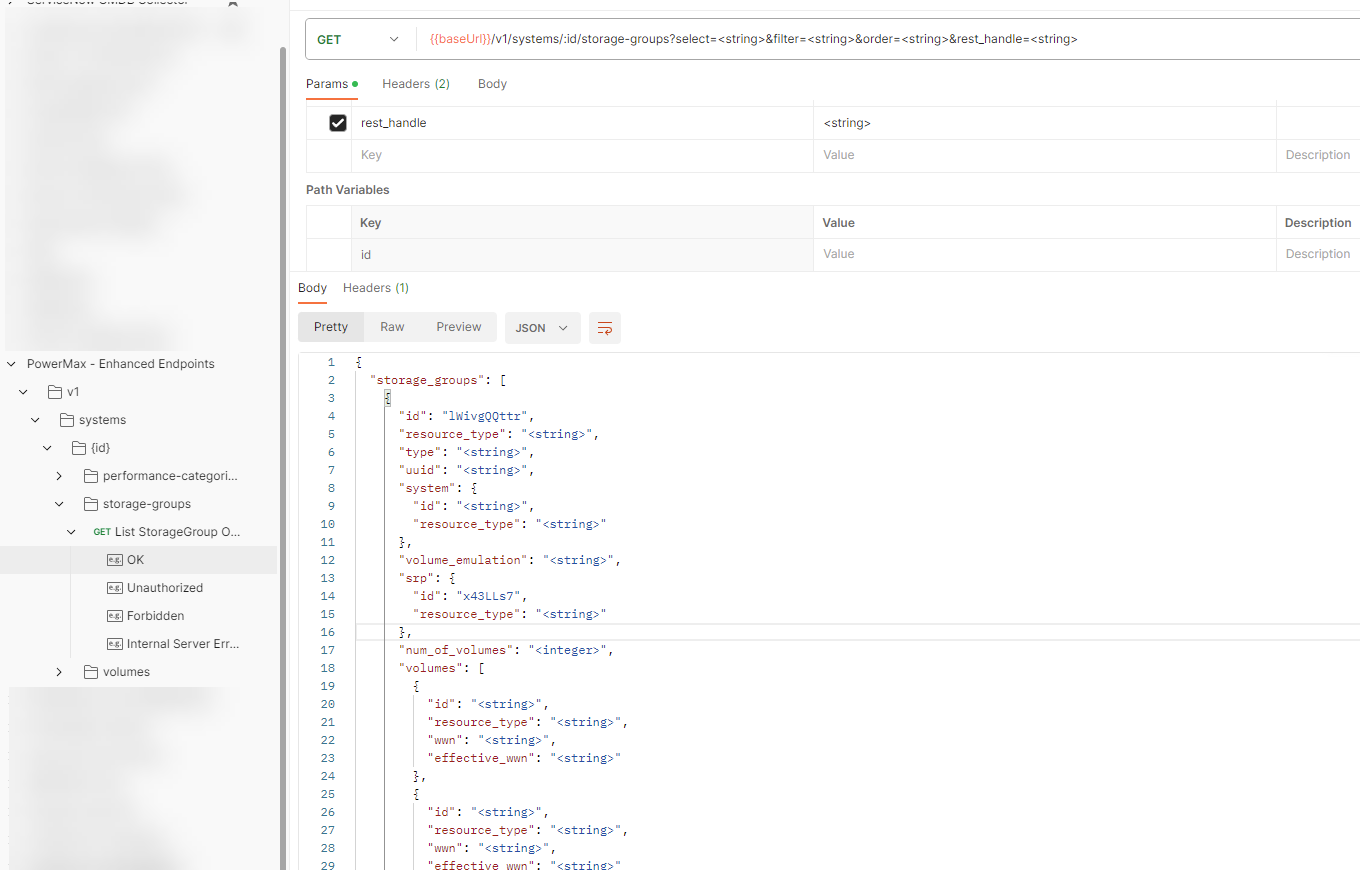
By default, running the GET call for storage-groups will return only the ID of every storage group on the array, this is to minimize the overhead the call will generate. The ID is the identifying object name for every attribute in these new API calls. The Object itself has a lot more optional attributes that are selectable and filterable to customize the return. The optional attributes for filtering and selection are documented in the developer docs here. The documentation is also available as OpenApi.json for easier and programmatic review.
The image below shows a snippet of the list of potential return parameters for the storage-groups get call as seen from the imported JSON in PostMan. The full list of attributes is too large to fit in a screenshot.
Let’s take an example call to build a return payload
- gathers data on all storage groups on a PowerMax array
- Select details on storage group capacity, the volume ids contained in the storage group with their effective_wwn
- Restrict the call to only return data only on storage groups with more than one snapshot
- Provide details on each snapshot including expiry data, link status and if it’s a secure snapshot.
To achieve this simply enter: append ?select= to the end of the URL for the API call followed by a comma separated list of attributes.
From the example, return in POSTMAN we can identify the following parameters will give the information
num_of_volumes, cap_gb, num_of_masking_views, masking_views.id, volumes.id, volumes.effective_wwn, volumes.resource_type, snapshots.id, snapshots.name, snapshots.timestamp_ms, snapshots.linked, snapshots.secured, snapshots.expired
Note: some of the attributes are noted with dot notation, this is necessary to select nested attributes so you will need to pay attention to this.

I generally recommend reviewing the JSON output in the examples, it’s easier to decipher for me than reading the tabular online documentation as the indentation makes it easier to identify sub attributes for the dot notation.
If I want to restrict the query only to storage groups that have at least one snapshot, I filter only storage groups with snapshots. To avoid unnecessary returned data,I can append a filter to the URL for the GET call &filter=num_of_snapshots gt 0.
You can also combine multiple filters, adding as many as you need on the URL for any attribute or sub attribute separated by comma. When specifying multiple filters, they are applied in an AND fashion.
Full details on all the operators for filters are documentation here.
After applying the attribute selection criteria and the filters of the API call, the URL look like the following:
https://ipaddress:8443/univmax/rest/v1/systems/000220200226/storage-groups?select=num_of_volumes,cap_gb,num_of_masking_views,masking_views.id,volumes.id,volumes.effective_wwn,volumes.resource_type,snapshots.id,snapshots.name,snapshots.timestamp_ms,snapshots.linked,snapshots.secured,snapshots.expired&filter=num_of_snapshots gt 0
When the call is executed, it returns a single response with the requested data for all storage groups matching the filter criteria. It displays all the selected attributes and sub-attributes. The resultant JSON return is shown below.
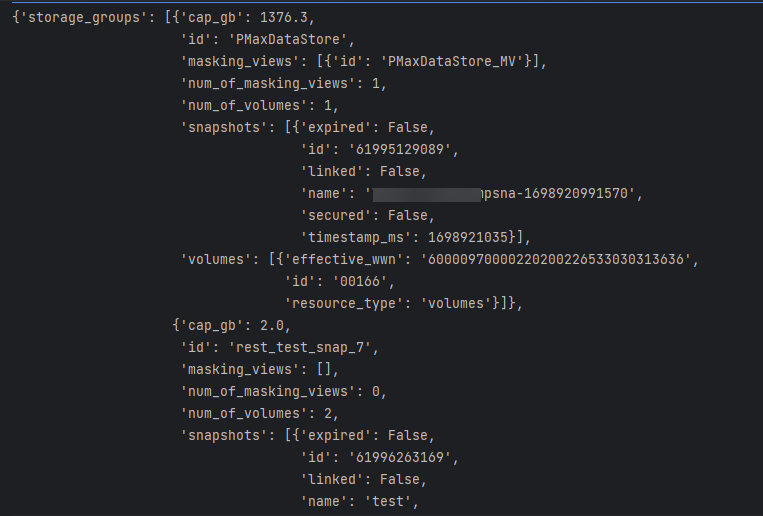
PyU4V our Python SDK for PowerMax API has support for the new enhanced API calls with version 10.1 available from PyPi and is fully documented on ReadTheDocs. New function libraries volumes, storage_groups, and performance_enhanced have been added. Functionality has been added to the volumes and storage_groups modules to return the attributes available for selection in JSON format so that the meta data is easier to access. The same query executed by python script is shown below.
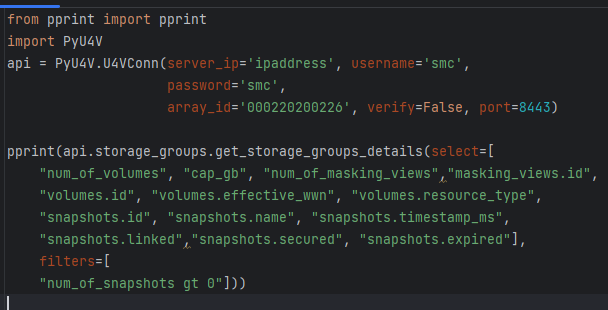
The short Python script is easily readable, executing a single API call to get all this information for all volumes matching the criteria. There are hundreds of attributes available to you for selection and filtering. It’s worth spending a little time up front to define the reports you need and create functions to capture the information in a repeatable way.
Remember if you don’t need information, don’t request it as it will create less load on the management server and the client application. The API is explicit in this way. PyU4V functions for volume and storage group by default will select to return to the top-level attributes for both storage groups and volumes, excluding rdf_infos and snapshot.
In summary, the new enhanced API calls give access to an SQL like interface for selecting, filtering and ordering data on your storage objects via the API, meaning you can effectively design API calls for yourself to give you the data you want and need.
Hopefully this post was informative and gave you some inspiration into how you can reduce the number of API calls needed to get large datasets on your storage groups and volumes for your PowerMax and VMAX arrays.
Check out this space for more about the PowerMax API. If there are topics that are of interest to you and you would like to learn more, send a request to @rawstorage on Twitter, and I’ll try to accommodate your request!
Be sure to provide feedback through your account team for any enhancement requests or start a discussion on https://www.dell.com/community/en/topics/automation. Our product managers will take your requests and bring them to the development team.
Author: Paul Martin
Related Blog Posts

Announcing Serviceability Improvements for PowerMax Embedded Management
Wed, 05 Apr 2023 16:35:53 -0000
|Read Time: 0 minutes
PowerMax 8500 and 2500 models have been launched Q4 2022 and with it came new management tools: specifically, Unisphere for PowerMax 10.0. The embedded management option is only applicable to the new PowerMax 8500 and 2500 models. If you are managing a VMAX All Flash array or a PowerMax 200/800, you can still use Unisphere for PowerMax 10 in an installed version on a supported operating system. This blog focuses on the features unique to embedded management, specifically around serviceability enhancements.
The vApp management interface has been retired
No, you didn’t read that heading wrong. The vApp interface in Unisphere for PowerMax 10 is no longer needed.

This means that you no longer need to point a browser at a different port and manage two sets of passwords. All the functionality in that second interface is now where it belongs, in the main UI, including:
- IP, DNS, and NTP settings management
- Solutions Enabler settings
- Certificate management
- Service Access for Dell support staff
- Updates to Unisphere versions
- Download log files
Using Unisphere to access serviceability settings
From Unisphere, simply click the local array. The serviceability icon appears in the left panel, as shown here:
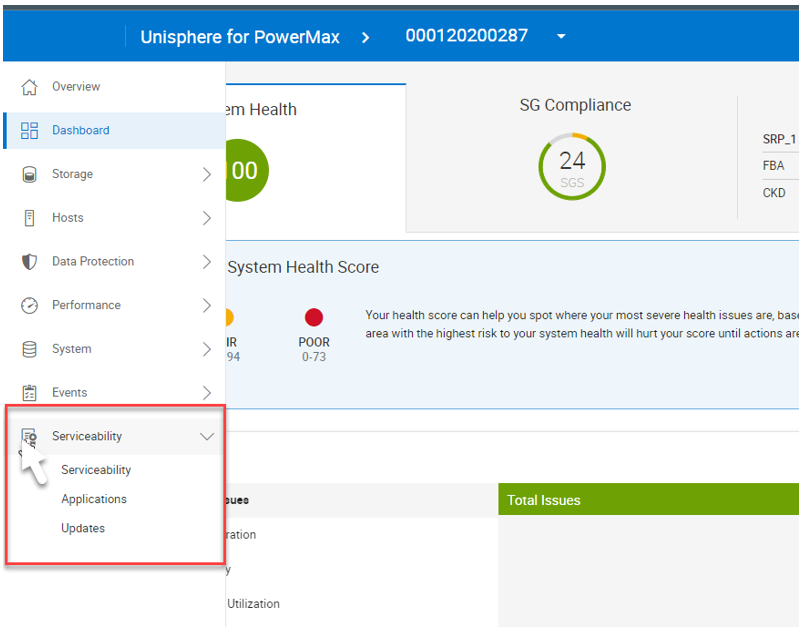
From here you can access and manage that functionality mentioned above:
- IP, DNS, and NTP settings
- Solutions Enabler settings
- Certificates
- Service Access for Dell support staff
- Updates to Unisphere versions
- Download log files
One key item to note: when updating any of the settings under Solutions Enabler Settings, the change is automatically propagated to the standby container. This means that you only need to do this once, such as when configuring client/server access, updating general SYMAPI options, or setting up symavoid.
