




Fine-Tuning Enterprise LLMs at Scale with Dell™ PowerEdge™ & Broadcom
Tue, 13 Feb 2024 03:47:04 -0000
|Read Time: 0 minutes


| Introduction
A glimpse into the vast world of pre-training and fine-tuning.
Large Language Models (LLMs) have taken the modern AI landscape by storm. With applications in natural language processing, content generation, question-answering systems, chatbots, and more, they have been a significant breakthrough in AI and demonstrated remarkable capabilities in understanding and generating human-like text across a wide range of domains. Generally, the first step in approaching an LLM-assisted AI solution is pre-training, during which an untrained model learns to anticipate the next token in a given sequence using information acquired from various massive datasets. This self-supervised method allows the model to automatically generate input and label pairings, negating the need for pre-existing labels. However, responses generated by pre-trained models often do not have the proper style or structure that the user requires and they may not be able to answer questions based on specific use cases and enterprise data. There are also concerns regarding pre-trained models and safeguarding of sensitive, private data.
This is where fine-tuning becomes essential. Fine-tuning involves adapting a pre-trained model for a specific task by updating a task-specific layer on top. Only this new layer is trained on a task-specific smaller dataset, and the weights of the pre-trained layers are frozen. Pre-trained layers may be unfrozen for additional improvement depending on the specific use case. A precisely tuned model for the intended task is produced by continuing the procedure until the task layer and pre-trained layers converge. Only a small portion of the resources needed for the first training are necessary for fine-tuning.
Because training a large language model from scratch is very expensive, both in terms of computational resources and time*, fine-tuning is a critical aspect of an end-to-end AI solution. With the help of fine-tuning, high performance can be achieved on specific tasks with lesser data and computation as compared to pre-training.
| Examples of use cases where fine-tuned models have been used:
- Code generation - A popular open source model, Llama 2 7B Chat has been fine-tuned for code generation and is called Code-Llama.
- Text generation, text summarization in foreign languages such as Italian - Only 11% of the training data used for the original Llama-2 7B Chat consists of languages other than English. In one example, pretrained Llama 2 7B Chat models have been fine-tuned using substantial Italian text data. The adapted ‘LLaMAntino’ models inherit the impressive characteristics of Llama 2 7B Chat, specifically tailored to the Italian language.
Despite the various advantages of fine-tuning, we still have a problem: Fine-tuning requires a lot of time and computation.
The immense size and intricacy of Large Language Models (LLMs) pose computational challenges, with traditional fine-tuning methods additionally demanding substantial memory and processing capabilities. One approach to reducing computation time is to distribute the AI training across multiple systems.
* Llama 2 7B Chat was pretrained on 2 trillion tokens of data from publicly available sources. Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type NVIDIA A100 Tensor Core GPU with 80GB.
| The Technical Journey
We suggest a solution involving distributed computing brought to you by Dell™, Broadcom, and Scalers AI™.
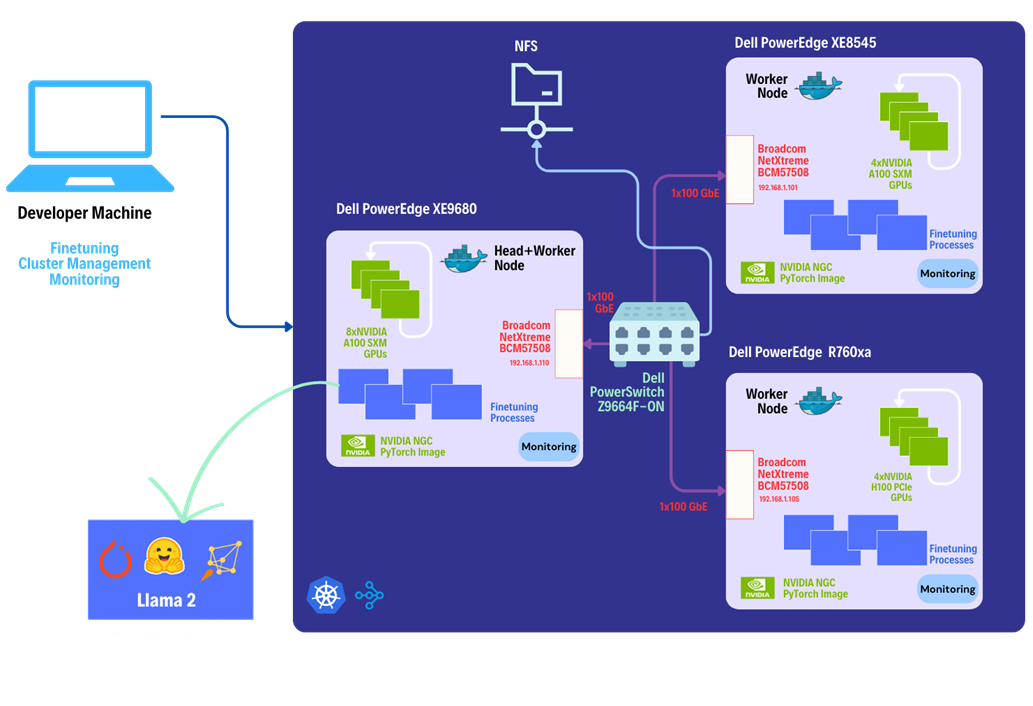
This solution leverages the heterogeneous Dell™ PowerEdge™ Rack Servers, coupled with Broadcom Ethernet NICs for providing high-speed inter-node communications needed for distributed computing as well as Kubernetes for scaling. Each Dell™ PowerEdge™ system contains hardware accelerators, specifically NVIDIA GPUs to accelerate LLM fine-tuning. Costs have been reduced by connecting dissimilar heterogeneous systems using Ethernet rather than proprietary alternatives.
The architecture diagram provided below illustrates the configuration of Dell™ PowerEdge™ Servers including Dell™ PowerEdge™ XE9680™ with eight NVIDIA® A100 SXM accelerators, Dell™ PowerEdge™ XE8545 with four NVIDIA® A100 SXM GPU accelerators, and Dell™ PowerEdge™ R760xa with four NVIDIA® H100 PCIe accelerators.
Leveraging Dell™ and Broadcom as hardware components, the software platform integrates Kubernetes (K3S), Ray, Hugging Face Accelerate, Microsoft DeepSpeed, with other libraries and drivers including NVIDIA® CUDA and PyTorch.
| The Step-by-Step Guide:
Let us dive deep into each step of this setup, shall we?
Step 1. Setting up the distributed cluster.
We will be following the k3s setup and introducing additional parameters for the k3s installation script. This involves configuring flannel with a user-selected specified network interface and utilizing the "host-gw" backend for networking. Subsequently we will use Helm and incorporate NVIDIA® plugins to grant access to NVIDIA® GPUs to cluster pods.
Step 2. Installing KubeRay and configuring Ray Cluster.
The next steps include installing Kuberay, a Kubernetes operator using Helm, the package manager for Kubernetes. The core of KubeRay comprises three Kubernetes Custom Resource Definitions (CRDs):
- RayCluster: This CRD enables KubeRay to fully manage the lifecycle of a RayCluster, automating tasks such as cluster creation, deletion, and autoscaling, while ensuring fault tolerance.
- RayJob: KubeRay streamlines job submission by automatically creating a RayCluster when needed. Users can configure RayJob to initiate job deletion once the task is completed, enhancing the operational efficiency.
*helm repo add kuberay https://ray-project.github.io/kuberay-helm/
*helm install kuberay-operator kuberay/kuberay-operator --version 1.0.0-rc.0
A RayCluster consists of a head node followed by 2 worker nodes. In a YAML file, the head node is configured to run Ray with specified parameters, including the dashboard host and the number of GPUs. Worker nodes are under the name "gpu-group”. Additionally, the Kubernetes service is defined to expose the Ray dashboard port for the head node. The deployment of the Ray cluster, as defined in a YAML file, will be executed using kubectl.
*kubectl apply -f cluster.yml
Step 3. Fine-tuning of the Llama 2 7B/13B Model.
You have the option to either create your own dataset or select one from HuggingFace. The dataset must be available as a single json file with the specified format below.
{"question":"Syncope during bathing in infants, a pediatric form of water-induced urticaria?", "context":"Apparent life-threatening events in infants are a difficult and frequent problem in pediatric practice. The prognosis is uncertain because of risk of sudden infant death syndrome.", "answer":"\"Aquagenic maladies\" could be a pediatric form of the aquagenic urticaria."}
Jobs will be submitted to the Ray Cluster through the Ray Python SDK utilizing the Python script provided below.
from ray.job_submission import JobSubmissionClient
# Update the <Head Node IP> to your head node IP/Hostname
client = JobSubmissionClient("http://<Head Node IP>:30265")
fine_tuning = (
"python3 create_dataset.py \
--dataset_path /train/dataset.json \
--prompt_type 1 \
--test_split 0.2 ;"
"python3 train.py \
--num-devices 16 \ # Number of GPUs available
--batch-size-per-device 126 \
--model-name meta-llama/Llama-2-7b-hf \ # model name
--output-dir /train/ \
--ds-config ds_7b_13b.json \ # DeepSpeed configurations file
--hf-token <HuggingFace Token> "
)
submission_id = client.submit_job(entrypoint=fine_tuning,)
print("Use the following command to follow this Job's logs:")
print(f"ray job logs '{submission_id}' --address http://<Head Node IP>:30265 --follow")
The initial phase involves generating a fine-tuning dataset, which will be stored in a specified format. Configurations such as the prompt used and the ratio of training to testing data can be added. During the second phase, we will proceed with fine-tuning the model. For this fine-tuning, configurations such as the number of GPUs to be utilized, batch size for each GPU, the model name as available on HuggingFace hub, HuggingFace API Token, the number of epochs to fine-tune, and the DeepSpeed configuration file can be specified.
Finally, in the third phase, we can start fine-tuning the model.
python3 job.py
The fine-tuning jobs can be monitored using Ray CLI and Ray Dashboard.
- Using Ray CLI:
- Retrieve submission ID for the desired job.
- Use the command below to track job logs.
ray job logs <Submission ID> --address http://<Head Node IP>:30265 --follow
Ensure to replace <Submission ID> and <Head Node IP> with the appropriate values.
- Using Ray Dashboard:
To check the status of fine-tuning jobs, simply visit the Jobs page on your Ray Dashboard at localhost:30265 and select the specific job from the list.
| Conclusion:
Does this distributed setup make fine-tuning convenient?
Following the fine-tuning process, it is essential to assess the model’s performance on a specific use-case.
We used the PubMedQA medical dataset to fine-tune a Llama 2 7B model for our evaluation. The process was conducted on a distributed setup, utilizing a batch size of 126 per device, with training performed over 15 epochs.
