




Implementing AI: Dell PowerEdge XE9640 and Intel® Data Center GPU Max 1550
Fri, 12 Apr 2024 15:36:58 -0000
|Read Time: 0 minutes
Implementing AI: Dell PowerEdge XE9640 and Intel® Data Center GPU Max 1550
An AI inference and training POC powered by Dell Technologies
Author: Esther Baldwin – Intel, Yashesh Shroff – Intel, Justin King - Dell
Summary
In the current economic climate, the CIO’s access to infrastructure for Artificial Intelligence (AI) development and delivery is challenging. In addition to the increasing demand for FLOPs to generate new and faster insights for their business, CIO’s face challenges on several fronts. These include the supply chain and lead time for traditional resources and the need to continue to maintain modernized environments which drive growth while reducing the cost of programs and bring forward tangible value.
In addition to modernization challenges for new data management approaches, such as data lakes, CIOs are being asked to support artificial intelligence technology for various uses as it permeates all aspects of the business environment. For many, this is an emerging technology, and they are often under a barrage of marketing and sales information. Dell Technologies, as a trusted advisor, is there to alleviate these pressures and help its customers navigate the complex decisions that turn vision and planning into reality.
With Dell Technologies’ this solution is designed and optimized to give CIOs options. With the Intel® Data Center GPU Max Series, developers working on multiple models for inference and training will find extensive resources to combat today’s competitive landscape. This comprehensive brief will provide an overview of how AI best meets the AI developer's needs.
Dell and Intel have partnered to deliver a server solution powered by Dell infrastructure with the Intel Max Series GPU. The PowerEdge XE9640 offers:
|
Business Challenges and Benefits
The Intel Max Series 1550 GPU meets industry challenges with flexible options that empower you to deliver everything you would expect from a modern high-performance graphics processing unit.
• Program once - No code changes between Intel ® Xeon® CPU and Max Series GPU
• Intel oneAPI to allow hardware vendor independence - No vendor lock-in
• AI-boosting Intel® Xe Matrix Extensions (XMX) with deep systolic arrays enabling vector and matrix capabilities in a single device
• Solving large problems - Largest L2 Cache for a GPU, 408MB (10x of A100 and 25x of MI250)
• Built-in hardware accelerated Ray Tracing cores, an advantage for visualization
• Xe Link – high-speed coherent, unified fabric offers flexibility to any form factor, enabling scale-up - 16Xe Links for GPU – to-GPU comms
• Advanced manufacturing processes - Modular & Flexible architecture that allows the SoC to be constructed from 47 individual silicon tiles
• High Bandwidth Memory - integrated on the package
• Versatile: Supports both HPC and AI workloads. AI support for popular models such as Resnet, Bert, Cosmic Tagger, Llama 2-(7B, 13B, 70B), GPT-J 6B, BLOOM-176B, and more.
• Available today from Dell
|
What is Intel® Data Center GPU Max 1550?
The Intel Max Series GPU provides support for over 60 AI models. It also offers application readiness for business applications in high-performance computing, including energy, life science, and physics as well as top applications in the financial services industry and manufacturing and more. It is available with the Dell PowerEdge XE964.
What do AI developers care about, and where and why will the XE9640 work for them?
AI developers look for several key features in a compute platform, such as performance, versatility, scalability, ease of use, and support for AI frameworks. The Dell XE9640 platform is designed with these needs in mind.
Performance: With the Max 1550 GPUs, the Dell XE9640 platform offers 2.7X peak throughput across various datatypes (FP64, FP32, TF32, BF16/FP16, and INT8).
Versatility: This performance translates into inference and training advantages for the top AI models used for image classification, image segmentation, object detection, natural language processing, speech recognition, speech synthesis, and recommendation. Details of these workloads are provided in the following section.
Scalability: With XeLink, developers can access high-speed connections via GPU-to-GPU fabric on Max 1550, thereby scaling up workloads to four cards on the Dell XE9640 platform. Moreover, ethernet or Infiniband fabric can connect GPUs across nodes in a scale-out configuration.
