




Llama 2: Efficient Fine-tuning Using Low-Rank Adaptation (LoRA) on Single GPU


Introduction
With the growth in the parameter size and performance of large-language models (LLM), many users are increasingly interested in adapting them to their own use case with their own private dataset. These users can either search the market for an Enterprise-level application which is trained on large corpus of public datasets and might not be applicable to their internal use case or look into using the open-source pre-trained models and then fine-tuning them on their own proprietary data. Ensuring efficient resource utilization and cost-effectiveness are crucial when choosing a strategy for fine-tuning a large-language model, and the latter approach offers a more cost-effective and scalable solution given that it’s trained with known data and able to control the outcome of the model.
This blog investigates how Low-Rank Adaptation (LoRA) – a parameter effective fine-tuning technique – can be used to fine-tune Llama 2 7B model on single GPU. We were able to successfully fine-tune the Llama 2 7B model on a single Nvidia’s A100 40GB GPU and will provide a deep dive on how to configure the software environment to run the fine-tuning flow on Dell PowerEdge R760xa featuring NVIDIA A100 GPUs.
This work is in continuation to our previous work, where we performed an inferencing experiment on Llama2 7B and shared results on GPU performance during the process.
Memory bottleneck
When finetuning any LLM, it is important to understand the infrastructure needed to load and fine-tune the model. When we consider standard fine-tuning, where all the parameters are considered, it requires significant computational power to manage optimizer states and gradient checkpointing. The optimizer states and gradients usually result in a memory footprint which is approximately five times larger than the model itself. If we consider loading the model in fp16 (2 bytes per parameter), we will need around 84 GB of GPU memory, as shown in figure 1, which is not possible on a single A100-40 GB card. Hence, to overcome this memory capacity limitation on a single A100 GPU, we can use a parameter-efficient fine-tuning (PEFT) technique. We will be using one such technique known as Low-Rank Adaptation (LoRA) for this experiment.
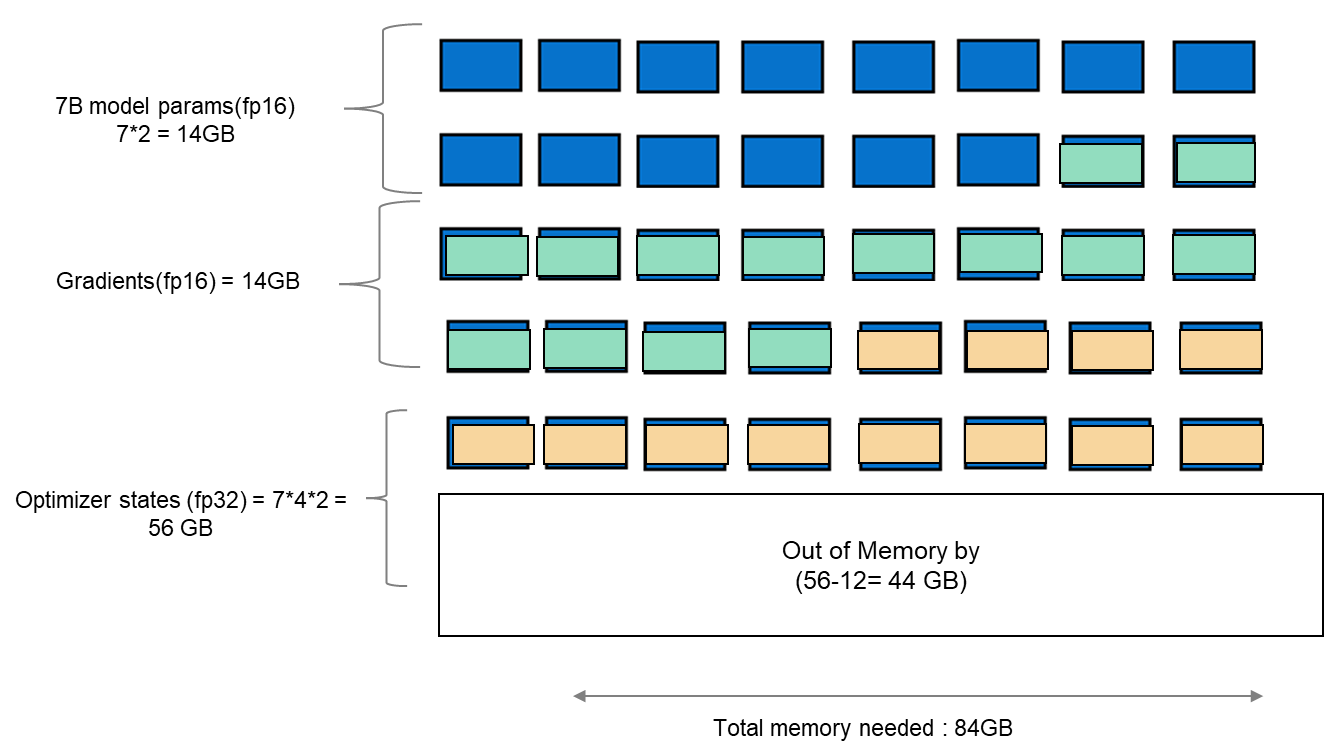
Figure 1. Schematic showing memory footprint of standard fine-tuning with Llama 27B model.
