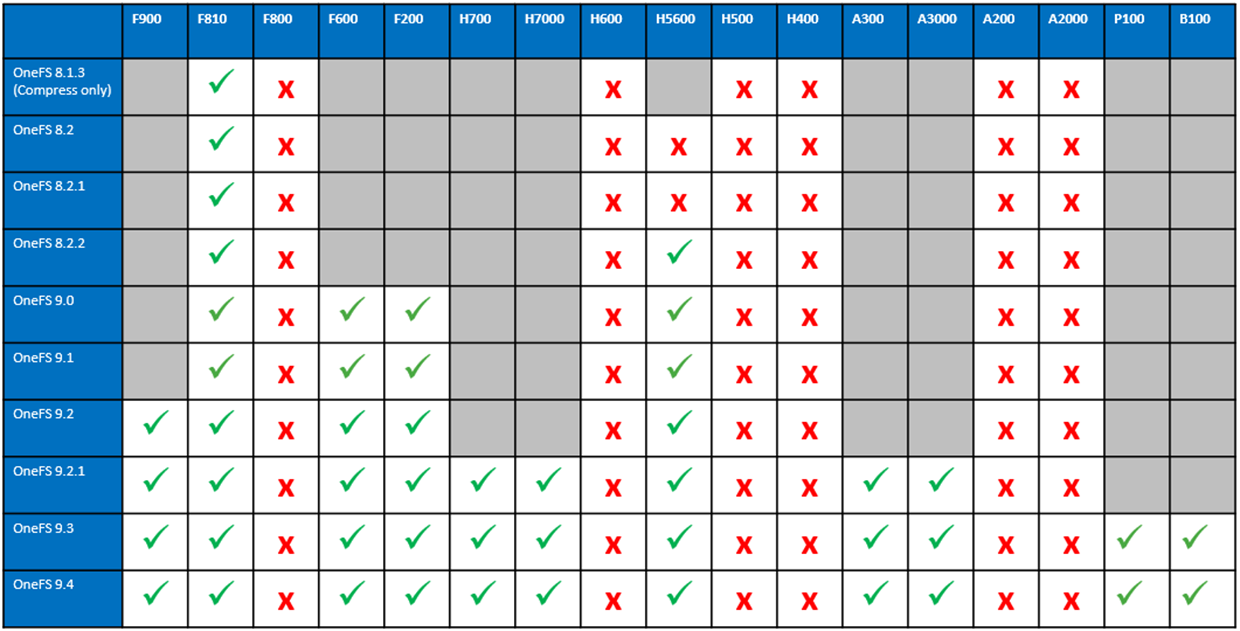
OneFS In-line Dedupe

Among the features and functionality delivered in the new OneFS 9.4 release is the promotion of in-line dedupe to enabled by default, further enhancing PowerScale’s dollar-per-TB economics, rack density and value.
Part of the OneFS data reduction suite, in-line dedupe initially debuted in OneFS 8.2.1. However, it was enabled manually, so many customers simply didn’t use it. But with this enhancement, new clusters running OneFS 9.4 now have in-line dedupe enabled by default.
Cluster configuration | In-line dedupe | In-line compression |
New cluster running OneFS 9.4 | Enabled | Enabled |
New cluster running OneFS 9.3 or earlier | Disabled | Enabled |
Cluster with in-line dedupe enabled that is upgraded to OneFS 9.4 | Enabled | Enabled |
Cluster with in-line dedupe disabled that is upgraded to OneFS 9.4 | Disabled | Enabled |
That said, any clusters that upgrade to 9.4 will not see any change to their current in-line dedupe config during upgrade. Also, there is also no change to the behavior for in-line compression, which remains enabled by default in all OneFS versions from 8.1.3 onwards.
But before we examine the-under-the-hood changes in OneFS 9.4, let’s have a quick dedupe refresher.
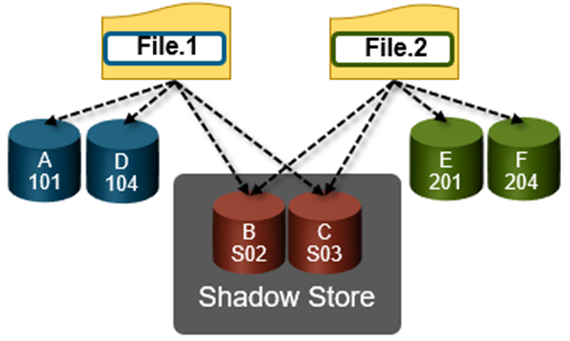
Currently, OneFS in-line data reduction, which encompasses compression, dedupe, and zero block removal, is supported on the F900, F600, and F200 all-flash nodes, plus the F810, H5600, H700/7000, and A300/3000 Gen6.x chassis.

Within the OneFS data reduction pipeline, zero block removal is performed first, followed by dedupe, and then compression. This order allows each phase to reduce the scope of work each subsequent phase.
