
Verifying the solution
Verifying the solution
-
You can use AI workloads that use GPU hardware acceleration to verify solution. Deploy AI workloads either as VMs or as Kubernetes pods.
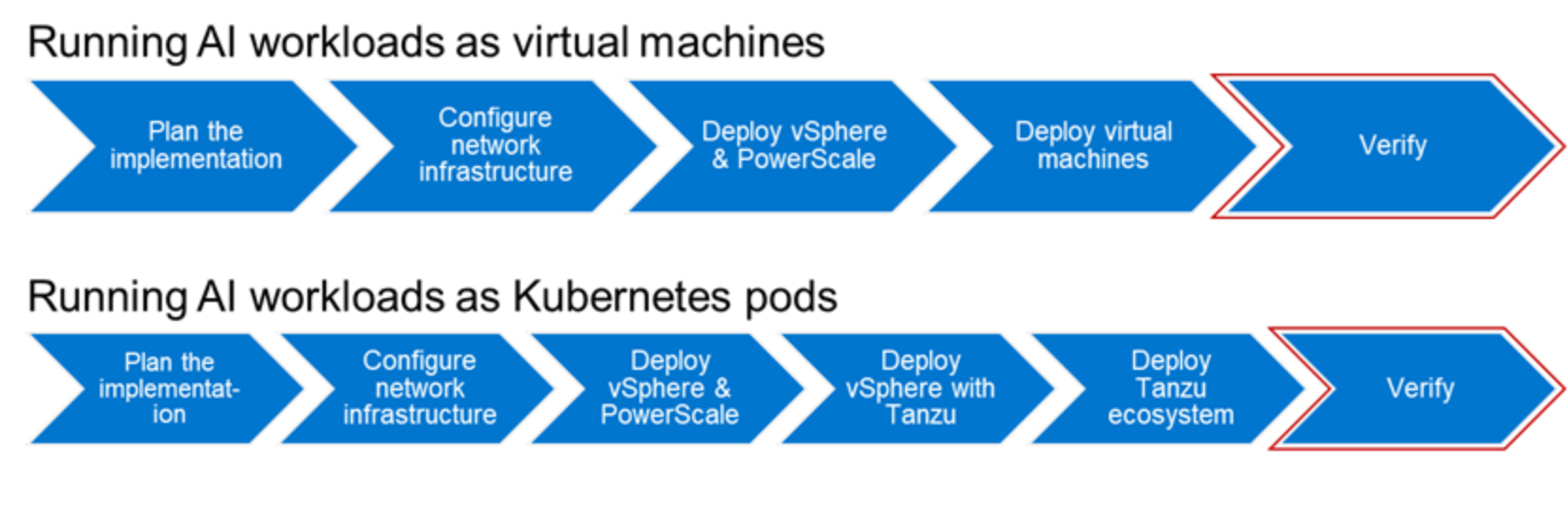
Verify the solution with an NVIDIA AI Enterprise Tensorflow container
To verify this validated design, you can use a Tensorflow container, which is available with NVIDIA AI Enterprise. You can use the same methodology to validate a single node as well as a multinode training configuration.
To verify the validated design:- Log in to the VM.
- Copy and paste the following content into a text file, which will be used to build the Docker container:
FROM nvcr.io/nvaie/tensorflow-1-1:21.08-nvaie1.1-tf1-py3
ARG DEBIAN_FRONTEND=noninteractiv
# Set MOFED version, OS version and platform
ENV MOFED_VERSION 5.5-1.0.3.2
ENV OS_VERSION ubuntu20.04
ENV PLATFORM x86_64
RUN pip3 install --user --upgrade pip && \
pip3 install --no-cache-dir absl-py
RUN apt-get update && \
apt-get install -y --allow-downgrades --allow-change-held-packages --no-install-recommends \
apt-utils build-essential cmake tcsh tcl tk \
make git curl vim wget ca-certificates \
iputils-ping net-tools ethtool \
perl lsb-release python-libxml2 \
iproute2 pciutils libnl-route-3-200 \
kmod libnuma1 lsof openssh-server \
swig libelf1 automake libglib2.0-0 \
autoconf graphviz chrpath flex libnl-3-200 m4 \
debhelper autotools-dev gfortran libltdl-dev \
dmidecode build-essential cmake git zip pciutils hwloc numactl \
dpatch bison pkg-config numactl dkms udev libnl-route-3-dev libnl-3-dev \
libmnl0 libmnl-dev expect-dev ncat \
usbutils iperf3 bc tree \
quilt \
landscape-common libpci-dev && \
rm -rf /var/lib/apt/lists/*
WORKDIR /workspace
RUN wget http://content.mellanox.com/ofed/MLNX_OFED-${MOFED_VERSION}/MLNX_OFED_LINUX-$MOFED_VERSION-$OS_VERSION-$PLATFORM.tgz && \
tar -xvf MLNX_OFED_LINUX-${MOFED_VERSION}-${OS_VERSION}-${PLATFORM}.tgz && \
MLNX_OFED_LINUX-${MOFED_VERSION}-${OS_VERSION}-${PLATFORM}/mlnxofedinstall --user-space-only --without-fw-update --force && \
tree /workspace/MLNX_OFED_LINUX-${MOFED_VERSION}-${OS_VERSION}-${PLATFORM}/
WORKDIR /workspace
RUN git clone -b cnn_tf_v1.15_compatible https://github.com/tensorflow/benchmarks.git
WORKDIR /workspace
RUN git clone https://github.com/NVIDIA/nccl-tests && \
cd nccl-tests && \
make MPI=1 MPI_HOME=/usr/local/mpi
WORKDIR /workspace
RUN git clone https://github.com/linux-rdma/perftest && \
cd perftest && \
./autogen.sh && \
CUDA_H_PATH=/usr/local/cuda/include/cuda.h ./configure && \
make install
WORKDIR /test
RUN rm -f ${_CUDA_COMPAT_PATH}/.*.checked
- Build the Docker Image:
sudo docker build -t singlenode:latest .
- Run the container, which opens a bash prompt:
sudo docker run -it --gpus=all --net=host --uts=host --ipc=host -v /mnt/ifs/programs/data_2_0:/mnt/ifs/programs/data_2_0 --ulimit stack=67108864 --ulimit memlock=-1 --shm-size=1g --name=mpicont --device=/dev/infiniband -v /home/test/.ssh/ssh_container:/root/.ssh singlenode:latest /bin/bash
- Start the benchmark test:
python /workspace/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=1 --batch_size=1024 --use_fp16 --model=resnet50 --variable_update=parameter_server --xla=True
The following sample output of the benchmark test is displayed after the initial log messages:
Step Img/sec total_loss
1 images/sec: 2811.1 +/- 0.0 (jitter = 0.0) 7.908
10 images/sec: 2809.7 +/- 1.7 (jitter = 2.6) 7.828
20 images/sec: 2808.1 +/- 1.2 (jitter = 4.0) 7.781
30 images/sec: 2808.1 +/- 0.9 (jitter = 2.9) 7.758
40 images/sec: 2807.2 +/- 0.8 (jitter = 3.7) 7.758
50 images/sec: 2805.8 +/- 0.9 (jitter = 5.0) 7.680
60 images/sec: 2804.1 +/- 1.0 (jitter = 5.1) 7.627
70 images/sec: 2802.7 +/- 1.1 (jitter = 6.3) 7.620
80 images/sec: 2802.0 +/- 1.0 (jitter = 7.2) 7.580
90 images/sec: 2801.2 +/- 0.9 (jitter = 8.2) 7.534
100 images/sec: 2800.7 +/- 0.9 (jitter = 9.2) 7.521
----------------------------------------------------------------
total images/sec: 2800.37
Verify the solution with the NVIDIA NGC catalog
To verify this validated design, use the DeepStream - Intelligent Video Analytics Demo that is available in the NVIDIA NGC catalog.
The DeepStream SDK delivers a complete streaming analytics toolkit for real-time AI-based video and image understanding and multisensor processing. It features hardware-accelerated building blocks (called plugins) that bring deep neural networks and other complex processing tasks into a stream processing pipeline. The SDK enables you to focus on building core deep learning networks and intellectual property rather than designing end-to-end solutions from scratch.
To run the DeepStream demo to validate the solution:
- From the workstation that is configured to use the recently deployed Tanzu Kubernetes cluster as a helm context, deploy the Intelligent Video Analytics Demo with integrated Video and WebUI:
helm fetch https://helm.ngc.nvidia.com/nvidia/charts/video-analytics-demo-0.1.7.tgz
helm install video-analytics-demo-0.1.7.tgz
- View the video output.
From a browser, use the following WebUI URL to access the DeepStream application:
http://<IPAddress of node:31115>/WebRTCApp/play.html?name=videoanalytics

Figure 10. Video Analytics Demo running on Tanzu Kubernetes cluster
- Run the nvidia-smi command on the container to verify that the video analytics demo uses the GPU, as shown in the following figure:
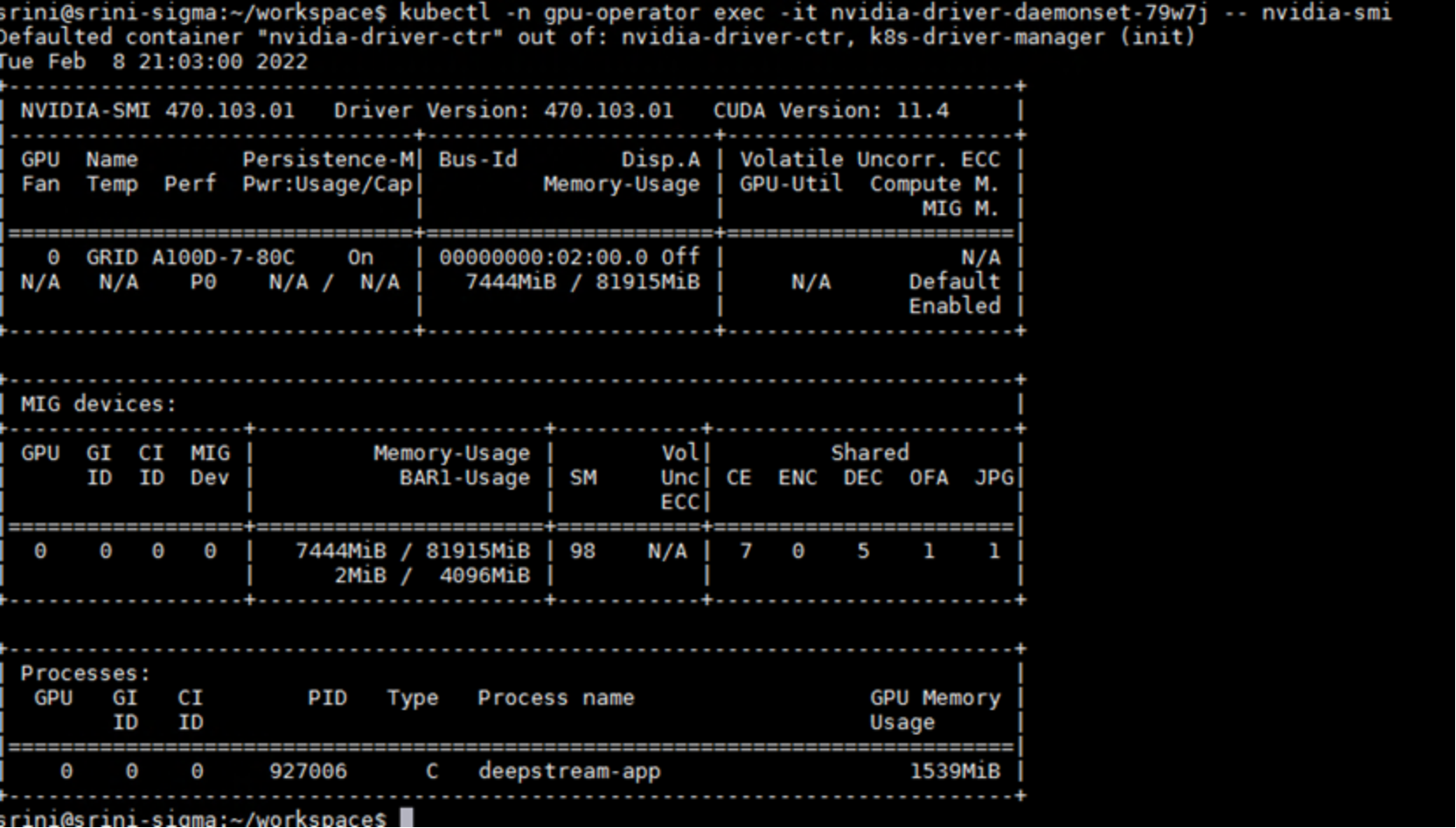
Figure 11. Verifying GPU use for video analytics demo