
Target volume access mode
Target volume access mode
-
The default access mode for target volumes in an RCG is no access. If the target volume needs to be mapped to an SDC, change the access mode to read-only:
scli --modify_replication_consistency_group_target_volume_access_mode --replication_consistency_group_name RCG03 --target_volume_access_mode read_only
You can then map the volume to an SDC as read-only:
scli --map_volume_to_sdc --sdc_name sdc1 --volume_name vol01 --access_mode read_only
Changing the access mode can be useful for examining the data on the target volume without taking a snapshot. However, unless the Freeze Apply option is also selected, the volume will continue to receive updated writes from the source.
When configuring replicated systems to also participate in VMware Site Recovery Manager protection groups, the target volumes must be mapped Read Only to the Recovery Site ESXi hosts. For additional information about using VMware SRM to protect VMs in datastores backed by replicated PowerFlex volumes, see the Disaster Recovery for Dell PowerFlex Using VMware Site Recovery Manager White Paper.
Test Failover behavior
PowerFlex includes a useful tool for testing disaster recovery without stopping the source-side application and failing over to a secondary site. The act of issuing the Test Failover command:
- Creates a snapshot on the target system for all volumes attached to the RCG
- Replaces the pointer used by the volume mapping for each volume with a pointer to its snapshot
- Sets the access mode of the snapshot/volume mapping of each volume in the target system RCG to read_write
These steps all happen in milliseconds, making the volumes immediately write-accessible to the SDC, if they were previously mapped Read Only. Otherwise, you can map the target volumes to any SDC for testing. Because the volumes are snapshots, you can freely test your application. If the storage pool is of the same type and composition as the source system, your application will perform equally well.
During the Test Failover, replication is paused between the source and target. However, the RCG is still active, so writes are still flowing through the SDRs and accumulating in the source-side journal volumes. While the Test Failover feature can be used to run analytics or perform other test operations, such actions are better done with the Create Snapshots feature (see Create Snapshots behavior).
Test Failovers allow administrators to safely run DR scenarios without downtime and a maintenance window. When the Test Failover Stop command is run, the target-side pointers are returned to their original state, pointing once again to the replicated volume itself. The snapshots are deleted, and any writes made to them are discarded. Finally, replication of data between the source and target is resumed, and the journal intervals resume shipping.
Failover behavior
When the RCG Failover command is run, the access mode of the original source volumes switches to read_only. If the failover event has been planned, you must shut down your applications. The access mode of the target volumes switches to read_write. Further action is not required, and the behavior is the same if the failover is issued from the CLI or REST API.
If the failover is planned but the original storage cluster continues functioning, you have the option of initiating the RCG command to reverse replication. Reversing the replication keeps the volume pairs synchronized, only now in the reverse direction. If the primary system is going to be offline for a prolonged period, you should terminate the RCG to put it into an inactive state. The RCG volumes will have to undergo an initial synchronization when later reactivated.
Note: Each PowerFlex storage system creates unique volume and SCSI IDs, so the IDs are different for the source and target systems.
Create Snapshots behavior
The RCG Create Snapshots command creates snapshots for all volumes attached to the RCG on the target side, but it does not manage the snapshots any further. Consuming the snapshots is done separately and manually. From there, to test your applications or use the data contained in them, you must:
- Map the volumes to a target SDC compute system.
- Use the volumes as needed.
- Unmap the volumes when they are no longer needed.
- Delete the snapshots.
As previously noted, the Test Failover feature is not best suited to long-running or intensive testing of data in the target side volumes. Writable snapshots are an acceptable alternative when you want to:
- Perform resource-intensive operations on secondary storage without affecting production
- Test application upgrades on the target system without production impact
- Attach different and higher-performing compute systems or media in the target environment
- Attach systems with different hardware attributes, such as GPUs, in the target domain
- Run analytics on the data without impeding your operational systems
- Perform “what-if” actions on the data because that data will not be written back to production
Monitoring journal capacity and health
The journal capacity can be monitored from PowerFlex Manager at Protection > Journal Capacity. You can track utilization of the journal space reservations.
