
Assets

Dell Validated Design Guides for Inferencing and for Model Customization – March ’24 Updates
Fri, 15 Mar 2024 20:16:59 -0000
|Read Time: 0 minutes
Continuous Innovation with Dell Validated Designs for Generative AI with NVIDIA
Since Dell Technologies and NVIDIA introduced what was then known as Project Helix less than a year ago, so much has changed. The rate of growth and adoption of generative AI has been faster than probably any technology in human history.
From the onset, Dell and NVIDIA set out to deliver a modular and scalable architecture that supports all aspects of the generative AI life cycle in a secure, on-premises environment. This architecture is anchored by high-performance Dell server, storage, and networking hardware and by NVIDIA acceleration and networking hardware and AI software.
Since that introduction, the Dell Validated Designs for Generative AI have flourished, and have been continuously updated to add more server, storage, and GPU options, to serve a range of customers from those just getting started to high-end production operations.
A modular, scalable architecture optimized for AI
This journey was launched with the release of the Generative AI in the Enterprise white paper.
This design guide laid the foundation for a series of comprehensive resources aimed at integrating AI into on-premises enterprise settings, focusing on scalable and modular production infrastructure in collaboration with NVIDIA.
Dell, known for its expertise not only in high-performance infrastructure but also in curating full-stack validated designs, collaborated with NVIDIA to engineer holistic generative AI solutions that blend advanced hardware and software technologies. The dynamic nature of AI presents a challenge in keeping pace with rapid advancements, where today's cutting-edge models might become obsolete quickly. Dell distinguishes itself by offering essential insights and recommendations for specific applications, easing the journey through the fast-evolving AI landscape.
The cornerstone of the joint architecture is modularity, offering a flexible design that caters to a multitude of use cases, sectors, and computational requirements. A truly modular AI infrastructure is designed to be adaptable and future-proof, with components that can be mixed and matched based on specific project requirements and which can span from model training, to model customization including various fine-tuning methodologies, to inferencing where we put the models to work.
The following figure shows a high-level view of the overall architecture, including the primary hardware components and the software stack:
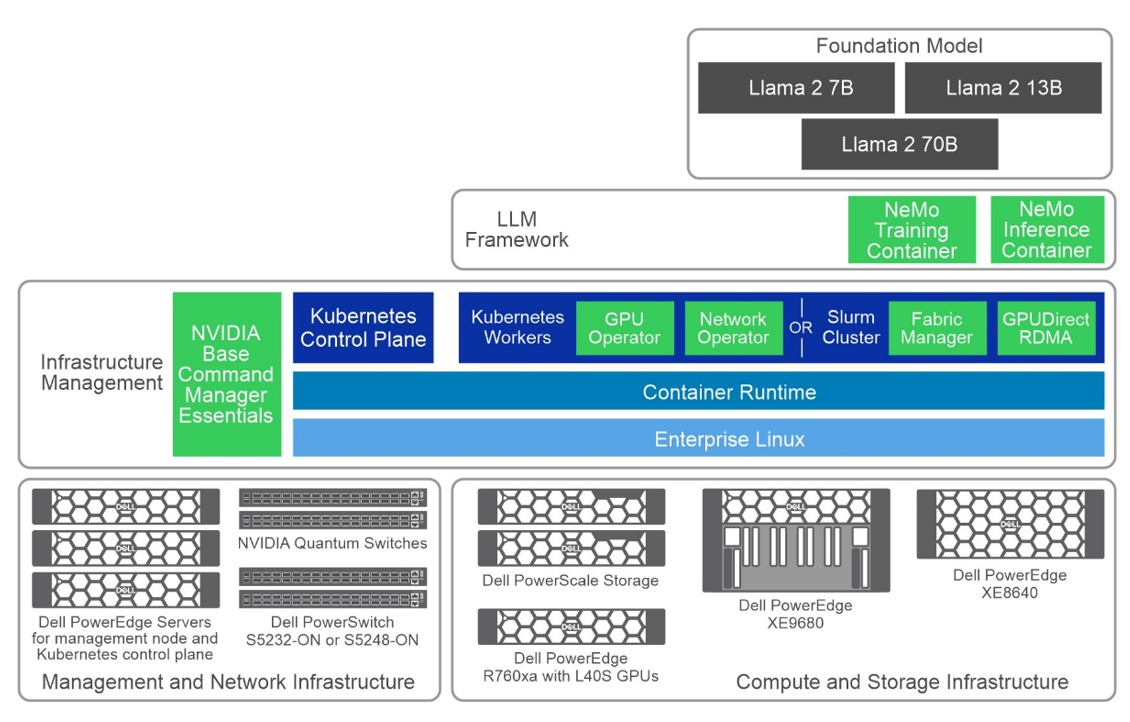
Figure 1: Common high-level architecture
Generative AI Inferencing
Following the introductory white paper, the first validated design guide released was for Generative AI Inferencing, in July 2023, anchored by the innovative concepts introduced earlier.
