
Failure considerations
Failure considerations
-
Servers, processes, and network links periodically fail, so we performed tests related to these types of failures. In our tests, we used a PowerFlex R740xd 6-node cluster with three SSDs per storage pool. Replication was active on both storage pools at the time of the failures.
SDR failure scenarios
We started with a baseline workload, as shown in the following figure:
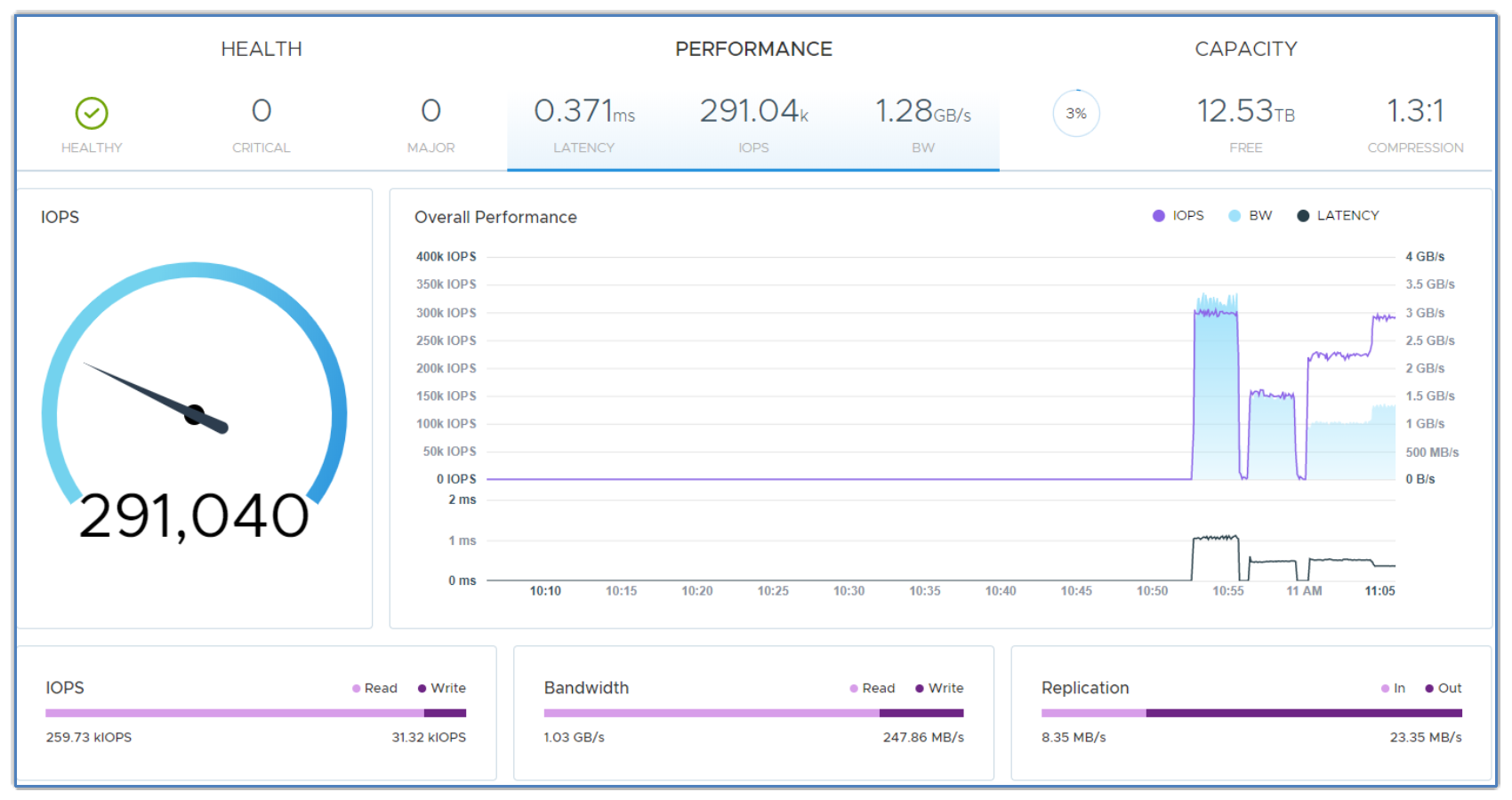
Figure 23. Workload baseline
We went on to fail an SDR, observe the impact, and observe the later impact of restarting it. The following figure shows the results:
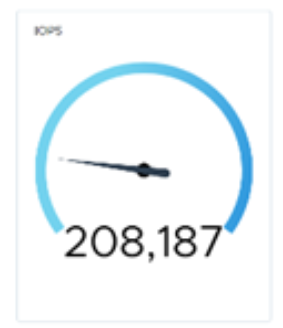


Immediately after failing the SDR, we see a drop in I/O processing.
The I/O resumes slightly lower.
After restarting, the I/O is slightly affected, but eventually ramps back up to the baseline.
Figure 24. Performance with SDR failure
SDS failure scenarios
We performed the same test for SDS failure. The results show that the system was more than capable of handling the workload with five active SDS systems:

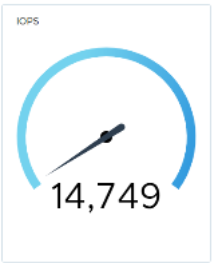

Baseline workload.
IOPS just after failing the SDS.
5 seconds later, I/O starts ramping up, and within 10 seconds the baseline workload resumes.
Figure 25. Performance with SDS failure
Also, as expected, we saw rebalance activity:

Figure 26. Rebalance activity
The following figure shows performance after SDS recovery:


When we restart the failed SDS, we see an immediate, but insubstantial, drop.
As the rebalance continues, the I/O ramps back up to the baseline.
Figure 27. Performance after SDS recovery
Network link failure scenario
Next, we failed a network link to demonstrate how the updated native load balancing affects the I/O rate, as shown in the following figure. The system has a network configuration consisting of four data links between systems.
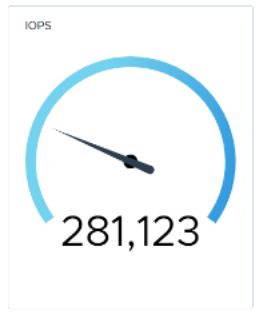
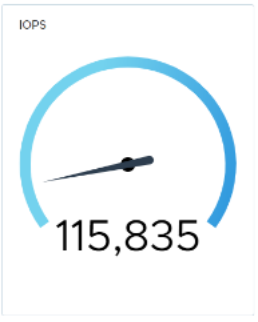
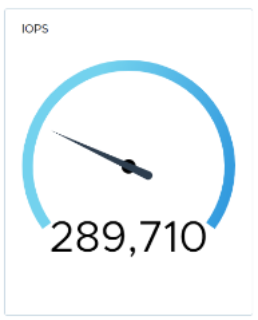
Again, we establish a baseline.
We fail a link and notice a 3-second drop in I/O.
5 seconds later, the baseline returns.
Figure 28. Performance during network link failure
After we reconnected the failed port, the baseline I/O level resumed within a few seconds with no noticeable dip:
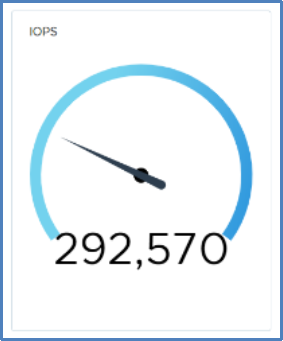
Figure 29. Performance after reconnection of failed port
All these failure scenarios demonstrate the resilience of PowerFlex. They also show that the system is well tuned and that rebuild activity does not have a severe impact on our workload.