




PowerMax 2500 and 8500 Dynamic Fabric—A High-Performance Clustered Architecture for Enterprise Storage
Tue, 18 Apr 2023 16:15:55 -0000
|Read Time: 0 minutes
Introduced in 2022, the PowerMax 2500 and 8500 systems represent the next generation of the PowerMax family. At their core, the PowerMax 2500 and 8500 have a high-performing cluster architecture solely dedicated to processing the vast amounts of storage operations and storage data from modern applications. The four key components of the PowerMax cluster architecture are the compute nodes; the storage Dynamic Media Enclosures (DMEs); the Dynamic Fabric that ties the elements together; and the internal system software, PowerMaxOS 10. The PowerMax 2500 and 8500 cluster architecture provides the following benefits natively without the need for added hardware, software, or licensing:
- High reliability and fault tolerance: All the nodes in the PowerMax can access application I/O and supply resources to process it, making it a true shared everything, active/active system. In case of a node failure, there is no failover operation needed as with active/passive systems. PowerMaxOS 10 will automatically redirect the failed node’s I/O to other nodes. Since no failover is required, there is no need to ever configure a quorum device to guard against issues such as “split brain.”
- Simplicity: All the compute nodes and DMEs in a PowerMax system appear to the user as a single entity. A user does not have to log in to separate individual nodes to manage or configure the PowerMax system. The management of the entire system is performed using the HTML5-based Unisphere for PowerMax UI and/or REST API. These tools provide an easy-to-use interface for management actions and monitoring operations that are crucial to an organization’s needs.
- Fully autonomous operations: PowerMaxOS 10 manages all system resources autonomously—continuously running diagnostics, and scrubbing and moving data within the system for maximum performance and availability 24x7. There is no need to manually configure load balancing between the nodes because PowerMaxOS 10 automatically decides which node will process the incoming I/O data based on locality and resource availability.
- Predicable performance and scalability: As compute requirements increase, you can “scale out” the PowerMax system by adding nodes nondisruptively to supply a predictable linear increase in performance and computing power. As capacity requirements increase, you can “scale up” the system granularly, using single-drive increments. This allows PowerMax to scale based on application requirements rather than system architectural requirements. The architecture also enables holistic software scalability; the PowerMax can support 64K host-presentable devices, more than 65 million snapshots, and 2,048 remote replication groups with other systems.
The compute nodes, DMEs, and PowerMaxOS 10 software supply the foundation for a true active/active, shared everything solution for the demanding requirements of enterprise data centers. The glue that ties all these components together and allows PowerMax to deliver these benefits to customers is the internal Dynamic Fabric.
PowerMax Dynamic Fabric
Both the PowerMax 2500 and 8500 use full end-to-end, internal Non-Volatile Memory Express over Fabrics (NVMe-oF) topologies between the compute nodes and DMEs. These NVMe-oF topologies are referred to as the PowerMax Dynamic Fabric.
Core elements
The Dynamic Fabric turns the compute and backend storage elements into individual independent endpoints on a large internal storage fabric. Each endpoint in this fabric is dual ported, with each port being connected to a physically isolated fabric—Fabric A or Fabric B—for redundancy. These individual compute and storage endpoints can be placed into shared resource pools, disaggregating the storage and compute in the system. In this architecture, all compute node endpoints can access all shared memory in all the other compute nodes using the system’s high-speed RDMA protocol. Further, all compute node endpoints can access all storage endpoints and SSDs in the DMEs using the system’s high-speed NVMe-oF protocol. This access to all shared memory and all storage endpoints and DME SSDs creates a true active/active and share everything system architecture. This system disaggregation decouples the compute and storage so that they can be scaled and provisioned independently of each other to meet application requirements rather than adhering to strict system architecture requirements. To allow for this shared everything decoupled architecture, the Dynamic Fabric provides the system with these key elements:
- Ability to share memory access between the nodes
- High-speed interconnection between cluster components
- End-to-end data consistency checking based on SCSI T10-DIF Protection Information that protects against erroneous data transmission and data corruption
Shared memory
The PowerMax system uses an active/active, share everything architecture. This includes memory content sharing, where each node can access data in another node’s memory. On PowerMax, this is done by using Remote Direct Memory Access (RDMA). RDMA is the ability to read from and write to memory on an external compute node without interrupting the processing of the CPU(s) on that node. RDMA permits high-throughput, low-latency data transfer between the memory of two computing systems, which is essential in high performing clustered computing systems such as PowerMax. Using RDMA, all PowerMax nodes can access the memory content of any other node in the system as if it was its own. The ability for each node to access other nodes’ memory using RDMA turns the total capacity of cache in the PowerMax systems into a truly shared resource pool called PowerMax Global Cache.
