
cnvrg.io on VMware Tanzu
cnvrg.io on VMware Tanzu
-
The cnvrg.io MLOps platform is delivered on Validated Design for AI with VMware and NVIDIA, which includes Dell Technologies infrastructure, VMware vSphere with Tanzu, NVIDIA GPUs, and NVIDIA AI Enterprise. This validated design is a virtualization platform that enables an enterprise to manage clusters of both on-demand Kubernetes containers alongside traditional virtual machines, providing complete life cycle management of those compute and storage resources.
See the following documentation for more information about the Validated Design for AI using VMware and NVIDIA:
- White paper, which details how enterprises can run AI workloads alongside existing applications in data centers without compromising performance
- Design guide, which describes the reference architecture of the Validated Design for AI, which was designed in collaboration with VMware and NVIDIA
- Implementation guide, which describes the implementation for the Validated Design for AI.
The following figure shows how cnvrg.io is deployed on these components:
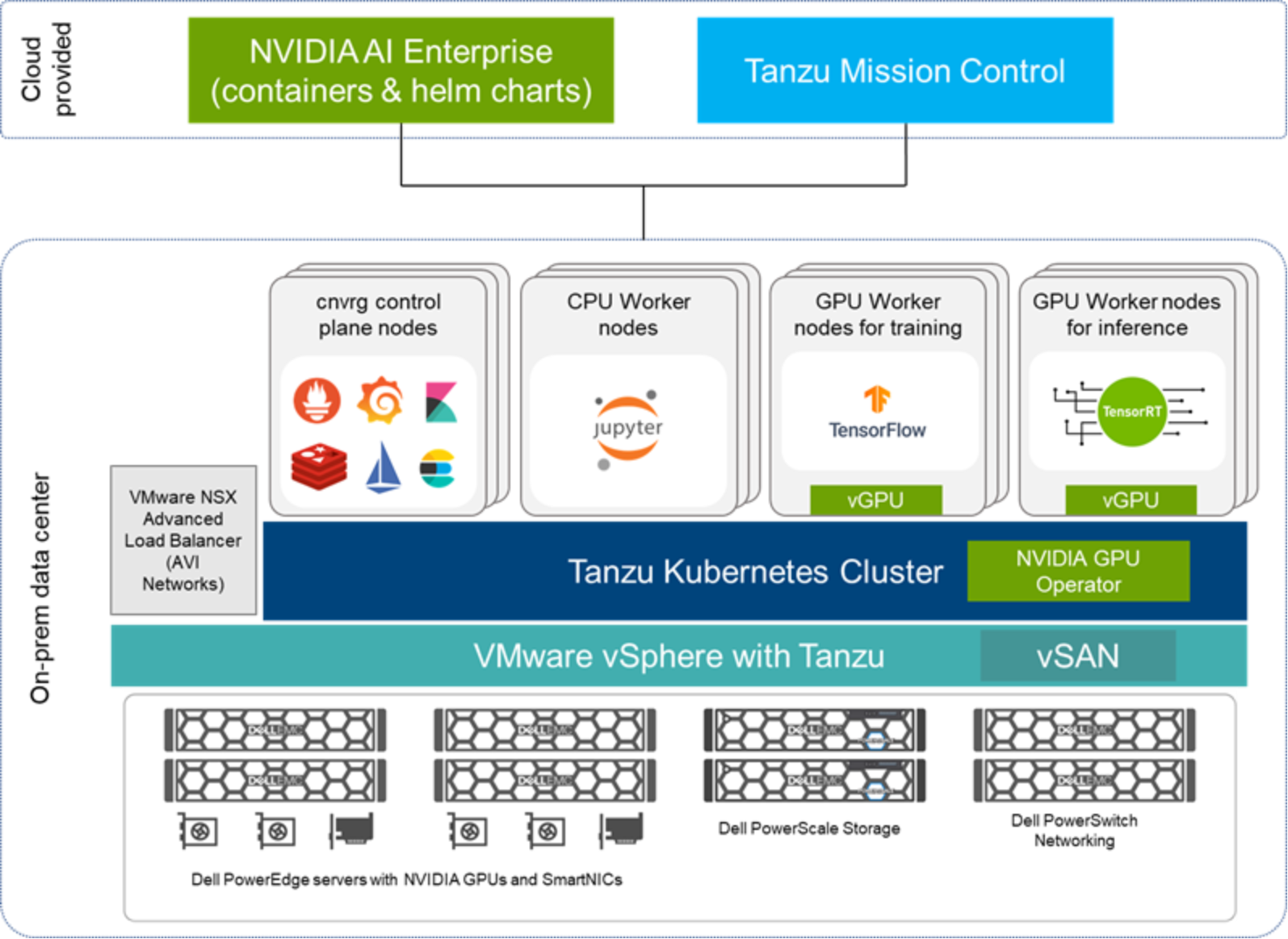
Figure 3. Solution architecture for cnvrg.io on VMware vSphere with Tanzu
PowerEdge servers or the VxRail HCI Appliance provide compute resources for the AI workloads and pipelines deployed on cnvrg.io. The PowerEdge servers can be optionally configured with NVIDIA GPUs to support acceleration for neural network training and inference. PowerScale provides storage for the data lake—the data repository for unstructured data that you can use for neural network training. Isilon F800 All-Flash Scale-out NAS storage is ideal, delivering the analytics performance and extreme concurrency at scale to consistently feed the most data-hungry DL algorithms. PowerSwitches are used for network connectivity and out-of-band (OOB) connectivity.
These PowerEdge servers are configured with VMware vSphere with Tanzu to enable creation of Tanzu Kubernetes clusters, which can be managed by Tanzu Mission Control. Servers running VMware vSAN provide a storage repository for the VM and pods.
NVIDIA AI Enterprise and its GPU operator provide automated deployment of NVIDIA software components required for the GPUs. Using the MIG capability of the NVIDIA GPUs, administrators can create vGPU profiles and assign them to Kubernetes worker nodes. Using cnvrg.io, these nodes can run various workloads such as TensorFlow for training, Jupyter notebooks for interactive model development, and TensorRT for inference.
NVIDIA AI Enterprise provides fully validated and supported AI frameworks that are made available as containers and can be integrated into the cnvrg.io catalog.
Worker pods
ML workloads run as worker pods. Worker pods are categorized. Each category of worker pods is associated with specific types of Kubernetes worker nodes that have a specific hardware resource configuration, such as the type of GPU configured in each worker node. The categories of worker pods include:
- CPU worker pods include workers that can be used for AI workloads that do not require GPUs. AI workloads consist of all the stages of an AI model, such as model development, training, and inference. Examples of these workloads include liner regression, statistical models, or data exploration. The worker nodes associated with these pods are not configured with any GPUs resources. The number of worker nodes depends on the number of cnvrg.io projects that run such workloads.
- GPU model development worker pods include pods that can be used for AI model development that requires a GPU for acceleration. These pods can be associated with smaller clusters of worker nodes with a GPU. They can be used for building an ML model, running quick proofs of concept, and building an ML pipeline. The worker nodes associated with the node pool consist of medium GPU MIG partitions.
- GPU training worker pods are used for training complex neural network models that require accelerated resources and scalable performance. Examples of such workloads include training convolutional neural networks for image classification. The worker nodes associated with the node pool consist of high-performance worker nodes with full GPUs allocated and are used for training.
- GPU Inference pods are used to deploy the model and serve API end points for prediction when the model is trained. The worker nodes associated with the node pool consist of small GPU MIG partitions.
Pod affinity to worker nodes
As described earlier, each category of worker pods is associated with a specific type of Kubernetes worker node using node pools. We constrain certain pods to run only on a set of nodes (pools) using “node labels.” Node labels in Kubernetes are key/value pairs that are attached to nodes. Pods are then constrained to run using “nodeSelector.” The nodeSelector field is added to the pod specification to specify the node labels that you want the target node to have. Kubernetes only schedules the pod onto nodes that have the labels that you specify.
The following node pools can be created by manually assigning node labels to the corresponding worker nodes:
- CPU worker node pool
- GPU model development node pool
- GPU training node pool
- GPU inference node pool
Data scientists can specify node labels when creating compute templates that will be used for their project or workspace.
Administrators can also manually configure the control plane pods with corresponding node labels to constrain the control plane pods to run only on certain nodes (control plane node pool). However, this option is beyond the scope of this design guide. This validated design relies on the Kubernetes scheduler to automatically place the cnvrg.io control plane pods on worker nodes based on resource availability.
For smaller deployments, some of these node pools, such as the GPU model development and GPU training node, can be combined. Alternatively, we can avoid creating node pools for certain pods (CPU worker pods) and let the Kubernetes scheduler automatically place the pods (for example, spreading your pods across nodes without placing pods on a node with insufficient free resources).
Cluster configuration and VM classes
To better use the resources and make them available to AI workloads, we recommend creating multiple node pools in the Tanzu Kubernetes Cluster. Using node pools provides a way to improved use of CPU and GPU resources and simplify management. Each node pool has nodes (or workers) with a specific CPU, memory, and GPU resource allocation. These resources are configured through a VM class. The node pools can then be associated with cnvrg.io workspaces through node labels in the compute templates. The following figure shows the configuration:
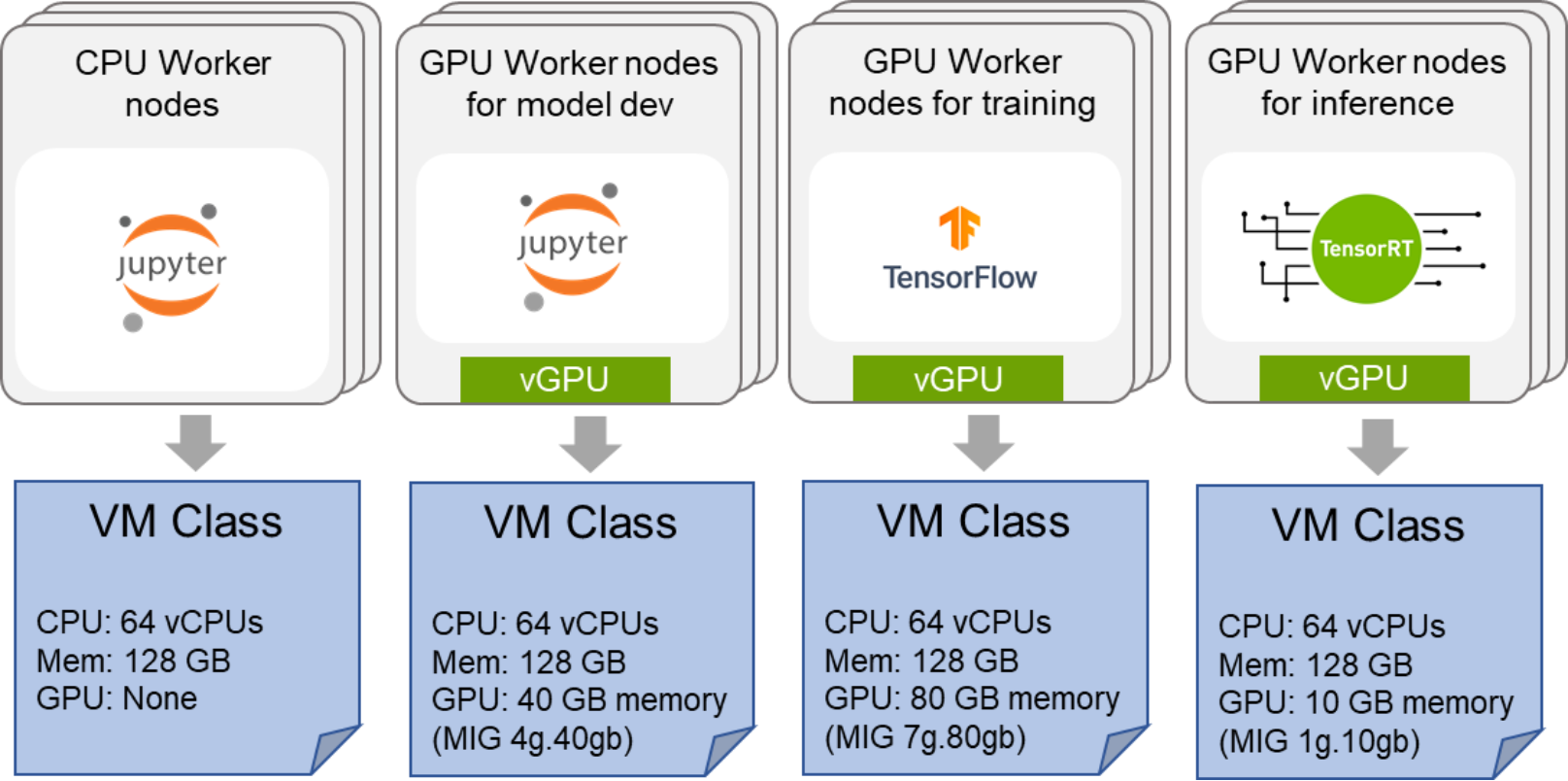
Figure 4. Multiple-node pool configuration with associated VM classes
When assigning GPU resources to a VM class using MIG profiles, specify the memory size associated with that MIG profile. The following table shows the recommended VM classes for a cnvrg.io deployment, which is a vSphere with Tanzu specific instance of Table 3.
Table 4. Recommended sizing of different worker node configurations in a Tanzu Kubernetes cluster using VM Classes
VM Class for worker node
Number of vCPUs
vMemory (in GB)
GPU Count, GPU Memory (Per VM)
CPU-only
64
128
None
GPU-train-medium
24
96
GPU-train-large
48
96
1 GPU, 80 GB
GPU-infer-small
16
32
1 GPU, 10 GB
GPU-infer-medium
16
32
1 GPU, 20 GB
We recommend creating a Tanzu Kubernetes cluster with three Kubernetes control plane nodes.
Recommended server configurations for CPU-only
The design guide for the Validated Design for AI using VMware and NVIDIA provides recommended configurations that use NVIDIA GPUs. Additionally, a CPU-only configuration can be used for cnvrg.io deployments that do not require hardware acceleration for neural network training.
The following table provides the recommendation for a CPU-only configuration:
Table 5. Recommended configurations for the CPU-only Validated Design
Configuration
CPU-only configuration
Compute server
PowerEdge R750 or VxRail P670F
Server configuration
- Processor: 2 Intel Xeon Platinum or Gold processors
- Memory: 512 GB or higher
- Network adapter: ConnectX-6 Lx 25 GbE
- Internal storage for ESXi: BOSS controller card with 2 M.2 Sticks 480 GB (RAID 1)
- Storage and hard drive configuration:
- Storage controllers: HBA 330,
- Cache tier: 2 x 800 GB SSD SAS Write Intensive, and
- Capacity tier: 12 x 960 GB SSD SAS Read Intensive
Number of nodes in a cluster
Minimum of 3 hosts; 4 ESXi hosts are recommended when using vSAN for resiliency during updating and upgrading
Network switch
2 x Dell S5248F-ON
OOB switch
1 x Dell PowerSwitch N3248TE-ON or 1 x Dell PowerSwitch S4148T-ON
VMware vSphere
- VMware vSphere 7.0 U3c or later
- VMware vSphere with Tanzu (Required for container orchestration)
Recommend edition: Standard
Storage
- vSAN for VM storage
- PowerScale all flash (F200, F600, F800) or hybrid nodes (H400, H500, H600, H5600) for data lake
Network configuration
The Validated Design for AI using VMware and NVIDIA has two options for network architecture: 25 GbE-based design and 100 GbE-based design. For deploying cnvrg.io, we recommend the 25 GbE-based design with PowerSwitch network switches. This network design is suited for neural network training jobs that can run on a single node (using at most two GPUs), and for model development and inference jobs that take advantage of GPU partitioning. Because we do not support multi-GPU training in this release, a 100 GbE-based network is not required.
In this validated design, we use VMware NSX Advanced Load Balancer as the ingress controller and load balancer.
Storage architecture
vSAN is the recommended storage for VMs that serve as the Tanzu Kubernetes Cluster control plane nodes and worker nodes. vSAN automatically creates a default Storage Class through the vSAN Container Storage Interface (CSI) driver. When cnvrg.io is deployed, vSAN is used for pods storage and Docker images. cnvrg.io application data is stored as persistent volumes in vSAN. Also, datasets imported to cnvrg.io are also hosted on vSAN.
We recommend PowerScale storage for data lake storage, that is, storing data that are required for neural network training. PowerScale storage can also be used for NFS caching for datasets. Local NFS cache can save time when working with large datasets pulled from an external object-storage. The data is saved to an NFS server accessible to the Kubernetes cluster."
The following figure illustrates the storage configuration for this validated design:
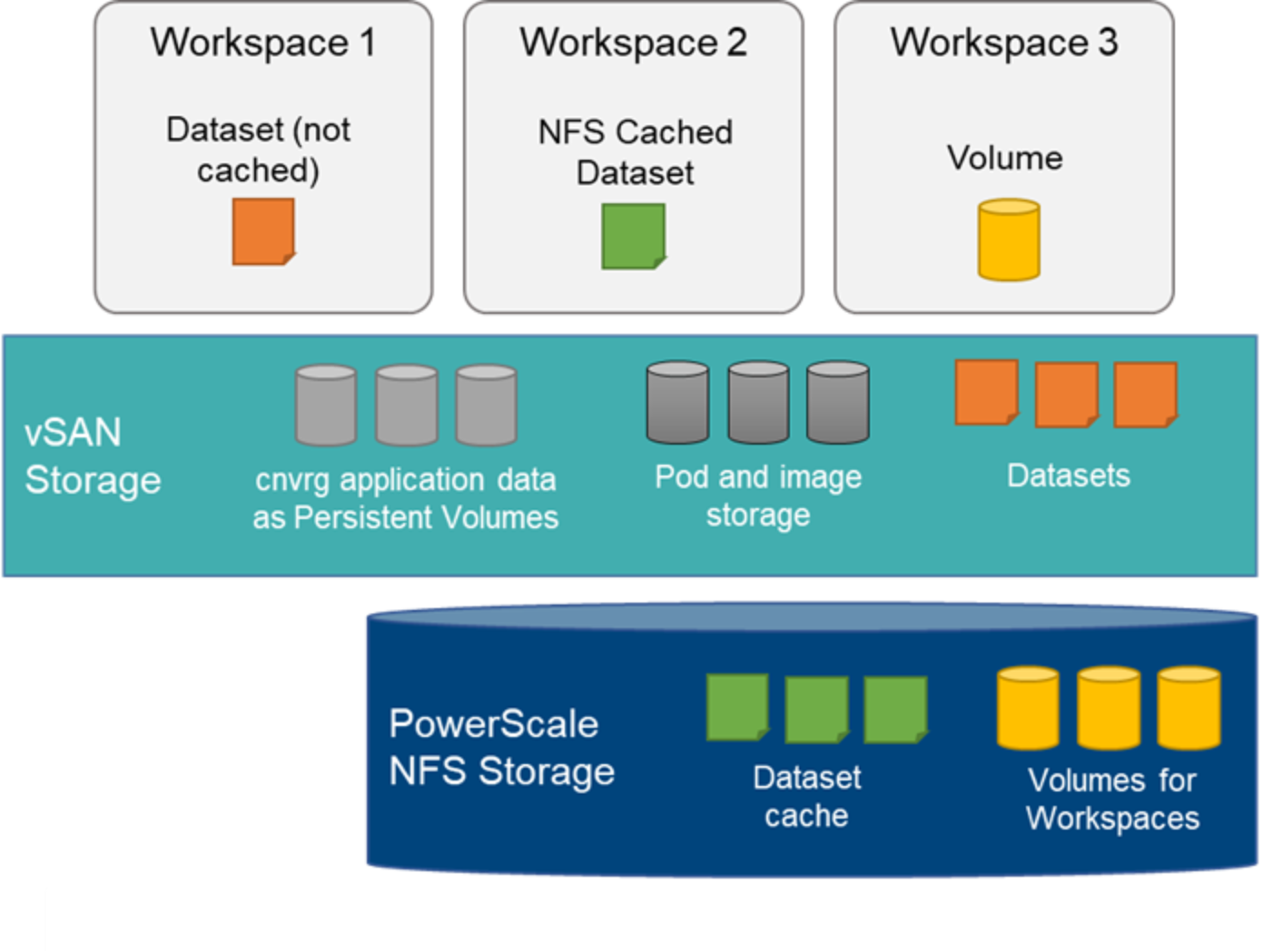
Figure 5. cnvrg.io storage configuration with vSAN and PowerScale
Sizing considerations
We recommend creating different types of worker nodes in a Tanzu Kubernetes Cluster to support the templates described in Table 2. Worker nodes that have the same configuration are grouped as node pools and are assigned a particular node label.
The following table provides the recommended sizing for different worker node configurations in a Tanzu Kubernetes cluster:
Table 6. Recommended sizing for node configurations
Worker node configuration
Number of CPU cores
Memory (in GB)
NVIDIA GPU profile for A100 80 GB
CPU-only
64
128
No
GPU-train-medium
24
96
grid_a100d-3-40c
GPU-train-large
48
96
grid_a100d-7-80c
GPU-infer-small
16
32
grid_a100d-1-10c
GPU-infer-medium
16
32
grid_a100d-2-20c
Note that a CPU-only worker node can host multiple CPU-only compute templates. However, each of the GPU worker nodes described in the preceding table can host only one GPU-based compute template. The number of CPU cores and memory allocated to a worker node is more than what is available to the compute template to ensure that enough compute resources are available for system processes such as GPU operators, Kubernetes management pods, and cnvrg.io management pods.