




PowerProtect Data Manager – Kubernetes data protection for CSI volumes without CSI snapshots
Fri, 12 Jan 2024 18:58:56 -0000
|Read Time: 0 minutes
In this blog, we’re continuing the tradition of great (and humble 😊) PowerProtect Data Manager and k8s blogs. Other than that, in this blog, I want to introduce you to a groundbreaking new capability we’ve added in the recent PowerProtect Data Manager 19.15 release which is the ability to protect CSI (Container Storage Interface) volumes without CSI snapshots.
This new ability is advantageous mostly in cases where the CSI does not support snapshots. In other words, we are enabling the protection of CSI volumes which was otherwise difficult to protect.
So, let’s take a closer look at this new capability.
Protection of non-snapshot CSI PVCs – what does it do ?
This feature enables protection for CSI PVCs (Persistent Volumes Claims) without the use of CSI snapshots. This introduces a way to backup volumes which were provisioned by a CSI driver without support for snapshots. Refer to this list of available CSI drivers and their snapshot support status.
What are the challenges this capability comes to solve ?
The main use case this newly added capability comes to solve is backup of CSI network file shares (or NFS) that have no snapshotting capability with their CSI driver. vSAN File Services (vSAN-FS) is a prime example of that. Now PowerProtect Data Manager can protect RWX PVCs (volumes which were provisioned with the Read Write Many volume access mode) which are quite popular for many use cases and also prevalent for NFS CSI drivers.
Another challenge worth talking about is CSI snapshots, there are cases where even if the CSI driver supports snapshots, there are certain inefficiencies that are mostly related to volume cloning and are storage platform dependent. Therefore, another advantage of PPDM’s ability to backup CSI volumes without the use of CSI snapshots is that it is not tied to a specific storage platform.
How does this feature work ?
This backup of non-snapshot CSI PVCs feature is an opt-in feature meaning that the user can choose which storage class this feature would apply for; but by default, PPDM would opt to use CSI snapshots as the primary data path.
For protection of workloads which use PVCs provisioned on storage classes to be used for non-snapshot backups, the data mover pod (AKA cProxy pod) is updated with topology specifications so that it would run on the same k8s worker node as the original pod(s).
The cProxy pod mounts the PVCs in read-only mode without detaching or impacting the user application volume. This enables the feature to support the Read Write Once (RWO) volume access mode but other \access modes such as Read Write Many (RWX) and Read Only Many (ROX) are supported as well for protection of CSI PVCs without CSI snapshot.
OK, how do I configure backup of non-snapshot PVCs ?
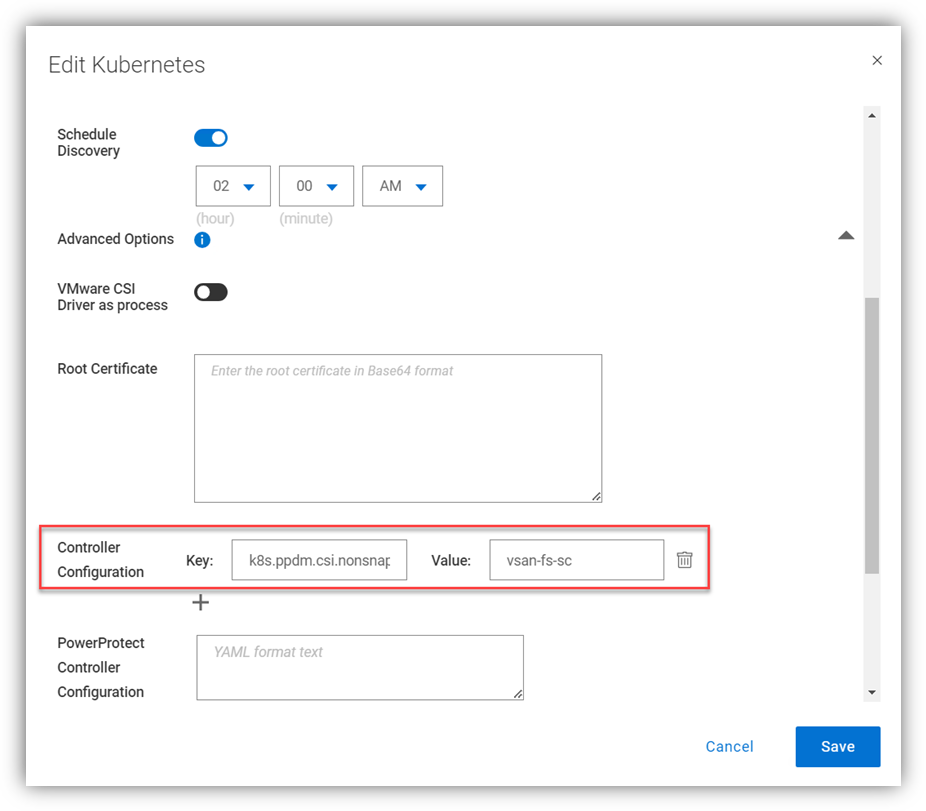
The first step is to edit the k8s asset source and under advanced options, add the controller configuration key/value pair:
Configuration Key: k8s.ppdm.csi.nonsnapshot.storageclasses
Supported Value: Comma-separated list of non-snapshot CSI storage classes
 A
A
Naturally, this can be configured when the k8s cluster is added as an asset source for the first time.
