



Scaling Neural Machine Translation - Challenges and Solution
As I mentioned in our previous blog post, the translation quality of neural machine translation (NMT) systems has improved immensely in recent years. However, these models still take considerable time to train, and little work has been focused on improving their time to solution. Distributed training across multiple compute nodes can potentially improve the time to train, but there are various challenges associated with scale-out training of NMT systems.
In this blog, we highlight solutions developed at Dell EMC which address a few common issues encountered when scaling an NMT architecture like the Transformer model in TensorFlow, highlight the performance benefits associated with these solutions. All of the experiments and results obtained used Zenith, DellEMC’s very own Intel® Xeon® Scalable processor-based supercomputer, which is housed in the Dell EMC HPC & AI Innovation Lab in Austin, Texas.
Performance degradation and OOM errors
One of the main roadblocks to scaling NMT models is the memory required to accumulate gradients. When training neural networks, the gradients are vectors – or directional arrays – of numbers that roughly correspond to the difference between the current network weights and a set of weights that provide a better solution. Essentially, the gradients point each weight value in a different, and hopefully, a better direction which leads to better solutions. While convolutional neural networks for image classification use dense gradient vectors which can be easily worked with, the design of the transformer model uses an embedding layer that does not necessarily scale well to multiple servers.
This design causes severe performance degradation and out of memory (OOM) errors because TensorFlow does not accumulate the embedding layer gradients correctly. Gradients from the embedding layer are sparse, whereas the gradients from the projection matrix are dense. TensorFlow then accumulates both of these tensors as sparse objects. This has a dramatic effect on TensorFlow’s gradient accumulation strategy, and subsequently on the total size of the accumulated gradient tensor. This results in large message buffers which scale linearly with the number of processes, thereby causing segmentation faults or out-of-memory errors.
The assumed-sparse tensors make Horovod (the distributed training framework used with TensorFlow) to perform gradient accumulation by MPI_Gather rather than MPI_Reduce. To fix this issue, we can convert all assumed sparse tensors to dense tensors. This is done by adding the flag “sparse_as_dense=True” in Horovod’s DistributedOptimizer method.
opt = hvd.DistributedOptimizer(opt, sparse_as_dense=True)
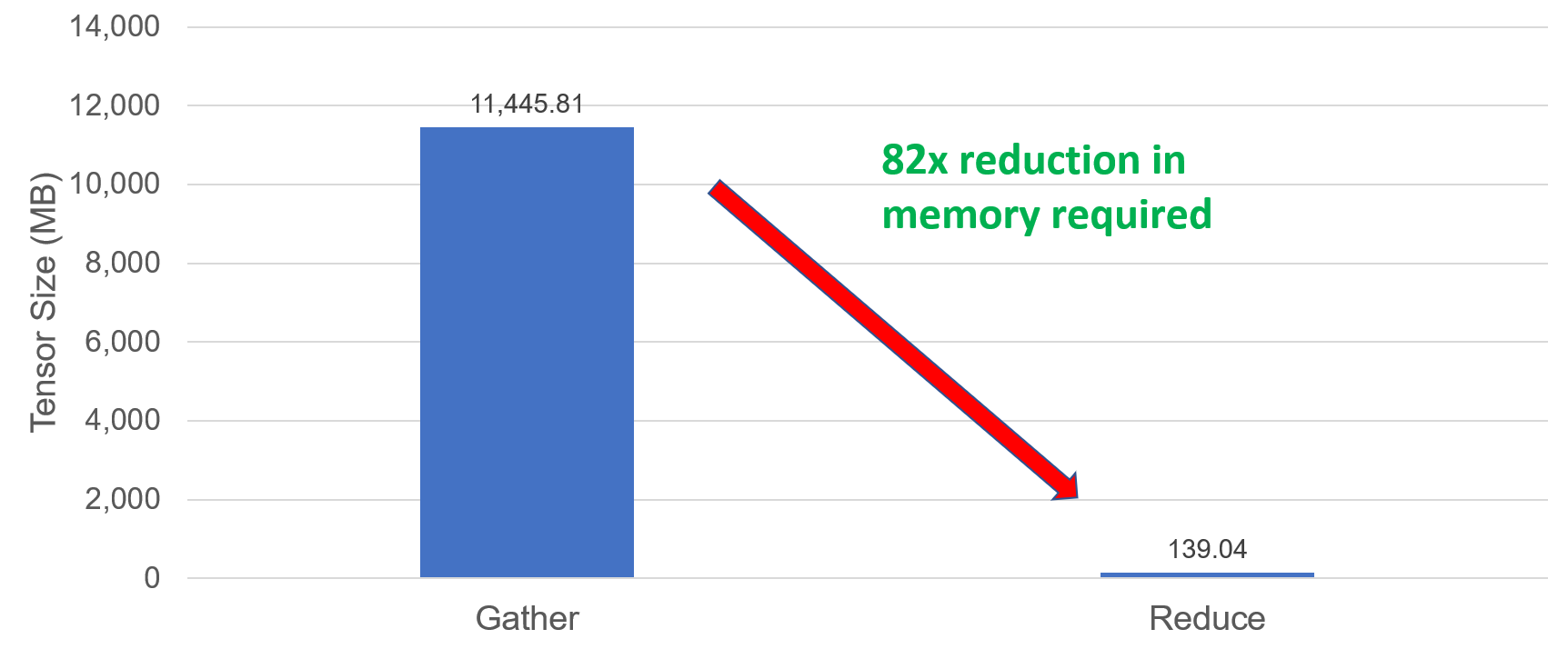
Figure 1: Accumulate size
Figure 1 shows the accumulation size when using 64 nodes (1ppn, batch_size=5000 tokens). There’s an 82x reduction in accumulation size when the assumed sparse tensors are converted to dense. This solution allows to scale and train the model using 100’s of nodes.
