




What’s New in PowerMax REST API 10.0

Unisphere for PowerMax 10.0 has been released, bringing support for the new PowerMax 2500, and 8500 models, and a host of other improvements in the updated API.
Documentation for all Dell APIs are viewable from https://developer.dell.com. The PowerMax documentation features a “What’s New” section, with links back to the latest REST API change log on our support pages. REST API documentation is linked directly from the UI Help, making it easier to find.
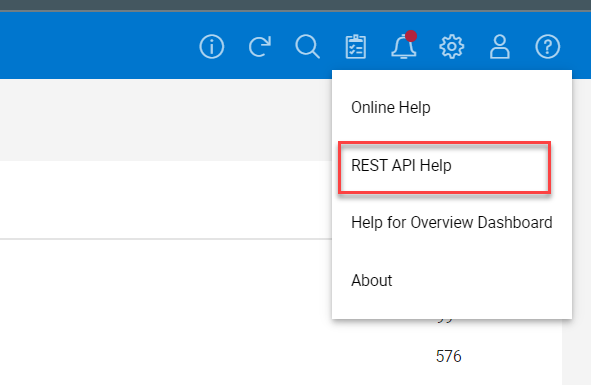
The documentation can also be downloaded in OpenAPI.json format from the overview tab, using the export button as shown.
As with previous releases, the new API is accessible under new versioned endpoints:
https://unisphereIP:8443/univmax/restapi/100
Older versions of the API are still available with N-2 versions of the API. This means that you can use version 9.2 or version 9.1 API calls with a server that is running Unisphere 10.0.
A big change is that VMAX 10K/20K/40K arrays are no longer manageable using the 10.0 REST API because Unisphere 10.0 no longer supports them. You’ll notice when looking at the API documentation that the provisioning endpoint no longer exists under the 100 resources. Provisioning tasks on the PowerMax and VMAX3 arrays are still managed through the sloprovisioning endpoints, so this has no impact on the newer model arrays.
Front End Emulation Convergence. “What is that?” I hear you say. On the new platforms we no longer have separate RDF and FA/SE Directors. Instead, we have a single emulation that supports ports that can be enabled for the required function. This is a new director type, the OR, short for Open Systems and Replication. With OR director ports supporting different protocols, we need to apply new filters when listing ports to find out which ones are enabled for which protocol.
https://ipaddress:8443/univmax/restapi/100/sloprovisioning/symmetrix/symmetrixId/port?enabled_protocol=RDF_FC
Another change: when listing ports with sloprovisioning API calls, the calls no longer return internal and back end ports. Because the user can never use these anyway, it’s really just removing noise from the API which in general is a good thing. If you do want to identify any back-end directors and ports on your system, you can use the system level director calls to get this information.
With PowerMax 8500 and 2500 models, creating port groups now requires an additional key that specifies the port group protocol: either SCSI_FC, iSCSI, or NVMe_TCP.
https://ipaddress:8443/univmax/restapi/100/sloprovisioning/symmetrix/000120000322/portgroup
{
"portGroupId": "finance1_portgroup",
"port_group_protocol": "SCSI_FC",
"symmetrixPortKey": [
{
"directorId": "OR-1C",
"portId": "1"
}
]
}Local replication changes
The replication resource of the API has some notable changes. We’ve introduced new API calls for creating TimeFinder Clones with storage groups. Check out the very good blog Attack of the Clones that details what you can expect with clones. It also covers why we are bringing new features for clone into the new PowerMax 8500 and 2500 arrays, in addition to the SnapVX features we already have in the API. Note that the Clone API calls can be used with existing models of PowerMax and with the new arrays. However, the increased scale and a new “establish_terminate” feature (which creates a clone copy and immediately removes the session when pointers are in place) is only available on arrays running PowerMax OS 10.
Under the hood for replication calls here are some invisible but beneficial changes. In previous releases, REST calls referenced the Unisphere Object model for some information. Now with Unisphere 10.0, the API calls for replication make solutions enabler API calls to ensure that the information returned is always in tandem with the array.
Performance API changes
The performance section of Unisphere has had significant changes, mostly to make it easier to use for new consumers. Our developers have added several helper methods to enable you to list performance categories for your array type.
https://ipaddress:port/univmax/restapi/performance/Array/help/SystemSerial/categories
When you have built your list of categories, you can use the category metrics helper calls to find the list of supported metrics for each category. You can specify a type for All or KPI:
https://ipaddress:8443/univmax/restapi/performance/Array/help/symmetrixId/category/metrics/type
Another big change in our performance metrics is that you can now get device level diagnostic statistics. These can be collected for a range of devices, or a list of storage groups: up to 100 storage groups per query or 10,000 devices per query. Each query is limited to one hour of performance data. These limits are to prevent developers from unwittingly creating very intensive long ranging queries that may impact other API or UI users. Note: This change relies on the Unisphere version only. The array model is not a factor in usage. So if you are running VMAX3 Hybrid or the latest PowerMax, if Unisphere is at 10.0 or higher, you have this functionality available to you in the API.
A sample call and payload is listed below. You can use the volume category with the helper methods above to determine valid categories. As with all performance calls, timestamps are in EPOCH timestamp milliseconds.
https://ipaddress:port/univmax/restapi/performance/Volume/metrics (POST)
{
"systemId": "0000213456789",
"volumeStartRange": "00A1",
"volumeEndRange": "00A5",
"dataFormat": "Maximum",
"startDate": 123456468,
"endDate": 123456465,
"metrics": [
"HostMBs",
"MBRead",
"MBWritten",
"IoRate",
"ResponseTime"
]
}New file API interface for PowerMax
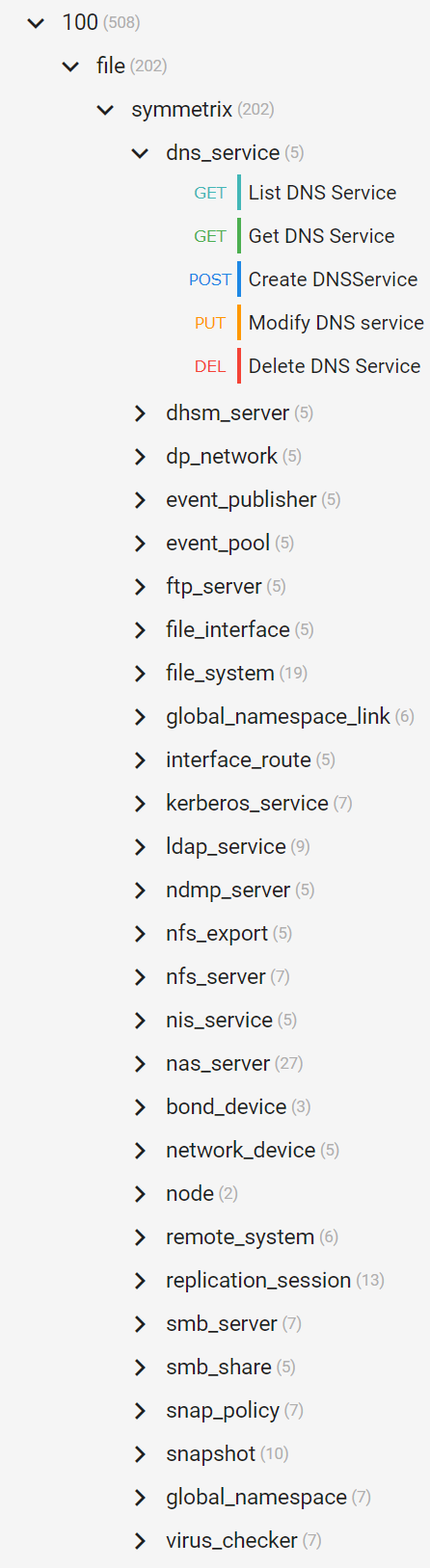
With the new 64 Bit SDNAS Platform integrated with PowerMax File API, we now have a whole new set of endpoints for Day0 to Day2 operations with file objects. The API has more than 200 API calls for file operations. All file operations can now be completed with either the UI or REST, giving 100% coverage of the product. The following figure provides an outline of the API which can be browsed in the online documentation.
PyU4V – the SDK for PowerMax API
With a new API we are also releasing PyU4V 10.0, which is only compatible with Unisphere 10.0. Because Unisphere is backward compatible with the API, you can still use PyU4V version 9.2.1.6 with Unisphere version 10.0. Any scripts written at previous versions of PyU4V are forward compatible, assuming that you are not using any depreciated functions. (PyU4V has provided warning messages for the last two releases to notify users if their scripts need to be changed for forward compatibility, so we hope there are no issues!)
Ansible support for PowerMax API 10.0
Updated Ansible modules will be released in September with full support for new arrays. In the meantime, you can update any Unisphere server to version 10 and existing Ansible modules will continue to function, providing that your Ansible server has the latest PyU4V version installed (either 9.2.1.6 or 10.0 with Ansible collection for PowerMax <=1.8).
Author: Paul Martin, Senior Principal Technical Marketing Engineer
Related Blog Posts

RESTing on our Laurels - What’s New with the PowerMax API and Unisphere 10.1
Tue, 17 Oct 2023 13:12:28 -0000
|Read Time: 0 minutes
Unisphere 10.1 has just been released! Although the internal code name was Laurel, we are doing a lot in the API, so we definitely haven’t been RESTing on our laurels!
