




Deploy Machine Learning Models Quickly with cnvrg.io and VMware Tanzu
Download PDFWed, 13 Dec 2023 21:09:16 -0000
|Read Time: 0 minutes
Related Documents

Launch Flexible Machine Learning Models Quickly with cnvrg.io® on Red Hat OpenShift
Wed, 17 Jan 2024 14:11:31 -0000
|Read Time: 0 minutes
Summary
Data scientists hold a high degree of responsibility to support the decision-making process of companies and their strategies. To this end, data scientists extract insights from a large amount of heterogeneous data through a set of iterative tasks that include various aspects: cleaning and formatting the data available to them, building training and testing datasets, mining data for patterns, deciding on the type of data analysis to apply and the ML methods to use, evaluating and interpreting the results, refining ML algorithms, and possibly even managing infrastructure. To ensure that data scientists can deliver the most impactful insights for their companies efficiently and effectively, convrg.io provides a unified platform to operationalize the full machine learning (ML) lifecycle from research to production.
As the leading data-science platform for ML model operationalization (MLOps) and management, cnvrg.io is a pioneer in building cutting-edge ML development solutions that provide data scientists with all the tools they need in one place to streamline their processes. In addition, by deploying MLOps on Red Hat OpenShift, data scientists can launch flexible, container-based jobs and pipelines that can easily scale to deliver better efficiency in terms of compute resource utilization and cost. Infrastructure teams can also manage and monitor ML workloads in a single managed and cloud-native environment. For infrastructure architects who are deploying cnvrg.io on Dell PowerEdge servers and Intel® components, this document provides recommended hardware bill of materials (BoM) configurations to help get them started.
Key considerations
Key considerations for using the recommended hardware BoMs for deploying cnvrg.io on Red Hat OpenShift include:
- Provision external storage. When deploying cnvrg.io on Red Hat OpenShift, local storage is used only for container images and ephemeral volumes. External persistent storage volumes should be provisioned on a storage array or on another solution that you already have in place. If you do not already have a persistent storage solution, contact your Dell Technologies representative for guidance.
- Use high-performance object storage. The hardware BoMs below assume that you use an in-cluster solution based on MinIO for object storage. The number of drives and the capacity for MinIO object storage depends on the dataset size and performance requirements. An alternative object store would be an external S3-compatible object store such as Elastic Cloud Storage (ECS) or Dell PowerScale (Isilon), powered by high-capacity Solidigm SSDs.
- Scale object storage independently. Object storage capacity can be scaled independently of worker nodes by deploying additional storage nodes. Both high-performance, high capacity (with NVM Express [NVMe] Solidigm solid-state drives [SSDs]), and high-capacity (with rotational hard-disk drives [HDDs]) configurations can be used. All nodes using NVMe drives should be configured with 100 Gbps network interface controllers (NICs) to take full advantage of the drives’ I/O throughput.
Recommended configurations
Controller nodes (3 nodes required) and worker nodes
Table 1. PowerEdge R660-based, up to 10 NVMe drives, 1RU
Feature | Control-Plane (Master) Nodes | ML/Artificial Intelligence (AI) CPU Cluster (Worker) Nodes | |
Platform | Dell R660 supporting 10 x 2.5” drives with NVMe backplane - direct connection | ||
CPU |
| Base configuration | Plus configuration |
2x Xeon® Gold 6426Y (16c @ 2.5GHz) | 2x Xeon® Gold 6448Y (32c @ 2.1GHz) | 2x Xeon® Platinum 8468 (48c @ 2.1GHz) | |
DRAM | 128GB (8x 16GB DDR5-4800) | 256GB (16x 16GB DDR5-4800) | 512GB (16x 32GB DDR5-4800) |
Boot device | Dell BOSS-N1 with 2x 480GB M.2 NVMe SSD (RAID1) | ||
Storage[1] | 1x 1.6TB Solidigm[2] D7-P5620 SSD (PCIe Gen4, Mixed-use) | 2x 1.6TB Solidigm2 D7-P5620 SSD (PCIe Gen4, Mixed-use) | |
Object storage[3] | N/A | 4x (up to 10x) 1.92TB, 3.84TB or 7.68TB Solidigm D7-P5520 SSD (PCIe Gen4, Read-Intensive) | |
Shared storage[4] | N/A | External | |
NIC[5] | Intel® X710-T4L for OCP3 (Quad-port 10Gb) | Intel® X710-T4L for OCP3 (Quad-port 10Gb), or Intel® E810-CQDA2 PCIe add-on card (dual-port 100Gb) | |
Additional NIC for external storage[6] | N/A | Intel® X710-T4L for OCP3 (Quad-port 10Gb), or Intel® E810-CQDA2 PCIe add-on card (dual-port 100Gb) | |
Optional – Dedicated storage nodes
Figure 2. PowerEdge R660-based, up to 10 NVMe drives or 12 SAS drives, 1RU
Feature | Description | |
Node type | High performance | High capacity |
Platform | Dell R660 supporting 10x 2.5” drives with NVMe backplane | Dell R760 supporting 12x 3.5” drives with SAS/SATA backplane |
CPU | 2x Xeon® Gold 6442Y (24c @ 2.6GHz) | 2x Xeon® Gold 6426Y (16c @ 2.5GHz) |
DRAM | 128GB (8x 16GB DDR5-4800) | |
Storage controller | None | HBA355e adapter |
Boot device | Dell BOSS-N1 with 2x 480GB M.2 NVMe SSD (RAID1) | |
Object storage3 | up to 10x 1.92TB / 3.84TB / 7.68TB Solidigm D7-P5520 SSD (PCIe Gen4, Read-Intensive) | up to 12x 8TB/16TB/22TB 3.5in 12Gbps SAS HDD 7.2k RPM |
NIC4 | Intel® E810-CQDA2 PCIe add-on card (dual-port 100Gb) | Intel® E810-XXV for OCP3 (dual-port 25Gb) |
Learn more
Contact your Dell or Intel account team for a customized quote at 1-877-289-3355
[1] Local storage used only for container images and ephemeral volumes; persistent volumes should be provisioned on an external storage system.
