

Assets

A Metadata-based Approach to Tiering in PowerScale OneFS
Wed, 24 Apr 2024 13:12:26 -0000
|Read Time: 0 minutes
OneFS SmartPools provides sophisticated tiering between storage node types. Rules based on file attributes such as last accessed time or creation date can be configured in OneFS to drive transparent motion of data between PowerScale node types. This kind of “set and forget” approach to data tiering is ideal for some industries but not workable for most content creation workflows.
A classic case of how this kind of tiering falls short for media is the real-time nature of video playback. For an extreme example, take an uncompressed 4K image sequence (or even 8K), that might require >1.5GB/s of throughput to play properly. If this media has been tiered down to low performing archive storage and it needs to be used, those files must be migrated back up before they will play. This problem causes delays and confusion all around and makes media storage administrators hesitant to archive anything.
The good news is that the PowerScale OneFS ecosystem has a better way of doing things!
The approach I have taken here is to pull metadata from elsewhere in the workflow and use it to drive on demand tiering in OneFS. How does that work? OneFS supports file extended attributes, which are <key/value> pairs (metadata!) that can be written to the files and directories stored in OneFS. File Policies can be configured in OneFS to move data based on those file extended attributes. And a SmartPoolsTree job can be run on only the path that needs to be moved. All this goodness can be controlled externally by combining the DataIQ API and the OneFS API.

Figure 1: API flow
Note that while I’m focused on combining the DataIQ and OneFS APIs in this post, other API driven tools with OneFS file system visibility could be substituted for DataIQ.
DataIQ
DataIQ is a data indexing and analysis tool. It runs as an external virtual machine and maintains an index of mounted file systems. DataIQ’s file system crawler is efficient, fast, and lightweight, meaning it can be kept up to date with little impact on the storage devices it is indexing.
DataIQ has a concept called “tagging”. Tags in DataIQ apply to directories and provide a mechanism for reporting sets of related data. A tag in DataIQ is an arbitrary <key>/<value> pair. Directories can be tagged in DataIQ in three different ways:
- Autotagging rules:
- Tags are automatically placed in the file system based on regular expressions defined in the Autotagging configuration menu.
- Use of .cntag files:
- Empty files named in the format <key>.<value>.cntag are placed in directories and will be recognized as tags by DataIQ.
- API-based tagging:
- The DataIQ API allows for external tagging of directories.
Tags can be placed throughout a file system and then reported on as a group. For instance, temporary render directories could contain a render.temp.cntag file. Similarly, an external tool could access the DataIQ API and place a <Project/Name> tag on the top-level directory of each project. DataIQ can generate reports on the storage capacity those tags are consuming.
File system extended attributes in OneFS
As I mentioned earlier, OneFS supports file extended attributes. Extended attributes are arbitrary metadata tags in the form of <key/value> pairs that can be applied to files and directories. Extended attributes are not visible in the graphical interface or when accessing files over a share or export. However, the attributes can be accessed using the OneFS CLI with the getexattr and setextattr commands.
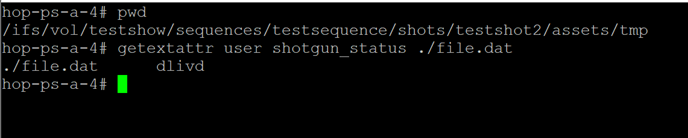
Figure 2: File extended attributes
The SmartPools job engine will move data between node pools based on these file attributes. And it is that SmartPools functionality that uses this metadata to perform on demand data tiering.
Crucially, OneFS supports creation of file system extended attributes from an external script using the OneFS REST API. The OneFS API Reference Guide has great information about setting and reading back file system extended attributes.
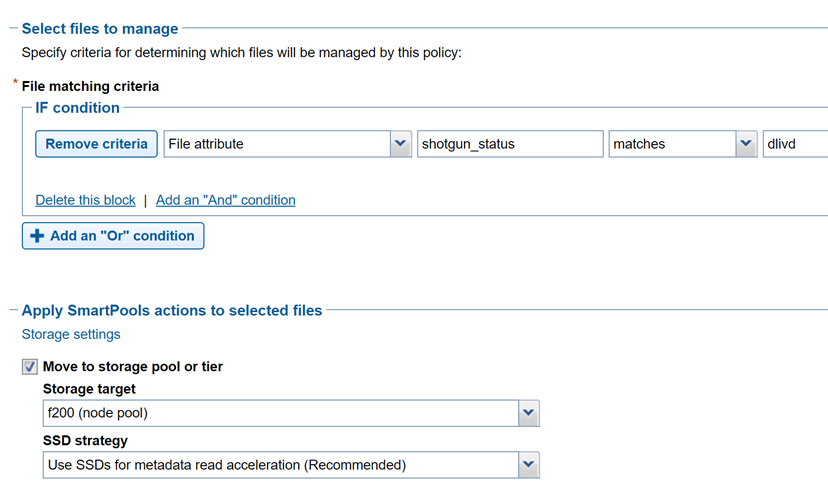
Figure 3: File policy configuration
Tiering example with Autodesk Shotgrid, DataIQ, and OneFS
Autodesk ShotGrid (formerly Shotgun) is a production resource management tool common in the visual effects and animation industries. ShotGrid is a cloud-based tool that allows for coordination of large production teams. Although it isn’t a storage management tool, its business logic can be useful in deciding what tier of storage a particular set of files should live on. For instance, if a shot tracked in ShotGrid is complete and delivered, the files associated with that shot could be moved to archive.
