




Optimizing Computer Vision Workloads: A Guide to Selecting NVIDIA GPUs


Introduction
Long gone are the days when facilities managers and security personnel were required to be in a control room with their attention locked onto walls of video monitors. The development of lower-cost and more capable video cameras, more powerful data science computing platforms, and the need to reduce operations overhead have caused the deployment of video management systems (VMS) and computer vision analytics applications to skyrocket in the last ten years in all sectors of the economy. Modern computer vision applications can detect a wide range of events without constant human supervision, including overcrowding, unauthorized access, smoke detection, vehicle operation infractions, and more. Better situational awareness of their environments can help organizations achieve better outcomes for everyone involved.
Table 1 – Outcomes achievable with better situational awareness
Increased operational efficiencies | Leverage all the data that you capture to deliver high-quality services and improve resource allocation. |
Optimized safety and security | Provide a safer, more real-time aware environment. |
Enhanced experience | Provide a more positive, personalized, and engaging experience for both customers and employees. |
Improved sustainability | Measure and lower your environmental impact. |
New revenue opportunities | Unlock more monetization opportunities from your data with more actionable insights. |
The technical challenge
Computer vision analytics uses various techniques and algorithms, including object detection, classification, feature extraction, and more. The computation resources that are required for these tasks depend on the resolution of the source video, frame rates, and the complexity of both the scene and the types of analytics being processed. The diagram below shows a simplified set of steps (pipeline) that is frequently implemented in a computer vision application.
Figure 1: Logical processing pipeline for computer vision
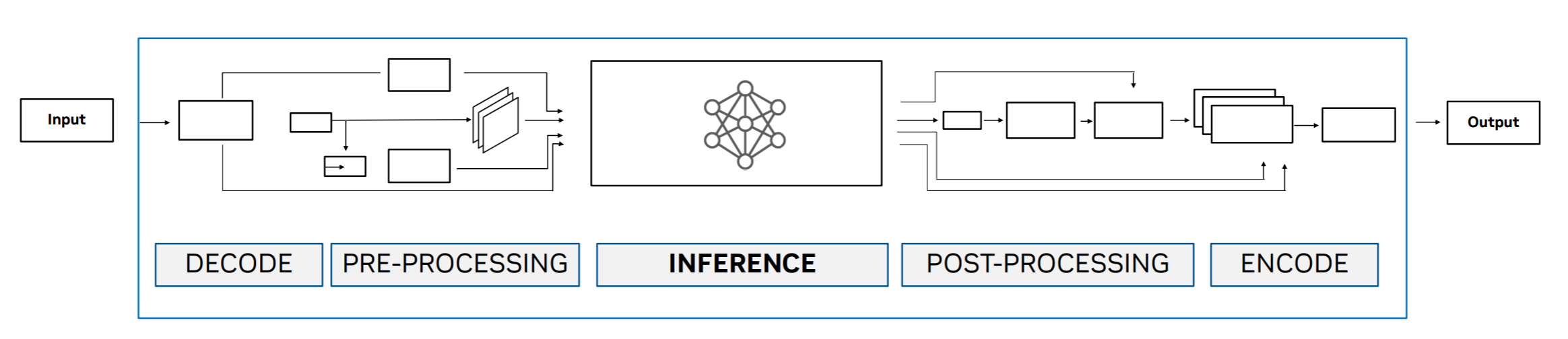
Inference is the step that most people are familiar with. A trained algorithm can distinguish between a passenger automobile and a delivery van, similar to the classic dogs versus cats example often used to explain computer vision. While the other steps are less familiar to the typical user of computer vision applications, they are critical to achieving good results and require dedicated graphics processing units (GPUs). For example, the Decode/Encode steps are tuned to leverage hardware that resides on the GPU to provide optimal performance.
Given the extensive portfolio of NVIDIA GPUs available today, organizations that are getting started with computer vision applications often need help understanding their options. We have tested the performance of computer vision analytics applications with various models of NVIDIA GPUs and collected the results. The remainder of this article provides background on the test results and our choice of model.
Choosing a GPU
The market for GPUs is broadly divided into data center, desktop, and mobility products. The workload that is placed on a GPU when training large image classification and detection models is almost exclusively performed on data center GPUs. Once these models are trained and delivered in a computer vision application, multiple CPU and GPU resource options can be available at run time. Small facilities, such as a small retailer with only a few cameras, can afford to deploy only a desktop computer with a low-power GPU for near real-time video analytics. In contrast, large organizations with hundreds to thousands of cameras need the power of data center-class GPUs.
However, all data center GPUs are not created equal. The table below compares selected characteristics for a sample of NVIDIA data center GPUs. The FP32 floating point calculations per second metric indicates the relative performance that a developer can expect on either model training or the inference stage of the typical pipeline used in a computer vision application, as discussed above.
The capability of the GPU for performing other pipeline elements required for high-performance computer vision tasks, including encoding/decoding, is best reflected by the Media Engines details.
First, consider the Media Engines row entry for the A30 GPU column. There is 1 JPEG decoder and 4 video decoders, but no video encoders. This configuration makes the A30 incompatible with the needs of many market-leading computer vision application vendors' products, even though it is a data center GPU.
Table 2: NVIDA Ampere architecture GPU characteristics
| A2 | A16 | A30 | A40 |
FP32 (Tera Flops) | 4.5 | 4x 4.5 | 10.3 | 37.4 |
Memory (GB) | 16 GDDR6 | 4x 16 GDDR6 | 24 GB HBM2 | 48 GDDR6 with ECC |
Media Engines | 1 video encoder 2 video decoders (includes AV1 decode) | 4 video encoder 8 video decoders (includes AV1 decode) | 1 JPEG decoder 4 video decoders 1 optical flow accelerator | 1 video encoder 2 video decoders (includes AV1 decode) |
Power (Watts) | 40-60 (Configurable) | 250 | 165 | 300 |
Comparing the FP32 TFLOPS between the A30 and A40 shows that the A40 is a more capable GPU for training and pure inference tasks. During our testing, the computer vision applications quickly exhausted the available Media Engines on the A40. Selecting a GPU for computer vision requires matching the available resources needed for computer vision including media engines, available memory, and other computing capabilities that can be different across use cases.
Next, examining the Media Engines description for the A2 GPU column confirms that the product houses 1 video encoder and 2 video decoders. This card will meet the needs of most computer vision applications and is supported for data center use; however, the low number of encoders and decoders, memory, and floating point processing will limit the number of concurrent streams that can be processed. The low power consumption of the A2 increases the flexibility of choice of server for deployment, which is important for edge and near-edge scenarios.
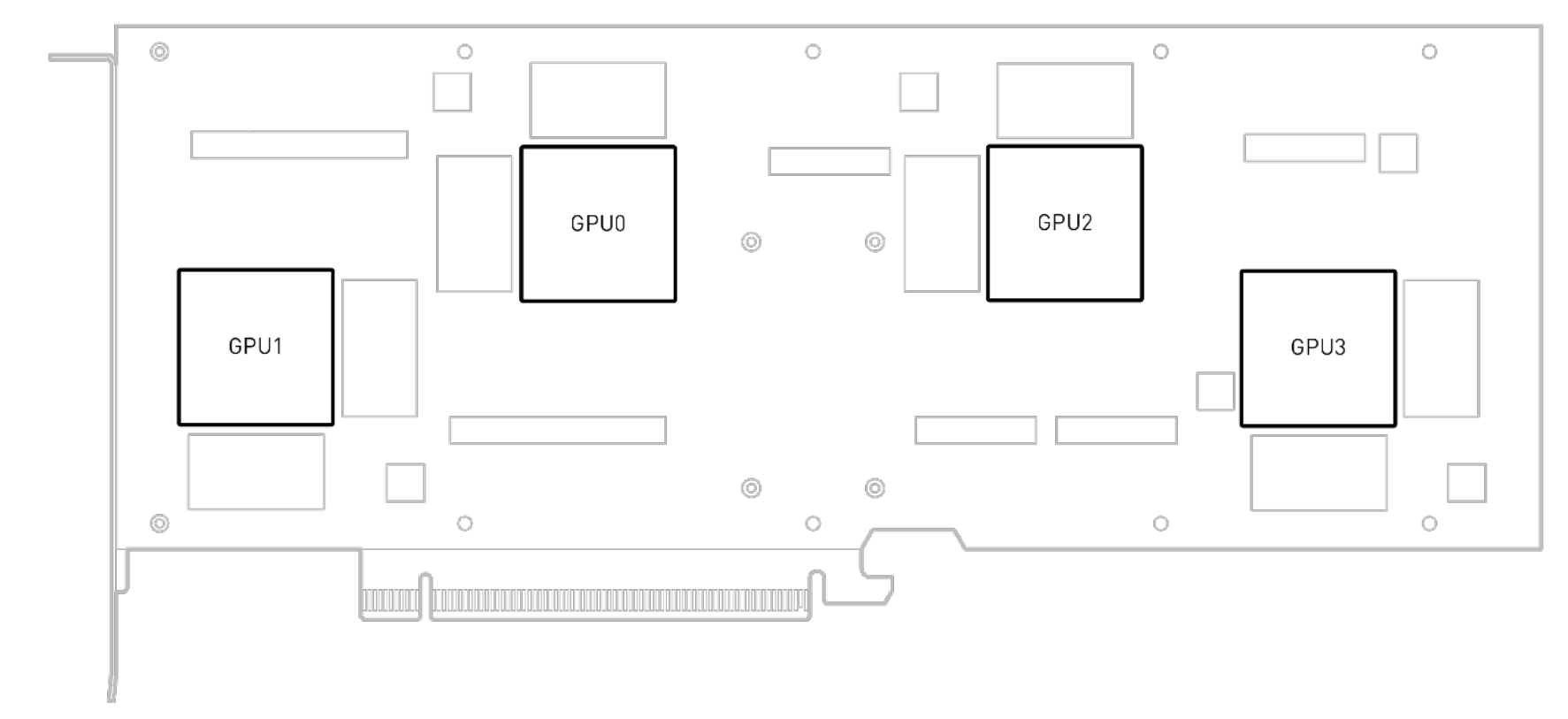
Still focusing on the table above, compare all the characteristics of the A2 GPU column with the A16 GPU. Notice that there are four times the resources on the A16 versus the A2. This can be explained by looking at the diagram below. The A16 was constructed by putting four A2 “engines” on a single PCI card. Each of the boxes labeled GPU0-GPU3 contains all the memory, media engines and other processing capabilities that you would have available to a server that had a standard A2 GPU card installed. Also notice that the A16 requires approximately 4 times the power of an A2.
The table below shows the same metric comparison used in the discussion above for the newest NVIDIA GPU products based on the Ada Lovelace architecture. The L4 GPU offers 2 encoders and 4 decoders for a card that consumes just 72 W. Compared with the 1 encoder and 2 decoder configuration on the A2 at 40 to 60 W, the L4 should be capable of processing many more video streams for less power than two A2 cards. The L40 with 3 encoders and 3 decoders is expected to be the new computer vision application workhorse for organizations with hundreds to thousands of video streams. While the L40S has the same number of Media Engines and memory as the L40, it was designed to be an upgrade/replacement for the A100 Ampere architecture training and/or inference computing leader.
| L4 | L40 | L40S |
FP32 (Tera Flops) | 30.3 | 90.5 | 91.6 |
Memory (GB) | 24 GDDR6 w/ ECC | 48 GDDR6 w/ ECC | 48 GDDR6 w/ ECC |
Media Engines | 2 video encoder 4 video decoders 4 JPEG decoder (includes AV1 decode) | 3 video encoder 3 video decoders
| 3 video encoder 3 video decoders
|
Power (Watts) | 72 | 300 | 350 |
Conclusion
In total seven different NVIDIA GPU cards were discussed that are useful for CV workloads. From the Ampere family of cards we found that the A16 performed well for a wide variety of CV inference workloads. The A16 provides a good balance of video Decoders/Encoders, CUDA cores and memory for computer vision workloads.
For the newer Ada Lovlace family of cards, the L40 looks like a well-balanced card with great throughput potential. We are currently testing out this card in our lab and will provide a future blog on its performance for CV workloads.
References
A2 - https://www.nvidia.com/content/dam/en-zz/solutions/data-center/a2/pdf/a2-datasheet.pdf
A16 - https://images.nvidia.com/content/Solutions/data-center/vgpu-a16-datasheet.pdf
A30 - https://www.nvidia.com/en-us/data-center/products/a30-gpu/
A40 - https://images.nvidia.com/content/Solutions/data-center/a40/nvidia-a40-datasheet.pdf
L4 - https://www.nvidia.com/en-us/data-center/l4/