




CloudPools Reporting
Fri, 12 Jan 2024 20:33:21 -0000
|Read Time: 0 minutes
Related Blog Posts

CloudPools Operation Workflows
Fri, 12 Jan 2024 21:01:01 -0000
|Read Time: 0 minutes
The Dell PowerScale CloudPools feature of OneFS allows tiering cold or infrequently accessed data to move to lower-cost cloud storage. CloudPools extends the PowerScale namespace to the private cloud, or the public cloud. For CloudPools supported cloud providers, see the CloudPools Supported Cloud Providers blog.
This blog focuses on the following CloudPools operation workflows:
- Archive
- Recall
- Read
- Update
Archive
The archive operation is the CloudPools process of moving file data from the local PowerScale cluster to cloud storage. Files are archived either using the SmartPools Job or from the command line. The CloudPools archive process can be paused or resumed.
The following figure shows the workflow of the CloudPools archive.
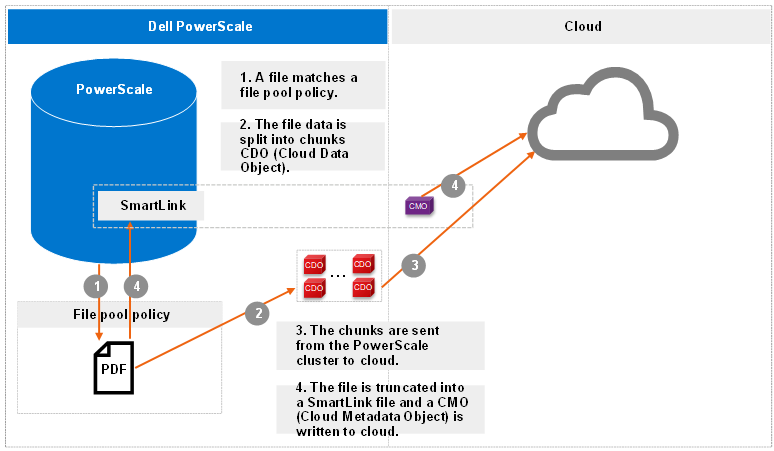
Figure 1. Archive workflow
More workflow details include:
- The file pool policy in Step 1 specifies a cloud target and cloud-specific parameters. Policy examples include:
- Encryption: CloudPools provides an option to encrypt data before the data is sent to the cloud storage. It uses the PowerScale key management module for data encryption and uses AES-256 as the encryption algorithm. The benefit of encryption is that only encrypted data is being sent over the network.
- Compression: CloudPools provides an option to compress data before the data is sent to the cloud storage. It implements block-level compression using the zlib compression library. CloudPools does not compress data that is already compressed.
- Local data cache: Caching is used to support local reading and writing of SmartLink files. To optimize performance, it reduces bandwidth costs by eliminating repeated fetching of file data for repeated reads and writes. The data cache is used for temporarily caching file data from the cloud storage on PowerScale disk storage for files that have been moved off cluster by CloudPools.
- Data retention: Data retention is a concept used to determine how long to keep cloud objects on the cloud storage.
- When chunks are sent from the PowerScale cluster to cloud in Step 3, a checksum is applied for each chunk to ensure data integrity.
Recall
The recall operation is the CloudPools process of reversing the archive process. It replaces the SmartLink file by restoring the original file data on the PowerScale cluster and removing the cloud objects in cloud. The recall process can only be performed using the command line. The CloudPools recall process can be paused or resumed.
The following figure shows the workflow of CloudPools recall.
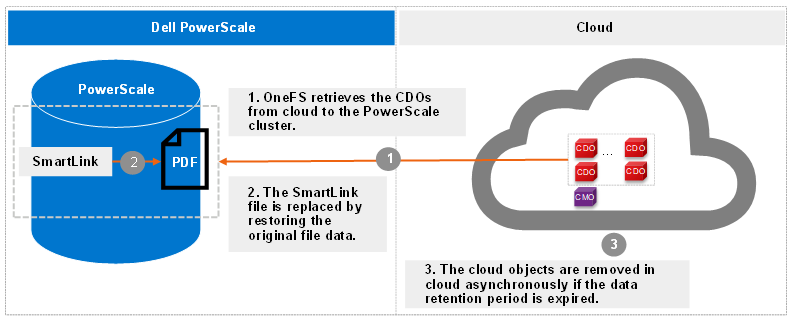
Figure 2. Recall workflow
Read
The read operation is the CloudPools process of client data access, known as inline access. When a client opens a file for read, the blocks are added to the cache in the associated SmartLink file by default. The cache can be disabled by setting the accessibility in the file pool policy for CloudPools. The accessibility setting is used to specify how data is cached in SmartLink files when a user or application accesses a SmartLink file on the PowerScale cluster. Values are cached (default) and no cache.
The following figure shows the workflow of CloudPools read by default.
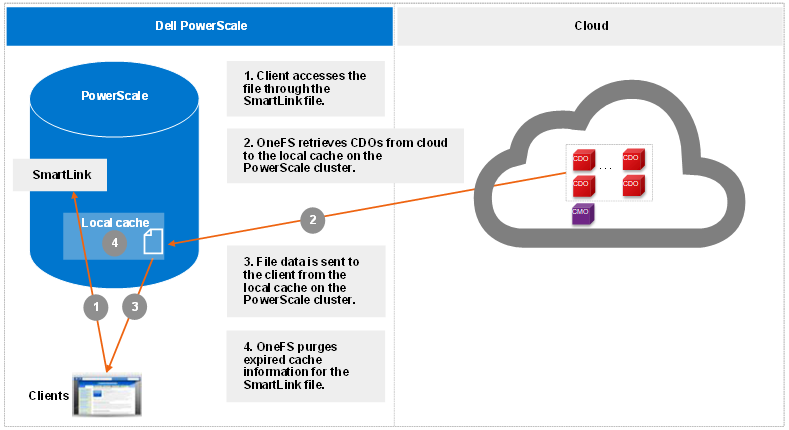
Figure 3. Read workflow
Starting from OneFS 9.1.0.0, cloud object cache is introduced to enhance CloudPools functions for communicating with cloud. In Step 1, OneFS looks for data in the object cache first and OneFS retrieves data from the object cache if the data is already in the object cache. Cloud object cache reduces the number of requests to cloud when reading a file.
Prior to OneFS 9.1.0.0, in Step 1, OneFS looks for data in the local data cache first. It moves to Step 3 if the data is already in the local data cache.
Note: Cloud object cache is per node. Each node maintains its own object cache on the cluster.
Update
The update operation is the CloudPools process that occurs when clients update data. When clients change to a SmartLink file, CloudPools first writes the changes in the data local cache and then periodically sends the updated file data to cloud. The space used by the cache is temporary and configurable.
The following figure shows the workflow of CloudPools update.
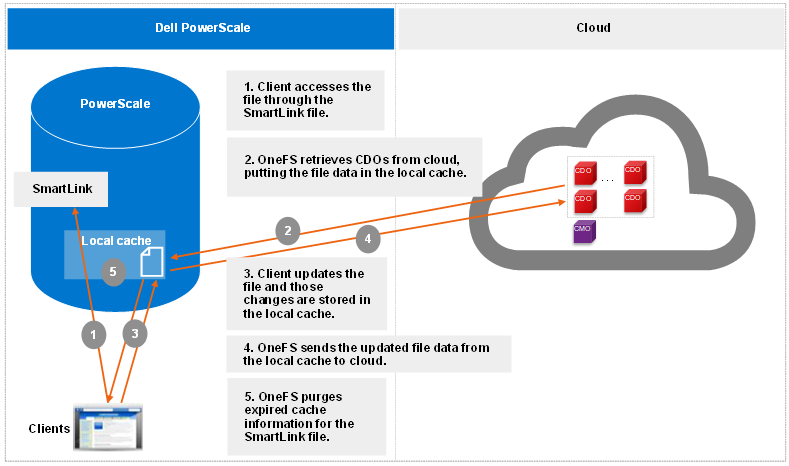
Figure 4. Update workflow
Thank you for taking the time to read this blog, and congratulations on gaining a clear understanding of how the OneFS CloudPools operation works!
Author: Jason He, Principal Engineering Technologist

Protecting CloudPools SmartLink Files
Fri, 12 Jan 2024 17:20:14 -0000
|Read Time: 0 minutes
Dell PowerScale CloudPools SmartLink files are the sole means to access file data stored in the cloud, so ensure that you protect them from accidental deletion.
Note: SmartLink files cannot be backed up using a copy command, such as secure copy (scp).
This blog focuses on backing up SmartLink files using OneFS SyncIQ and NDMP (Network Data Management Protocol).
When the CloudPools version differs between the source cluster and the target PowerScale cluster, the CloudPools cross-version compatibility is handled.
NDMP and SyncIQ provide two types of copy or backup:
- Shallow copy (SC)/backup: Replicates or backs up SmartLink files to the target PowerScale cluster or tape as SmartLink files without file data.
- Deep copy (DC)/backup: Replicates or backs up SmartLink files to the target PowerScale cluster or tape as regular files or unarchived files. The backup or replication will be slower than for a shallow copy backup. Disk space will be consumed on the target cluster for replicating data.
The following table shows the CloudPools and OneFS mapping information. CloudPools 2.0 is released along with OneFS 8.2.0. CloudPools 1.0 is running in OneFS 8.0.x or 8.1.x.
Table 1. CloudPools and OneFS mapping information
OneFS version | CloudPools version |
OneFS 8.0.x/OneFS 8.1.x | CloudPools 1.0 |
OneFS 8.2.0 or higher | CloudPools 2.0 |
The following table shows the NDMP and SyncIQ supported use cases when different versions of CloudPools are running on the source and target clusters. As noted in the following table, if CloudPools 2.0 is running on the source PowerScale cluster and CloudPools 1.0 is running on the target PowerScale cluster, shallow copies are not allowed.
