




Introducing NVMe over TCP (NVMe/TCP) in PowerFlex 4.0

Anyone who has used or managed PowerFlex knows that an environment is built from three lightweight software components: the MDM, the SDS, and the SDC. To deploy a PowerFlex environment, the typical steps are:
- Deploy an MDM management cluster
- Create a cluster of storage servers by installing and configuring the SDS software component
- Add Protection Domains and Storage Pools
- Install the SDC onto client systems
- Provision volumes and away you go!!*
*No requirement for multipath software, this is all handled by the SDC/SDS
There have been additions to this over the years, such as an SDR component for replication and the configuration of NVDIMM devices to create finegranularity storage pools that provide compression. Also added are PowerFlex rack and appliance environments. This is all automated with PowerFlex Manager. Fundamentally, the process involves the basic steps outlined above.
So, the question is why would we want to change anything from an elegant solution that is so simple?
This is due to where the SDC component ‘lives’ in the operating system or hypervisor hosting the application layer. Referring to the diagram below, it shows that the SDC must be installed in the kernel of the operating system or hypervisor, meaning that the SDC and the kernel must be compatible. Also the SDC component must be installed and maintained, it does not just ‘exist’.
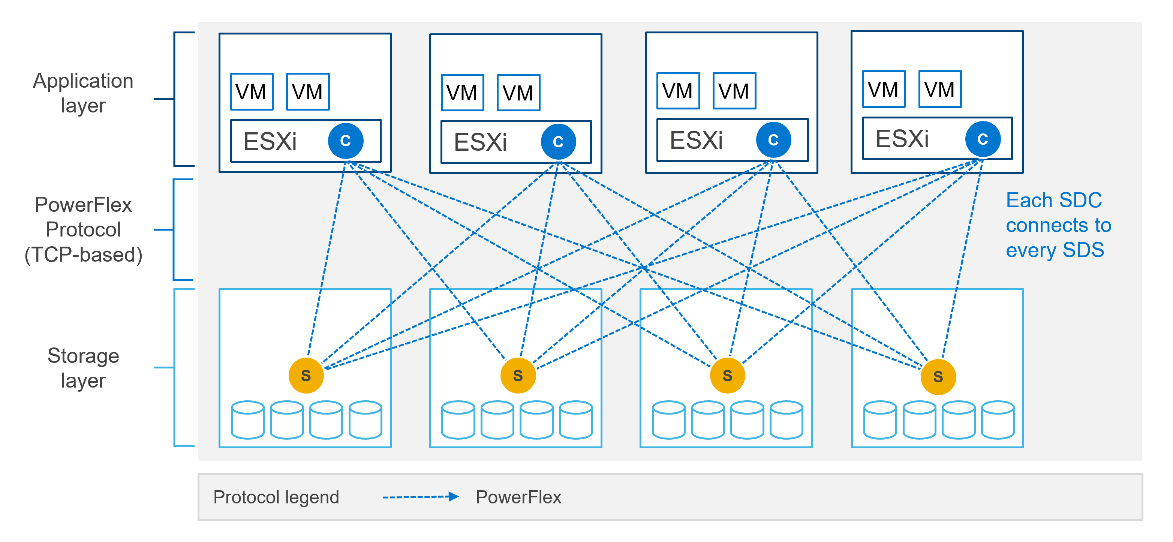
In most cases, this is fine and there are no issues whatsoever. The PowerFlex development team keeps the SDC current with all the major operating system versions and customers are happy to update the SDC within their environment when new versions become available.
There are, however, certain cases where manual deployment and management of the SDC causes significant overhead. There are also some edge use cases where there is no SDC available for specific operating systems. This is why the PowerFlex team has investigated alternatives.
In recent years, the use of Non-Volatile Memory Express (NVMe) has become pervasive within the storage industry. It is seen as the natural replacement to SCSI, due to its simplified command structure and its ability to provide multiple queues to devices, aligning perfectly with modern multi-core processors to provide very high performance.
NVMe appeared initially as a connection directly to disks within a server over a PCIe connection, progressing to being used over a variety of fabric interconnects.