Fine-tuning method
LoRA is an efficient fine-tuning method where instead of finetuning all the weights that constitute the weight matrix of the pre-trained LLM, it optimizes rank decomposition matrices of the dense layers to change during adaptation. These matrices constitute the LoRA adapter. This fine-tuned adapter is then merged with the pre-trained model and used for inferencing. The number of parameters is determined by the rank and shape of the original weights. In practice, trainable parameters vary as low as 0.1% to 1% of all the parameters. As the number of parameters needing fine-tuning decreases, the size of gradients and optimizer states attached to them decrease accordingly. Thus, the overall size of the loaded model reduces. For example, the Llama 2 7B model parameters could be loaded in int8 (1 byte), with 1 GB trainable parameters loaded in fp16 (2 bytes). Hence, the size of the gradient (fp16), optimizer states (fp32), and activations (fp32) aggregates to approximately 7-9 GB. This brings the total size of the loaded model to be fine-tuned to 15-17 GB, as illustrated in figure 2.
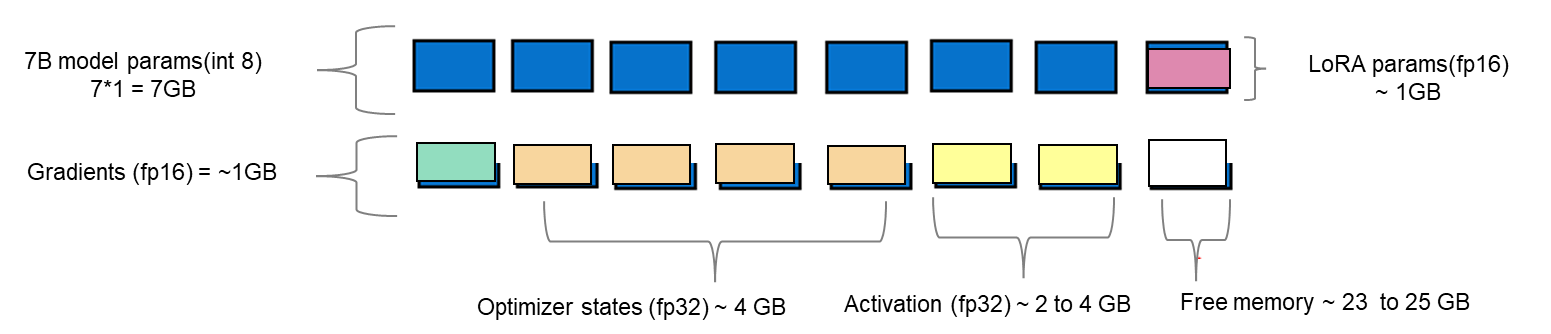
Figure 2. Schematic showing an example of memory footprint of LoRA fine tuning with Llama 2 7B model.
Experimental setup
A model characterization gives readers valuable insight into GPU memory utilization, training loss, and computational efficiency measured during fine-tuning by varying the batch size and observing out-of-memory (OOM) occurrence for a given dataset. In table 1, we show resource profiling when fine-tuning Llama 2 7B-chat model using LoRA technique on PowerEdge R760xa with 1*A100-40 GB on Open- source SAMsum dataset. To measure tera floating-point operations (TFLOPs) on the GPU, the DeepSpeed Flops Profiler was used. Table 1 gives the detail on the system used for this experiment.
Table 1. Actual memory footprint of Llama 27B model using LoRA technique in our experiment.
