
Reprotection
Reprotection
-
After a recovery plan has run, there are often cases where the environment must continue to be protected against failure to ensure its resilience and to meet objectives for disaster recovery. SRM offers “reprotection” which is an extension to recovery plan management that enables the environment at the recovery site to establish replication and protection of the environment back to the original protected site. This behavior allows users to recover the environment quickly and easily back to the original site if necessary.
It is important to note that a completely unassisted reprotection by SRM may not always be possible depending on the circumstances and results of the preceding recovery operation. Recovery plans executed in “Planned Migration” mode are the likeliest candidates for a subsequent successful automated reprotection by SRM. Exceptions to this occur if certain failures or changes have occurred between the time the recovery plan was run and the reprotection operation was initiated. Those situations may cause the reprotection to fail. Similarly, if a recovery plan was executed in “Disaster Recovery” mode any persisting failures may cause a partial or complete failure of a reprotection of a recovery plan.
These different situations are discussed in the subsequent sections.
Note: If a reprotect operation fails, a discover devices operation, performed at the recovery site, may be necessary to resolve. The use of device/composite (consistency) groups (prerequisite) is essential in mitigating any failure.
Reprotect after Planned Migration
The scenario that will most likely lead to a successful reprotection is one after a planned migration. In the case of a planned migration there are no failures in either the storage or compute environment that preceded the recovery operation. Therefore reversing recovery plans/protections groups as well as swapping and establishing replication in the reverse direction is possible.
If failed-over virtual machines will eventually need to be returned to the original site or if they require SRDF replication protection, it is recommended to run a reprotect operation as soon as possible after a migration.
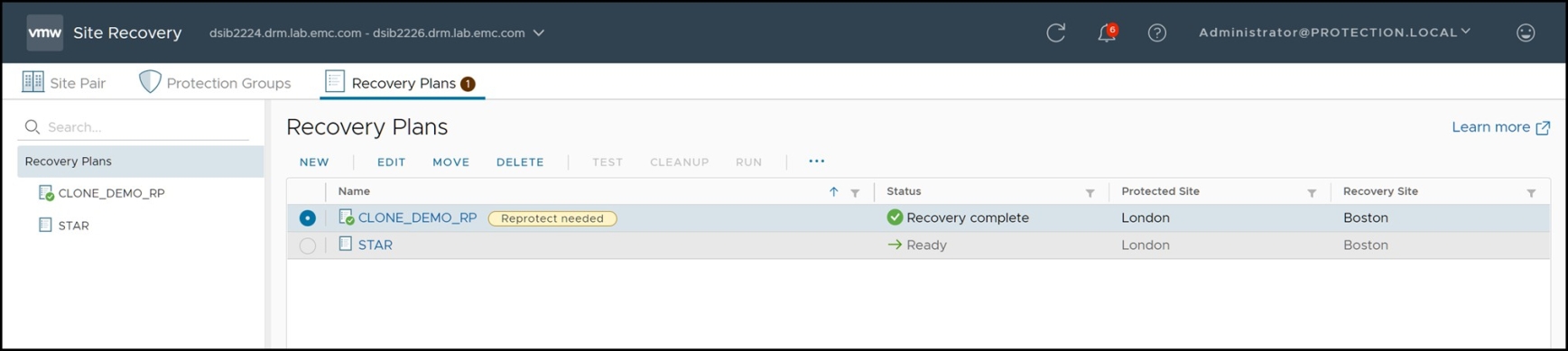
Reprotect is only available after a recovery operation has occurred, which is indicated by the recovery plan being in the “Recovery Complete” state. Later versions of SRM will warn the user to run Reprotect as in Figure 125.
Figure 125. SRM warns user to run Reprotect
A reprotect can be executed by selecting the appropriate recovery plan and selecting one of the REPROTECT links as shown in Figure 126.