There are two new options:
1. Service Access – enabling this option allows Dell support to dial into the array and view the Same Unisphere UI that customers see. This is a valuable option for saving time on support calls.
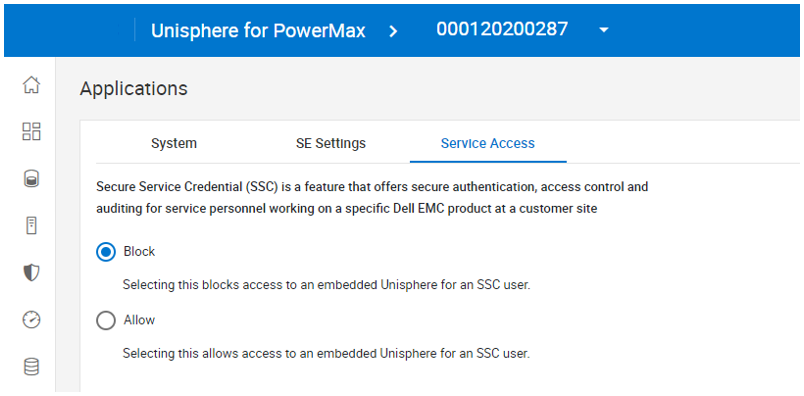
2. Updates – Customers are now in full control of downloading and installing new versions of Unisphere on their embedded management system. (With earlier systems, upgrades were scheduled with code upgrades and patches to the array.) To self upgrade, customers need now only connect an array to the Secure Services Gateway.
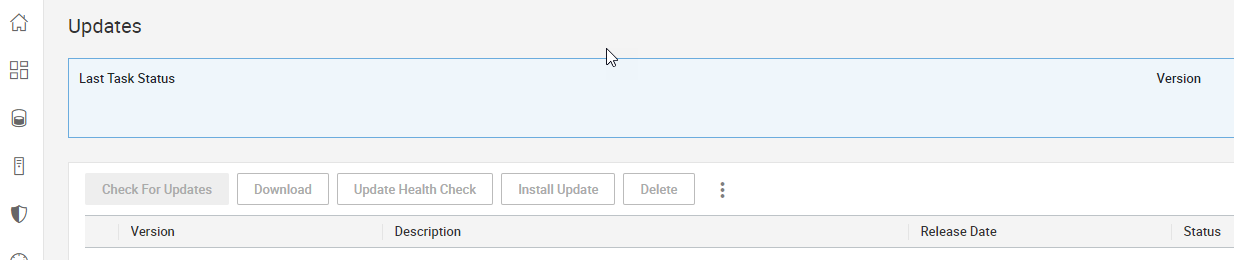
I think customers will agree that consolidating these settings into the main UI makes everything easier. In a future blog post, I’ll show you how to use the new serviceability UI to configure Client Server connectivity, to enable CLI access from a remote client.
Author: Paul Martin

Unisphere for PowerMax Workload Planner
Fri, 15 Mar 2024 21:21:58 -0000
|Read Time: 0 minutes
Workload Planner (WLP) is a FAST component used to display performance metrics to calculate VMAX component utilizations and storage group Service Level Objective compliance. It allows for more informed workload monitoring, using up-stream components (Unisphere GUI and REST API) with respect to current VMAX performance capacity.
WLP is supported on arrays running 5977 and upwards code levels. Each service level and workload type has a response band associated with it. When a storage group (workload) is said to be compliant, it is operating within the associated response time band.
When assessing the compliance of a storage group, Workload Planner calculates its weighted response time for the past 4 hours and the past 2 weeks, and then compares the two values to the maximum response time associated with its given service level. If both calculated values fall within (under) the service level-defined response time band, the compliance state is STABLE. If one of them complies and the other is out of compliance, then the compliance state is MARGINAL. If both are out of compliance, then the compliance state is CRITICAL.
SG SLO compliance
To begin, let’s examine our SG SLO compliance to examine how our SG’s have been performing.
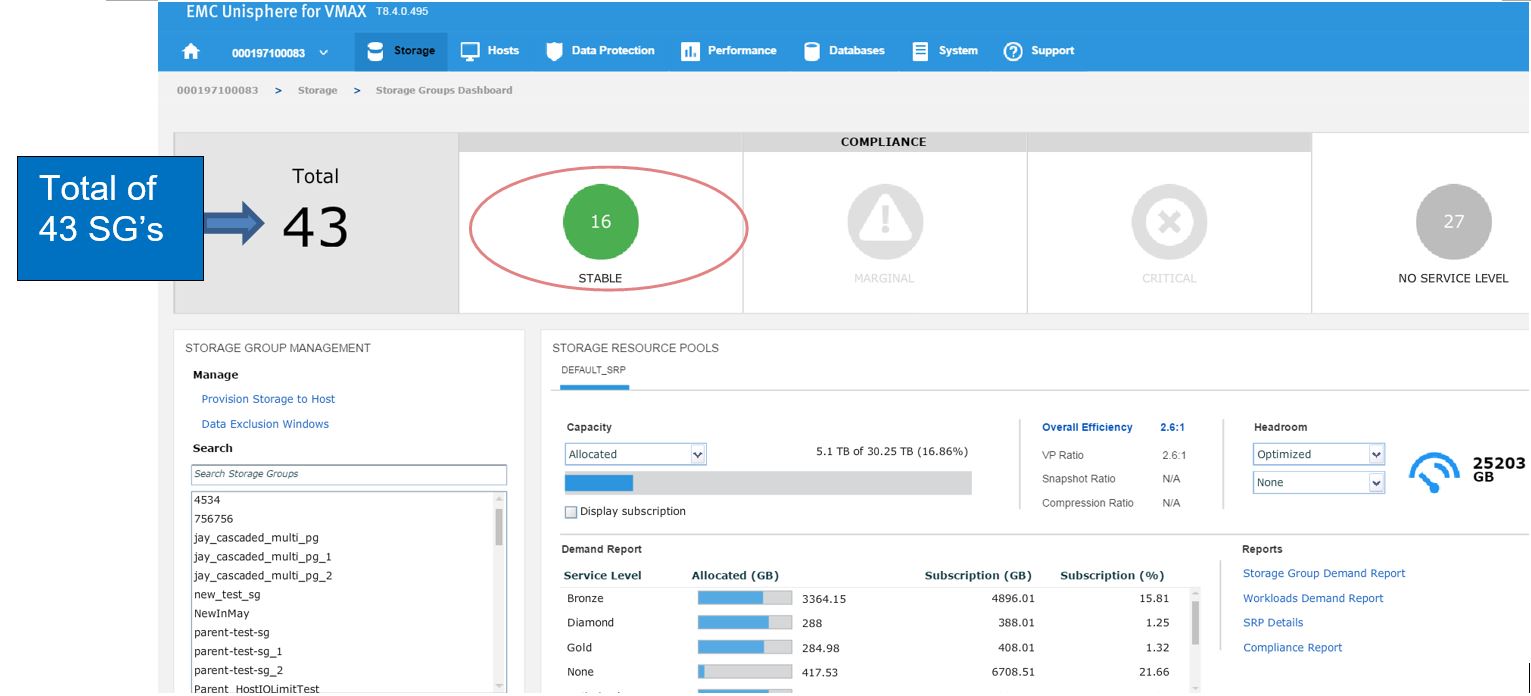 Figure 1. Storage group view
Figure 1. Storage group view
In this example, we have a total of 43 SGs with none being in a marginal or critical state. Let’s click on 16 stable SG’s and review further.
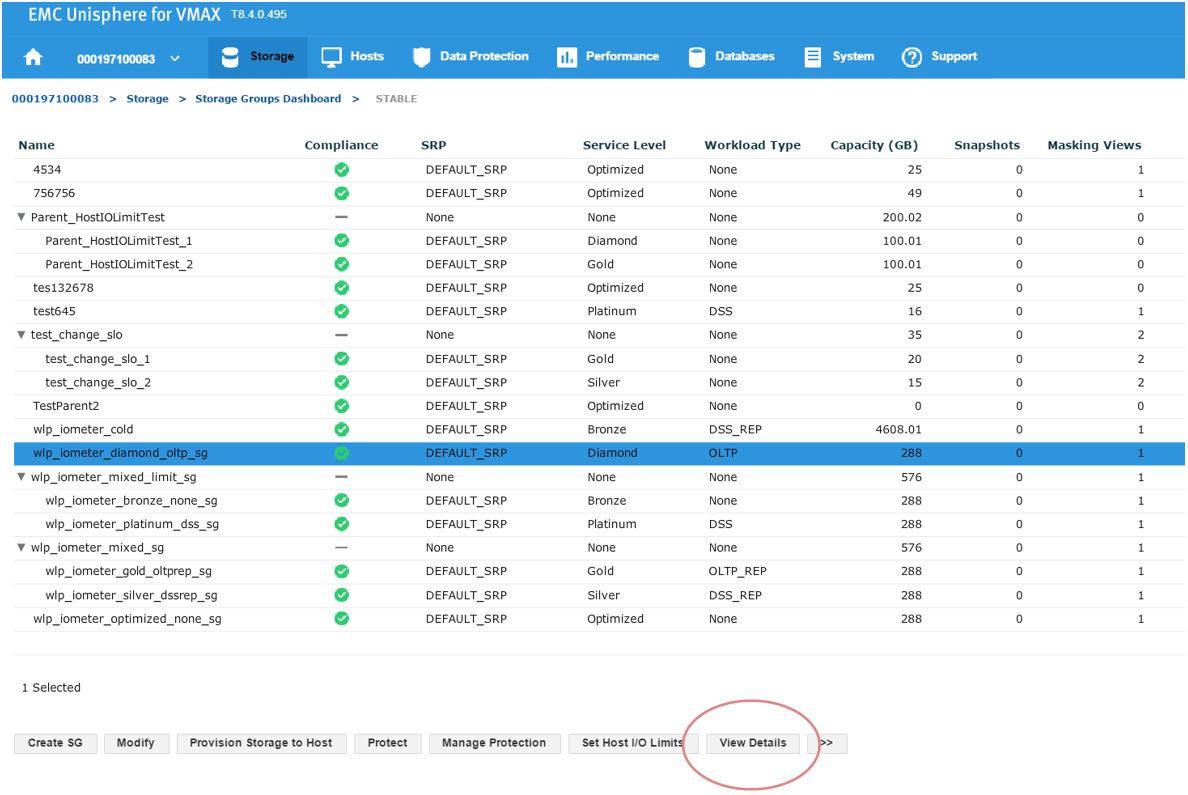
Figure 2. Storage groups drill down view
Here, we have a SG list for the array. In the second column, we see that our sg wlp_iometer_diamond is in a compliant SLO state. Let’s review this SG further by selecting this SG, and then clicking on View Details. This takes us to Details view where we can review the properties of the SG and check its performance on the right-hand side. Here, we want to select Compliance and select the storage tab.