[2] Formerly Intel
[3] The number of drives and capacity for MinIO object storage depends on the dataset size and performance requirements.
[4] External shared storage required for Kubernetes persistent volumes.
[5] 100 Gb NICs are recommended for higher throughput.
[6] Optional, required only if a dedicated storage network for external storage system is necessary.

Powering Kafka with Kubernetes and Dell PowerEdge Servers with Intel® Processors
Mon, 29 Jan 2024 23:33:38 -0000
|Read Time: 0 minutes
Kafka with Kubernetes
At the top of this webpage are 3 PDF files outlining test results and reference configurations for Dell PowerEdge servers using both the 3rd Generation Intel® Xeon® processors and 4th Generation Intel Xeon processors. All testing was conducted in Dell Labs by Intel and Dell Engineers in October and November of 2023.
- “Dell DfD Kafka ICX” – highlights the recommended configurations for Dell PowerEdge servers using 3rd generation Intel® Xeon® processors.
- “Dell DfD Kafka SPR” – highlights the recommended configurations for Dell PowerEdge servers using 4th generation Intel® Xeon® processors.
- “Dell DfD Kafka Kubernetes Test Report” – Highlights the results of performance testing on both configurations with comparisons that demonstrate the performance differences between them.
Solution Overview
The Apache® Software Foundation developed Kafka as an Open Source solution to provide distributed event store and stream processing capabilities. Apache Kafka uses a publish-subscribe model to enable efficient data sharing across multiple applications. Applications can publish messages to a pool of message brokers, which subsequently distribute the data to multiple subscriber applications in real time.
Kafka is often deployed for mission-critical applications and streaming analytics along with other use cases. These types of workloads require leading-edge performance which places significant demand on hardware.
There are five major APIs in Kafka[i]:
- Producer API – Permits an application to publish streams of records.
- Consumer API – Permits an application to subscribe to topics and process streams of records.
- Connect API – performs the reusable producer and consumer APIs that can link the topics to the existing applications.
- Streams API – This API converts the input streams to output and produces the result.
- Admin API – Used to manage Kafka topics, brokers, and other Kafka objects.
Kafka with Dell PowerEdge and Intel processor benefits
The introduction of new server technologies allows customers to deploy solutions using the newly introduced functionality, but it can also provide an opportunity for them to review their current infrastructure and determine if the new technology might increase performance and efficiency. Dell and Intel recently conducted testing of Kafka performance in a Kubernetes environment and measured the performance of two different compression engines on the new Dell PowerEdge R760 with 4th generation Intel® Xeon® Scalable processors and compared the results to the same solution running on the previous generation R750 with 3rd generation Intel® Xeon® Scalable processors to determine if customers could benefit from a transition.
Some of the key changes incorporated into 4th generation Intel® Xeon® Scalable processors include:
- Quick Assist Technology (QAT) to accelerate data compression and encryption.
- Support for 4800 MT/s DDR5 memory
Raw performance: As noted in the report, our tests showed a 72% producers’ latency decrease with gzip compression and a 62% producers’ latency decrease with zstd compression.
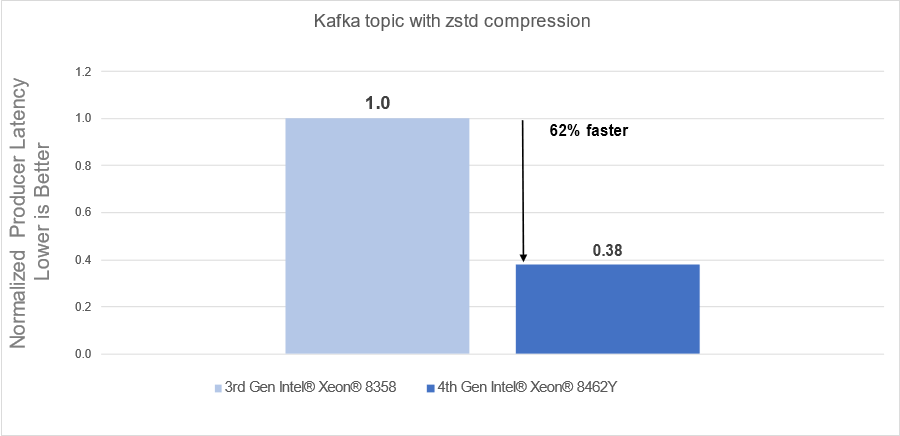
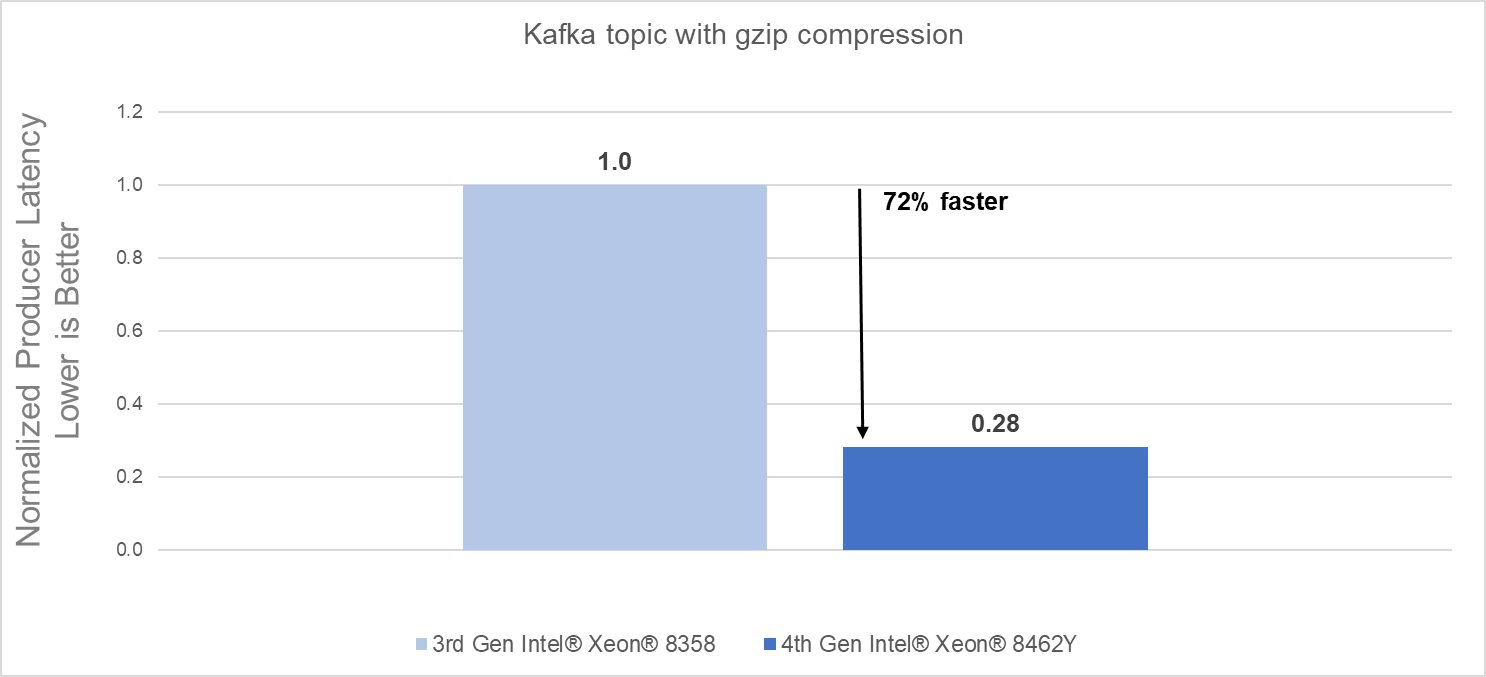
Conclusion
Choosing the right combination of Server and Processor can increase performance and reduce time, allowing customers to react faster and process more data. As this testing demonstrated, the Dell PowerEdge R760 with 4th Generation Intel® Xeon® CPUs significantly outperformed the previous generation.
- The Dell PowerEdge R760 with 4th Generation Intel® Xeon® Scalable processors delivered:
- 62% faster processing using zstd compression
- 72% faster procession using gzip compression
- 4th Generation Intel® Xeon® Scalable processors benefits are the results of:
- Innovative CPU microarchitecture providing a performance boost
- Introduction of DDR5 memory support
[i] https://en.wikipedia.org/wiki/Apache_Kafka