Figure 126. Executing a reprotect operation in VMware vCenter SRM
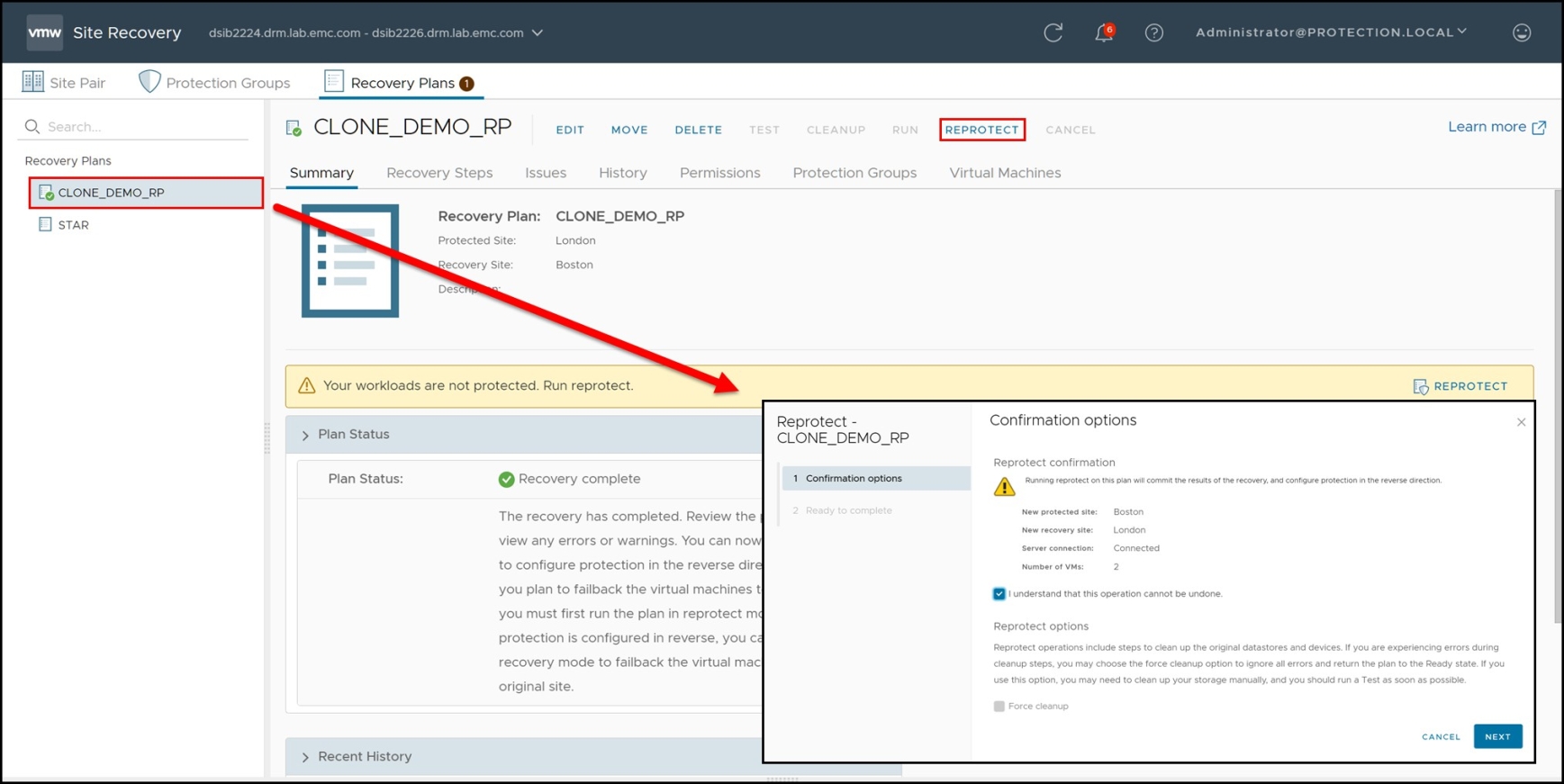
The reprotect operation does the following things:
- Reverses protection groups. The protection groups are deleted on the original protection SRM server and are recreated on the original recovery SRM server. The inventory mappings are configured (assuming the user has pre-configured them in SRM on the recovery site) and the necessary “shadow” or “placeholder” VMs are created and registered on the newly designated recovery SRM server[42].