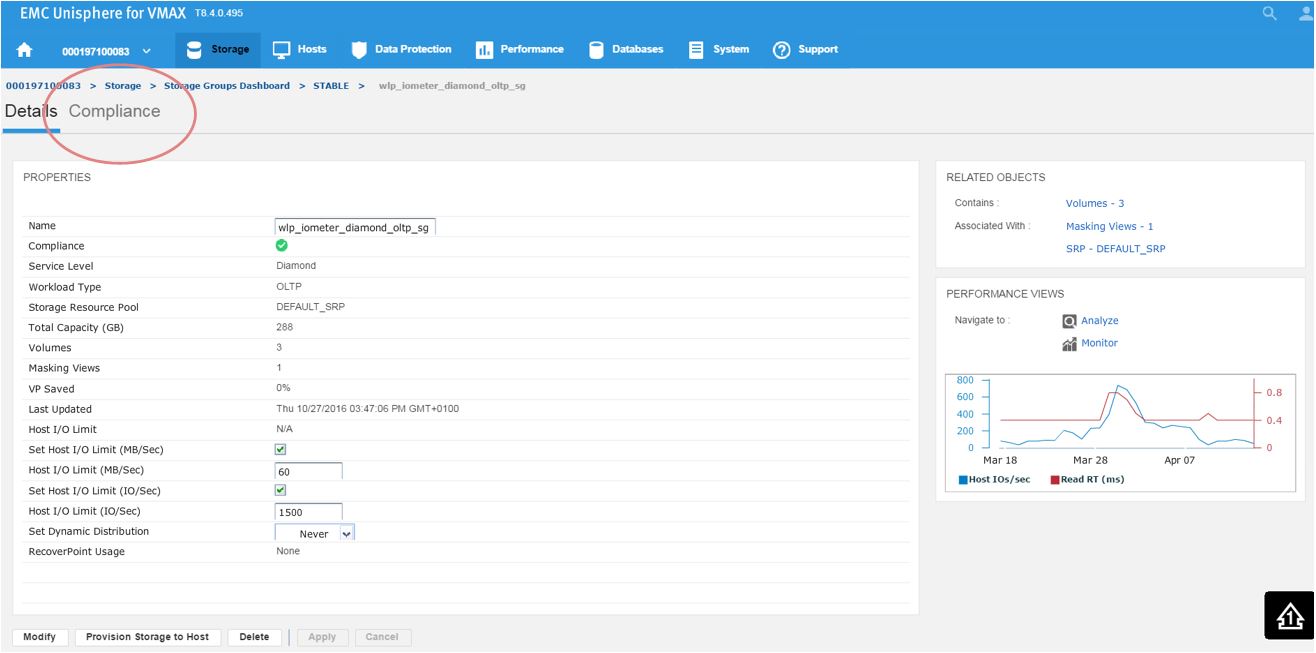
Figure 3. Storage group Details view
Here, we get greater detail on the current compliance state of the SG. We can see that it has a Diamond SLO which is stable. Currently, its capacity trend is flat, however we can also see how our response times over the windows of time. Additionally, we can review how the SG is performing compared to when it was first created.
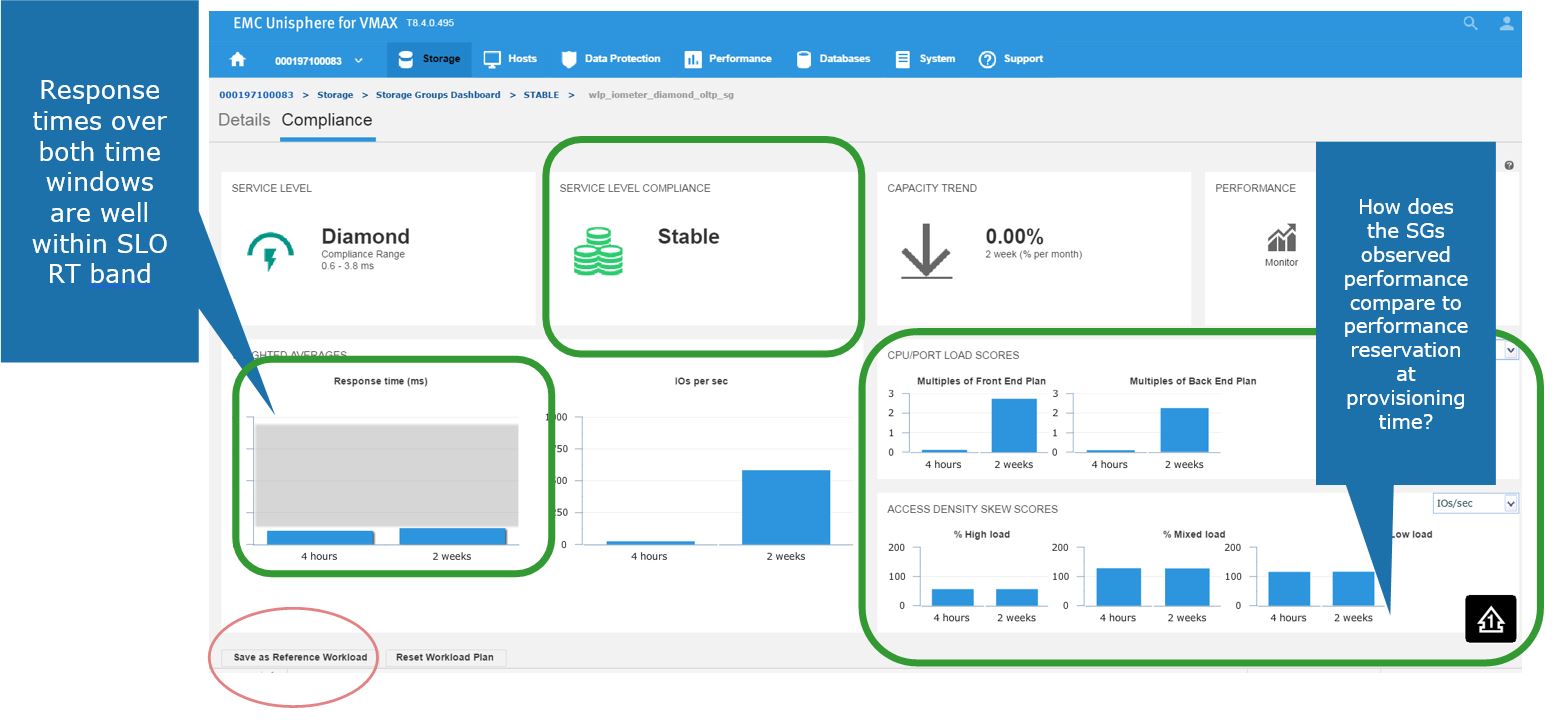
Figure 4. Storage group Compliance view
Saving a favorite reference workload
Here, we also have the ability to save this as a reference workload. For example, this SG is being used for an Oracle database, and we are happy with its performance and configuration since we rolled the application out into production.
Let’s leverage Unisphere to keep this workload for use in the future.
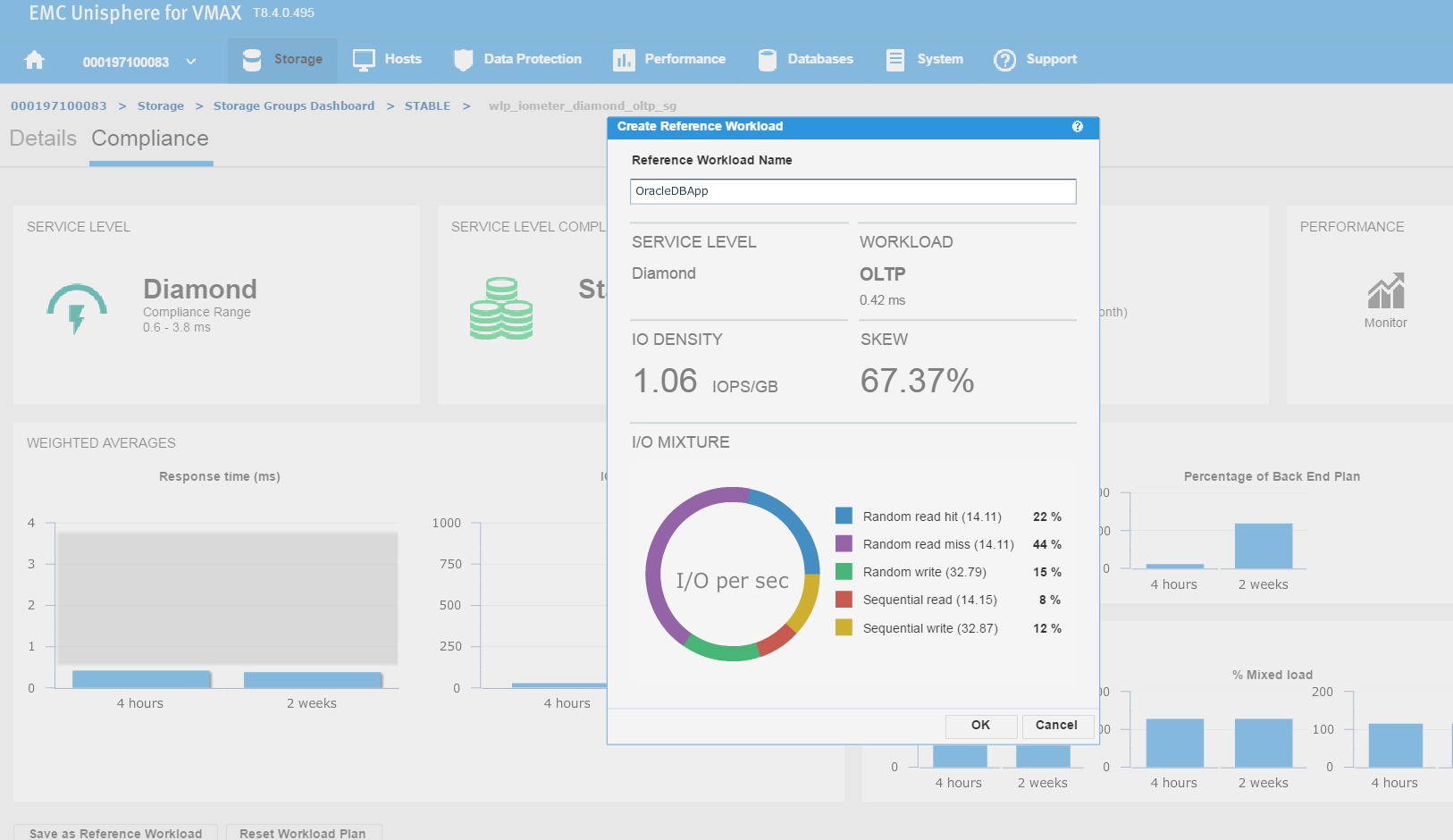
Figure 5. Create reference workload
We have named the workload OracleDBApp, so we can use this as a reference point when we roll out a similar Oracle Application with the breakdown of read and writes in terms of I/O.
Continuing along, let’s first verify that our workload type was saved correctly. To do this, go to Storage > Service Level, and select the Workload Types tab.
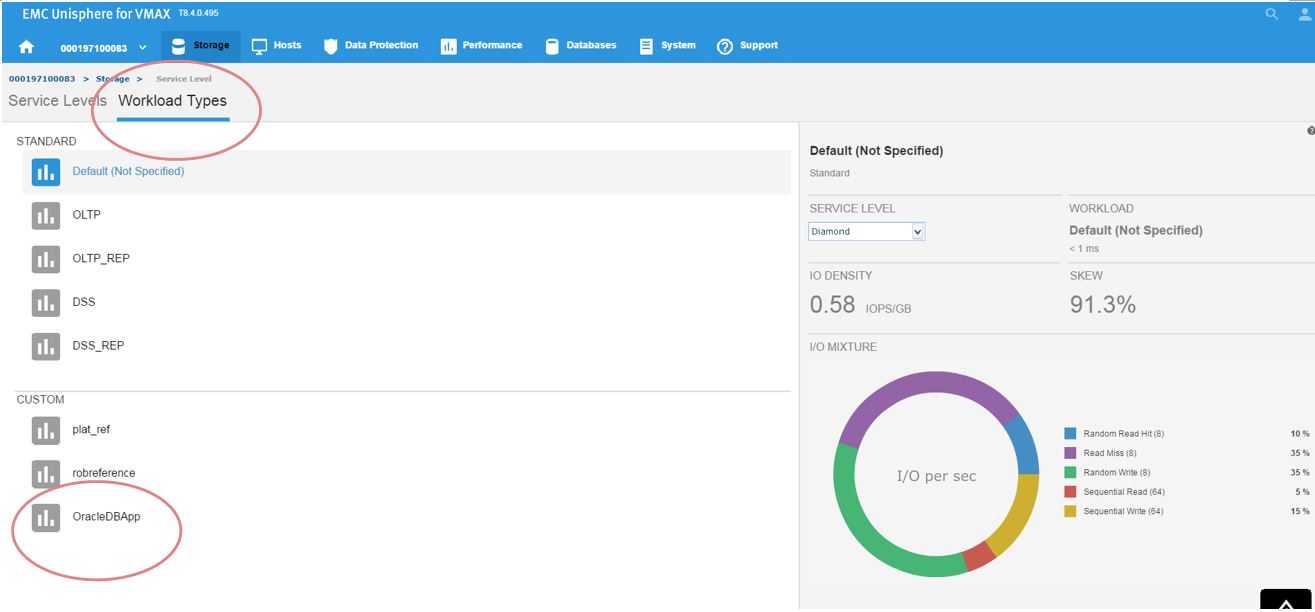
Figure 6. Save workload type
Now, we can see the reference workload we have customized in OracleDBApp. Since we are satisfied with the configuration of this application’s performance, we can leverage this workload type for use in the future when rolling out similar type applications.
