




A Metadata-based Approach to Tiering in PowerScale OneFS

OneFS SmartPools provides sophisticated tiering between storage node types. Rules based on file attributes such as last accessed time or creation date can be configured in OneFS to drive transparent motion of data between PowerScale node types. This kind of “set and forget” approach to data tiering is ideal for some industries but not workable for most content creation workflows.
A classic case of how this kind of tiering falls short for media is the real-time nature of video playback. For an extreme example, take an uncompressed 4K image sequence (or even 8K), that might require >1.5GB/s of throughput to play properly. If this media has been tiered down to low performing archive storage and it needs to be used, those files must be migrated back up before they will play. This problem causes delays and confusion all around and makes media storage administrators hesitant to archive anything.
The good news is that the PowerScale OneFS ecosystem has a better way of doing things!
The approach I have taken here is to pull metadata from elsewhere in the workflow and use it to drive on demand tiering in OneFS. How does that work? OneFS supports file extended attributes, which are <key/value> pairs (metadata!) that can be written to the files and directories stored in OneFS. File Policies can be configured in OneFS to move data based on those file extended attributes. And a SmartPoolsTree job can be run on only the path that needs to be moved. All this goodness can be controlled externally by combining the DataIQ API and the OneFS API.

Figure 1: API flow
Note that while I’m focused on combining the DataIQ and OneFS APIs in this post, other API driven tools with OneFS file system visibility could be substituted for DataIQ.
DataIQ
DataIQ is a data indexing and analysis tool. It runs as an external virtual machine and maintains an index of mounted file systems. DataIQ’s file system crawler is efficient, fast, and lightweight, meaning it can be kept up to date with little impact on the storage devices it is indexing.
DataIQ has a concept called “tagging”. Tags in DataIQ apply to directories and provide a mechanism for reporting sets of related data. A tag in DataIQ is an arbitrary <key>/<value> pair. Directories can be tagged in DataIQ in three different ways:
- Autotagging rules:
- Tags are automatically placed in the file system based on regular expressions defined in the Autotagging configuration menu.
- Use of .cntag files:
- Empty files named in the format <key>.<value>.cntag are placed in directories and will be recognized as tags by DataIQ.
- API-based tagging:
- The DataIQ API allows for external tagging of directories.
Tags can be placed throughout a file system and then reported on as a group. For instance, temporary render directories could contain a render.temp.cntag file. Similarly, an external tool could access the DataIQ API and place a <Project/Name> tag on the top-level directory of each project. DataIQ can generate reports on the storage capacity those tags are consuming.
File system extended attributes in OneFS
As I mentioned earlier, OneFS supports file extended attributes. Extended attributes are arbitrary metadata tags in the form of <key/value> pairs that can be applied to files and directories. Extended attributes are not visible in the graphical interface or when accessing files over a share or export. However, the attributes can be accessed using the OneFS CLI with the getexattr and setextattr commands.
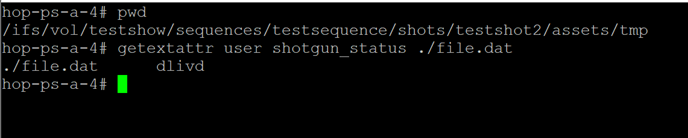
Figure 2: File extended attributes
The SmartPools job engine will move data between node pools based on these file attributes. And it is that SmartPools functionality that uses this metadata to perform on demand data tiering.
Crucially, OneFS supports creation of file system extended attributes from an external script using the OneFS REST API. The OneFS API Reference Guide has great information about setting and reading back file system extended attributes.
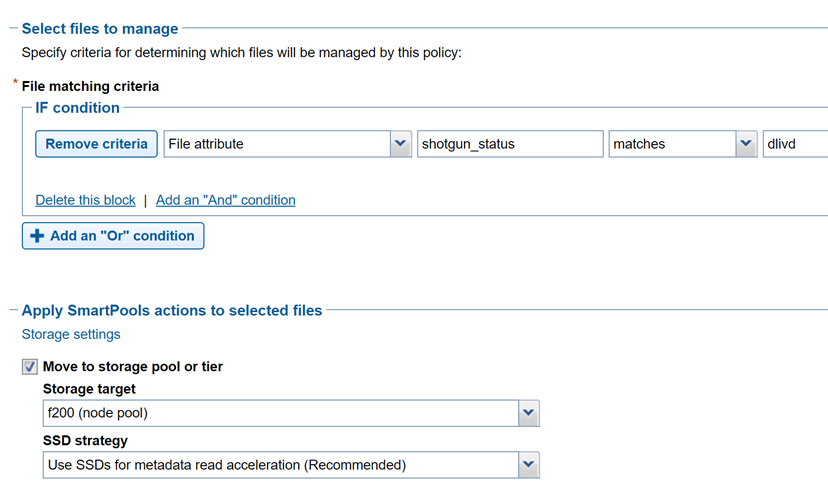
Figure 3: File policy configuration
Tiering example with Autodesk Shotgrid, DataIQ, and OneFS
Autodesk ShotGrid (formerly Shotgun) is a production resource management tool common in the visual effects and animation industries. ShotGrid is a cloud-based tool that allows for coordination of large production teams. Although it isn’t a storage management tool, its business logic can be useful in deciding what tier of storage a particular set of files should live on. For instance, if a shot tracked in ShotGrid is complete and delivered, the files associated with that shot could be moved to archive.
DataIQ plug-in for Autodesk ShotGrid
The open-source DataIQ plug-in for ShotGrid is available on GitHub here:
Dell DataIQ Autodesk ShotGrid Plugin
This plug-in is proof of concept code to show how the ShotGrid and DataIQ APIs can be combined to tag data in DataIQ based on shot status in ShotGrid. The DataIQ tags are dynamically updated with the current shot status in ShotGrid.
Here is a “shot” in ShotGrid configured with various possible statuses:
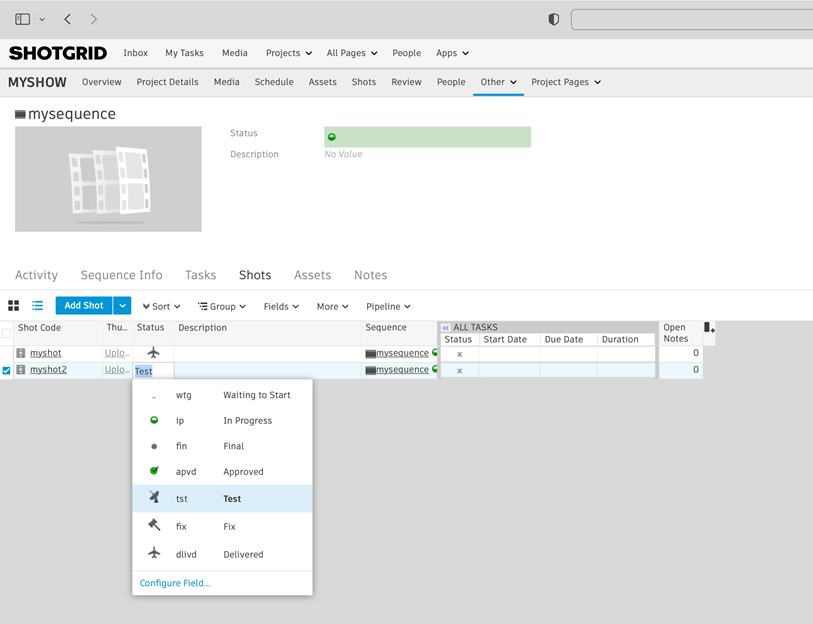
Figure 4: ShotGrid status
The following figure of DataIQ shows where the shot status field from ShotGrid has been automatically applied as a tag in DataIQ.
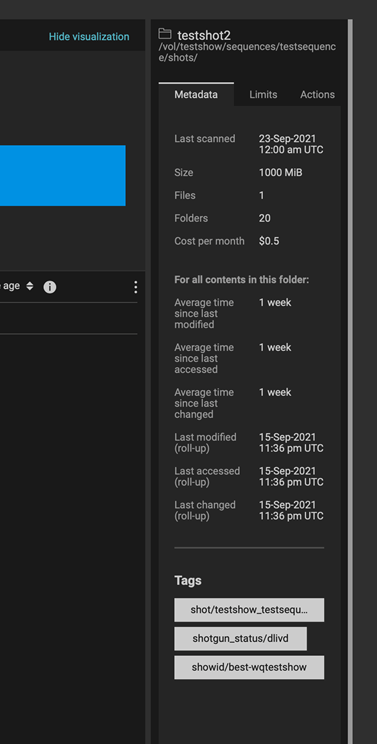
Figure 5: DataIQ tags
Once metadata from ShotGrid has been pulled into DataIQ, that information can be used to drive OneFS SmartPools tiering:
- A user (or system) passes the DataIQ tag <key/values> to the DataIQ API. The DataIQ API returns a list of directories associated with that tag.
- A directory chosen from Step 1 above can be passed back to the DataIQ API to get a listing of all contents by way of the DataIQ file index.
- Those items are passed programmatically to the OneFS API. The <key/value> pair of the original DataIQ tag is written as an extended attribute directly to the targeted files and directories.
- And finally, the SmartPoolsTree job can be run on the parent path chosen in Step 2 above to begin tiering the data immediately.
Using business logic to drive storage tiering
DataIQ and OneFS provide the APIs necessary to drive storage tiering based on business logic. Striking efficiencies can be gained by taking advantage of the metadata that exists in many workflow tools. It is a matter of “connecting the dots”.
The example in this blog uses ShotGrid and DataIQ, however it is easy to imagine that similar metadata-based techniques could be developed using other file system index tools. In the media and entertainment ecosystem, media asset management and production asset management systems immediately come to mind as candidates for this kind of API level integration.
As data volumes increase exponentially, it is unrealistic to keep all files on the highest costing tiers of storage. Various automated storage tiering approaches have been around for years, but for many use cases this automated tiering approach falls short. Bringing together rich metadata and an API driven workflow bridges the gap.
To see the Python required to put this process together, refer to my white paper PowerScale OneFS: A Metadata Driven Approach to On Demand Tiering.
Author: Gregory Shiff, Principal Solutions Architect, Media & Entertainment LinkedIn