- Reverses recovery plan. The failed-over recovery plan is deleted on the original recovery SRM server and recreated with the newly reversed protection group.
- Swaps personality of RDF devices. The SRDF SRA performs an RDF swap on the target RDF pairs which enables replication to be established back to the original site. R1 devices will become R2 devices and R2 devices will become R1 devices.
- Re-establishes replication. After the RDF swap, the SRDF SRA incrementally re-establishes replication between the RDF pairs, but in the opposite direction from what it was before the failover/migration.
The status of the devices after a migration, but before a reprotect operation, can be seen in the previous Figure 110. The R2 devices do not change personality after the migration or disaster recovery. The pair state is Failed Over and the devices are Ready.
Figure 127 shows the steps involved in a reprotect operation.
Figure 127. Reprotect operation steps
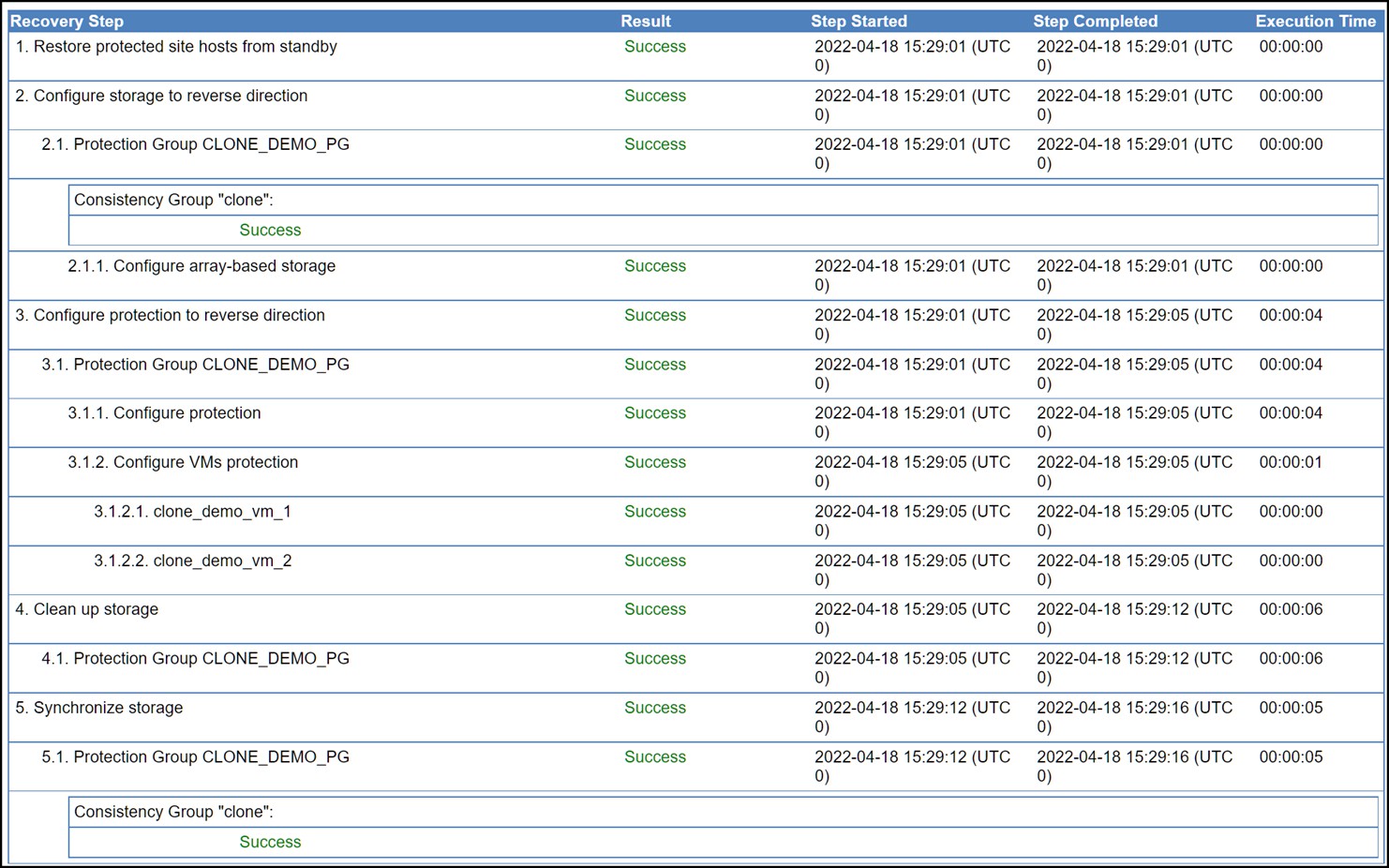
Step 2 of the reprotect operation (as shown in Figure 127) causes the SRA to issue an RDF personality swap and establish the replication in the reverse direction. This means the R2 is converted to an R1, the R1 to an R2, and an incremental establish back to the new R2 is started, i.e., pushing the changes to the original array.
Reprotect after a temporary failure