Let’s see how we can use this in the provisioning wizard.
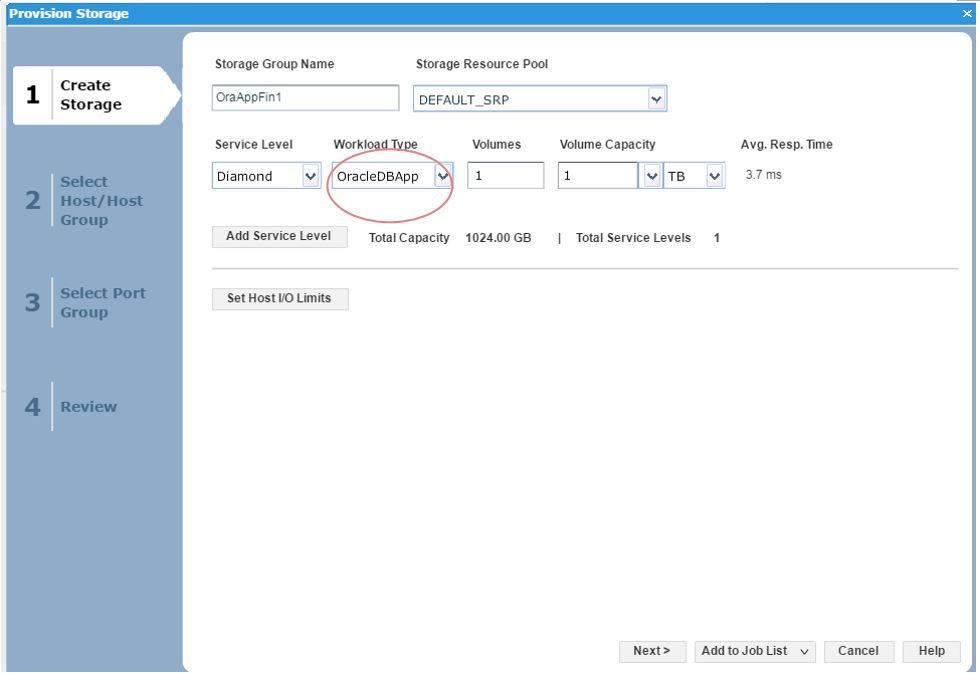
Figure 7. Create storage group view
Here, we can see that as we have received another request from our finance team for a new SG, so we decide to choose the workload type we had previously customized as a reference point and use this for the new SG.
Investigating an SG compliance issue with WLP
Let’s begin with a realistic scenario. One of our application teams contacted us over an issue with an SG, and they wanted us to investigate further to see if it has had any compliance issues in the recent past. Let’s begin with looking at the SG compliance report.
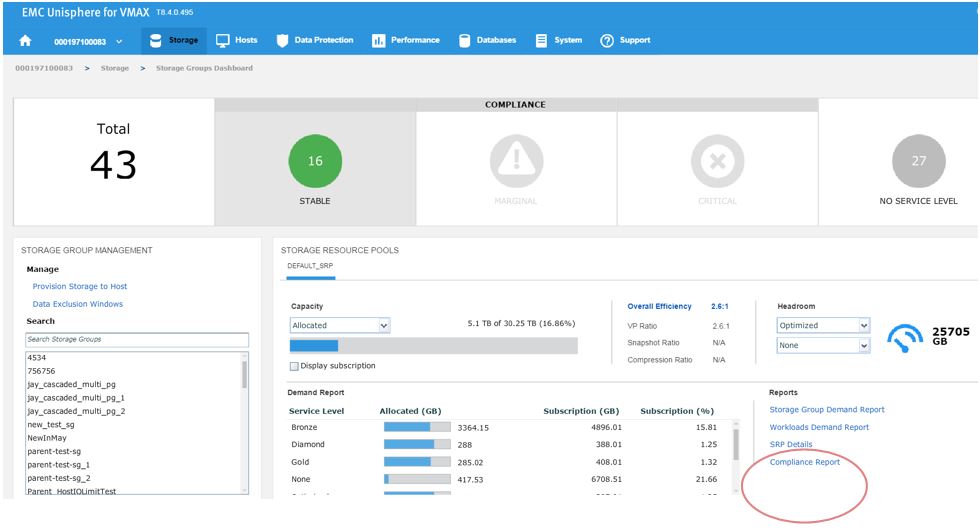
Figure 8. Storage group compliance view 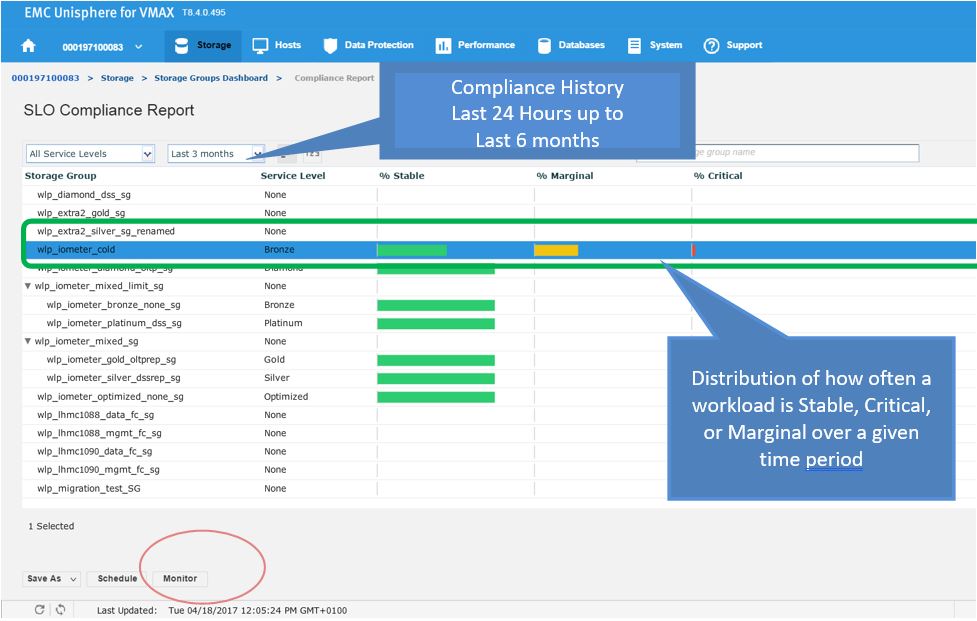
Figure 9. Storage group compliance issue
Here we see for the SG wlp_iometer_cold, we had a compliance issue in the last 3 months, with some being in a marginal state and some being in a critical state. If we select the SG, we have the option of saving the report off for reference or to potentially show to the application owner. We can also select Monitor, which will launch us directly into the Performance section of Unisphere shown in the following figure where we can check specific metrics.
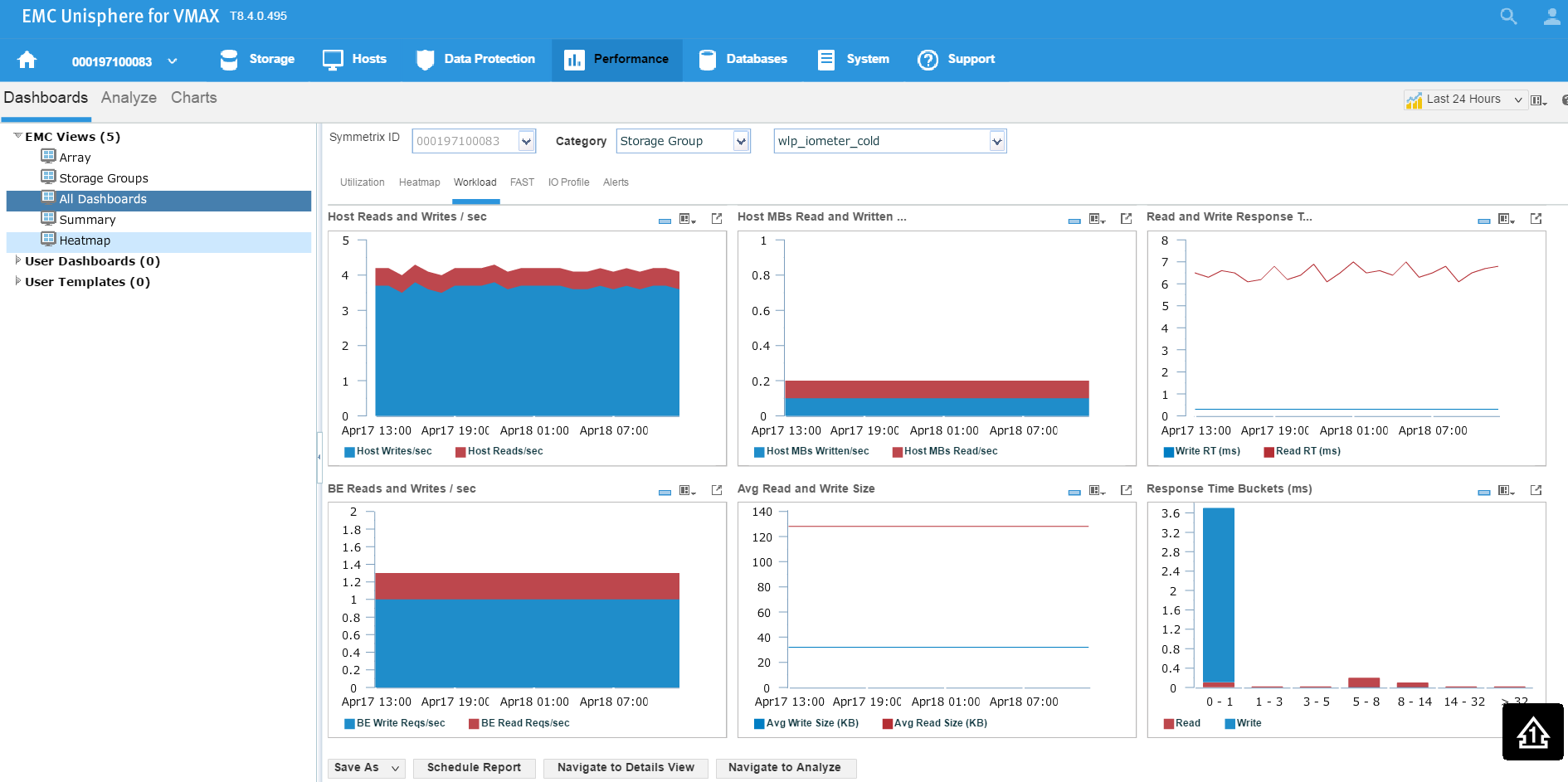
Figure 10. Storage group performance view
Examining headroom for Service Level and Workload Type combinations
In this section, I will be covering how to examine the available headroom for various Service Level and Workload Type combinations. Also, I will show you how to run a suitability check while provisioning more storage to an existing storage group.
The headroom available shows the space available for a certain combination of service level and workload type if all the remaining capacity was on that type. Here, I wanted to show you two examples for different service levels to showcase the calculation change.
