




What to do with all that data? Answer: SingleStore on PowerFlex

Every organization has data, every organization has databases, every organization must figure out what to do with all that data from those databases. According to research by the University of Tennessee, Knoxville’s Haslam College of Business there were 44 zettabytes of data in 2020, and by 2025 it is estimated that 463 exabytes of data will be created daily. That’s a lot of data, and even if your organization only contributes a fraction of a precent to those 463 exabytes of data a day, that’s still a lot of data to manage. A great approach to this modern ocean of data is using SingleStore on Dell PowerFlex.
Recently Dell and SingleStore released a joint validation white paper on a virtualized SingleStore environment running on PowerFlex. The paper provides an overview of the technologies used and then looks at an architecture that can be used to run SingleStore on PowerFlex. After that, the paper looks at how the environment was validated.
SingleStore
Before I get into the details of the paper, I suspect there might be a few readers who have yet to hear about SingleStore or know about some of its great features, so let’s start there. Built for developers and architects, SingleStoreDB is based on a distributed SQL architecture, delivering 10–100 millisecond performance on complex queries—all while ensuring that your organization can effortlessly scale. Now let’s go a bit deeper….
The SingleStoreDB :
- Scales horizontally providing high throughput across a wide range of platforms.
- Maintains a broad compatibility with common technologies in the modern data processing ecosystem (for example, orchestration platforms, developer IDEs, and BI tools), so you can easily integrate it in your existing environment.
- Features an in-memory rowstore and an on-disk columnstore to handle both highly concurrent operational and analytical workloads.
- Features the SingleStore Pipelines data ingestion technology that streams large amounts of data at high throughput into the database with exactly once semantics.
This means that you can continue to run your traditional SQL queries against your every growing data, which all resides on a distributed system, and you can do it fast. This is a big win for organizations who have active data growth in their environment.
What makes this even better is the ability of PowerFlex to scale from a few nodes to thousands. This provides a few different options to match your growing needs. You can start with just your SingleStore system deployed on PowerFlex and migrate other workloads on to the PowerFlex environment as time permits. This allows you to focus on just your database environment to start and then, as infrastructure comes up for renewal, you migrate those workloads and scale up your environment with more compute and storage capacity.
Or maybe you are making a bigger contribution to that 463 exabytes of data per day I mentioned earlier, and you need to scale out your environment to handle your data’s growth. You can do that too!
That’s the great thing about PowerFlex, you can consume resources independently of each other. You can add more storage or compute as you need them.
Additionally, with PowerFlex, you can deliver bare-metal and virtualized environments without having to choose only one. That’s right—you can run bare-metal servers right next to virtualized workloads.
Architecture
The way the engineers built this environment was using PowerFlex deployed in a hyper-converged infrastructure (HCI) configuration where the compute nodes are also storage nodes. (PowerFlex supports both two-tier architectures and HCI.)
As shown in the following diagram, our engineering team used five Dell PowerEdge R640 servers with dual CPUs, 384 GB of RAM, and eight SSDs per node. These five nodes were configured as HCI nodes and connected with a 25 Gbps network. The storage from across the nodes is aggregated to create a large software-defined pool of storage as a single protection domain that provides volumes to the SingleStore VMs. This is ideal for even the most demanding databases due to its high I/O capability.
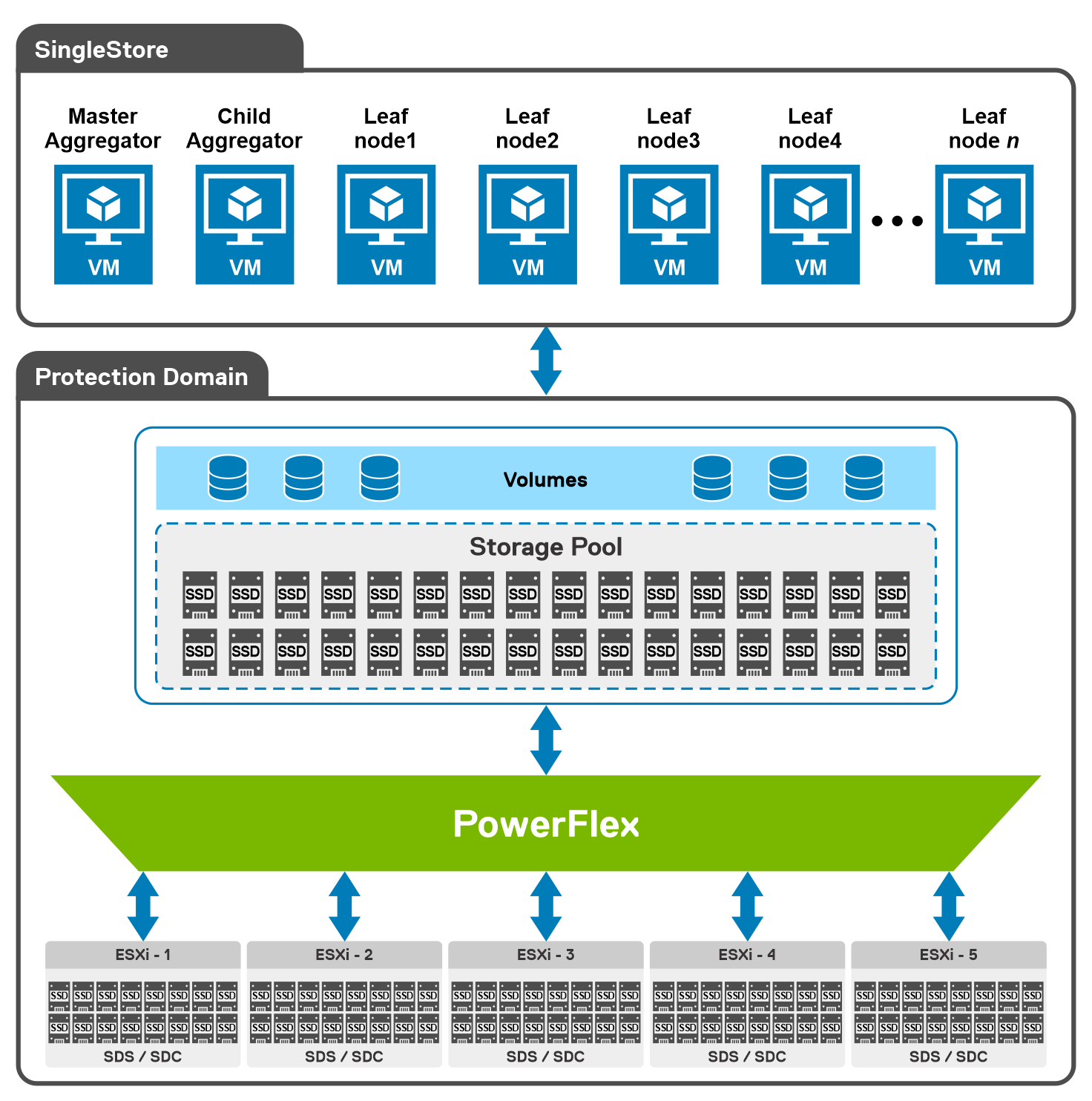
For this validation, the SingleStore Cluster VMs consist of two aggregator VMs and multiple leaf VMs. The white paper details the configuration of these VMs.
Additionally, the white paper provides an overview of the steps used to deploy SingleStore on VMware vSphere in a PowerFlex environment. For this validation, they followed the online user interface method to deploy SingleStore.
Testing
With the environment configured, the white paper then discusses how to validate the environment using TPC-DS. This tool provides 99 different queries that can be used to test a database. For this validation, only 95 of the 99 were used. The paper then describes both how the sample data set was created and how the tests were run.
The validation tests were run on 4, 6, and 8 leaf node configurations. This was done to understand the variation in performance as the environment scales. The testing showed that having more SingleStore leaf nodes results in better performance outcomes.
The testing also showed that there were no storage bottlenecks for the TPC-DS like workload and that using more powerful CPUs could further enhance the environment.
The white paper shows how SingleStore and PowerFlex can be used to create a dynamic and robust environment for your growing data needs as you do your part to contribute to the 463 exabytes of data that is expected to be created daily by 2025. To find out more about this design, contact your Dell representative.
Resources
Author: Tony Foster
Twitter: @wonder_nerd
LinkedIn