The previous section describes the best possible scenario for a smooth reprotection because it follows a planned migration where no errors are encountered. For recovery plans failed over in disaster recovery mode, this may not be the case.
Disaster recovery mode allows for failures ranging from the very small to a full site failure of the protection datacenter. If these failures are temporary and recoverable a fully-successful reprotection may be possible once those failures have been rectified. In this case, a reprotection will behave similar to the scenario described in the previous section. If a reprotection is run before the failures are corrected or certain failures cannot be fully recovered, an incomplete reprotection operation will occur. This section describes this scenario.
For reprotect to be available, the following steps must first occur:
- A recovery must be executed with all steps finishing successfully. If there were any errors during the recovery, the user needs to resolve the issues that caused the errors and then rerun the recovery.
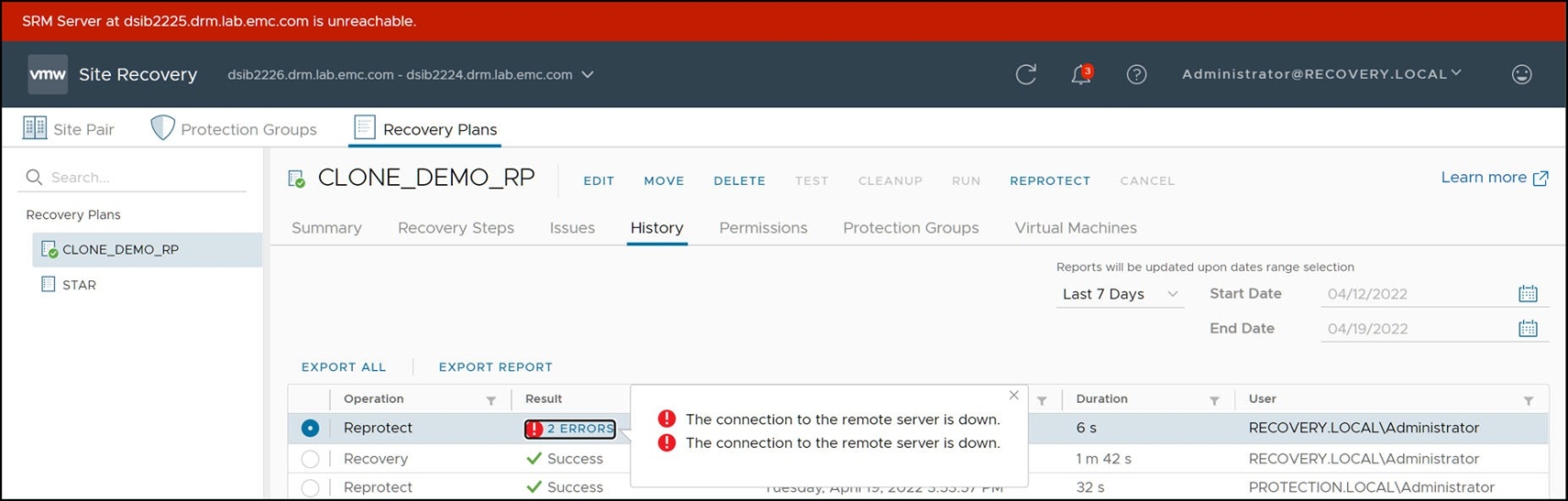
- The original site should be available and SRM servers at both sites should be in a connected state. If the sites are disconnected, a Reprotect will fail immediately as in Figure 128. If the original site cannot be restored (for example, if a physical catastrophe destroys the original site) automated reprotection cannot be run and manual recreation will be required if and when the original protected site is rebuilt.