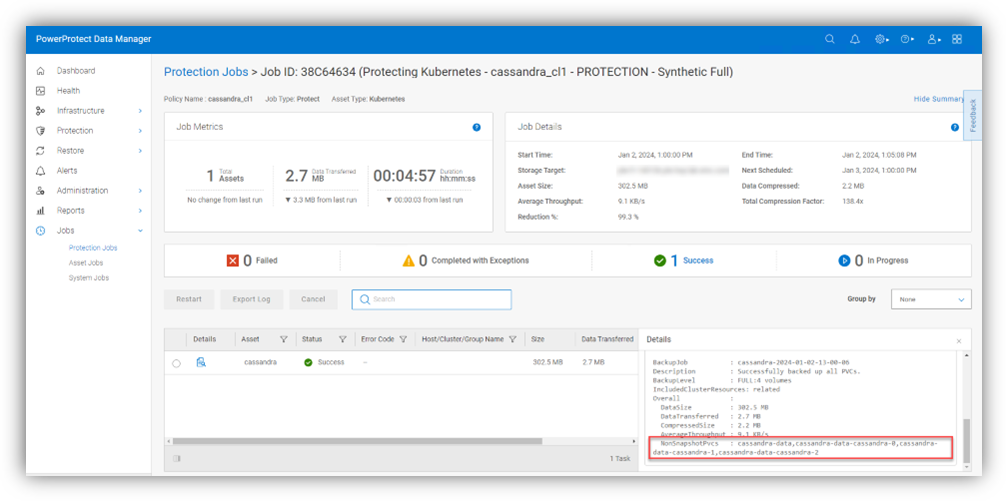
Afterwards, we just need to protect the workload by creating a protection policy and running a backup. I won’t spend much time talking about the protection process as it’s pretty straightforward, but I will include a nice little diagram to illustrate the flow here:

The protection job details include list of PVCs which were backed up without CSI snapshots under the NonSnapshotPvcs field.
Caveats and recommendations
So, I thought it would be helpful to talk about few important caveats and recommendations.
- The ability to protect CSI PVCs without CSI snapshots performs a backup of a live file system which means that data may not be captured at the same exact point-in-time as the CSI snapshot approach.
- As of PPDM 19.15, every backup of non-snapshot CSI PVCs is a full backup of the live volume. Open files would be skipped, detected, and logged by the controller so that they will be included in the next backup. The number of skipped files is shown in the PPDM UI under Jobs -> Protection Jobs for job type protect. The file paths of the skipped files appear in the controller logs (the powerprotect-controller pod running on the powerprotect namespace), which are pulled into the /logs/external-components/k8s directory on the PPDM appliance.
- The cProxy (data mover) pod is running in the user namespace as part of the backup flow so there is a need to make sure that the PPDM service account can create and delete secrets in that namespace. The PPDM RBAC YAML files can help with creating the required service account for PPDM discovery and operations. The rbac.tar.gz can be retrieved in one of the following ways:
- You can download the archive from the PowerProtect Data Manager UI by navigating to this location: Settings > Downloads > Kubernetes > RBAC
- Retrieve the rbac.tar.gz file from the PPDM appliance at the following location: /usr/local/brs/lib/cndm/misc/rbac.tar.gz
Note that the there is no requirement to provide root access to the host file system.
- vSphere CSI considerations – The vSphere CSI decides whether to provision PVCs from block storage or vSAN-FS (vSAN File Services) based on volume access mode therefore the recommendation is to separate storage classes for block and vSAN-FS. PPDM would automatically use non-snapshot on configured storage classes for PVCs with access mode of Read Only Many (ROX) and Read Write Many (RWX) as these result in PVC being provisioned on vSAN-FS.
Contrarily, PPDM would automatically backup PVCs that are provisioned using Read Write Once (RWO) with the optimized data path for VMware First Class Disks (or FCDs). So, even if there are PVCs provisioned on vSAN-FS and FCD on the same storage class, PPDM has the intelligence to trigger the most suitable data path granted that storage class is configured for non-snapshots as per the configuration we talked about earlier.
Resources
Always remember - documentation is your friend! The PowerProtect Data Manager Kubernetes User Guide has some useful information for any PPDM with K8s deployment. Furthermore, make sure to check out the PowerProtect Data Manager Compatibility Matrix.
Thanks for reading, and feel free to reach out with any questions or comments.
Idan
Related Blog Posts

PowerProtect Data Manager Deployment Automation – Deploy PowerProtect Data Manager in Minutes
Mon, 18 Sep 2023 22:34:52 -0000
|Read Time: 0 minutes
In the spirit of automating EVERYTHING, this blog will showcase the complete deployment of PowerProtect Data Manager (PPDM).
In the PPDM universe, we have auto-policy creation and ad-hoc VM backup solutions, use-case driven tasks, and so on -- all available in the official PowerProtect Data Manager GitHub repository. And now, I am proud to present to you the complete PPDM deployment automation solution.
Without further ado, let’s get started.
What does the solution do?
The PowerProtect Data Manager automated deployment solution boasts a wide array of functionality, including:
- Automatically provisioning PPDM from OVA
- Automatically deploying and configuring PPDM based on a JSON configuration file
- Adding PowerProtect DD (optional)
- Registering vCenter (optional)
- Registering remote PPDM systems (optional)
- Configuring bi-directional replication between two PPDM systems (optional)
What is the solution?
It’s a Python-based script that operates in conjunction with the PPDM REST API and vCenter.
Here is the list of prerequisites:
- Python 3.x (The script supports every platform Python is supported on)
- Python requests module, which can be installed using pip with the command: “pip install requests” or “python -m pip install requests”
- PowerProtect Data Manager 19.14 and later
- Connectivity from the host running the script to vCenter and PPDM
- PowerProtect Data Manager OVA image located on the host that is running the script
- Ovftool installed on the same host the script is running on
- Connectivity to remote PPDM system from the host running the script (only if the -ppdm parameter is provided)
How do I use the script?
The script accepts one mandatory parameter, -configfile or --config-file, and six optional parameters:
- (1) justova to deploy only the PPDM OVA or (2) skipova to skip OVA deployment
- (3) vc and (4) dd to register vCenter and PowerProtect DD respectively
- (5) ppdm and (6) cross to configure a remote PPDM system and bi-directional communication between the two PPDM systems respectively
- -cross / --bi-directional requires the argument -ppdm / --connect-ppdm to be specified as well
Here is the full script syntax:
# ppdm_deploy.py -h
usage: ppdm_deploy.py [-h] -configfile CONFIGFILE [-skipova] [-justova] [-vc] [-dd] [-ppdm] [-cross]
Script to automate PowerProtect Data Manager deployment
options:
-h, --help show this help message and exit
-configfile CONFIGFILE, --config-file CONFIGFILE
Full path to the JSON config file
-skipova, --skip-ova Optionally skips OVA deployment
-justova, --just-ova Optionally stops after OVA deployment
-vc, --register-vcenter
Optionally registers vCenter in PPDM
-dd, --add-dd Optionally adds PowerProtect DD to PPDM
-ppdm, --connect-ppdm
Optionally connects remote PPDM system
-cross, --bi-directional
Optionally configures bi-directional communication between the two PPDM hosts
Use Cases
Let’s look at some common use cases for PPDM deployment:
1. Greenfield deployment of PPDM including registration of PowerProtect DD and vCenter:
# python ppdm_deploy.py -configfile ppdm_prod.json -vc -dd2. PPDM deployment including registration of vCenter and DD as well as a remote PPDM system:
# python ppdm_deploy.py -configfile ppdm_prod.json -vc -dd -ppdm3. Full deployment of two PPDM systems including configuration of the remote PPDM systems for bi-directional communication.
In this case, we would run the script twice in the following manner:
# python ppdm_deploy.py -configfile ppdm_siteA.json -vc -dd -ppdm -cross# python ppdm_deploy.py -configfile ppdm_siteB.json -vc -dd
4. In case of evaluation or test purposes, the script can stop right after the PPDM OVA deployment:
# python ppdm_deploy.py -configfile ppdm_test.json -justova5. In case of PPDM implementation where deployment needs to take place based on an existing PPDM VM or former OVA deployment:
# python ppdm_deploy.py -configfile ppdm_prod.json -skipova
Script output
# python ppdm_deploy.py -configfile ppdm_prod.json -vc -dd -ppdm -cross
-> Provisioning PPDM from OVA
Opening OVA source: C:\Users\idan\Downloads\dellemc-ppdm-sw-19.14.0-20.ova
Opening VI target: vi://idan%40vsphere.local@vcenter.hop.lab.dell.com:443/ProdDC/host/DC_HA1/
Deploying to VI: vi://idan%40vsphere.local@vcenter.hop.lab.dell.com:443/ProdDC/host/DC_HA1/
Transfer Completed
Powering on VM: PPDM_Prod_36
Task Completed
Completed successfully
---> OVA deployment completed successfully
-> Checking connectivity to PPDM
---> PPDM IP 10.0.0.36 is reachable
-> Checking PPDM API readiness
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is unreachable. Retrying
---> PPDM API is available
-> Obtaining PPDM configuration information
---> PPDM is deployment ready
-> Accepting PPDM EULA
---> PPDM EULA accepted
-> Applying license
-> Using Capacity license
-> Applying SMTP settings
-> Configuring encryption
-> Building PPDM deployment configuration
-> Time zone detected: Asia/Jerusalem
-> Name resolution completed successfully
-> Deploying PPDM
---> Deploying configuration 848a68bb-bd8e-4f91-8a63-f23cd079c905
---> Deployment status PROGRESS 2%
---> Deployment status PROGRESS 16%
---> Deployment status PROGRESS 20%
---> Deployment status PROGRESS 28%
---> Deployment status PROGRESS 28%
---> Deployment status PROGRESS 28%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 32%
---> Deployment status PROGRESS 36%
---> Deployment status PROGRESS 40%
---> Deployment status PROGRESS 40%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 48%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 52%
---> Deployment status PROGRESS 56%
---> Deployment status PROGRESS 56%
---> Deployment status PROGRESS 56%
---> Deployment status PROGRESS 60%
---> Deployment status PROGRESS 60%
---> Deployment status PROGRESS 72%
---> Deployment status PROGRESS 76%
---> Deployment status PROGRESS 76%
---> Deployment status PROGRESS 80%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status PROGRESS 88%
---> Deployment status SUCCESS 100%
-> PPDM deployed successfully
-> Initiating post-install tasks
-> Accepting TELEMETRY EULA
---> TELEMETRY EULA accepted
-> AutoSupport configured successfully
-> vCenter registered successfully
--> Hosting vCenter configured successfully
-> PowerProtect DD registered successfully
-> Connecting peer PPDM host
---> Monitoring activity ID 01941a19-ce75-4227-9057-03f60eb78b38
---> Activity status RUNNING 0%
---> Activity status COMPLETED 100%
---> Peer PPDM registered successfully
-> Configuring bi-directional replication direction
---> Monitoring activity ID 8464f126-4f28-4799-9e25-37fe752d54cf
---> Activity status RUNNING 0%
---> Activity status COMPLETED 100%
---> Peer PPDM registered successfully
-> All tasks have been completed
Where can I find it?
You can find the script and the config file in the official PowerProtect GitHub repository:
https://github.com/dell/powerprotect-data-manager
Resources
Other than the official PPDM repo on GitHub, developer.dell.com provides comprehensive online API documentation, including the PPDM REST API.
How can I get help?
For additional support, you are more than welcome to raise an issue in GitHub or reach out to me by email:
Thanks for reading!
Idan
Author: Idan Kentor

Accelerating and Optimizing AI Operations with Infrastructure as Code


Fri, 03 May 2024 12:00:00 -0000
|Read Time: 0 minutes
Accelerating and Optimizing AI Operations with Infrastructure as Code
Achieving maturity in a DevOps organization requires overcoming various barriers and following specific steps. The level of maturity attained depends on the short-term and long-term goals set for the infrastructure. In the short term, IT teams must focus on upskilling their resources and integrating tools for containerization and automation throughout the operating lifecycles, from Day 0 to Day 2. Any progress made in scaling up containerized environments and automating processes significantly enhances the long-term economic viability and sustainability of the company. Furthermore, in the long term, it involves deploying these solutions across multicloud, multisite landscapes and effectively balancing workloads.
The optimization of your AI applications, and by extension, other high-value workloads, hinges upon the velocity, scalability, and efficacy of your infrastructure, as well as the maturity of your DevOps processes. Prior to the explosion that is AI, recent survey results indicated the state of automation for infrastructure operations’ workflows was overall less than 50%; partner that with twofold the increase of application counts and organizations may struggle against the waves of change[1].
From compute capabilities to storage density and speed, spanning across unstructured, block, and file formats, there exists fundamental elements of automation ripe for swift integration to establish a robust foundation. By seamlessly layering pre-built integration tools and a complementary portfolio of products at each stage, the journey towards ramping up AI can be alleviated.
There are important considerations regarding the various hardware infrastructure components for a generative AI system, including high performance computing, highspeed networking, and scalable, high-capacity, and low-latency storage to name a few. The infrastructure requirements for AI/ML workloads are dynamic and dependent on several factors, including the nature of the task, the size of the dataset, the complexity of the model, and the desired performance levels. There is no one-size-fits-all solution when it comes to Gen AI infrastructure, as different tasks and projects may demand unique configurations. Central to the success of generative AI initiatives is the adoption of Infrastructure-as-Code (IaC) principles which facilitate the automation and orchestration of underlying infrastructure components. By leveraging IaC tools like RedHat Ansible and HashiCorp Terraform, organizations can streamline the deployment and management of hardware resources, ensuring seamless integration with Gen AI workloads.
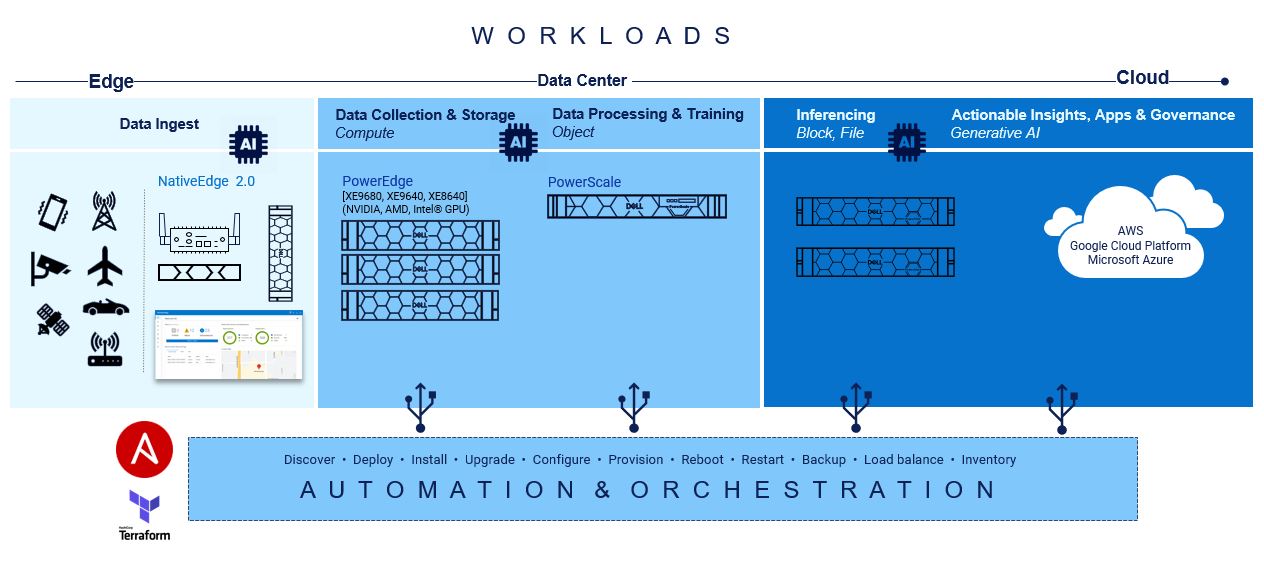 At the base of this foundation is Red Hat Ansible modules for Dell, and they speed up the provisioning of servers and storage for quick AI application workload mobility.
At the base of this foundation is Red Hat Ansible modules for Dell, and they speed up the provisioning of servers and storage for quick AI application workload mobility.
Creating playbooks with Ansible to automate server configurations, provisioning, deployments, and updates are seamless while data is being collected. Due to the declarative and mutable nature of Ansible, the playbooks can be changed in real-time without interruption to processes or end users.
Compute
On the compute front, a lot goes into configuring servers for the different AI and ML operations:
GPU Drivers and CUDA toolkit Installation: Install appropriate GPU drivers for the server's GPU hardware. For example, installing CUDA Toolkit and drivers to enable GPU acceleration for deep learning frameworks such as TensorFlow and PyTorch.
Deep Learning Framework Installation: Install popular deep learning frameworks such as TensorFlow or PyTorch, along with their associated dependencies.
Containerization: Consider using containerization technologies such as Docker or Kubernetes to encapsulate AI workloads and their dependencies into portable and isolated containers. Containerization facilitates reproducibility, scalability, and resource isolation, making it easier to deploy and manage GenAI workloads across different environments.
Performance Optimization: Optimize server configurations, kernel parameters, and system settings to maximize performance and resource utilization for GenAI workloads. Tune CPU and GPU settings, memory allocation, disk I/O, and network configurations based on workload characteristics and hardware capabilities.
Monitoring and Management: Implement monitoring and management tools to track server performance metrics, resource utilization, and workload behavior in real-time.
Security Hardening: Ensure server security by applying security best practices, installing security patches and updates, configuring firewalls, and implementing access controls. Protect sensitive data and AI models from unauthorized access, tampering, or exploitation by following security guidelines and compliance standards.
Dell Openmanage Ansible collection offers modules and roles both at the iDRAC/Redfish interface level and at the OpenManage Enterprise level for server configurations such as PowerEdge XE 9860 designed to collect, develop, train, and deploy large machine learning models (LLMs).
The following is a summary of the OME and iDRAC modules and roles as part of the openmanage collection:


Storage
When it comes to AI and storage, during the data processing and training aspects, customers rely on scalable and simple access to file systems which increased data is trained on. With AI unstructured data storage is necessary for the bounty of rich context and nuance that will be accessed during the building phase. It also highly depends on user access to be variable, and Ansible automation playbooks can help change and adapt quickly.
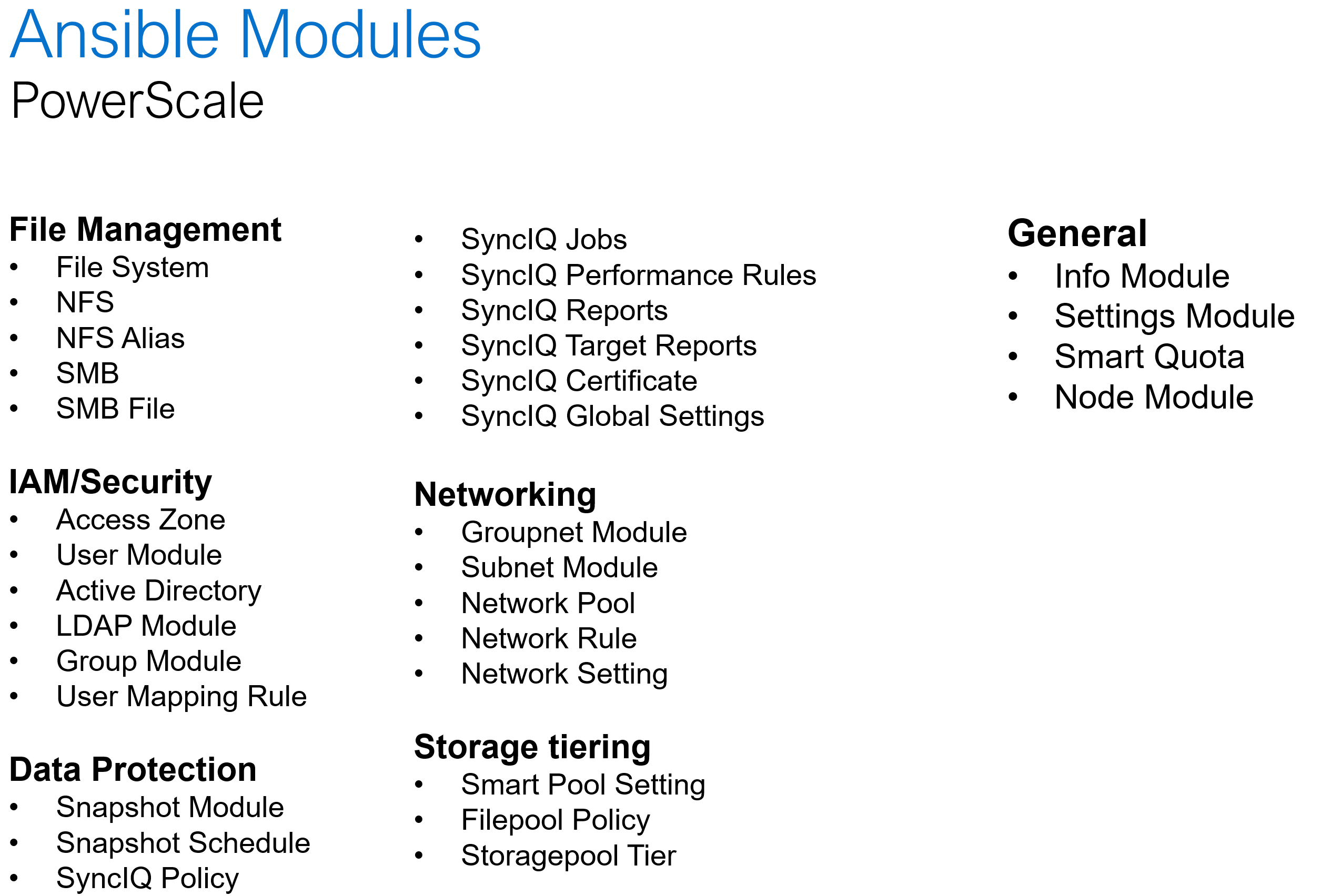
Dell PowerScale is the world’s leading scale-out NAS platform, and it recently became the first ethernet storage certified on NVIDIA SuperPod. When it comes to Ansible automation, PowerScale comes with an extensive set of modules that covers a wide range of platform operations:
Software defined storage
Hyper converged platforms like PowerFlex offer highly scalable and configurable compute and storage clusters. In addition to the common day-2 tasks like storage provisioning, data protection and user management, the Ansible collection for PowerFlex can be used for cluster deployment and expansion. Here is a summary of what Ansible collections for PowerFlex offers:

Conclusion
The one thing agreed upon is that Generative AI tools need the scale, repeatability, and reliability beyond anything created from the software and data center combined. This is precisely what building infrastructure-as-code practices into a multisite operation are designated to do. From PowerEdge to PowerScale, the level of capacity and performance is unmatched. This allows AI operations and Generative AI to absorb, grow and provide the intelligence that organizations need to be competitive and innovative.
[1] Infrastructure-as-code and DevOps Automation: The Keys to Unlocking Innovation and Resilience, September 2023
Other resources:
GenAI Acceleration Depends on Infrastructure as Code
Authors: Jennifer Aspesi, Parasar Kodati