




Deploying Llama 7B Model with Advanced Quantization Techniques on Dell Server


Introduction
Large-language Models (LLMs) have gained great industrial and academic interest in recent years. Different LLMs have been adopted in various applications, such as: content generation, text summarization, sentiment analysis, and healthcare. The LLM evolution diagram in Figure 1 shows the popular pre-trained models since 2017 when the transformer architecture was first introduced [1]. It is not hard to find the trend of larger and more open-source models following the timeline. Open-source models boosted the popularity of LLMs by eliminating the huge training cost associated with the large scale of the infrastructure and long training time required. Another portion of the cost of LLM applications comes from the deployment where an efficient inference platform is required.
This blog focuses on how to deploy LLMs efficiently on Dell platform with different quantization techniques. We first benchmarked the model accuracy under different quantization techniques. Then we demonstrated their performance and memory requirements of running LLMs under different quantization techniques through experiments. Specifically, we chose the open-source model Llama-2-7b-chat-hf for its popularity [2]. The server is chosen to be Dell main-stream server R760xa with NVIDIA L40 GPUs [3] [4]. The deployment framework in the experiments is TensorRT-LLM, which enables different quantization techniques including advanced 4bit quantization as demonstrated in the blog [5].
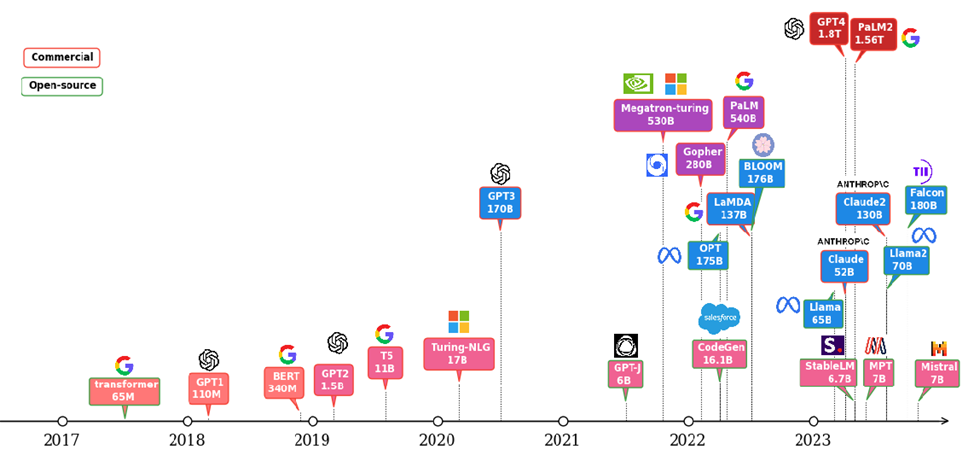
Figure 1 :LLM evolution
Background
LLM inferencing processes tend to be slow and power hungry, because of the characteristics of LLMs being large in weight size and having auto-regression. How to make the inferencing process more efficient under limited hardware resources is among the most critical problems for LLM deployment. Quantization is an important technique widely used to push for more efficient LLM deployment. It can relieve the large hardware resource requirements by reducing the memory footprint and computation energy, as well as improve the performance with faster memory access time compared to the deployment with the original un-quantized model. For example, in [6], the performance in terms of throughput by tokens per second (tokens/s) for Llama-2-7b model is improved by more than 2x by quantizing from floating point 16-bit format to integer 8-bit. Recent research made more aggressive quantization techniques like 4-bit possible and available in some deployment frameworks like TensorRT-LLM. However, quantization is not free, and it normally comes with accuracy loss. Besides the cost, reliable performance with acceptable accuracy for specific applications is what users would care about. Two key topics covered in this blog are accuracy and performance. We first benchmark the accuracy of the original model and quantized models over different tasks. Then we deployed those models into Dell server and measured their performance. We further measured the GPU memory usage for each scenario.
Test Setup
The model under investigation is Llama-2-7b-chat-hf [2]. This is a finetuned LLMs with human-feedback and optimized for dialogue use cases based on the 7-billion parameter Llama-2 pre-trained model. We load the fp16 model as the baseline from the huggingface by setting torch_dtype to float16.
We investigated two advanced 4-bit quantization techniques to compare with the baseline fp16 model. One is activation-aware weight quantization (AWQ) and the other is GPTQ [7] [8]. TensorRT-LLM integrates the toolkit that allows quantization and deployment for these advanced 4-bit quantized models.
For accuracy evaluation across models with different quantization techniques, we choose the Massive Multitask Language Understanding (MMLU) datasets. The benchmark covers 57 different subjects and ranges across different difficulty levels for both world knowledge and problem-solving ability tests [9]. The granularity and breadth of the subjects in MMLU dataset allow us to evaluate the model accuracy across different applications. To summarize the results more easily, the 57 subjects in the MMLU dataset can be further grouped into 21 categories or even 4 main categories as STEM, humanities, social sciences, and others (business, health, misc.) [10].
Performance is evaluated in terms of tokens/s across different batch sizes on Dell R760xa server with one L40 plugged in the PCIe slots. The R760xa server configuration and high-level specification of L40 are shown in Table 1 and 2 [3] [4]. To make the comparison easier, we fix the input sequence length and output sequence length to be 512 and 200 respectively.
System Name | PowerEdge R760xa |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Process Name | Intel® Xeon® Gold 6430 |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity and Type | 512GB, 16 x 32GB DIMM, 4800 MT/s DDR5 |
Host Storage Capacity | 1.8 TB, NVME |
Table 1: R760xa server configuration
GPU Architecture | L40 NVIDIA Ada Lovelace Architecture |
GPU Memory Bandwidth | 48 GB GDDR6 with ECC |
Max Power Consumption | 300W |
Form Factor | 4.4" (H) x 10.5" (L) Dual Slot |
Thermal | Passive |
Table 2: L40 High-level specification
The inference framework that includes different quantization tools is NVIDIA TensorRT-LLM initial release version 0.5. The operating system for the experiments is Ubuntu 22.04 LTS.
Results
We first show the model accuracy results based on the MMLU dataset tests in Figure 2 and Figure 3, and throughput performance results when running those models on PowerEdge R760xa in Figure 4. Lastly, we show the actual peak memory usage for different scenarios. Brief discussions are given for each result. The conclusions are summarized in the next section.
Accuracy
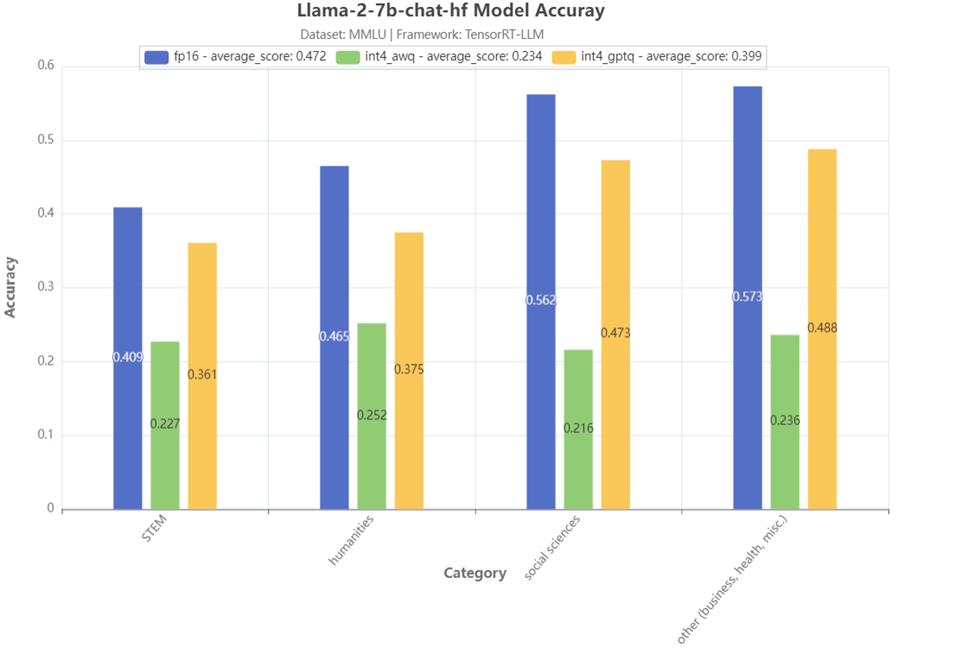
Figure 2:MMLU 4-category accuracy test result
Figure 2 shows the accuracy test results of 4 main MMLU categories for the Llama-2-7b-chat-hf model. Compared to the baseline fp16 model, we can see that the model with 4-bit AWQ has a significant accuracy drop. On the other hand, the model with 4-bit GPTQ has a much smaller accuracy drop, especially for the STEM category, the accuracy drop is smaller than 5%.
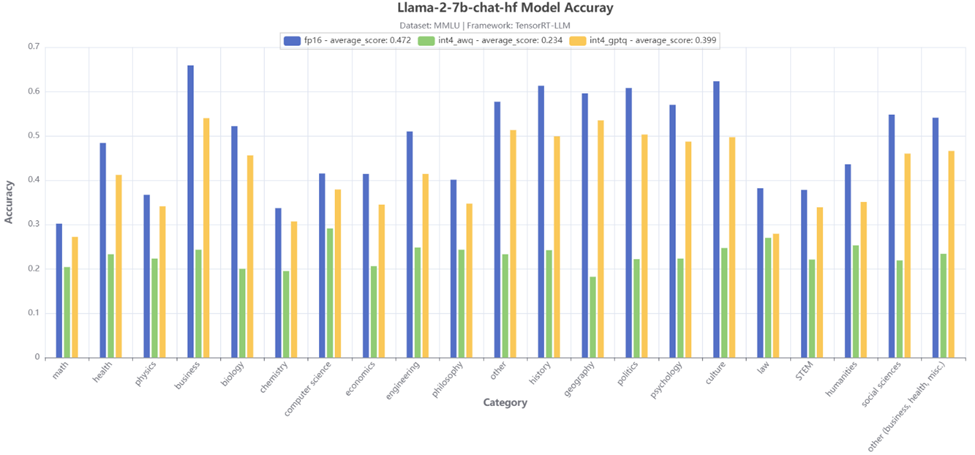
Figure 3:MMLU 21-category accuracy test result
Figure 3 further shows the accuracy test results of 21 MMLU sub-categories for the Llama-2-7b-chat-hf model. Similar conclusions can be made that the 4-bit GPTQ quantization gives much better accuracy, except for the law category, the two quantization techniques achieve a close accuracy.
Performance
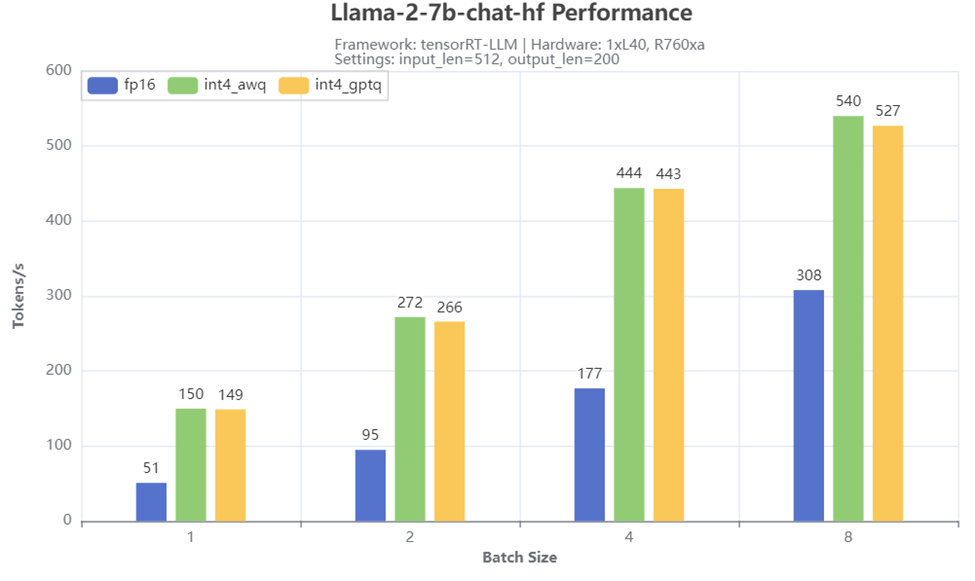
Figure 4: Throughput test result
Figure 4 shows the throughput numbers when running Llama-2-7b-chat-hf with different batch size and quantization methods on R760xa server. We observe significant throughput boost with the 4-bit quantization, especially when the batch size is small. For example, a 3x tokens/s is achieved when the batch size is 1 when comparing the scenarios with 4-bit AWQ or GPTQ quantization to the 16-bit baseline scenario. Both AWQ and GPTQ quantization give similar performance across different batch sizes.
