
Assets

AI Driven Pop-up Manufacturing Made Possible with PowerEdge XR7620
Thu, 14 Mar 2024 16:47:06 -0000
|Read Time: 0 minutes
| Executive Summary
As traditional manufacturing processes are being gradually replaced by advanced technology, deep learning, 3D printing, and open programmable robotics offer an unprecedented opportunity to accelerate this transformation and deliver high quality, personalized products more affordably.
To demonstrate this opportunity we took on a challenge to showcase AI pop-up manufacturing by 3D printing orthopaedic components, specifically acetabular liners used in hip replacement surgeries and running them through a robotic arm & AI quality inspection and a sorting process, with worker safety embedded within.
This solution was both developed and deployed on Dell™ PowerEdge™ XR7620 purpose built for the edge with NVIDIA® A100 tensor core GPUs, including the custom acetabular liner defect detection model.
The proof of concept resulting in a live demo was completed within a quarter from the AI development, to the mechanical work to create a custom gripper, to the robotic arm assembly programming and AI integration. The live demo was successfully set-up and deployed in a day and ran for three days.
- 1 50% saving in engineering time to reach targeted 1.2 second latency across application with Dell™ PowerEdge™ XR7620
- Three AI models running on Dell™ PowerEdge™ XR7620 to enable Industrial Transformation
We trained our defect defection model for acetabular liners on Dell™ PowerEdge™ XR7620 and deployed it on the same system at the edge. We also ran our worker safety model and segment anything model, all in the compact rugged edge form factor.
- Steen Graham, CEO at Scalers AI™

| Industry Challenge
The American Academy of Orthopedic Surgeons reports more than 300,000 hip replacements are performed annually. Defective hip implants can lead to complications and high-cost revision surgeries. According to the FDA, over 500,000 people in the United States have been injured by defective hip implants. A study published in the Journal of Bone and Joint Surgery found that patients with defective hip implants were 3.5 times more likely to need revision surgery. The same study found that patients with defective hip implants were 2.5 times more likely to experience series complications such as infection, dislocation, and fracture.
Further, the cost of the artificial hip and liner can range into the thousands with the overall surgery range from $20,000 to $45,000 according to the American Academy of Orthopaedic Surgeons, with revision surgery even higher.
| Solution Architecture
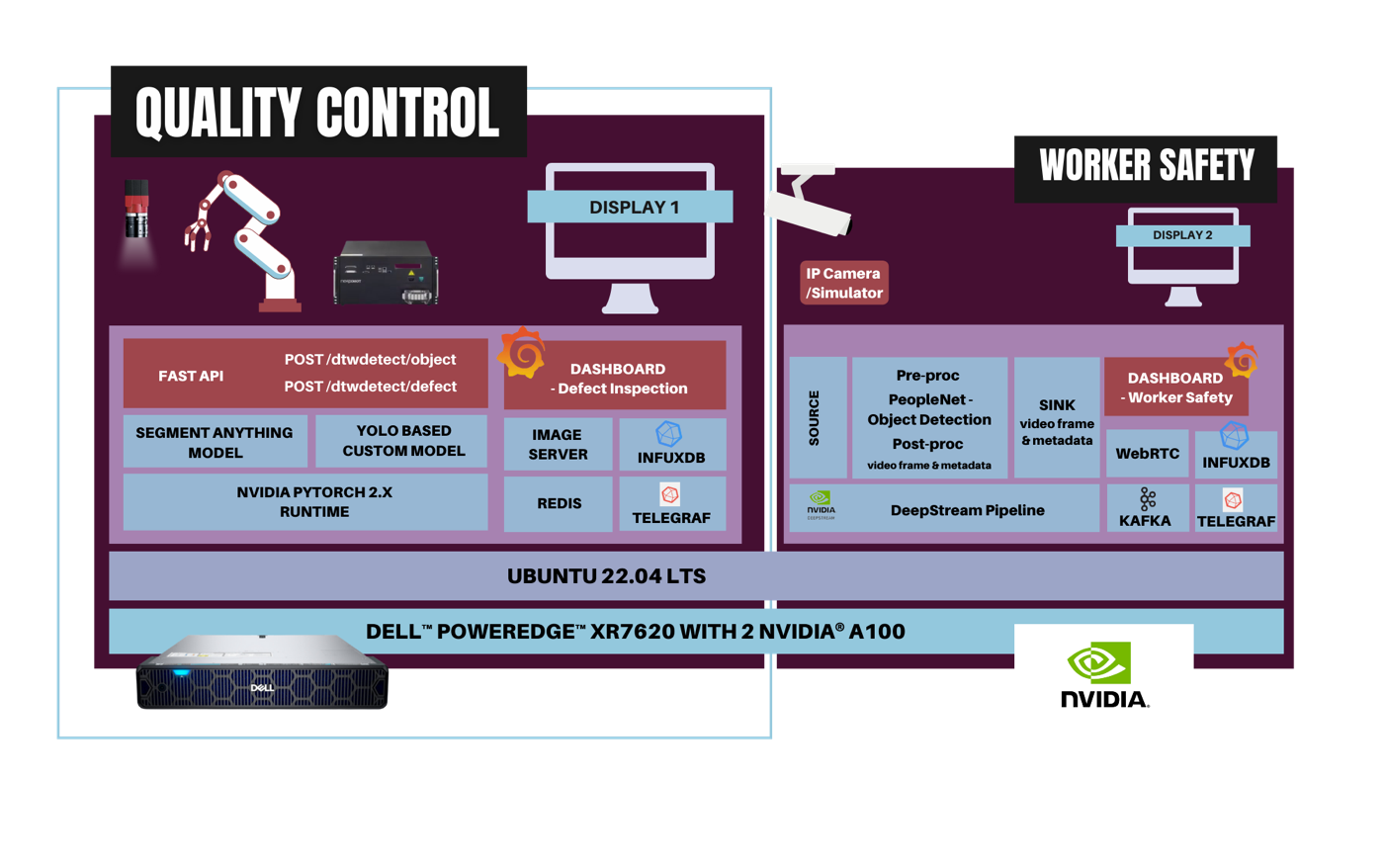
| The Concept
Demonstrate how we can improve production and quality inspection with the latest techniques in deep learning to reduce the likelihood of defective hip implants, while lowering the manufacturing cost. Ultimately, showing how modern techniques in AI, 3D printing, and robotics can improve patient safety and reduce costs.
Note: ~50% time savings estimated based on engineering resources applied in development (~2000 hours) and estimated incremental time required to label, train, custom API development, and post training optimization (~2000 hours).
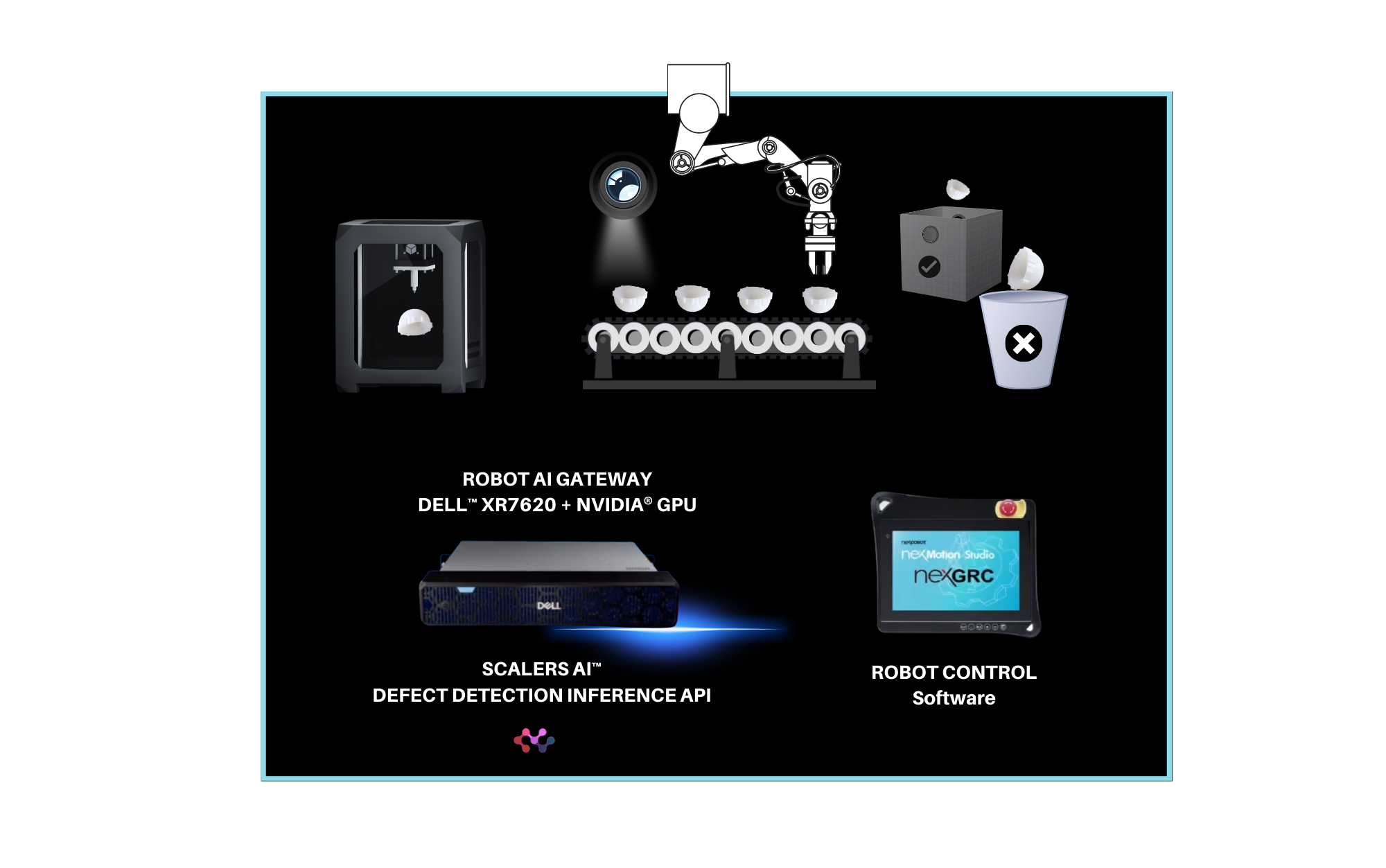
| Robotics
A 7-axis robotic arm and custom gripper was developed specifically for the demo to pick up acetabular liners within a few months. The robot controller is integrated with the AI APIs to pick up the liners and run defect detection. The robotic arm picks up the liners and rotates them under the camera to enable the defect detection. Then, the robot places the liners in different buckets based on whether they pass or fail the quality inspection.
The NexCOBOT robotic controller and 7-axis robotic arm were integrated with Scalers AI™ APIs and run on Dell™ PowerEdge™ XR7620 server.
| Deep Learning Models
The deep learning model involves three Neural Networks (NNs), including the latest Segment Anything model (SAM) for object detection, and a custom model built specifically to detect defects in acetabular liners, as well as a workers safety model. The custom model showcases the ability to build high-performance models using modest-sized datasets.
| Demo
Dashboards | Defect Detection
Quality Inspection Process
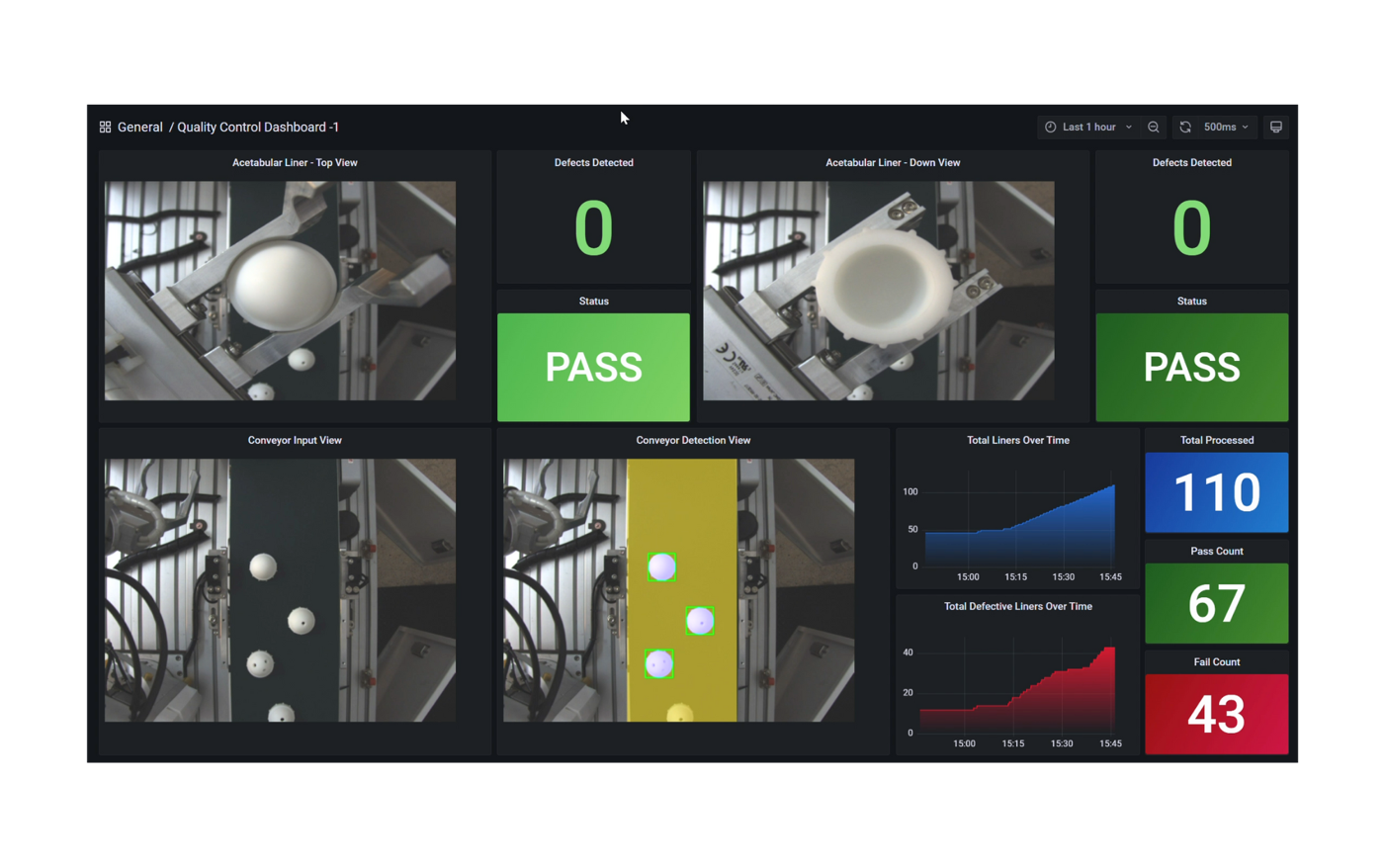
- During the quality control, no defects have been detected on the liner picked up. The robot arm will then place it in the bucket dedicated to non defective hip implants.