High-speed interconnecting fabric
PowerMax RDMA communications are subject to fabric latency, thereby making the PowerMax a Non-Uniform Memory Access (NUMA) system. A key requirement for PowerMax Global Cache (and NUMA systems in general) is that the fabric that transports the internode RDMA communications must be extremely low latency and have high bandwidth. For this reason, PowerMax uses the InfiniBand (IB) protocol as its primary internode fabric. IB is a fabric technology and set of protocols most often seen in high-performance computing (HPC) environments such as Wall Street’s real-time trading and risk analysis applications. It is used in these environments because it natively provides:
- A highly energy-efficient, high-bandwidth, and low-latency fabric: In PowerMax, the IB fabric is run in connected mode, where a single lane can transmit 100 Gbps with MTUs of 2 MB. Larger single-lane data transfer is more efficient than smaller multilane data transfer because more data is transferred using a single clock cycle—consuming far fewer compute resources to transfer data. Studies have shown that when run in connected mode, IB is over 70 percent more energy efficient per byte sent than other RDMA fabric choices such as Ethernet: Evaluating Energy Efficiency of Gigabit Ethernet and Infiniband Software Stacks in Data Centres (IEEE study).
- Scalability: IB can support tens of thousands of fabric endpoints in a flat single-subnet network. Thus, you can scale the PowerMax disaggregated architecture by adding independent compute and storage endpoints into the fabric without having to add more subnets and without incurring additional latency penalties.
- High security: The protocol is implemented in hardware, and the communication attributes are configured centrally in a way that does not enable software applications to gain control over them and maliciously spoof or change those attributes.
- Resiliency: RDMA data transfers can be protected with SCSI T10-DIF Protection Information. This allows detection of data corruption from many sources, and, with the PowerMax redundant architecture, the correct data can always be referenced.
Implementation
Using RDMA and NVMe-oF with an IB fabric architecture, the PowerMax Dynamic Fabric delivers the high levels of performance, scalability, efficiency, and security that enterprise customers require. Implementation of the Dynamic Fabric to achieve these outcomes is different between the PowerMax 2500 and PowerMax 8500.
PowerMax 2500
A PowerMax 2500 can scale up to two node pairs. Each node pair comes with its own direct-attached PCIe DME. A key architectural part of the PowerMax 2500 Dynamic Fabric is the use of PCIe multihost technology. In the case of the PowerMax 2500, PCIe multihost allows both nodes to share each other's internal PCIe IB 100 Gb Host Channel Adapter (HCA), creating a high-speed, switchless fabric between the nodes for low-latency RDMA communication. Data transfer between the nodes and direct-attached PCIe DMEs uses a x32 lane NVMe/PCIe fabric.
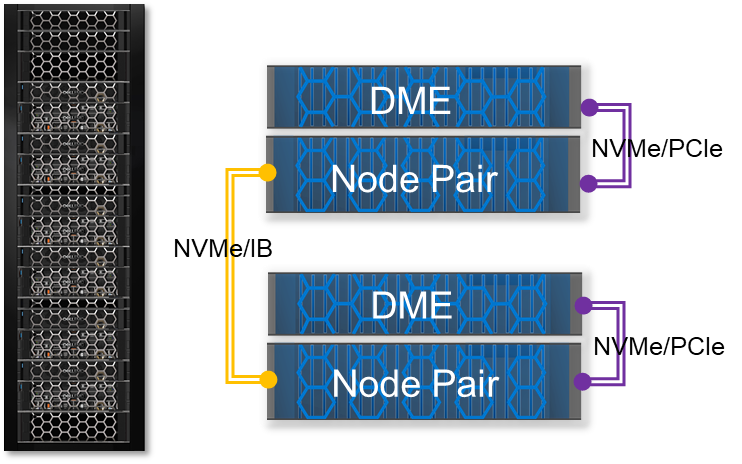
The Dynamic Fabric configuration on the PowerMax 2500 allows the system to deliver performance and scalability in a compact package. It allows for higher levels of efficiency because the PowerMax 2500 can store up to 7x more capacity in half the rack space (over 4 PBe in 5U) compared with the earlier-generation PowerMax 2000. Along with its compact design, the 2500 supports the full complement of rich data services for open systems, mainframe, file, and virtual environments.
PowerMax 8500
The PowerMax 8500 Dynamic Fabric is a fully switched 100 Gbps per lane, NVMe/IB fabric that is used by all RDMA communications and NVMe data transfers. This is different from the PowerMax 2500 where the NVMe data transfers from the node to its PCIe-connected DME use NVMe/PCIe. On the PowerMax 8500, each compute node and storage DME are treated as unique endpoints on the fabric, allowing them to be added into the fabric independently of each other while being able to access all other endpoints. The system nodes and DMEs are fully disaggregated and dynamically connected, allowing the system to scale up compute to eight-node pairs while scaling out storage to eight DMEs—providing over 18 PBe in a single system.
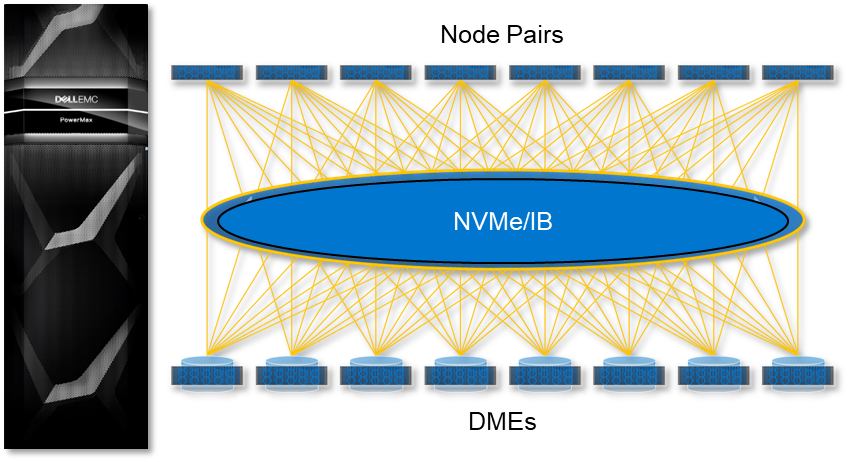
Another difference with the Dynamic Fabric on the PowerMax 8500 is the use of intelligent DMEs. The DMEs connect into the NVMe/IB fabric using dual Link Control Cards (LCCs), each with dual 100 Gb IB ports. Each LCC board has its own NVIDIA BlueField data processing unit (DPU), allowing it to perform critical storage management functions such as fabric offload. The LCCs with their DPUs essentially make each PowerMax 8500 DME a unique active/active, dual-controller NVMe storage subsystem on the fabric.
Conclusion
The Dynamic Fabric is what enables the PowerMax 2500 and 8500 to function as a true active/active, share everything architecture for enterprise storage. With this native architecture, customers can:
- Achieve high levels of fault tolerance and resiliency natively without the need for costly additional hardware and software
- Meet workload requirements with less power and fewer resources
- Scale up and scale out with no manual intervention for load balancing or other backend clustering operations, which are performed automatically by PowerMaxOS
The Dynamic Fabric is the key component that allows for the low-latency, high-bandwidth connections required for RDMA communication between the nodes and for the extensive NVMe data processing and movement between the nodes and DMEs in the system. The Dynamic Fabric is the backbone of the PowerMax 2500 and 8500. It allows the systems to deliver the kind of performance, security, efficiency, and scalability required by the modern data center.
Resources
- The Next-Generation PowerMax Family Overview White Paper
- The PowerMax 2500 and 8500 Specification Sheet
- The PowerMax 2500 and 8500 Data Sheet
- New PowerMax Architecture adds NVIDIA Bluefield DPUs
Author: Jim Salvadore, Senior Principal Engineering Technologist
Email: james.salvadore@dell.com
Related Blog Posts

Model Training – Dell Validated Design
Fri, 03 May 2024 16:09:06 -0000
|Read Time: 0 minutes
Introduction
When it comes to large language models (LLMs), there may be fundamental question that everyone looking to leverage foundational models need to answer: should I train my model, or should I customize an existing model?
There can be strong arguments for either. In a previous post, Nomuka Luehr covered some popular customization approaches. In this blog, I will look at the other side of the question: training, and answer the following questions: Why would I train an LLM? What factors should I consider? I’ll also cover the recently announced Generative AI in the Enterprise – Model Training Dell Validated Design - A Scalable and Modular Production Infrastructure for AI Large Language Model Training. This is a collaborative effort between Dell Technologies and NVIDIA, aimed at facilitating high-performance, scalable, and modular solutions for training large language models (LLMs) in enterprise settings (more about that later).
Training pipeline
The data pipelines for training and customization are similar because both processes involve feeding specific datasets through the LLM.
In the case of training, the dataset is typically much larger than for customization, because customization is targeted at a specific domain. Remember, for training a model, the goal is to embed as much knowledge into the model as possible, so the dataset must be large.
This raises the question of the dataset and its accuracy and relevance. Curating and preparing the data are essential processes to avoid biases and misinformation. This step is vital for ensuring the quality and relevance of the data fed into the LLM. It involves meticulously selecting and refining data to minimize biases and misinformation, which if overlooked, could compromise the model's output accuracy and reliability. Data curation is not just about gathering information; it's about ensuring that the model's knowledge base is comprehensive, balanced, and reflects a wide array of perspectives.
When the dataset is curated and prepped, the actual process of training involves a series of steps where the data is fed through the LLM. The model generates outputs based on the input provided, which are then compared against expected results. Discrepancies between the actual and expected outputs lead to adjustments in the model's weights, gradually improving its accuracy through iterative refinement (using supervised learning, unsupervised learning, and so on).
While the overarching principle of this process might seem straightforward, it's anything but simple. Each step involves complex decisions, from selecting the right data and preprocessing it effectively to customizing the model's parameters for optimal performance. Moreover, the training landscape is evolving, with advancements, such as supervised and unsupervised learning, which offer different pathways to model development. Supervised learning, with its reliance on labeled datasets, remains a cornerstone for most LLM training regimes, by providing a structured way to embed knowledge. However, unsupervised learning, which explores data patterns without predefined labels, is gaining traction for its ability to unearth novel insights.
These intricacies highlight the importance of leveraging advanced tools and technologies. Companies like NVIDIA are at the forefront, offering sophisticated software stacks that automate many aspects of the process, and reducing the barriers to entry for those looking to develop or refine LLMs.
Network and storage performance
In the previous section, I touched on the dataset required to train or customize models. While having the right dataset is a critical piece of this process, being able to deliver that dataset fast enough to the GPUs running the model is another critical and yet often overlooked piece. To achieve that, you must consider two components:
- Storage performance
- Network performance
For anyone looking to train a model, having a node-to-node (also known as East-West) network infrastructure based on 100Gbps, or better yet, 400Gbps, is critical, because it ensures sufficient bandwidth and throughput to keep saturated the type of GPUs, such as the NVIDIA H100, required for training.
Because customization datasets are typically smaller than full training datasets, a 100Gbps network can be sufficient, but as with everything in technology, your mileage may vary and proper testing is critical to ensure adequate performance for your needs.
Datasets used to train models are typically very large: in the 100s of GB. For instance, the dataset used to train GPT-4 is said to be over 550GB. With the advance of RDMA over Converged Ethernet (RoCE), GPUs can pull the data directly from storage. And because 100Gbps networks are able to support that load, the bottleneck has moved to the storage.
Because of the nature of large language models, the dataset used to train them is made of unstructured data, such as Sharepoint sites and document repositories, and are therefore most often hosted on network attached storage, such as Dell PowerScale. I am not going to get into further details on the storage part because I’ll be publishing another blog on how to use PowerScale to support model training. But you must make careful considerations when designing the storage to ensure that the storage is able to keep up with the GPUs and the network.
A note about checkpointing
As we previously mentioned, the process of training is iterative. Based on the input provided, the model generates outputs, which are then compared against expected results. Discrepancies between the actual and expected outputs lead to adjustments in the model's weights, gradually improving its accuracy through iterative refinement. This process is repeated across many iterations over the entire training dataset.
A training run (that is, running an entire dataset through a model and updating its weight), is extremely time consuming and resource intensive. According to this blog post, a single training run of ChatGPT-4 costs about $4.6M. Imagine running a few of them in a row, only to have an issue and having to start again. Because of the cost associated with training runs, it is often a good idea to save the weights of the model at an intermediate stage during the run. Should something fail later on, you can load the saved weights and restart from that point. Snapshotting the weights of a model in this way is called checkpointing. The challenge with checkpointing is performance.
A checkpoint is typically stored on an external storage system, so again, storage performance and network performance are critical considerations to offer the proper bandwidth and throughput for checkpointing. For instance, the Llama-2 70B consumes about 129GB of storage. Because each of its checkpoints is the exact same predictable size, they can be saved quickly (to disk) to ensure the proper performance of the training process.
NVIDIA software stack
The choice of which framework to use depends on whether you typically lean more towards doing it yourself or buying specific outcomes. The benefit of doing it yourself is ultimate flexibility, sometimes at the expense of time to market, whereas buying an outcome can offer better time to market at the expense of having to choose within a pre-determined set of components. In my case, I have always tended to favor buying outcomes, which is why I want to cover the NVIDIA AI Enterprise (NVAIE) software stack at a high level.
The following figure is a simple layered cake that showcases the various components of the NVAIE, in light green.
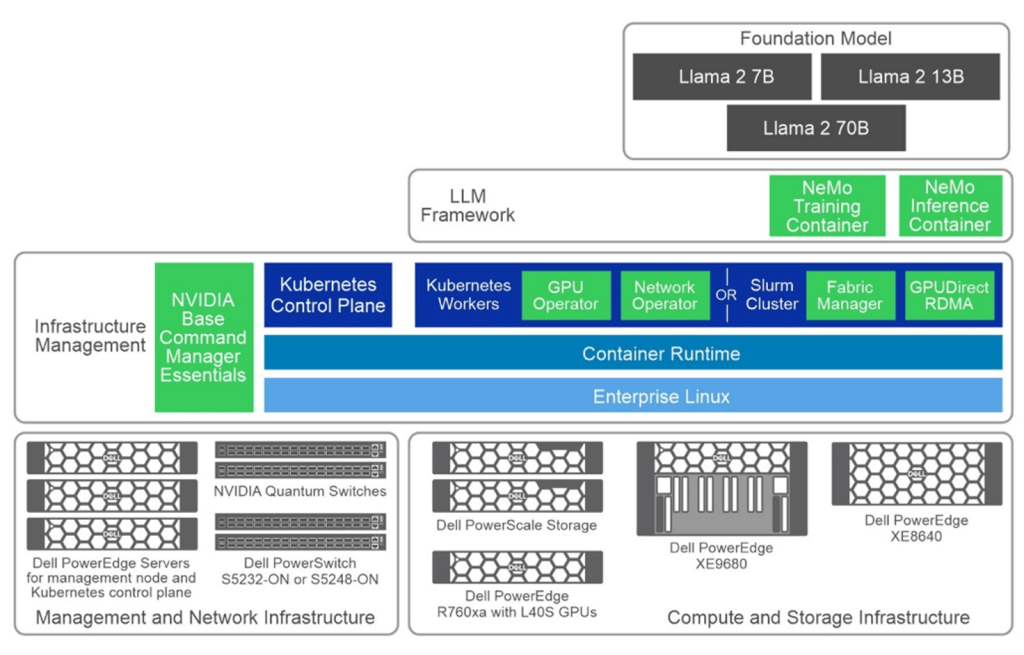
The white paper Generative AI in the Enterprise – Model Training Dell Validated Design provides an in-depth exploration of a reference design developed by Dell Technologies in collaboration with NVIDIA. It offers enterprises a robust and scalable framework to train large language models effectively. Whether you're a CTO, AI engineer, or IT executive, this guide addresses the crucial aspects of model training infrastructure, including hardware specifications, software design, and practical validation findings.
Training the Dell Validated Design architecture
The validated architecture aims to give the reader a broad output of model training results. We used two separate configuration types across the compute, network and GPU stack.
There are two 8x PowerEdge XE9680 configurations both with 8x NVIDIA H100 SXM GPUs. The difference between the configurations (again) is the network. The first configuration is equipped with 8x ConnectX-7; the second configuration is equipped with four ConnectX-7 adapters. Both are configured for NDR.
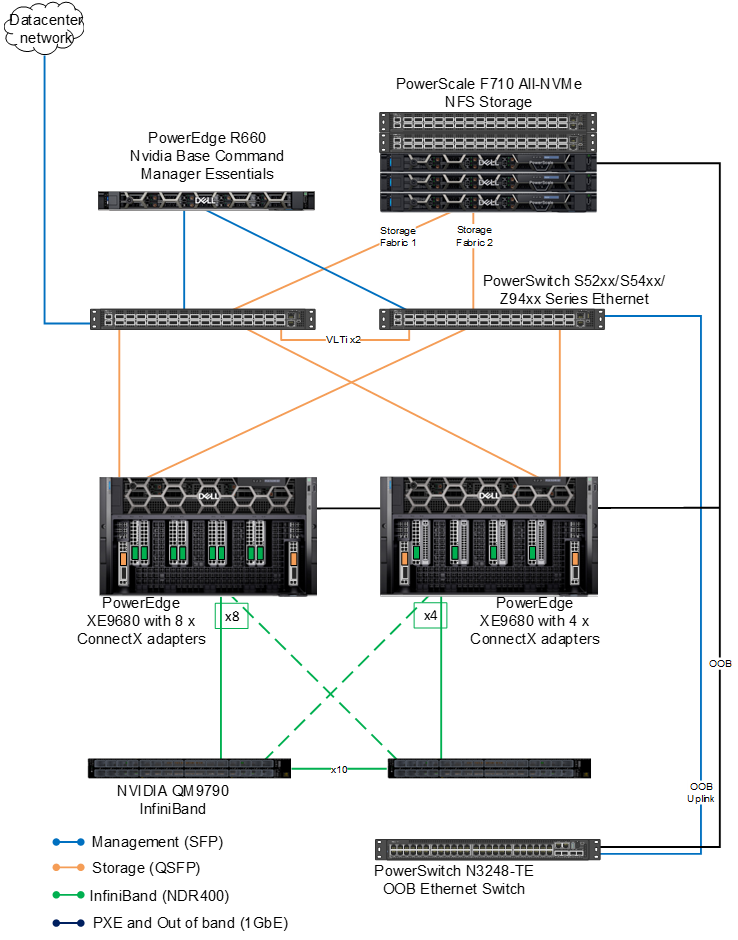
On the storage side, the evolution of PowerScale continues to thrive in the AI domain with the launch of its latest line, including the notable PowerScale F710. This addition embraces Dell PowerEdge 16G servers, heralding a new era in performance capabilities for PowerScale's all-flash nodes. On the software side, the F710 benefits from the enhanced performance features found in the PowerScale OneFS 9.7 update.
Key takeaways
The guide provides training times for the Llama 2 7B and Llama 2 70B models over 500 steps, with variations based on the number of nodes and configurations used.
Why only 500 steps? The decision to train models for a set number of steps (500), rather than to train models for convergence, is practical for validation purposes. It allows for a consistent benchmarking metric across different scenarios and models, to produce a clearer comparison of infrastructure efficiency and model performance in the early stages.
Efficiency of Model Sizing: The choice of 7B and 70B Llama 2 model architectures indicates a strategic approach to balance computational efficiency with potential model performance. Smaller models like the 7B are quicker to train and require fewer resources, making them suitable for preliminary tests and smaller-scale applications. On the other hand, the 70B model, while significantly more resource-intensive, was chosen for its potential to capture more complex patterns and provide more accurate outputs.
Configuration and Resource Optimization: Comparing two hardware configurations provides valuable insights into optimizing resource allocation. While higher-end configurations (Configuration 1 with 8 adapters) offer slightly better performance, you must weigh the marginal gains against the increased costs. This highlights the importance of tailoring the hardware setup to the specific needs and scale of the project, where sometimes, a less maximalist approach (Configuration 2 with 4 adapters) can provide a more balanced cost-to-benefit ratio, especially in smaller setups. Certainly something to think about!
Parallelism Settings: The specific settings for tensor and pipeline parallelism (as covered in the guide), along with batch sizes and sequence lengths, are crucial for training efficiency. These settings impact the training speed and model performance, indicating the need for careful tuning to balance resource use with training effectiveness. The choice of these parameters reflects a strategic approach to managing computational loads and training times.
To close
With the scalable and modular infrastructure designed by Dell Technologies and NVIDIA, you are well-equipped to embark on or enhance your AI initiatives. Leverage this blueprint to drive innovation, refine your operational capabilities, and maintain a competitive edge in harnessing the power of large language models.
Authors: Bertrand Sirodot and Damian Erangey
MLPerf™ Inference v4.0 Performance on Dell PowerEdge R760xa and R7615 Servers with NVIDIA L40S GPUs
Fri, 05 Apr 2024 17:41:56 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf™ Inference v4.0 benchmark suite. This blog highlights Dell Technologies’ closed division submission made for the Dell PowerEdge R760xa, Dell PowerEdge R7615, and Dell PowerEdge R750xa servers with NVIDIA L40S and NVIDIA A100 GPUs.
Introduction
This blog provides relevant conclusions about the performance improvements that are achieved on the PowerEdge R760xa and R7615 servers with the NVIDIA L40S GPU compared to the PowerEdge R750xa server with the NVIDIA A100 GPU. In the following comparisons, we held the GPU constant across the PowerEdge R760xa and PowerEdge R7615 servers to show the excellent performance of the NVIDIA L40S GPU. Additionally, we also compared the PowerEdge R750xa server with the NVIDIA A100 GPU to its successor the PowerEdge R760xa server with the NVIDIA L40S GPU.
System Under Test configuration
The following table shows the System Under Test (SUT) configuration for the PowerEdge servers.
Table 1: SUT configuration of the Dell PowerEdge R750xa, R760xa, and R7615 servers for MLPerf Inference v4.0
Server | PowerEdge R750xa | PowerEdge R760xa | PowerEdge R7615 |
MLPerf Version | V4.0
| ||
GPU | NVIDIA A100 PCIe 80 GB | NVIDIA L40S
| |
Number of GPUs | 4 | 2 | |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | R760xa_L40Sx4_TRT | R7615_L40Sx2_TRT
|
CPU | 2 x Intel Xeon Gold 6338 CPU @ 2.00GHz | 2 x Intel Xeon Platinum 8470Q | 1 x AMD EPYC 9354 32-Core Processor |
Memory | 512 GB | ||
Software Stack | TensorRT 9.3.0 CUDA 12.2 cuDNN 8.9.2 Driver 535.54.03 / 535.104.12 DALI 1.28.0 | ||
The following table lists the technical specifications of the NVIDIA L40S and NVIDIA A100 GPUs.
Table 2: Technical specifications of the NVIDIA A100 and NVIDIA L40S GPUs
Model | NVIDIA A100 | NVIDIA L40S | ||
Form factor | SXM4 | PCIe Gen4 | PCIe Gen4 | |
GPU architecture | Ampere | Ada Lovelace | ||
CUDA cores | 6912 | 18176 | ||
Memory size | 80 GB | 48 GB | ||
Memory type | HBM2e | HBM2e | ||
Base clock | 1275 MHz | 1065 MHz | 1110 MHz | |
Boost clock | 1410 MHz | 2520 MHz | ||
Memory clock | 1593 MHz | 1512 MHz | 2250 MHz | |
MIG support | Yes | No | ||
Peak memory bandwidth | 2039 GB/s | 1935 GB/s | 864 GB/s | |
Total board power | 500 W | 300 W | 350 W | |
Dell PowerEdge R760xa server
The PowerEdge R760xa server shines as an Artificial Intelligence (AI) workload server with its cutting-edge inferencing capabilities. This server represents the pinnacle of performance in the AI inferencing space with its processing prowess enabled by Intel Xeon Platinum processors and NVIDIA L40S GPUs. Coupled with NVIDIA TensorRT and CUDA 12.2, the PowerEdge R760xa server is positioned perfectly for any AI workload including, but not limited to, Large Language Models, computer vision, Natural Language Processing, robotics, and edge computing. Whether you are processing image recognition tasks, natural language understanding, or deep learning models, the PowerEdge R760xa server provides the computational muscle for reliable, precise, and fast results.

Figure 1: Front view of the Dell PowerEdge R760xa server

Figure 2: Top view of the Dell PowerEdge R760xa server
Dell PowerEdge R7615 server
The PowerEdge R7615 server stands out as an excellent choice for AI, machine learning (ML), and deep learning (DL) workloads due to its robust performance capabilities and optimized architecture. With its powerful processing capabilities including up to three NVIDIA L40S GPUs supported by TensorRT, this server can handle complex neural network inference and training tasks with ease. Powered by a single AMD EPYC processor, this server performs well for any demanding AI workloads.

Figure 3: Front view of the Dell PowerEdge R7615 server

Figure 4: Top view of the Dell PowerEdge R7615 server
Dell PowerEdge R750xa server
The PowerEdge R750xa server is a perfect blend of technological prowess and innovation. This server is equipped with Intel Xeon Gold processors and the latest NVIDIA GPUs. The PowerEdge R760xa server is designed for the most demanding AI, ML, and DL workloads as it is compatible with the latest NVIDIA TensorRT engine and CUDA version. With up to nine PCIe Gen4 slots and availability in a 1U or 2U configuration, the PowerEdge R750xa server is an excellent option for any demanding workload.

Figure 5: Front view of the Dell PowerEdge R750xa server

Figure 6: Top view of the Dell PowerEdge R750xa server
Performance results
Classical Deep Learning models performance
The following figure presents the results as a ratio of normalized numbers over the Dell PowerEdge R750xa server with four NVIDIA A100 GPUs. This result provides an easy-to-read comparison of three systems and several benchmarks.
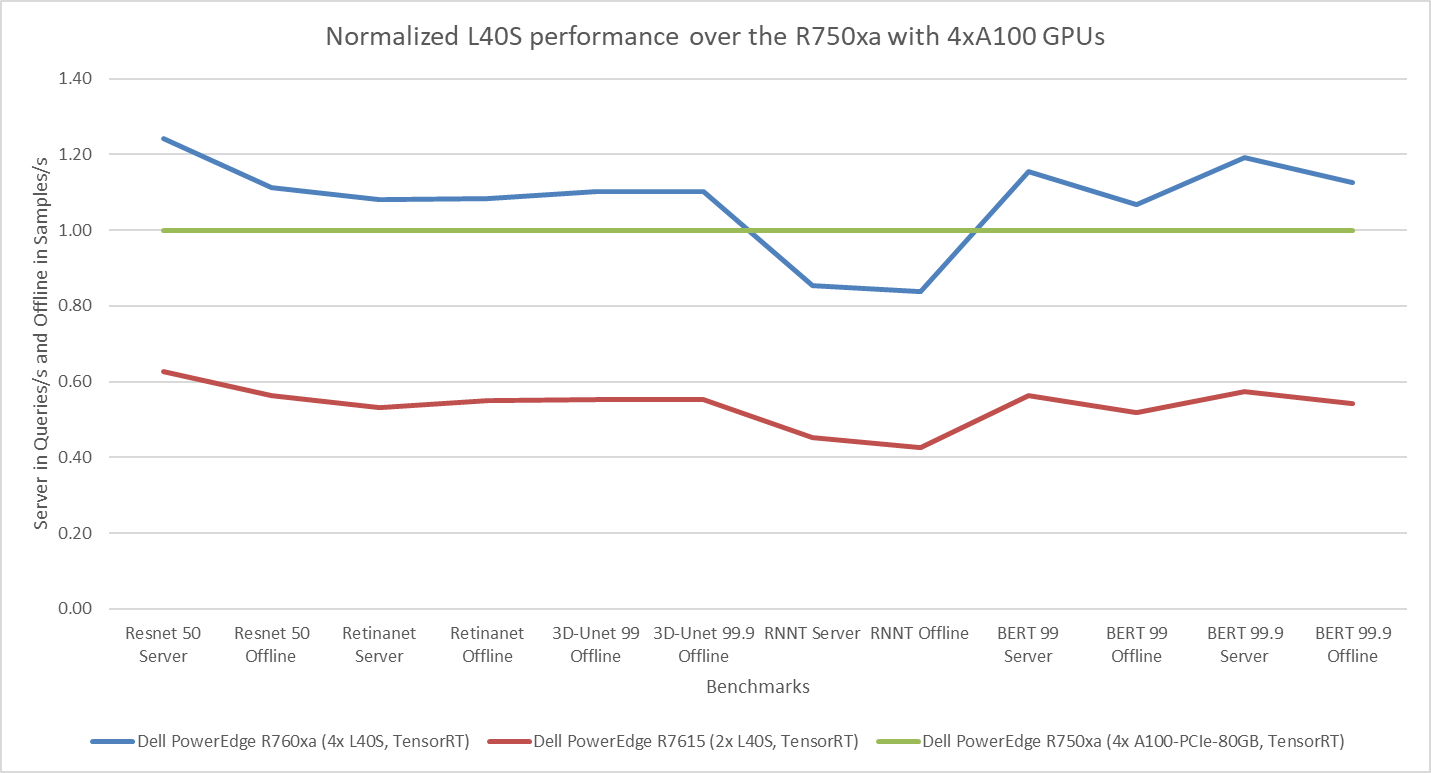
Figure 7: Normalized NVIDIA L40S GPU performance over the PowerEdge R750xa server with four A100 GPUs
The green trendline represents the performance of the Dell PowerEdge R750xa server with four NVIDIA A100 GPUs. With a score of 1.00 for each benchmark value, the results have been divided by themselves to serve as the baseline in green for this comparison. The blue trendline represents the performance of the PowerEdge R760xa server with four NVIDIA L40S GPUs that has been normalized by dividing each benchmark result by the corresponding score achieved by the PowerEdge R750xa server. In most cases, the performance achieved on the PowerEdge R760xa server outshines the results of the PowerEdge R750xa server with NVIDIA A100 GPUs, proving the expected improvements from the NVIDIA L40S GPU. The red trendline has also been normalized over the PowerEdge R750xa server and represents the performance of the PowerEdge R7615 server with two NVIDIA L40S GPUs. It is interesting that the red line almost mimics the blue line. This result suggests that the PowerEdge R7615 server, despite having half the compute resources, still performs comparably well in most cases, showing its efficiency.
Generative AI performance
The latest submission saw the introduction of the new Stable Diffusion XL benchmark. In the context of generative AI, stable diffusion is a text to image model that generates coherent image samples. This result is achieved gradually by refining and spreading out information throughout the generation process. Consider the example of dropping food coloring into a large bucket of water. Initially, only a small, concentrated portion of the water turns color, but gradually the coloring is evenly distributed in the bucket.
The following table shows the excellent performance of the PowerEdge R760xa server with the powerful NVIDIA L40S GPU for the GPT-J and Stable Diffusion XL benchmarks. The PowerEdge R760xa takes the top spot in GPT-J and Stable Diffusion XL when compared to other NVIDIA L40S results.
Table 3: Benchmark results for the PowerEdge R760xa server with the NVIDIA L40S GPU
Benchmark | Dell PowerEdge R760xa L40S result (Server in Queries/s and Offline in Samples/s) | Dell’s % gain to the next best non-Dell results (%) |
Stable Diffusion XL Server | 0.65 | 5.24 |
Stable Diffusion XL Offline | 0.67 | 2.28 |
GPT-J 99 Server | 12.75 | 4.33 |
GPT-J 99 Offline | 12.61 | 1.88 |
GPT-J 99.9 Server | 12.75 | 4.33 |
GPT-J 99.9 Offline | 12.61 | 1.88 |
Conclusion
The MLPerf Inference submissions elicit insightful like-to-like comparisons. This blog highlights the impressive performance of the NVIDIA L40S GPU in the Dell PowerEdge R760xa and PowerEdge R7615 servers. Both servers performed well when compared to the performance of the Dell PowerEdge R750xa server with the NVIDIA A100 GPU. The outstanding performance improvements in the NVIDIA L40S GPU coupled with the Dell PowerEdge server position Dell customers to succeed in AI workloads. With the advent of the GPT-J and Stable diffusion XL Models, the Dell PowerEdge server is well positioned to handle Generative AI workloads.