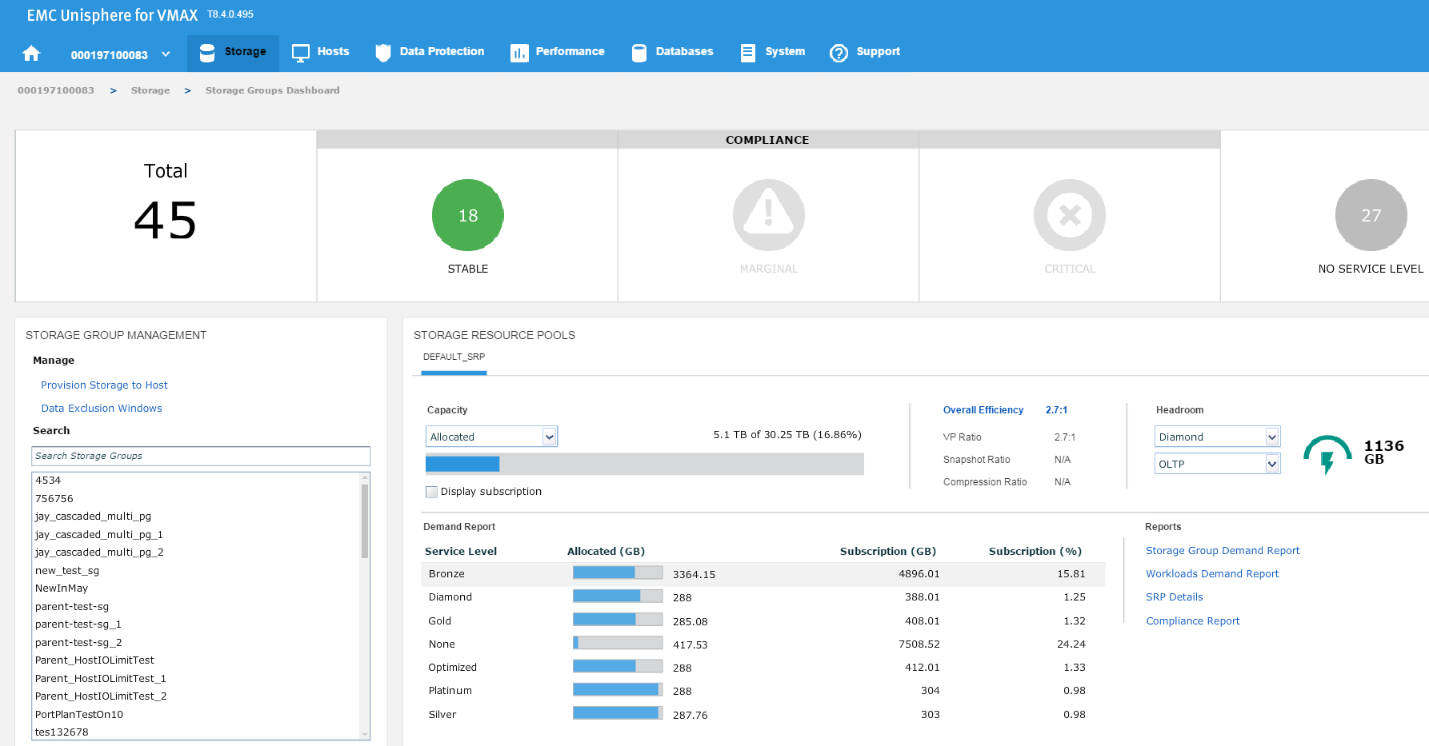
Figure 11. Storage group compliance view
In this example, we have chosen a Diamond SLO and an OLTP workload, which allows us free space of 1136 GB with that combination for that array. Let’s change the parameters, and see what happens.
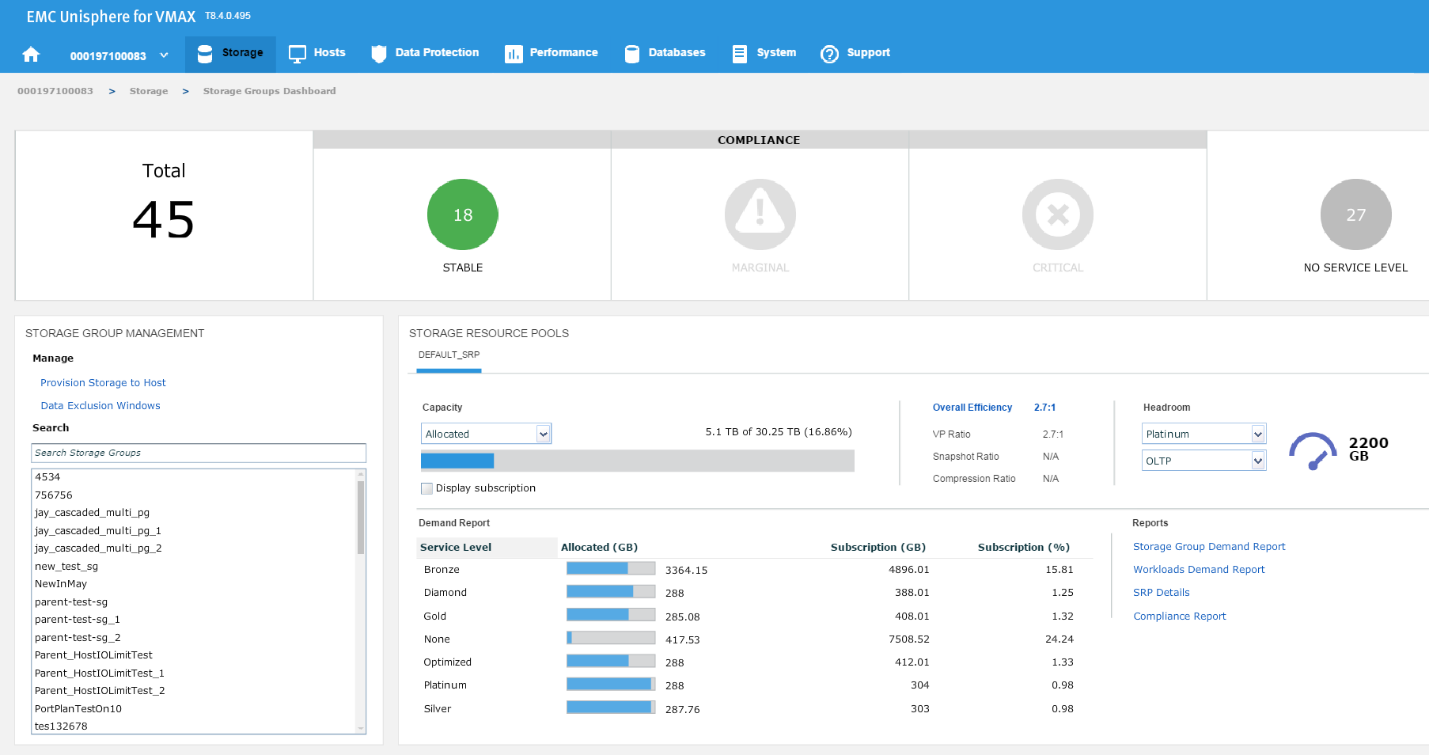
Figure 12. Storage group resource pools view
Now, we have 2200 GB of space available at a platinum level, which is almost double the capacity we had at Diamond level. These can be useful indicators of when we have an array that is nearing capacity as we can gauge which of our most important applications can go on to which SLO so we can maximize the efficiency of our storage.
Expanding the capacity of an existing SG
Now, let’s examine how we can expand the capacity of an existing SG while checking its suitability through the provisioning wizard. Let’s start at the SG list view in the storage group dashboard. We select our SG and then click on View Details.
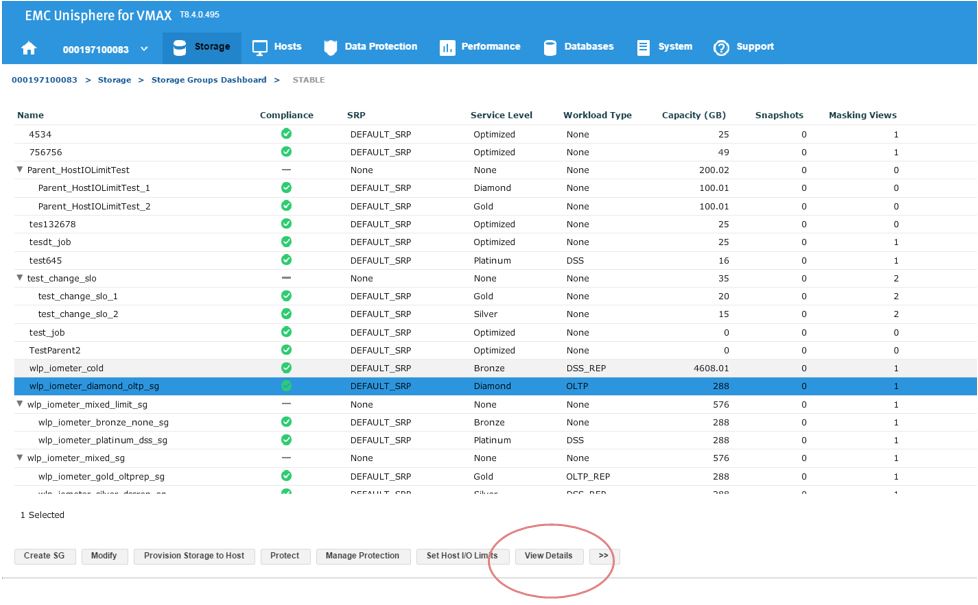
Figure 13. Storage group dashboard view
This will take us to the Details view of the wlp_iometer_diamond SG, which is the SG we want to expand. We then select Modify to start the process.
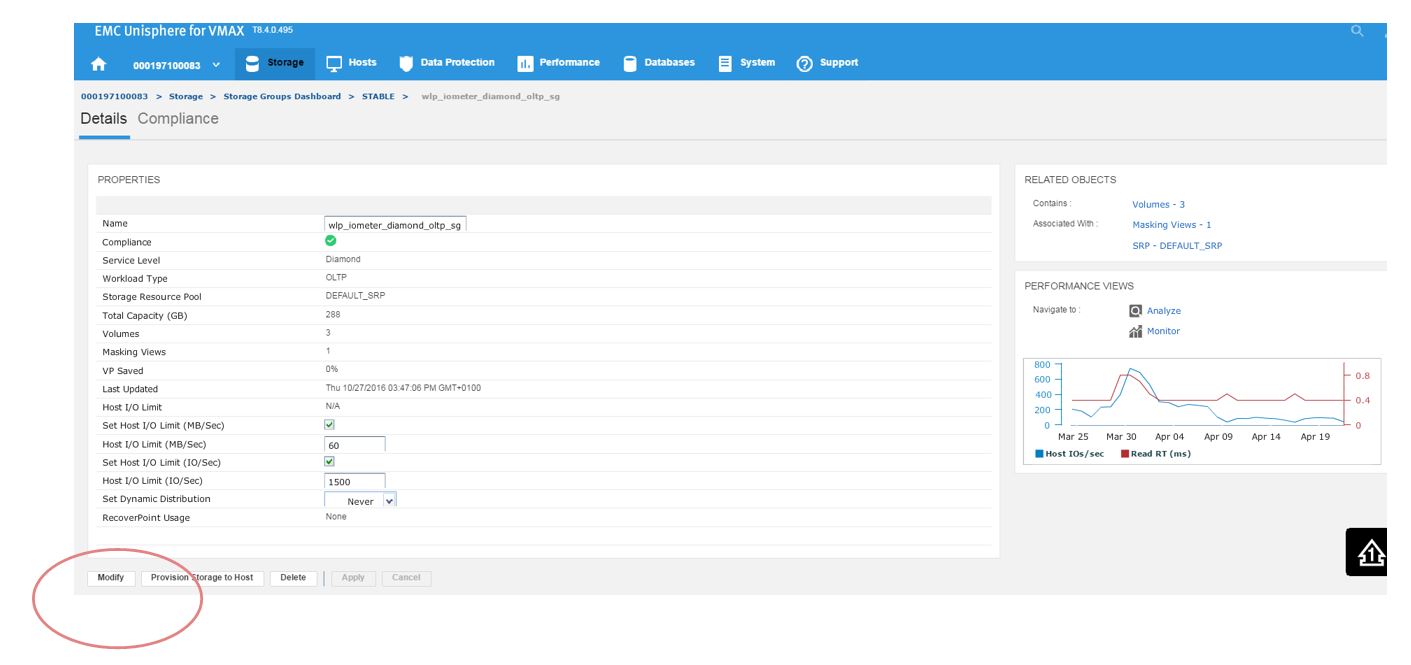
Figure 14. Storage group properties view
This launches the Modify Storage Group wizard shown in the following figure. We have received a request from the application owner that they need additional storage, however we wanted to be sure prior to allocation that they will not breach their SLO compliance nor experience any performance problems.