GPU Memory Usage
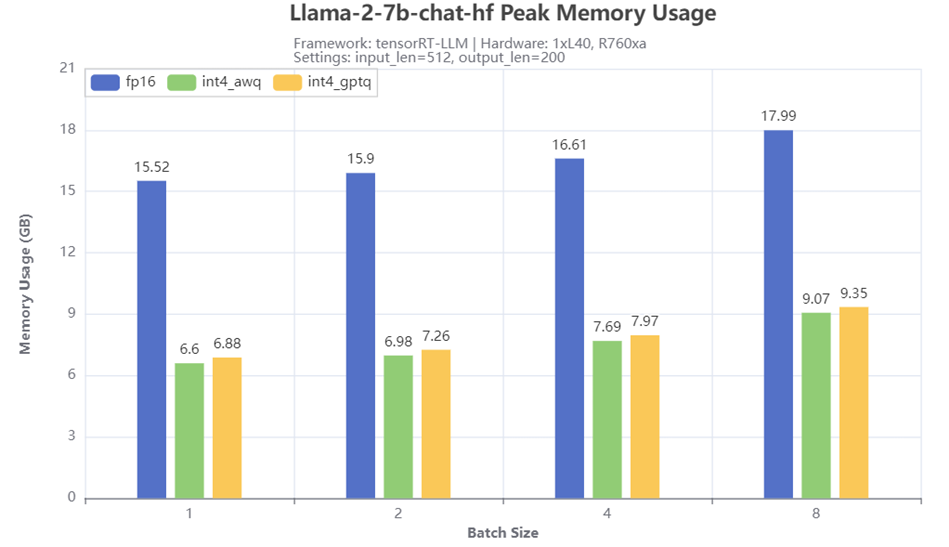
Figure 5: Peak GPU memory usage
Figure 5 shows the peak GPU memory usage when running Llama-2-7b-chat-hf with different batch size and quantization methods on R760xa server. From the results, 4-bit quantization techniques greatly reduced the memory required for running the model. Compared to the memory size required for the baseline fp16 model, the quantized models with AWQ or GPTQ only requires half or even less of the memory, depending on the batch size. A slightly larger peak memory usage is also observed for GPTQ quantized model compared to the AWQ quantized model.
Conclusion
- We have shown the impacts for accuracy, performance, and GPU memory usage by applying advanced 4-bit quantization techniques on Dell PowerEdge server when running Llama 7B model.
- We have demonstrated the great benefits of these 4-bit quantization techniques in terms of improving throughput and saving GPU memory.
- We have quantitively compared the quantized models with the baseline model in terms of accuracy among various subjects based on the MMLU dataset.
- Tests showed that with an acceptable accuracy loss, 4-bit GPTQ is an attractive quantization method for the LLM deployment where the hardware resource is limited. On the other hand, large accuracy drops across many MMLU subjects have been observed for the 4-bit AWQ. This indicates the model should be limited to the applications tied to some specific subjects. Otherwise, other techniques like re-training or fine-turning techniques may be required to improve accuracy.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
[4]. https://www.nvidia.com/en-us/data-center/l40/
[5]. https://github.com/NVIDIA/TensorRT-LLM
[7]. J. Lin et. al, “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration”, https://arxiv.org/abs/2306.00978
[8]. E. Frantar et. al, “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers”, https://arxiv.org/abs/2210.17323
[9]. D. Hendrycks et. all, “Measuring Massive Multitask Language Understanding”, https://arxiv.org/abs/2009.03300
[10]. https://github.com/hendrycks/test/blob/master/categories.py