




AI-Powered Smart Cities: PowerEdge and Intel Team Up to Deliver the Future
Mon, 07 Aug 2023 19:49:44 -0000
|Read Time: 0 minutes
Have you ever found yourself stuck at a red light with no other cars in sight, wondering why it takes so long to change? Or witnessed another never-ending traffic study in your city? What if we harness artificial intelligence to help cities make smart decisions fast?
The power of AI in smart cities
Artificial intelligence has emerged as a critical technology that is driving advancements in smart cities. It can analyze vast amounts of data to identify patterns and help make informed decisions, allowing city leaders to respond swiftly. These real-time insights will revolutionize how cities manage their infrastructures and services.
Improving traffic flow with AI
Imagine a world where AI optimizes traffic flow, minimizes wasted commute time, and reduces traffic congestion and thus pollution. Dell Technologies, Intel, and Scalers AI developed a concept solution combining the power of the latest PowerEdge servers offering 4th Gen Intel® Xeon® CPUs and Intel Data Center Flex Series GPUs. This innovative solution harnesses every ounce of computing power offered in the latest generation of PowerEdge servers to deliver maximum server performance.
Leading the way with smart city solutions
We developed this cutting-edge concept solution to give us a glimpse of the possible. Our approach involves monitoring automotive behavior and traffic using real-time video footage from many strategically positioned cameras. By analyzing this data, the application identifies safety hazards like reckless driving and vehicle collisions, empowering cities to respond swiftly.
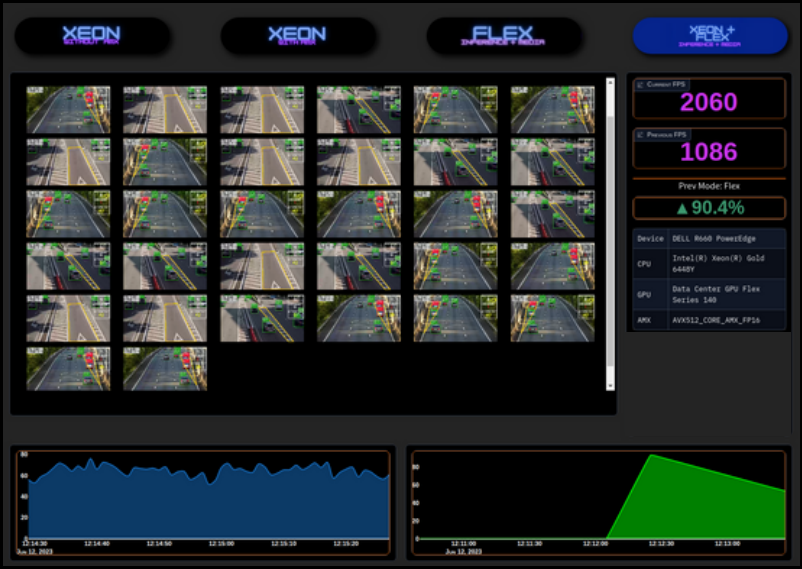
The impact of the Intel–Dell partnership
The partnership between Intel and Dell, supported by the expertise of Scalers AI, is driving smart cities into reality. The combined power of CPUs and GPUs for AI workloads enhances urban safety, sustainability, and efficiency. This collaboration allows cities to explore the potential of AI for real-world applications.
To learn more about this groundbreaking solution and how the latest technology from Dell Technologies and Intel will revolutionize urban living, visit https://infohub.delltechnologies.com/section-assets/07-09-intel-data-center-flex-series-gpu-with-poweredge-r660-driving-innovation.
Author: Delmar Hernandez
Related Blog Posts

Can CPUs Effectively Run AI Applications?
Fri, 03 Mar 2023 20:06:28 -0000
|Read Time: 0 minutes
Due to the inherent advantages of GPUs in high speed scale matrix operations, developers have gravitated to GPUs for AI training (developing the model) and inference (the model in execution).
With the scarcity of GPUs driven by the massive growth of AI applications, including recent advancements in stable diffusion and large language models that have taken the world by storm, such as ChatGPT by OpenAI, the question for many developers is:
Are CPUs up to the task of AI?
To answer the question, Dell Technologies and Scalers AI set up a Dell PowerEdge R760 server with 4th Gen Intel® Xeon® processors and integrated Intel® Deep Learning acceleration. Notably, we did not install a GPU on this server.