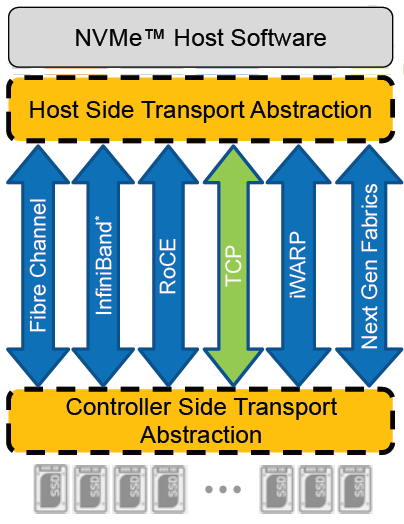
Added to this is the widespread support for NVMe/TCP across numerous operating system and hypervisor vendors. Most include support natively in their kernels.
There have been several announcements by Dell Technologies over the past months highlighting NVMe/TCP as an alternative interconnect to iSCSI across several of the storage platforms within the portfolio. It is therefore a natural progression for PowerFlex to also provide support for NVMe/TCP, particularly because it already uses a TCP-based interconnect.
PowerFlex implements support for NVMe/TCP with the introduction of a new component installed in the storage layer called the SDT.
The SDT is installed at the storage layer. The NVMe initiator in the operating system or hypervisor communicates with the SDT, which then communicates with the SDS. The NVMe initiator is part of the kernel of the operating system or hypervisor.
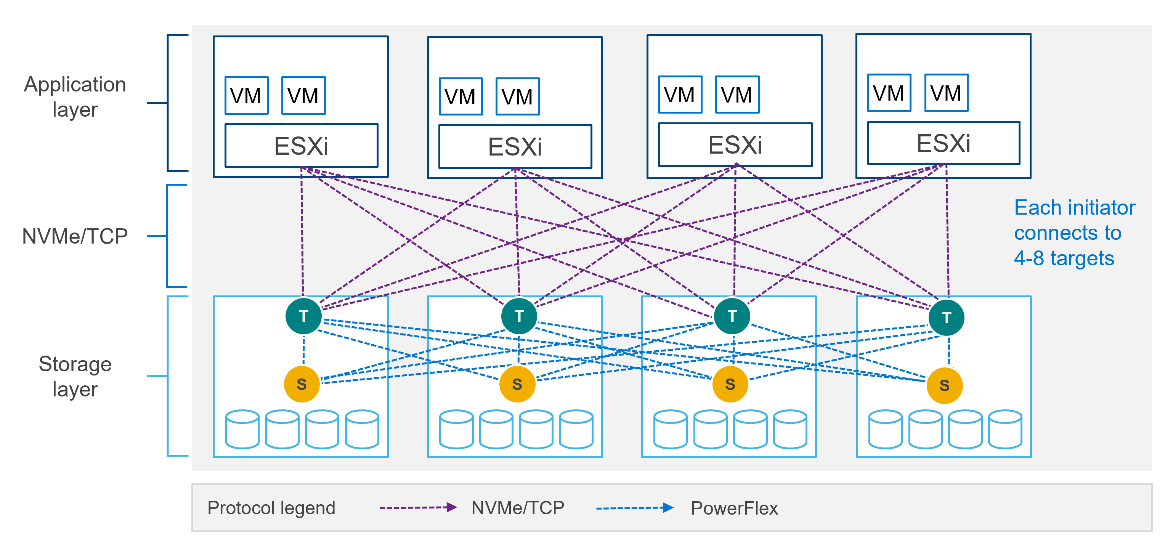
Of course, because PowerFlex is so ‘flexible,’ both connection methods (SDC and NVMe/TCP) are supported at the same time. The only limitation is that a volume can only be presented using one protocol or the other.
For the initial PowerFlex 4.0 release, the VMware ESXi hypervisor is supported. This support starts with ESXi 7.0 U3f. Support for Linux TCP initiators is currently in “tech preview” as the initiators continue to grow and mature, allowing for all failure cases to be accounted for.
NVMe/TCP is a very powerful solution for the workloads that take advantage of it. If you are interested in discovering more about how PowerFlex can enhance your datacenter, reach out to your Dell representative.
Authors:
Kevin M Jones, PowerFlex Engineering Technologist.
Tony Foster, Senior Principal Technical Marketing Engineer.
Twitter: @wonder_nerd
LinkedIn