Figure 128. Reprotect fails with sites disconnected
If the protected site SRM server was disconnected during failover and is reconnected later, SRM will want to retry certain recovery operations before allowing reprotect. This typically occurs if the recovery plan was not able to connect to the protected side vCenter server and power down the virtual machines due to network connectivity issues. If network connectivity is restored after the recovery plan was failed over, SRM will detect this situation and require the recovery plan to be re-run in order to power those VMs down.
A reprotection operation will fail if it encounters any errors the first time it runs. If this is the case, the reprotect must be run a second time but with the “Force cleanup” option selected as in Figure 129.
Figure 129. Forcing a reprotect operation
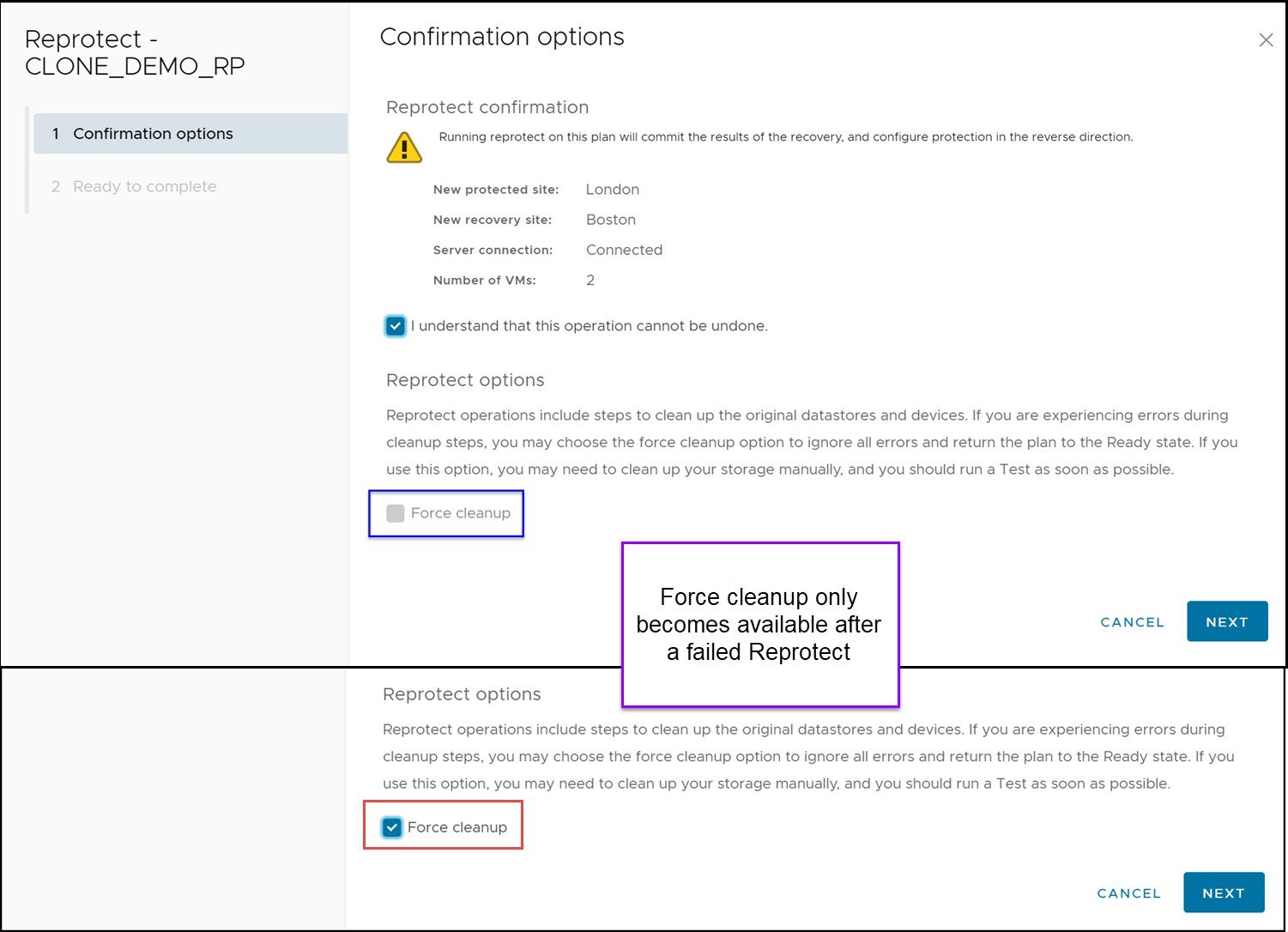
Once the force option is selected, any errors will be acknowledged and reported but ignored. This will allow the reprotect operation to continue even if the operation has experienced errors. It will attempt all of the typical steps and complete whichever ones are possible.
Therefore, in certain situations, the SRDF replication may not be properly reversed even though the recovery plan and protection group(s) were. If the “Configure Storage to Reverse Direction” step fails, manual user intervention with Unisphere for VMAX/PowerMax or Solutions Enabler CLI may be required to complete the process. The user should ensure that:
- An RDF swap has occurred by ensuring the replicated target/source devices have changed personalities
- Replication has been re-established and is in an appropriate and supported SRDF replication mode
In the case of a temporary storage failure or replication partition, it is likely that manual intervention will be required prior to executing a reprotect operation. In this situation the R1 devices may not have been unmounted and write-disabled properly so invalid tracks may appear on the R1. When there are invalid tracks on both sites a RDF resume cannot be attempted and a reprotect operation will fail. Therefore, a storage administrator must decide which invalid tracks must be cleared and then clear them from the appropriate devices. Once this has been done a reprotect may proceed. A message such as the one below will be reported when there are conflicting invalid tracks in the SRDF SRA log:
[ERROR]: Failed to perform RDF operation [RESUME
-FORCE] on DG [SRDFS], Symm [000195701248].
[ERROR]: [Solutions Enabler_C_RDF_CONF_INV_TRACKS : Cannot proceed because conflicting invalid tracks were found in the device group]
The typical method for clearing these invalids is to perform a manual RDF swap and then an establish operation instead of a resume.
Reprotect after a failover due to unrecoverable failure
In extreme circumstances, the storage and/or the compute environment may be rendered completely unrecoverable due to a disaster. In this scenario, reprotect will not be possible. Therefore the process of “re-protecting” the original recovery site is no different than the original setup of the protection groups and recovery plans from scratch. Refer to Chapter 3 for instructions on that process. An example of an unrecoverable failure would be if the protection site array was lost and then replaced, requiring new SRDF pair relationships.
[42] For detailed information on the non-storage related portions of the reprotect operation refer to VMware documentation.