Trainable params (LoRA) | 0.0042 B (0.06% of 7B model) |
7B model params(int8) | 7 GB |
Lora adapter (fp16) | 0.0084 GB |
Gradients (fp32) | 0.0168 GB |
Optimizer States(fp32) | 0.0168 GB |
Activation | 2.96 GB |
Total memory for batch size 1 | 10 GB = 9.31 GiB |
System configuration
In this section, we list the hardware and software system configuration of the R760xa PowerEdge server used in this experiment for the fine-tuning work of Llama-2 7B model. 
Figure 3. R760XA Specs
Table 2. Hardware and software configuration of the system
Component | Details |
Hardware | |
Compute server for inferencing | PowerEdge R760xa |
GPUs | Nvidia A100-40GB PCIe CEM GPU |
Host Processor Model Name | Intel(R) Xeon(R) Gold 6454S (Sapphire Rapids) |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.2 GHz |
Host Memory Capacity | 512 GB, 16 x 32GB 4800 MT/s DIMMs |
Host Storage Type | SSD |
Host Storage Capacity | 900 GB |
Software | |
Operating system | Ubuntu 22.04.1 |
Profiler | |
Framework | PyTorch |
Package Management | Anaconda |
Dataset
The SAMsum dataset – size 2.94 MB – consists of approximately 16,000 rows (Train, Test, and Validation) of English dialogues and their summary. This data was used to fine-tune the Llama 2 7B model. We preprocess this data in the format of a prompt to be fed to the model for fine-tuning. In the JSON format, prompts and responses were used to train the model. During this process, PyTorch batches the data (about 10 to 11 rows per batch) and concatenates them. Thus, a total of 1,555 batches are created by preprocessing the training split of the dataset. These batches are then passed to the model in chunks for fine-tuning.
Fine-tuning steps
- Download the Llama 2 model
- The model is available either from Meta’s git repository or Hugging Face, however to access the model, you will need to submit the required registration form for Meta AI license agreement
- The details can be found in our previous work here
- Convert the model from the Meta’s git repo to a Hugging face model type in order to use the PEFT libraries used in the LoRA technique
- Use the following commands to convert the model
## Install HuggingFace Transformers from source pip freeze | grep transformers ## verify it is version 4.31.0 or higher
git clone git@github.com:huggingface/transformers.git
cd transformers
pip install protobuf
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
- Use the following commands to convert the model
- Build a conda environment and then git clone the example fine-tuning recipes from Meta’s git repository to get started
- We have modified the code base to include Deepspeed flops profiler and nvitop to profile the GPU
- Load the dataset using the dataloader library of hugging face and, if need be, perform preprocessing
- Input the config file entries with respect to PEFT methods, model name, output directory, save model location, etc
- The following is the example code snippet
train_config: model_name: str="path_of_base_hugging_face_llama_model" run_validation: bool=True batch_size_training: int=7 num_epochs: int=1 val_batch_size: int=1 dataset = "dataset_name" peft_method: str = "lora" output_dir: str = "path_to_save_fine_tuning_model" save_model: bool = True |
6. Run the following command to perform fine tuning on a single GPU
python3 llama_finetuning.py --use_peft --peft_method lora --quantization --model_name location_of_hugging_face_model |
Figure 4 shows fine tuning with LoRA technique on 1*A100 (40GiB) with Batch size = 7 on SAMsum dataset, which took 83 mins to complete.