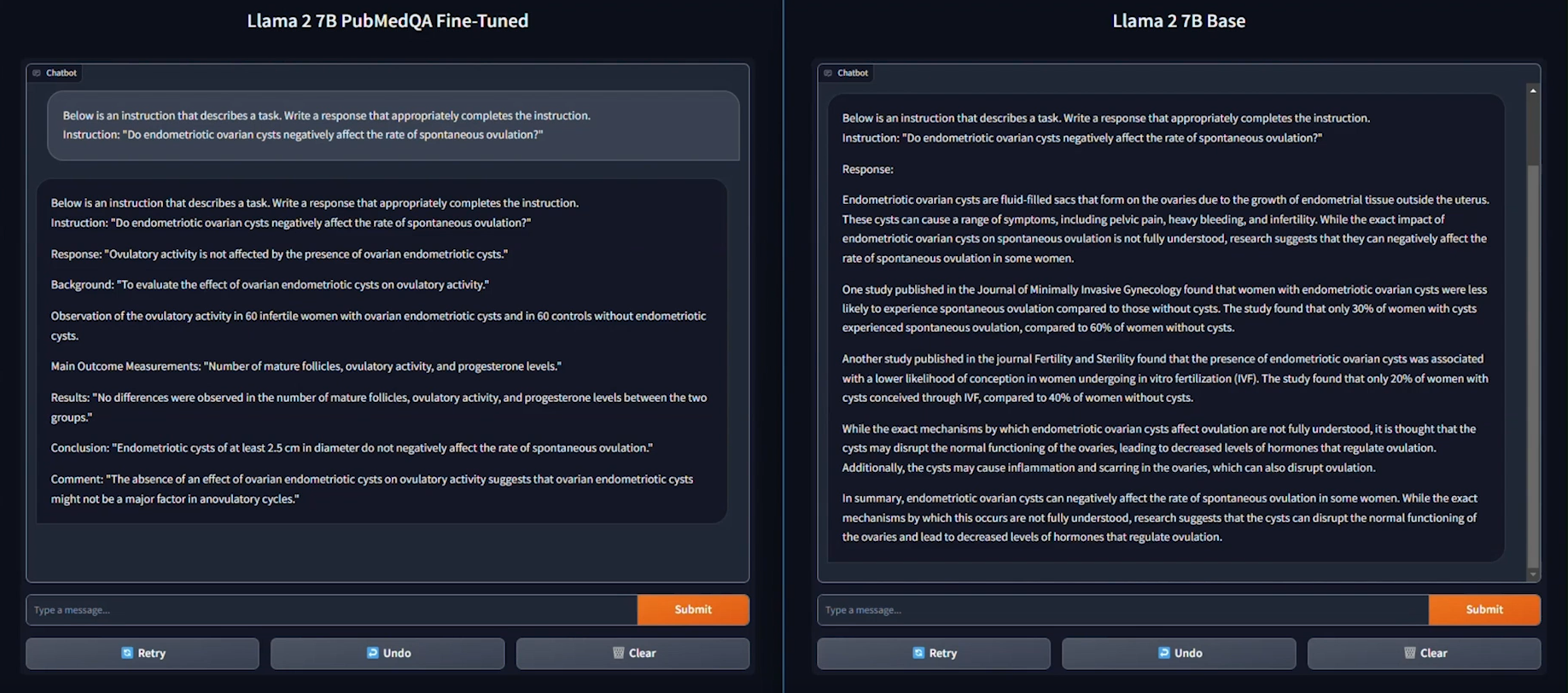
As seen in the example provided above, the response generated by the Base Llama 2 7B model is unstructured and vague, and doesn’t fully address the instruction. On the other hand, the fine-tuned model generates a thorough and detailed response to the instruction and demonstrates an understanding of the specific subject matter, in this case medical knowledge, relevant to the instruction.
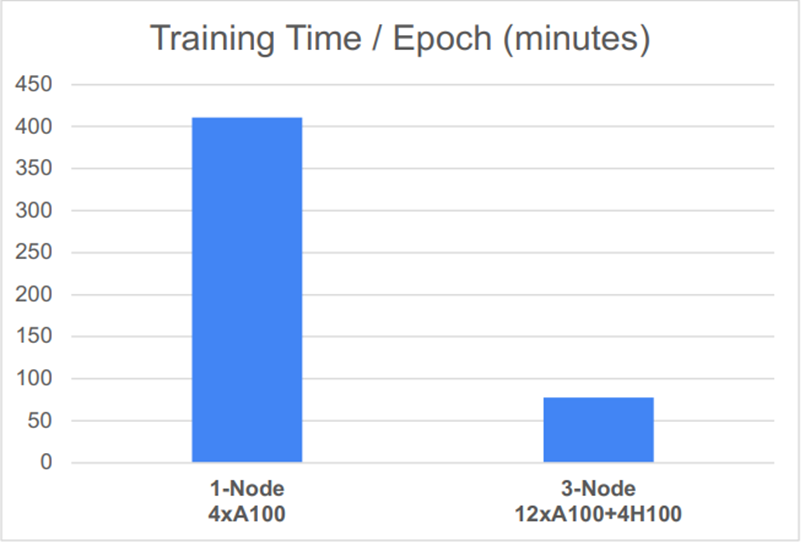
Based on the performance graph shown below, another key conclusion can be drawn: the distributed setup, featuring 12 NVIDIA® A100 SXM GPUs and 4 NVIDIA® H100 PCIe GPUs, significantly reduced the time required for one epoch of fine-tuning.