With this release the Unisphere for PowerMax team focused on what could be done better in the PowerMax API, to make things easier for developers and to reduce the amount of code people must maintain to work with the PowerMax API. Personally, I think they have knocked it out of the park with some new features. These features lay the groundwork for more of the same in the future. As always, there is a full change log for the API published along with updated OpenAPI documents available on https://developer.dell.com. In this blog I provide my own take and highlight some areas that I think will help you as a customer.
Let’s start with the traditional Unisphere for PowerMax API. With this new version of Unisphere there is a new version of the API and simpler versioning referencing throughout the API. For example, the following GET version API call returns the api_version (in this case, 101), and the currently supported API versions with this release (101, 100, and 92). As always, the previous two versions are supported. Here, the supported_api_versions key takes any guesswork out of the equation. If you are using PyU4V, a new version (10.1) is available, which supports all of the new functionality mentioned here.
https://Unisphere:8443/univmax/restapi/version (GET) { "version": "T10.1.0.468", "api_version": "101", "supported_api_versions": [ "101", "100", "92" ] }
I’ll break the other changes down by functional resource so you can skip any that you’re not using:
- Serviceability API calls
- Replication Call Enhancements
- Sloprovisioning Call Enhancements
- System Call Enhancements
- Performance API Call Enhancements
- The All New Enhanced PowerMax API – Bulk API calls
Serviceability API calls
For embedded Unisphere for PowerMax users, when the system is updated to the latest version of Unipshere, a new Serviceability API Resource becomes available.
The new serviceability API calls (as shown in the following figure) give control over the embedded Unisphere, providing access to solutions enabler settings, and Unisphere settings that up until now have only been accessible in the UI, such as:
- Setting up the nethosts file for client/server access from CLI hosts running Solutions Enabler
- Host based access control
- Certificate Management of the Solutions Enabler Guest OS
- And more
Here’s the tree of the Serviceability API resource:

Note: When executing API calls to update the Unisphere application, the server will restart as a result of these changes. You must wait for these to complete before you can issue more API calls. Also, as a reminder, if you are changing the IP address of the Unisphere server you must update your API connection for future calls.
Replication call enhancements
Good news for customers using snapshots and snapshot policies. New replication calls and keys will make the management workflows easier for anyone automating snapshot control and using policies.
An updated API call adds keys for directly associated policies vs inherited policies:
101/replication/symmetrix/{symmetrixId}/storagegroup/{storageGroupId} (GET)In the API, identifying and tracking back linked snapshots has been time consuming in the past. Based on valued customer feedback, our product management and developers have implemented key changes that will help.
The ability to list storage groups that are linked targets has been there for a while, with query parameters in the following GET call:
101/replication/symmetrix/{symmetrixId}/storagegroup?is_link_target=trueHowever, finding out which snapshot was linked, and which source storage group owned that snapshot was a challenge. To make this easier, new keys now appear:
101/replication/symmetrix/{symmetrixId}/storagegroup/{storageGroupId} (GET)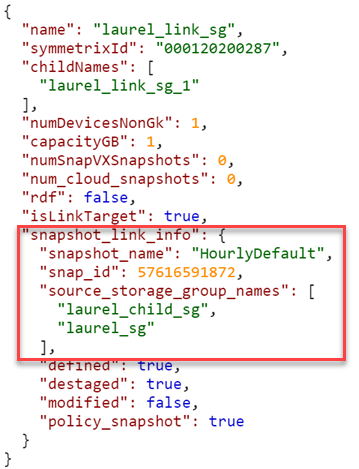
As you can see, the 10.1 API call returns a new key (snapshot_link_info) that includes all the information you need to be able to manipulate the linked snapshots, without having to engineer any trickery yourself.
Sloprovisioning call enhancements
Probably the single biggest change to the Provisioning API calls is the ability to Validate and return a Bad Request when the performance_impact_validation_option is set for sloprovisoning the /maskingview POST call. This gives the developer a way to check, at the time of provisioning, whether a workload is suited to run on the supplied PowerMax serial number. This call uses performance data from the workload planner database and can help create enhanced provisioning workloads with performance and zoning in mind.
The Payload can now accept a new key (performance_impact_validation_option) which can be set to:
- IfRecommended – Run performance impact tests. If no performance capacity threshold is breached, run the requested configuration change.
- Preview – Run performance impact tests and return performance impact scores for the requested operation. Return the input object (with generated fields, if applicable) for relevant follow up API calls.
In addition, the payload has a “portGroupSelection” key that can automatically create a new port group or use an existing port group based. If automatic selection is used, selection can be either UtilizationBased or ZoningBased. (Note: Automatic port selection is only available for Fibre (SCSI FC))
If you choose to use an existing port group, existing port groups are evaluated by the workload planner algorithms examining port groups that are already configured on the system. The algorithm will select the least loaded port group for the provisioning and ignore zoning. Users have the Option to restrict selection to a supplied list of port groups using the API keys. See documentation for details of the various keys.
