
MongoDB overview
MongoDB overview
-
MongoDB is a modern NoSQL database that uses a document-based data model to store both structured and unstructured data. It is highly scalable and can process massive amounts of data efficiently. A MongoDB database can scale up to hundreds of systems with petabytes of data distributed across them. With a modern database architecture comes the need for modern storage and application-driven infrastructure that is engineered to optimize and consolidate existing and new business use cases. The PowerStore storage platform is an ideal choice for MongoDB, offering advanced capabilities and scalability.
MongoDB is engineered with replica sets to increase data availability and fault tolerance of the MongoDB servers. Full copies of the data are replicated to multiple secondary members. A single replica set supports up to 50 members. Using a larger number of replicas increases data availability and protection. It also provides automatic failover of the primary member during planned or unplanned events such as server updates, server failures, rack failures, data-center failures, or network partitions. Replicating the data to a different server in a different data center further increases data availability and data locality for distributed clients. However, having too many replica members can lead to lower storage efficiencies, higher network-bandwidth usage, and increased management complexities. PowerStore can alleviate these challenges with its integrated data reduction feature, the embedded hypervisor on PowerStore X brings applications closer to storage, and tight integration of the storage platform and VMware virtualization environment.
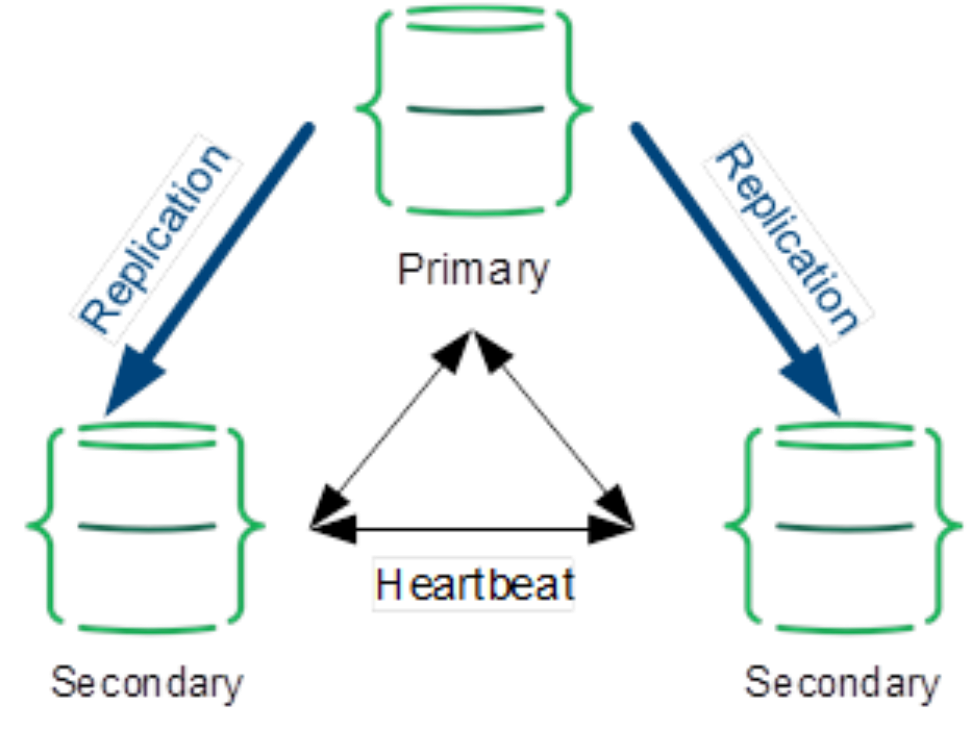
Figure 1. A three-member MongoDB replica set
By default, the primary member is responsible for the write and read operations for the replica set. The clients can specify a read preference to send read operations to the closest secondaries also. You can also configure a data-bearing member (a primary or secondary member but not an arbiter) to be hidden and serve as a backup copy if needed.
As the workload grows, the primary or secondary members must be able to scale their processing capacity by adding CPU, memory, or storage. In a read-oriented workload, more secondaries, each with a full copy of data, might be required. To increase the data durability and to avoid data from being rolled back when a primary member fails over, you can specify a write concern with a value of majority and enable journaling on all voting members. The write concern specifies how many members must acknowledge the write operations before it is considered to be successful. Starting in MongoDB 5.0, the implicit default write concern is ‘majority’ for most configurations. MongoDB determines the default write concern using a specific formula. See the MongoDB documentation for details. When the write concern is set to ‘majority’, MongoDB calculates the required number of received acknowledgments from the data-bearing voting members. WiredTiger journaling preserves all data modifications on disk between checkpoints to guarantee write operation durability. When MongoDB fails between checkpoints, it uses the journal logs to replay the changes since the last checkpoint. Journaling is required for replica set members that use the WiredTiger storage engine starting in MongoDB 4.0.
Building a flexible scale-out distributed database architecture
With large datasets and high-throughput environments, MongoDB uses the sharding process to distribute data across multiple systems to increase storage capacity, throughput, and performance. A sharded cluster consists of three components:
Shards hold a subset of the data and are deployed as a replica set.
Mongos process communications with the config servers and route the client requests to the appropriate shards.
Config servers store the metadata for the cluster configuration settings.
The config servers are deployed as a replica set. In a non-sharded database, there is only one primary member in a replica set that is responsible for write operations. However, in a sharded cluster, each shard can perform write operations respective to its dataset.

Figure 2. A MongoDB sharded cluster
Modern pluggable storage platform engines
MongoDB supports a wide variety of traditional and business-critical workloads including both operational and real-time analytics workloads. The MongoDB pluggable storage architecture extends new capabilities to the storage platform depending on the different workloads. These storage engines are responsible for storing the data and specify how the data is stored. Starting with version 4.2, MongoDB supports various storage engines including the WiredTiger storage engine, the in-memory engine, and the encrypted storage engine. The MMAPv1 storage engine was deprecated in version 4.2.
The WiredTiger storage engine is the default and preferred storage engine for most workloads. It persists data on disk and provides features such as a document-level concurrent model, journaling, checkpoints, and compression.
The in-memory storage engine stores the dataset in the memory to reduce data-access latency but does not persist data on disk. It is available only in the MongoDB Enterprise Edition.
The encrypted storage engine is the native encryption option for the WiredTiger storage engine. It provides encryption at rest and is only available in the MongoDB Enterprise Edition.
It is possible to mix the different engines based on the use case in the same replica set. This capability allows you to optimize and meet the needs of specific application requirements in a way that benefits the specific engines. For example, you can combine the in-memory engine for ultralow latency operations with the WiredTiger engine for on-disk persistence.