Table 2. NDMP and SyncIQ supported use cases with CloudPools
Source | Target | SC NDMP | DC NDMP | SC SyncIQ replication | DC SyncIQ replication |
CloudPools 1.0 | CloudPools 2.0 | Supported | Supported | Supported | Supported |
CloudPools 2.0 | CloudPools 1.0 | Not Supported | Supported | Not Supported | Supported |
SyncIQ
SyncIQ is CloudPools-aware but consider the guidance in snapshot efficiency, especially where snapshot retention periods on the target cluster will be long.
SyncIQ policies support two types of data replication for CloudPools:
- Shallow copy: This option is used to replicate files as SmartLink files without file data from the source PowerScale cluster to the target PowerScale cluster.
- Deep copy: This option is used to replicate files as regular files or unarchived files from the source PowerScale cluster to the target PowerScale cluster.
SyncIQ, SmartPools, and CloudPools licenses are required on both the source and target PowerScale cluster. It is highly recommended to set up a scheduled SyncIQ backup of the SmartLink files.
When SyncIQ replicates SmartLink files, it also replicates the local cache state and unsynchronized cache data from the source PowerScale cluster to the target PowerScale cluster. The following figure shows the SyncIQ replication when replicating directories including SmartLink files and unarchived normal files. Both unidirectional and bi-directional replication are supported.
Note: OneFS manages cloud access at the cluster level and does not support managing cloud access at the directory level. When failing over a SyncIQ directory containing SmartLink files to a target cluster, you need to remove cloud access on the source cluster and add cloud access on the target cluster. If there are multiple CloudPools storage accounts, removing/adding cloud access will impact all CloudPools storage accounts on the source/target cluster.
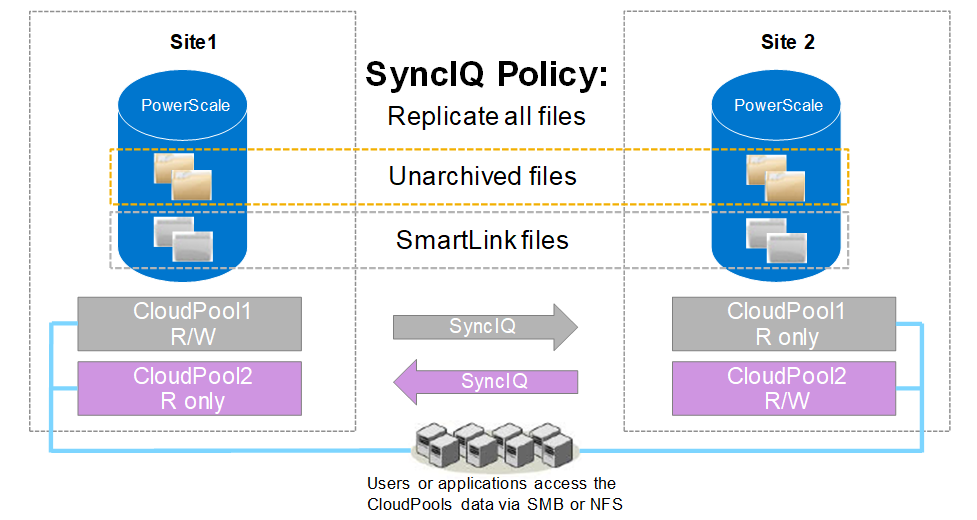
Figure 1. SyncIQ replication
Note: If encryption is enabled in a file pool policy for CloudPools, SyncIQ also replicates all the relevant encryption keys to the secondary PowerScale cluster along with the SmartLink files.
NDMP
NDMP is also CloudPools-aware and supports three backup and restore methods for CloudPools:
- DeepCopy: This option is used to back up files as regular files or unarchived files. Files can only be restored as regular files.
- ShallowCopy: This option is used to back up files as SmartLink files without file data. Files can only be restored as SmartLink files.
- ComboCopy: This option is used to back up files as SmartLink files with file data. Files can be restored as regular files or SmartLink files.
It is possible to update the file data and send the updated data to the cloud storage. Multiple version SmartLink files can be backed up to tape using NDMP, and multiple versions of CDOs (Cloud Data Objects) are protected in the cloud under the data retention setting. You can restore a specific version of a SmartLink file from tape to a PowerScale cluster and continue to access (read or update) the file as before.
Note: If encryption is enabled in the file pool policy for CloudPools, NDMP also backs up all the relevant encryption keys to tapes along with the SmartLink files.
Thank you for taking the time to read this blog, and congratulations on knowing the solutions for protecting SmartLink files using OneFS SyncIQ and NDMP.
Author: Jason He, Principal Engineering Technologist