Note: When using the performance impact selection, you can’t specify an existing storage group because it’s assumed that they are already provisioned. Full documentation for the API call mentioned is here with the supported parameters.
The provisioning API calls include other additions:
- Update POST for Create Masking View, to allow the specifying of a Starting LUN Address. This was a customer enhancement to make it easier to configure boot from SAN.
- Update PUT for Modify SG, to allow the specifying of a Starting LUN Address when adding volumes. .
- Update PUT for Modify SG, to allow terminating snapshots associated with volumes being removed from a SG in a single call. This is very useful because it prevents stranded snapshots from consuming space on the array.
System call enhancements
We have added system calls to enable the refresh of Unisphere. This is useful to customers who are working in a distributed environment and who want to ensure that Unisphere data is up to the second with the latest information. This should be the case, but in the event that there were changes made on a remote system, it could take a minute or so before these are reflected in the object model. The new refresh call has some guardrails, in that you can only run it once every five minutes. If you try to execute too soon, status code 429 will return with message telling you to wait for it to come back:
“Bad or unexpected response from the storage volume backend API: Error POST None resource. The status code received is 429 and the message is {'retry_after_ms': 285417}.”The documentation for this API call (/101/system/symmetrix/{array_serial}/refresh) is here.
Getting information about REST API resources and server utilization was previously only ever available in the user interface. It made sense to make this information available through the REST API because the information pertains to REST. The new GET call to obtain this information (/101/system/management_server_resources) is available, documentation is here.
Along the same lines, we have also added the following calls:
- Change Log Level - /101/system/logging (PUT/GET)
- Configure/Check SNMP Destination - /101/system/snmp (GET/POST/PUT/DELETE)
- Server Cert management - /101/system/snmp/server_cert (POST)
- Configure SNMPv3 with TLS - /101/system/snmp/v3_tls (POST)
- Manage PowerMax Licensing via API
Performance API call enhancements
There is only one minor change in the traditional API for performance with this release. We are adding the ability to register a list of storage groups for real time performance and also bring file metrics for SDNAS onto the Unisphere for PowerMax array for monitoring. The POST call /performance/Array/register has been updated to take new keys, selectedSGs, and a file.
The new payload would look something like this:
{
"symmetrixId": "01234568779",
"selectedSGs": "sg1,sg2,sg3",
"diagnostic": "true",
"realtime": "true",
"file": "true"
}There are some additional changes for mainframe and also Workload Planner which are covered in the changelog documentation. I just want to highlight here what I think most customers will be interested in and give some background.
The all new enhanced PowerMax API – Bulk API calls
I’ve been looking forward to being able to announce some very nice enhancements to the PowerMax API. The API provides new calls with resources accessible under a different Base URI. Rather than https:// {server_ip}:{port}/univmax/restapi/, the new API calls are under https://{server_ip}:{port}/univmax/rest/v1.
The difference between the two entry points will become apparent as you get used to these calls and the versioning will be arguably simpler going forward. Documentation is here.
- GET - /systems/{id}/volumes
- GET - /systems/{id}/storage-groups
- GET - /systems/{id}/performance-categories
- GET - /systems/{id}/performance-categories/{id}
For complete details about these endpoints, see:
- The API documentation marked "POWERMAX - ENHANCED ENDPOINTS"
- The Unisphere for PowerMax 10.1 REST API Changelog
“Ok” I hear you say, “so what’s the big deal?”. Well, these endpoints behave differently from our existing API calls. The provide more information faster so that developers don’t have to maintain a lot of code to get the information they need.
The volumes GET call returns details about every volume on a system in a single call. There is no pagination required and you don’t need to worry about iterators or have to deal with anything fancy. The API just gives you back one big JSON response with all the information you need. This eliminates the need to loop on calls and will dramatically cut down the number of API calls you need to issue to the server.
The same is true for the storage groups calls. With a single call, you can get information on all storage groups on the system, their attributes, and which volumes are in those groups.
But wait, there’s more…
We have implemented a modified form of filtering of the response. You can now filter on all attributes and nested attributes that are returned in the response:
../storage-groups?filter=cap_gb eq 100 ../storage-groups?filter=volumes.wwn like 12345678
The available filter options are:
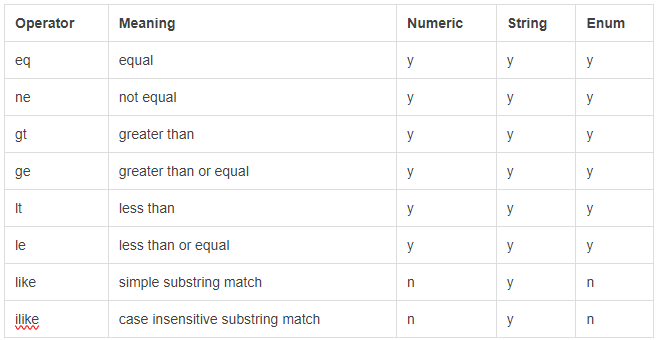 The endpoints require you to “select” the desired attributes instead of returning everything up front. By doing so, you can control how server-intensive each request is by omitting or including only the relevant info:
The endpoints require you to “select” the desired attributes instead of returning everything up front. By doing so, you can control how server-intensive each request is by omitting or including only the relevant info:
…/storage-groups?select=cap_gb,uuid,type,num_of_volumes
This returns only the cap_gb,uuid, type and num_of_volumes for each storage group.
This also applies to nested attributes (a full stop is used to define child attributes):
…/storage-groups?select=volumes.wwn,volumes.effective_wwn,snapshots.timestamp_ms
If no attributes are defined in the “select”, only the default values, such as “id”, are returned. The list of attributes that can be selected is available in the documentation here.
Functions are also available for this in PyU4V. Currently multiple filter options are combined in an AND pattern and select can be applied to the data to reduce the output to only what you are interested in. The following is an example of this functionality as executed through PyU4V 10.1:
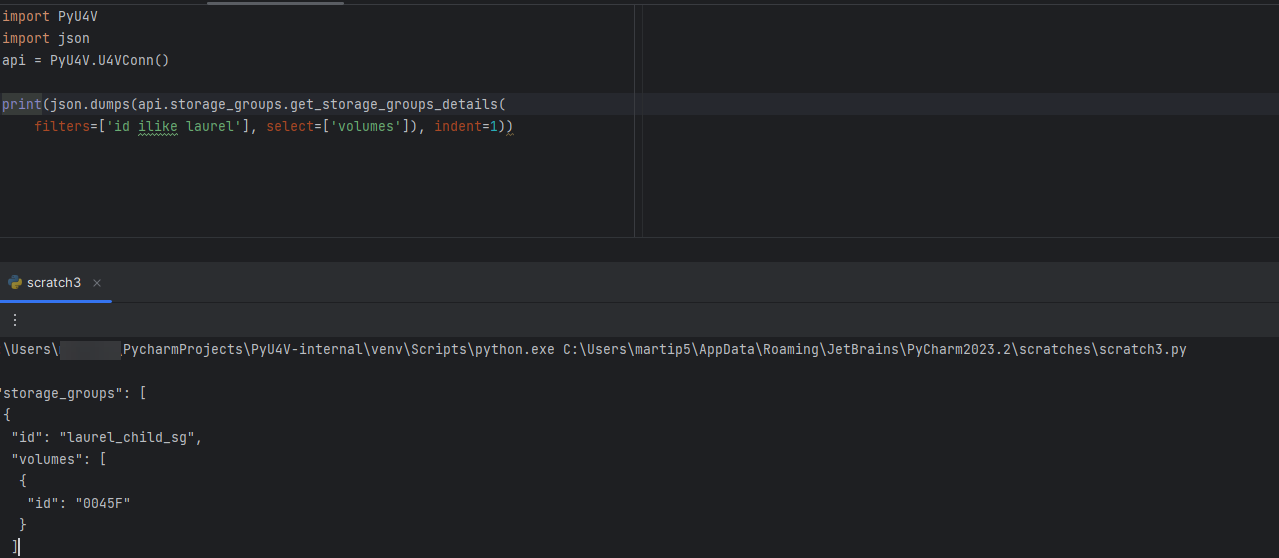
With this new functionality you can get all details for your volumes and storage groups in two calls per array, reduced from tens of thousands of calls on larger systems.
Enhanced performance metrics with the new Bulk API
In addition to the new GET calls for Volumes and Storage groups, there are new calls for the performance metrics.
The /systems/{id}/performance-categories (GET) call returns a list of performance categories valid for the arrays you are querying.
When you query each category, the API returns the last interval of diagnostic performance data using the new /systems/{id}/performance-categories/{id} GET call. This returns all key performance indicator metrics at the diagnostic level for the category and all instances in that category for the last five minutes.
These new enhanced API calls reduce the amount of code that developers need to write and maintain. The API call is intentionally designed to provide only the latest information. This reduces the amount of code for which developers need to maintain performance data collection for dashboard type tools and data collectors.
