
Planned Migration: 2-site replication
Planned Migration: 2-site replication
-
The recovery option “Planned Migration” assures a graceful migration of virtual machines from a local vCenter to a remote vCenter. Any errors that the recovery plan encounters will immediately fail the operation and require the user to remediate these errors and restart the migration process. Therefore, a Planned Migration assumes the following things (among other minor details):
- The protected and recovery VMware environments are up and running (including ESXi hosts, vCenter, virtual machines, SRM server etc.) without issues.
- The storage environment is stable and configured properly. This includes the array(s), the fabric (SAN) and the Solutions Enabler servers configured in the array managers.
- No network connectivity issues.
Before executing a recovery plan failover, it is highly recommended to test the recovery plan first (preferably multiple times) using the “Test” feature offered by SRM. Information on configuring and running a recovery test is discussed in detail in Chapter 4.
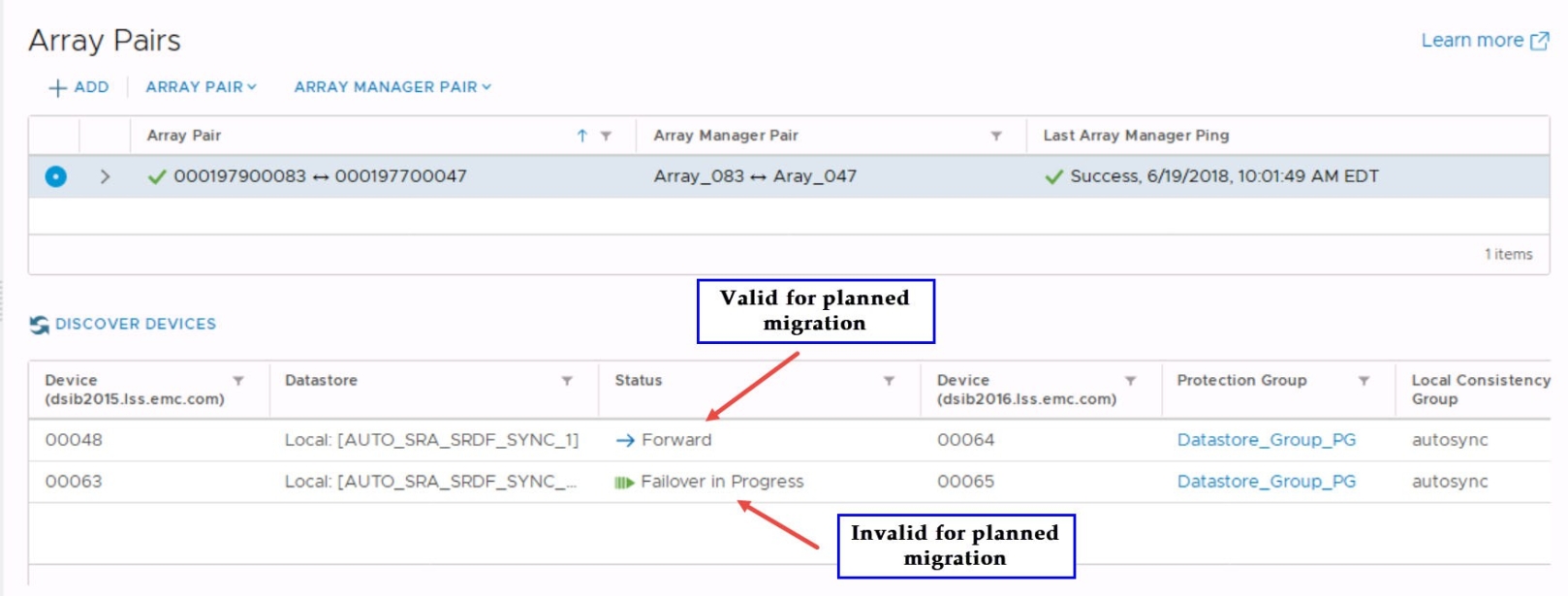
The first step is to ensure that each RDF Pair is in a proper state. In order to run a successful recovery the RDF Pair state must be either, “ActiveActive”, “ActiveBias”, “Synchronized”, “SyncInProg”, “Consistent”, or “Suspended”, unless purposely executing a test in a disconnected state with the TestFailoverForce global option. If the RDF pair is not in one of these states, it must either be changed to a proper state using PowerMax management applications or a Disaster Recovery operation may need to be run to allow the SRA to ignore invalid RDF pair states. Generally, a good indicator of valid RDF pair status is shown in the “Status” column in a given array pair. If the “Status” column shows a blue directional arrow with “Forward”, the RDF Pair State is valid for Planned Migration. If the “Status” column shows a different message, such as green arrows with “Failover in Progress”, either manual intervention is required or the Disaster Recovery option needs to be selected. An example of both states can be seen in Figure 105.