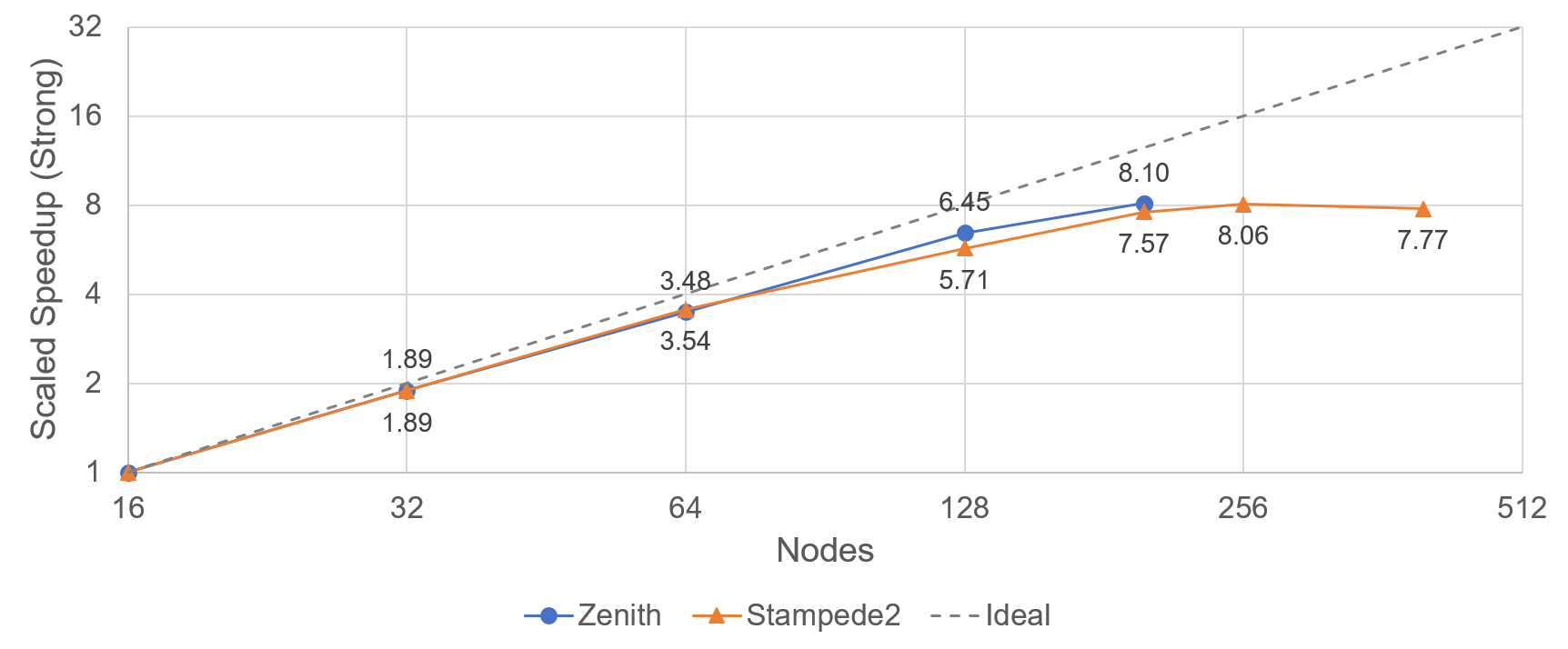
Figure 2: Scaled speedup (strong) performance.
Apart from the weak scaling performance benefit shown in our previous blog, the reduced gradient size also provides a way to perform efficient strong scaling. Figure 2 shows the strong scaling speedup performed on zenith and stampede2 supercomputers using up to 200 nodes on Zenith (Dell EMC) and 256 nodes on Stampede2 (TACC). Efficient strong scaling greatly helps to reduce the time to train the model
Diverged Training
While building a model quickly is important, it is critical the make sure that the resulting model is also accurate. Diverged training, where the produced model becomes less accurate (rather than more accurate) with continued training is a common problem not just for large batch training but in general for any NMT system. Monitoring the loss graph would help to understand the convergence of the deep learning model. Setting the learning rate to an optimal value is crucial for the model’s convergence.
Measures can be taken to prevent diverged training. Experiments suggest that having a very high learning rate at the beginning of the training would cause diverged training. But on the other hand, setting the learning rate too low also would make the model converge slowly. Finding the ideal learning rate for the model is therefore critical.
One solution is to reduce the learning rate (cool down or decay) or increase the learning rate (warm up), or more often a combination of both By allowing the learning rate to increase linearly to the set value for certain number of steps after which it decays based on a chosen function, the resulting model can be more accurate and produced faster. For transformer model, the decay is proportional to the inverse square root of the number of steps.
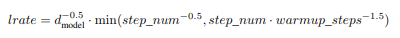
Figure 3: Learning rate decay used in Transformer model
Based on our experiments we found that for large batch sizes (130k, 402k, 630k, 1M tokens), setting the learning rate to 0.001 – 0.005 would prevent diverged training of the big model.
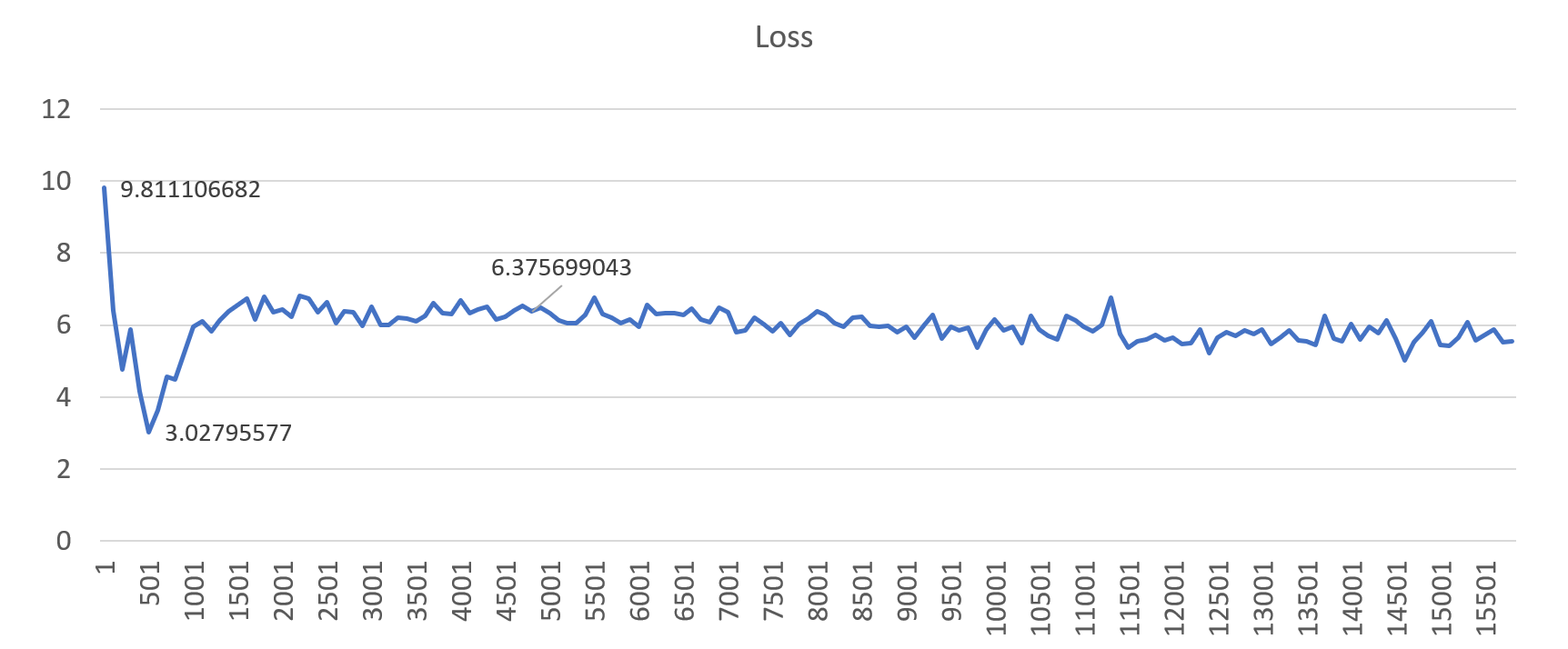
Figure 4: An example loss profile showing diverged training (gbz=130k, lr=0.01)
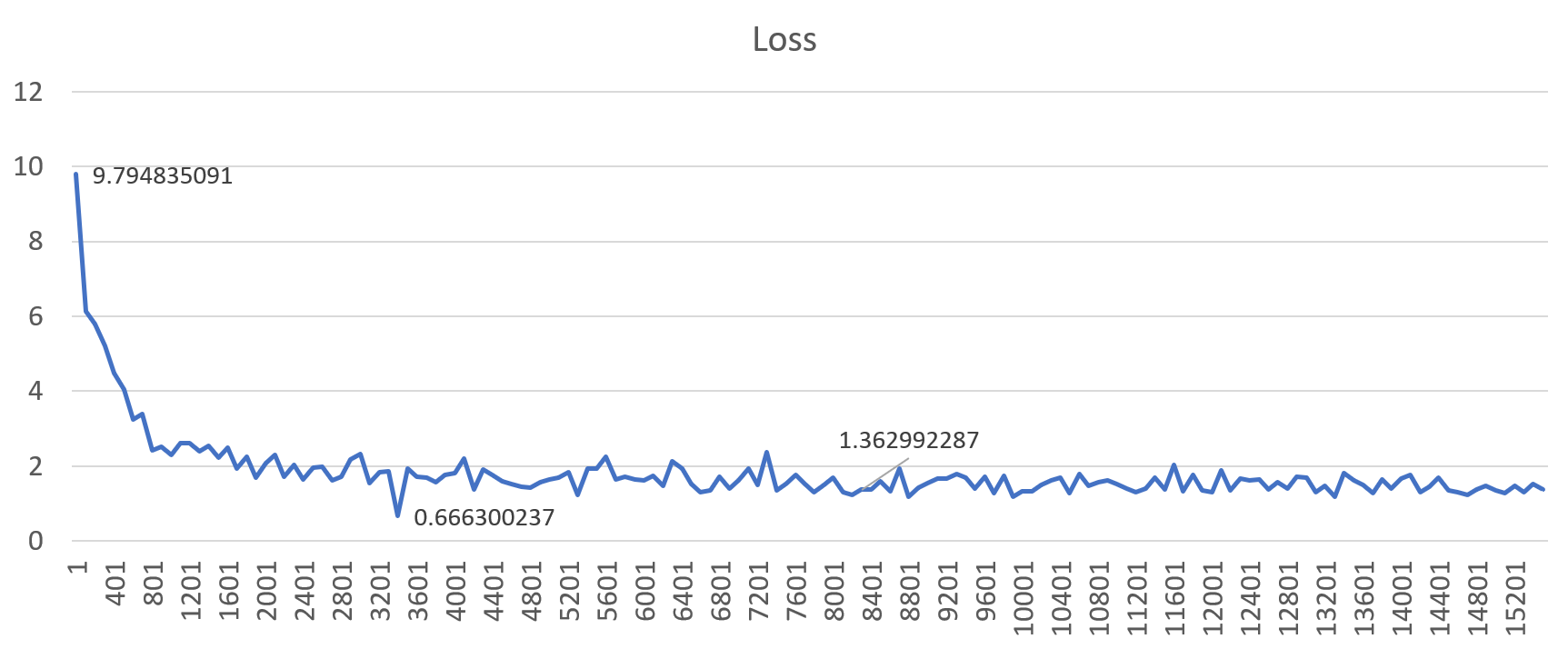
Figure 5: An example loss profile showing correct training behavior (gbz=130k, lr=0.001)
Figures 4 and 5 show the loss profiles when trained with a global batch size of 130k. Setting the learning rate to a “high” value (0.01) results in diverged training, but when set to 1e-3 (0.001), the model converges better. This results in good translation quality on the final model. Similar results were observed for all other large batch sizes.
Conclusion
In this blog, we highlighted a few common challenges when performing distributed training of the transformer model for neural machine translation (NMT). The solutions developed by Dell EMC in collaboration with Uber, Amazon, Intel, and SURFsara resulted in dramatically improved scaling capabilities and model accuracy. The results are now added part of our research paper accepted at the ISC High Performance 2019 conference. The paper has further details about the modifications to Horovod and improvements in terms of memory usage, scaling efficiency, reduced time to train and translation quality. The work has been incorporated into Horovod so that the research community can explore further scaling potential and produce more efficient NMT models.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda