
Digital Assistant with Red Hat OpenShift AI on Dell APEX Cloud Platform for Red Hat OpenShift
Digital assistant design
Digital assistant design
-
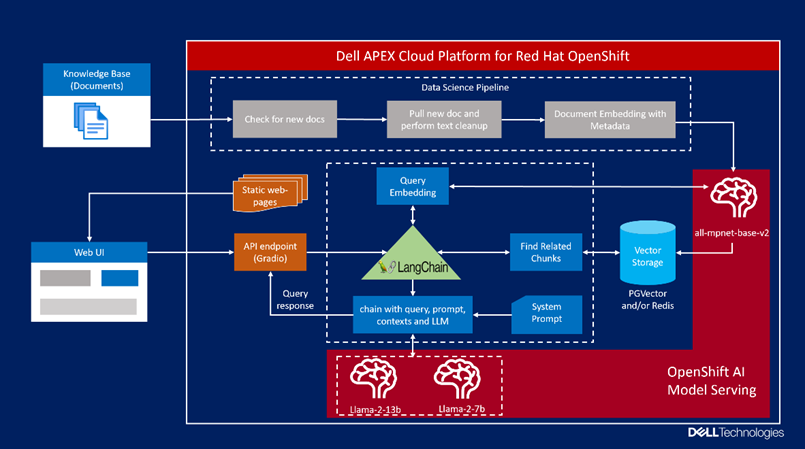 Figure 2. Digital assistant design
Figure 2. Digital assistant designThe following list outlines digital assistant components and workflow.
- Data ingestion: The data science pipeline is leveraged to ingest data, which is created and scheduled to run at specific intervals. This pipeline discovers any new files, extracts text, performs data cleanup, stores metadata, and embeds data into the PGVector database.
- Model serving: Red Hat OpenShift AI includes a single model serving platform that is based on KServe to serve LLMs. KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. vLLM is used as the serving runtime in our solution to serve the Llama 2 model. Serving LLM models can be surprisingly slow, even on expensive hardware. vLLM serving runtime is a fast and easy-to-use LLM inference engine that can help overcome this challenge using its high-throughput LLM serving architecture with efficient memory management enabled by PagedAttention. It natively supports Llama 2 model and does not require weights to be converted to specific format. PagedAttention is a new attention algorithm that allows attention keys and values to be stored in non-contiguous paged memory. The Llama 2 model weights and configuration files copied from the Hugging Face repository and stored in Dell ObjectScale. Storing the models in object storage provides the capability of model versioning and eliminates the need of maintaining multiple copies locally.
- Query processing: When users submit a query, the query will first be converted to vector embedding. Embedding is a process of converting text chunks to a fixed sized vector. Semantic search is then performed for the query embedding against the knowledge base vector embeddings stored in PGVector database. Results from PGVector are ranked and sent to the Llama 2 model along with predefined system prompts, the Llama model generates the response based on retrieved context from PGVector and its pretrained capabilities.
- User interface: Chatbot is a popular interface used to interact and work with LLMs. We implemented the chatbot interface as the digital assistant. This was built using Gradio framework. The user interface provides multiple functionalities and controls to change the digital assistant behavior to get the relevant and accurate response grounded to the knowledge base.