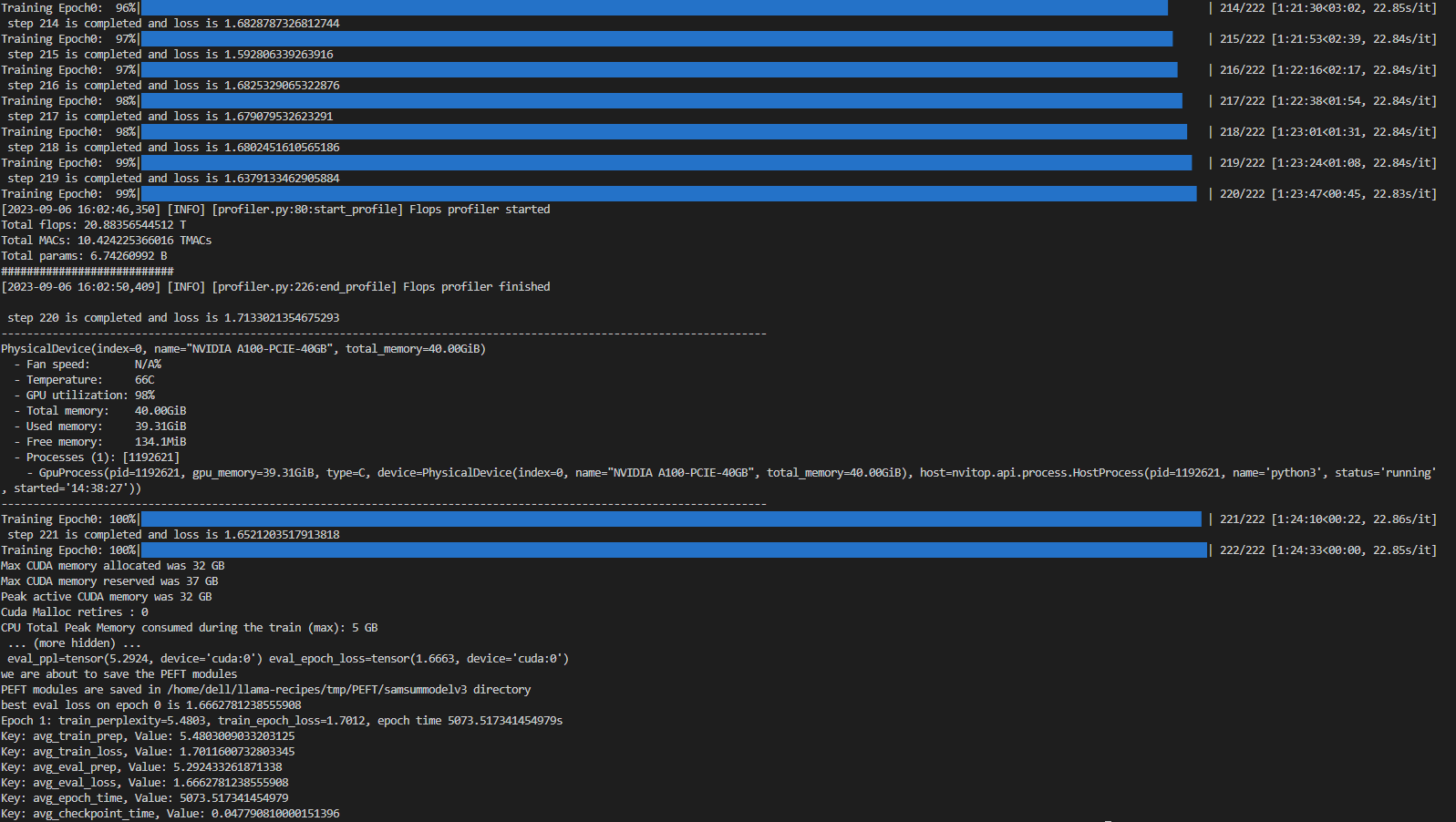
Figure 4. Example screenshot of fine-tuning with LoRA on SAMsum dataset
Experiment results
The fine-tuning experiments were run at batch sizes 4 and 7. For these two scenarios, we calculated training losses, GPU utilization, and GPU throughput. We found that at batch size 8, we encountered an out-of-memory (OOM) error for the given dataset on 1*A100 with 40 GB.
When a dialogue was sent to the base 7B model, the summarization results are not proper as shown in figure 5. After fine-tuning the base model on the SAMsum dataset, the same dialogue prompts a proper summarized result as shown in figure 6. The difference in results shows that fine-tuning succeeded.
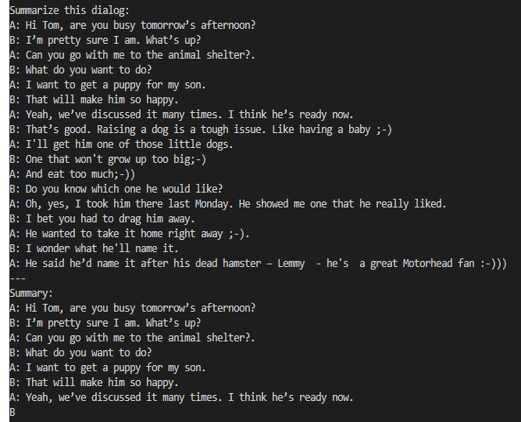
Figure 5. Summarization results from the base model.