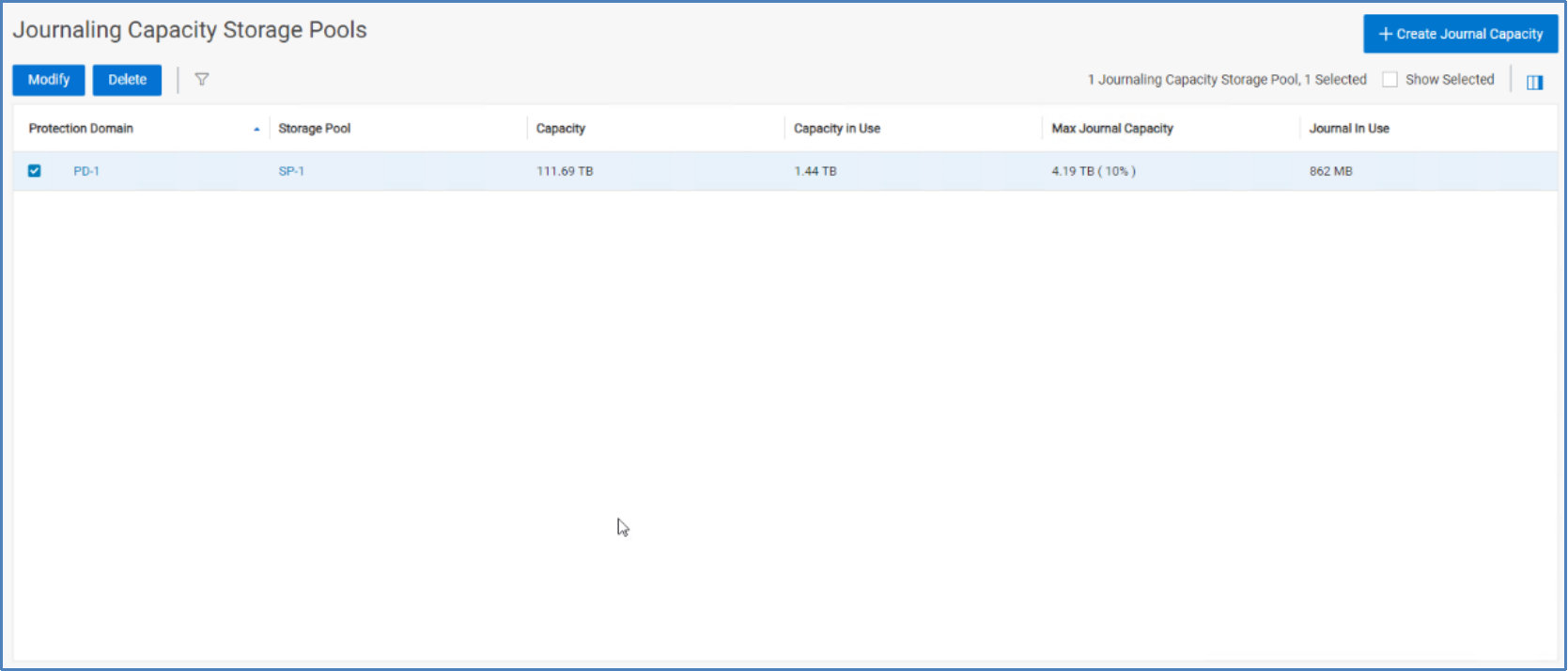
Figure 17. Journal capacity by storage pool
The preceding figure shows that we have reserved 10 percent or 4.19 TB from storage pool SP1 for journaling, and we have 862 MB of journal capacity in use. If there is concern that the space reservation is too small or too large, you can change it at any time. Select the storage pool checkbox and click Modify. Make any needed edits to the reservations. As previously noted, changes to the overall storage pool capacity might be one reason to increase or decrease the journal reservation percentage. Another reason might be an increase in volumes or applications that will use replication.