Figure 105. Checking replication status in SRM
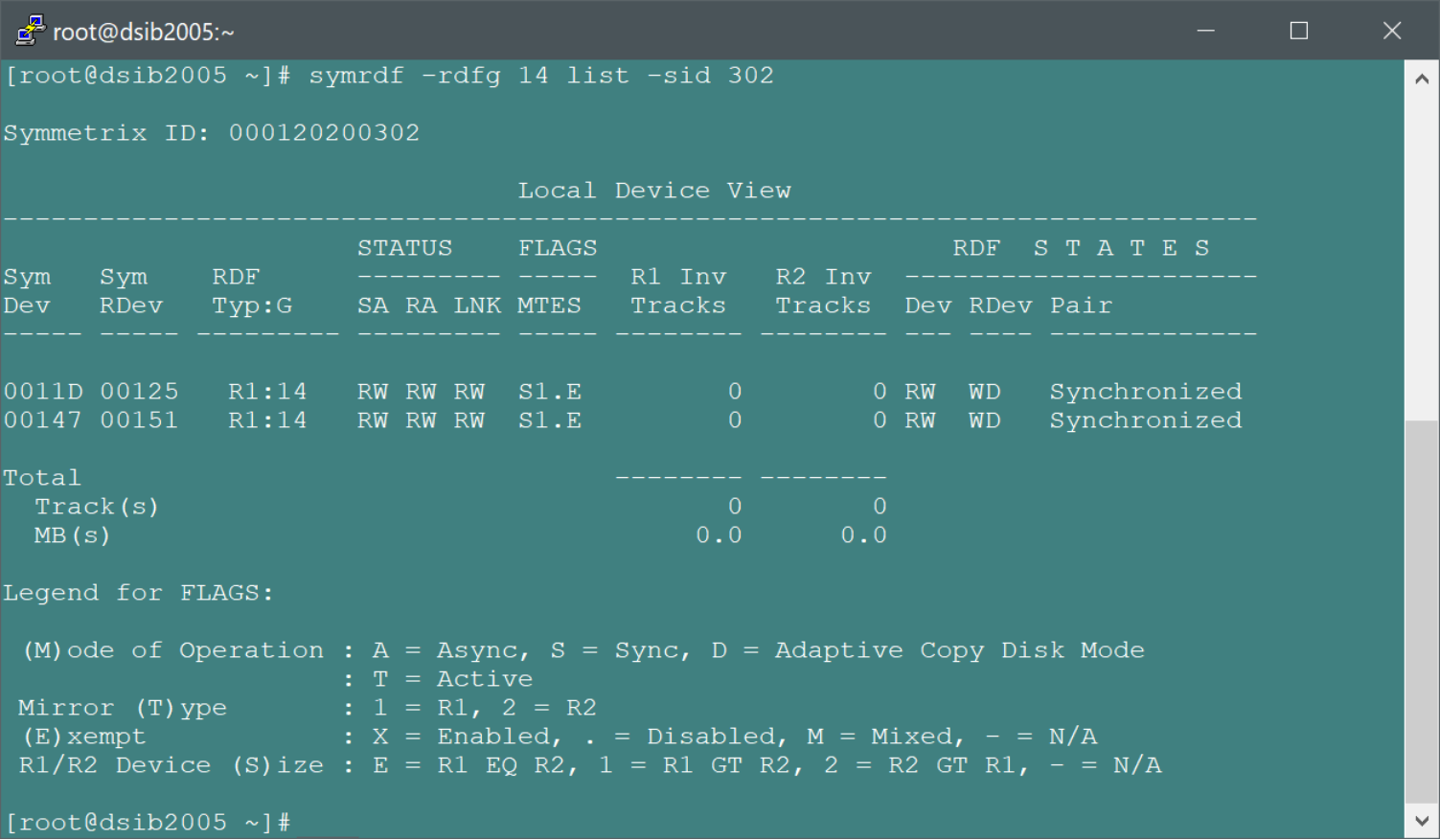
While the “Status” column is, in general, a good indicator of RDF pair states, it is inadequate to cover the many diverse possibilities of RDF pair states. Therefore, it is advisable to use Unisphere for PowerMax or Solutions Enabler to determine the exact status. Figure 106 shows an example of an RDF group containing two SRDF/S devices which are both “Synchronized”. Note these pairs are being used in the next planned migration.
Figure 106. Querying for SRDF status with Solutions Enabler
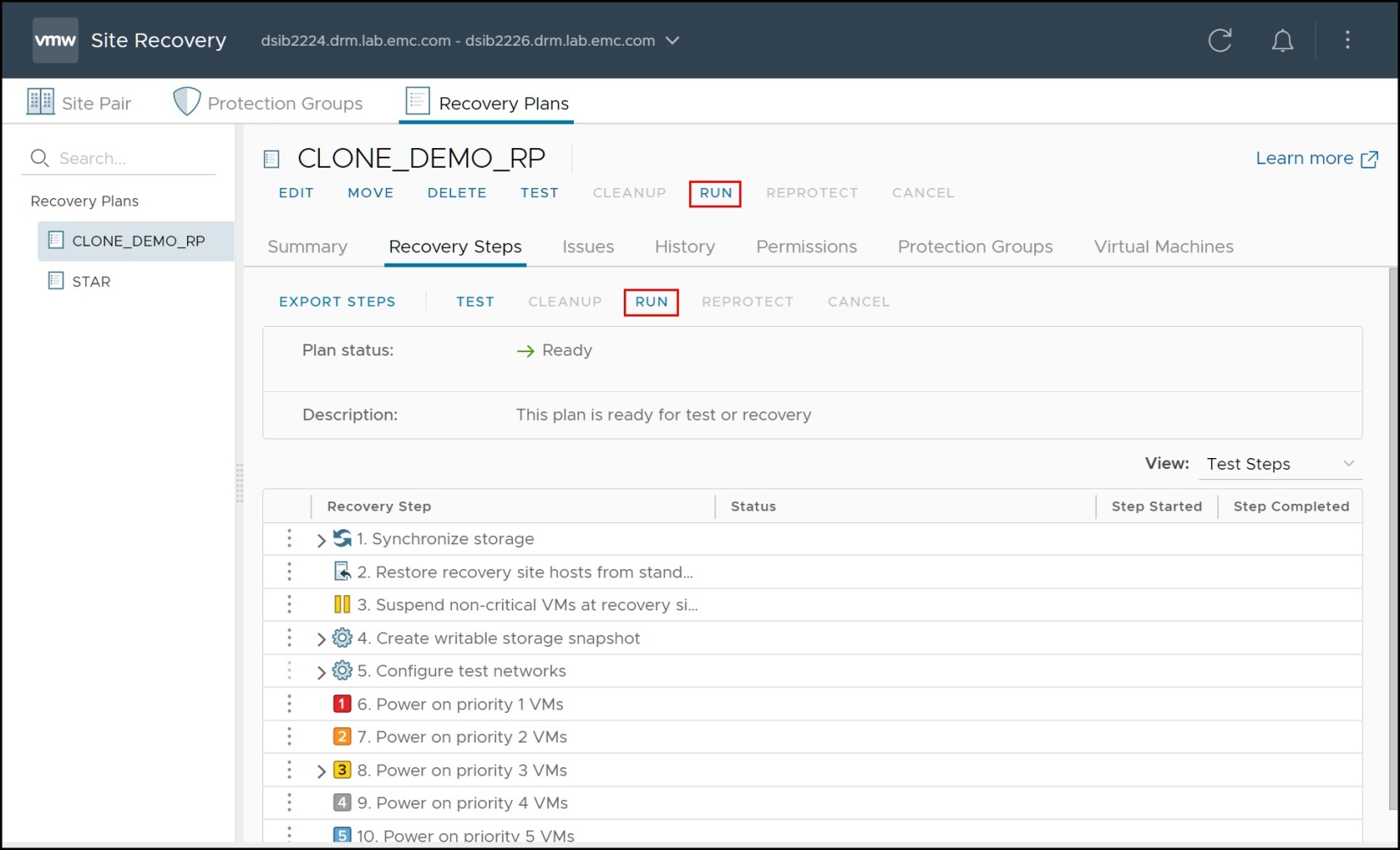
At this point, a planned migration can be initiated by selecting the appropriate recovery plan and selecting the “RUN” link as seen in Figure 107.
Figure 107. Initiating a planned migration with SRM
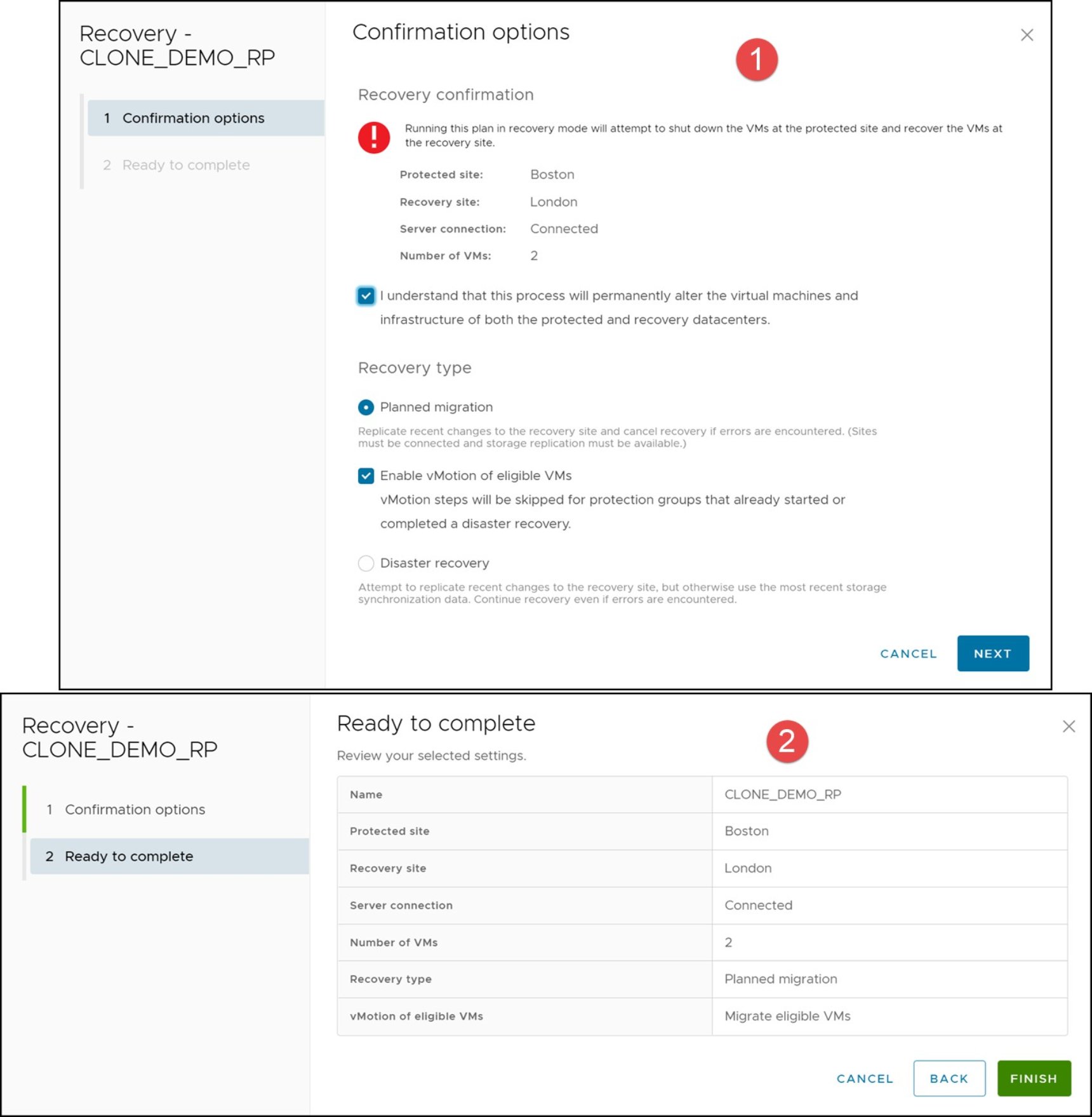
Once the Recovery link has been selected, a short confirmation wizard appears asking to confirm the initiation of the recovery operation and in which mode the recovery plan should be run. In this example, Planned migration is chosen which is the default. The check box must be selected to proceed. This screen is shown in Figure 108 for 8.5 SRM which includes a new option to enable vMotion of VMs.
Figure 108. Recovery operation confirmation wizard in SRM
As soon as the wizard completes, the recovery operation will commence. When a recovery plans reaches the “Change Recovery Site Storage to Writable” step, as shown in Figure 109, the SRA performs an RDF failover operation on the devices in the protection group.
Figure 109. Steps of a recovery plan in SRM
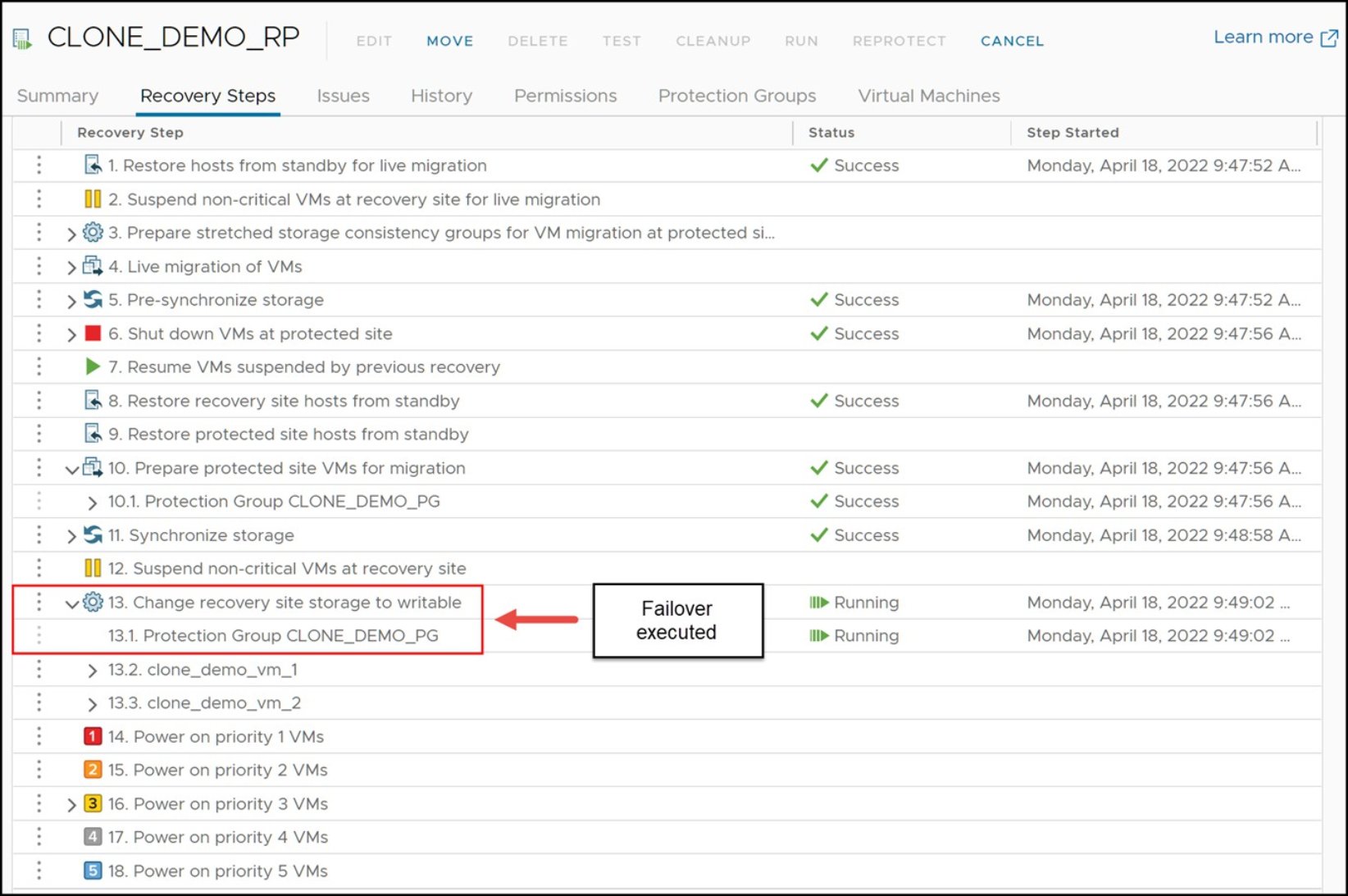
In situations where the link is still in “SyncInProg” the SRA will wait for the remote devices to fully synchronize. They will need to reach states of either “Consistent” or “Synchronized” depending on whether or not they are SRDF/A or SRDF/S respectively. As soon as the RDF pairs synchronize, the RDF failover operation will be run.
Failover will behave similarly when the RDF Pair state is “Suspended”. The SRDF SRA will detect this state and perform an “RDF Resume” to resume replication. The adapter will intermittently query the state and wait until the pairs synchronize. In both of these situations (depending on the amount of data that needs to synchronize) this process could take a long time to complete and may exceed the default timeout for storage operations of five minutes.
Therefore, it is advisable to ensure the storage is synchronized before a planned migration is attempted. The other option is to raise the storage operation timeout setting to a sufficiently high enough value to allow for a full synchronization. If increasing the timeout is preferred, the setting needs to be changed on the recovery site SRM server.
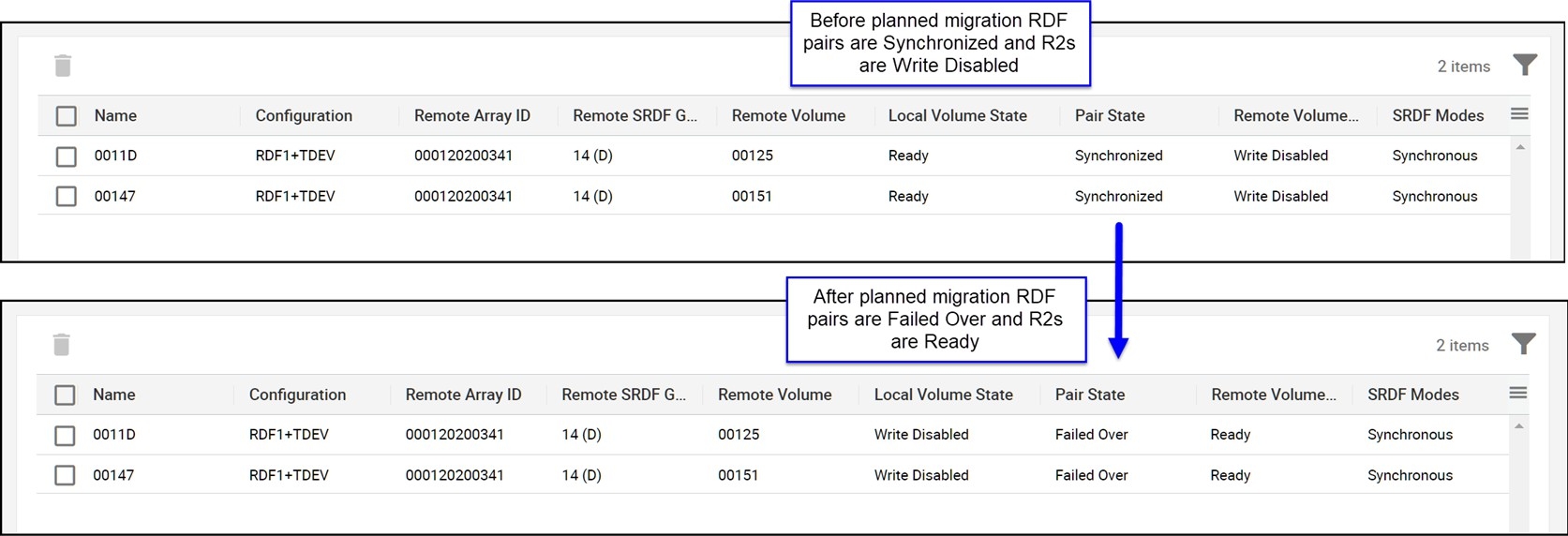
When the RDF failover is issued, the RDF pair state changes from “Synchronized” (if SRDF/S) or “Consistent” (if SRDF/A) to “Failed Over” or “ActiveActive” or “ActiveBias” (if SRDF/Metro) to “Suspended”. A “before and after” example of this changed state for SRDF/S devices is shown in Figure 110 using Unisphere for PowerMax.
The RDF Failover operation includes the following steps that are automatically executed in a planned migration:
- SRDF links are suspended.
- Source (R1) devices are write disabled to protected site ESXi servers.
- If configured, the R1 devices will be removed from the protected site storage group and/or the R2 devices will be added to the recovery site storage group.
- The target (R2) devices are read/write enabled to recovery site ESXi servers.
Figure 110. RDF pair states as seen from the recovery site before and after failover
Once the R2 devices are write-enabled, the devices can be mounted and the virtual machines can be registered and powered-on. In addition to the R2 devices being mounted on the recovery-side ESXi hosts, the R1 volumes will be unmounted and detached from the protection-side ESXi hosts.
When the VMFS volumes on the R2 devices are mounted, the ESXi kernel must resignature the VMFS first because it is seen as a copy due to its invalid signature. The reason for the invalid signature, and therefore the subsequent resignaturing, is due to the fact that the R1 and R2 devices have different world-wide names (WWNs) but an identical VMFS volume signature. The VMFS volume was originally created on the R1 device and the signature of the VMFS is based, in part, on the WWN of the underlying device. Since the WWN changes between the R1 and the R2 but the signature is copied over, the ESXi kernel will identify a WWN/VMFS signature mismatch and require a resignature before use.
Note: While ESXi allows for the ability to force mount VMFS volumes with invalid signatures without resignaturing the datastore, SRM does not.
The VMware kernel automatically renames VMFS volumes that have been resignatured by adding a “SNAP-XXXXXX” prefix to the original name to denote that it is a copied and resignatured file system. SRM provides an advanced setting, that is disabled by default, storageProvider.fixRecoveredDatastoreNames. Enabling this setting will cause this suffix to be automatically removed during the recovery plan. Check this option on the recovery site SRM server to enable this automatic prefix removal behavior.
Note: SRM offers an advanced Disaster Recovery option called Forced Recovery. Forced Recovery allows SRM to recover virtual machines in cases where storage arrays fail at the protected site and, as a result, protected virtual machines are unmanageable and cannot be shut down, powered off, or unregistered. This option is disabled by default as it is only useful in very specific scenarios. Please reference the VMware documentation for more detail.