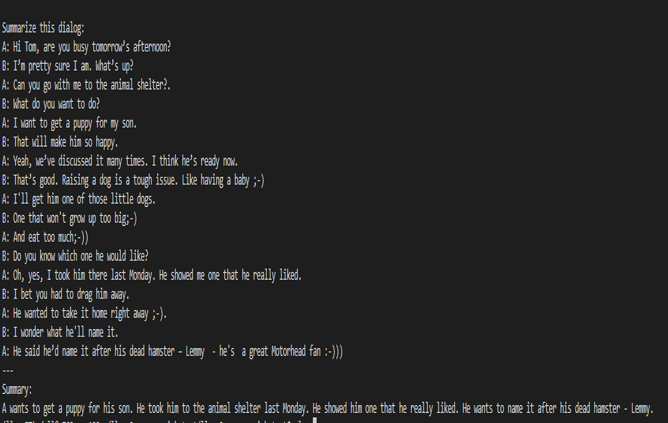
Figure 6. Summarization results from the fine-tuned model.
Figures 7 and 8 show the training losses at batch size 4 and 7 respectively. We found that even after increasing the batch size by approximately 2x times, the model training performance did not degrade.
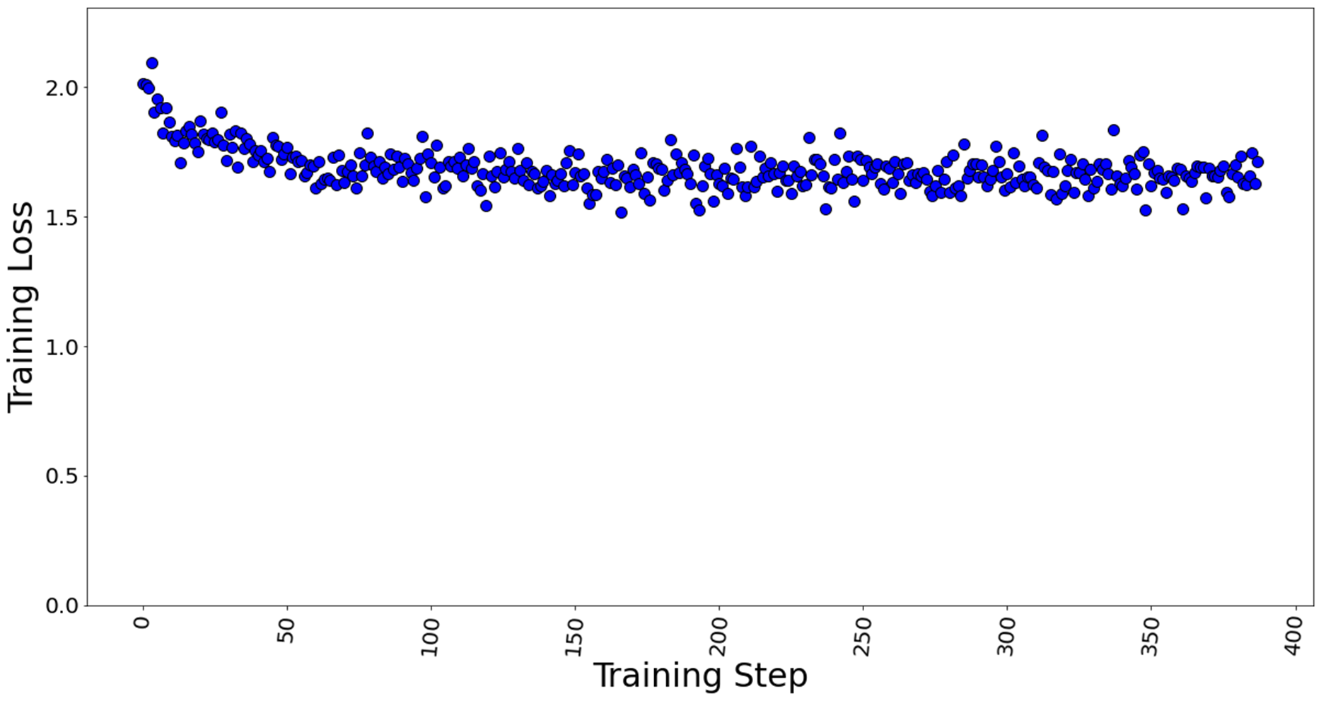
Figure 7. Training loss with batch size = 4, a total of 388 training steps in 1 epoch.