DataIQ plug-in for Autodesk ShotGrid
The open-source DataIQ plug-in for ShotGrid is available on GitHub here:
Dell DataIQ Autodesk ShotGrid Plugin
This plug-in is proof of concept code to show how the ShotGrid and DataIQ APIs can be combined to tag data in DataIQ based on shot status in ShotGrid. The DataIQ tags are dynamically updated with the current shot status in ShotGrid.
Here is a “shot” in ShotGrid configured with various possible statuses:
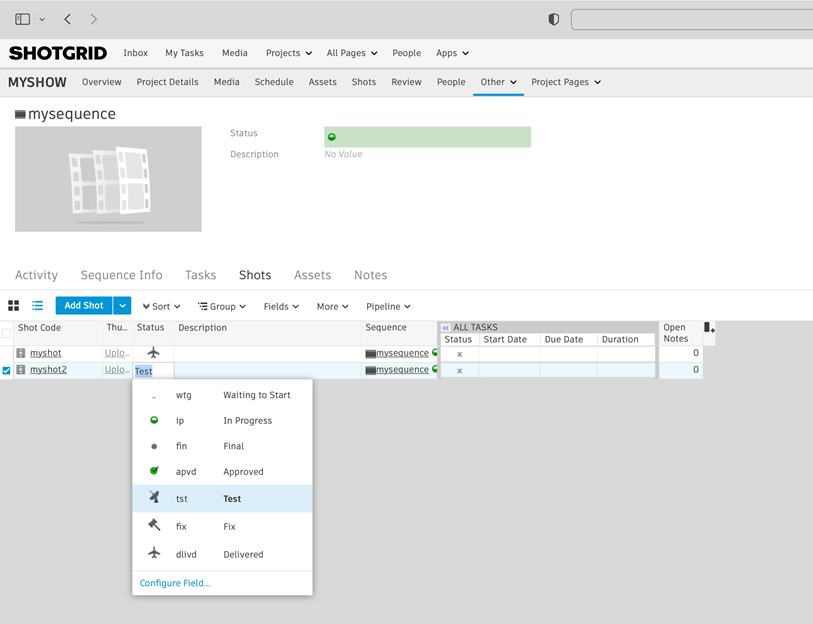
Figure 4: ShotGrid status
The following figure of DataIQ shows where the shot status field from ShotGrid has been automatically applied as a tag in DataIQ.
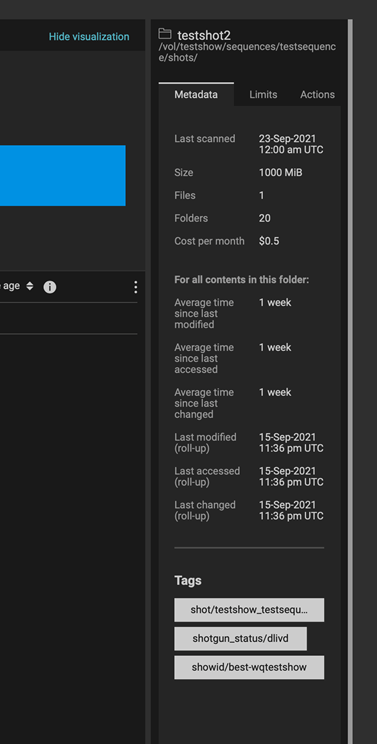
Figure 5: DataIQ tags
Once metadata from ShotGrid has been pulled into DataIQ, that information can be used to drive OneFS SmartPools tiering:
- A user (or system) passes the DataIQ tag <key/values> to the DataIQ API. The DataIQ API returns a list of directories associated with that tag.
- A directory chosen from Step 1 above can be passed back to the DataIQ API to get a listing of all contents by way of the DataIQ file index.
- Those items are passed programmatically to the OneFS API. The <key/value> pair of the original DataIQ tag is written as an extended attribute directly to the targeted files and directories.
- And finally, the SmartPoolsTree job can be run on the parent path chosen in Step 2 above to begin tiering the data immediately.
Using business logic to drive storage tiering
DataIQ and OneFS provide the APIs necessary to drive storage tiering based on business logic. Striking efficiencies can be gained by taking advantage of the metadata that exists in many workflow tools. It is a matter of “connecting the dots”.
The example in this blog uses ShotGrid and DataIQ, however it is easy to imagine that similar metadata-based techniques could be developed using other file system index tools. In the media and entertainment ecosystem, media asset management and production asset management systems immediately come to mind as candidates for this kind of API level integration.