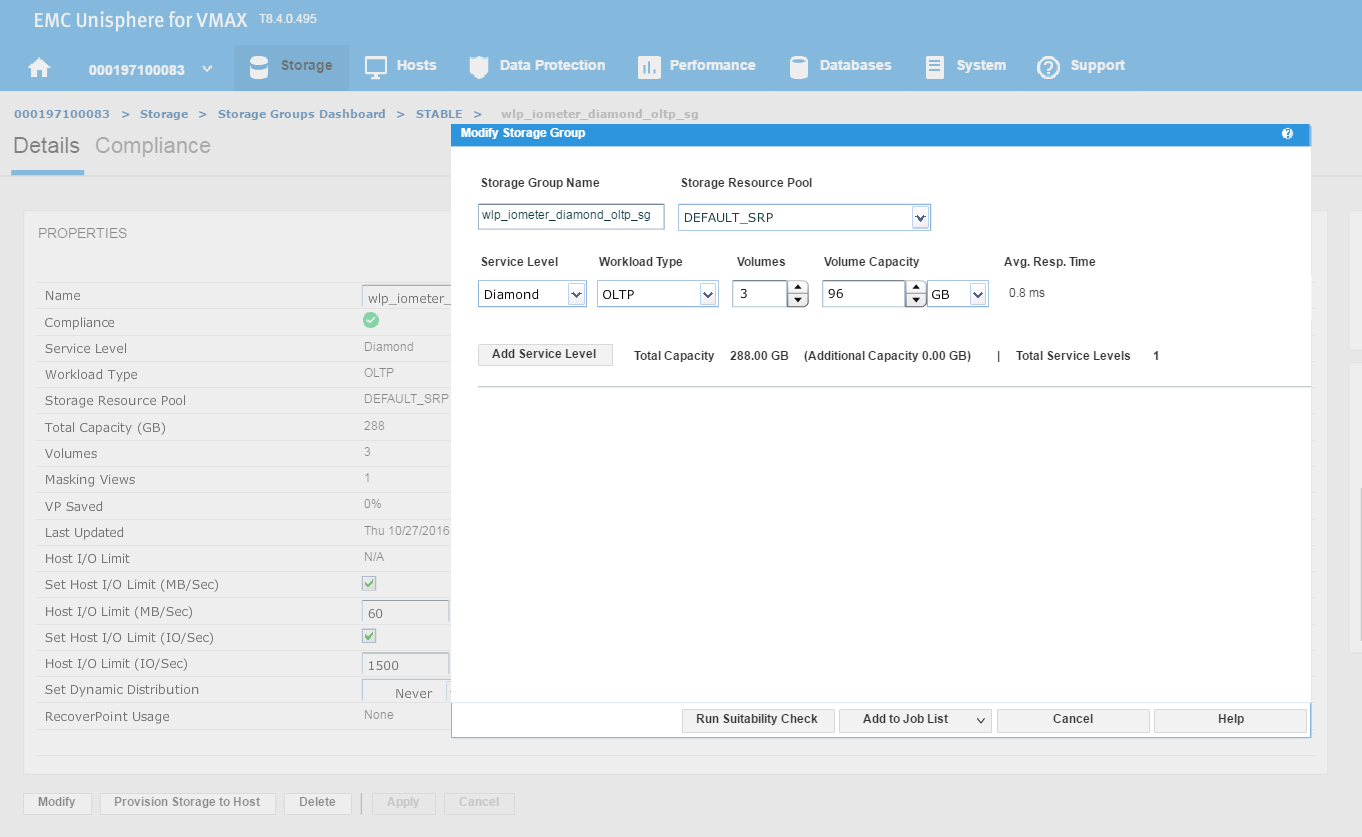
Figure 15. Modify storage group view
We have agreed with the application owners to grant them an additional 96 GB of storage, which will expand their capacity by roughly 25%. This allows us to increase the number of volumes by 1, and then select Run Suitability Check to verify this change won’t affect the performance of the SG adversely.
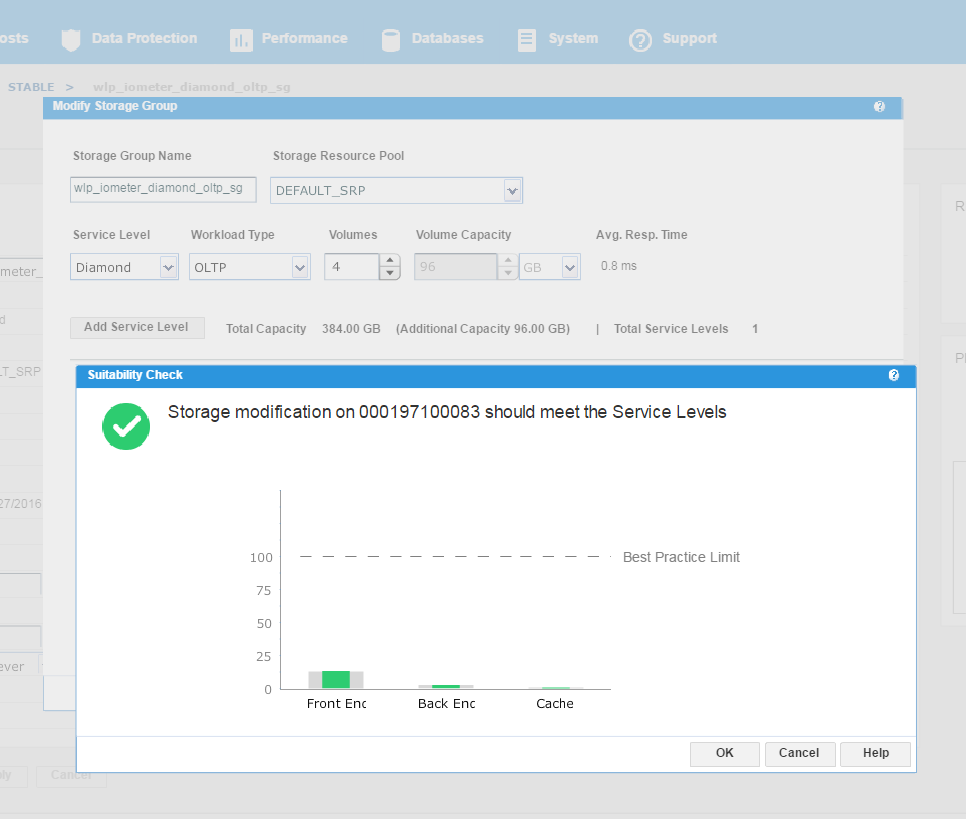
Figure 16. Storage group service levels view
We can see that the check has completed successfully and that increasing the capacity of the SG will not have any adverse effects on its performance. This promotes good housekeeping in terms of the storage array as we prevent poor configurations from being rolled out. At this stage, we can select Run Now and add to the job list to run later.
Data Exclusion Windows
In this section, I will be covering how to manage Data Exclusion Windows. This procedure explains how to manage Data Exclusion windows for calculating headroom and suitability.
Peaks in storage system statistics can occur due to:
- Anomalies or unusual events
- Recurring maintenance during off-hours that fully loads the storage system
Due to the way this data is condensed and used, unexpected headroom and suitability results can occur. There are two ways to improve the handling of these cases:
- One-time exclusion period – When the one-time exclusion period value is set, all statistics before this time are ignored. This helps resolve anomalies or unusual events where a significant one-time peak distorts the results due to reliance on two weeks of data points. This is set system wide for all components.
- Recurring exclusion period – You can select n of 42 buckets to use in admissibility checks. This is set system wide for all components. Recurring exclusion periods are repeating periods of selected weekday or time slot combinations where collected data is ignored for the purpose of compliance and admissibility considerations. The data is still collected and reported, but it is not used in those calculations.
Let’s begin at our usual starting point, the storage group dashboard, by selecting the Data Exclusion Window.
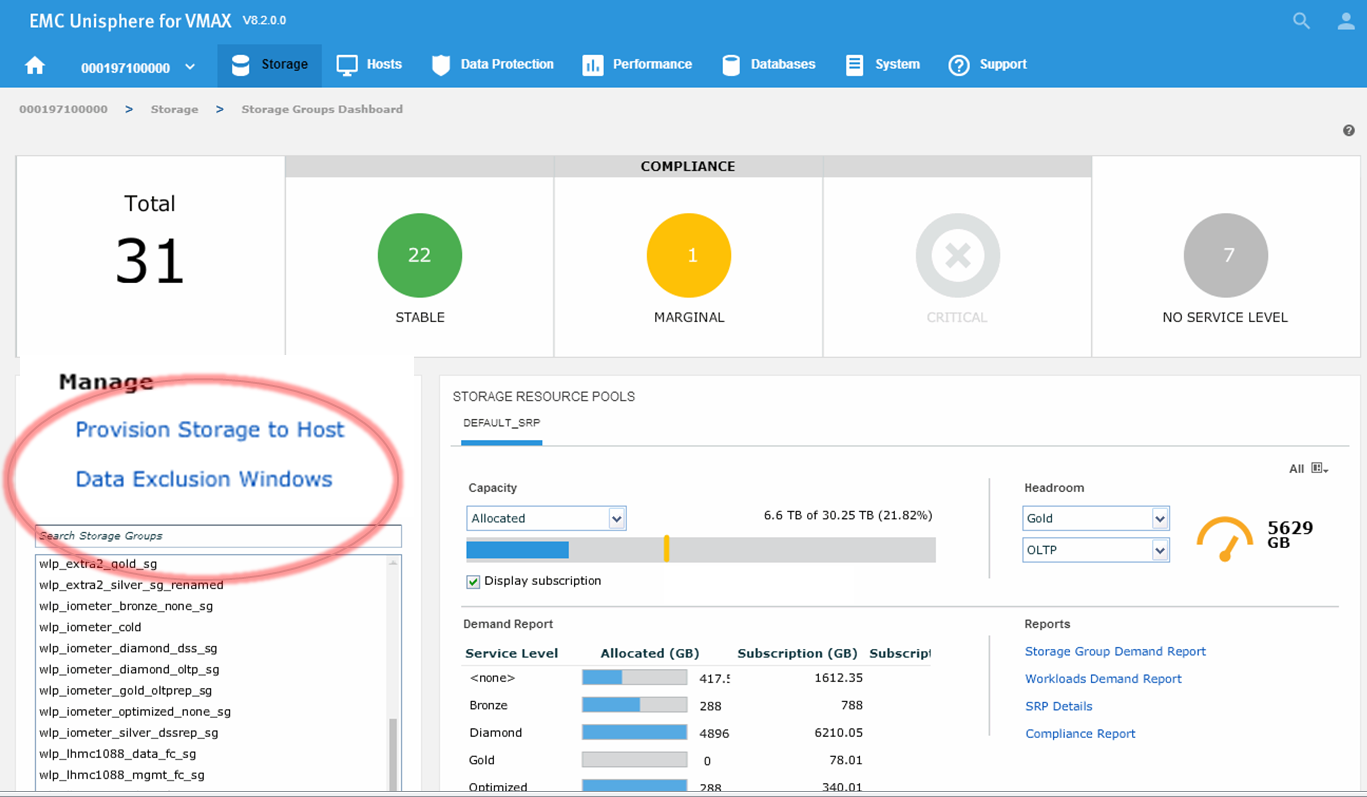
Figure 17. Data Exclusion Windows
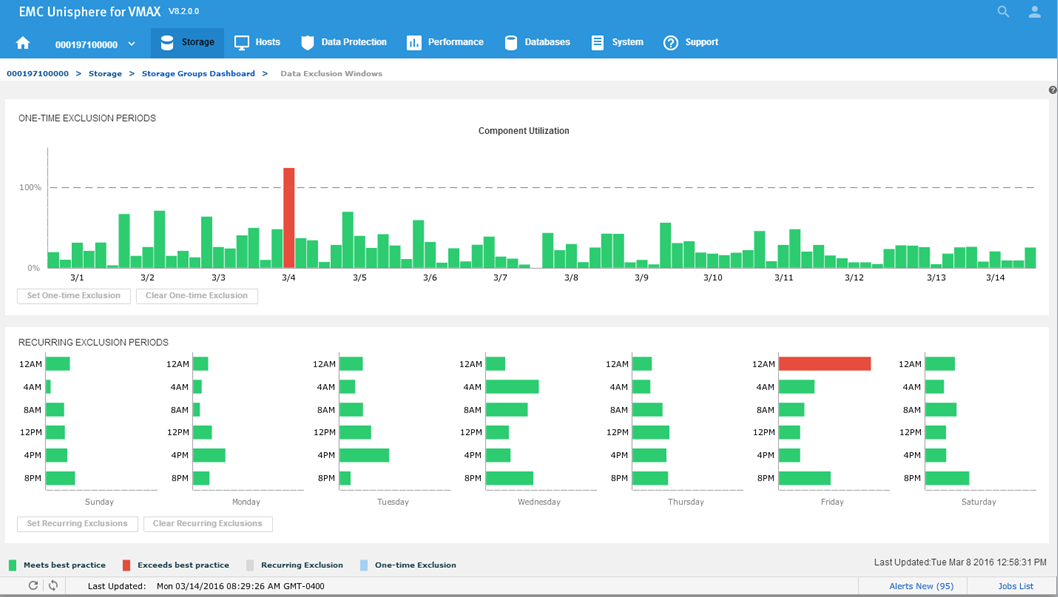
Figure 18. Data Exclusion Windows
All the component utilizations for the prior two-week period are compared, and the greatest (with respect to its individual best-practice limit) is displayed across the top of this display. Each weekly time period, represented by two bars in the top display, is also displayed across the bottom.
Now we will set a one-time exclusion window. When you click on the tallest bar in the top display, all history up to that time is shaded. You can then select Set One-time Exclusion so the bottom display panel is recalculated excluding that time frame.
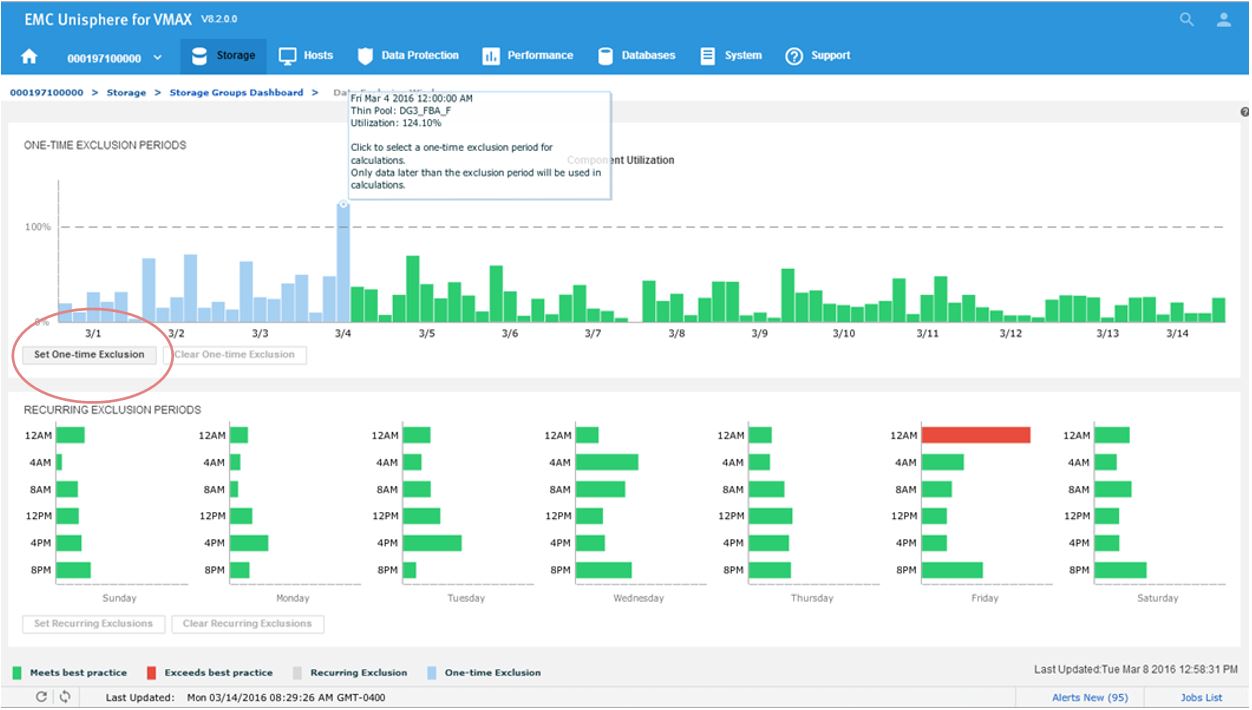
Figure 19. Data Exclusion time window view
After setting the exclusion, you can now see that at 12 a.m, we are green in the bottom panel as we have chosen to ignore that specific timeframe in our calculations.
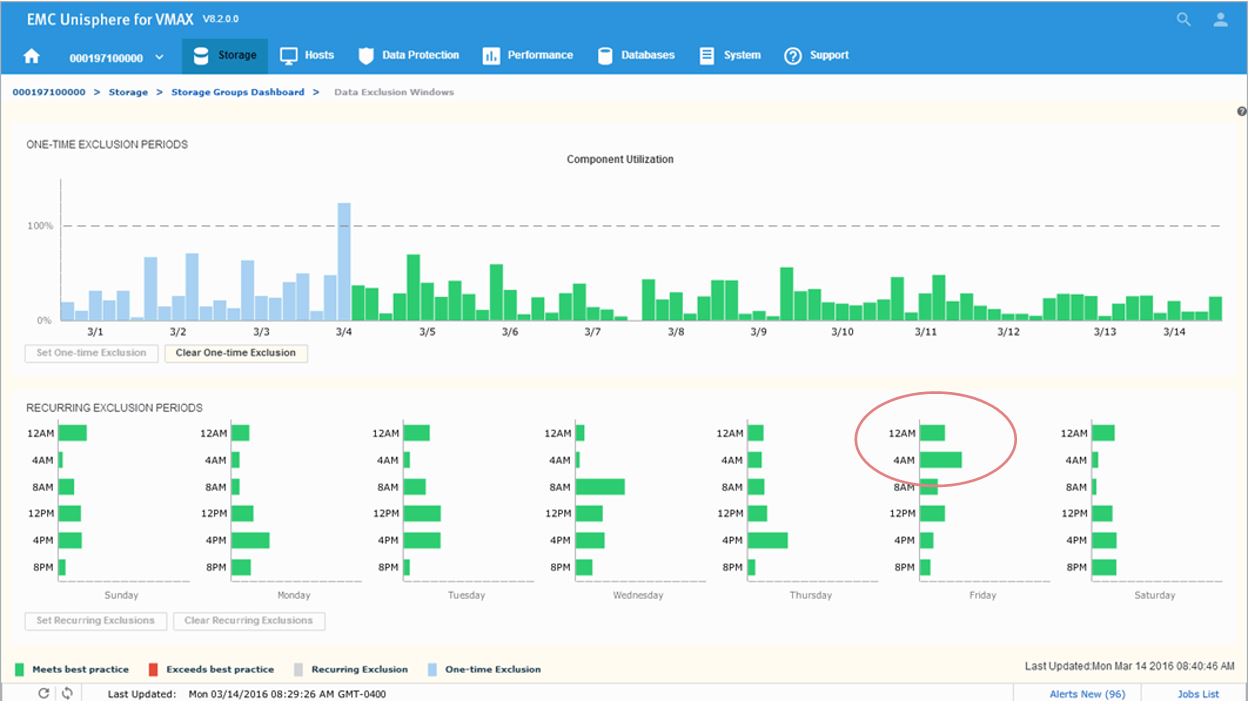
Figure 20. Data Exclusion Windows time view
Next, we will look to set a recurring Exclusion window:
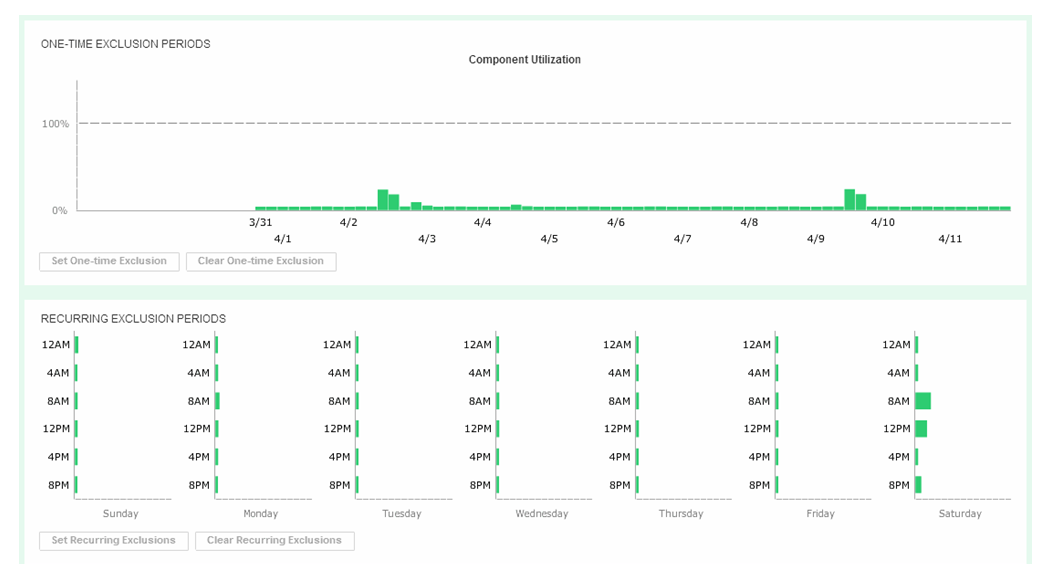
Figure 21. Set recurring Data Exclusion Window
If you click on the bars in the bottom display, their state will toggle, shading themselves and the two corresponding bars in the top display to set any weekly period to be excluded from all suitability and headroom calculations from there on for the future.
FAST Array Advisor
In this section, I will be covering how to leverage FAST Array Advisor to see if you could move workloads between arrays. The FAST Array Advisor wizard determines the performance impact of migrating the workload from one storage system (source) to another storage system (target). If the wizard determines that the target storage system can absorb the added workload, it automatically creates all the necessary auto provisioning groups to duplicate the source workload on the target system.
Let’s pick a suitable SG PF_NDM_2_SG and select the More Options button.
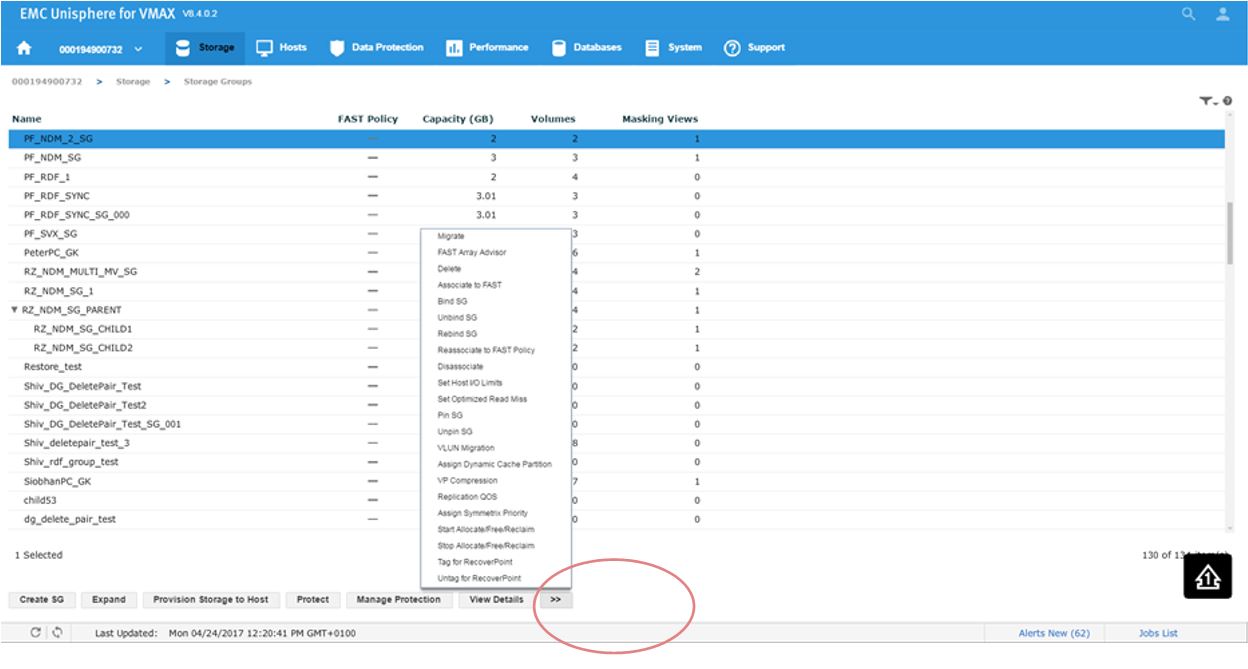
Figure 22. Storage group selection view
This will present us with a series of options. Second from the top, we see FAST Array Advisor, so we select that.
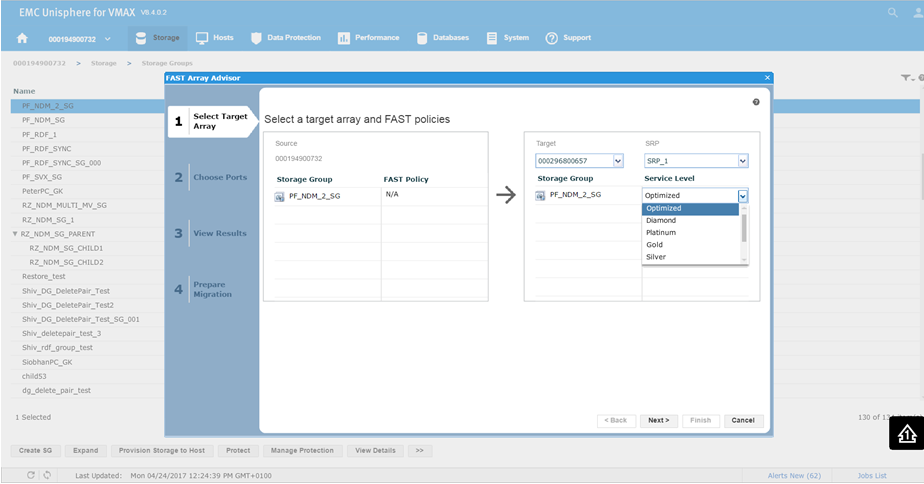
Figure 23. Select target array view
This will bring us the wizard where we select the source and target array. In this example, 0732 is a V1 running 76 code, and we want to look at the possibility of moving it to 0657 which is a V3 running 77 codes. This is viewed in terms of a migration of the SG off the older source array and on the newer target array. You can see that on a V1, we did not have service levels, however we can set them on our V3 array. For this example, we choose a Silver SLO and click Next.
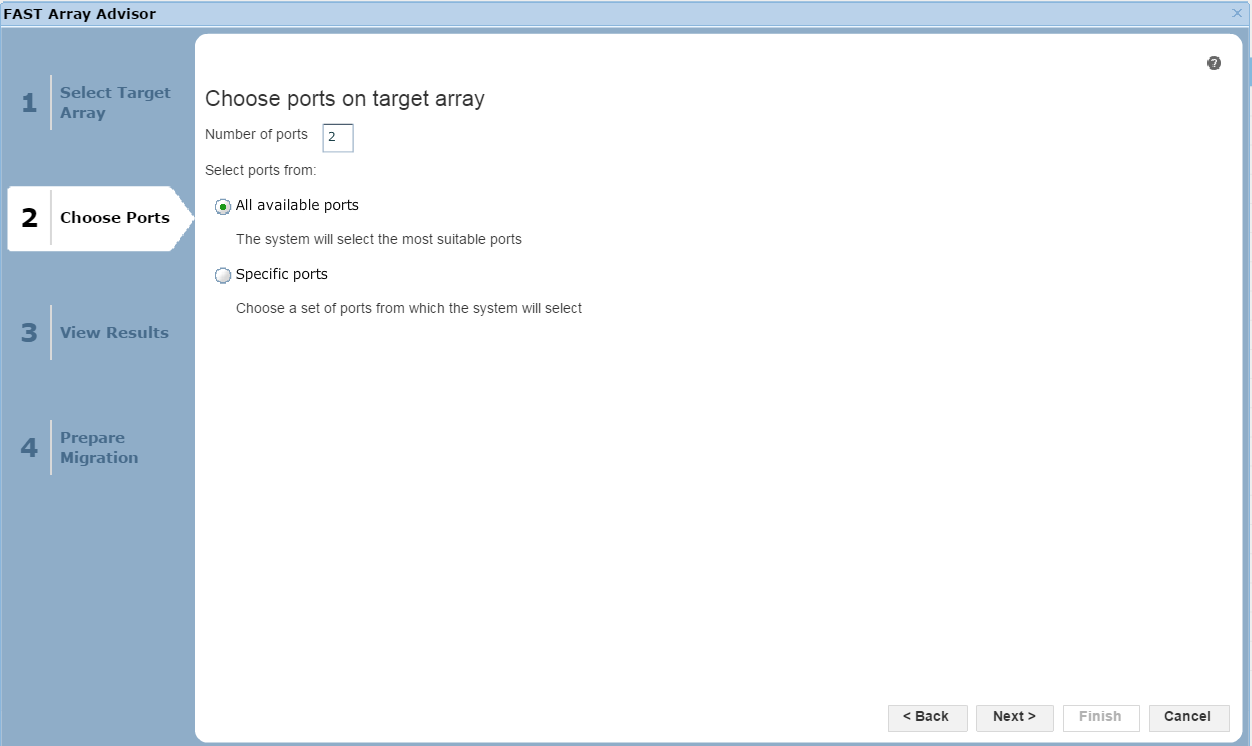
Figure 24. Port selection view
In this section of the wizard, we have the option of allowing Unisphere to choose the most suitable ports based on how busy they are, or we can select specific ports if we like. Click Next to view the results.
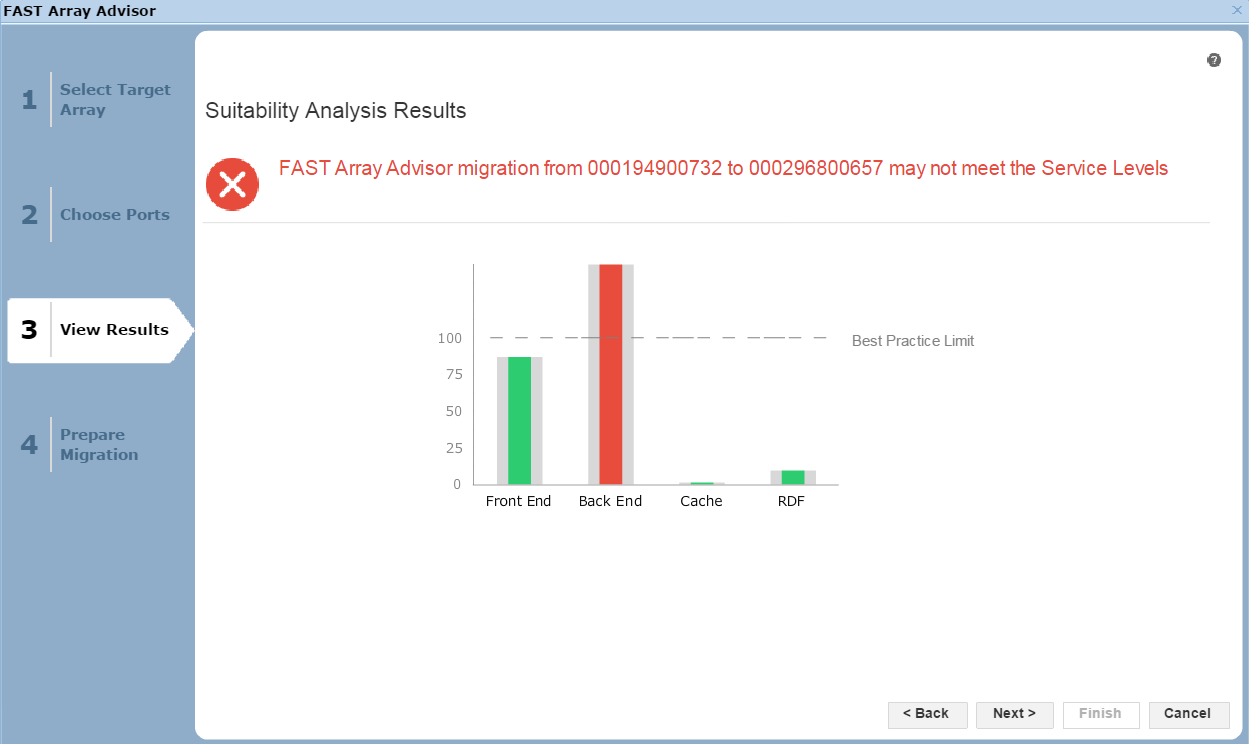
Figure 25. Suitability analysis view
Here, we see the results of the potential migration. The front end, the cache utilization, and the RDF impact all look fine. That said, in the back end, we would exceed our Best Practice Limit, so we may suffer from contention and performance issues as a result. It would be up to the individual customer to proceed in these circumstances, however we would recommend adhering to best practices. In this case, let’s select Next to view the final screen of the wizard.
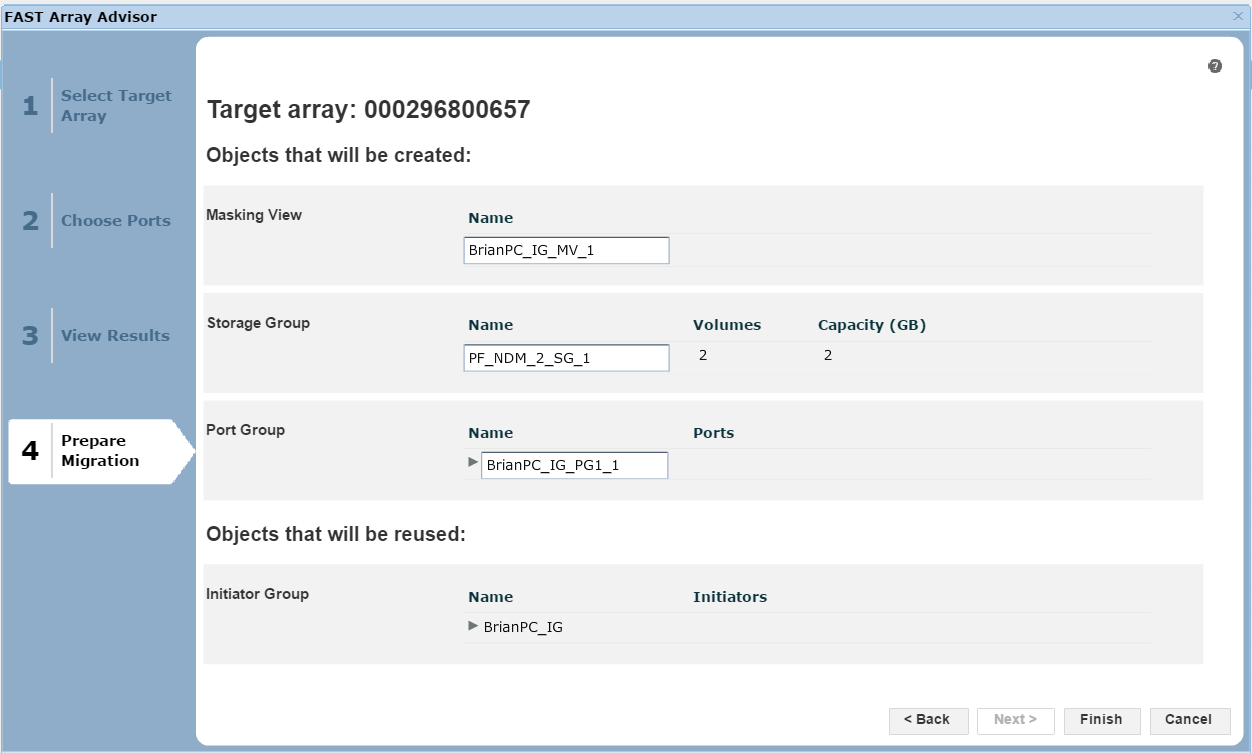
Figure 26. Prepare migration view
Here, we are presented with a summary of the migration if we were to go ahead, listing what objects, such as the masking views, storage groups and port groups, would be created on the target array 0657. At this point, we can click Finish to begin the migration.
Author: Finbarr O’Riordan, ISG Technical Program Manager for Transformation