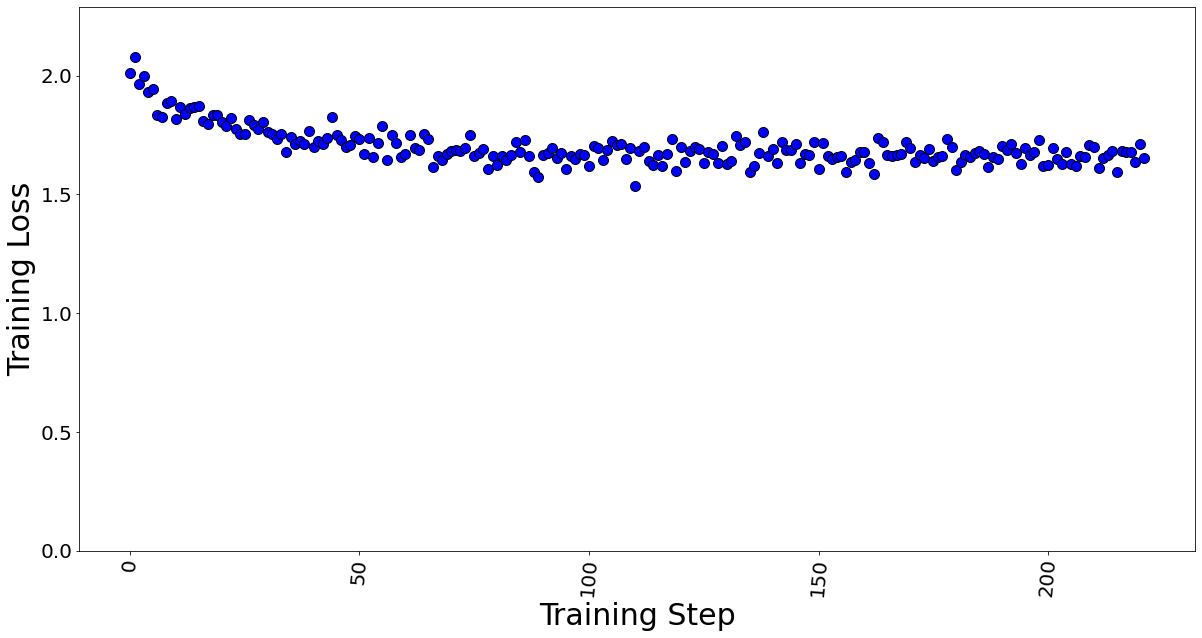
Figure 8. Training loss with batch size = 7, a total of 222 training steps in 1 epoch.
The GPU memory utilization was captured with LoRA technique in Table 3. At batch size 1, used memory was 9.31 GB. At batch size of 4, used memory was 26.21 GB. At batch size 7, memory used was 39.31 GB. Going further, we see an OOM at batch size 8 for 40 GB GPU card. The memory usage remains constant throughout fine-tuning, as shown in Figure 9, and is dependent on the batch size. We calculated the reserved memory per batch to be 4.302 GB on 1*A100.
Table 3. The GPU memory utilization is captured by varying the max. batch size parameter.