As data volumes increase exponentially, it is unrealistic to keep all files on the highest costing tiers of storage. Various automated storage tiering approaches have been around for years, but for many use cases this automated tiering approach falls short. Bringing together rich metadata and an API driven workflow bridges the gap.
To see the Python required to put this process together, refer to my white paper PowerScale OneFS: A Metadata Driven Approach to On Demand Tiering.
Author: Gregory Shiff, Principal Solutions Architect, Media & Entertainment LinkedIn

Boosting Storage Performance for Media and Entertainment with RDMA
Wed, 24 Apr 2024 13:04:15 -0000
|Read Time: 0 minutes
We are in a new golden era of content creation. The explosion of streaming services has brought an unprecedented volume of new and amazing media. Production, post-production, visual effects, animation, finishing: everyone is booked solid with work. And the expectations for this content are higher than ever, with new technically challenging formats becoming the norm rather than the exception. Anyone who has had to work with this content knows that even in 2021, working natively with 8K video or high frame rate 4K video is no joke.
During post, storage and workstation performance can be huge bottlenecks. These bottlenecks can be particularly painful for “hero” seats that are tasked with working in real time with uncompressed media.
So, let’s look at a new PowerScale OneFS 9.2 feature that can improve storage and workstation performance simultaneously. That technology is Remote Direct Memory Access (RDMA), and specifically NFS over RDMA.
Why NFS? Linux is still the operating system of choice for the applications that media professionals use to work with the most challenging media. Even if those applications have Windows or macOS variants, the Linux version is what is used in the truly high-end. And the native way for a Linux computer to access network storage is NFS. In particular, NFS over TCP.
Already this article is going down a rabbit hole of acronyms! I imagine that most people reading are already familiar with NFS (and SMB) and TCP (and UDP) and on and on. For the benefit of those folks who are not, NFS stands for Network File System. NFS is how Linux systems talk to network storage (there are other ways, but mostly, it is NFS). NFS traffic sits on top of other lower-level network protocols, in particular TCP (or UDP, but mostly it is TCP). TCP does a great job of handling things like packet loss on congested networks, but that comes with performance implications. Back to RDMA.
As the name implies, RDMA is a protocol that allows for a client system to copy data from a storage server’s memory directly into that client’s own memory. And in doing so, the client system bypasses many of the buffering layers inherent in TCP. This direct communication improves storage throughput and reduces latency in moving data between server and client. It also reduces CPU load on both the client and storage server.
RDMA was developed in the 1990s to support high performance compute workloads running over InfiniBand networks. In the 2000s, two methods of running RDMA over Ethernet networks were developed: iWARP and RoCE. Without going into too much detail, iWARP uses TCP for RDMA communications and RoCE uses UDP. There are various benefits and drawbacks of these two approaches. iWARP’s reliance on TCP allows for greater flexibility in network design, but suffers from many of the same performance drawbacks of native TCP communications. RoCE has reduced CPU overhead as compared to iWARP, but requires a lossless network. Once again, without going into too much detail, RoCE is the clear winner given that we are looking for the maximum storage performance with the lowest CPU load. And that is exactly what PowerScale OneFS uses, RoCE (actually RoCEv2, also known as Routable RoCE or RRoCE).
So, put that all together, and you can run NFS traffic over RDMA leveraging RoCE! Yes, back into alphabet soup land. But what this means is that if your environment and PowerScale storage nodes support it, you can massively boost performance by mounting the network storage with a few mount options. And that is a neat trick. The performance gains of RDMA are impressive. In some cases, RDMA is twice as performant as TCP, all other things being equal (with a similar drop in workstation utilization).
A good place to start learning if your PowerScale nodes support RDMA is my colleague Nick Trimbee’s excellent blog: Unstructured Data Tips.
Let’s bring this back to media creation and look at some real-world examples that were tested for this article. The first example is playing an uncompressed 8K DPX image sequence in DaVinci Resolve. Uncompressed video puts less of a strain on the workstation (no real-time decompression), but the file sizes and bandwidth requirements are huge. As an image sequence, each frame of video is a separate file, and at 8K resolution, that meant that each file was approximately 190 MB. To sustain 24 frames per second playback requires 4.5 GB! Long story short, the image sequence would not play with the storage mounted using TCP. Mounting the exact same storage using RDMA was a night and day difference: 8K video at 24 frames per second in Resolve over the network.
Now let’s look at workstation performance. Because to be fair, uncompressed 8K video is unwieldy to store or work with. The number of facilities truly working in uncompressed 8K is small. Far more common is a format such as 6K PIZ compressed OpenEXR. OpenEXR is another image sequence format (file per frame) and PIZ compression is lossless, retaining full image fidelity. The PIZ compressed image sequence I used here had frames that were between 80 MB and 110 MB each. To sustain 24 frames per second requires around 2.7 GB. This bandwidth is less than uncompressed 8K but still substantial. However, the real challenge is that the workstation needs to decompress each frame of video as it is being read. Pulling the 6K image sequence into DaVinci Resolve again and attempting playback over the network storage mounted using TCP did not work. The combination of CPU cycles required for reading the files over network storage and decoding each 6K frame were too much. RDMA was the key for this kind of playback. And sure enough, remounting the storage using RDMA enabled smooth playback of this OpenEXR 6K PIZ image sequence over the network in Resolve.
Going a little deeper with workstation performance, let us look at some other common video formats: Sony XAVC and Apple ProRes 422HQ both at full 4K DCI resolution and 59.94 frames per second. This time AutoDesk Flame 2022 is used as the playback application. Flame has a debug mode that shows video disk dropped frames, GPU dropped frames, and broadcast output dropped frames. With the file system mounted using TCP or RDMA, the video disk never dropped a frame.
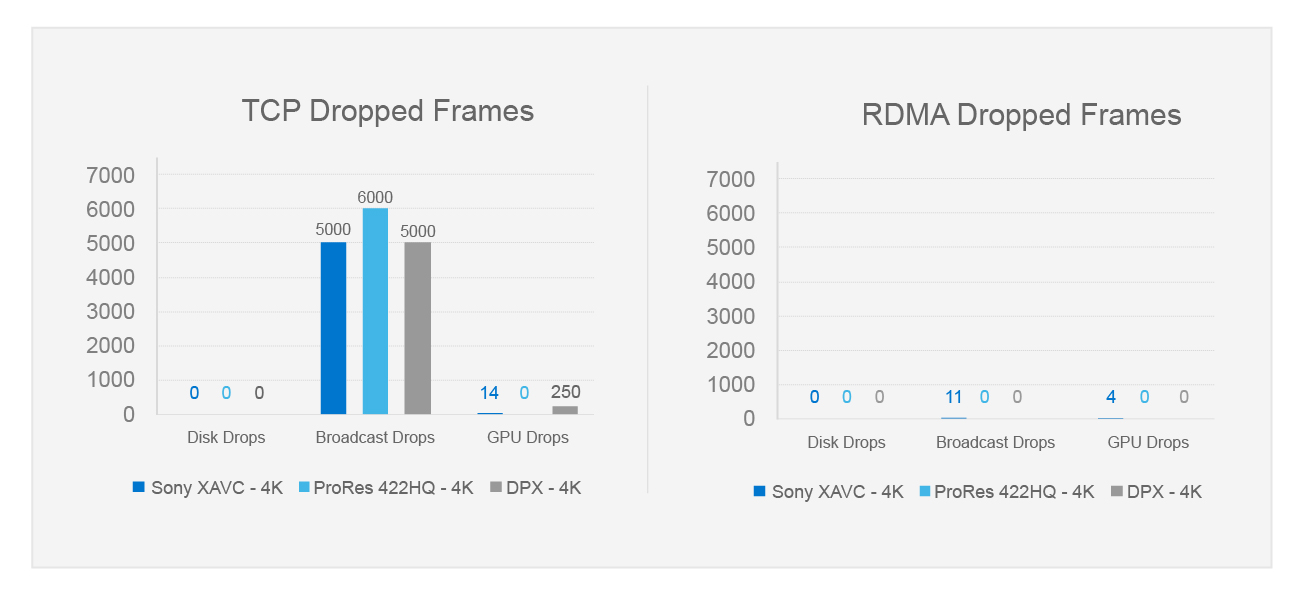
The storage is plenty fast enough. However, with the file system mounted using TCP, the broadcast output dropped thousands of frames, and the workstation could not keep up. Playing back the material over RDMA was a different story, smooth broadcast output and essentially no dropped frames at all. In this case, it was all about the CPU cycles freed up by RDMA.
NFS over RDMA is a big deal for PowerScale OneFS environments supporting the highest end playback. The twin benefits of storage performance and workstation CPU savings change what is possible with network storage. For more specifics about the storage environment, the tests run, and how to leverage NFS over RDMA, see my detailed white paper PowerScale OneFS: NFS over RDMA for Media.
Author: Gregory Shiff, Principal Solutions Architect, Media & Entertainment LinkedIn

Success with Dell PowerScale and Baselight by FilmLight
Wed, 19 Jul 2023 18:19:27 -0000
|Read Time: 0 minutes
In my role as technical lead for media workflows at Dell Technologies, I’m fortunate to partner with companies making some of the best tools for creatives. FilmLight is undeniably one of those companies. Baselight by FilmLight is used in the highest end of feature film production. I was eager to put the latest all-flash PowerScale OneFS nodes to the test and see how those storage nodes could support Baselight workflows. I’m pleased to say that PowerScale supports Baselight very well, and I’m able to share best practices for integrating PowerScale into Baselight environments.
Baselight is a color grading and image-processing system that is widely used in cinematic production. Traditionally, Baselight DI workflows are the domain of SAN or block storage. The journey towards supporting modern DI workflows on PowerScale started with OneFS’s support of NFS-over-RDMA. Using the RDMA protocol with PowerScale all flash storage allows for high throughput workflows that are unobtainable with TCP. Using RDMA for media applications is well documented in the blog and white paper: NFS over RDMA for Media Workflows.
With successful RDMA testing on other color correction software complete, I was confident that we could add Baselight to the list of supported platforms. The time seemed ripe, and FilmLight agreed to work with us on getting it done. In partnership with the FilmLight team in LA, we got Baselight One up and running in the Seattle media lab.
FilmLightOS already has a driver installed that supports RDMA for the NIC in the workstation. This made configuration easy, because no additional software had to be installed to support the protocol (at least in our case). While RDMA remains the best choice for using PowerScale with Baselight, not all networks can support RDMA. The good news here is that there is another option: nconnect.
The Linux distribution that Baselight runs on also supports the NFS nconnect mount option. Nconnect allows for multiple TCP connections between the Baselight client and the PowerScale storage. Testing with nconnect demonstrated enough throughput to support 8K uncompressed playback from PowerScale. While RDMA is preferred, it is not an absolute requirement.
With the storage mounted and performing as expected, we set about adjusting Baselight threads and DirectIO settings to optimize the interaction of Baselight and PowerScale. The results of this testing showed that increasing BaseLight’s thread count to 16 improved performance. (These threads were unrelated to the nconnect connections mentioned above.) DirectIO is a mechanism that bypasses some caching layers in Linux. DirectIO improved Baselight’s write performance and degraded read performance. Thankfully, Baselight is flexible enough to selectively enable DirectIO only for writes.

PowerScale is an easy win for Baselight One. However, Baselight also comes in other variations: Baselight Two and Baselight X. These versions of Baselight have separate processing nodes and host UI devices to tackle the most challenging workflows. These Baselight systems share configuration files that can cause issues with how the storage is mounted on the processing nodes as compared to the host UI nodes. When using RDMA, the processing nodes will use an RDMA mount while the host UI will use TCP. Working with the FilmLight team in LA, changes were made to support separate mount options for the processing nodes vs, host UI node.
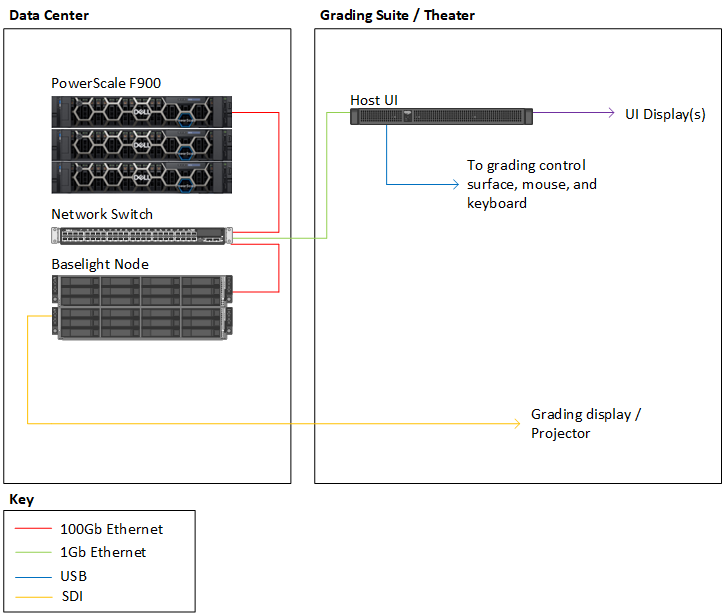
Getting to know Baselight and partnering with FilmLight on this project was highly satisfying. It would not have been easy to understand the finer intricacies of how Baselight interacts with storage without their help (the rendering and caching mechanisms within Baselight are awesome).
For more details about how to use PowerScale with Baselight, check out the full white paper: PowerScale OneFS: Baselight by FilmLight Best Practices and Configuration.
For more information, and the latest content on Dell Media and Entertainment storage solutions, visit us online.

OneFS 9.5 Performance Enhancements for Video Editing
Wed, 19 Jul 2023 18:16:59 -0000
|Read Time: 0 minutes
Of the many changes in OneFS 9.5, the most exciting are the performance enhancements on the NVMe-based PowerScale nodes: F900 and F600. These performance increases are the result of some significant changes “under-the-hood” to OneFS. In the lead-up to the National Association of Broadcasters show last April, I wanted to qualify how much of a difference the extra performance would make for Adobe Premiere Pro video editing workflows. Adobe is one of Dell’s biggest media software partners, and Premiere Pro is crucial to all sorts of media production, from broadcast to cinema.
The awesome news is that the changes to OneFS make a big difference. I saw 40% more video streams with the software upgrade: up to 140 streams of UHD ProRes422 from a single F900 node!
Changes to OneFS
Broadly speaking, there were changes to three areas in OneFS that resulted in the performance boost in version 9.5. These areas are L2 cache, backend networking, and prefetch.
L2 cache -- Being smart about how and when to bypass L2 cache and read directly from NVMe is one part of the OneFS 9.5 performance story. PowerScale OneFS clusters maintain a globally accessible L2 cache for all nodes in the cluster. Manipulating L2 cache can be “expensive” computationally speaking. During a read, the cluster needs to determine what data is in cache, whether the read should be added to cache, and what data should be expired from cache. NVMe storage is so performant that bypassing the L2 cache and reading data directly from NVMe frees up cluster resources. Doing so results in even faster reads on nodes that support it.
Backend networking -- OneFS uses a private backend network for internode communication. With the massive performance of NVMe based storage and the introduction of 100 GbE, limits were getting reached on this private network. OneFS 9.5 gets around these limitations with a custom multichannel approach (similar in concept to nconnect from the NFS world for the Linux folks out there). In OneFS 9.5, the connection channels on the backend network are bonded in a carefully orchestrated way to parallelize some aspects, while still keeping a predictable message ordering.
Prefetch -- The last part of the performance boost for OneFS 9.5 comes from improved file prefetch. How OneFS prefetches file system metadata was reworked to more optimally read ahead at the different depths of the metadata tree. Efficiency was improved and “jitter” between file system processes minimized.
Our lab setup
First a little background on PowerScale and OneFS. PowerScale is the updated name for the Isilon product line. The new PowerScale nodes are based on Dell servers with compute, RAM, networking, and storage. PowerScale is a scale-out, clustered network-attached-storage (NAS) solution. To build a OneFS file system, PowerScale nodes are joined to create cluster. The cluster creates a single NAS file system with the aggregate resources of all the nodes in the cluster. Client systems connect using a DNS name, and OneFS SmartConnect balances client connections between the various nodes. No matter which node the client connects to, that client has the potential to access all the data on the entire cluster. Further, the client systems benefit from the all the nodes acting in concert.
Even before the performance enhancements in OneFS 9.5, the NVMe-based PowerScale nodes were speedy, so a robust lab environment was going to be needed to stress the system. For this particular set of tests, I had access to 16 workstations running the latest version of Adobe Premiere Pro 2023. Each workstation ran Windows 10 with Nvidia GPU, Intel processor, and 10 GbE networking. On the storage side, the tests were performed against a minimum sized 3-node F900 PowerScale cluster with 100 GbE networking.
Adobe Premiere Pro excels at compressed video editing. The trick with compressed video is that an individual client workstation will get overwhelmed long before the storage system. As such, it is critical to evaluate whether any dropped frames are the result of storage or an overwhelmed workstation. A simple test is to take a single workstation and start playing back parallel compressed video streams, such as ProRes 422. Keeping a close watch on the workstation performance monitors, at a certain point CPU and GPU usage will spike and frames will drop. This test will show the maximum number of streams that a single workstation can handle. Because this test is all about storage performance, keeping the number of streams per workstation to a healthy range takes individual workstation performance out of the equation.
I settled on 10x streams of ProRes 422 UHD video running at 30 frames per second per workstation. Each individual video stream was ~70 MBps (560mbps). Running ten of these streams meant each workstation was pulling around 700 MBps (though with Premiere Pro prefetching this number was closer to 800 MBps). With this number of video streams, the workstation wasn’t working too hard and it was well within what would fit down a 10 GbE network pipe.
Running some quick math here, 16 workstations each pulling 800-ish MBps works out to about 12.5 GBps of total throughput. This throughput is not enough throughput to overwhelm even a small 3-node F900 cluster. In order to stress the system, all 16 workstations were manually pointed to single 100 GbE port on a single F900 node. Due to the clustered nature of OneFS, the clients will get benefit from the entire cluster. But even with the rest of the cluster behind it, at a certain point, a single F900 node is going to get overwhelmed.
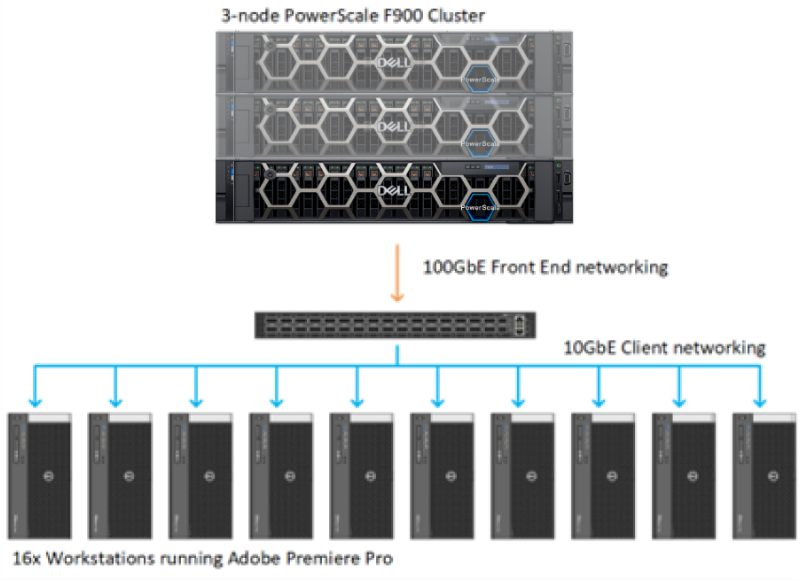
Figure 1. OneFS Lab configuration
Test methodology
The first step was to import test media for playback. Each workstation accessed its own unique set of 10x one-hour long UHD ProRes422 clips. Then a separate Premiere Pro project was created for each workstation with 10 simultaneous layers of video. The plan was to start playback one by one on each workstation and see where the tipping point was for that single PowerScale F900 node. The test was to be run first with OneFS 9.4 and then with OneFS 9.5.
Adobe Premiere Pro has a debug overlay called DogEars. In addition to showing dropped frames, DogEars provides some useful metrics about how “healthy” video playback is in Premiere Pro. Even before a system starts to drop frames, latency spikes and low prefetch buffers show when Premiere Pro is struggling to sustain playback.
The metrics in DogEars that I was focused on were the following:
Dropped frames: This metric is obvious, dropped frames are unacceptable. However, at times Premiere Pro will show single digit dropped frames at playback start.
FramePrefetchLatency: This metric only shows up during playback. The latency starts high while the prefetch frame buffer is filling. When that buffer gets up to slightly over 300 frames, the latency drops down to around 20 to 30 milliseconds. When the storage system was overwhelmed, this prefetch latency goes well above 30 milliseconds and stays there.
CompleteAheadOfPlay: This metric also only shows up during playback. The number of frames creeps up during playback and settles in at slightly over 300 prefetched frames. The FramePrefetchLatency above will be high (in the 100ms range or so) until the 300 frames are prefetched, at which point the latency will drop down to 30ms or lower. When the storage system is stressed, Premiere Pro is never able to fill this prefetch buffer, and it never gets up to the 300+ frames.

Figure 2. Premiere Pro with Dogears overlay
Test results
With the test environment configured and the individual projects loaded, it was time to see what the system could provide.
With the PowerScale cluster running OneFS 9.4, playback was initiated on each Adobe Premiere workstation. Keep in mind that all the workstations were artificially pointed to a single node in this 3-node F900 cluster. That single F900 node running OneFS 9.4 could handle 10x of the workstations, each playing back 10x UHD streams. That’s 100x streams of UHD ProRes 422 video from one node. Not too shabby.
At 110x streams (11 workstations), no frames were dropped, but the CompleteAheadOfPlay number on all the workstations started to go below 300. Also, the FramePreFetchLatency spiked to over 100 milliseconds. Clearly, the storage node was unable to provide more performance.
After reproducing these results several times to confirm accuracy, we unmounted the storage from each workstation and upgraded the F900 cluster to OneFS 9.5. Time to see how much of a difference the OneFS 9.5 performance boost would make for Premiere Pro.
As before, each workstation loaded a unique project with unique ProRes media. At 100x streams of video, playback chugged along fine. Time to load up additional streams and see where things break. 110, 120, 130, 140… playback from the single F900 node continued to chug along with no drops and acceptable latency. It was only at 150 streams of video that playback began to suffer. By this time, that single F900 node was pumping close to 10GBps out of that single 100 GbE NIC port. These 14x workstations were not entirely saturating the connection, but getting close. And the performance was a 40% bump from the OneFS 9.4 numbers. Impressive.
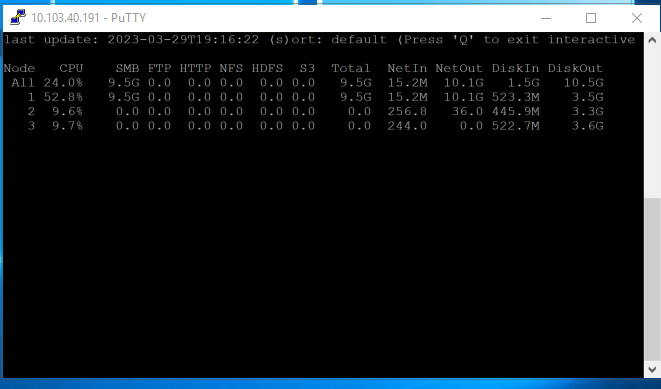
Figure 3. isi statistics output with 140 streams of video from a single node
These results exceeded my expectations going into the project. Getting a 40% performance boost with a code upgrade to existing hardware is impressive. This increase lined up with some of the benchmarking tools used by engineering. But performance from a benchmark tool vs. a real-world application are often two entirely different things. Benchmark tools are particularly inaccurate for video playback where small increases in latency can result in unacceptable results. Because Adobe Premiere is one of the most widely used applications with PowerScale storage, it made sense as a test platform to gauge these differences. For more information about PowerScale storage and media, check out https://Dell.to/media.
Click here to learn more about the author, Gregory Shiff

Distributed Media Workflows with PowerScale OneFS and Superna Golden Copy
Tue, 06 Sep 2022 20:46:32 -0000
|Read Time: 0 minutes
Object is the new core
Content creation workflows are increasingly distributed between multiple sites and cloud providers. Data orchestration has long been a key component in these workflows. With the extra complexity (and functionality) of multiple on-premises and cloud infrastructures, automated data orchestration is more crucial than ever.
There has been a subtle but significant shift in how media companies store and manage data. In the old way, file storage formed the “core” and data was eventually archived off to tape or object storage for long-term retention. The new way of managing data flips this paradigm. Object storage has become the new “core” with performant file storage at edge locations used for data processing and manipulation.
Various factors have influenced this shift. These factors include the ever-increasing volume of data involved in modern productions, the expanding role of public cloud providers (for whom object storage is the default), and media application support.
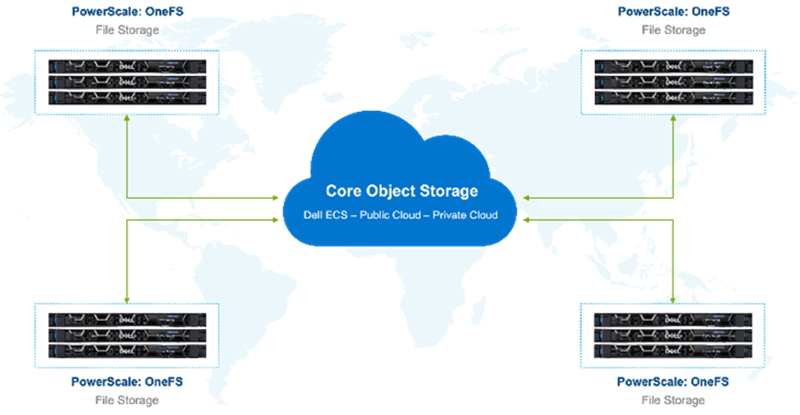
Figure 1. Global storage environment
With this shift in roles, new techniques for data orchestration become necessary. Data management vendors are reacting to these requirements for data movement and global file system solutions.
However, many of these solutions require data to be ingested and accessed through dedicated proprietary gateways. Often this gateway approach means that the data is now inaccessible using the native S3 API.
PowerScale OneFS and Superna Golden Copy provide a way of orchestrating data between file and object that retains the best qualities of both types of storage. Data is available to be accessed on both the performant edge (PowerScale) and the object core (ECS or public cloud) with no lock in at either end.
Further, Superna Golden Copy is directly integrated with the PowerScale OneFS API. The OneFS snapshot change list is used for immediate incremental data moves. Filesystem metadata is preserved in S3 tags.
Golden Copy and OneFS are a solution built for seamless movement of data between locations, file system, and object storage. File structure and metadata are preserved.
Right tool for the job
Data that originates on object storage needs to be accessible natively by systems that can speak object APIs. Also, some subset of data needs to be moved to file storage for further processing. Production data that originates on file storage similarly needs native access. That file data will need to be moved to object storage for long-term retention and to make it accessible to globally distributed resources.
Content creation workflows are spread across multiple teams working in many locations. Multisite productions require distributed storage ecosystems that can span geographies. This architecture is well suited to a core of object storage as the “central source of truth”. Pools of highly performant file storage serve teams in their various global locations.
The Golden Copy GraphQL API allows external systems to control, configure, and monitor Golden Copy jobs. This type of API-based data orchestration is essential to the complex global pipelines of content creators. Manually moving large amounts of data is untenable. Schedule-based movement of data aligns well with some content creation workflows; other workflows require more ad hoc data movement.
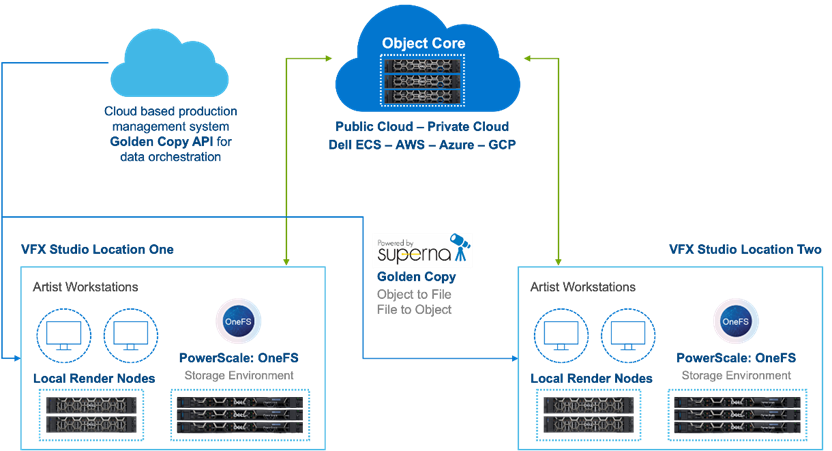
Figure 2. Object Core with GoldenCopy and PowerScale
A large ecosystem of production management tools, such as Autodesk Shotgrid, exist for managing global teams. These tools are excellent for managing projects, but do not typically include dedicated data movers. Data movement can be particularly challenging when large amounts of media need to be shifted between object and file.
Production asset management can trigger data moves with Golden Copy based on metadata changes to a production or scene. This kind of API and metadata driven data orchestration fits in the MovieLabs 2030 vision for software-defined workflows for content creation. This topic is covered in some detail for tiering within a OneFS file system in the paper: A Metadata Driven Approach to On Demand Tiering.
For more information about using PowerScale OneFS together with Superna GoldenCopy, see my full white paper PowerScale OneFS: Distributed Media Workflows.
Author: Gregory Shiff