The complexity of assembling an AI infrastructure, often involving an intricate mix of open-source and proprietary components, can be formidable. Dell Technologies addresses this complexity by providing fully validated solutions where every element is meticulously tested, ensuring functionality and optimization for deployment. This validation gives users the confidence to proceed, knowing their AI infrastructure rests on a robust and well-founded base.
Key Takeaways
- In October 2023, the guide received its first update, broadening its scope with added validation and configuration details for Dell PowerEdge XE8640 and XE9680 servers. This update also introduced support for NVIDIA Base Command Manager Essentials and NVIDIA AI Enterprise 4.0, marking a significant enhancement to the guide's breadth and depth.
- The guide's evolution continues into March 2024 with its third iteration, which includes support for the PowerEdge R760xa servers equipped with NVIDIA L40S GPUs.
- The design now supports several options for NVIDIA GPU acceleration components across the multiple Dell server options. In this design, we showcase three Dell PowerEdge servers with several GPU options tailored for generative AI purposes:
- PowerEdge R760xa server, supporting up to four NVIDIA H100 GPUs or four NVIDIA L40S GPUs
- PowerEdge XE8640 server, supporting up to four NVIDIA H100 GPUs
- PowerEdge XE9680 server, supporting up to eight NVIDIA H100 GPUs
The choice of server and GPU combination is often a balance of performance, cost, and availability considerations, depending on the size and complexity of the workload.
- This latest edition also saw the removal of NVIDIA FasterTransformer, replaced by TensorRT-LLM, reflecting Dell’s commitment to keeping the guide abreast of the latest and most efficient technologies. When it comes to optimizing large language models, TensorRT-LLM is the key. It ensures that models not only deliver high performance but also maintain efficiency in various applications.
The library includes optimized kernels, pre- and postprocessing steps, and multi-GPU/multi-node communication primitives. These features are specifically designed to enhance performance on NVIDIA GPUs.
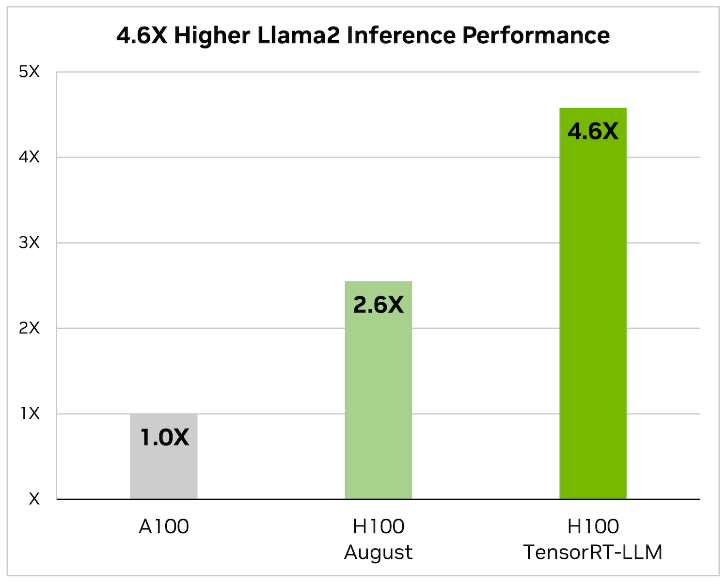
It uses tensor parallelism for efficient inference across multiple GPUs and servers, without the need for developer intervention or model changes.
- Additionally, this update includes revisions to the models used for validation, ensuring users have access to the most current and relevant information for their AI deployments. The Dell Validated Design guide covers Llama 2 and now Mistral as the foundation models for inferencing with this infrastructure design with Triton Inference Server:
- Llama 2 7B, 13B, and 70B
- Mistral
- Falcon 180B
- Finally (and most importantly) performance test results and sizing considerations showcase the effectiveness of this updated architecture in handling large language models (LLMs) for various inference tasks. Key takeaways include:
- Optimized Latency and Throughput—The design achieved impressive latency metrics, crucial for real-time applications like chatbots, and high tokens per second, indicating efficient processing for offline tasks.
- Model Parallelism Impact—The performance of LLMs varied with adjustments in tensor and pipeline parallelism, highlighting the importance of optimal parallelism settings for maximizing inference efficiency.
- Scalability with Different GPU Configurations—Tests across various NVIDIA GPUs, including L40S and H100 models, demonstrated the design’s scalability and its ability to cater to diverse computational needs.
- Comprehensive Model Support—The guide includes performance data for multiple models (as we already discussed) across different configurations, showcasing the design’s versatility in handling various LLMs.
- Sizing Guidelines—Based on performance metrics, updated sizing examples are available to help users determine the appropriate infrastructure based on their specific inference requirements (these guidelines very welcome)
All this highlights Dell’s commitments and capability to deliver high-performance, scalable, and efficient generative AI inferencing solutions tailored to enterprise needs.
Generative AI Model Customization
The validated design guide for Generative AI Model Customization was first released in October 2023, anchored by the PowerEdge XE9680 server. This guide detailed numerous model customization methods, including the specifics of prompt engineering, supervised fine-tuning, and parameter-efficient fine-tuning.
The updates to the Dell Validated Design Guide from October 2023 to March 2024 included the initial release, the addition of validated scenarios for multi-node SFT and Kubernetes in November 2023, updated performance test results, and new support for PowerEdge R760xa servers, PowerEdge XE8640 servers, and PowerScale F710 all-flash storage as of March 2024.
Key Takeaways
- The validation aimed to test the reliability, performance, scalability, and interoperability of a system using model customization in the NeMo framework, specifically focusing on incorporating domain-specific knowledge into Large Language Models (LLMs).
- The process involved testing foundational models of sizes 7B, 13B, and 70B from the Llama 2 series. Various model customization techniques were employed, including:
- Prompt engineering
- Supervised Fine-Tuning (SFT)
- P-Tuning, and
- Low-Rank Adaptation of Large Language Models (LoRA)
- The design now supports several options for NVIDIA GPU acceleration components across the multiple Dell server options. In this design, we showcase three Dell PowerEdge servers with several GPU options tailored for generative AI purposes:
- PowerEdge R760xa server, supporting up to four NVIDIA H100 GPUs or four NVIDIA L40S GPUs. While the L40S is cost-effective for small to medium workloads, the H100 is typically used for larger-scale tasks, including SFT.
- PowerEdge XE8640 server, supporting up to four NVIDIA H100 GPUs.
- PowerEdge XE9680 server, supporting up to eight NVIDIA H100 GPUs.
As always, the choice of server and GPU combination depends on the size and complexity of the workload.
- The validation used both Slurm and Kubernetes clusters for computational resources and involved two datasets: the Dolly dataset from Databricks, covering various behavioral categories, and the Alpaca dataset from OpenAI, consisting of 52,000 instruction-following records. Training was conducted for a minimum of 50 steps, with the goal being to validate the system's capabilities rather than achieving model convergence, to provide insights relevant to potential customer needs.
The validation results along with our analysis can be found in the Performance Characterization section of the design guide.
What’s Next?
Looking ahead, you can expect even more innovation at a rapid pace with expansions to the Dell’s leading-edge generative AI product and solutions portfolio.
For more information, see the following resources:
- Dell Generative AI Solutions
- Dell Technical Info Hub for AI
- Generative AI in the Enterprise white paper
- Generative AI Inferencing in the Enterprise Inferencing design guide
- Generative AI in the Enterprise Model Customization design guide
- Dell Professional Services for Generative AI
~~~~~~~~~~~~~~~~~~~~~