Max. Batch Size | Steps in 1 Epoch | Total Memory (GiB) | Used Memory (GiB) | Free Memory (GiB) |
1 | 1,555 | 40.00 | 9.31 | 30.69 |
4 | 388 | 40.00 | 26.21 | 13.79 |
7 | 222 | 40.00 | 39.31 | 0.69 |
8 | Out of Memory Error | |||
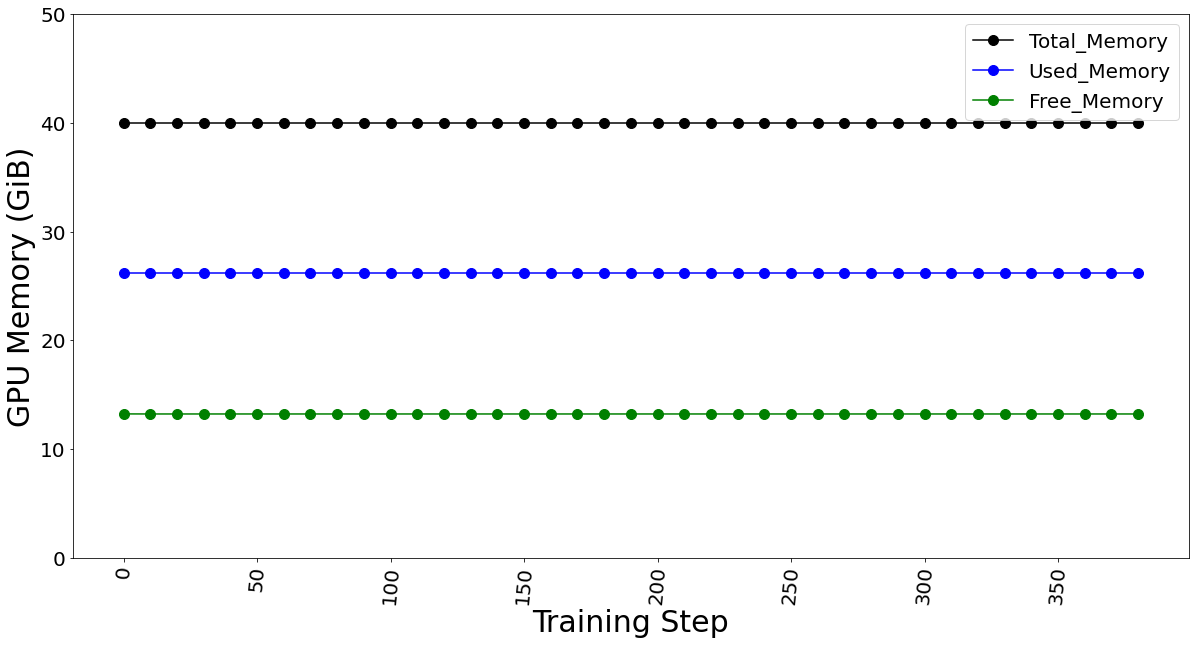
Figure 9. GPU memory utilization for batch size 4 (which remains constant for fine-tuning)
The GPU TFLOP was determined using DeepSpeed Profiler, and we found that FLOPs vary linearly with the number of batches sent in each step, indicating that FLOPs per token is the constant.
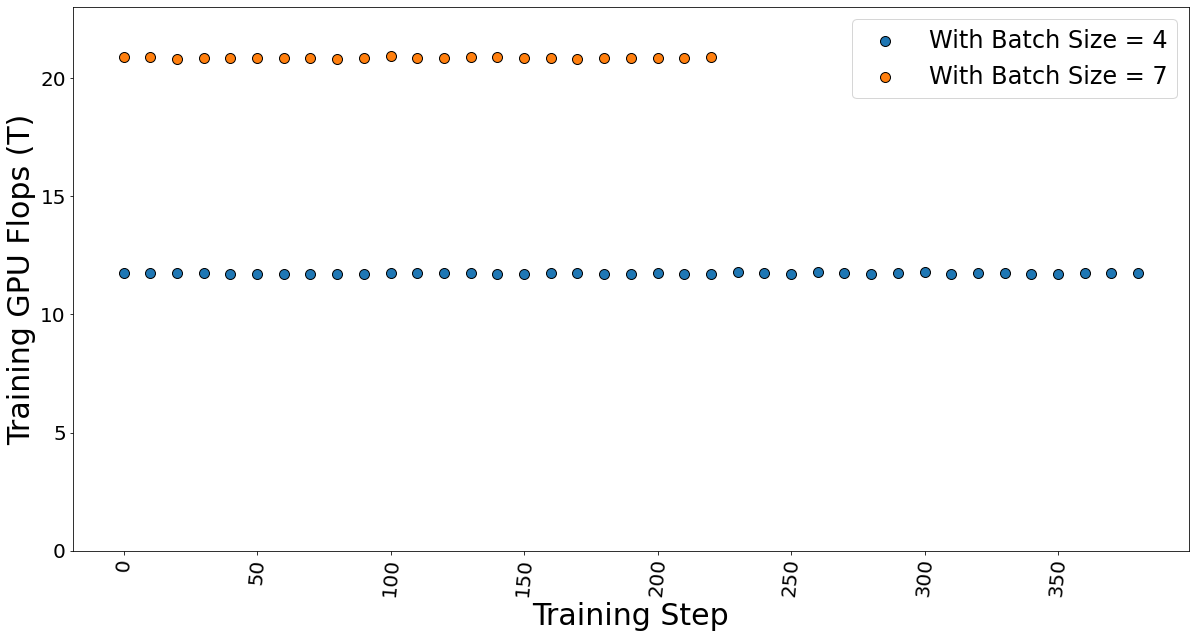
Figure 10. Training GPU TFlops for batch sizes 4 and 7 while fine-tuning the model.