Ease of use: With numerous models now available for easy onboarding via GitHub (https://github.com/IntelAI/models) and a well-documented oneAPI software stack, developers can start building applications that leverage Intel’s advanced Data Center CPU capabilities, such as AVX512, and Max GPU
AI Frameworks: The oneAPI software stack supports the latest releases of PyTorch and Tensorflow through plugins, IPEX and ITEX, respectively. This makes writing code that runs efficiently on the Max 1550 GPU cards with as little as two lines of change. Find more details on this at https://software.intel.com/.
AI Workloads
Published AI and HPC workloads can be found here. Find detailed guides on running the workloads with supported frameworks and essential open-source libraries which provide developers with the tools and experiences they need to deliver value. The workloads are provided as deployable PyTorch and Tensorflow containers and include sample scripts that minimize deployment time.
Below are sample use cases and associated models:
- Enterprise: Llama 2, GPT-J-6B, BLOOM-176, ResNet-50, BERT-Large, and many more
- Financial Services: STAC-A2 and FSI Kernels
- Life & Material Sciences: LAMMPS Multi-GPU scaling–Tungsten workload, NWChemEx PWDFT, AutoDock, NAMD, RELION
- Astrophysics: DPEcho
- Physics: 3D GAN for Particle Shower Simulation, DeepGalaxy, QMCPack,
- Earth Systems Modelling: SpecFEM3D_Globe Multi-GPU Scaling – Global_s362ani_shakemovie,
ECMWF Cloudsc - Energy: Seismic Kernel Multi-GPU scaling
- Manufacturing: CoMLSim, JacobiSolver
Generative AI is of high interest in delivering business impact. The Dell PowerEdge XE9640 has the software and hardware capabilities to drive GenAI use cases in an Enterprise setting. Along with traditional deep learning (CV, RecSys, NLP) models, there is growing support for GenAI workloads such as Llama-2, Mistral for use with inference, fine-tuning, and developing Retrieval Augmented Generation (RAG) pipelines. To see the performance results for a workload that interests you, contact your Dell representative.
oneAPI Software and AI Tools from Intel
Making developers’ life easier is the oneAPI open and standards-based specification which supports multiple architecture types including but not limited to GPU, CPU, and FPGA. The specification defines a set of library interfaces that are commonly used in a variety of workflows.
AI Tools from Intel is a toolkit that provides familiar Python tools and frameworks to data scientists, AI developers, and researchers to accelerate end-to-end data science and analytics pipelines on Intel® architecture, a vital component of the Dell PowerEdge XE9640. The components are built using oneAPI libraries for low-level compute optimizations.
The AI Tools maximize performance from preprocessing through machine learning and provide interoperability for efficient model development. Train on Intel® CPUs and GPUs and integrate fast inference into your AI development workflow with Intel®-optimized deep learning frameworks for TensorFlow and PyTorch, pre-trained models, and model optimization tools. Don’t forget to look at the Intel Distribution for Python with highly optimized scikit-learn which is part of the AI Tools from Intel.
With compute-intensive Python packages, Modin*, scikit-learn*, and XGBoost, you can achieve drop-in acceleration for data preprocessing and machine learning workflows.
For more details, refer to the oneAPI specification page here and the Resources section at the end of the guide, where you can download the oneAPI base toolkit and AI Tools from Intel.
Dell PowerEdge XE9640 Overview
Density-optimized AI acceleration with the Dell PowerEdge delivers real-time insights. Dell’s first liquid-cooled 4-way GPU platform is in the XE9640 2U server. It is designed to drive the latest cutting-edge AI, Machine Learning, and Deep Learning Neural Network applications.
- Combines a high core count of up to 56 cores in the 4th Gen Intel® Xeon® processors and the most GPU. memory and bandwidth available today to break through the bounds of today’s and tomorrow’s AI computing.
- The Intel Data Center Max GPU series 1550 600W OAM GPUs is fully interconnected with XeLink.
- Ideal 2U form factor building block for dense Supercomputer and HPC acceleration workloads and applications.
- Supports Rack Direct Liquid Cooling Infrastructure: Cool IT with 42U XE9640 rack manifold and 48U XE9640 rack manifold.
Security
Security is integrated into every phase of the PowerEdge lifecycle, including a protected supply chain and factory-to-site integrity assurance. Silicon-based root of trust anchors end-to-end boot resilience while Multi-Factor Authentication (MFA) and role-based access controls ensure trusted operations.
- Cryptographically signed firmware
- Data at Rest Encryption (SEDs with local or external key mgmt)
- Secure Boot
- Secured Component Verification (Hardware integrity check)
- Secure Erase
- Silicon Root of Trust
- System Lockdown (requires iDRAC9 Enterprise or Datacenter)
- TPM 2.0 FIPS, CC-TCG certified, TPM 2.0 China NationZ
Accelerated I/O throughput
- Direct liquid-cooled Processors and GPUs enable efficient cooling for the highest performance, efficient power utilization, and lower TCO
- Dell Multi-vector cooling manages components to operate optimally
- Is the ideal dual-socket 1U rack server for dense scale-out data center computing applications. Benefiting from the flexibility of 2.5” or 3.5” drives, the performance of NVMe, and embedded intelligence, it ensures optimized application performance in a secure platform.
Dell Infrastructure Components
The following Dell components provide the foundation for AI solutions that lend themselves to development and delivery.
Dell PowerScale is an AI-ready data platform designed to easily store, manage, and protect data. Accelerate your AI workloads wherever your unstructured data lives—on-premises, at the edge, and in any cloud.
Dell Unity XT Storage provides flexible hybrid flash storage for cost-sensitive enterprises that want to leverage a combination of flash and disk for lower cost than all flash/NVMe architectures. It supports unified block and file workloads, online upgrades without migrations, guaranteed 3:1 dedupe, and sync replication.
Dell PowerVault Storage is optimized for DAS and SAN applications and supports PowerEdge server capacity expansion via PowerEdge-ready JBODs. It provides management simplicity and low-cost block storage and is ideal for edge and high-capacity data warehouse deployments.
Dell ECS Storage is an enterprise-grade, cloud-scale object storage platform providing comprehensive protocol support for unstructured object and file workloads on a single modern platform. Depending on capacity requirements, either the ECS EX500 or EX5000 may be used.
Dell PowerSwitch Networking switches are based on open standards to free the data center from outdated, proprietary approaches: They support future-ready networking technology that helps you improve network performance, lower network management cost, and complexity, and adopt innovations in networking.
Why Dell Technologies
The technology required for data management and enterprise analytics is evolving quickly, and companies may not have experts on staff or who have the time to design, deploy, and manage solution stacks at the pace required. Dell Technologies has been a leader in AI, Big Data, and advanced analytics for over a decade with proven products, solutions, and expertise. Dell Technologies has teams of application and infrastructure experts dedicated to staying on the cutting edge, testing new technologies, and tuning solutions for your applications to help you keep pace with this constantly evolving landscape.
Dell Technologies is building a broad ecosystem of partners in the data space to bring our customers the necessary experts, resources, and capabilities and accelerate their data strategy. We believe customers should be able to deliver AI innovation using data irrespective of where it resides, across on-prem, public cloud, and edge. By partnering with industry leaders in enterprise data management and analytics, we create optimized solutions for our customers.
Dell Technologies uniquely provides an extensive portfolio of technologies to deliver the advanced infrastructure that underpins successful data implementations. With years of experience and an ecosystem of curated technology and service partners, Dell Technologies provides innovative solutions, servers, networking, storage, workstations, and services that reduce complexity and enable you to capitalize on a data universe.
Proof Points
One of the more recent and fast-growing use cases is Generative AI (GenAI). The following chart shows a sample benchmark of a GenAI workload run on a Dell PowerEdge XE9640 x4 platform:
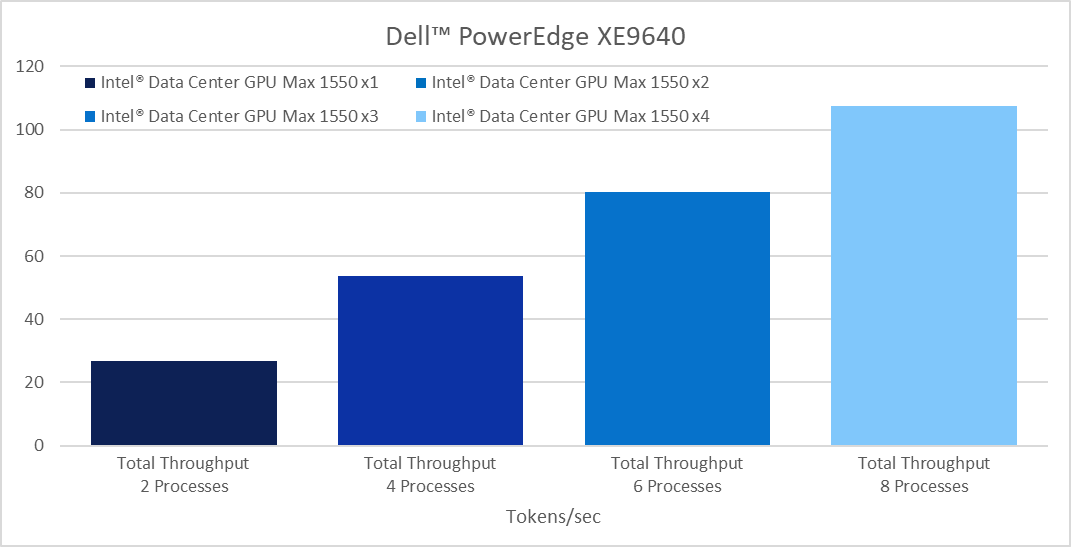
This figure demonstrates efficient linear scale-up from a single card workload up to four cards for LlaMA-2 7B inference. Details on the workload configuration and environment setup can be found at the Dell Infohub blog: https://infohub.delltechnologies.com/p/expanding-gpu-choice-with-intel-data-center-gpu-max-series/. Scalers AI, A Dell partner, developed and performed the benchmark.
Conclusion
Whether you want to expand your existing capabilities or start your first project, talk to us about your AI vision and what you need.
Your company needs all tools and technologies working in concert to achieve success. Fast, effective systems that complement time management practices are crucial to maximizing every employee hour. High-level data collection and processing that provides rich, detailed analytics can ensure your marketing campaigns strategically target your ideal customers and encourage conversion. To top it off, you need affordable products in a timely fashion that meet your criteria and then some. The XE9640 with the Intel Max 1550 GPU will meet the needs of AI developers.
Understanding AI Language
AI Models
A model is a program that analyzes data. There are many different models in use in AI, and they are specialized for the type of data they analyze. The model being used for this brief is LLaMa V2, a collection of generative AI models that are pretrained and fine-tuned to generate text (can scale from 7 to 70 billion parameters). LLaMa V2 is part of a new trend of having “nimble” models. These models are more customized to specific business needs, smaller, and lower cost to train and deploy.
“Dell uses Llama 2 internally for both experimental work and production deployment. One use case provides a chatbot-style interface to support Retrieval Augmented Generation (RAG) to get information from Dell’s knowledge base of articles. Llama 2 itself is a freely available open-source technology.” [i]
What is “GenAI”
Generative AI, or GenAI, is a subset of artificial intelligence with the potential to transform the business world due to its ability to create new content from existing data. It is a powerful tool that can generate text, images, videos, and even code, revolutionizing businesses' operations.
- Healthcare: generate synthetic data for research without violating privacy regulations.
- Research: create new models for chemical compound molecules for pharmaceutical drug discovery. Manufacturing product and part design.
- Creativity: create music, fashion design, and product design; edit images; create unique art; provide realistic images and immersive worlds for virtual and augmented reality; augment game development for in-game content creation and game play adaptation.
- Natural language understanding and processing: human-like chatbot interaction, virtual assistants.
- Software: write code, significantly reducing development time and costs.
- Data generation: create synthetic data for training machine learning models and testing edge-based communication systems.
Parameters
A variable that indicates the size of the model. For instance, Llama-2 70B is around 70 billion parameters.
Tokens
A unit that a model uses to compute the length of a text can be pieces of words, punctuation, or emojis. It is used to learn context and semantics. Text is split up into smaller units to be processed, and then new text is generated. One way to measure its capacity is the number of tokens your hardware can process.
References
- Dell PowerScale
- Dell PowerEdge XE9640
- PowerEdge XE9640 Rack Server
- Dell PowerVault Storage
- Dell Unity XT Storage
- Dell ECS Object Storage
- Dell PowerSwitch Networking
- https://arxiv.org/abs/2210.05837 for CoMLSim background
- Intel® oneAPI Base Toolkit
- AI Tools from Intel