




Scaling Neural Machine Translation with Intel Xeon Scalable Processors
The field of machine language translation is rapidly shifting from statistical machine learning models to efficient neural network architecture designs which can dramatically improve translation quality. However, training a better performing Neural Machine Translation (NMT) model still takes days to weeks depending on the hardware, size of the training corpus and the model architecture. Improving the time-to-solution for NMT training will be crucial if these approaches are to achieve mainstream adoption.
Intel® Xeon® Scalable processors are the workhorse of the modern datacenter, and over 90% of the Top500 super computers run on Intel. We can apply the supercomputing approach of scaling out to multiple servers to training NMT models in any datacenter. In this article we show some the effectiveness of and highlight important considerations when scaling a NMT model using Intel® Xeon® Scalable processors.
Encoder – decoder architecture
An NMT model reads a sentence in a source language and passes it to an encoder, which builds an intermediate representation. A decoder then processes the intermediate representation to produce a translated sentence in a target language.
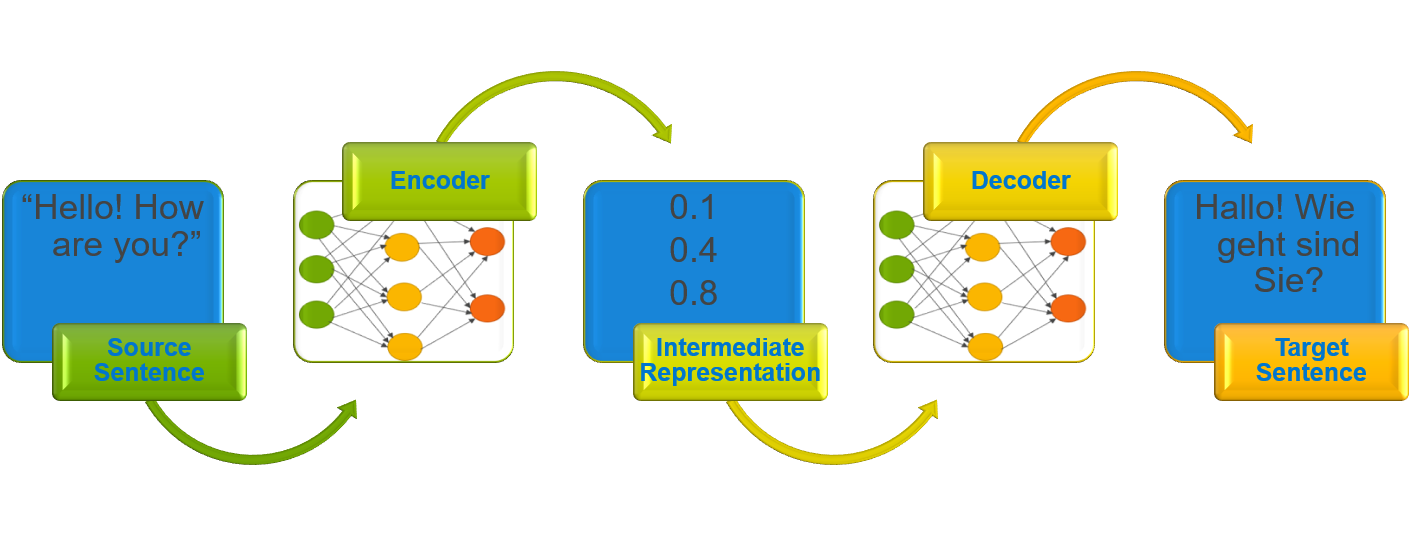
Figure 1: Encoder-decoder architecture
The figure above illustrates the encoder-decoder architecture. The English source sentence, “Hello! How are you?” is read and processed by the architecture to produce a translated German sentence “Hallo! Wie geht sind Sie?”. Traditionally, Recurrent Neural Network (RNN) was used in encoders and decoders, but other neural network architectures such as Convolutional Neural Network (CNN) and attention mechanism-based architectures are also used.
Architecture and environment
The Transformer model is one of the current architectures of interest in the field of NMT, and is built with variants of the attention mechanism which replace the traditional RNN components in the architecture. This architecture was able to produce a model that achieved state of the art results in English-German and English-French translation tasks.
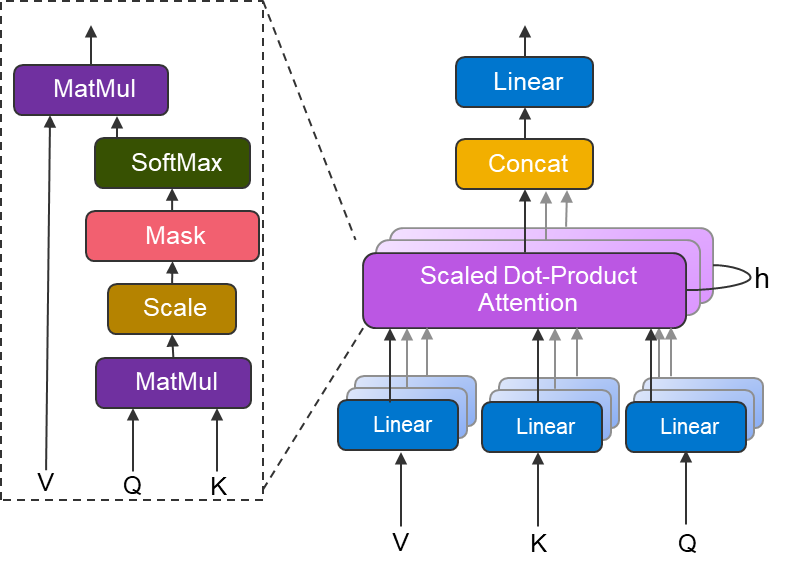
Figure 2: Multi-head attention block
The above figure shows the multi-head attention block used in the transformer architecture. At a high-level, the scaled dot-product attention can be thought as finding the relevant information, in the form of values (V) based on Query (Q) and Keys (K). Multi-head attention can be thought of as several attention layers in parallel, which together can identify distinct aspects of the input.
We use the Tensorflow official model implementation of the transformer architecture, which has been augmented with Uber’s Horovod distributed training framework. The training dataset used is the WMT English-German parallel corpus, which contains 4.5M English-German sentence pairs.
Our tests were performed in house on Zenith super computerin the Dell EMC HPC and AI Innovation lab. Zenith is a Dell EMC PowerEdge C6420-based cluster, consisting of 388 dual socket nodes powered by Intel® Xeon® Scalable Gold 6148 processors and interconnected with an Intel® Omni-path fabric.
System Information
CPU Model | Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz |
Operating System | Red Hat Enterprise Linux Server release 7.4 (Maipo) |
Tensorflow Version | 1.10.1 with Intel® MKL |
Horovod Version | 0.15.0 |
MPI | Open MPI 3.1.2 |
Note: We used a specific Horovod branch to handle sparse gradients. Which is now part of the main branch in their GitHub repository.
Weak scaling, environment variables and TF configurations
When training using CPUs, environment variable settings and TensorFlow runtime configuration values play a vital role in improving the throughput and reducing the time to solution.
Below are the suggested settings based on our empirical tests when running 4 processes per node for the transformer (big) model on 50 zenith nodes.
Environment Variables
export OMP_NUM_THREADS=10 export KMP_BLOCKTIME=0 export KMP_AFFINITY=granularity=fine,verbose,compact,1,0 |
TF Configurations:
intra_op_parallelism_threads=$OMP_NUM_THREADS inter_op_parallelism_threads=1 |
Experimenting with weak scaling options allows finding the optimal number of processes run per node such that the model fits in the memory and performance doesn’t deteriorate. For some reason, TensorFlow creates an extra thread. Hence, to avoid oversubscription it’s better to set the OMP_NUM_THREADS to 9, 19 or 39 when training with 4,2,1 process per node respectively. Although we didn’t see it affecting the throughput performance in our experiments but may affect performance in a very large-scale setup.
Taking advantage of multi-threading can dramatically improve performance. This can be done by setting OMP_NUM_THREADS such that the product of its value and number of MPI ranks per node equals the number of available CPU cores per node. In the case of Zenith, this is 40 cores, as each PowerEdge C6420 node contains 2 20-core Intel® Xeon® Gold 6148 processors.
The KMP_AFFINITY environment variable provides a way to control the interface which binds OpenMP threads to physical processing units, while KMP_BLOCKTIME, sets the time in milliseconds that a thread should wait after completing a parallel execution before sleeping. TF configuration settings, intra_op_parallelism_threads, and inter_op_parallelism_threads are used to adjust the thread pools thereby optimizing the CPU performance.
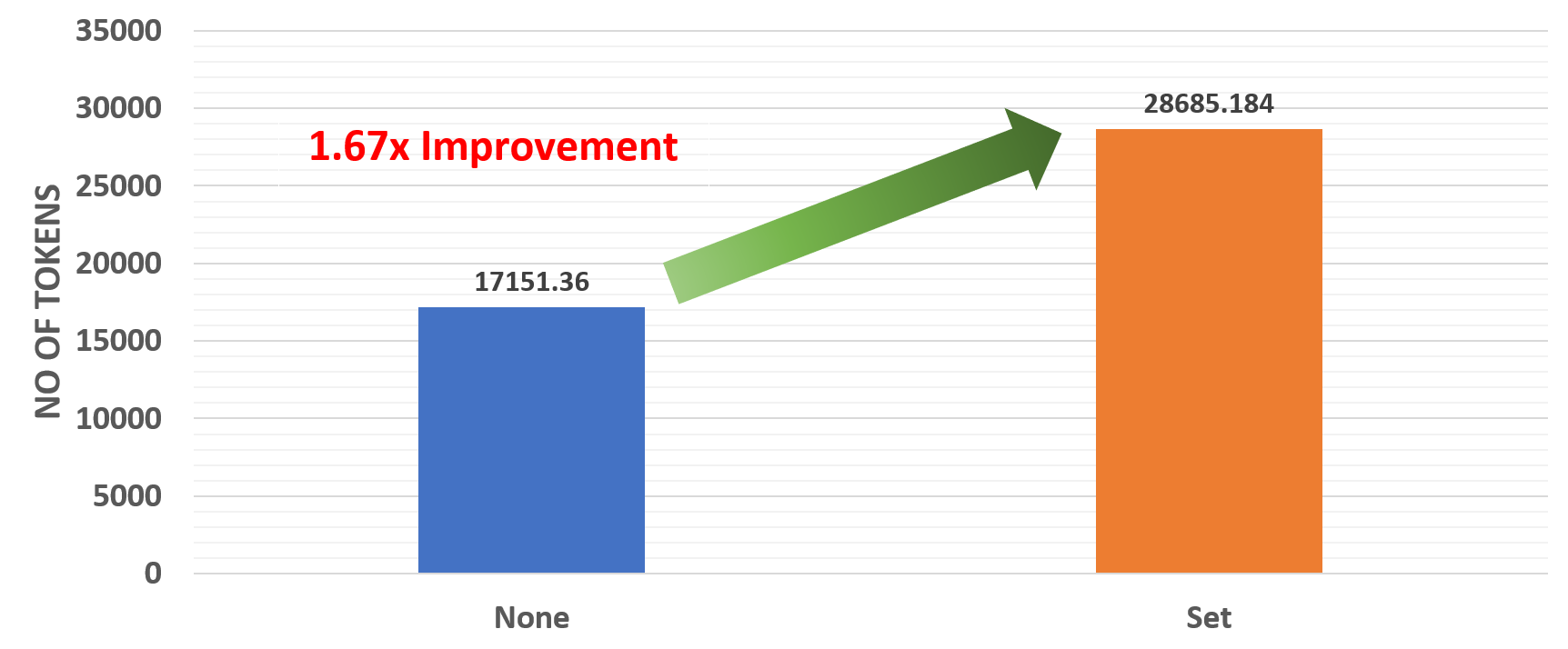
Figure 3: Effect of environment variables
The above results show that there’s a 1.67x improvement when environment variables are set correctly.
Faster distributed training
Training a large neural network architecture can be time-consuming, making it difficult to perform rapid prototyping or hyperparameter tuning. Thanks to distributed training and open source frameworks like Horovod, which allows training a model using multiple workers, the time to train can be substantially reduced. In our previous blog, we showed the effectiveness of training an AI radiologist with distributed deep learning and using Intel® Xeon® Scalable processors. Here, we show how distributed deep learning improves the time to train for machine translation models.
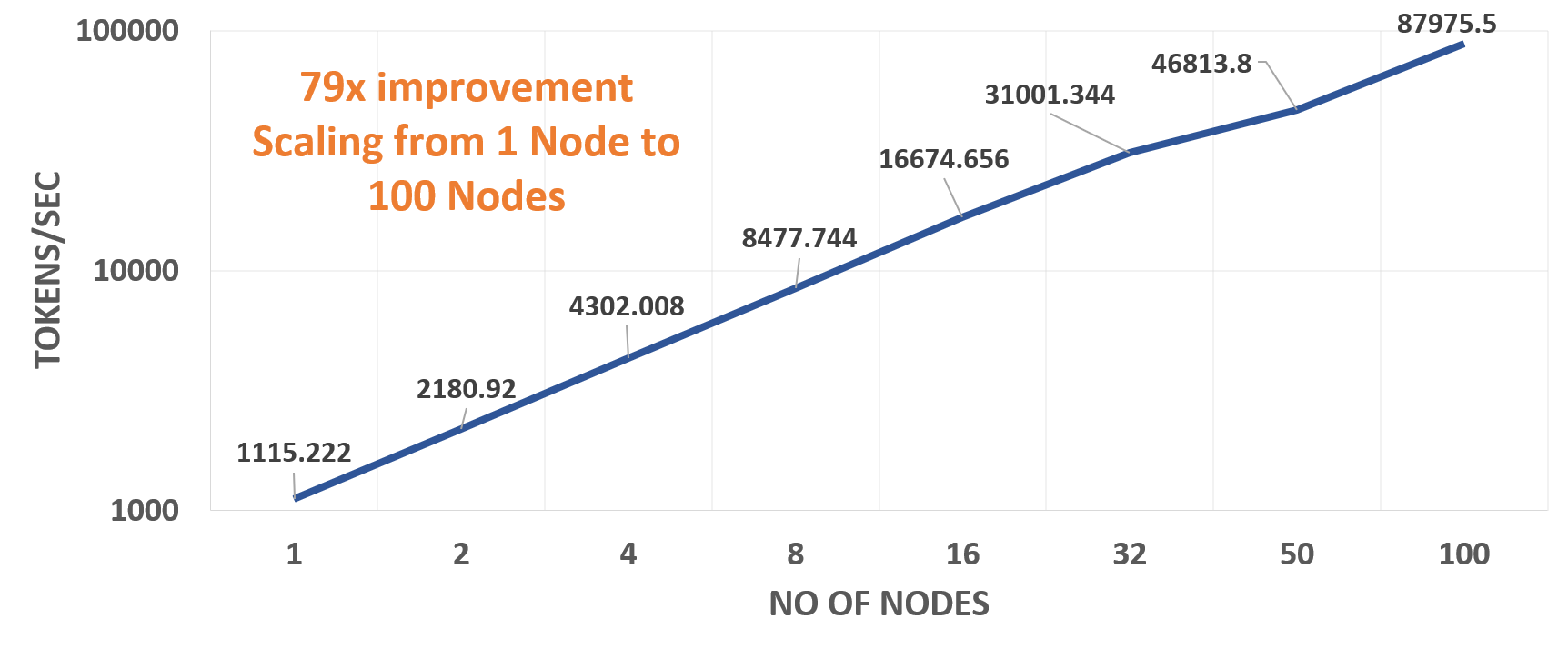
Figure 4: Scaling Performance
The above chart shows the throughput of the transformer (big) model when trained using up to 100 Zenith nodes. Our experiments show linear performance when scaling up the number of nodes. Based on our tests, which include setting the correct environment variables and the optimal number of MPI processes per node, we see a 79x improvement on 100 Zenith nodes with 2 processes per node compared to the throughput on a single node with 4 processes.
Translation Quality
NMT models’ translation quality is measured in terms of BLEU (Bi-Lingual Evaluation Understudy) score. It’s a measure to compute the difference between the human and machine-translated output.
In a previous blog post, we explained some of the challenges of large-batch training of deep learning models. Here, we experimented using a large global batch size of 402k tokens to determine the models’ accuracy on the English to German translation task. Hyperparameters were set to match those used for the transformer (big) model, and the model was trained using 50 Zenith nodes with 4 processes per node. The learning rate grows linearly for 4000 steps to 0.001 and then follows inverse square root decay.
Case-Insensitive BLEU | Case-Sensitive BLEU | |
TensorFlow Official Benchmark Results | 28.9 | - |
Our results | 29.15 | 28.56 |
Note: Case-Sensitive score not reported in the Tensorflow Official Benchmark.
The above table shows our results on the test set (newstest2014) after training the model for around 2.7 days (26000 steps). We can see a clear improvement in the translation quality compared to the results posted on the Tensorflow Official Benchmarks page. This shows that training with large batches does not adversely affect the quality of the resulting translation models, which is an encouraging result for future studies with even larger batch sizes.
Conclusion
In this post, we showed how to effectively train a Neural Machine Translation(NMT) system using Intel® Xeon® Scalable processors using distributed deep learning. We highlighted some of the best practices for setting environment variables and the corresponding scaling performance. Based on our experiments, and following other research work on NMT to understand some of the important aspects of scaling an NMT system, we were able to demonstrate better translation quality and accelerate the training process. With a research interest in the field of neural machine translation continuing to grow, we expect to see more interesting and innovative NMT architectures in the future.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda
LinkedIn: https://www.linkedin.com/in/srinivasvaradharajan
Related Blog Posts

Effectiveness of Large Batch Training for Neural Machine Translation with Intel Xeon
Wed, 24 Apr 2024 15:17:12 -0000
|Read Time: 0 minutes
We know that using really large batch sizes during training can cause models to poorly generalize. But how do large batches actually affect the generalization and optimization of neural network models? 2018 was a great year for research on Neural Machine Translation (NMT). We’ve seen an explosion in the number of research papers published in this field, ranging from descriptions of new and interesting architectures to efficient training techniques. Research papers have shown how larger batch sizes and reduced precision can help to improve both the training time and quality.
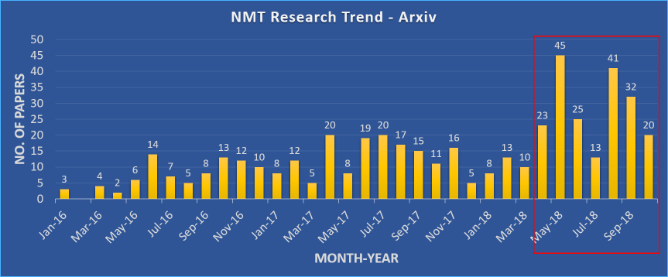
Figure 1: Numbers of papers published in Arxiv with ‘neural machine translation’ in the title or abstract in the ‘cs’ category.
In our previous blogs, we showed how to effectively scale an NMT system, as well as some of the challenges associated with scaling. In this blog, we will explore the effectiveness of large batch training using Intel® Xeon® Scalable processors. The work discussed in the blog is based on neural network training performed using Zenith supercomputer at Dell EMC’s HPC and AI Innovation Lab.
System Information
CPU Model | Intel® Xeon® Gold 6148 CPU @ 2.40GHz |
Operating System | Red Hat Enterprise Linux Server release 7.4 (Maipo) |
Tensorflow Version | Anaconda TensorFlow 1.12.0 with Intel® MKL |
Horovod Version | 0.15.2 |
MPI | MVAPICH2 2.1 |
Incredible strong scaling efficiency helps to dramatically reduce the time to solution of the model. To best visualize this, consider figure 2. The time to solution drops from around 1 month on a single node to just over 6 hours using 200 nodes. This 121x faster solution would significantly help the productivity of NMT researchers using CPU-based HPC infrastructures. The results observed were based on the models achieving a baseline BLEU score (case-sensitive) of 27.5.
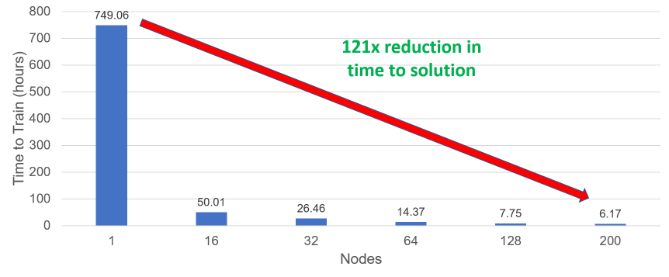
Figure 2: Time to train the model to solution
For the single node case, we have used the largest batch size that could fit in a node's memory, 25,600 tokens per worker. For all other cases, we use a global batch size of 819,200, leading to per-worker batch sizes of 25,600 in the 16-node case, down to only 2,048 in the 200-node case. The number of training iterations is similar for all experiments in the 16-200 node range and is increased by a factor of 16 for the single-node case (to compensate for the larger batch).
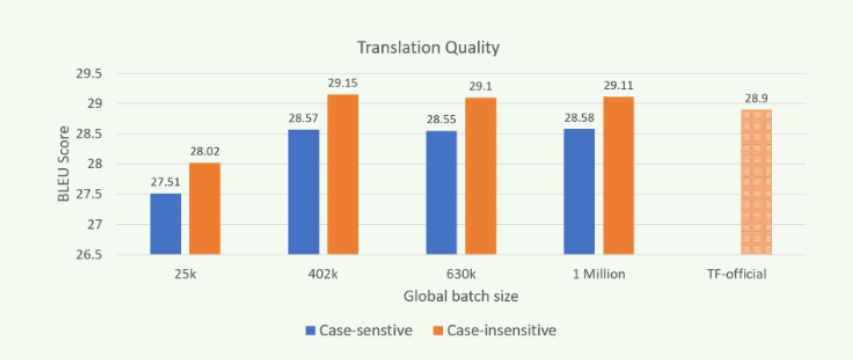
Figure 3: Translation quality (BLEU) when trained with different batch sizes on Zenith.
Scaling out the “transformer” model training using MPI and Horovod improves throughput performance while producing models of similar translation quality as shown in Figure 3. The results were obtained by using newstest2014 as the test set. Models of comparable quality can be trained in a reduced amount of time by scaling computation over many more nodes, and with larger global batch sizes (GBZ). Our experiments on Zenith demonstrate the ability to train models of comparable or higher translation quality (as measured by BLEU score) than the reported best for TensorFlow's official model, even when training with batches of a million or more tokens.
Note: The results shown in figure 3 were obtained by using the settings mentioned in our previous blog and by using Open MPI.
Conclusion
Here in this blog, we showed the generalization of large batch training of NMT model. We also showed how efficiently Intel® Xeon® Scalable processors are able to scale and reduce the time to solution. We hope this would benefit the productivity of the NMT research community using CPU-based HPC infrastructures.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda
LinkedIn: https://www.linkedin.com/in/srinivasvaradharajan
Scaling Neural Machine Translation - Challenges and Solution
Wed, 24 Apr 2024 15:15:31 -0000
|Read Time: 0 minutes
As I mentioned in our previous blog post, the translation quality of neural machine translation (NMT) systems has improved immensely in recent years. However, these models still take considerable time to train, and little work has been focused on improving their time to solution. Distributed training across multiple compute nodes can potentially improve the time to train, but there are various challenges associated with scale-out training of NMT systems.
In this blog, we highlight solutions developed at Dell EMC which address a few common issues encountered when scaling an NMT architecture like the Transformer model in TensorFlow, highlight the performance benefits associated with these solutions. All of the experiments and results obtained used Zenith, DellEMC’s very own Intel® Xeon® Scalable processor-based supercomputer, which is housed in the Dell EMC HPC & AI Innovation Lab in Austin, Texas.
Performance degradation and OOM errors
One of the main roadblocks to scaling NMT models is the memory required to accumulate gradients. When training neural networks, the gradients are vectors – or directional arrays – of numbers that roughly correspond to the difference between the current network weights and a set of weights that provide a better solution. Essentially, the gradients point each weight value in a different, and hopefully, a better direction which leads to better solutions. While convolutional neural networks for image classification use dense gradient vectors which can be easily worked with, the design of the transformer model uses an embedding layer that does not necessarily scale well to multiple servers.
This design causes severe performance degradation and out of memory (OOM) errors because TensorFlow does not accumulate the embedding layer gradients correctly. Gradients from the embedding layer are sparse, whereas the gradients from the projection matrix are dense. TensorFlow then accumulates both of these tensors as sparse objects. This has a dramatic effect on TensorFlow’s gradient accumulation strategy, and subsequently on the total size of the accumulated gradient tensor. This results in large message buffers which scale linearly with the number of processes, thereby causing segmentation faults or out-of-memory errors.
The assumed-sparse tensors make Horovod (the distributed training framework used with TensorFlow) to perform gradient accumulation by MPI_Gather rather than MPI_Reduce. To fix this issue, we can convert all assumed sparse tensors to dense tensors. This is done by adding the flag “sparse_as_dense=True” in Horovod’s DistributedOptimizer method.
opt = hvd.DistributedOptimizer(opt, sparse_as_dense=True)
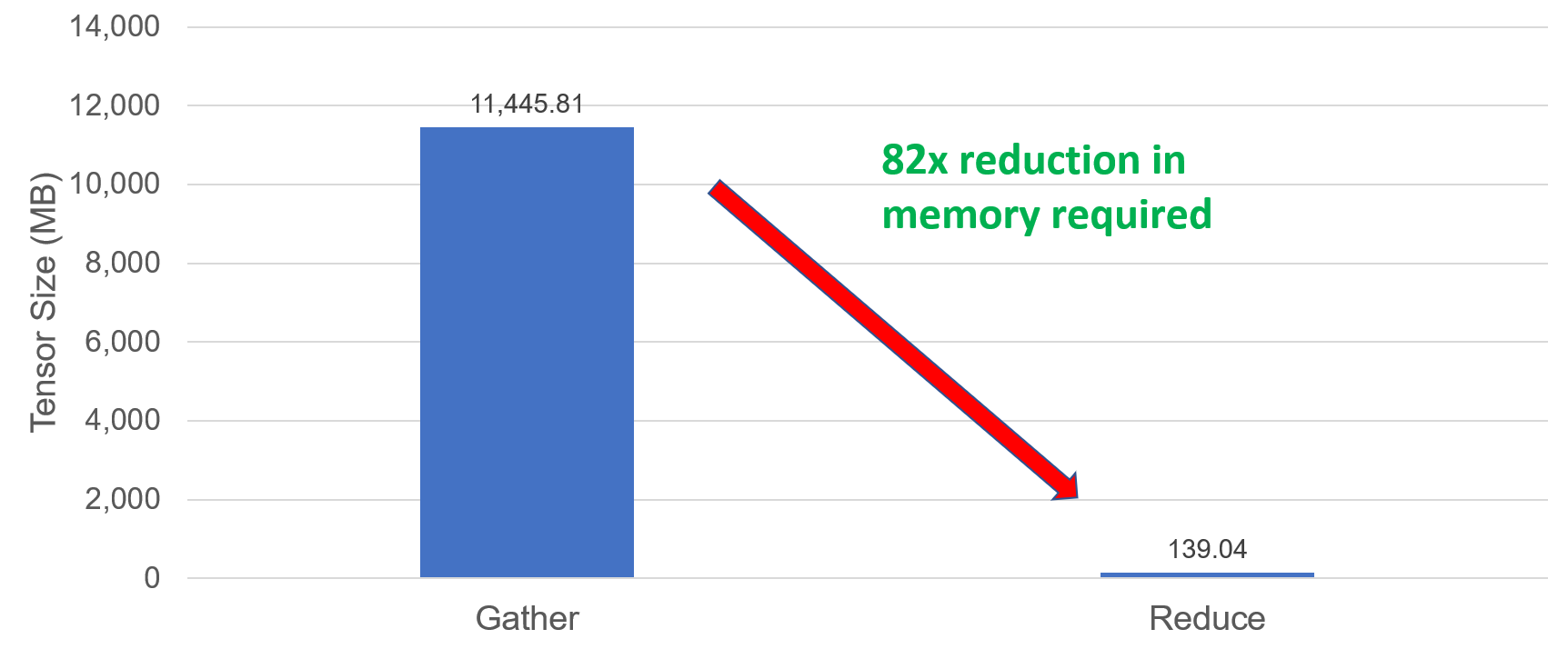
Figure 1: Accumulate size
Figure 1 shows the accumulation size when using 64 nodes (1ppn, batch_size=5000 tokens). There’s an 82x reduction in accumulation size when the assumed sparse tensors are converted to dense. This solution allows to scale and train the model using 100’s of nodes.
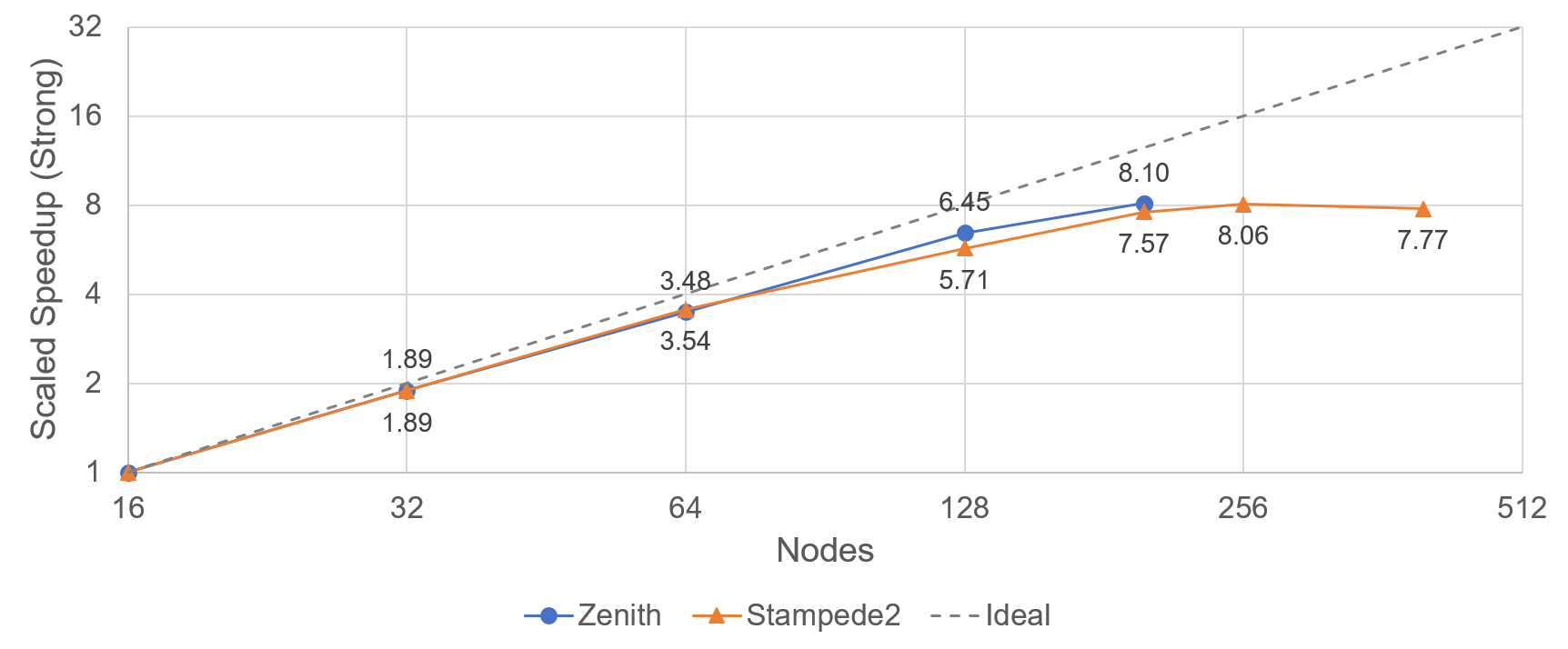
Figure 2: Scaled speedup (strong) performance.
Apart from the weak scaling performance benefit shown in our previous blog, the reduced gradient size also provides a way to perform efficient strong scaling. Figure 2 shows the strong scaling speedup performed on zenith and stampede2 supercomputers using up to 200 nodes on Zenith (Dell EMC) and 256 nodes on Stampede2 (TACC). Efficient strong scaling greatly helps to reduce the time to train the model
Diverged Training
While building a model quickly is important, it is critical the make sure that the resulting model is also accurate. Diverged training, where the produced model becomes less accurate (rather than more accurate) with continued training is a common problem not just for large batch training but in general for any NMT system. Monitoring the loss graph would help to understand the convergence of the deep learning model. Setting the learning rate to an optimal value is crucial for the model’s convergence.
Measures can be taken to prevent diverged training. Experiments suggest that having a very high learning rate at the beginning of the training would cause diverged training. But on the other hand, setting the learning rate too low also would make the model converge slowly. Finding the ideal learning rate for the model is therefore critical.
One solution is to reduce the learning rate (cool down or decay) or increase the learning rate (warm up), or more often a combination of both By allowing the learning rate to increase linearly to the set value for certain number of steps after which it decays based on a chosen function, the resulting model can be more accurate and produced faster. For transformer model, the decay is proportional to the inverse square root of the number of steps.
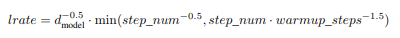
Figure 3: Learning rate decay used in Transformer model
Based on our experiments we found that for large batch sizes (130k, 402k, 630k, 1M tokens), setting the learning rate to 0.001 – 0.005 would prevent diverged training of the big model.
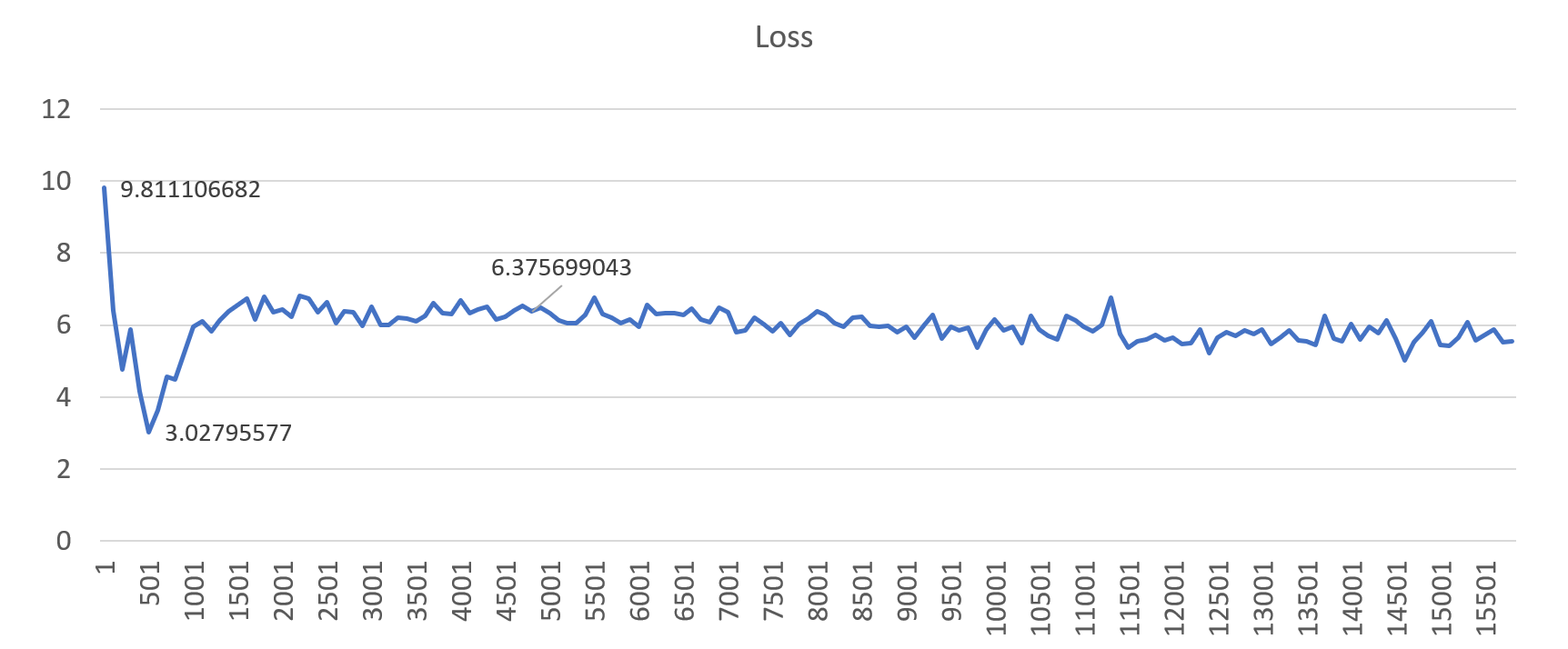
Figure 4: An example loss profile showing diverged training (gbz=130k, lr=0.01)
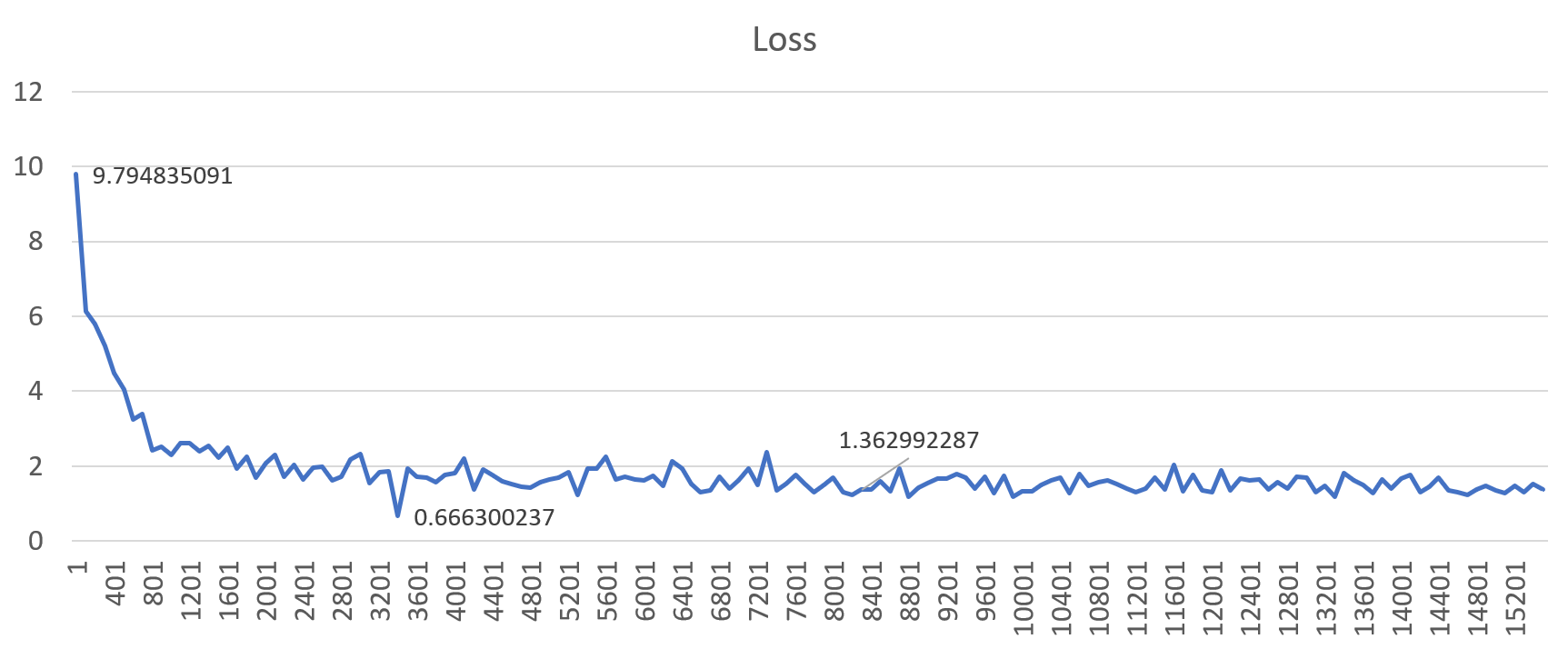
Figure 5: An example loss profile showing correct training behavior (gbz=130k, lr=0.001)
Figures 4 and 5 show the loss profiles when trained with a global batch size of 130k. Setting the learning rate to a “high” value (0.01) results in diverged training, but when set to 1e-3 (0.001), the model converges better. This results in good translation quality on the final model. Similar results were observed for all other large batch sizes.
Conclusion
In this blog, we highlighted a few common challenges when performing distributed training of the transformer model for neural machine translation (NMT). The solutions developed by Dell EMC in collaboration with Uber, Amazon, Intel, and SURFsara resulted in dramatically improved scaling capabilities and model accuracy. The results are now added part of our research paper accepted at the ISC High Performance 2019 conference. The paper has further details about the modifications to Horovod and improvements in terms of memory usage, scaling efficiency, reduced time to train and translation quality. The work has been incorporated into Horovod so that the research community can explore further scaling potential and produce more efficient NMT models.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda