
Prerequisites for installing SAP Data Intelligence 3.1
Prerequisites for installing SAP Data Intelligence 3.1
-
After a successful deployment of OpenShift Container Platform 4.6 and OpenShift Container Storage 4.6, some additional tasks are required to prepare the cluster for a deployment of SAP Data Intelligence 3.1. For details, see the Red Hat SAP Data Intelligence 3 on OpenShift Container Platform 4 knowledge base. Ensure that you note any recent changes and troubleshooting information in the knowledge base.
This section describes the main prerequisites for the installation.
Configuring the compute nodes
Some SAP Data Intelligence components require changes at the operating level of compute nodes, which might affect other workloads running on the same cluster. To avoid any impact, we recommend dedicating a set of nodes to the SAP Data Intelligence workload by:
- Labeling the chosen nodes for SAP Data Intelligence, for example, as node-role.kubernetes.io/sdi="".
- Creating configuration files called MachineConfigs that are specific to SAP Data Intelligence. The files will be applied only to the selected nodes.
- Creating a MachineConfigPool to associate the chosen nodes with the newly created MachineConfigs.
The following sections describe how to perform these operations.
Label the compute nodes for SAP Data Intelligence
Choose compute nodes for the SAP Data Intelligence workload and label them by running:
# oc label node/sdi-worker{1,2,3} node-role.kubernetes.io/sdi=""
Preload the required kernel modules
To apply the changes you want to the existing compute nodes, create another machine configuration file and run:
# oc create -f https://raw.githubusercontent.com/redhat-sap/sap-data-intelligence/master/snippets/mco/mc-75-worker-sap-data-intelligence.yaml
Change the maximum number of process identifiers (PIDs) per container
In SAP Data Intelligence, the required settings are:
.spec.containerRuntimeConfig.pidsLimit in a ContainerRuntimeConfig.
The result is a modified /etc/crio/crio.conf configuration file on each affected worker node, with pids_limit set to the desired value.
Create a ContainerRuntimeConfig by running:
# oc create -f https://raw.githubusercontent.com/redhat-sap/sap-data-intelligence/master/snippets/mco/ctrcfg-sdi-pids-limit.yaml
Associate the MachineConfigs to the nodes
Follow these steps:
- If workload=sapdataintelligence is associated to the worker MachineConfigPool, disassociate it by running the following command in bash:
# tmpl=$'{{with $wl := index $m.labels "workload"}}{{if and $wl (eq $wl "sapdataintelligence")}}{{$m.name}}\n{{end}}{{end}}'; \
if [[ "$(oc get mcp/worker -o go-template='{{with $m := .metadata}}'"$tmpl"'{{end}}')" == "worker" ]]; then
oc label mcp/worker workload-;
fi
- Create a MachineConfigPool to associate MachineConfigs to the nodes:
# oc create -f https://raw.githubusercontent.com/redhat-sap/sap-data-intelligence/master/snippets/mco/mcp-sdi.yaml
The nodes will inherit all the MachineConfigs targeting worker and sdi roles. The changes are rendered into machineconfigpool/sdi and the worker nodes are restarted one by one until the changes are applied to all of them.
- Run # oc get nodes
A new role sdi is assigned to the chosen nodes and a new MachineConfigPool containing the nodes is displayed, as shown in the following figures:
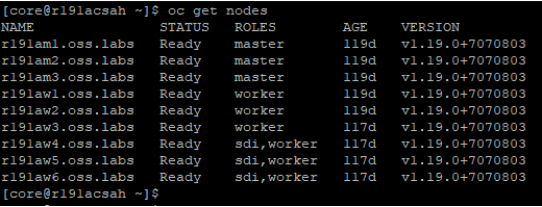
Figure 8. Viewing the updated names, status, and roles of all nodes
- Run # oc get mcp output
The MachineConfigPool nodes are displayed, as shown in the following figure:
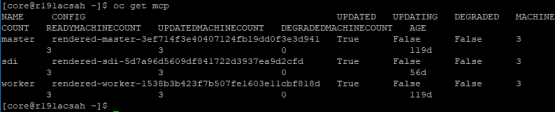
Figure 9. Viewing the updated MachineConfigPools status
Note: If the control-plane nodes will be used for running SDI workloads, the nodes must be schedulable and the machine config files must be duplicated to the nodes and inherit the process ID (PID) limits. For more information, see the Red Hat SAP Data Intelligence 3 on OpenShift Container Platform 4 knowledge base.
Configuring the S3 access keys and bucket
OpenShift Container Storage contains the NooBaa object data service. This object data service provides an S3 API to the object storage bucket that can be used with the SAP Data Intelligence solution. You must provide the following information:
- S3 host URL prefixed with https:// or http://
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- Bucket name
After deploying OpenShift Container Storage, create the access keys and bucket through the OpenShift CLI:
- Verify that the S3 service is available by running:
# oc get svc -n openshift-storage -l app=noobaa
The following output is displayed:

Figure 10. Confirming that the S3 service is available
Create an S3 bucket
To create the S3 bucket:
- Confirm the storage class name, for example, by running oc get sc.
The bucket can be stored in any OpenShift project, for example, sdi-infra.
- Switch to an appropriate project/namespace (such as sdi) and run:
# for claimName in sdi-checkpoint-store sdi-data-lake; do
oc create -f - <<EOF
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: ${claimName}
spec:
generateBucketName: ${claimName}
storageClassName: openshift-storage.noobaa.io
EOF
done
The object buckets are created, the claims are bound, and the secrets are created with the same names (in our example, sdi-checkpoint-store and sdi-data-lake) as the ObjectBucketClaim (obc). When it is ready, the obc will be bound.
- Run # oc get obc -w
The following output is displayed:

Figure 11. Bucket created
- To determine the name of the created bucket, run:
# oc get cm sdi-data-lake -o jsonpath='{.data.BUCKET_NAME}{"\n"}'

Figure 12. Name for the created bucket
- To determine the access keys, run the following command in bash:
# for claimName in sdi-checkpoint-store sdi-data-lake; do
printf 'Bucket/claim %s:\n Bucket name:\t%s\n' "$claimName" "$(oc get obc -o jsonpath='{.spec.bucketName}' "$claimName")"
for key in AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY; do
printf ' %s:\t%s\n' "$key" "$(oc get secret "$claimName" -o jsonpath="{.data.$key}" | base64 -d)"
done
done | column -t -s $'\t'
The following figure shows a sample output value:

Figure 13. Output value example
- Make a note of the values of sdi-checkpoint-store. These values are passed to the SLC Bridge parameters during the SAP Data Intelligence installation to enable the checkpoint store. The following table shows these parameters:
Table 9. SAP Data Intelligence credentials for the checkpoint store
Parameter
Sample value
Amazon S3 Access Key
2NI09x5X4T23N4YeqGCI
Amazon S3 Secret Access Key
xn1fozP9pOdLKYEBCb1c3NBtGhWn/D82JUlgXTq0
Amazon S3 bucket and directory
sdi-checkpoint-store-652fdcc8-1752-46f4-b7f9-05b4a2d2d79e
Amazon S3 Region (optional)
Leave empty