
AI workloads are broken into three different aspects:
- Training—Sustained “elephant or long,” bursty, and nonlatency-sensitive traffic flows that take place in large clusters with predictable traffic patterns.
- Fine-tuning—Smaller-scale training.
- Inferencing—Latency-sensitive and unpredictable traffic patterns.
These AI workload aspects make it computationally intensive, involving large and complex models such as Large Language Models (LLMs) and Deep Learning Recommendation Models (DLRMs).
These models have led to the need of distributed computing, involving the distribution of workloads across multiple interconnected computing resources through a lossless, high-performance, and scalable network. As a result, a new type of network is needed.
In an AI environment, the network or fabric is divided into three fabrics:
- Front-End Fabric
- Out-of-Band Management Fabric
- Back-End Fabric
The front-end fabric supports non-GenAI or general application traffic, storage access, and connection to the general network. This front-end fabric usually consists of 25/100 Gigabit Ethernet (GE) connections. Furthermore, it is worth mentioning that Ethernet is the default network connectivity technology used for all front-end fabrics.
The out-of-band management fabric supports network administration and fabric management. This fabric consists of 1/10GE connections.
The back-end fabric has the most performance-demanding characteristics as it must provide high-performance, lossless, low-latency, and scalable behavior as the backbone of AI workloads. This fabric consists of 400GE and higher connections.
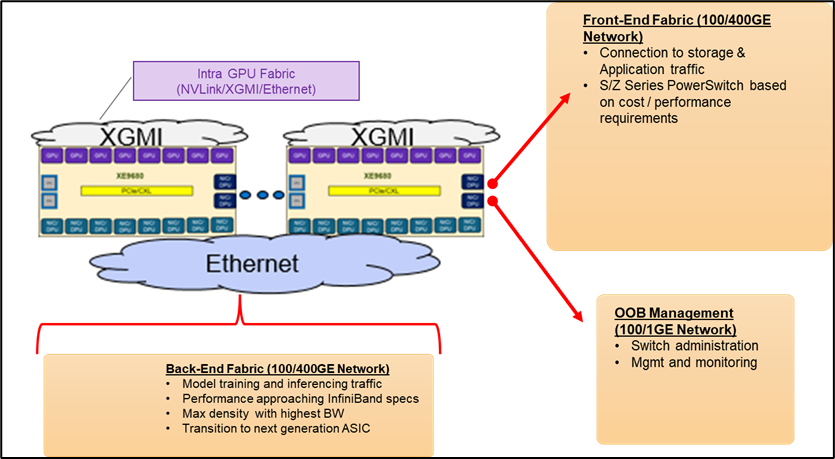
Within the fabric, two types of GPU-to-GPU communication take place: Intra-GPU and Inter-GPU.
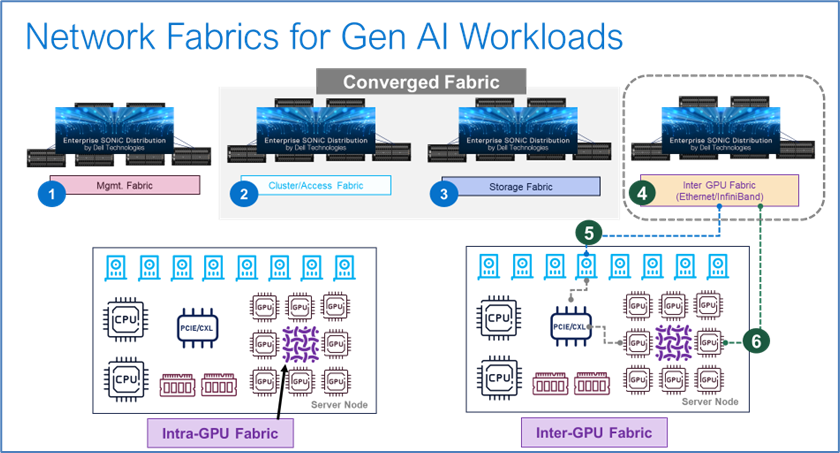
Intra-GPU refers to GPU-to-GPU communication within the same node, whereas inter-GPU refers to GPU communication across different nodes.
There are two forms of communication in an inter-GPU scenario. The first scenario takes place over the PCIe interface and NIC card to the fabric (see number 5 in Figure 7). The second scenario takes place using the embedded GPU NIC card to the fabric (see number 6 in Figure 7).
The network fabric becomes relevant in the inter-GPU scenario.