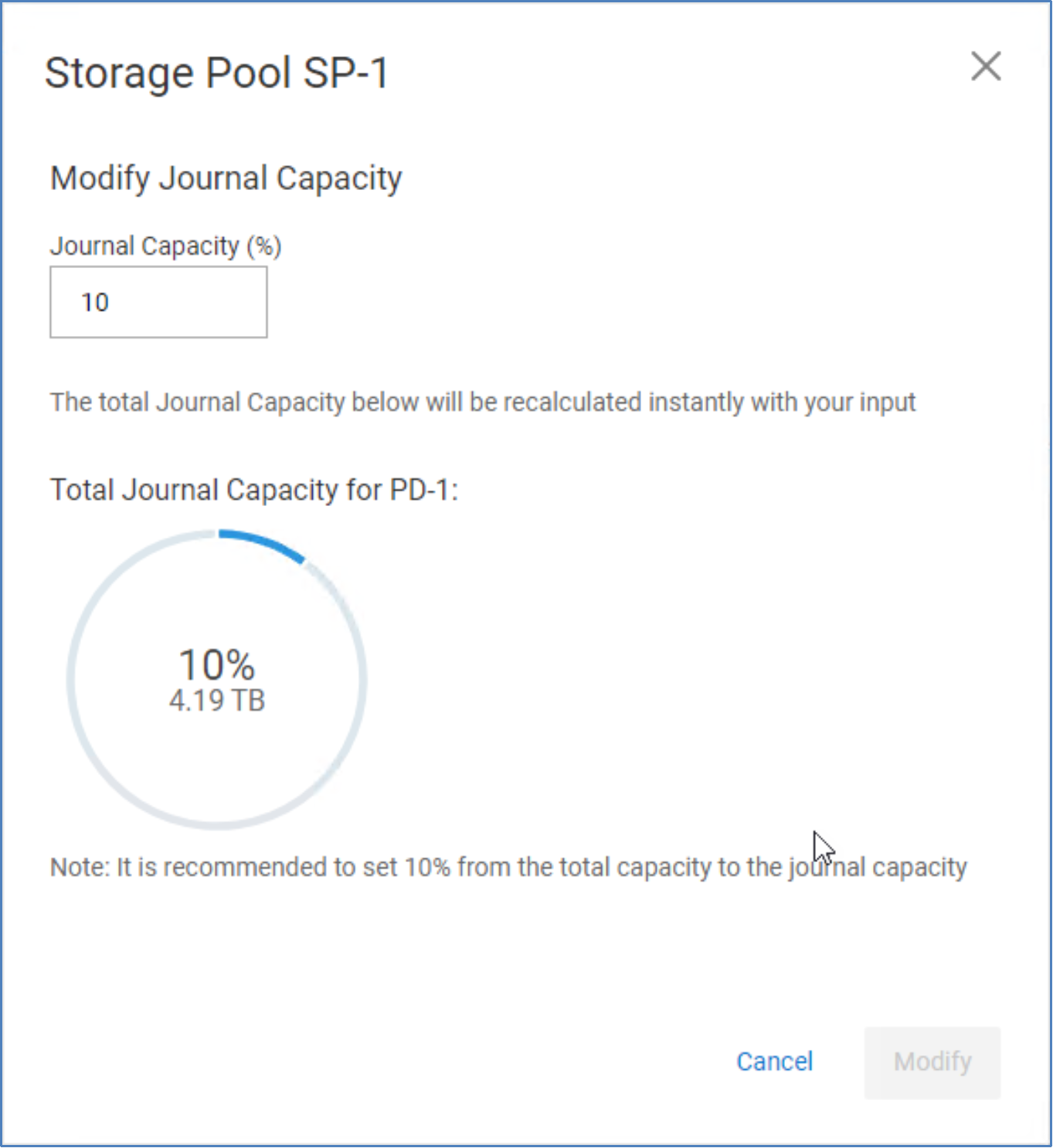
Figure 18. Modify journal capacity