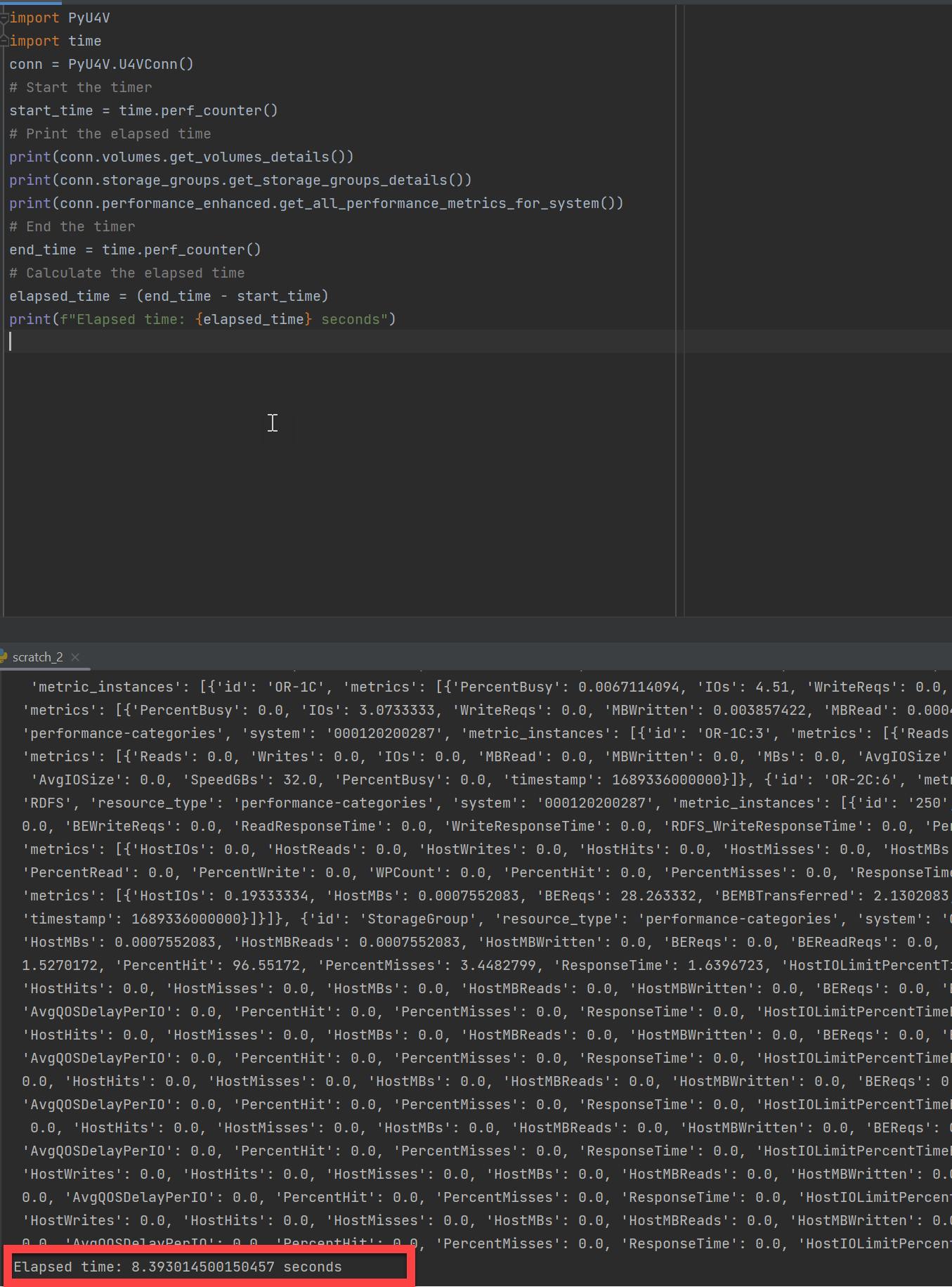
The following example shows a PyU4V script executing a few lines of code to gather all performance stats for every category on every component of a PowerMax array. It’s also gathering details on all volumes and all storage groups using the new Enhanced API calls. On my system, the code takes about eight seconds on average to gather all that information.
To wrap up
Hopefully this blog has provided some insight into the latest changes in the PowerMax REST API. As you can see, our developers have not been RESTing on their laurels!
Watch this space for more about the PowerMax API, and if there are topics that are of interest to you and you would like to learn more, send a request to @rawstorage on Twitter and I’ll try to accommodate your request!
Be sure to provide feedback through your account team for any enhancement requests or start a discussion on https://www.dell.com/community/en/topics/automation. Our product managers will take your requests and bring them to the development team.
Author: Paul Martin

Local Replication with the PowerMax REST API, Working with SnapVX Snapshots
Tue, 13 Jun 2023 16:02:04 -0000
|Read Time: 0 minutes
PowerMax arrays provide feature rich local replication options in SnapVX and clone technologies. The PowerMax REST API supports all of these features, and Dell Technologies provides pre-written Python functions as part of PyU4V -- a Python package for managing the PowerMax REST API as well as Ansible modules that support SnapVX. In this blog I provide examples in native REST calls and in a Python example.
If you are not familiar with REST, you’ll enjoy reading one or both of these blogs:
- https://infohub.delltechnologies.com/p/getting-started-with-rest-api-1
- https://infohub.delltechnologies.com/p/getting-started-with-the-powermax-rest-api-time-for-a-rest
Full API documentation is available on the developer hub here. All REST endpoints for the SnapVX and clone operations are under the replication resource of the API. This means that URI addresses are prefixed with the base URL https://{{base_url}}/{{api_version}}/replication. In addition to SnapVX and clone functionality, it’s also possible to assign snapshot policies to storage groups at the time of creation or when modifying using sloprovisioning resources. Examples appear further ahead in this blog.
Managing SnapVX snapshots with the REST API
SnapVX provides PowerMax administrators with the ability to take point in time snapshots across a collection of devices to create a consistent point in time image of the data in a very space efficient manner. The user can manipulate the snapshots for restore purposes or link them to volumes and present them to hosts using masking views to provide a copy of the snapshot image.
For details about SnapVX functionality, see the white paper Dell PowerMax and VMAX All Flash: TimeFinder SnapVX Local Replication. The PowerMax REST API provides all the functionality of Unisphere for PowerMax with snapshot management, and just like the UI management is orchestrated with the storage group. If you need to manipulate a snapshot for a single volume, you can use the CLI tools or add the volume to its own storage group.
Some points to remember with SnapVX snapshots:
- A SnapVX snapshot is never altered by host access and therefore is always available to the administrator for restore purposes until it is terminated by user action or it expires based on the time to live value (if set).
- Snapshots will only automatically expire when they are unlinked from all target storage groups.
- Snapshots can be set secure at or after creation time. Once set secure, the user cannot terminate the snapshot until the time to live has passed or modify the security of that snapshot except to extend secure time to live.
- When linking snapshots with the API or UI, if the target storage group doesn’t already exist the API will automatically create the storage group with the correct number of devices and size, matching the source device configurations.
- If you add devices to a source storage group, you must add devices to target storage groups. This is not automatic and needs to be planned for. Naming conventions can help simplify this process.
- Although SnapVX snapshots present with both a generation number and snapId, if automating, snapid is preferred because this number is a static reference id.
Creating and identifying SnapVX SnapShots with the REST API
Creating a snapshot is a simple process. A REST API POST call is sent to the management software, directed at the storage group to be snapped, specifying a name for the snapshot along with any optional parameters to be set (for example, you can set the snapshot to be secure or set time to live).
The following is an example POST call and payload for creating a snapshot of a storage group, with a snapshot named REST_SG_snapshot, setting a time to live of 10 days. (Values to be supplied are enclosed in {} signaling substitution required for actual values or variables.)
https://unisphereIP:8443/univmax/restapi/{{api_version}}/replication/symmetrix/{symmetrixId}/storagegroup/{storageGroupId}/snapshot (POST)
Payload
{
"snapshotName": "REST_SG_snapshot",
"timeToLive": 10
}PyU4V has functions for complete control of SnapVX, making the API easier to consume. The following is a simple script to create a snapshot and print the return from the API.
import PyU4V
conn = PyU4V.U4VConn(username='smc', password='smc',
server_ip='unisphereip', port='8443', array_id=None,
verify=False)
#create a snapshot and assign returned information to variable snap_details
snap_details = (conn.replication.create_storage_group_snapshot(
storage_group_id='snapsrc', snap_name='snap4blog', ttl=1, secure=False,
hours=True))
#Get SnapIds for all snapshots for storage group with name snap4blog
all_sg_snaps = (conn.replication.get_storage_group_snapshot_snap_id_list(
storage_group_id='snapsrc', snap_name='snap4blog'))
#print details of snapshot created above
print(snap_details)
#Print only snapid from snap_details
print(snap_details.get('snapid'))
#Print all SnapIds associated with snap4blog snapshot on snapsrc storage group
print(all_sg_snaps)The output is shown below.
- The first print statement shows the detailed information for the snapshot just created with details such as timestamp, snapid, and so on.
- The second line prints only the snapid extracted from the JSON using the key ‘snapid’.
- The third line prints the variable ‘all_sg_snaps’ showing all snapshot ids with the name snap4blog associated with the snapsrc storage group.

To make the snapshot data available to a host, you can add some additional REST calls to link to a storage group.
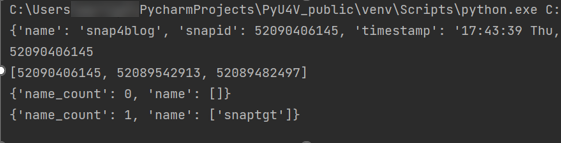
The following script performs these tasks:
- Lists any storage group that has a snapshot linked to it on my test array. There are none to begin with.
- Creates a link to an existing snapshot using the snapid
- Runs the listing again. This time there is data to display showing the linked storage group.
#list any storage group that is being used as a linked target for snapvx
#snapshot
print(conn.common.get_request(
target_uri=f'/100/replication/symmetrix/'
f'000120200287/storagegroup?is_link_target=True',
resource_type=None))
#Link a snapshot from ‘snapsrc’ storage group to ‘snaptgt’ storage group, #this will create snaptgt storage group as it doesn’t exist
#with the name ‘snap4blog’ and snapid matching value in variable set earlier.
conn.replication.modify_storage_group_snapshot_by_snap_id(
src_storage_grp_id='snapsrc',tgt_storage_grp_id='snaptgt',
snap_name='snap4blog', snap_id=snap_details.get('snapid'),
link=True)
#Print updated list of storage groups used as snap target
print(conn.common.get_request(
target_uri=f'/100/replication/symmetrix/'
f'000120200287/storagegroup?is_link_target=True',0
resource_type=None))The following is the output of the functions showing the snaptgt group in the list after the link has been issued.
SnapVX lends a lot of flexibility when refreshing test and development environments. The ability to relink the same snapshot (essentially wiping any changes to the target copy while preserving the point in time image) greatly simplifies iterative testing. You can also quickly relink to a different snapshot or unlink to reuse the target volumes for another purpose. To relink a snapshot with PyU4V, simply change the parameter in the modify_storage_group call instead of “link=True” we set “relink=True”.
If you are relinking directly from the API, modify the payload for the PUT call to reflect that the action is relink, as shown here:
https://UnisphereIP:8443/univmax/restapi/100/replication/symmetrix/{symmetrixId}/storagegroup/{storageGroupId}/snapshot/{snapshotId}/snapid/{snapId} (PUT)
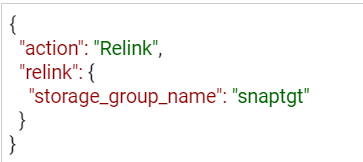
When you no longer require your snapshots, don’t forget to terminate or unlink any linked targets to allow for automatic expiration if you’ve set a time to live. All actions use the same URI link, however the REST method will be PUT (with modified payload) or DELETE.
It’s generally a good practice to adopt a friendly naming convention for storage groups that are being used as snapvx targets to make them easy to identify in the UI and API output. Simply adding _TGT to the sg name may be enough, but your naming convention can be whatever works best for your organization.
Snapshot policies
In addition to regular snapshots, SnapVX provides a mechanism for users to assign snapshot policies to storage groups. (More details about snapshot policies are described in the white paper Dell PowerMax and VMAX All Flash: TimeFinder SnapVX Local Replication.) Assigning a snapshot policy means that you will have an automated rotation and preservation of a defined number of snapshots for your storage groups with a clearly defined recovery time objective. Users don’t need to manage the scheduling -- the policy automates all of that and can be assigned when storage groups are created, or at a later time.
Associating snapshot policies to storage groups is available through the POST and PUT calls for creating storage groups. A separate set of API calls is available for managing directly from the Snapshot Policy section of the API documentation.
For Py4V in Python, the code only requires an extra variable on the create and modify functions. The following example will create a snapshot policy (example_policy) that will take a snapshot every 12 minutes, retaining a maximum of 24 snapshots. The second part creates a storage group associated with this policy. Note that there are default policies already created on all arrays that users can use without having to create anything new.
import PyU4V api = PyU4V.U4VConn(username='smc',password='smc', server_ip='unisphereip', verify=None, array_id='000297600841') api.snapshot_policy.create_snapshot_policy( snapshot_policy_name='example_policy', interval="12 Minutes", local_snapshot_policy_snapshot_count=24) api.provisioning.create_non_empty_storage_group( srp_id="SRP_1", storage_group_id="blog_example_sg", num_vols=1, vol_size=1, cap_unit="GB",snapshot_policy_ids=["example_policy"], service_level="Diamond", workload=None)
Hopefully this blog has given you the basics to working with SnapVX snapshots using REST and Python!
For more information and a list of all functions for SnapVX, see the documentation for PyU4V on readthedocs.io and the REST API documentation on the Dell developer portal here.
In upcoming blogs, I will also be looking at using clone technology with the REST API, and when this is a good alternative to SnapVX depending on your needs. Have fun automating and if you have questions, you can always start a discussion on the PyU4V GitHub -- we are always willing to help!
Author: Paul Martin