




VxRail with vSAN Express Storage Architecture (ESA)
vSAN Express Storage Architecture: The New Era. It may well be given the dramatic gains in performance that VMware is claiming (my VxRail with vSAN ESA performance blog will be next month) and the major changes to the capabilities of data services provided in vSAN ESA. It’s important to understand that this is the next step in vSAN’s evolution, not an end. vSAN’s Original Storage Architecture (OSA) has been continuously evolving since it was first released in 2014. vSAN 8.0 Express Storage Architecture is just another small step on that evolutionary journey – well maybe more of a giant leap. A giant leap that VxRail will take along with it.
vSAN OSA was designed at a time when spinning disks were the norm, flash was expensive, double digit multi-core processors were new-ish, and 10Gbit networking was for switch uplinks not servers. Since then, there have been significant changes in the underlying hardware, which vSAN has benefited from and leveraged along the way. Fast forward to today, spinning disk is for archival use, NVMe is relatively cheap, 96 core processors exist, 25Gb networking is the greenfield default with 100Gb networking available for a small premium. Therefore, it is no surprise to see VMware optimizing vSAN to exploit the full potential of the latest hardware, unlocking new capabilities, higher efficiency, and more performance. Does this spell the end of the road for vSAN OSA? Far from it! Both architectures are part of vSAN 8.0, with OSA getting several improvements. The most exciting of which is the Increased Write Buffer Capacity from 600GB to 1.6TB per diskgroup. This will not only increase performance, but equally important also improve performance consistency.
Before you get excited about the performance gains and new capabilities that upgrading to vSAN ESA will unlock on your VxRail cluster, be aware of one important item. vSAN ESA is, for now, greenfield only. This was done to enable vSAN ESA to fully exploit the potential of the latest in server hardware and protocols to deliver new capabilities and performance to meet the ever-evolving demands that business places on today’s IT infrastructure.
Aside from being greenfield only, vSAN ESA has particular hardware requirements. So that you can hit the ground running this New Year with vSAN ESA, we’ve refreshed the VxRail E660N and P670N with configurations that meet or exceed vSAN ESA’s significantly different requirements, enabling you to purchase with confidence:
- Six 3.2TB or 6.4TB mixed-use TLC NVMe devices
- 32 cores
- 512GB RAM
- Two 25Gb NIC ports, with 100Gb recommended for maximum performance. Yes, vSAN ESA will saturate a 25Gb network port. And yes, you could bond multiple 25Gb network ports, but the price delta (including switches and cables) between quad 25Gb and dual 100Gb networking is surprisingly small.
And as you’d expect, VxRail Manager has already been in training and is hitting the ground running alongside you. At deployment, VxRail Manager will recognize this new configuration, deploy the cluster following vSAN ESA best practices and compatibility checks, and perform future updates with Continuously Validated States.
But hardware is only half of the story. What VMware did with vSAN to take advantage of the vastly improved hardware landscape is key. vSAN ESA stands on the shoulders of the work that OSA has done, re-using much of it, but optimizing the data path to utilize today’s hardware. These architectural changes occur in two places: a new log-structured file system, and an optimized log-structured object manager and data structure. Pete Koehler’s blog post An Introduction to the vSAN Express Storage Architecture explains this in a clear and concise manner – and much better than I could. What I found most interesting was that these changes have created a storage paradox of high performing erasure coding with highly valued data services:
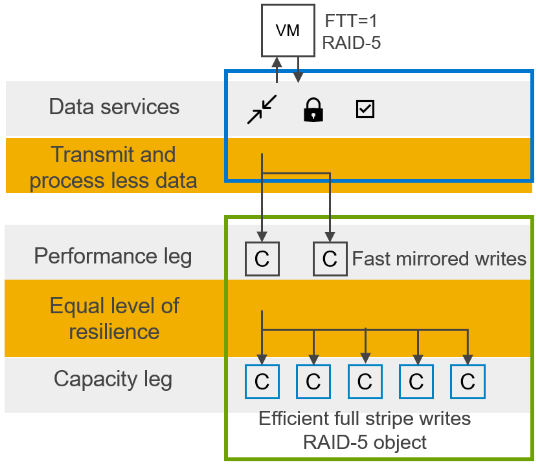
Figure 1. Log structured file system - optimized data handling
- Data services like compression and encryption occur at the highest layer, minimizing process amplification, and lowering processor and network utilization. To put this another way, data services are done once, and the resulting now smaller and encrypted data load is sent over the network to be written on multiple hosts.
- The log-structured file system rapidly ingests data, while organizing it into a full stripe write. The key part here is that full stripe write. Typically, with erasure coding, a partial stripe write is done. This results in a read-modify-write which causes the performance overhead we traditionally associate with RAID5 and RAID6. Thus, full stripe writes enable the space efficiency of RAID5/6 erasure coding with the performance of RAID1 mirroring.
- Snapshots also benefit from the log structured file system, with writes written to new areas of storage and metadata pointers tracking which data belongs to which snapshot. This change enables Scalable, High-Performance Native Snapshots with compatibility for existing 3rd party VDAP backup solutions and vSphere Replication.
Does this mean we get to have our cake and eat it too? This is certainly the case, but check out my next blog where we’ll delve into the brilliant results from the extensive testing by the VxRail Performance team.
Back to the hardware half of the story. Don’t let the cost of mixed-use NVMe drives scare you away from vSAN ESA. The TCO of ESA is actually lower than OSA. There are a few minor things that contribute to this, no SAS controller, and no dedicated cache devices. However, because of ESA’s RAID-5/6 with the Performance of RAID-1, less capacity is needed, delivering significant costs savings. Traditionally, performance and mirroring, required twice the capacity, but ESA RAID6 can deliver comparable performance, with 33% more usable capacity, and better resiliency with a failure to tolerate of two. Even small clusters benefit from ESA with adaptive RAID5, which has a 2+1 data placement scheme for use on clusters with as few as three nodes. As these small clusters grow beyond five nodes, vSAN ESA will adapt that RAID5 2+1 data placement to the more efficient RAID5 4+1 data placement.

Figure 2. Comparing vSAN OSA and ESA on different storage policies against performance and efficiency
Finally, ESA has an ace up its sleeve with the more resource efficient and granular compression with a claimed “up to a 4x improvement over original storage architecture”. ESA’s minimum hardware requirements may seem high, but bear in mind, they are specified to enable ESA to deliver the high performance it is capable of. When running the same workload that you have today on your VxRail with vSAN OSA cluster on a VxRail with vSAN ESA cluster, the resource consumption will be noticeably lower – releasing resources for additional virtual machines and their workloads.
A big shoutout to my technical marketing peers over at VMware for the many great blogs, videos, and other assets they have delivered. I linked to several of them above, but you can find the all of their vSAN ESA material over at core.vmware.com/vsan-esa including a very detailed FAQ, and an updated Foundations of vSAN Architecture video series on YouTube.
vSAN Express Storage Architecture is a giant leap forward for datacenter administrators everywhere and will draw more of them into the world of hyperconverged infrastructure. vSAN ESA on VxRail provides the most effective and secure path for customers to leverage this new technology. The New Era has started, and it is going to be very interesting.
Author: David Glynn, Sr. Principal Engineer, VxRail Technical Marketing
Images courtesy of VMware
For the curious and the planners out there, migrating to vSAN ESA is, as you’d expect, just a vMotion and SvMotion.