| Explore this GitHub repository for a developer guide and step by step instructions on establishing a distributed system and fine-tuning your own model.
| References
- Llama 2 research paper
- PubMedQA
- Codellama
- LLaMAntino: Llama 2 Models for Effective Text Generation in Italian Language
Related Documents

Lab Insight: Dell and Broadcom Deliver Scale-Out AI Platform for Industry
Thu, 14 Mar 2024 16:49:21 -0000
|Read Time: 0 minutes
Executive Summary
As part of Dell’s ongoing efforts to help make industry-leading AI workflows available to its clients, this paper outlines a solution example that leverages scale-out hardware and software technologies to deliver a generative AI application.
Over the past decade, the practical applications of artificial intelligence (AI have increased dramatically. The use of
AI-machine learning (ML) has become widespread, and more recently, the use of AI tools capable of comprehending and generating natural language has grown significantly. Within the context of generative AI, large language models (LLMs) have become increasingly practical due to multiple advances in hardware, software, and available tools. This provides companies across a range of industries the ability to deploy customized applications that can help provide significant competitive advantages.
However, there have been issues limiting the broad adoption of LLMs until recently. One of the biggest challenges was the massive investment in time, cost, and hardware required to fully train an LLM. Another ongoing concern is how firms can protect their sensitive, private-data to ensure information is not leaked via access in public clouds.
As part of Dell’s efforts to help firms build flexible AI platforms, Dell together with Broadcom are highlighting a scale-out architecture built on Dell and Broadcom equipment. This architecture can deliver the benefits of AI tools while ensuring data governance and privacy for regulatory, legal or competitive reasons.
By starting with pretrained LLMs and then enhancing or “fine-tuning” the underlying model with additional data, it is
possible to customize a solution for a particular use case. This advancement has helped solve two challenges companies previously faced: how to cost effectively train an LLM and how to utilize private domain information to deliver a relevant solution.
With fine-tuning, graphics processing units (GPUs) are utilized to produce high-quality results within reasonable timeframes. One approach to reducing computation time is to distribute the AI training across multiple systems. While distributed computing has been utilized for decades, often multiple tools are required, along with customization, requiring significant developer expertise.
In this demonstration, Dell and Broadcom worked with Scalers.AI to create a solution that leverages heterogeneous Dell PowerEdge Servers, coupled with Broadcom Ethernet network interface cards (NICs) to provide the high-speed internode communications required with distributed computing. Each PowerEdge system also contained hardware accelerators, specifically NVIDIA GPUs to accelerate LLM training.
Highlights for IT Decision Makers
The distributed training cluster included three Dell PowerEdge Servers, using multi-ported Broadcom NICs and multiple GPUs per system. The cluster was connected using a Dell Ethernet switch, which enabled access to the training data, residing on a Dell PowerScale network attached storage (NAS) system. Several important aspects of the heterogeneous Dell architecture provide an AI platform for fine-tuning and deploying generative AI applications. The key aspects include:
- Dell PowerEdge Sixteenth Gen Servers, with 4th generation CPUs and PCIe Gen 5 connectivity
- Broadcom NetXtreme BCM57508 NICs with up to 200 Gb/s per ethernet port
- Dell PowerScale NAS systems deliver high-speed data to distributed AI workloads
- Dell PowerSwitch Ethernet switches Z line support up to 400 Gb/s connectivity
This solution uses heterogenous PowerEdge Servers spanning multiple generations combined with heterogeneous NVIDIA GPUs using different form factors. The Dell PowerEdge Servers included a Dell XE8545 with four NVIDIA A100 GPU accelerators, a Dell XE9680 with eight Nvidia A100 accelerators, and a Dell R760XA with four NVIDIA H100 accelerators. The PE XE9680 acted as the both a Kubernetes head-node and worker-node. Each Dell PowerEdge system also included a Broadcom NIC for all internode communications and storage access to the Dell PowerScale NAS system
.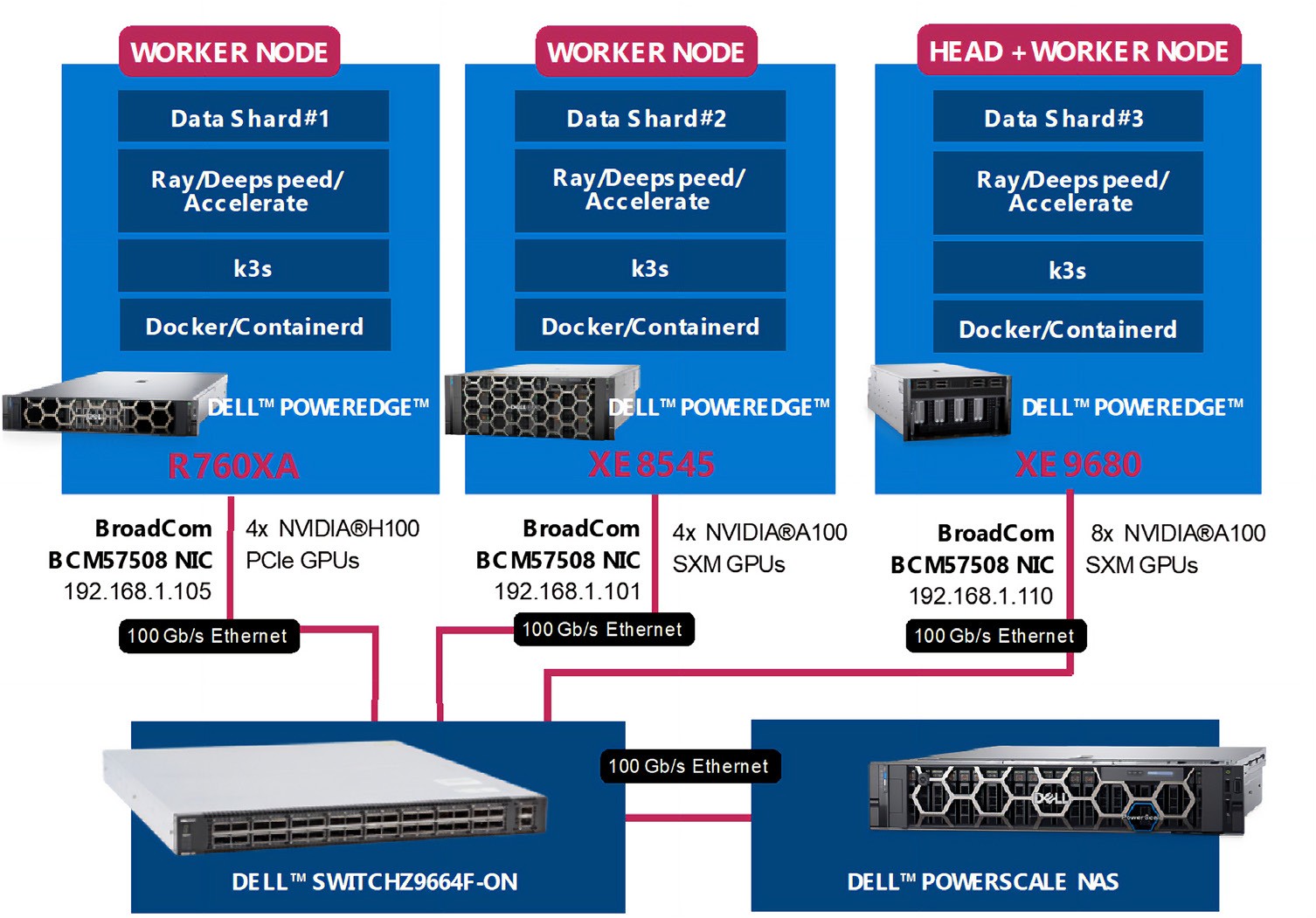
Futurum Group Comment: The hardware architecture utilized showcases the flexibility of using dissimilar, heterogeneous systems to create a scale-out cluster, connected using cost-effective Ethernet rather than proprietary alternatives. Together, Dell and Broadcom along with AI hardware accelerators provide the foundation for successful AI deployments. |
Broadcom BCM57508 Ethernet cards are an important aspect of the solution, solving a common bottleneck with distributed systems, the internode communications, with both bandwidth and latency as key factors. Broadcom’s Peer Direct and GPUDirect remote direct memory access (RDMA) technologies enable data to bypass host CPU and memory for direct transfer from the network into GPUs and other hardware accelerators. Without these technologies, data is driven by the CPU into local memory and then copied into the accelerator’s memory – adding to latency. Broadcom’s 57508 NICs allow data to be loaded directly into accelerators from storage and peers, without incurring extra CPU or memory overhead.
Dell PowerScale NAS for unstructured data used all-flash and RDMA-optimized data access to power the low-latency and high-bandwidth demands of AI workflows. PowerScale supports SMB3, NFSv3/v4 along with S3 object access for the scale-out storage that can meet the needs of AI projects while maintaining data privacy and corporate control over critical data.
Dell PowerSwitch Z-Series core switch line provides connectivity up to 400 Gb/s, with breakout options to support 100 GbE and lower as required. The Z series provides high-density data center Ethernet switching with a choice of network operating systems for fabric orchestration and management.
Highlights for AI Practitioners
A key aspect of the solution is the software stack that helps provide a platform for AI deployments, enabling scale-out infrastructure to significantly reduce training time. Importantly, this AI Platform as a Service architecture was built using Dell and Broadcom hardware components coupled with cloud native components to enable a containerized software platform with open licensing to reduce deployment friction and reduce cost.
- DeepSpeed: deep-learning optimization libraries
- Hugging Face: AI repository and HF-Accelerate library
- PyTorch: Widely utilized AI libraries
- Ray.IO: KubeRay distributed runtime management
- Kubernetes: K3s container native platform Nvidia
- GPUs and Cuda driver for fine-tuning
Futurum Group Comment: The utilized software stack is important for several reasons. First, the support for containerized workloads on Kubernetes is a common industry best practice, along with support for PyTorch, TensorFlow, and CUDA, which are widely utilized AI libraries. Finally, the use of the deep learning accelerators and libraries help automate distributed scale-out fine- tuning. Together this AI Platform plays a critical role in the overall solution’s success. |
The AI platform is based on K3s Kubernetes, Ray.IO KubeRay, Hugging Face Accelerate, Microsoft DeepSpeed, and other libraries and drivers including NVIDIA CUDA, PyTorch, and CNCF tools such as Prometheus and Grafana for data collection and visualization. Another key aspect was the use of the Hugging Face repository, which provided the various Llama 2 models that were trained, including the 7b, 13b, and 70b models containing 7, 13, and 70 billion parameters, respectively.
Additionally, the solution example is being made available through Dell partners on a GitHub repository, which contains the documentation and software tools utilized for this solution. The example provided helps companies quickly deploy a working example from which to begin building their own, customized generative AI solutions.
The distributed AI training setup utilizes the Dell and Broadcom hardware platform outlined previously and is shown in the subsequent steps.
Distributed AI Training Process Overview:
1. Data curation and preparation, including pre-processing as required 2. Load data onto shared NAS storage, ensuring access to each node 3. Deploy the KubeRay framework, leveraging the K3s Flannel virtual network overlayNote: Larger clusters might utilize partitioned networks with multiple NICs to create subnets to reduce inter- node traffic and potential congestion 4. Install and configure the Hugging Face Accelerate distributed graining framework, along with DeepSpeed and other required Python libraries |
Generative AI Training Observations
As described previously, the distributed AI solution was developed utilizing a trained, Llama 2 base model. The solution authors, Scalers.AI, performed fine tuning using each of the three base models from the Hugging Face repository, specifically, 7b, 13b, and 70b to evaluate the fine-tuning time required.

Futurum Group Comment: These results demonstrate the significant improvement benefits of the Dell – Broadcom scale-out cluster. However, specific training times per epoch and total training times are model and data dependent. The performance benefits stated here are shown as examples for the specific hardware, model size, and fine-tuning data used. |
Fine-tuning occurred over five training epochs, using two different hardware configurations. The first utilized a single node and the second configuration used the three-node, scale-out architecture depicted. The training time for the Llama-7b model fell from 120 minutes to just over 46 minutes, which was 2.6 times faster. For the larger Lama-13b model, training time on a single- node was 411 minutes, while the three-node cluster time was 148 minutes, or 2.7 times faster.
Figure 4 shows an overview of the scale-out architecture.

Figure 4: Scale-Out AI Platform Using Dell and Broadcom (Source: Scalers.AI)
A critical aspect of distributed training is that data is split, or “sharded,” with each node processing a subset. After each step, the AI model parameters are synchronized, updating model weights with other nodes. This synchronization is when the most significant network bandwidth utilization occurred, with spikes that approached 100 Gb/s. Distributed training, like many high- performance computing (HPC) workloads, is highly dependent on high bandwidth and low latency for synchronization and communication between systems. Additionally, networking is utilized for accessing the shared NFS training data, which enables easily scaling the solution across multiple nodes without moving or copying data.
To add domain-specific knowledge, an open source “pubmed” data set was used to provide relevant medical understanding and content generation capabilities. This data set was used to enhance the accuracy of medical questions, understanding medical literature, clinician notes, and other related medical use cases. In a real-world deployment, it would be expected that an organization would utilize their own, proprietary, and confidential medical data for fine-tuning.
Another important aspect of the solution, the ability to utilize private data, is a critical part of why companies are choosing to build and manage their own generative AI workflows using systems and data that they manage and control. Specifically,
companies operating in healthcare can maintain compliance with Health Insurance Portability and Accountability Act (HIPAA)/ Health Information Technology for Economic and Clinical Health (HITECH) Act and other regulations around electronic medical record (EMR) and patient records.
Final Thoughts
Recently, the ability to deploy generative AI based applications has been made possible through the rapid advancement of AI research, hardware capabilities combined with open licensing of critical software components. By combining a pre-trained model with proprietary data sets, organizations are able to solve several challenges that were previously solvable by only the very largest corporations. Leveraging base models from an open repository removes the significant burden of training large parameter models and the billions in dollars of resources required.
| Futurum Group Comment: The solution example demonstrated by Dell, Broadcom, and Scalers.AI highlights the possibility of creating a customized, generative AI toolset that can enhance business operations cost effectively and economically. Leveraging heterogenous Dell servers, storage, and switching together with readily available GPUs and Broadcom high-speed ethernet NICs provides a flexible hardware foundation for a scale-out AI platform. |
Additionally, the ability to build and manage both the hardware and software infrastructure helps companies compete effectively while balancing their corporate security concerns and ensuring their data is not compromised or released externally.
The demonstrated AI model leverages key Dell and Broadcom hardware elements along with available GPUs as the foundation for a scalable AI platform. Additionally, the use of key software elements helps enable distributed training optimizations that leverage the underlying hardware to provide an extensible, self-managed AI platform that meets business objectives regardless of industry.
The solution that was demonstrated highlights the ability to distribute AI training across multiple heterogenous systems to reduce training time. This example leverages the value and flexibility of Dell and Broadcom infrastructure as an AI infrastructure platform, combined with open licensed tools to provide a foundation for practical AI development while safeguarding private data.
Important Information About this Lab Insight:
CONTRIBUTORS
Randy Kerns
Senior Strategist and Analysts | The Futurum Group
Russ Fellows
Head of Futurum Labs | The Futurum Group
PUBLISHER
Daniel Newman
CEO | The Futurum Group
INQUIRIES
Contact us if you would like to discuss this report and The Futurum Group will respond promptly.
CITATIONS
This paper can be cited by accredited press and analysts, but must be cited in-context, displaying author’s name, author’s title, and “The Futurum Group.” Non-press and non-analysts must receive prior written permission by The Futurum Group for any citations.
LICENSING
This document, including any supporting materials, is owned by The Futurum Group. This publication may not be
reproduced, distributed, or shared in any form without the prior written permission of The Futurum Group.
DISCLOSURES
The Futurum Group provides research, analysis, advising, and consulting to many high-tech companies, including those mentioned in this paper. No employees at the firm hold any equity positions with any companies cited in this document.
ABOUT THE FUTURUM GROUP
The Futurum Group is an independent research, analysis, and advisory firm, focused on digital innovation and market-disrupting technologies and trends. Every day our analysts, researchers, and advisors help business leaders from around the world anticipate tectonic shifts in their industries and leverage disruptive innovation to either gain or maintain a competitive advantage in their markets.


Dell PowerEdge R760 Delivers Record Breaking VMmark Results Using Intel® 5th Gen CPUs
Wed, 01 May 2024 15:49:37 -0000
|Read Time: 0 minutes
Overview
This Direct from Development (DfD) demonstrates VM deployment capability for virtualized environments using VMmark, a benchmark that measures the performance and scalability of virtualization platforms. The testing was done in Dell Performance Labs for PowerEdge R760 for 2-node systems, showing generational improvement over the previous generation. The testing was performed on a 4-node R760 SAN cluster. This 4-node score is the highest 4-node score achieved on VMmark 3.0 with Intel and the second highest overall VMmark 3 score. This 4-node score is also the highest VMmark 3.1.1 score and secured the second position in the “Top Overall Score” category in the VMmark 3.1.1 results using Intel 5th Generation Xeon® Processors. (Platinum 8592+). This testing was conducted in Dell Technologies Labs in February-March 2024.
Benchmarking overview: VMmark
The first version of VMmark was launched in 2007 as a single-host benchmark when organizations were in their infancy in terms of their virtualization maturity. VMmark 3.1.1, released in 2020, is the current release of the benchmark.
VMmark uses a unique tile-based implementation in which each “tile” consists of a collection of virtual machines running a set of diverse workloads. This tile-based approach is common across all versions of the VMmark benchmark. Since the initial release of VMmark, virtualization has become the norm for applications, and these applications have evolved. The workloads that are run in the VMmark tiles have also evolved to provide the closest to real-world metrics for users to assess their virtual environments.
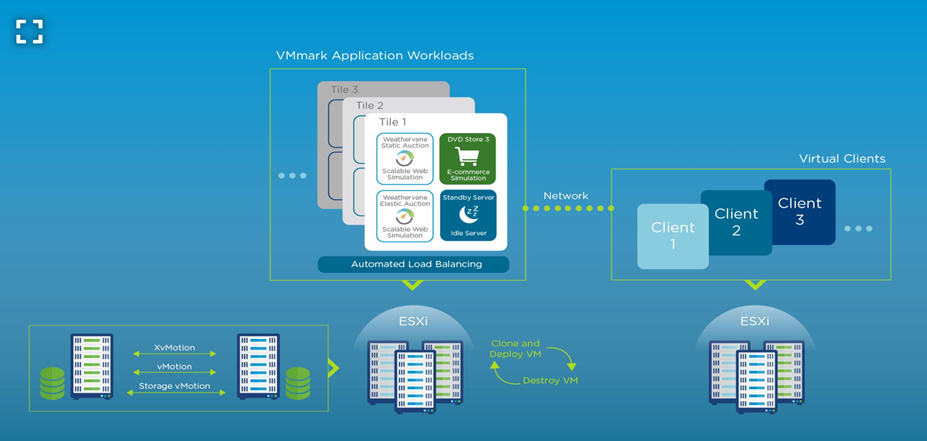
Figure 1. A web-scale multi-server virtualization platform benchmark
Solution architecture
For the purpose of generational testing, we tested Dell PowerEdge R750 powered by 3rd Gen Intel Processors and then compared it with Dell PowerEdge R760 powered by 4th Gen and 5th Gen Xeon Scalable processors respectively.
This solution includes the following components:
Component | Details | ||
SUTs | 2 x Dell PowerEdge R750 | 2 x Dell PowerEdge R760 | 2 x Dell PowerEdge R760 |
CPU | Intel Xeon Platinum 8380 Processor (Ice Lake) | Intel Xeon Platinum 8480+ Processor (Sapphire Rapids) | Intel Xeon Platinum 8592+ Processor (Emarald Rapids) |
Clients | 3 x Dell PowerEdge R740xd | 3 x Dell PowerEdge R740xd | 4 x Dell PowerEdge R7625 |
Storage | FC SAN used for Infrastructure Operations | FC SAN used for Infrastructure Operations | FC SAN used for Infrastructure Operations |
Network | Dell Z9432F-ON switch with Mellanox ConnectX-5 EN 25GbE Dual Port SFP28 Adapter | Dell Z9432F-ON switch with Intel Ethernet 100GbE 2P E810-C QSFP28 Adapter | Dell Z9432F-ON switch with Mellanox ConnectX-6 Dx Dual Port 100GbE QSFP56 Adapter |
OS | VMware ESXi 7.0 U2, Build 17630552 | VMware ESXi 8.0 GA, Build 20513097 | VMware ESXi 8.0 Update 2, Build 22380479 |
The metrics of the application workloads within each tile are computed and aggregated into a score for that tile. This aggregation is performed by first normalizing the different performance metrics (such as actions/minute and operations/minute) for a reference platform. Then, a geometric mean of the normalized scores is computed as the final score for the tile. The resulting per-tile scores are then summed to create the application workload portion of the final metric. The metrics for the infrastructure workloads are aggregated separately. The final benchmark score is computed as a weighted average: 80 percent to the application workload component and 20 percent to the infrastructure workload component.
Results
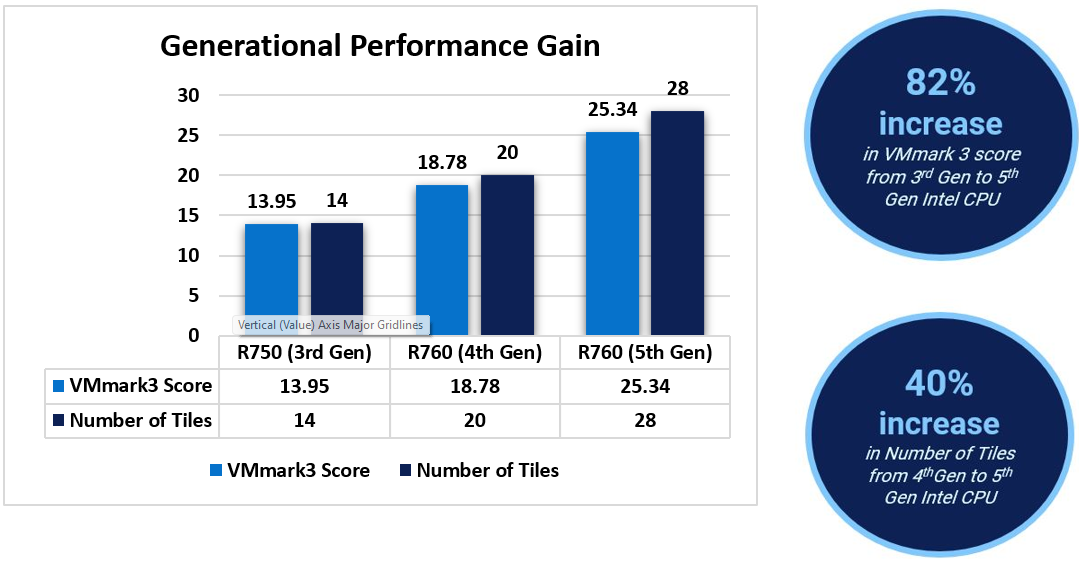
When comparing results from 3rd Gen Intel CPUs to 4th Gen and 5th Gen CPUs, we see a linear increment on the VMmark 3.1.1 score and on the Number of Tiles for each case. The percentage gain was up to 82% in the VMmark 3.1.1 score from 3rd to 5th generation. In addition, the number of tiles increased from 14 to 28, making a 2x increment in tiles from 3rd to 5th Gen CPUs[1].
World record with 4-node SAN
In addition to the above testing, Dell also tested the PowerEdge R760 with a 4-node SAN configuration and achieved a score of 51.23 @ 55 tiles. As of April 2, 2024, this 4-node score is the highest 4-node Intel score achieved on VMmark 3.1.1 and the 2nd highest overall VMMark 3.1.1 score.
This showcases the great performance and scalability of Dell PowerEdge R760 servers for virtualization use cases, especially when combined with high performance Dell storage. VMmark is an excellent indicator of today’s virtualized applications in the datacenter.
Component | Details |
SUTs | 4 x Dell PowerEdge R760 |
CPU | Intel Xeon Platinum 8592+ Processor (Emerald Rapids) |
Clients | 4 x Dell PowerEdge R7625 |
Storage | FC SAN used for Infrastructure Operations, using 1xConnectrix DS6620B, 32GB FC switch and Dell PowerMax 8000 |
Network | Dell Z9432F-ON switch with Mellanox ConnectX-6 Dx Dual Port 100GbE QSFP56 Adapter |
OS | VMware ESXi 8.0 Update 2, Build 22380479 |
The published results met all QoS thresholds and is compliant with VMmark 3.1.1 run and reporting rules. The following table shows the scores of the submitted test results. The results clearly showcase the Dell advantage over its competitors.

Conclusion
Virtualization is imminent for any enterprise application. Without virtualization, it is difficult to utilize the power of a modern server completely. In a virtualized environment, a software layer lets users create multiple independent VMs on a single physical server, to take full advantage of the hardware resources. vSAN-based solutions provide flexibility as you scale, reducing the initial and future cost of ownership. Add physical and virtual servers to the server pools to scale horizontally. Add virtual resources to the infrastructure to scale vertically. The PowerEdge R760 vSAN Ready Node is the recommended appliance for VDI deployments because it is leveraged for both “Density Optimized” and “Virtual Workstation” configurations. With the VMmark Score of 51.23 @ 55 tiles, different virtualization workloads can run optimally, providing a flexible solution for organizations of any size.
References
Dell Technologies documentation
The following Dell Technologies documentation provides other information related to this document. Access to these documents depends on your login credentials. If you do not have access to a document, contact your Dell Technologies representative.
VMware documentation
See the following VMware documentation.
- VMmark 3.x Results
- https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/vmmark/2021-06-29-DellEMC-PowerEdge-R750.pdf
- https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/vmmark/2023-01-17-Dell-PowerEdge-R760.pdf
- https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/vmmark/2024-02-20-Dell-PowerEdge-R760.pdf
[1] Based on the testing conducted in Dell Technologies Lab by Solutions and Performance Analysis team in February 2024.