In this blog, Part One of a two-part series, we’ll put this latest and greatest Intel® Xeon® CPU just released this month by Intel® to the test on AI inference . We’ll also run AI on video streams, one of the most common mediums to run AI, and pair industry specific application logic to showcase a real-world AI workload.
In Part Two, we’ll train a model in a technique called transfer learning. Most training is done on GPUs today, and transfer learning presents a great opportunity to leverage existing models while customizing for targeted use cases.
The industry specific use case
Scalers AI developed a smart city solution that uses artificial intelligence and computer vision to monitor traffic safety in real time. The solution identifies potential safety hazards, such as illegal lane changes on freeway on-ramps, reckless driving, and vehicle collisions, by analyzing video footage from cameras positioned at key locations.
For comparison, we also set up the previous generation Dell PowerEdge R750 server and ran the AI inferencing object detection workload on both servers. What did we learn?
Dell PowerEdge R760 with 4th Gen Intel® Xeon® Processors and Intel® Deep Learning Boost delivered!
Let’s find out about the generational server comparison.
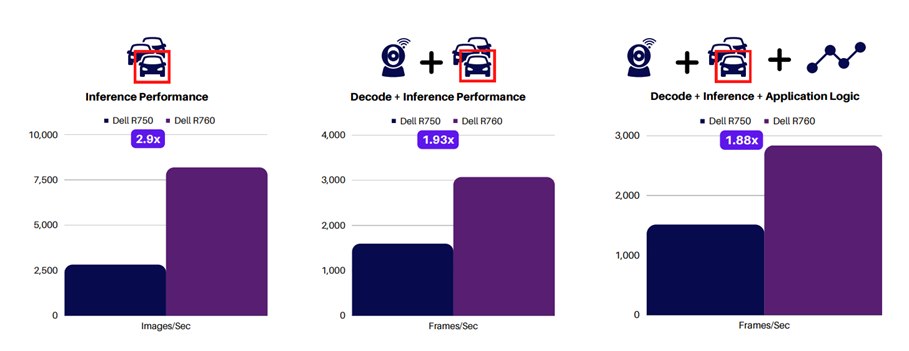
The following charts show the performance gain from the last gen to the current gen server. The graph on the left shows inference-only performance, while the middle graph adds video decode. Finally, the graph on the right shows the full application performance with the smart city solution application logic.
The performance claims are great. But what does this mean for my business?
Dell PowerEdge R760 and Scalers AI smart city solution results show that for a similar application, users can expect the Dell PowerEdge R760 server to perform real-time inferencing on up to 90 1080P video streams when it is deployed. Dell PowerEdge R750 can handle up to 50 1080P video streams, and this is all without a GPU. Although GPUs add additional AI computing capability, this study shows that they may only sometimes be necessary, depending on your unique requirements, such as how many streams must be displayed concurrently.
Given these results, Scalers AI confidently recommends using Dell PowerEdge R760 with 4th Gen Intel® Xeon® Processors and Intel® Deep Learning Boost for AI computer vision workloads, such as the Scalers AI Traffic Safety Solution using object detection, because they fulfill all application requirements.
Now that we have shown highly effective object detection on a CPU, what about a more compute-intensive complex model such as segmentation?
Here we are running segmentation on 10 streams, while displaying four streams on the more complex segmentation model.
As you can see, CPUs are up to the task of running AI inference on models such as object detection and segmentation. Perhaps more important for developers, they offer the flexibility to run the full workload on the same processor, thereby lowering the TCO.
With the rapid growth of AI, the ability to deploy on CPUs is a key differentiator for real-world use cases such as traffic safety. This frees up GPU resources for training and graphics use cases.
Check in for Part Two of this blog series as we discuss a technique to train a transfer learning model and put a CPU to the test there.
Resources
Interested in trying for yourself? Get access to the solution code!
To save developers hundreds of potential hours of development, Dell Technologies and Scalers AI are offering access to the solution code to fast-track development of AI workloads on next-generation Dell PowerEdge servers with 4th Gen Intel® Xeon® scalable processors.
For access to the code, reach out to your Dell representative or contact Scalers AI!
To learn more about the study discussed here, visit the following webpages:
• Myth-Busting:
Can Intel® Xeon® Processors Effectively Run AI Applications?
• Accelerate Industry Transformation:
Build Custom Models with Transfer Learning on Intel® Xeon®
• Scalers AI Performance Insights:
Dell PowerEdge R760 with 4th Gen Intel® Xeon® Scalable Processors in AI
Authors:
Steen Graham, CEO at Scalers AI
Delmar Hernandez, Server Technologist at Dell Technologies


Part II | How to Run Hugging Face Models with AMD ROCm™ on Dell™ PowerEdge™?
Tue, 14 Nov 2023 16:27:00 -0000
|Read Time: 0 minutes
In case you’re interested in learning more about how Dell and Hugging Face are working together, check out the November 14 announcement detailing how the two companies are simplifying GenAI with on-premises IT.
 PowerEdge R7615
PowerEdge R7615
 AMD Instinct MI210 Accelerator
AMD Instinct MI210 Accelerator
In our first blog, we explored the readiness of the AMD ROCm™ ecosystem to run modern Generative AI workloads. This blog provides a step-by-step guide to running Hugging Face models on AMD ROCm™ and insights on setting up TensorFlow, PyTorch, and GPT-2.
Dell PowerEdge offers a rich portfolio of AMD ROCm™ solutions, including Dell™ R7615, R760xa, R7615, and R7625 PowerEdge™ servers.
For this blog, we selected the Dell PowerEdge R7615.
| System Configuration Details
Operating system: Ubuntu 22.04.3 LTS
Kernel version: 5.15.0-86-generic
Docker Version: Docker version 24.0.6, build ed223bc
ROCm version: 5.7
Server: Dell™ PowerEdge™ R7615
CPU: AMD EPYC™ 9354P 32-Core Processor
GPU: AMD Instinct™ MI210
| Step-by-Step Guide
1. First, Install the AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using `rocm-smi.`
2. Next, we will select code snippets from Hugging Face. Hugging Face offers the most comprehensive developer tools for leading AI models. We will choose GPT2 code snippets for both TensorFlow and PyTorch.
| Running GPT2 on AMD ROCm™ with TensorFlow
Here, we use the AMD ROCm™ docker image for TensorFlow and launch GPT2 inference on an AMD™ GPU.
3. Use docker images for TensorFlow with AMD ROCm™ backend support to expedite the setup
Unset sudo docker run -it \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --ipc=host \ --shm-size 16G \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/dockerx \ -v $HOME/dockerx:/dockerx rocm/tensorflow:latest /bin/bash |
4. Run TensorFlow code from Hugging Face to infer GPT2 successfully inside a Docker container with the AMD™ GPU, using the following snippet
Python from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2") GPT2 = TFGPT2LMHeadModel.from_pretrained("gpt2") prompt = "What is Quantum Computing?"
input_ids = tokenizer.encode(prompt, return_tensors='tf')
output = GPT2.generate(input_ids, max_length = 100) print(tokenizer.decode(output[0], skip_special_tokens = True)) |
| Running GPT2 on AMD ROCm™ with PyTorch
5. Use docker images for PyTorch with AMD ROCm™ backend support to expedite the setup
Unset sudo docker run -it \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --ipc=host \ --shm-size 16G \ --group-add=video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --workdir=/dockerx \ -v $HOME/dockerx:/dockerx rocm/pytorch:rocm5.7_ubuntu22.04_py3.10_pytorch_2.0.1 /bin/bash |
6. Use the snippet below to run a PyTorch from Hugging Face script in a Docker container
| Python from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2', device_map="auto") model = GPT2LMHeadModel.from_pretrained('gpt2', device_map="auto") prompt = "What is Quantum Computing?"
encoded_input = tokenizer(prompt, return_tensors='pt') encoded_input = encoded_input.to('cuda')
output = model.generate(**encoded_input, max_length=100) print(tokenizer.decode(output[0], skip_special_tokens = True)) |
| As you can see, AMD ROCm™ has a rich ecosystem of support for leading AI frameworks like PyTorch, TensorFlow, and Hugging Face to set up and deploy industry-leading transformer models.
If you are interested in trying different models from Hugging Face, you can refer to the comprehensive set of transformer models supported here: https://huggingface.co/docs/transformers/index
Our next blog shows you how to run Llama-2 in a chat application, arguably the leading large language model available to developers today using Hugging Face.
| References
- https://huggingface.co/amd
- https://huggingface.co/docs/transformers/index
- https://rocm.docs.amd.com/en/latest/deploy/linux/quick_start.html
- https://medium.com/@qztseng/install-and-build-tensorflow2-3-on-amd-gpu-with-rocm-7c812f922f57
- https://hub.docker.com/r/rocm/pytorch/tags
| Authors:
Steen Graham, CEO of Scalers AI
Delmar Hernandez, Dell PowerEdge Technical Marketing
Mohan Rokkam, Dell PowerEdge Technical Marketing