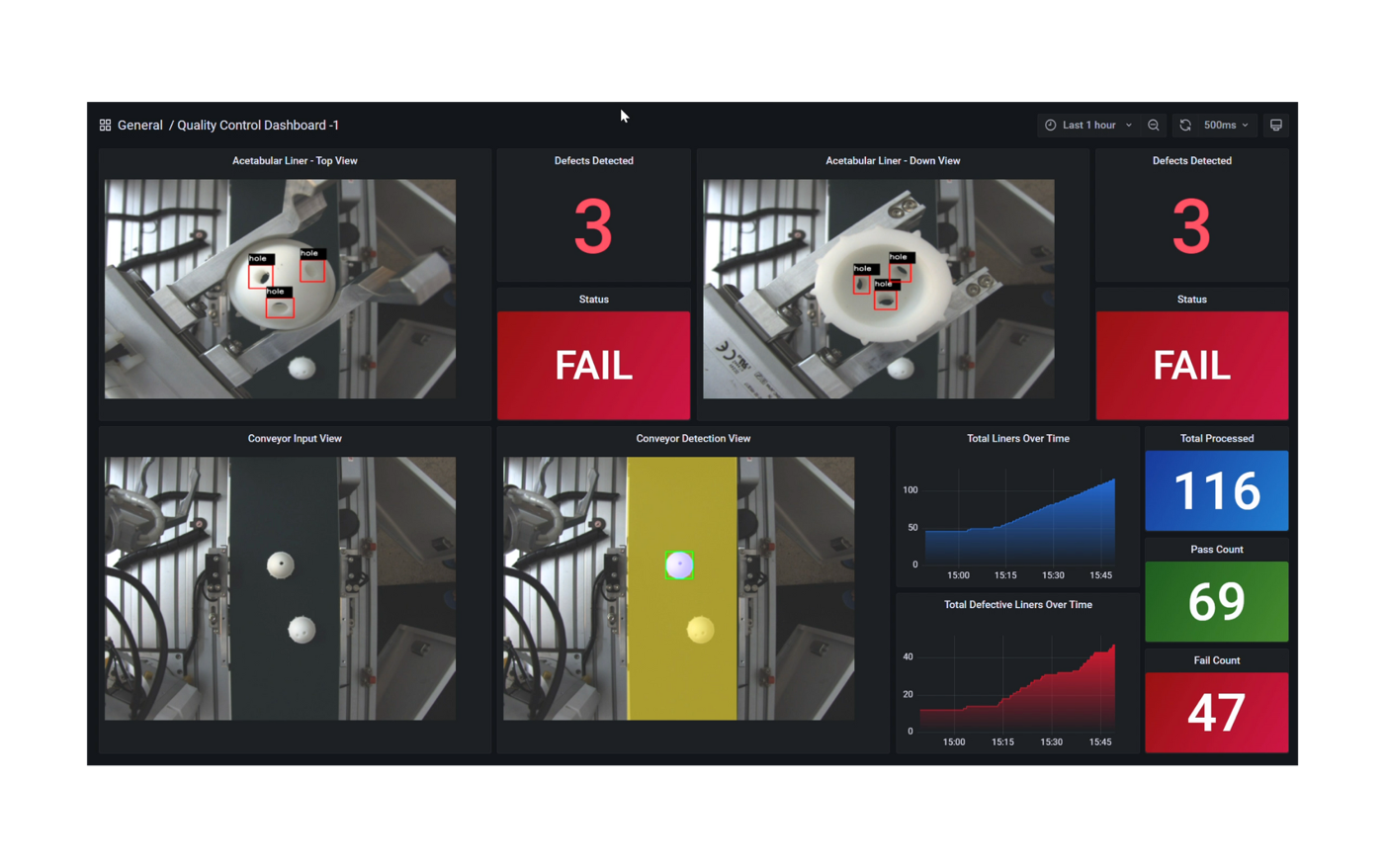
- Three defects have been detected on this acetabular liner. The robot arm will place it in the bucket for hip implants who did not pass the quality inspection.
Dashboards | Worker Safety
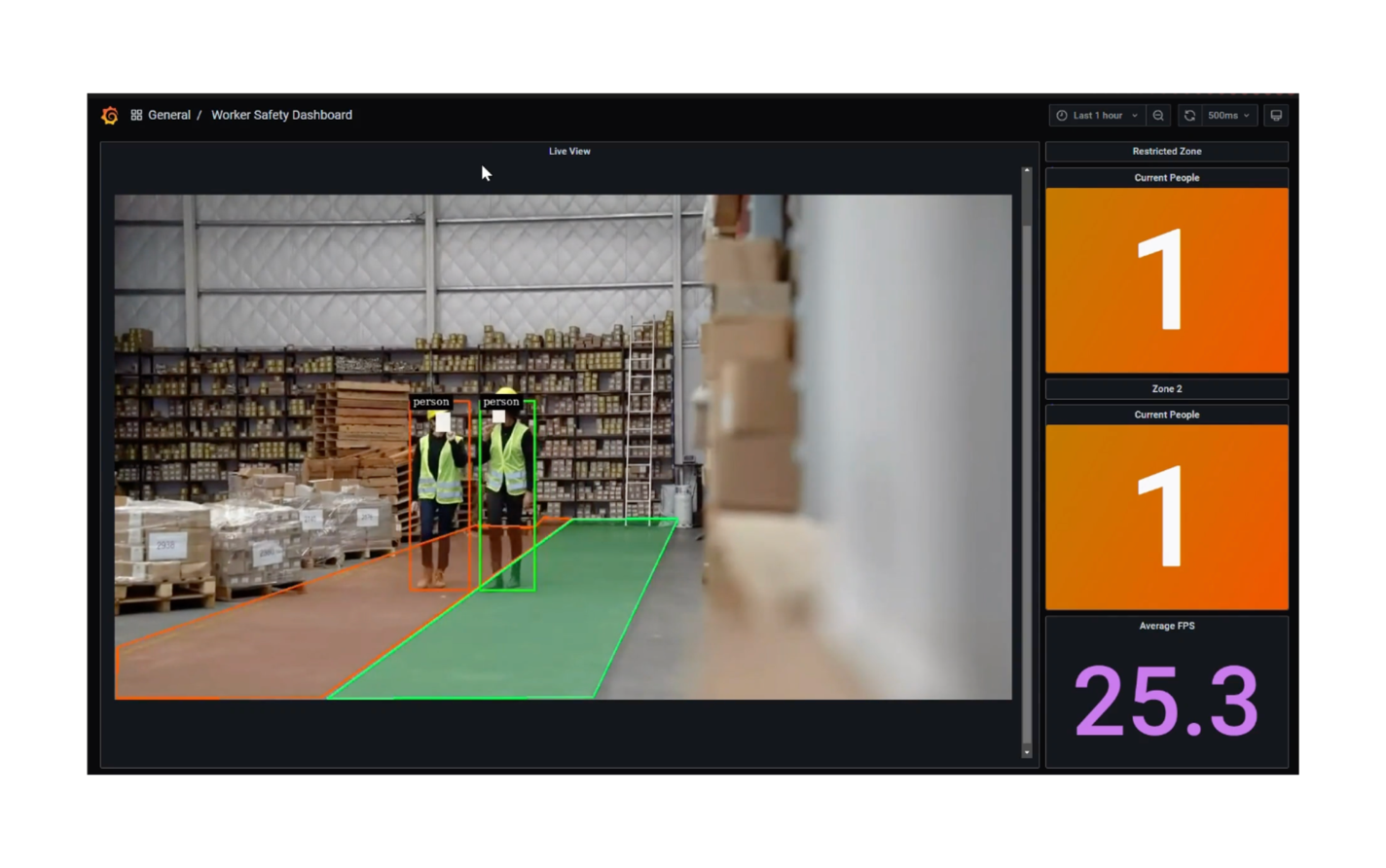
- One worker has been detected in the hazard zone triggering a worker safety notification.
| Integration of Dell™ PowerEdge™ XR7620 Server
Dell™ PowerEdge™ XR7620 server, designed to withstand harsh industrial conditions, houses two Intel® Xeon® Scalable Processors and two NVIDIA® A100 Tensor Core GPUs and KIOXIA SSDs within its 472mm chassis. Its ruggedized design, combined with NVIDIA® A100 GPUs offer powerful parallel processing capabilities, enables real-time analysis of 3D-printed components and rapid defect detection.
| Developed time saving on Dell™ PowerEdge™ XR7620 Server
By selecting the powerful Dell™ PowerEdge™ XR7620 server we are able to make this demonstration possible within a few months. Selecting a CPU or entry level GPU edge platform would have resulted in ~50% increase in development time for additional data labeling, training, custom API development, and post training optimization. This all would be required to reach our minimum latency requirement of sub 1.2 seconds for the object detection and defect detection models.
Note: ~50% time savings estimated based on engineering resources applied in development (~2000 hours) and estimated incremental time required to label, train, custom API development, and post training optimization (~2000 hours).
| Dell Technology™ World 23’
AI Driven Pop-Up Manufaturing Demo

| Conclusion
Our demo has potential implications in revolutionizing orthopedic implant manufacturing. The amalgamation of 3D printing, deep learning, and open programmable robots may provide a flexible, efficient, and affordable manufacturing solution for orthopedic components. The incorporation of Dell™ ruggedized PowerEdge™ XR7620 server and NVIDIA® powerful GPUs ensures reliable and real-time defect detection, proving essential in reducing production delays.
As our proof of concept gains further refinement, we anticipate its adoption in various other manufacturing domains, bringing in a new era of efficiency and precision.
About Scalers AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions for a wide range of industries, including retail, smart cities, manufacturing, and healthcare. The company is dedicated to helping organizations leverage the power of AI for their digital transformation. Scalers AI™ has a team of experienced AI developers and data scientists who are skilled in creating custom AI solutions for a variety of use cases, including predictive analytics, chatbots, image and speech recognition, and natural language processing.
As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads. Additionally, we also need advanced visualization libraries including the ability to render video in modern web application architectures.
| Fast track development with access to the solution code
Save hundreds of hours of development with the solution code. As part of this effort Scalers AI™ is making the solution code available.
Reach out to your Dell™ representative or contact Scalers AI™ at contact@scalers.ai for access.
Resources
- Reach out to your Dell™ representative or contact Scalers AI™ for access to the code!
This project was commissioned by Dell Technologies™ and conducted by Scalers AI, Inc.
Scalers AI™and Scalers AI™ logos are trademarks of Scalers AI, Inc.
Copyright © 2023 Scalers AI, Inc.
All rights reserved.
Other trademarks are the property of their respective owners.
Author:
Steen Graham CEO at Scalers AI™
Chetan Gadgil CTO at Scalers AI™
Delmar Hernandez, Server Technologist at Dell Technologies™
Manya Rastogi, Server Technologist at Dell Technologies™

Can CPUs Effectively Run AI Applications?
Fri, 03 Mar 2023 20:06:28 -0000
|Read Time: 0 minutes
Due to the inherent advantages of GPUs in high speed scale matrix operations, developers have gravitated to GPUs for AI training (developing the model) and inference (the model in execution).
With the scarcity of GPUs driven by the massive growth of AI applications, including recent advancements in stable diffusion and large language models that have taken the world by storm, such as ChatGPT by OpenAI, the question for many developers is:
Are CPUs up to the task of AI?
To answer the question, Dell Technologies and Scalers AI set up a Dell PowerEdge R760 server with 4th Gen Intel® Xeon® processors and integrated Intel® Deep Learning acceleration. Notably, we did not install a GPU on this server.
In this blog, Part One of a two-part series, we’ll put this latest and greatest Intel® Xeon® CPU just released this month by Intel® to the test on AI inference . We’ll also run AI on video streams, one of the most common mediums to run AI, and pair industry specific application logic to showcase a real-world AI workload.
In Part Two, we’ll train a model in a technique called transfer learning. Most training is done on GPUs today, and transfer learning presents a great opportunity to leverage existing models while customizing for targeted use cases.
The industry specific use case
Scalers AI developed a smart city solution that uses artificial intelligence and computer vision to monitor traffic safety in real time. The solution identifies potential safety hazards, such as illegal lane changes on freeway on-ramps, reckless driving, and vehicle collisions, by analyzing video footage from cameras positioned at key locations.
For comparison, we also set up the previous generation Dell PowerEdge R750 server and ran the AI inferencing object detection workload on both servers. What did we learn?
Dell PowerEdge R760 with 4th Gen Intel® Xeon® Processors and Intel® Deep Learning Boost delivered!
Let’s find out about the generational server comparison.
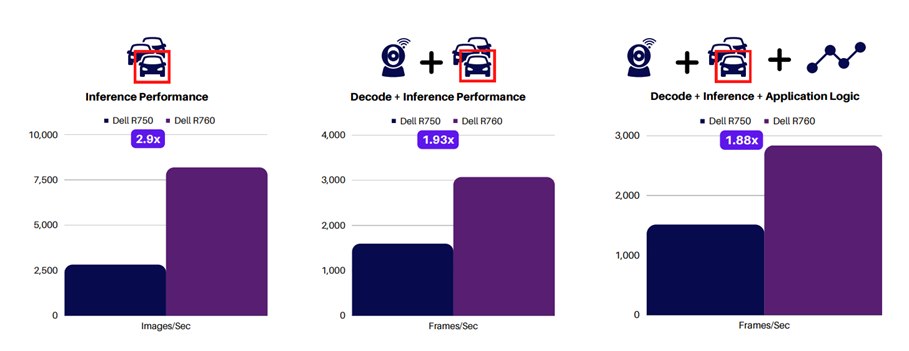
The following charts show the performance gain from the last gen to the current gen server. The graph on the left shows inference-only performance, while the middle graph adds video decode. Finally, the graph on the right shows the full application performance with the smart city solution application logic.
The performance claims are great. But what does this mean for my business?
Dell PowerEdge R760 and Scalers AI smart city solution results show that for a similar application, users can expect the Dell PowerEdge R760 server to perform real-time inferencing on up to 90 1080P video streams when it is deployed. Dell PowerEdge R750 can handle up to 50 1080P video streams, and this is all without a GPU. Although GPUs add additional AI computing capability, this study shows that they may only sometimes be necessary, depending on your unique requirements, such as how many streams must be displayed concurrently.
Given these results, Scalers AI confidently recommends using Dell PowerEdge R760 with 4th Gen Intel® Xeon® Processors and Intel® Deep Learning Boost for AI computer vision workloads, such as the Scalers AI Traffic Safety Solution using object detection, because they fulfill all application requirements.
Now that we have shown highly effective object detection on a CPU, what about a more compute-intensive complex model such as segmentation?
Here we are running segmentation on 10 streams, while displaying four streams on the more complex segmentation model.
As you can see, CPUs are up to the task of running AI inference on models such as object detection and segmentation. Perhaps more important for developers, they offer the flexibility to run the full workload on the same processor, thereby lowering the TCO.
With the rapid growth of AI, the ability to deploy on CPUs is a key differentiator for real-world use cases such as traffic safety. This frees up GPU resources for training and graphics use cases.
Check in for Part Two of this blog series as we discuss a technique to train a transfer learning model and put a CPU to the test there.
Resources
Interested in trying for yourself? Get access to the solution code!
To save developers hundreds of potential hours of development, Dell Technologies and Scalers AI are offering access to the solution code to fast-track development of AI workloads on next-generation Dell PowerEdge servers with 4th Gen Intel® Xeon® scalable processors.
For access to the code, reach out to your Dell representative or contact Scalers AI!
To learn more about the study discussed here, visit the following webpages:
• Myth-Busting:
Can Intel® Xeon® Processors Effectively Run AI Applications?
• Accelerate Industry Transformation:
Build Custom Models with Transfer Learning on Intel® Xeon®
• Scalers AI Performance Insights:
Dell PowerEdge R760 with 4th Gen Intel® Xeon® Scalable Processors in AI
Authors:
Steen Graham, CEO at Scalers AI
Delmar Hernandez, Server Technologist at Dell Technologies


Enhancing Satellite Node Management at Scale
Tue, 15 Mar 2022 20:30:40 -0000
|Read Time: 0 minutes
Satellite nodes are a great addition to the VxRail portfolio, empowering users at the edge, as described in David Glynn’s blog Satellite Nodes: Because sometimes even a 2-node cluster is too much. Although satellite nodes are still new, we’ve been working hard and have already started making improvements. Dell’s latest VxRail 7.0.350 release has a number of new VxRail enhancements and in this blog we’ll focus on these new satellite node features:
- Improved life cycle management (LCM)
- New APIs
- Improved security
Improved LCM
The first way we’ve improved satellite nodes is by reducing the required maintenance window. To do this, the satellite node update process has now been split in two. Instead of staging the recovery bundle and performing the update in one step, you can now stage the recovery bundle and perform the update separately.
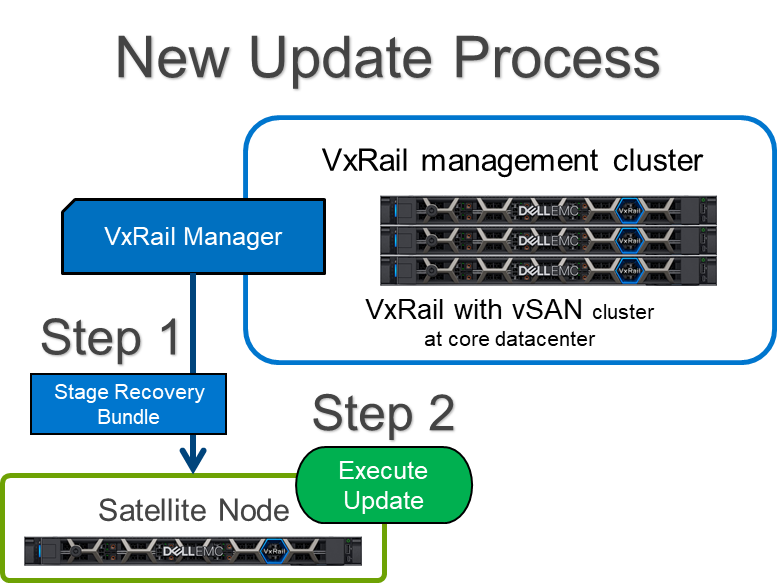
Staging the bundle in advance is great because we know bandwidth can be limited at the edge and this allows ample time to transfer the bundle in advance to ensure your update happens during your scheduled maintenance window. Once your bundles are staged, it’s as simple as scheduling the updates and letting VxRail execute the node update. This improvement ensures that you can complete the update within the expected timeframe to minimize downtime. Satellite nodes sit outside the cluster and, as a result, workloads will go offline while the node is updated.
New APIs
Do you have a large number of edge locations that could use satellite nodes and need an easier way to manage at scale? Good news! These new APIs are perfect for making edge life at scale easier.
The new APIs include:
- Satellite node LCM
- Add a satellite node to a managed folder
- Remove a satellite node from a managed folder
The introductory release of VxRail satellite nodes featured LCM operations through the VxRail Manager plug-in, which could be quite time consuming if you are managing a large number of satellite nodes. We saw room for improvement so now administrators can use VxRail APIs to add, update, and remove satellite nodes to simplify and speed up operations.
You can use the satellite node LCM API to adjust configuration settings that benefit management at scale, such as adjusting the number of satellite nodes you want to update in parallel. For example, although the default is to update 20 nodes in parallel, you can initiate updates for up to 30 satellite nodes in parallel, as needed.
There is also a failure rate feature that will set a condition to exit from an LCM operation. For example, if you are updating multiple satellite nodes at one time and nodes are failing to update, the failure rate setting is a way to abort the operation altogether if the rate surpasses a set threshold. The default threshold is 20% but can be set anywhere from 1% to 100%. Using the VxRail API, you can adjust settings like this that are not available in the VxRail Manager.
These new APIs are great for users with a large number of VxRail satellite nodes. Adding, removing, and updating satellite nodes can now be automated through the new APIs, saving you precious time across your edge locations.
Improved Security
VxRail satellite nodes can now use Secure Enterprise Key Management (SEKM), made available through the Dell PowerEdge servers that VxRail is built on. What is SEKM you might ask? Well, SEKM gives you the ability to secure drive access using encryption keys stored on a central key management server (not on the satellite node).
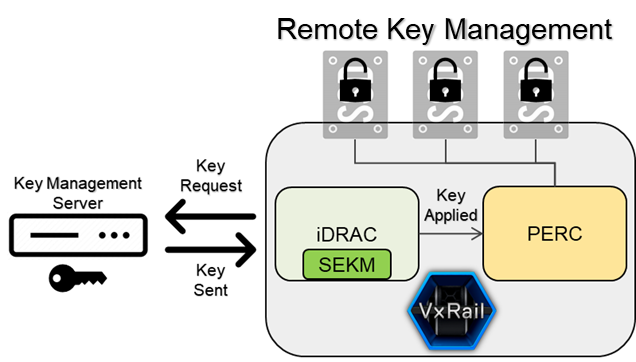
SEKM is great for many reasons. First, an edge location might be more exposed and have less physical security than your typical data center but that doesn’t mean securing your data is any less important. SEKM keeps your data drives locked even if the entire server is stolen. When paired with self-encrypting drives, you can secure the data even further. Second, the encryption keys are stored in a centralized location, making it easier to manage the security of large numbers of satellite nodes instead of having to manage each satellite node individually.
In this blog we’ve highlighted some exciting new satellite node features, including an improved update process, new APIs, and enhanced security, all of which enhance managing the edge at scale. Check out the full VxRail 7.0.350 release and see the full list of enhancements by clicking the link below.
Thanks for reading!
Resources
Author: Stephen Graham, VxRail Tech Marketing