Unlike SmartDedupe, which performs deduplication once data has been written to disk, or post-process, in-line dedupe acts in real time, deduplicating data as is ingested into the cluster. Storage efficiency is achieved by scanning the data for identical blocks as it is received and then eliminating the duplicates.
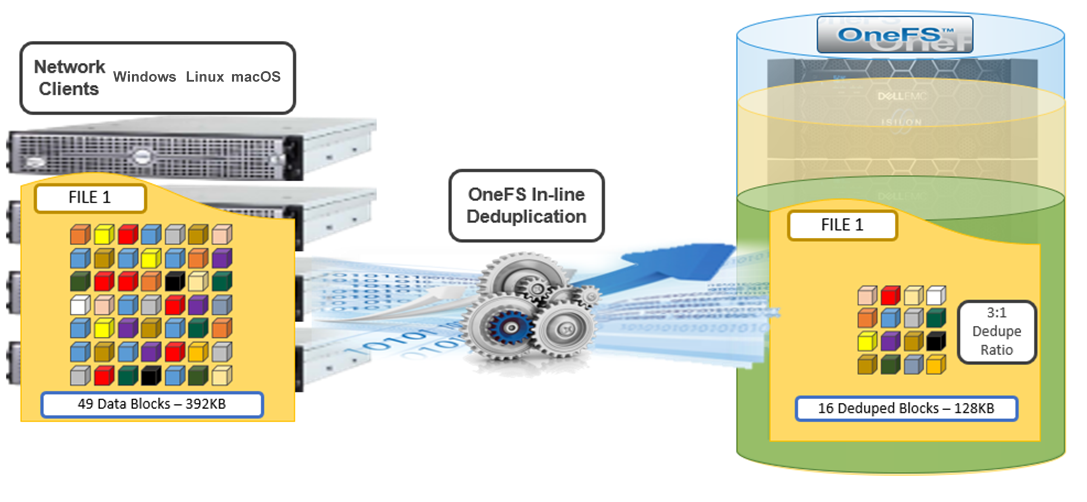
When in-line dedupe discovers a duplicate block, it moves a single copy of the block to a special set of files known as shadow stores. These are file-system containers that allow data to be stored in a sharable manner. As such, files stored under OneFS can contain both physical data and pointers, or references, to shared blocks in shadow stores.
Shadow stores are similar to regular files but are hidden from the file system namespace, so they cannot be accessed through a pathname. A shadow store typically grows to a maximum size of 2 GB, which is around 256 K blocks, and each block can be referenced by 32,000 files. If the reference count limit is reached, a new block is allocated, which may or may not be in the same shadow store. Also, shadow stores do not reference other shadow stores. And snapshots of shadow stores are not permitted because the data contained in shadow stores cannot be overwritten.
When a client writes a file to a node pool configured for in-line dedupe on a cluster, the write operation is divided up into whole 8 KB blocks. Each block is hashed, and its cryptographic ‘fingerprint’ is compared against an in-memory index for a match. At this point, one of the following will happen:
- If a match is discovered with an existing shadow store block, a byte-by-byte comparison is performed. If the comparison is successful, the data is removed from the current write operation and replaced with a shadow reference.
- When a match is found with another LIN, the data is written to a shadow store instead and is replaced with a shadow reference. Next, a work request is generated and queued that includes the location for the new shadow store block, the matching LIN and block, and the data hash. A byte-by-byte data comparison is performed to verify the match and the request is then processed.
- If no match is found, the data is written to the file natively and the hash for the block is added to the in-memory index.
For in-line dedupe to perform on a write operation, the following conditions need to be true:
- In-line dedupe must be globally enabled on the cluster.
- The current operation is writing data (not a truncate or write zero operation).
- The no_dedupe flag is not set on the file.
- The file is not a special file type, such as an alternate data stream (ADS) or an EC (endurant cache) file.
- Write data includes fully overwritten and aligned blocks.
- The write is not part of a rehydrate operation.
- The file has not been packed (containerized) by small file storage efficiency (SFSE).
OneFS in-line dedupe uses the 128-bit CityHash algorithm, which is both fast and cryptographically strong. This contrasts with the OneFS post-process SmartDedupe, which uses SHA-1 hashing.
Each node in a cluster with in-line dedupe enabled has its own in-memory hash index that it compares block fingerprints against. The index lives in system RAM and is allocated using physically contiguous pages and is accessed directly with physical addresses. This avoids the need to traverse virtual memory mappings and does not incur the cost of translation lookaside buffer (TLB) misses, minimizing dedupe performance impact.
The maximum size of the hash index is governed by a pair of sysctl settings, one of which caps the size at 16 GB, and the other which limits the maximum size to 10% of total RAM. The strictest of these two constraints applies. While these settings are configurable, the recommended best practice is to use the default configuration. Any changes to these settings should only be performed under the supervision of Dell support.
Since in-line dedupe and SmartDedupe use different hashing algorithms, the indexes for each are not shared directly. However, the work performed by each dedupe solution can be used by each other. For instance, if SmartDedupe writes data to a shadow store, when those blocks are read, the read-hashing component of in-line dedupe sees those blocks and indexes them.
When a match is found, in-line dedupe performs a byte-by-byte comparison of each block to be shared to avoid the potential for a hash collision. Data is prefetched before the byte-by-byte check and is compared against the L1 cache buffer directly, avoiding unnecessary data copies and adding minimal overhead. Once the matching blocks are compared and verified as identical, they are shared by writing the matching data to a common shadow store and creating references from the original files to this shadow store.
In-line dedupe samples every whole block that is written and handles each block independently, so it can aggressively locate block duplicity. If a contiguous run of matching blocks is detected, in-line dedupe merges the results into regions and processes them efficiently.
In-line dedupe also detects dedupe opportunities from the read path, and blocks are hashed as they are read into L1 cache and inserted into the index. If an existing entry exists for that hash, in-line dedupe knows there is a block-sharing opportunity between the block it just read and the one previously indexed. It combines that information and queues a request to an asynchronous dedupe worker thread. As such, it is possible to deduplicate a data set purely by reading it all. To help mitigate the performance impact, the hashing is performed out-of-band in the prefetch path, rather than in the latency-sensitive read path.
The original in-line dedupe control path design had its limitations, since it did not provide gconfig control settings for the default-disabled in-line dedupe. The previous control-path logic had no gconfig control settings for default-disabled in-line dedupe. But in OneFS 9.4, there are now two separate features that interact together to distinguish between a new cluster or an upgrade to an existing cluster configuration:
For the first feature, upon upgrade to 9.4 on an existing cluster, if there is no in-line dedupe config present, the upgrade explicitly sets it to disabled in gconfig. This has no effect on an existing cluster since it’s already disabled. Similarly, if the upgrading cluster already has an existing in-line dedupe setting in gconfig, OneFS takes no action.
For the other half of the functionality, when booting OneFS 9.4, a node looks in gconfig to see if there’s an in-line dedupe setting. If no config is present, OneFS enables it by default. Therefore, new OneFS 9.4 clusters automatically enable dedupe, and existing clusters retain their legacy setting upon upgrade.
Since the in-line dedupe configuration is binary (either on or off across a cluster), you can easily control it manually through the OneFS command line interface (CLI). As such, the isi dedupe inline settings modify CLI command can either enable or disable dedupe at will—before, during, or after the upgrade. It doesn’t matter.
For example, you can globally disable in-line dedupe and verify it using the following CLI command:
# isi dedupe inline settings viewMode: enabled# isi dedupe inline settings modify –-mode disabled # isi dedupe inline settings view Mode: disabled
Similarly, the following syntax enables in-line dedupe:
# isi dedupe inline settings view Mode: disabled # isi dedupe inline settings modify –-mode enabled # isi dedupe inline settings view Mode: enabled
While there are no visible userspace changes when files are deduplicated, if deduplication has occurred, both the disk usage and the physical blocks metrics reported by the isi get –DD CLI command are reduced. Also, at the bottom of the command’s output, the logical block statistics report the number of shadow blocks. For example:
Metatree logical blocks: zero=260814 shadow=362 ditto=0 prealloc=0 block=2 compressed=0
In-line dedupe can also be paused from the CLI:
# isi dedupe inline settings modify –-mode paused # isi dedupe inline settings view Mode: paused
However, it’s worth noting that this global setting states what you’d like to happen, after which each node attempts to enact the new configuration. However, it can’t guarantee the change, because not all node types support in-line dedupe. For example, the following output is from a heterogenous cluster with an F200 three-node pool supporting in-line dedupe, and an H400 four-node pool not supporting it.
Here, we can see that in-line dedupe is globally enabled on the cluster:
# isi dedupe inline settings view Mode: enabled
However, you can use the isi_for_array isi_inline_dedupe_status command to display the actual setting and state of each node:
# isi dedupe inline settings view Mode: enabled # isi_for_array -s isi_inline_dedupe_status 1: OK Node setting enabled is correct 2: OK Node setting enabled is correct 3: OK Node setting enabled is correct 4: OK Node does not support inline dedupe and current is disabled 5: OK Node does not support inline dedupe and current is disabled 6: OK Node does not support inline dedupe and current is disabled 7: OK Node does not support inline dedupe and current is disabled
Also, any changes to the dedupe configuration are also logged to /var/log/messages, you can find them by grepping for inline_dedupe.
In a nutshell, in-line compression has always been enabled by default since its introduction in OneFS 8.1.3. For new clusters running 9.4 and above, in-line dedupe is on by default. For clusters running 9.3 and earlier, in-line dedupe remains disabled by default. And existing clusters that upgrade to 9.4 will not see any change to their current in-line dedupe config during upgrade.
And here’s the OneFS in-line data reduction platform support matrix for good measure: