




Effectiveness of Large Batch Training for Neural Machine Translation with Intel Xeon
We know that using really large batch sizes during training can cause models to poorly generalize. But how do large batches actually affect the generalization and optimization of neural network models? 2018 was a great year for research on Neural Machine Translation (NMT). We’ve seen an explosion in the number of research papers published in this field, ranging from descriptions of new and interesting architectures to efficient training techniques. Research papers have shown how larger batch sizes and reduced precision can help to improve both the training time and quality.
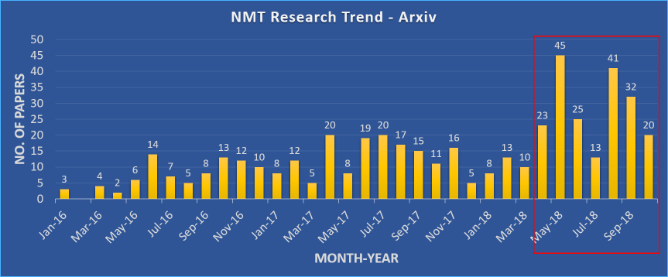
Figure 1: Numbers of papers published in Arxiv with ‘neural machine translation’ in the title or abstract in the ‘cs’ category.
In our previous blogs, we showed how to effectively scale an NMT system, as well as some of the challenges associated with scaling. In this blog, we will explore the effectiveness of large batch training using Intel® Xeon® Scalable processors. The work discussed in the blog is based on neural network training performed using Zenith supercomputer at Dell EMC’s HPC and AI Innovation Lab.
System Information
CPU Model | Intel® Xeon® Gold 6148 CPU @ 2.40GHz |
Operating System | Red Hat Enterprise Linux Server release 7.4 (Maipo) |
Tensorflow Version | Anaconda TensorFlow 1.12.0 with Intel® MKL |
Horovod Version | 0.15.2 |
MPI | MVAPICH2 2.1 |
Incredible strong scaling efficiency helps to dramatically reduce the time to solution of the model. To best visualize this, consider figure 2. The time to solution drops from around 1 month on a single node to just over 6 hours using 200 nodes. This 121x faster solution would significantly help the productivity of NMT researchers using CPU-based HPC infrastructures. The results observed were based on the models achieving a baseline BLEU score (case-sensitive) of 27.5.
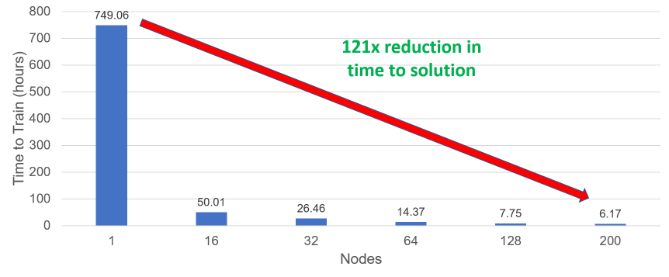
Figure 2: Time to train the model to solution
For the single node case, we have used the largest batch size that could fit in a node's memory, 25,600 tokens per worker. For all other cases, we use a global batch size of 819,200, leading to per-worker batch sizes of 25,600 in the 16-node case, down to only 2,048 in the 200-node case. The number of training iterations is similar for all experiments in the 16-200 node range and is increased by a factor of 16 for the single-node case (to compensate for the larger batch).
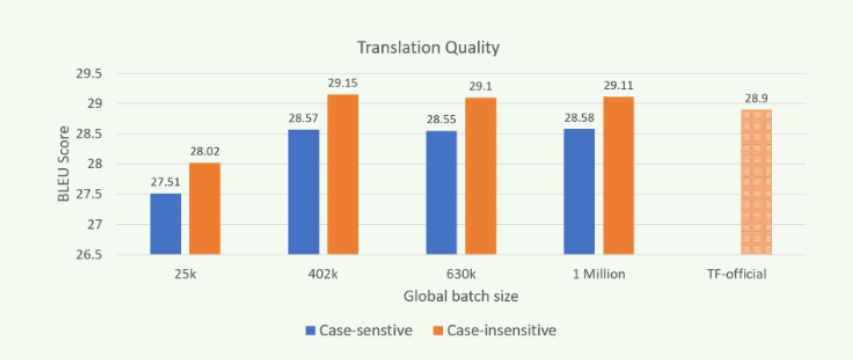
Figure 3: Translation quality (BLEU) when trained with different batch sizes on Zenith.
Scaling out the “transformer” model training using MPI and Horovod improves throughput performance while producing models of similar translation quality as shown in Figure 3. The results were obtained by using newstest2014 as the test set. Models of comparable quality can be trained in a reduced amount of time by scaling computation over many more nodes, and with larger global batch sizes (GBZ). Our experiments on Zenith demonstrate the ability to train models of comparable or higher translation quality (as measured by BLEU score) than the reported best for TensorFlow's official model, even when training with batches of a million or more tokens.
Note: The results shown in figure 3 were obtained by using the settings mentioned in our previous blog and by using Open MPI.
Conclusion
Here in this blog, we showed the generalization of large batch training of NMT model. We also showed how efficiently Intel® Xeon® Scalable processors are able to scale and reduce the time to solution. We hope this would benefit the productivity of the NMT research community using CPU-based HPC infrastructures.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda
LinkedIn: https://www.linkedin.com/in/srinivasvaradharajan