The GPU multiple-accumulate operations (MACs), which are common operations performed in deep learning models, are also determined. We found that MACs also follow a linear dependency on the batch size and hence constant per token.
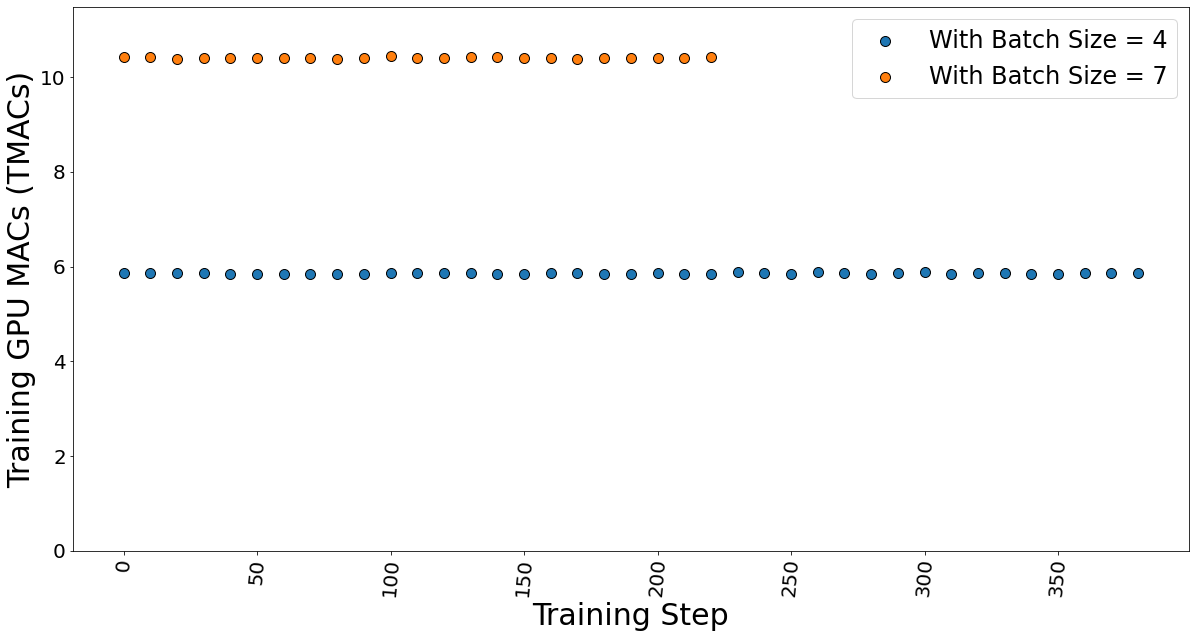
Figure 11. GPU MACs for batch sizes 4 and 7 while the fine-tuning the model.
The time taken for fine-tuning, which is also known as epoch time, is given in table 4. It shows that the training time does not vary much, which strengthens our argument that the FLOPs per token is constant. Hence, the total training time is independent of the batch size.
Table 4. Data showing the time taken by the fine-tuning process.
Max. Batch Size | Steps in 1 Epoch | Epoch time (secs) |
4 | 388 | 5,003 |
7 | 222 | 5,073 |
Conclusion and Recommendation
- We show that using a PEFT technique like LoRA can help reduce the memory requirement for fine-tuning a large-language model on a proprietary dataset. In our case, we use a Dell PowerEdge R760xa featuring the NVIDIA A100-40GB GPU to fine-tune a Llama 2 7B model.
- We recommend using a lower batch size to minimize automatic memory allocation, which could be utilized in the case of a larger dataset. We have shown that a lower batch size affects neither the training time nor training performance.
- The memory capacity required to fine-tune the Llama 2 7B model was reduced from 84GB to a level that easily fits on the 1*A100 40 GB card by using the LoRA technique.
Resources
- Llama 2: Inferencing on a Single GPU
- LoRA: Low-Rank Adaptation of Large Language Models
- Hugging Face Samsum Dataset
Author: Khushboo Rathi khushboo_rathi@dell.com | www.linkedin.com/in/khushboorathi
Co-author: Bhavesh Patel bhavesh_a_patel@dell.com | www.linkedin.com/in/BPat