
Blogs

Kubernetes Node Non-Graceful Shutdown and Remediation: Insights from Dell Technologies
Tue, 12 Dec 2023 18:16:57 -0000
|Read Time: 0 minutes
Introduction
Kubernetes has become a pivotal technology in managing containerized applications, but it's not without its challenges, particularly when dealing with Stateful Apps and non-graceful shutdown scenarios. This article delves into the intricacies of handling such situations, drawing insights from Dell Technologies' expertise and more importantly, how to enable it.
Understanding Graceful vs. Non-Graceful Node Shutdowns in Kubernetes
A 'graceful' node shutdown in Kubernetes is an orchestrated process. When kubelet detects a node shutdown event, it terminates the pods on that node properly, releasing resources before the actual shutdown. This orderly process allows critical pods to be terminated after regular pods, ensuring an application continues operating as long as possible. This process is vital for maintaining high availability and resilience in applications.
However, issues arise with a non-graceful shutdown, like a hard stop or node crash. In such cases, kubelet fails to detect a clean shutdown event. This leads to Kubernetes marking the node ‘NotReady', and Pods in a Stateful Set can remain stuck in 'Terminating' mode indefinitely!
Kubernetes adopts a cautious approach in these scenarios since it cannot ascertain if the issue is a total node failure, a kubelet problem, or a network glitch. This distinction is critical, especially for stateful apps, where rescheduling amidst active data writing could lead to severe data corruption.
Role of Dell's Container Storage Module (CSM) for Resiliency
Dell's CSM for Resiliency plays a crucial role in automating decision-making in these complex scenarios, aiming to minimize manual intervention and maximize uptime. The module's functionality is highlighted through a typical workflow:
- Consider a pod with two mounted volumes, annotated for protection with CSM resiliency.
- Upon an abrupt node power-off, the Kubernetes API detects the failure, marking the node as 'Not Ready'.
- The podmon controller of CSM Resiliency then interrogates the storage array, querying its status regarding the node and volumes.
- Depending on its findings and a set heuristic, the module determines whether it's safe to reschedule the pod.
- If rescheduling is deemed safe, the module quickly fences off access for the failed node, removes the volume attachment, and force-deletes the pod, enabling Kubernetes to reschedule it efficiently.
The following tutorial allow to test the functionality live: https://dell.github.io/csm-docs/docs/interactive-tutorials/
How to enable the module ?
To take advantage of the CSM resiliency you need two things:
- Enable it for your driver, for example with PowerFlex
- With the CSM wizard, just check the resiliency box
- With the Operator just set enable: true in the section .spec.modules.name['resiliency']
- With the helm chart set enable: true in the section .csi-vxflexos.podmon
- Then protect you application by adding the magic label podmon.dellemc.com/driver: csi-vxflexos
Conclusion:
Managing non-graceful shutdowns in Kubernetes, particularly for stateful applications, is a complex but essential aspect of ensuring system resilience and data integrity.
Tools like Dell's CSM for Resiliency are instrumental in navigating these challenges, offering automated, intelligent solutions that keep applications running smoothly even in the face of unexpected failures.
Sources
Stay informed of the latest updates of Dell CSM eco-system by subscribing to:
* The Dell CSM Github repository
* Our DevOps & Automation Youtube playlist
* The Slack

Kubernetes on Z with PowerMax: Modern Software Running on Mainframe

Mon, 02 Oct 2023 13:21:45 -0000
|Read Time: 0 minutes
Benefits of Kubernetes on System Z and LinuxOne
When I was a customer, I consistently evaluated how to grow the technical influence of the mainframe platform. If I were talking about the financials of the platform, I would evaluate the total cost of ownership (TCO) alongside various IT solutions and the value deduced thereof. If discussing existing technical pain points, I would evaluate technical solutions that may alleviate the issue.
For example, when challenged with finding a solution for a client organization aiming to refresh various x86 servers, I searched online presentations, YouTube videos, and technical websites for a spark. The client organization had already identified the pain point. The hard part was how.
Over time, I found the ability to run Linux on a mainframe (called Linux on Z), using an Integrated Facility for Linux (IFL) engine. Once the idea was formed, I started baking the cake. I created a proof-of-concept environment installing Linux and a couple of applications and began testing.
The light-bulb moment came not in resolving the original pain point, but in discovering new opportunities I had not originally thought of. More specifically:
- Physical server consolidation – I’ll create a plethora of virtual servers when needed
- License Consolidation – Certain applications with x86 were licensed on a per engine basis. A quad core x86 server may need four application licenses to function. I needed one license for my Linux on Z environment (at the time of testing)
- Scalability – I could scale horizontally by adding more virtual machines and vertically by increasing the network ports accessible to the server and adding more memory/storage
- Reliability – Mainframe technology has been known to be reliable, utilizing fault tolerant mechanisms within the software and hardware to continue business operations
With the 2023 addition of Kubernetes on LinuxOne (mainframe that only runs Linux), you can scale, reduce TCO, and build that hybrid cloud your IT management requires. With Kubernetes providing container orchestration irrelevant of the underlying hardware and architecture, you can leverage the benefits of LinuxOne to deploy your applications in a structured fashion.
Benefits when deploying Kubernetes to Linux on Z may include:
- Enablement of DevOps processes
- Container Scalability – using one LinuxOne box with hundreds (if not thousands) of containers
- Hybrid Cloud Strategy – where LinuxOne is servicing various internal business organizations with their compute and storage needs
With Dell providing storage to mainframe environments with PowerMax 8500/2500, a Container Storage Interface (CSI) was created to simplify your experience with allocating storage to Kubernetes environments when using Linux on Z with Kubernetes.
The remaining content will focus on the CSI for PowerMax. Continue reading to explore what’s possible.
Deploy Kubernetes
Linux on IBM Z runs on s390x architecture. This means that all the software we use needs to be compiled with that architecture in mind.
Luckily, Kubernetes, CSI sidecars, and Dell CSI drivers are built in Golang. Since the early days of Go, the portability and support of different OS and architectures has been one of the goals of the project. You can get the list of compatible OS and architecture with your go version using the command:
go tool dist listThe easiest and most straightforward way of trying Kubernetes on LinuxOne is by using the k3s distro. It installs with the following one-liner:
curl -sfL https://get.k3s.io | sh -
Build Dell CSI driver
The Dell CSI Driver for PowerMax is composed of a container to run all actions against Unisphere and mount a LUN to a pod, with a set of official CSI sidecars to interact with Kubernetes calls.
The Kubernetes official sidecars are published for multiple architectures including s390x while Dell publishes only images for x86_64.
To build the driver, we will first build the binary and then the image.
Binary
First, let’s clone the driver from https://github.com/dell/csi-powermax in your GOPATH. To build the driver, go in the directory and just execute:
CGO_ENABLED=0 GOOS=linux GOARCH=s390x GO111MODULE=on go buildAt the end of the build, you must have a single binary with static libs compiled for the s390x:
file csi-powermax
csi-powermax: ELF 64-bit MSB executable, IBM S/390, version 1 (SYSV), statically linked, Go BuildID=…, with debug_info, not strippedContainer
The distributed driver uses minimal Red Hat Universal Base Image. There is no s390x compatible UBI image. Therefore, we need to rebuild the container image from a Fedora base-image.
The following is the Dockerfile:
# Dockerfile to build PowerMax CSI Driver
FROM docker.io/fedora:37
# dependencies, following by cleaning the cache
RUN yum install -y \
util-linux \
e2fsprogs \
which \
xfsprogs \
device-mapper-multipath \
&& \
yum clean all \
&& \
rm -rf /var/cache/run
# validate some cli utilities are found
RUN which mkfs.ext4
RUN which mkfs.xfs
COPY "csi-powermax" .
COPY "csi-powermax.sh" .
ENTRYPOINT ["/csi-powermax.sh"]We can now build our container image with the help of docker buildx, which makes building cross-architecture a breeze:
docker buildx build -o type=registry -t coulof/csi-powermax:v2.8.0 --platform=linux/s390x -f Dockerfile.s390x .The last step is to change the image in the helm chart to point to the new one: https://github.com/dell/helm-charts/blob/main/charts/csi-powermax/values.yaml
Et voilà! Everything else is the same as with a regular CSI driver.
Wrap-up, limitations, and disclaimer
Thanks to the open-source model of Kubernetes and Dell CSM, it’s easy to build and utilize them for many different architectures.
The CSI driver for PowerMax supports FBA devices via Fiber Channel and iSCSI. There is no support for CKD devices which require code changes.
The CSI driver for PowerMax allows CSI-compliant calls.
Note: Dell officially supports (through Github tickets, Service Requests, and Slack) the image and binary, but not the custom build.
Useful links
Stay informed of the latest updates of the Dell CSM eco-system by subscribing to:
Authors: Justin Bastin & Florian Coulombel

CSM 1.8 Release is Here!
Fri, 22 Sep 2023 21:29:12 -0000
|Read Time: 0 minutes
Introduction
This is already the third release of Dell Container Storage Modules (CSM)!
The official changelog is available in the CHANGELOG directory of the CSM repository.
CSI Features
Supported Kubernetes distributions
The newly supported Kubernetes distributions are :
- Kubernetes 1.28
- OpenShift 4.13
SD-NAS support for PowerMax and PowerFlex
Historically, PowerMax and PowerFlex are Dell’s high-end and SDS for block storage. Both of these backends recently introduced support for software defined NAS.
This means that the respective CSI drivers can now provision PVC with the ReadWriteMany access mode for the volume type file. In other words, thanks to the NFS protocol different nodes from the Kubernetes cluster can access the same volume concurrently. This feature is particularly useful for applications, such as log management tools like Splunk or Elastic Search, that need to process logs coming from multiple Pods.
CSI Specification compliance
Storage capacity tracking
Like PowerScale in v1.7.0, PowerMax and Dell Unity allow you to check the storage capacity on a node before deploying storage to that node. This isn't that relevant in the case of shared storage, because shared storage generally will always show the same capacity to each node in the cluster. However, it could prove useful if the array lacks available storage.
Using this feature, an object from the CSIStorageCapacity type is created by the CSI driver in the same namespace as the CSI driver, one for each storageClass.
An example:
kubectl get csistoragecapacities -n unity # This shows one object per storageClass.
Volume Limits
The Volume Limits feature is added to both PowerStore and PowerFlex. All Dell storage platforms now implement this feature.
This option limits the maximum number of volumes to which a Kubernetes worker node can connect. This can be configured on a per-node basis, or cluster-wide. Setting this variable to zero disables the limit.
Here are some PowerStore examples.
Per node:
kubectl label node <node name> max-powerstore-volumes-per-node=<volume_limit>
For the entire cluster (all worker nodes):
Specify maxPowerstoreVolumesPerNode or maxVxflexVolumesPerNode in the values.yaml file upon Helm installation.
If you opted-in for the CSP Operator deployment, you can control it by specifying X_CSI_MAX_VOLUMES_PER_NODES in the CRD.
Useful links
Stay informed of the latest updates of the Dell CSM eco-system by subscribing to:
- The Dell CSM Github repository
- Our DevOps & Automation Youtube playlist
- Slack (under the Dell Infrastructure namespace)
- Live streaming on Twitch
Author: Florian Coulombel

CSM 1.7 Release is Here!
Fri, 30 Jun 2023 13:42:36 -0000
|Read Time: 0 minutes
Introduction
The second release of 2023 for Kubernetes CSI Driver & Dell Container Storage Modules (CSM) is here!
The official changelog is available in the CHANGELOG directory of the CSM repository.
As you may know, Dell Container Storage Modules (CSM) bring powerful enterprise storage features and functionality to your Kubernetes workloads running on Dell primary storage arrays, and provide easier adoption of cloud native workloads, improved productivity, and scalable operations. Read on to learn more about what’s in this latest release.
CSI features
Supported Kubernetes distributions
The newly supported Kubernetes distributions are:
- Kubernetes 1.27
- OpenShift 4.12
- Amazon EKS Anywhere
- k3s on Debian
CSI PowerMax
For the last couple of versions, the CSI PowerMax reverseproxy is enabled by default. The TLS certificate secret creation is now pre-packaged using cert-manager, to avoid manual steps for the administrator.
A volume can be mounted to a Pod as `readOnly`. This is the default behavior for a `configMap` or `secret`. That option is now also supported for RawBlock devices.
apiVersion: v1 kind: Pod metadata: name: task-pv-pod spec: volumes: - name: task-pv-storage persistentVolumeClaim: claimName: task-pv-claim # What ever is the accessMode it will be read-only for the Pod readOnly: true ...
CSM v1.5 introduced the capacity to provision Fibre Channel LUNs to Kubernetes worker nodes through VMware Raw Device Mapping. One limitation of the RDM/LUN was that it was sticky to a single ESXi host, meaning that the Pod could not move to another worker node.
The auto-RDM feature works at the HostGroup level in PowerMax and therefore supports clusters with multiple ESXi hosts.
We are exposing the host I/O limits on the storage groups parameter using the StorageClass. The Host I/O limit is here to implement QoS at the worker node level and to prevent any noisy neighbor behavior.
CSI PowerScale
Storage Capacity Tracking is used by the Kubernetes scheduler to make sure that the node and backend storage have enough capacity for Pod/PVC.
The user can now set Quota limit parameters from the PVC and StorageClass requests. This allows the user to have better control of the quota parameters (including Soft Limit, AdvisoryLimit, Softgrace period) attached to each PVC
The PVC settings take precedence if quota limit values are specified in both StorageClass and PVC.
CSM features
CSM Operator
One can now use the CSM Operator to install Dell Unity and PowerMax CSI drivers and affiliated modules.
The CSM Operator now provides CSM resiliency and CSM-Replication for CSI-PowerFlex.
A detailed matrix of supported CSM components is available here.
CSM Installation Wizard
The CSM Installation Wizard is the easiest and most straight forward way to install the Dell CSI drivers and Container Storage Modules.
In this release, we are adding support for Dell Unity, PowerScale, and PowerFlex.
To keep it simple, we removed the option to install the driver and modules in separate namespaces.
CSM Authorization
In this release of CSM, Secrets Encryption is enabled by default.
- All secrets are encrypted by default, using the AES-CBC key type.
- After installation/upgrade, all secrets will be encrypted.
- AES-CBC is the default key type.
- AES-CBC is the only supported key type.
CSM Replication
When you use CSM replication, two volumes are created: the active volume and the replica. Prior to CSM v1.7, if you removed the two PVs, the physical replica wasn't deleted.
Now on PV deletion, we cascade the removal to all objects, including the replica block volumes in PowerStore, PowerMax, and PowerFlex, so that there are no more orphan volumes.
Useful links
Stay informed of the latest updates of the Dell CSM eco-system by subscribing to:
- The Dell CSM Github repository
- Our DevOps & Automation Youtube playlist
- Slack (under the Dell Infrastructure namespace)
Author: Florian Coulombel

Mowing the DbaaS Weeds Without --Force

Tue, 04 Apr 2023 16:51:39 -0000
|Read Time: 0 minutes
With the release of a recent paper that I had the pleasure to co-author, Building a Hybrid Database-as-a-Service Platform with Azure Stack HCI, I wanted to continue to author some additional interesting perspectives, and dive deep into the DbaaS technical weeds.
That recent paper was a refresh of a previous paper that we wrote roughly 16 months ago. That time frame is an eternity for technology changes. It was time to refresh with tech updates and some lessons learned.
The detail in the paper describes an end-to-end Database as a Service solution with Dell and Microsoft product offerings. The entire SysOps, DevOps, and DataOps teams will appreciate the detail in the paper. DbaaS actually realized.
One topic that was very interesting to me was our analysis and resource tuning of Kubernetes workloads. With K8s (what the cool kids say), we have the option to configure our pods with a very tightly defined resource allocation, both requested and limits, for both CPU and memory.
A little test harness history
First, a little history from previous papers with my V1 test harness. I first started working through an automated test harness constructed by using the HammerDB CLI, T-SQL, PowerShell, and even some batch files. Yeah, batch files… I am that old. The HammerDB side of the harness required a sizable virtual machine with regard to CPU and memory—along with the overhead and maintenance of a full-blown Windows OS, which itself requires a decent amount of resource to properly function. Let’s just say this was not the optimal way to go about end-to-end testing, especially with micro-services as an integral part of the harness.
Our previous test harness architecture is represented by this diagram:
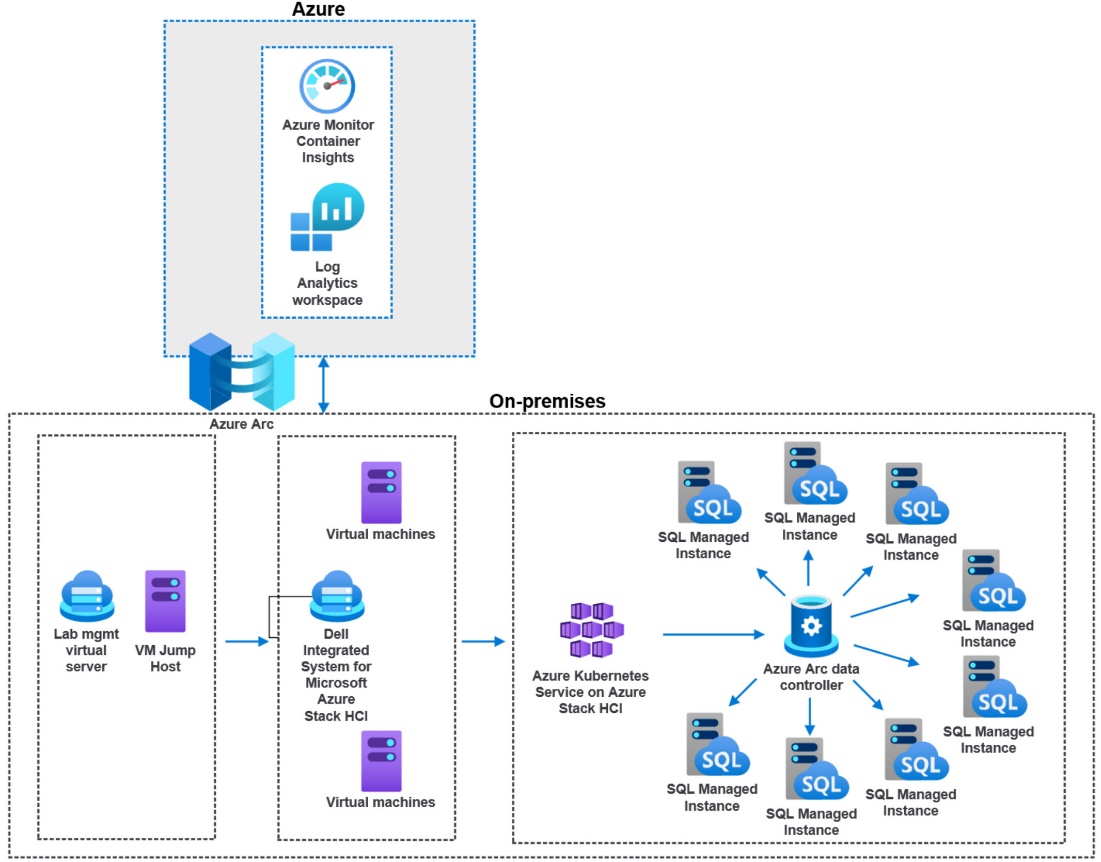
The better answer would be to use micro-services for everything. We were ready and up for the task. This is where I burned some quality cycles with another awesome Dell teammate to move the test harness into a V2 configuration. We decided to use HammerDB within a containerized deployment.
Each HammerDB in a container would map to a separate SQL MI (referenced in the image below). I quickly saw some very timely configuration opportunities where I could dive into resource consolidation. Both the application and the database layers were deployed into their own Kubernetes namespaces. This allowed us a much better way to provide fine-grained resource reporting analysis.
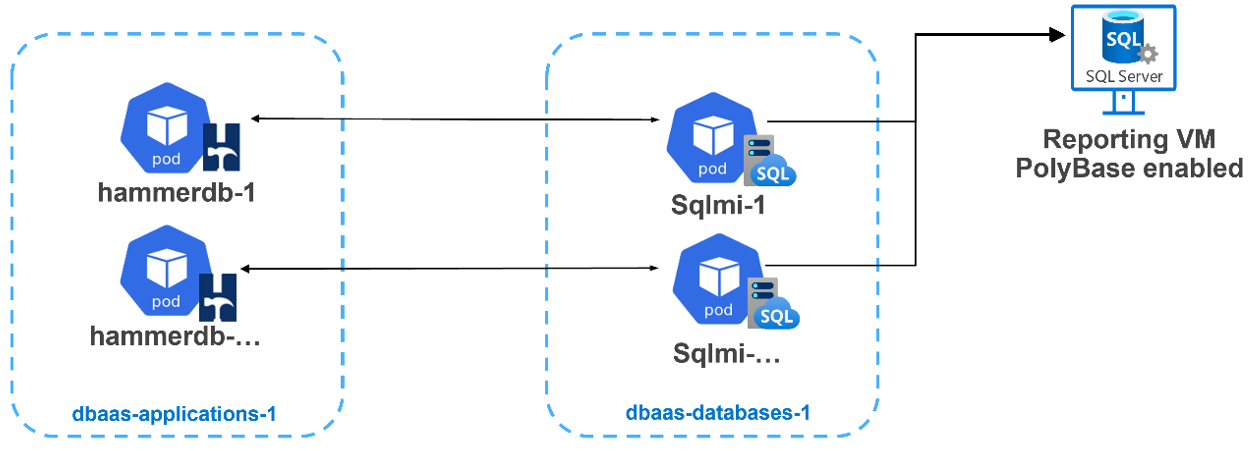
There is a section within our paper regarding the testing we worked through, comparing Kubernetes requests and limits for CPU and memory. For an Azure Arc-enabled SQL managed instance, defining these attributes is required and there are minimums as defined by Microsoft here. But where do you start? How do we size a pod? There are a few pieces of the puzzle to consider:
- What is the resource allocation of each Kubernetes worker node (virtual or physical)— CPU and memory totals?
- How many of these worker nodes exist? Can we scale? Should we use anti-affinity rules? (Not that it is better to let the scheduler sort it out.)
- Kubernetes does have its own overhead. A conservative resource allocation would allow for at least 20 percent overhead for each worker node.
For DbaaS CPU, how do we define our requests and limits?
We know a SQL managed instance is billed on CPU resource limits and not CPU resource requests. This consumption billing leaves us with an interesting paradigm. With any modern architecture, we want to maximize our investment with a very dense, but still performant, SQL Server workload environment. We need to strike a balance.
With microservices, we can finally achieve real consolidation for workloads.
Real… Consolidation...
What do we know about the Kubernetes scheduler around CPU?
- A request for a pod is a guaranteed baseline for the pod. When a pod is initially scheduled and deployed, the request attribute is used.
- Setting a CPU request is a solid best practice when using Kubernetes. This setting does help the scheduler allocate pods efficiently.
- The limit is the hard “limit” that that pod can consume. The CPU limit only affects how the spare CPU is distributed. This is good for a dense and highly consolidated SQL MI deployment.
- With Kubernetes, CPU represents compute processing time that is measured in cores. The minimum is 1m. My HammerDB pod YAML references 500m, or half a core.
- With a CPU limit, you are defining a period and a quota.
- CPU is a compressible resource, and it can be stretched. It can also be throttled if processes request too much.
Let go of the over-provisioning demons
It is time to let go of our physical and virtual machine sizing constructs, where most SQL Server deployments are vastly over-provisioned. I have analyzed and recommended better paths forward for over-provisioned machines for years.
- For SQL Server, do we always consume the limit, or max CPU, 100 percent of the time? I doubt it. Our workloads almost always go up and down—consuming CPU cycles, then pulling back and waiting for more work.
- For workload placement, the scheduler—by the transitive property—therein defines our efficiency and consolidation automatically. However, as mentioned, we do need to reference a CPU limit because it is required.
- There is a great deal of Kubernetes CPU sizing guidance to not use limits; however, for a database workload, this is a good thing, not to mention a requirement and good fundamental database best practice.
- Monitor your workloads with real production-like work to derive the average CPU utilization. If CPU consumption percentages remain low, throttle back the CPU requests and limits.
- Make sure that your requests are accurate for SQL Server. We should not over-provision resource “just because” we may need them.
- Start with half the CPU you had allocated for the same SQL Server running in a virtual machine, then monitor. If still over-provisioned, decrease by half again.
Kubernetes also exists in part to terminate pods that are no longer needed or no longer consuming resources. In fact, I had to fake out the HammerDB container with a “keep-alive” within my YAML file to make sure that the pod remained active long enough to be called upon to run a workload. Notice the command:sleep attribute in this YAML file:
apiVersion: v1 kind: Pod metadata: name: <hammerpod> namespace: <hammernamespace> spec: containers: - name: <hammerpod> image: dbaasregistry/hammerdb:latest command: - "sleep" - "7200" resources: requests: memory: "500M" cpu: "500m" limits: memory: "500M" cpu: "500m" imagePullPolicy: IfNotPresent
Proving out the new architecture
Our new fully deployed architecture is depicted below, with a separation of applications, in this case HammerDB from SQL Server, deployed into separate namespaces. This allows for tighter resource utilization, reporting, and tuning.
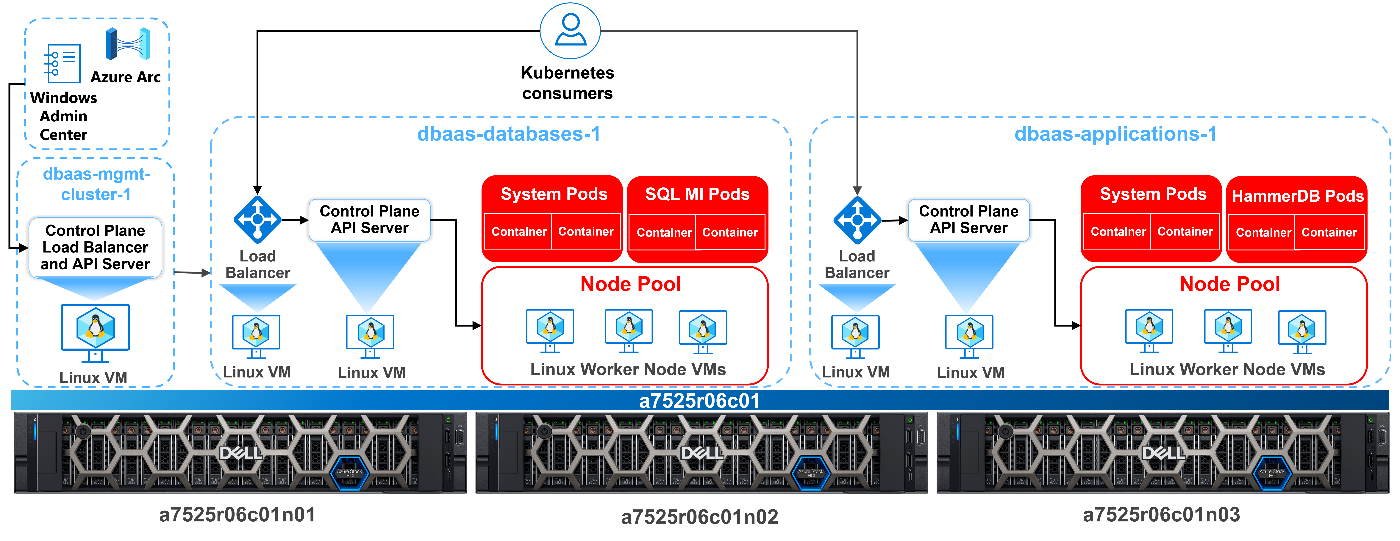
It's also important to note that setting appropriate resources and limits is just one aspect of optimizing your Azure Arc-enabled data services deployment. You should also consider other factors, such as storage configuration, network configuration, and workload characteristics, to ensure that your microservice architecture runs smoothly and efficiently.
Scheduled CPU lessons learned
The tests we conducted and described in the paper gave me some enlightenment regarding proper database microservice sizing. Considering our dense SQL MI workload, we again wanted to maximize the amount of SQL instances we could deploy and keep performance at an acceptable level. I also was very mindful of our consumption-based billing based on CPU limit. For all my tests, I did keep memory as a constant, as it is a finite resource for Kubernetes.
What I found is that performance was identical, and it was even better in some cases when:
- I set CPU requested to half the limit, letting the Kubernetes scheduler do what it is best at—managing resources.
- I monitored the tests and watched resource consumption, tightening up allocation where I could.
My conclusion is this: It is time to let go and not burn my own thinking analysis on trying to outsmart the scheduler. I have better squirrels to go chase and rabbit holes to dive into. 😊
Embrace the IT polyglot mindset
To properly engage and place the best practice stake in the ground, I needed to continue to embrace my polyglot persona. Use all the tools while containerizing all the things! I wrote about this previously here.
I was presenting on the topic of Azure Arc-enabled data services at a recent conference. I have a conversation slide that has a substantial list of tools that I use in my test engineering life. The question was asked, “Do you think all GUI will go away and scripting will again become the norm?” I explained that I think that all tools have their place, depending on the problem or deployment you are working through. For me, scripting is vital for repeatable testing success. You can’t check-in a point-and-click deployment.
There are many GUI tools for Linux and Kubernetes and others. They all have their place, especially when managing very large environments. I do also believe that honing your script skills first is best. Then you understand and appreciate the GUI.
Being an IT polyglot means that you have a broad understanding of various technologies and how they can be used to solve different problems. It also means that you can communicate effectively with developers and other stakeholders, from tin to “C-level” who may have expertise in different areas.
For most everything I do with Azure Arc, I first turn to command line tools, CLI or kubectl to name a few. I love the fact that I can script, check in my work, or feed into a GitOps pipe, and forget about it. It always works on my machine. 😉
To continue developing your skills as an IT polyglot, it's important to stay up to date with the latest industry trends and technologies. This can be done by attending conferences, reading industry blogs and publications, participating in online communities, and experimenting with new tools and platforms. As I have stated in other blogs… #NeverStopLearning
Author: Robert F. Sonders
Technical Staff – Engineering Technologist
Multicloud Storage Software
@RobertSonders | |
robert.sonders@dell.com | |
Blog | https://www.dell.com/en-us/blog/authors/robert-f-sonders/ |
Location | Scottsdale AZ, USA (GMT-7) |

Announcing CSM Release 1.6!
Fri, 31 Mar 2023 19:29:05 -0000
|Read Time: 0 minutes
Introduction
The first release of 2023 for Kubernetes CSI Driver & Dell Container Storage Modules (CSM) is here!
The official changelog is available in the CHANGELOG directory of the CSM repository.
CSI Features
Supported Kubernetes distributions
The newly supported Kubernetes distributions are:
- Kubernetes 1.26
- MKE 3.6
- RKE 1.4
Note: OpenShift 4.12 official qualification is not there yet. Indeed, these modules have been tested against Kubernetes 1.25 which is based on OpenShift 4.12. But you must install them using Helm package manager, not CSI or CSM Operators.
Installation Wizard
One of the major new features for CSI in CSM 1.6 is the Installation Wizard.
If you are a faithful reader of this blog series, you already know that Dell's CSI and CSM moved to pure Helm Charts and are distributed in our helm chart repository. This paved the way for the wizard installer!
Straight from the documentation portal, you can launch the wizard to configure and install the CSI and CSM modules for PowerStore and PowerMax. All the dependencies between CSI and CSM are managed.
The wizard doesn't aim to cover all use cases but gives an excellent default values.yaml, which can always be tuned later.
It has never been easier to install CSI and CSM!
cert-csi open-source
cert-csi is Dell's test framework to validate and qualify drivers against the Kubernetes distributions.
If all tests from cert-csi pass, we call a platform (Linux OS + Kubernetes distribution) certified and officially supported by the Dell Engineering and Support structure.
With cert-csi open-sourced, the community can validate a platform, even if it’s not in the support matrix yet.
For more details about how to use the cert-csi utility, see the documentation portal.
Other features
The dellctl images CLI prints all the container images needed by Dell CSI drivers.
PowerMax Metro volumes are now fully compliant with the CSI specification for volume expansion, clone, and snapshot.
CSM Features
CSM Operator adds PowerStore support
The CSM Operator is the future of the Operator framework for Dell CSI driver and Dell Container Storage Modules and now integrates the modules for PowerStore.
CSM Resiliency PowerStore support
Kubernetes is notably conservative with StatefulSets on node failures: it won't reschedule them automatically and requires an administrator to force the deletion of the pods.
CSM resiliency solves that problem (and more) by querying the backend storage and getting the volumes' status to allow rescheduling in a few seconds after a node is NotReady for Kubernetes.
PowerStore is now part of the supported storage backends!
CSM Replication PowerFlex support
CSM replication supports PowerFlex and it is now possible to combine it with an offering of PowerFlex in AWS. For these types of designs, it is recommended to have low latency between the source and the target. For example, here is the architecture of our lab:
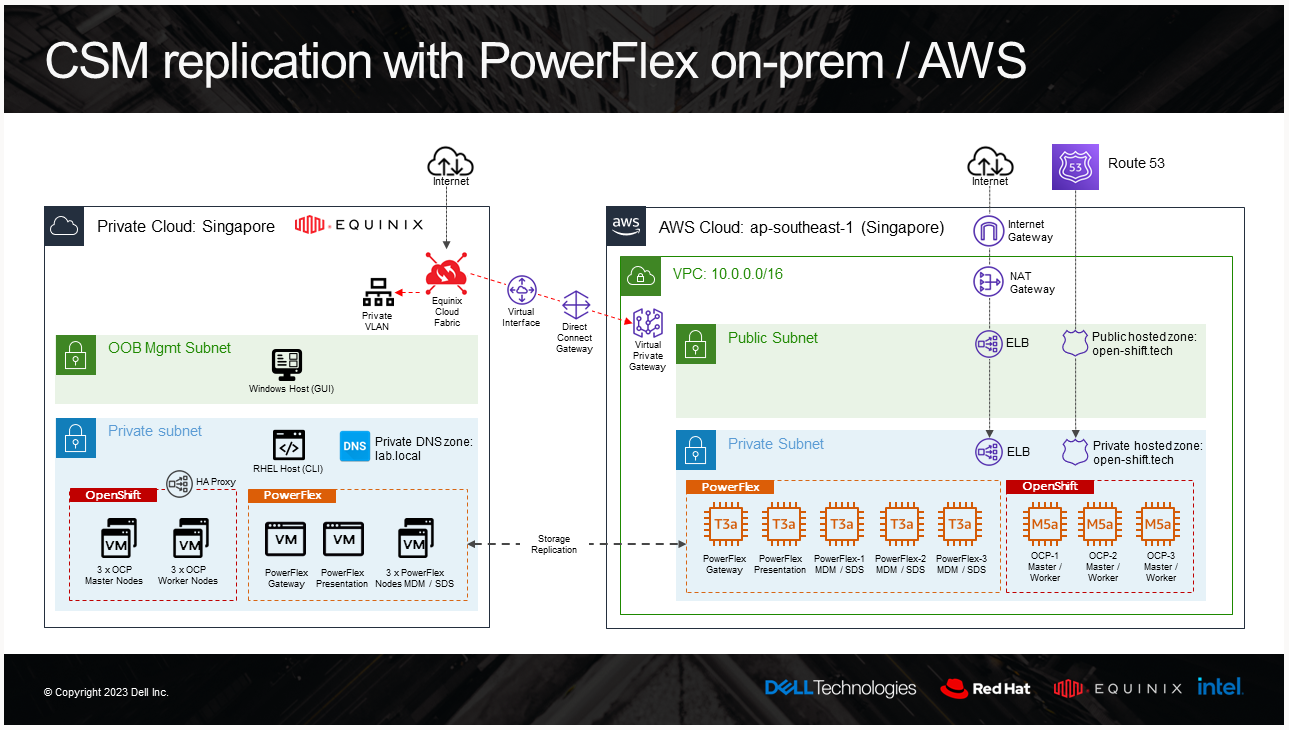
And the result of a replicated volume in PowerFlex UI in AWS looks like this:
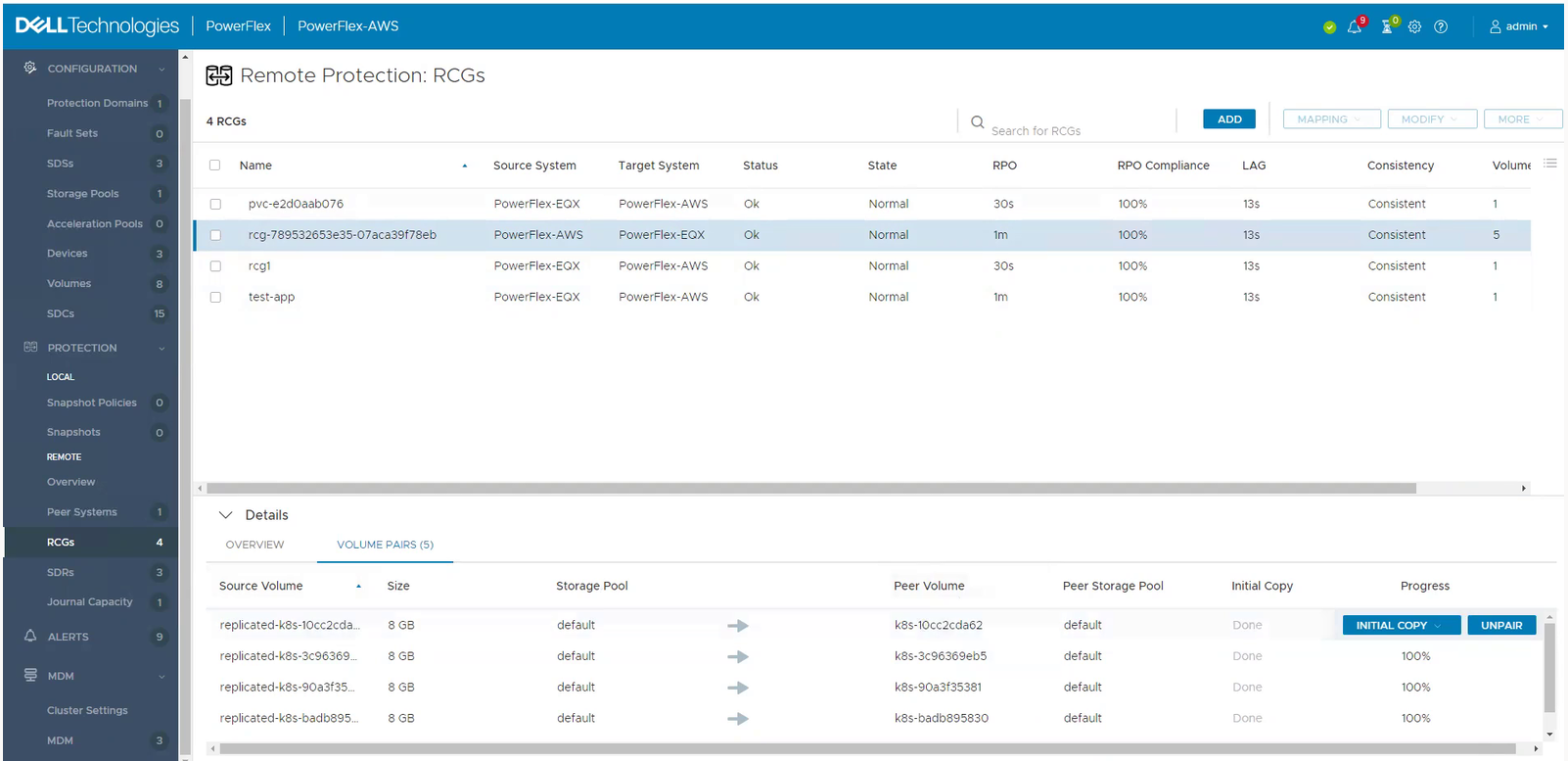
To learn more about PowerFlex in AWS, see the video Dell Project Alpine Gets Real with PowerFlex on AWS and the blog Dell PowerFlex is now available on AWS.
CSM Observability PowerMax support
CSM Observability can collect PowerMax metrics, including the performance of the storage groups that back the PVC, the capacity of the storage resource pool, and more.
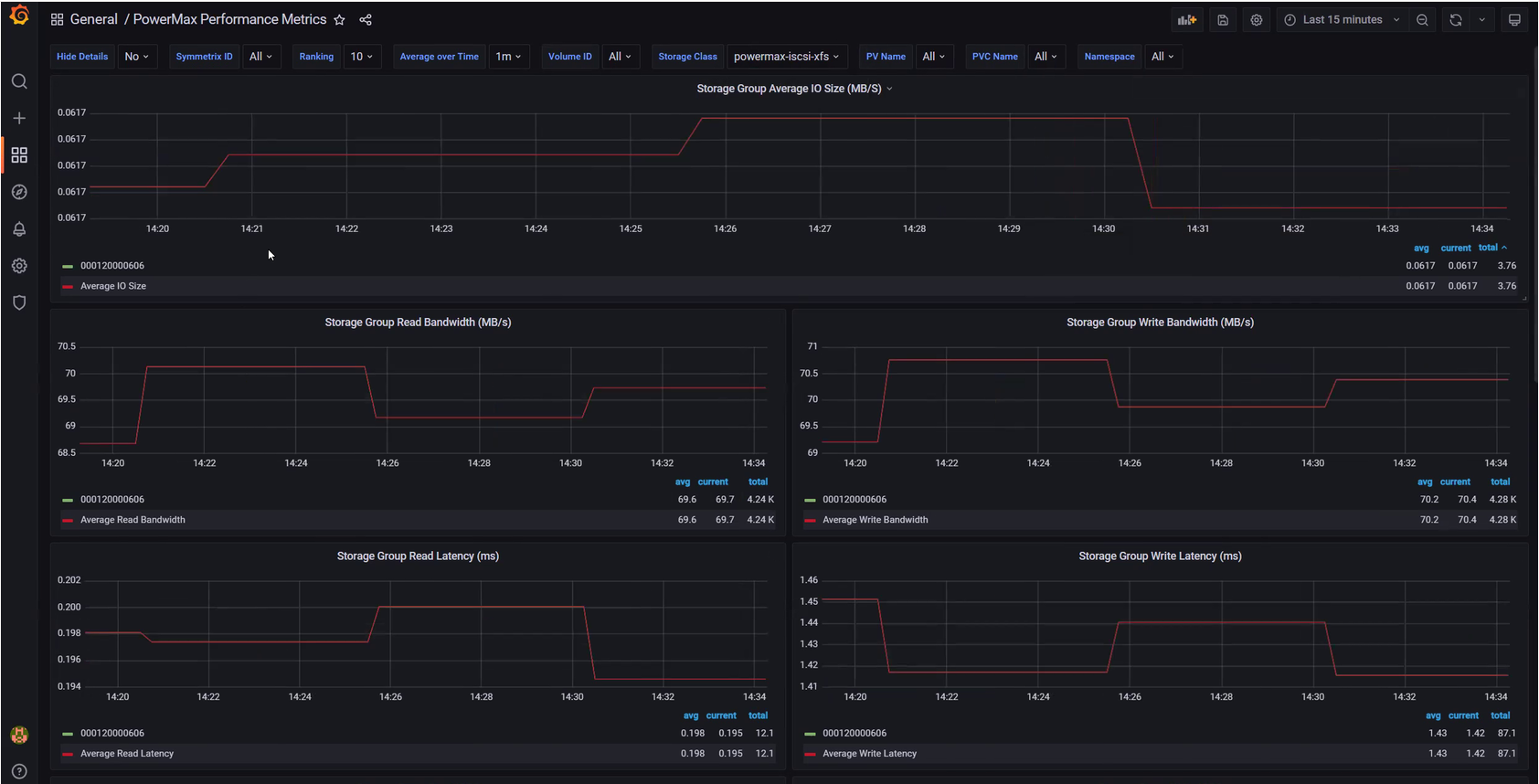
Useful links
Stay informed of the latest updates of the Dell CSM eco-system by subscribing to:
- The Dell CSM Github repository
- Our DevOps & Automation Youtube playlist
- The Slack Workspaces at Dell Technologies
- Demo of CSM replication with PowerFlex
Author: Florian Coulombel

Use Go Debugger’s Delve with Kubernetes and CSI PowerFlex
Wed, 15 Mar 2023 14:41:14 -0000
|Read Time: 0 minutes
Some time ago, I faced a bug where it was important to understand the precise workflow.
One of the beauties of open source is that the user can also take the pilot seat!
In this post, we will see how to compile the Dell CSI driver for PowerFlex with a debugger, configure the driver to allow remote debugging, and attach an IDE.

Compilation
Base image
First, it is important to know that Dell and RedHat are partners, and all CSI/CSM containers are certified by RedHat.
This comes with a couple of constraints, one being that all containers use the Red Hat UBI Minimal image as a base image and, to be certified, extra packages must come from a Red Hat official repo.
CSI PowerFlex needs the e4fsprogs package to format file systems in ext4, and that package is missing from the default UBI repo. To install it, you have these options:
- If you build the image from a registered and subscribed RHEL host, the repos of the server are automatically accessible from the UBI image. This only works with podman build.
- If you have a Red Hat Satellite subscription, you can update the Dockerfile to point to that repo.
- You can use a third-party repository.
- You go the old way and compile the package yourself (the source of that package is in UBI source-code repo).
Here we’ll use an Oracle Linux mirror, which allows us to access binary-compatible packages without the need for registration or payment of a Satellite subscription.
The Oracle Linux 8 repo is:
[oracle-linux-8-baseos] name=Oracle Linux 8 - BaseOS baseurl=http://yum.oracle.com/repo/OracleLinux/OL8/baseos/latest/x86_64 gpgcheck = 0 enabled = 1
And we add it to final image in the Dockerfile with a COPY directive:
# Stage to build the driver image
FROM $BASEIMAGE@${DIGEST} AS final
# install necessary packages
# alphabetical order for easier maintenance
COPY ol-8-base.repo /etc/yum.repos.d/
RUN microdnf update -y && \
...Delve
There are several debugger options available for Go. You can use the venerable GDB, a native solution like Delve, or an integrated debugger in your favorite IDE.
For our purposes, we prefer to use Delve because it allows us to connect to a remote Kubernetes cluster.
Our Dockerfile employs a multi-staged build approach. The first stage is for building (and named builder) from the Golang image; we can add Delve with the directive:
RUN go install github.com/go-delve/delve/cmd/dlv@latest
And then compile the driver.
On the final image that is our driver, we add the binary as follows:
# copy in the driver COPY --from=builder /go/src/csi-vxflexos / COPY --from=builder /go/bin/dlv /
In the build stage, we download Delve with:
RUN go get github.com/go-delve/delve/cmd/dlv
In the final image we copy the binary with:
COPY --from=builder /go/bin/dlv /
To achieve better results with the debugger, it is important to disable optimizations when compiling the code.
This is done in the Makefile with:
CGO_ENABLED=0 GOOS=linux GO111MODULE=on go build -gcflags "all=-N -l"
After rebuilding the image with make docker and pushing it to your registry, you need to expose the Delve port for the driver container. You can do this by adding the following lines to your Helm chart. We need to add the lines to the driver container of the Controller Deployment.
ports: - containerPort: 40000
Alternatively, you can use the kubectl edit -n powerflex deployment command to modify the Kubernetes deployment directly.
Usage
Assuming that the build has been completed successfully and the driver is deployed on the cluster, we can expose the debugger socket locally by running the following command:
kubectl port-forward -n powerflex pod/csi-powerflex-controller-uid 40000:40000
Next, we can open the project in our favorite IDE and ensure that we are on the same branch that was used to build the driver.
In the following screenshot I used Goland, but VSCode can do remote debugging too.
We can now connect the IDE to that forwarded socket and run the debugger live:
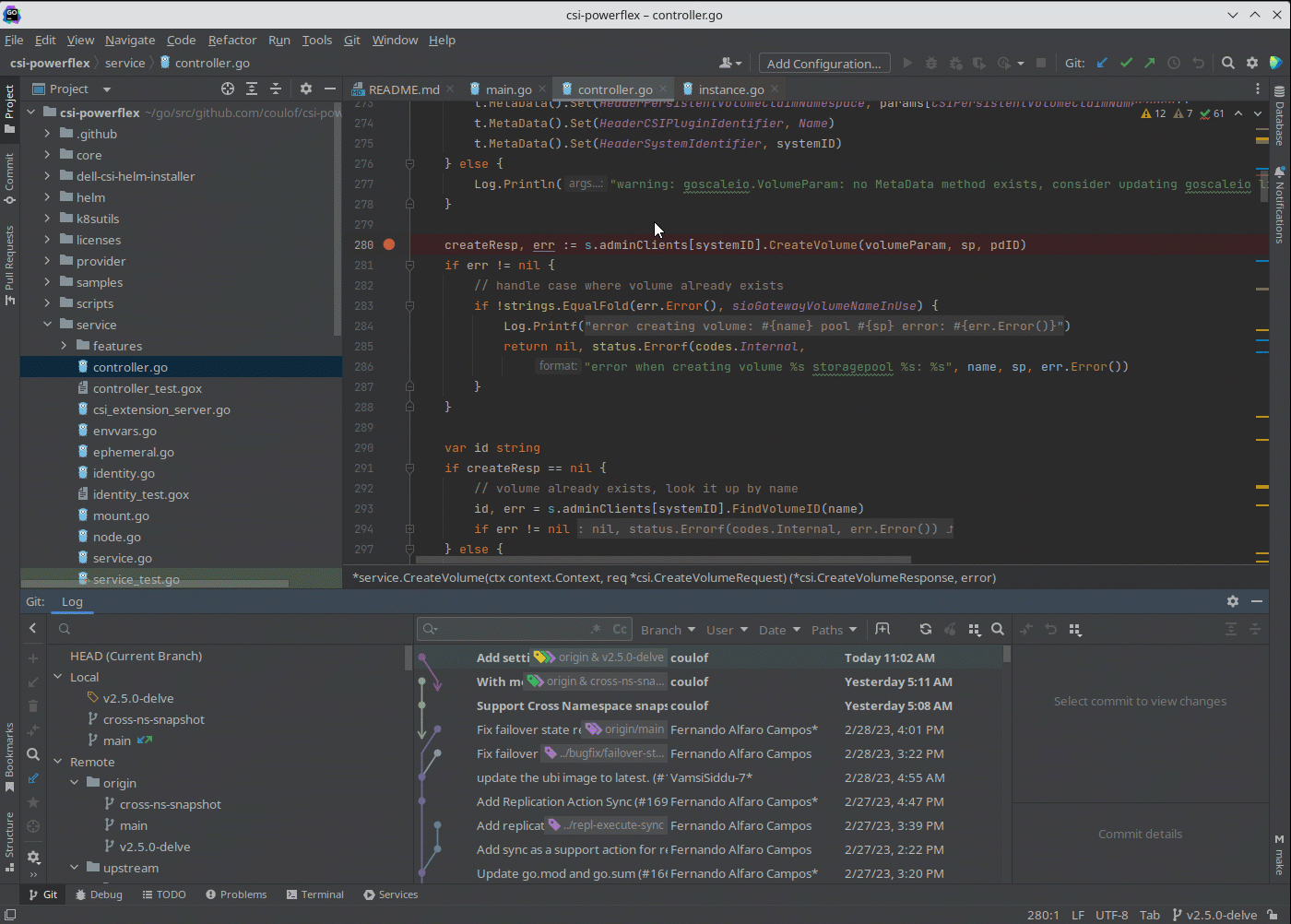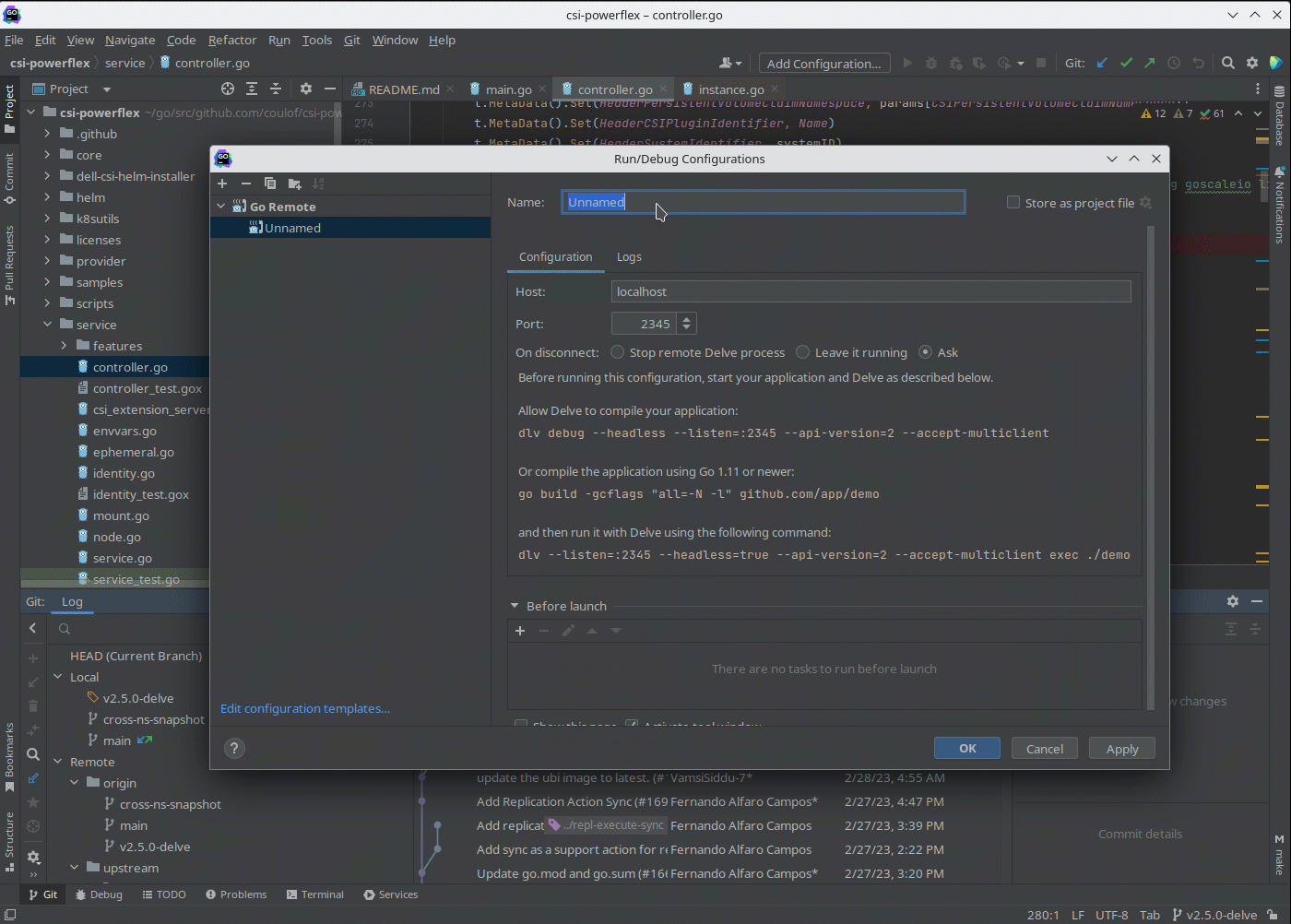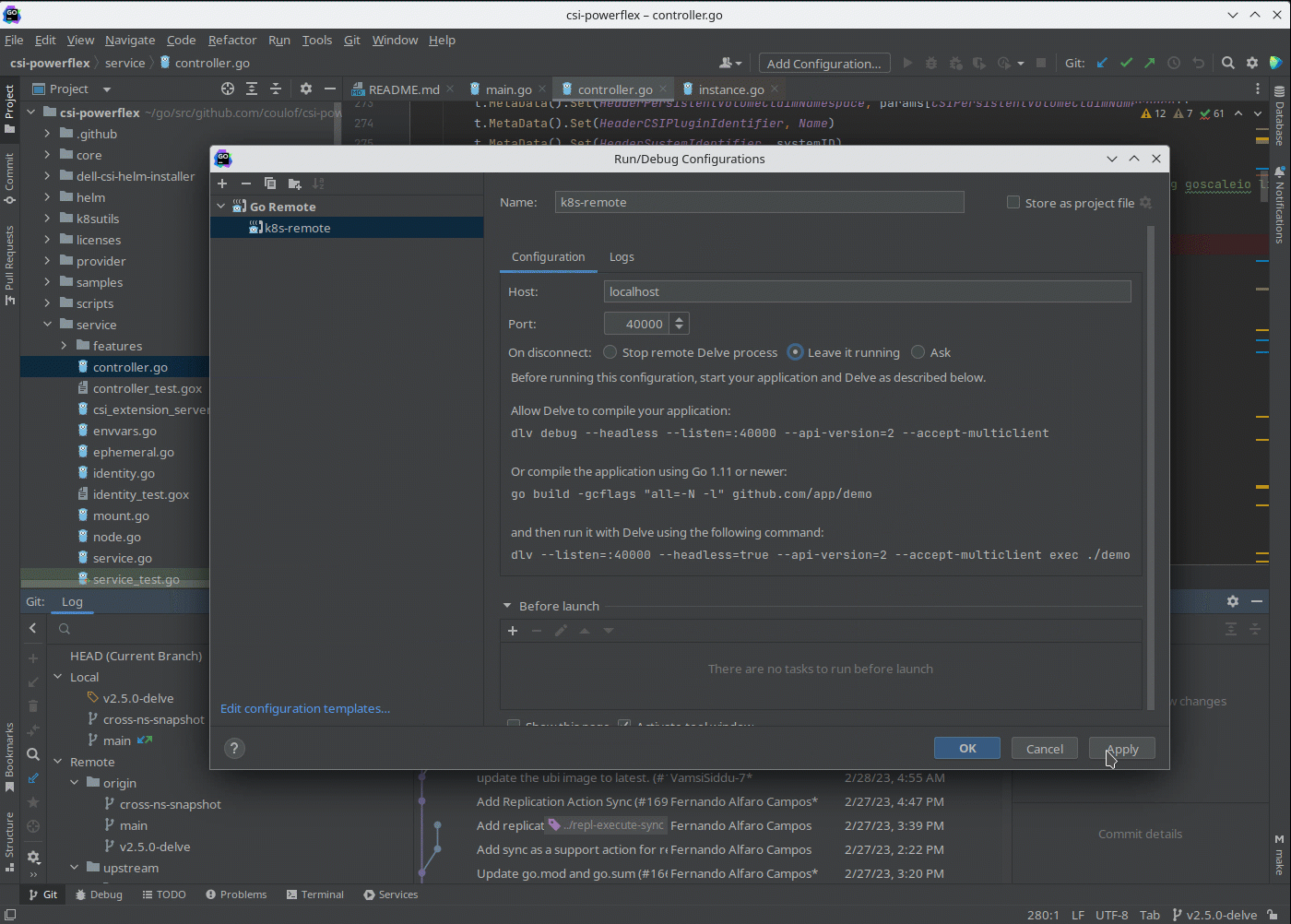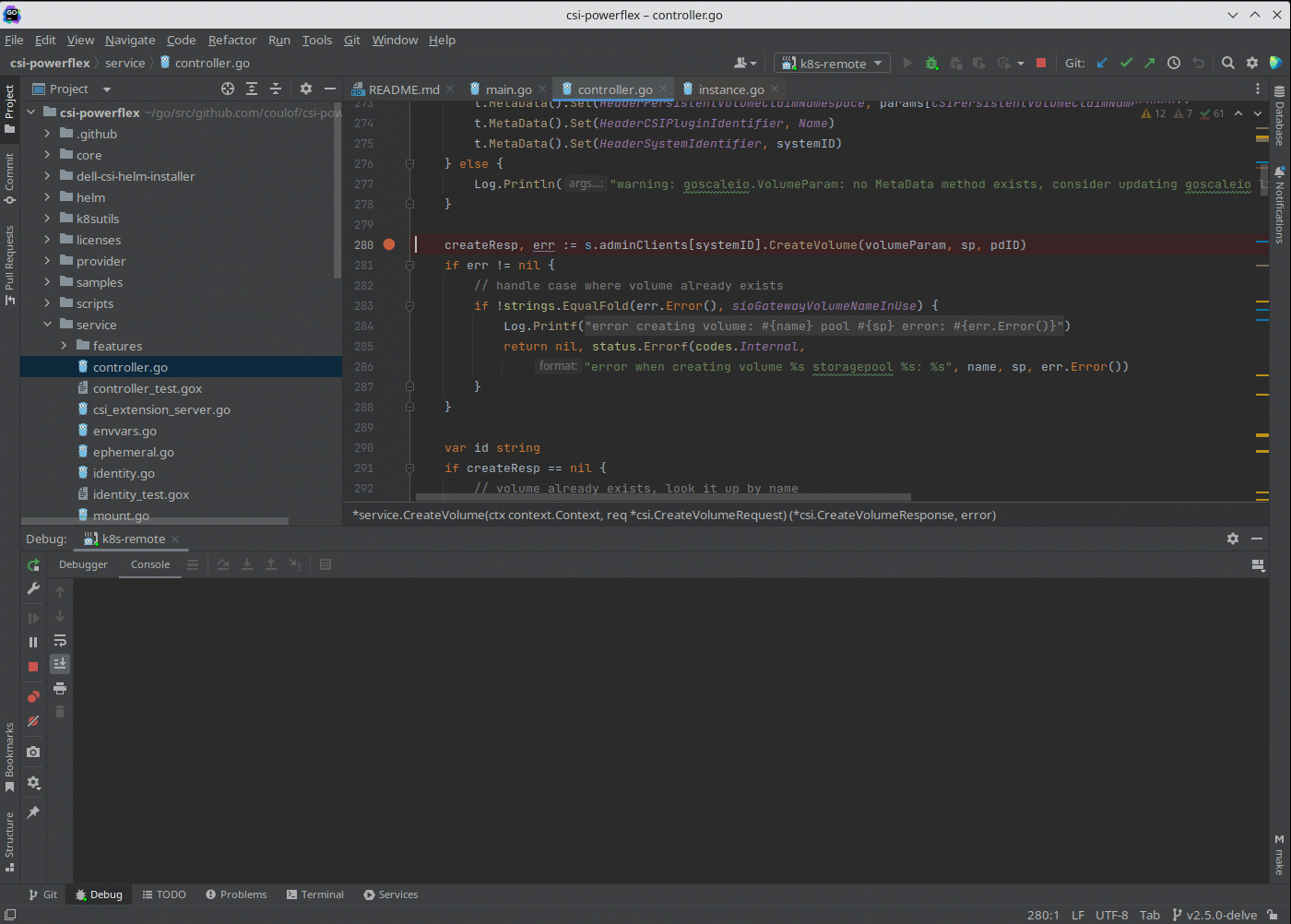
And here is the result of a breakpoint on CreateVolume call: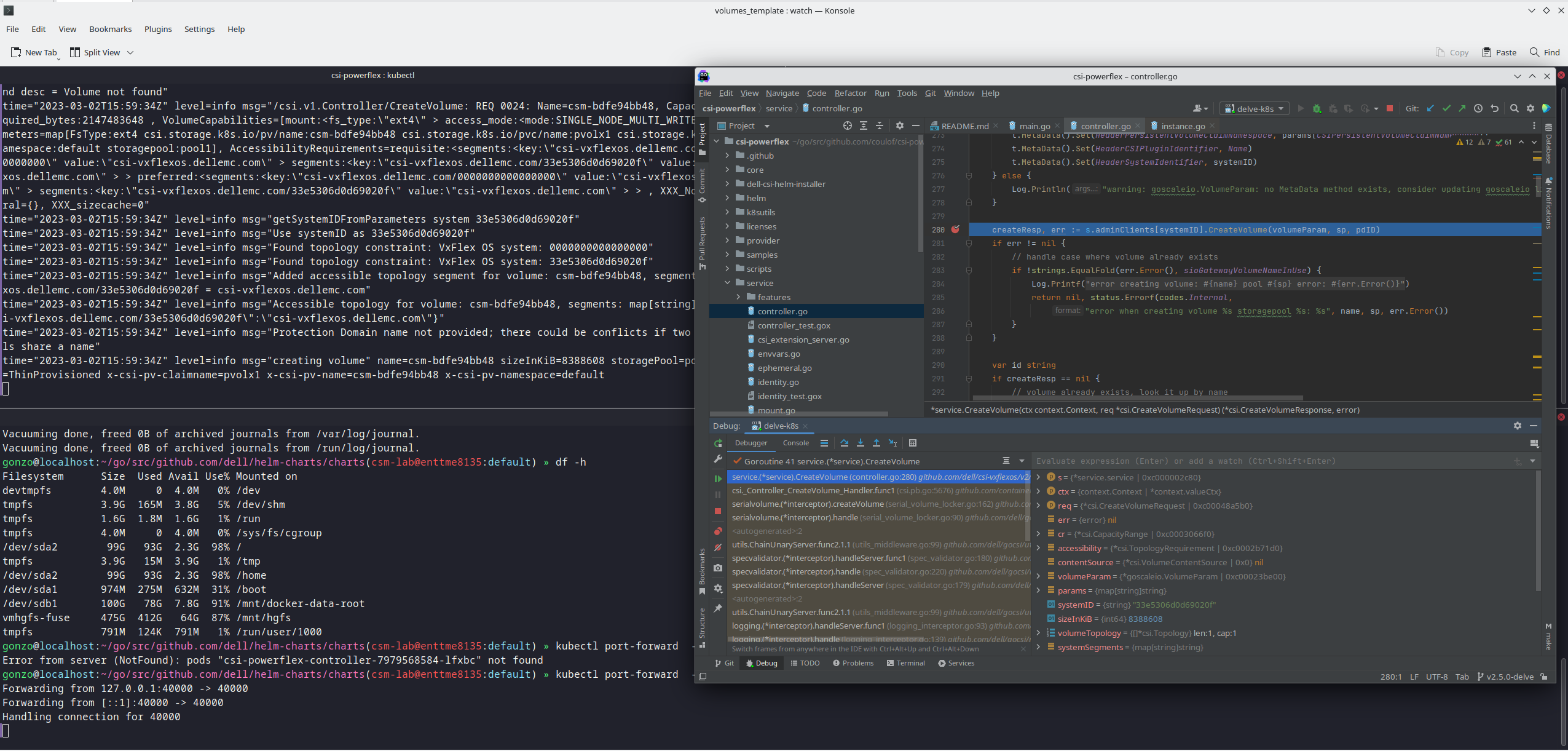
The full code is here: https://github.com/dell/csi-powerflex/compare/main...coulof:csi-powerflex:v2.5.0-delve.
If you liked this information and need more deep-dive details on Dell CSI and CSM, feel free to reach out at https://dell-iac.slack.com.
Author: Florian Coulombel

Dell PowerStore and Unity XT CSI Drivers Now Available in the Rancher Marketplace
Tue, 07 Feb 2023 23:00:11 -0000
|Read Time: 0 minutes
I am excited to announce that the PowerStore CSI driver and the Unity XT CSI driver are now available in the Rancher Marketplace. Customers have always been able to deploy the CSI drivers on any compatible Kubernetes cluster through a series of manual steps and command lines. If you are using Rancher to manage your Kubernetes clusters, you can now seamlessly deploy the drivers to the managed Kubernetes clusters through the familiar Rancher UI.
Dell CSI drivers
PowerStore CSI driver and Unity XT CSI driver are storage providers for Kubernetes that provide persistent storage for containers. Many containerized workloads, such as databases, often require storing data for a long period of time. The data also needs to follow the containers whenever they move between the Kubernetes nodes. With Dell CSI drivers, database applications can easily request and mount the storage from Dell storage systems as part of the automated workflow. Customers also benefit from the advanced data protection and data reduction features of Dell storage systems.
SUSE Rancher
Rancher is a high-performing open-source Kubernetes management platform. For those who operate and manage multiple Kubernetes clusters across on-premises and in the cloud, Rancher is an attractive solution because of its powerful features that unify the management and security of multiple Kubernetes clusters. Rancher can deploy and manage clusters running on on-premises infrastructure, such as VMware vSphere and on cloud providers such as Azure AKS, Google GKS, and Amazon EKS. Rancher also enhances and simplifies security with centralized user authentication, access control, and observability. The integrated App Catalog provides easy access to third-party applications and simplifies the deployment of complex applications.
The benefits of deploying Dell CSI drivers through the Rancher App Catalog are:
- The App Catalog is based on Helm, a Kubernetes package manager. Dell CSI drivers include the Helm charts in the App Catalog to facilitate the installation and deployment process.
- You can be confident that both Dell and SUSE have validated the deployment process.
- A single management UI to manage all aspects of your Kubernetes clusters.
- Enhances and centralizes user authentication and access control.
- Simplifies the deployment process with fewer command lines and an intuitive HTML5 UI.
- Pre-defined configurations are supplied. You can take the default values or make any necessary adjustments based on your needs.
- Makes it easy to monitor and troubleshoot issues. You can view the status and log files of the cluster components and applications directly in the UI.
How to deploy the CSI driver in Rancher
Let me show you a simple deployment of the CSI driver in Rancher here.
NOTE: Dell CSI drivers are regularly updated for compatibility with the latest Kubernetes version. Keep in mind that the information in this article might change in future releases. To get the latest updates, check the documentation on the Dell Github page (https://dell.github.io/csm-docs/docs).
1. First, review the requirements of the CSI driver. On the Rancher home page, click on a managed cluster. Then, on the left side panel, go to Apps > Charts. In the filter field, enter dell csi to narrow down the results. Click on the CSI driver you want to install. The install page displays the driver’s readme file that describes the overall installation process and the prerequisites for the driver. Perform all necessary prerequisite steps before moving on to the next step.
These prerequisites include, but are not limited to, ensuring that the iSCSI software, NVMe software, and NFS software are available on the target Kubernetes nodes, and that FC zoning is in place.
2. Create a new namespace for the CSI driver in which the driver software will be installed. On the left side panel, go to Cluster > Projects/Namespaces and create a new namespace. Create a csi-powerstore namespace for PowerStore or a unity namespace for Unity XT.
You can optionally define the Container Resource Limit if desired. 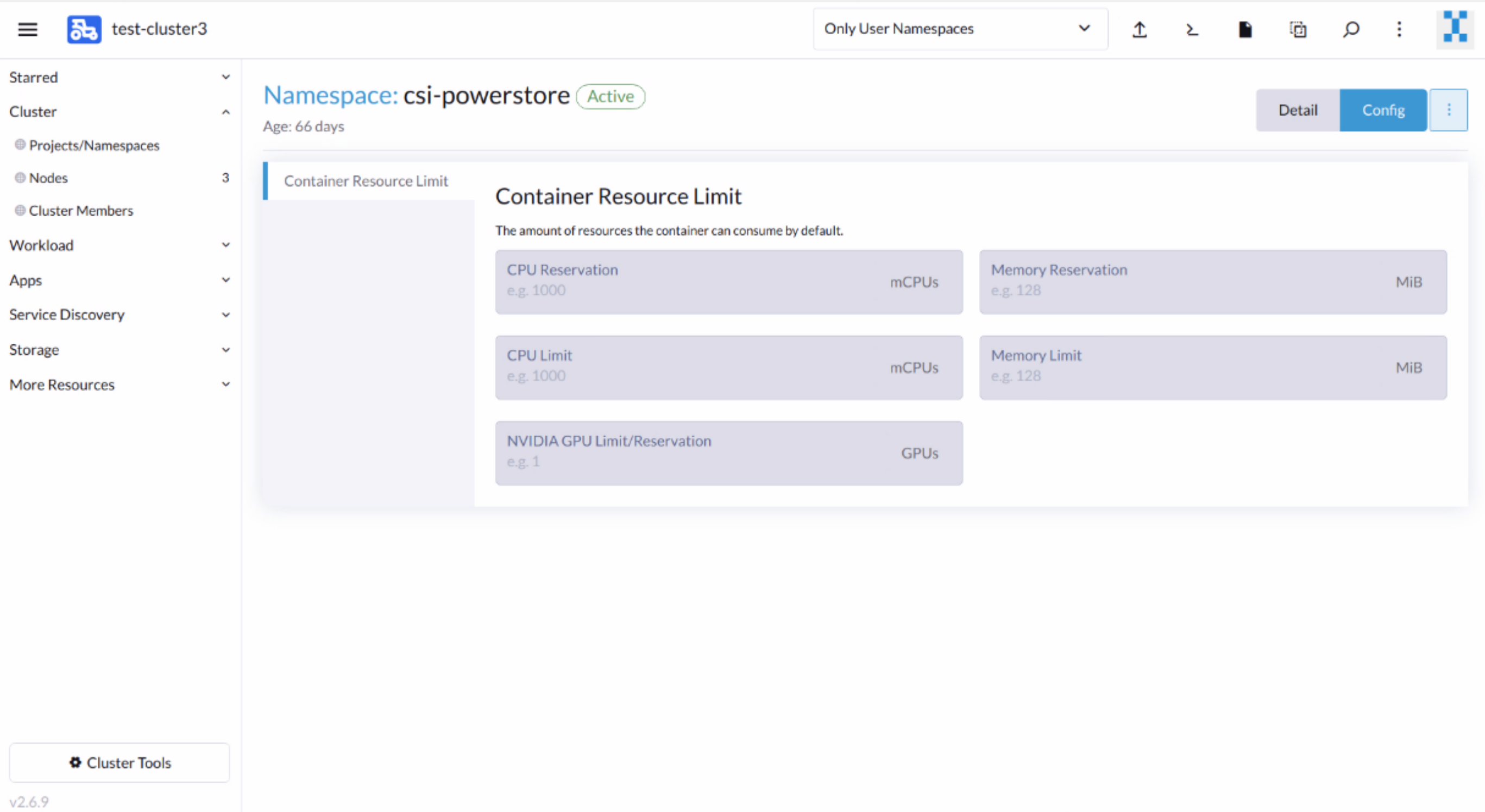
3. The CSI driver requires the array connection and credential information. Create a secret to store this information for the storage systems. On the left side panel, go to Cluster > Storage > Secrets.
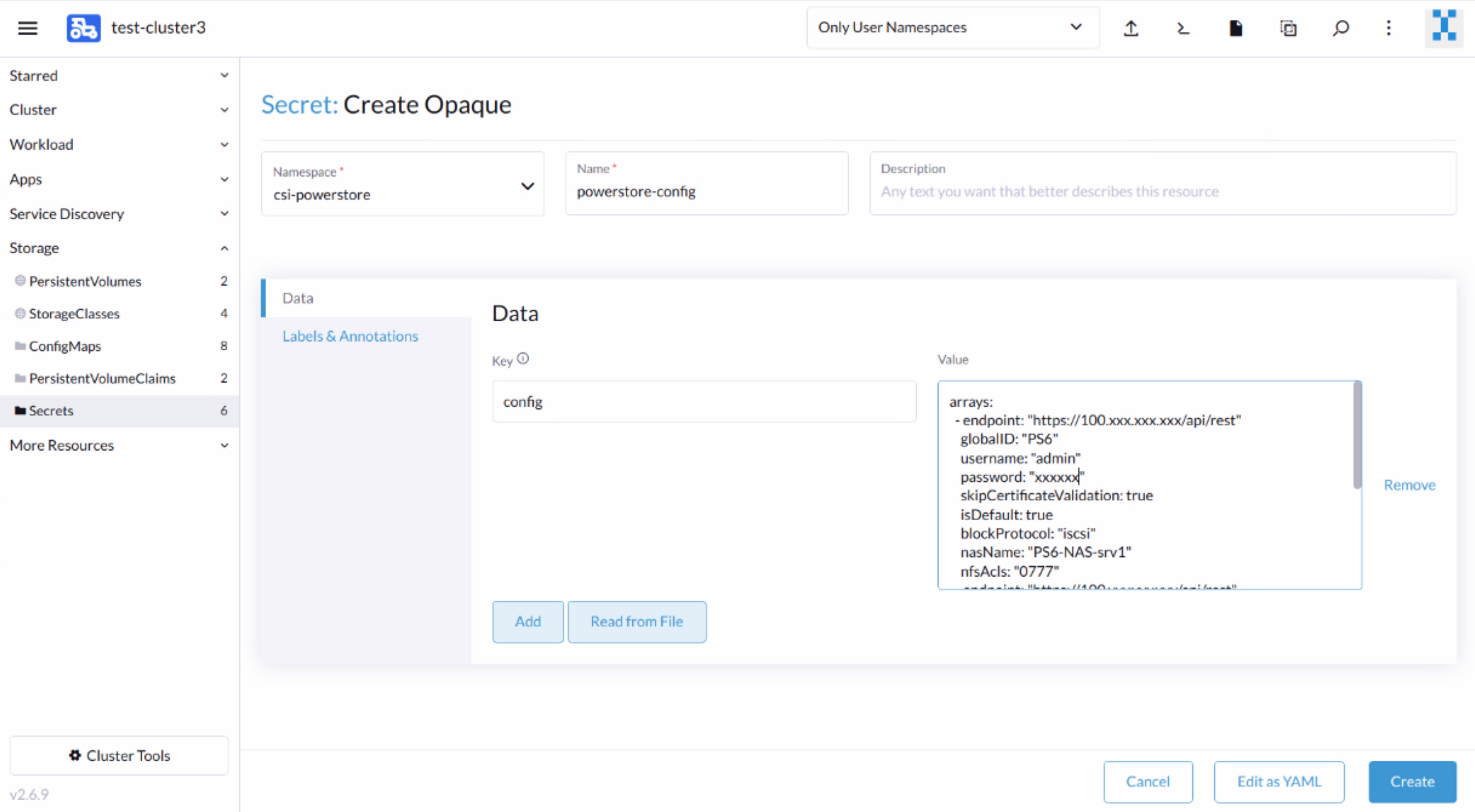
For PowerStore:
- Create an Opaque (generic) secret using a key-value pair in the csi-powerstore namespace.
- The secret name must be powerstore-config, with the single key name config. Copy the contents of the secret.yaml file to the value field. A sample secret.yaml file with parameter definitions is available here.
- You can define multiple arrays in the same secret.
For Unity XT:
- Create an Opaque (generic) secret using the key-value pair in the unity namespace.
- The secret name must be unity-creds, with the single key name config. Copy the contents of the secret.yaml file to the value field. A sample secret.yaml file is available here.
- You can define multiple arrays in the same secret.
- The Unity XT CSI driver also requires a certificate secret for Unity XT certificate validation. The secrets are named unity-certs-0, unity-certs-1, and so on. Each secret contains the X509 certificate of the CA that signed the Unisphere SSL certificate, in PEM format. More information is available here.
4. Now, we are ready to install the CSI driver. Go to Apps > Charts and select the CSI driver. Click Install to start the guided installation process.
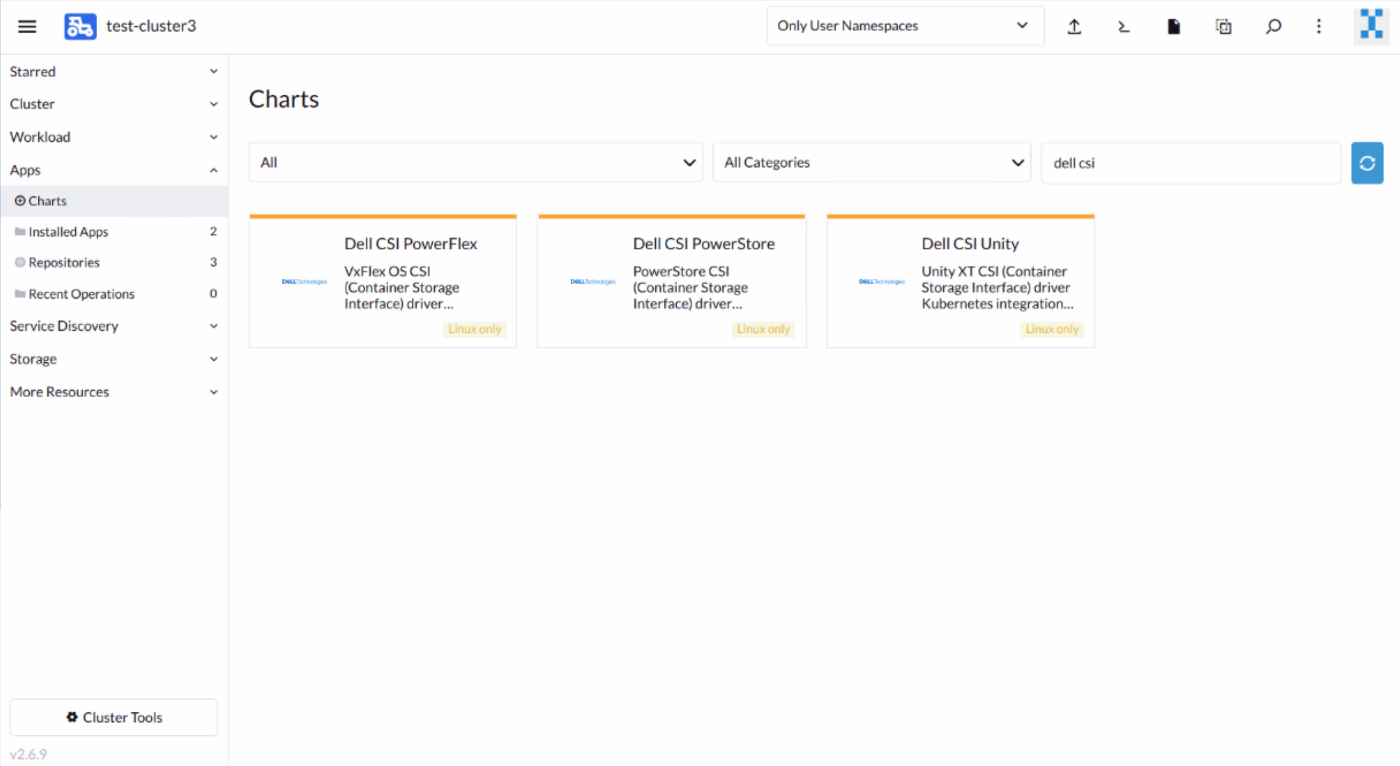
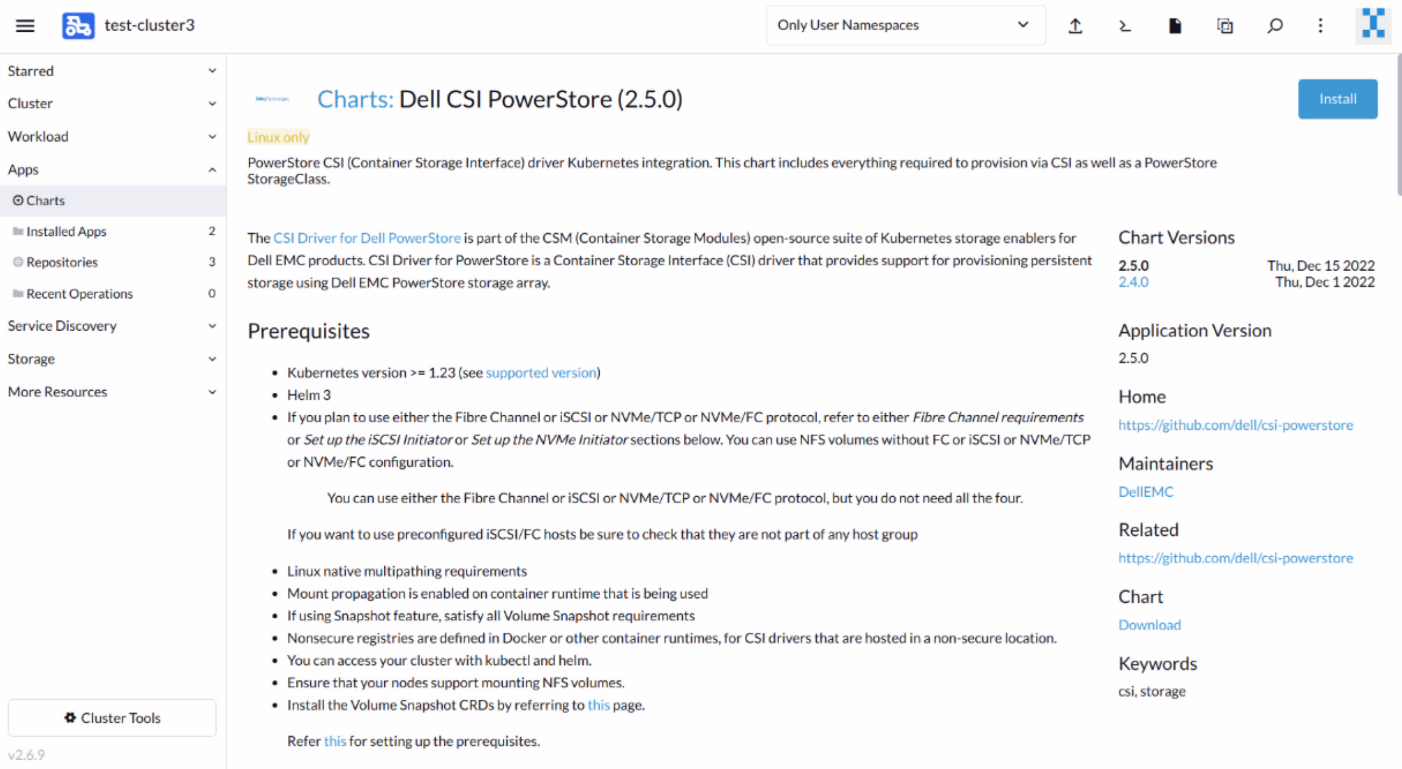
Select the appropriate namespace (csi-powerstore or unity) for the corresponding driver.
The guided installation also pre-populates the driver configuration in key/value parameters. Review and modify the configuration to suit your requirements. You can find the detailed information about these parameters in the Helm Chart info page (Click the ViewChart Info button on the installation page). (A copy of the values.yaml file that the installation uses is available here for PowerStore and here for Unity XT.)
When the installation starts, you can monitor its progress in Rancher and observe the different resources being created and started. The UI also offers easy access to the resource log files to help troubleshooting issues during the installation.
5. Before using the CSI driver to provision Dell storage, we need to create StorageClasses that define which storage array to use and their attributes. The StorageClasses are used in Persistent Volumes to dynamically provision persistent storage.
To create StorageClasses for Dell storage systems, we use the Import YAML function to create them. If you use the Create function under Storage > StorageClasses, the UI does not offer the Dell storage provisioners in the drop-down menu. Copy and paste the contents of the StorageClass yaml file to the Import Dialog window. (Sample PowerStore StorageClasses yaml files are available here; sample Unity XT StorageClasses yaml files are available here.)
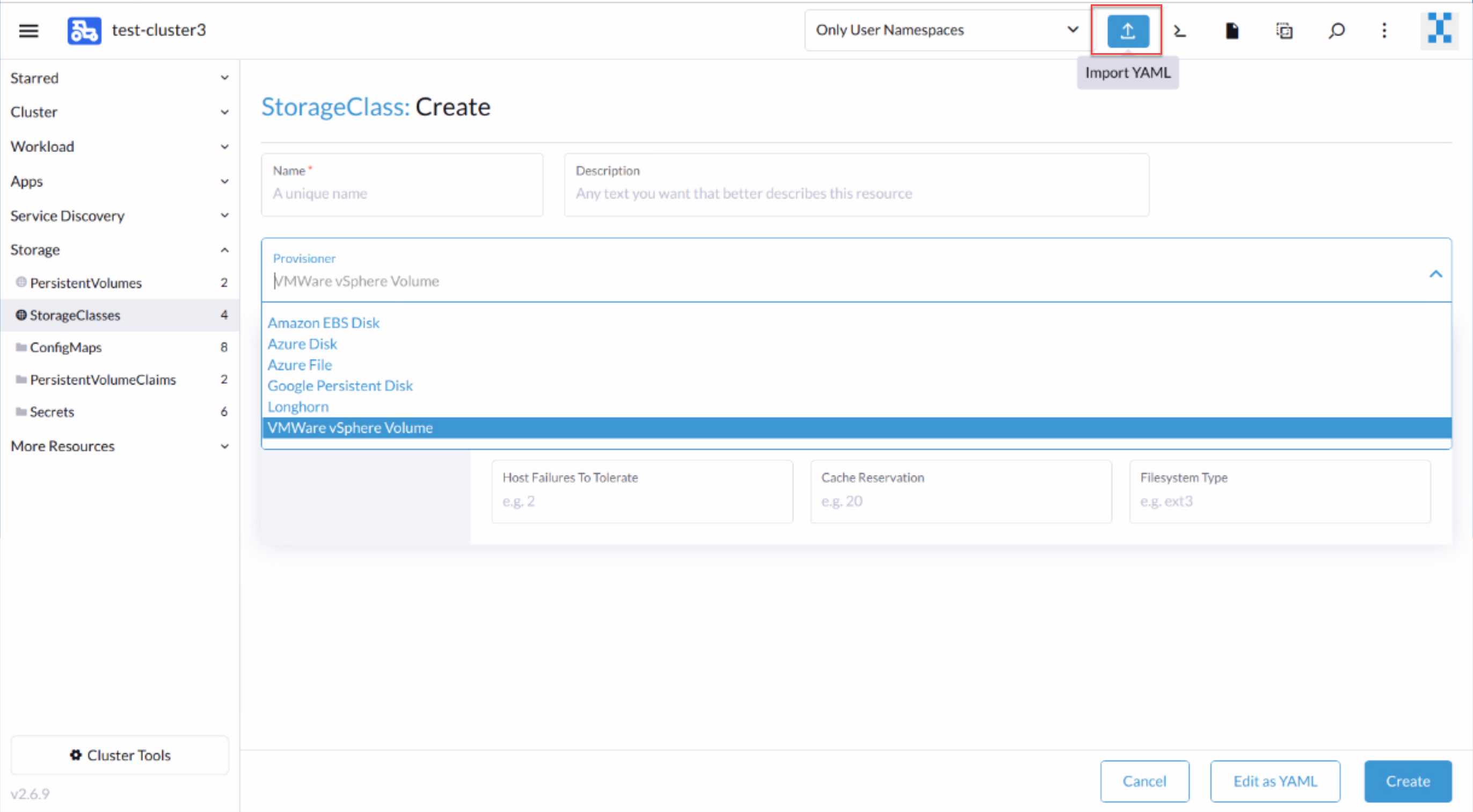
Congratulations! You have now deployed the Dell CSI driver in a Kubernetes Cluster using Rancher and are ready to provision persistent storage for the cluster applications.
Conclusion
Deploying and managing Dell CSI drivers on multiple Kubernetes clusters is made simple with Rancher. Dell storage systems are ideal storage platforms for containers to satisfy the need for flexible, scalable, and highly efficient storage. The powerful features of Rancher streamline the deployment and operation of Kubernetes clusters with unified management and security.
Resources
- https://github.com/dell/csi-powerstore
- https://github.com/dell/csi-unity
- https://dell.github.io/csm-docs/docs/csidriver/installation/
Author: Henry Wong, Senior Principal Engineering Technologist

CSI drivers 2.0 and Dell EMC Container Storage Modules GA!
Thu, 26 Jan 2023 19:18:02 -0000
|Read Time: 0 minutes
The quarterly update for Dell CSI Driver is here! But today marks a significant milestone because we are also announcing the availability of Dell EMC Container Storage Modules (CSM). Here’s what we’re covering in this blog:
Container Storage Modules
Dell Container Storage Modules is a set of modules that aims to extend Kubernetes storage features beyond what is available in the CSI specification.
The CSM modules will expose storage enterprise features directly within Kubernetes, so developers are empowered to leverage them for their deployment in a seamless way.
Most of these modules are released as sidecar containers that work with the CSI driver for the Dell storage array technology you use.
CSM modules are open-source and freely available from : https://github.com/dell/csm.
Volume Group Snapshot
Many stateful apps can run on top of multiple volumes. For example, we can have a transactional DB like Postgres with a volume for its data and another for the redo log, or Cassandra that is distributed across nodes, each having a volume, and so on.
When you want to take a recoverable snapshot, it is vital to take them consistently at the exact same time.
Dell CSI Volume Group Snapshotter solves that problem for you. With the help of a CustomResourceDefinition, an additional sidecar to the Dell CSI drivers, and leveraging vanilla Kubernetes snapshots, you can manage the life cycle of crash-consistent snapshots. This means you can create a group of volumes for which the drivers create snapshots, restore them, or move them with one shot simultaneously!
To take a crash-consistent snapshot, you can either use labels on your PersistantVolumeClaim, or be explicit and pass the list of PVCs that you want to snap. For example:
apiVersion: v1 apiVersion: volumegroup.storage.dell.com/v1alpha2 kind: DellCsiVolumeGroupSnapshot metadata: # Name must be 13 characters or less in length name: "vg-snaprun1" spec: driverName: "csi-vxflexos.dellemc.com" memberReclaimPolicy: "Retain" volumesnapshotclass: "poweflex-snapclass" pvcLabel: "vgs-snap-label" # pvcList: # - "pvcName1" # - "pvcName2"
For the first release, CSI for PowerFlex supports Volume Group Snapshot.
Observability
The CSM Observability module is delivered as an open-telemetry agent that collects array-level metrics to scrape them for storage in a Prometheus DB.
The integration is as easy as creating a Prometheus ServiceMonitor for Prometheus. For example:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: otel-collector
namespace: powerstore
spec:
endpoints:
- path: /metrics
port: exporter-https
scheme: https
tlsConfig:
insecureSkipVerify: true
selector:
matchLabels:
app.kubernetes.io/instance: karavi-observability
app.kubernetes.io/name: otel-collectorWith the observability module, you will gain visibility on the capacity of the volume you manage with Dell CSI drivers and their performance, in terms of bandwidth, IOPS, and response time.
Thanks to pre-canned Grafana dashboards, you will be able to go through these metrics’ history and see the topology between a Kubernetes PersistentVolume (PV) until its translation as a LUN or fileshare in the backend array.
The Kubernetes admin can also collect array level metrics to check the overall capacity performance directly from the familiar Prometheus/Grafana tools.
For the first release, Dell EMC PowerFlex and Dell EMC PowerStore support CSM Observability.
Replication
Each Dell storage array supports replication capabilities. It can be asynchronous with an associated recovery point objective, synchronous replication between sites, or even active-active.
Each replication type serves a different purpose related to the use-case or the constraint you have on your data centers.
The Dell CSM replication module allows creating a persistent volume that can be of any of three replication types -- synchronous, asynchronous, and metro -- assuming the underlying storage box supports it.
The Kubernetes architecture can build on a stretched cluster between two sites or on two or more independent clusters. The module itself is composed of three main components:
- The Replication controller whose role is to manage the CustomResourceDefinition that abstracts the concept of Replication across the Kubernetes cluster
- The Replication sidecar for the CSI driver that will convert the Replication controller request to an actual call on the array side
- The repctl utility, to simplify managing replication objects across multiple Kubernetes clusters
The usual workflow is to create a PVC that is replicated with a classic Kubernetes directive by just picking the right StorageClass. You can then use repctl or edit the DellCSIReplicationGroup CRD to launch operations like Failover, Failback, Reprotect, Suspend, Synchronize, and so on.
For the first release, Dell EMC PowerMax and Dell EMC PowerStore support CSM Replication.
Authorization
With CSM Authorization we are giving back more control of storage consumption to the storage administrator.
The authorization module is an independent service, installed and owned by the storage admin.
Within that module, the storage administrator will create access control policies and storage quotas to make sure that Kubernetes consumers are not overconsuming storage or trying to access data that doesn’t belong to them.
CSM Authorization makes multi-tenant architecture real by enforcing Role-Based Access Control on storage objects coming from multiple and independent Kubernetes clusters.
The authorization module acts as a proxy between the CSI driver and the backend array. Access is granted with an access token that can be revoked at any point in time. Quotas can be changed on the fly to limit or increase storage consumption from the different tenants.
For the first release, Dell EMC PowerMax and Dell EMC PowerFlex support CSM Authorization.
Resilency
When dealing with StatefulApp, if a node goes down, vanilla Kubernetes is pretty conservative.
Indeed, from the Kubernetes control plane, the failing node is seen as not ready. It can be because the node is down, or because of network partitioning between the control plane and the node, or simply because the kubelet is down. In the latter two scenarios, the StatefulApp is still running and possibly writing data on disk. Therefore, Kubernetes won’t take action and lets the admin manually trigger a Pod deletion if desired.
The CSM Resiliency module (sometimes named PodMon) aims to improve that behavior with the help of collected metrics from the array.
Because the driver has access to the storage backend from pretty much all other nodes, we can see the volume status (mapped or not) and its activity (are there IOPS or not). So when a node goes into NotReady state, and we see no IOPS on the volume, Resiliency will relocate the Pod to a new node and clean whatever leftover objects might exist.
The entire process happens in seconds between the moment a node is seen down and the rescheduling of the Pod.
To protect an app with the resiliency module, you only have to add the label podmon.dellemc.com/driver to it, and it is then protected.
For more details on the module’s design, you can check the documentation here.
For the first release, Dell EMC PowerFlex and Dell EMC Unity support CSM Resiliency.
Installer
Each module above is released either as an independent helm chart or as an option within the CSI Drivers.
For more complex deployments, which may involve multiple Kubernetes clusters or a mix of modules, it is possible to use the csm installer.
The CSM Installer, built on top of carvel gives the user a single command line to create their CSM-CSI application and to manage them outside the Kubernetes cluster.
For the first release, all drivers and modules support the CSM Installer.
New CSI features
Across portfolio
For each driver, this release provides:
- Support of OpenShift 4.8
- Support of Kubernetes 1.22
- Support of Rancher Kubernetes Engine 2
- Normalized configurations between drivers
- Dynamic Logging Configuration
- New CSM installer
VMware Tanzu Kubernetes Grid
VMware Tanzu offers storage management by means of its CNS-CSI driver, but it doesn’t support ReadWriteMany access mode.
If your workload needs concurrent access to the filesystem, you can now rely on CSI Driver for PowerStore, PowerScale and Unity through the NFS protocol. The three platforms are officially supported and qualified on Tanzu.
NFS behind NAT
NFS Driver, PowerStore, PowerScale, and Unity have all been tested and work when the Kubernetes cluster is behind a private network.
PowerScale
By default, the CSI driver creates volumes with 777 POSIX permission on the directory.
Now with the isiVolumePathPermissions parameter, you can use ACLs or any more permissive POSIX rights.
The isiVolumePathPermissions can be configured as part of the ConfigMap with the PowerScale settings or at the StorageClass level. The accepted parameter values are: private_read, private, public_read, public_read_write, and public for the ACL or any combination of [POSIX Mode].
Useful links
For more details you can:
- Watch CSM demos on our VP Youtube channel : https://www.youtube.com/user/itzikreich/
- Ask for help from the Dell container community website
- Read the FAQs
- Subscribe to Github notification and be informed of the latest releases on: https://github.com/dell/csm
- Chat with us on Slack
Author: Florian Coulombel

Looking Ahead: Dell Container Storage Modules 1.2
Thu, 26 Jan 2023 19:15:43 -0000
|Read Time: 0 minutes
The quarterly update for Dell CSI Drivers & Dell Container Storage Modules (CSM) is here! Here’s what we’re planning.
CSM Features
New CSM Operator!
Dell Container Storage Modules (CSM) add data services and features that are not in the scope of the CSI specification today. The new CSM Operator simplifies the deployment of CSMs. With an ever-growing ecosystem and added features, deploying a driver and its affiliated modules need to be carefully studied before beginning the deployment.
The new CSM Operator:
- Serves as a one-stop-shop for deploying all Dell CSI driver and Container Storage Modules
- Simplifies the install and upgrade operations
- Leverages the Operator framework to give a clear status of the deployment of the resources
- Is certified by Red Hat OpenShift
In the short/middle term, the CSM Operator will deprecate the experimental CSM Installer.
Replication support with PowerScale
For disaster recovery protection, PowerScale implements data replication between appliances by means of the the SyncIQ feature. SyncIQ replicates the data between two sites, where one is read-write while the other is read-only, similar to Dell storage backends with async or sync replication.
The role of the CSM replication module and underlying CSI driver is to provision the volume within Kubernetes clusters and prepare the export configurations, quotas, and so on.
CSM Replication for PowerScale has been designed and implemented in such a way that it won’t collide with your existing Superna Eyeglass DR utility.
A live-action demo will be posted in the coming weeks on our VP YouTube channel: https://www.youtube.com/user/itzikreich/.
CSI features
Across the portfolio
In this release, each CSI driver:
- Supports OpenShift 4.9
- Supports Kubernetes 1.23
- Supports the CSI Spec 1.5
- Updates the latest UBI-minimal image
- Supports fsGroupPolicy
fsGroupPolicy support
Kubernetes v1.19 introduced the fsGroupPolicy to give more control to the CSI driver over the permission sets in the securityContext.
There are three possible options:
- None -- which means that the fsGroup directive from the securityContext will be ignored
- File -- which means that the fsGroup directive will be applied on the volume. This is the default setting for NAS systems such as PowerScale or Unity-File.
- ReadWriteOnceWithFSType -- which means that the fsGroup directive will be applied on the volume if it has fsType defined and is ReadWriteOnce. This is the default setting for block systems such as PowerMax and PowerStore-Block.
In all cases, Dell CSI drivers let kubelet perform the change ownership operations and do not do it at the driver level.
Standalone Helm install
Drivers for PowerFlex and Unity can now be installed with the help of the install scripts we provide under the dell-csi-installer directory.
A standalone Helm chart helps to easily integrate the driver installation with the agent for Continuous Deployment like Flux or Argo CD.
Note: To ensure that you install the driver on a supported Kubernetes version, the Helm charts take advantage of the kubeVersion field. Some Kubernetes distributions use labels in kubectl version (such as v1.21.3-mirantis-1 and v1.20.7-eks-1-20-7) that require manual editing.
Volume Health Monitoring support
Drivers for PowerFlex and Unity implement Volume Health Monitoring.
This feature is currently in alpha in Kubernetes (in Q1-2022), and is disabled with a default installation.
Once enabled, the drivers will expose the standard storage metrics, such as capacity usage and inode usage through the Kubernetes /metrics endpoint. The metrics will flow natively in popular dashboards like the ones built-in OpenShift Monitoring:
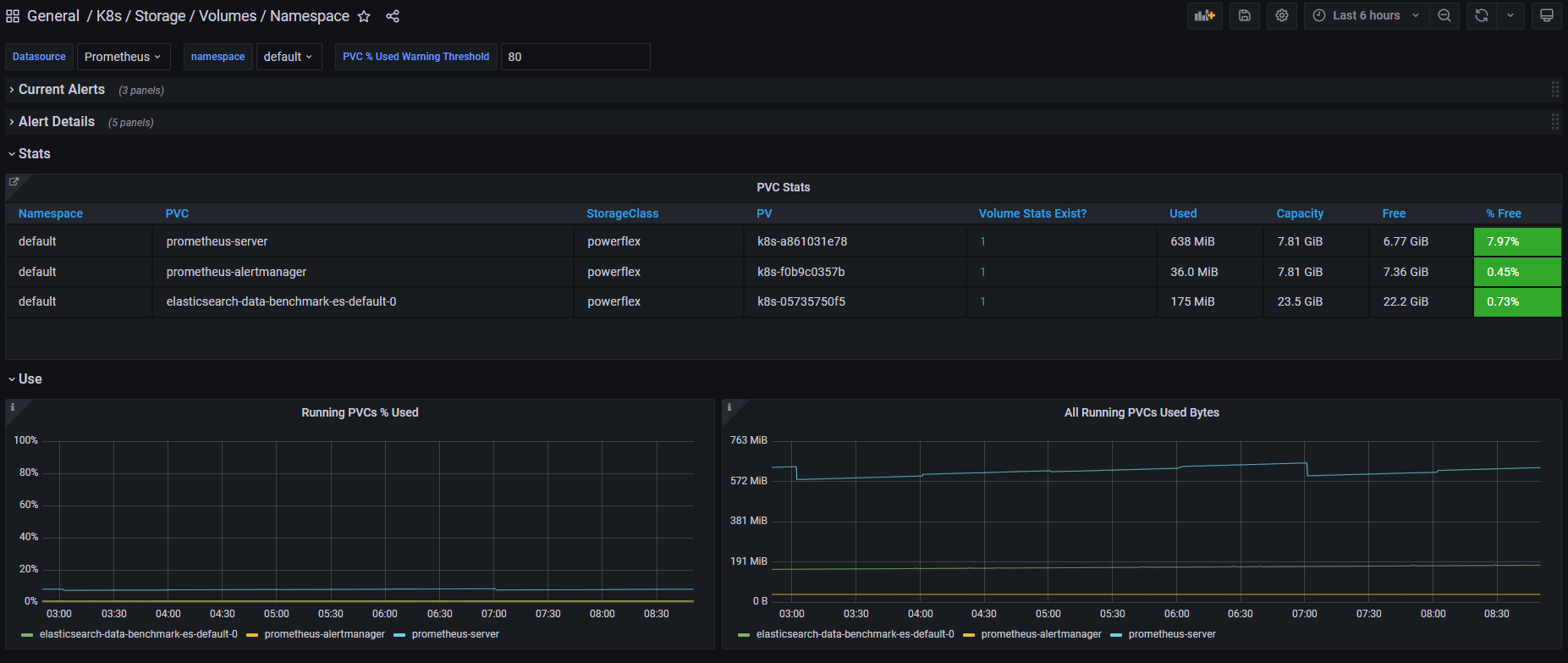
Pave the way for full open source!
All Dell drivers and dependencies like gopowerstore, gobrick, and more are now on Github and will be fully open-sourced. The umbrella project is and remains https://github.com/dell/csm, from which you can open tickets and see the roadmap.
Google Anthos 1.9
The Dell partnership with Google continues, and the latest CSI drivers for PowerScale and PowerStore support Anthos v1.9.
NFSv4 POSIX and ACL support
Both CSI PowerScale and PowerStore now allow setting the default permissions for the newly created volume. To do this, you can use POSIX octal notation or ACL.
- In PowerScale, you can use plain ACL or built-in values such as private_read, private, public_read, public_read_write, public or custom ones;
- In PowerStore, you can use the custom ones such as A::OWNER@:RWX, A::GROUP@:RWX, and A::OWNER@:rxtncy.
Useful links
For more details you can:
- Watch these great CSM demos on our VP YouTube channel: https://www.youtube.com/user/itzikreich/
- Read the FAQs
- Subscribe to Github notification and be informed of the latest releases on: https://github.com/dell/csm
- Ask for help or chat with us on Slack
Author: Florian Coulombel

How to Build a Custom Dell CSI Driver
Thu, 26 Jan 2023 19:11:59 -0000
|Read Time: 0 minutes
With all the Dell Container Storage Interface (CSI) drivers and dependencies being open-source, anyone can tweak them to fit a specific use case.
This blog shows how to create a patched version of a Dell CSI Driver for PowerScale.
The premise
As a practical example, the following steps show how to create a patched version of Dell CSI Driver for PowerScale that supports a longer mounted path.
The CSI Specification defines that a driver must accept a max path of 128 bytes minimal:
// SP SHOULD support the maximum path length allowed by the operating
// system/filesystem, but, at a minimum, SP MUST accept a max path
// length of at least 128 bytes.
Dell drivers use the gocsi library as a common boilerplate for CSI development. That library enforces the 128 bytes maximum path length.
The PowerScale hardware supports path lengths up to 1023 characters, as described in the File system guidelines chapter of the PowerScale spec. We’ll therefore build a csi-powerscale driver that supports that maximum length path value.
Steps to patch a driver
Dependencies
The Dell CSI drivers are all built with golang and, obviously, run as a container. As a result, the prerequisites are relatively simple. You need:
- Golang (v1.16 minimal at the time of the publication of that post)
- Podman or Docker
- And optionally make to run our Makefile
Clone, branch, and patch
The first thing to do is to clone the official csi-powerscale repository in your GOPATH source directory.
cd $GOPATH/src/github.com/
git clone git@github.com:dell/csi-powerscale.git dell/csi-powerscale
cd dell/csi-powerscaleYou can then pick the version of the driver you want to patch; git tag gives the list of versions.
In this example, we pick the v2.1.0 with git checkout v2.1.0 -b v2.1.0-longer-path.
The next step is to obtain the library we want to patch.
gocsi and every other open-source component maintained for Dell CSI are available on https://github.com/dell.
The following figure shows how to fork the repository on your private github:
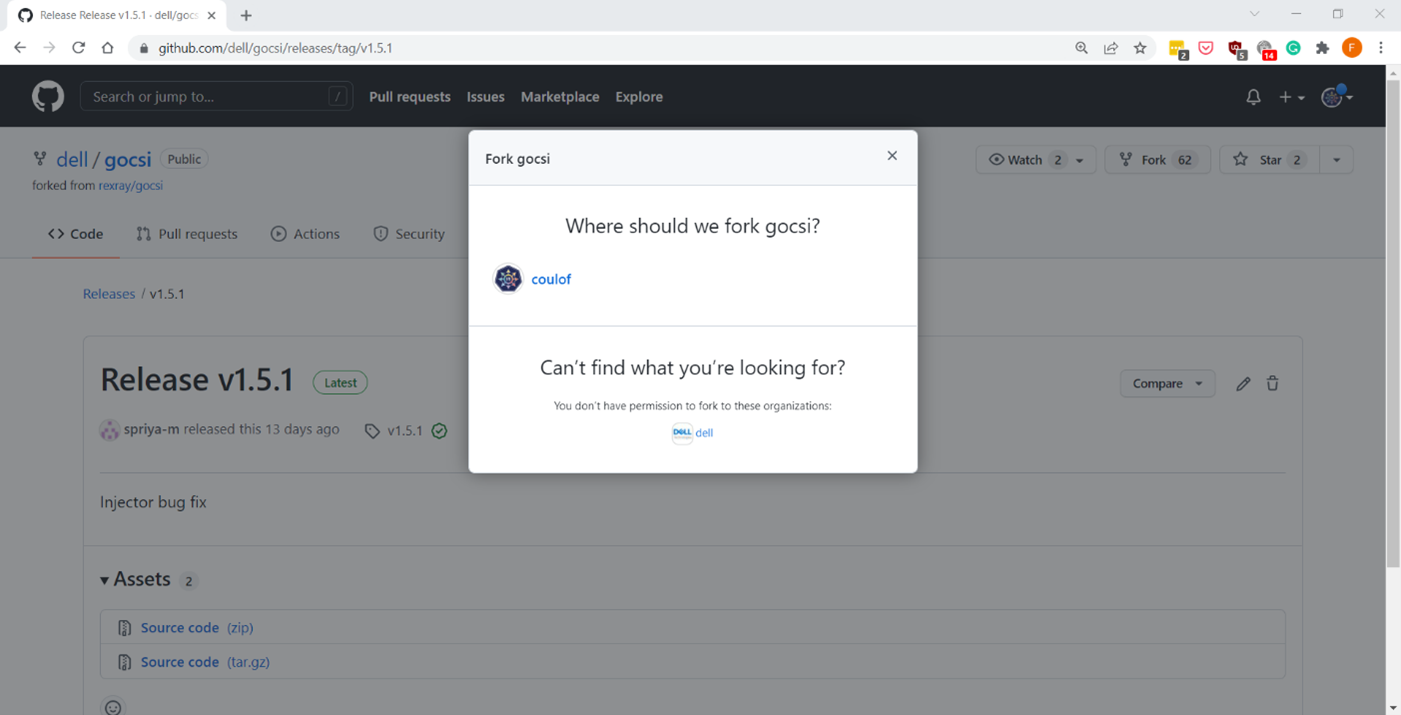
Now we can get the library with:
cd $GOPATH/src/github.com/
git clone git@github.com:coulof/gocsi.git coulof/gocsi
cd coulof/gocsiTo simplify the maintenance and merge of future commits, it is wise to add the original repo as an upstream branch with:
git remote add upstream git@github.com:dell/gocsi.gitThe next important step is to pick and choose the correct library version used by our version of the driver.
We can check the csi-powerscale dependency file with: grep gocsi $GOPATH/src/github.com/dell/csi-powerscale/go.mod and create a branch of that version. In this case, the version is v1.5.0, and we can branch it with: git checkout v1.5.0 -b v1.5.0-longer-path.
Now it’s time to hack our patch! Which is… just a oneliner:
--- a/middleware/specvalidator/spec_validator.go
+++ b/middleware/specvalidator/spec_validator.go
@@ -770,7 +770,7 @@ func validateVolumeCapabilitiesArg(
}
const (
- maxFieldString = 128
+ maxFieldString = 1023
maxFieldMap = 4096
maxFieldNodeId = 256
)We can then commit and push our patched library with a nice tag:
git commit -a -m 'increase path limit'
git push --set-upstream origin v1.5.0-longer-path
git tag -a v1.5.0-longer-path
git push --tagsBuild
With the patch committed and pushed, it’s time to build the CSI driver binary and its container image.
Let’s go back to the csi-powerscale main repo: cd $GOPATH/src/github.com/dell/csi-powerscale
As mentioned in the introduction, we can take advantage of the replace directive in the go.mod file to point to the patched lib. In this case we add the following:
diff --git a/go.mod b/go.mod
index 5c274b4..c4c8556 100644
--- a/go.mod
+++ b/go.mod
@@ -26,6 +26,7 @@ require (
)
replace (
+ github.com/dell/gocsi => github.com/coulof/gocsi v1.5.0-longer-path
k8s.io/api => k8s.io/api v0.20.2
k8s.io/apiextensions-apiserver => k8s.io/apiextensions-apiserver v0.20.2
k8s.io/apimachinery => k8s.io/apimachinery v0.20.2When that is done, we obtain the new module from the online repo with: go mod download
Note: If you want to test the changes locally only, we can use the replace directive to point to the local directory with:
replace github.com/dell/gocsi => ../../coulof/gocsiWe can then build our new driver binary locally with: make build
After compiling it successfully, we can create the image. The shortest path to do that is to replace the csi-isilon binary from the dellemc/csi-isilon docker image with:
cat << EOF > Dockerfile.patch
FROM dellemc/csi-isilon:v2.1.0
COPY "csi-isilon" .
EOF
docker build -t coulof/csi-isilon:v2.1.0-long-path -f Dockerfile.patch . Alternatively, you can rebuild an entire docker image using provided Makefile.
By default, the driver uses a Red Hat Universal Base Image minimal. That base image sometimes misses dependencies, so you can use another flavor, such as:
BASEIMAGE=registry.fedoraproject.org/fedora-minimal:latest REGISTRY=docker.io IMAGENAME=coulof/csi-powerscale IMAGETAG=v2.1.0-long-path make podman-buildThe image is ready to be pushed in whatever image registry you prefer. In this case, this is hub.docker.com: docker push coulof/csi-isilon:v2.1.0-long-path.
Update CSI Kubernetes deployment
The last step is to replace the driver image used in your Kubernetes with your custom one.
Again, multiple solutions are possible, and the one to choose depends on how you deployed the driver.
If you used the helm installer, you can add the following block at the top of the myvalues.yaml file:
images:
driver: docker.io/coulof/csi-powerscale:v2.1.0-long-pathThen update or uninstall/reinstall the driver as described in the documentation.
If you decided to use the Dell CSI Operator, you can simply point to the new image:
apiVersion: storage.dell.com/v1
kind: CSIIsilon
metadata:
name: isilon
spec:
driver:
common:
image: "docker.io/coulof/csi-powerscale:v2.1.0-long-path"
...Or, if you want to do a quick and dirty test, you can create a patch file (here named path_csi-isilon_controller_image.yaml) with the following content:
spec:
template:
spec:
containers:
- name: driver
image: docker.io/coulof/csi-powerscale:v2.1.0-long-pathYou can then apply it to your existing install with: kubectl patch deployment -n powerscale isilon-controller --patch-file path_csi-isilon_controller_image.yaml
In all cases, you can check that everything works by first making sure that the Pod is started:
kubectl get pods -n powerscale and that the logs are clean:
kubectl logs -n powerscale -l app=isilon-controller -c driver.Wrap-up and disclaimer
As demonstrated, thanks to the open source, it’s easy to fix and improve Dell CSI drivers or Dell Container Storage Modules.
Keep in mind that Dell officially supports (through tickets, Service Requests, and so on) the image and binary, but not the custom build.
Thanks for reading and stay tuned for future posts on Dell Storage and Kubernetes!
Author: Florian Coulombel

Network Design for PowerScale CSI
Thu, 26 Jan 2023 19:07:58 -0000
|Read Time: 0 minutes
Network connectivity is an essential part of any infrastructure architecture. When it comes to how Kubernetes connects to PowerScale, there are several options to configure the Container Storage Interface (CSI). In this post, we will cover the concepts and configuration you can implement.
The story starts with CSI plugin architecture.
CSI plugins
Like all other Dell storage CSI, PowerScale CSI follows the Kubernetes CSI standard by implementing functions in two components.
- CSI controller plugin
- CSI node plugin
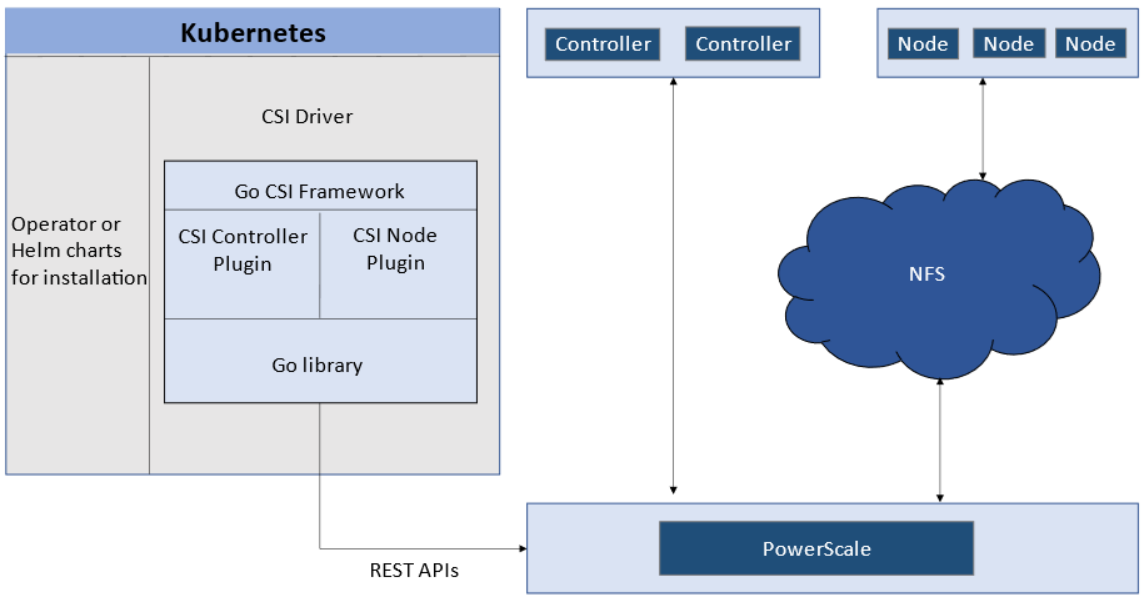
The CSI controller plugin is deployed as a Kubernetes Deployment, typically with two or three replicas for high-availability, with only one instance acting as a leader. The controller is responsible for communicating with PowerScale, using Platform API to manage volumes (to PowerScale it’s to create/delete directories, NFS exports, and quotas), to update the NFS client list when a Pod moves, and so on.
A CSI node plugin is a Kubernetes DaemonSet, running on all nodes by default. It’s responsible for mounting the NFS export from PowerScale, to map the NFS mount path to a Pod as persistent storage, so that applications and users in the Pod can access the data on PowerScale.
Roles, privileges, and access zone
Because CSI needs to access both PAPI (PowerScale Platform API) and NFS data, a single user role typically isn’t secure enough: the role for PAPI access will need more privileges than normal users.
According to the PowerScale CSI manual, CSI requires a user that has the following privileges to perform all CSI functions:
Privilege | Type |
ISI_PRIV_LOGIN_PAPI | Read Only |
ISI_PRIV_NFS | Read Write |
ISI_PRIV_QUOTA | Read Write |
ISI_PRIV_SNAPSHOT | Read Write |
ISI_PRIV_IFS_RESTORE | Read Only |
ISI_PRIV_NS_IFS_ACCESS | Read Only |
ISI_PRIV_IFS_BACKUP | Read Only |
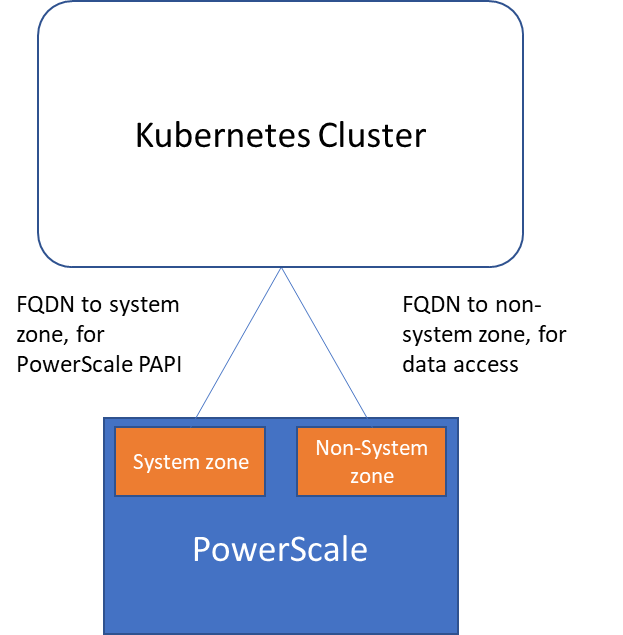
Among these privileges, ISI_PRIV_SNAPSHOT and ISI_PRIV_QUOTA are only available in the System zone. And this complicates things a bit. To fully utilize these CSI features, such as volume snapshot, volume clone, and volume capacity management, you have to allow the CSI to be able to access the PowerScale System zone. If you enable the CSM for replication, the user needs the ISI_PRIV_SYNCIQ privilege, which is a System-zone privilege too.
By contrast, there isn’t any specific role requirement for applications/users in Kubernetes to access data: the data is shared by the normal NFS protocol. As long as they have the right ACL to access the files, they are good. For this data accessing requirement, a non-system zone is suitable and recommended.
These two access zones are defined in different places in CSI configuration files:
- The PAPI access zone name (FQDN) needs to be set in the secret yaml file as “endpoint”, for example “f200.isilon.com”.
- The data access zone name (FQDN) needs to be set in the storageclass yaml file as “AzServiceIP”, for example “openshift-data.isilon.com”.
If an admin really cannot expose their System zone to the Kubernetes cluster, they have to disable the snapshot and quota features in the CSI installation configuration file (values.yaml). In this way, the PAPI access zone can be a non-System access zone.
The following diagram shows how the Kubernetes cluster connects to PowerScale access zones.
Network
Normally a Kubernetes cluster comes with many networks: a pod inter-communication network, a cluster service network, and so on. Luckily, the PowerScale network doesn’t have to join any of them. The CSI pods can access a host’s network directly, without going through the Kubernetes internal network. This also has the advantage of providing a dedicated high-performance network for data transfer.
For example, on a Kubernetes host, there are two NICs: IP 192.168.1.x and 172.24.1.x. NIC 192.168.1.x is used for Kubernetes, and is aligned with its hostname. NIC 172.24.1.x isn’t managed by Kubernetes. In this case, we can use NIC 172.24.1.x for data transfer between Kubernetes hosts and PowerScale.
Because by default, the CSI driver will use the IP that is aligned with its hostname, to let CSI recognize the second NIC 172.24.1.x, we have explicitly set the IP range in “allowedNetworks” in the values.yaml file in the CSI driver installation. For example:
allowedNetworks: [172.24.1.0/24]
Also, in this network configuration, it’s unlikely that the Kubernetes internal DNS can resolve the PowerScale FQDN. So, we also have to make sure the “dnsPolicy” has been set to “ClusterFirstWithHostNet” in the values.yaml file. With this dnsPolicy, the CSI pods will reach the DNS server in /etc/resolv.conf in the host OS, not the internal DNS server of Kubernetes.
The following diagram shows the configuration mentioned above:
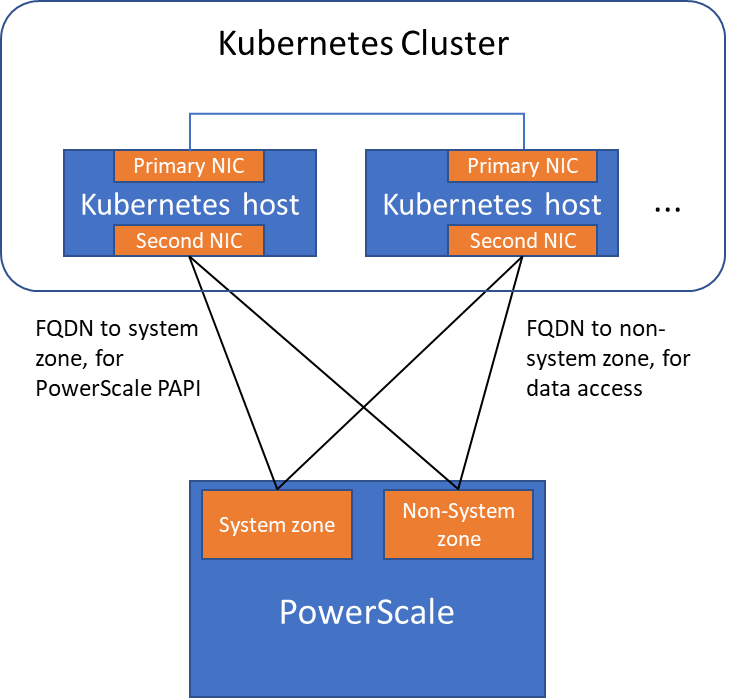
Please note that the “allowedNetworks” setting only affects the data access zone, and not the PAPI access zone. In fact, CSI just uses this parameter to decide which host IP should be set as the NFS client IP on the PowerScale side.
Regarding the network routing, CSI simply follows the OS route configuration. Because of that, if we want the PAPI access zone to go through the primary NIC (192.168.1.x), and have the data access zone to go through the second NIC (172.24.1.x), we have to change the route configuration of the Kubernetes host, not this parameter.
Hopefully this blog helps you understand the network configuration for PowerScale CSI better. Stay tuned for more information on Dell Containers & Storage!
Authors: Sean Zhan, Florian Coulombel

Dell Container Storage Modules—A GitOps-Ready Platform!
Thu, 26 Jan 2023 19:04:30 -0000
|Read Time: 0 minutes
One of the first things I do after deploying a Kubernetes cluster is to install a CSI driver to provide persistent storage to my workloads; coupled with a GitOps workflow; it takes only seconds to be able to run stateful workloads.
The GitOps process is nothing more than a few principles:
- Git as a single source of truth
- Resource explicitly declarative
- Pull based
Nonetheless, to ensure that the process runs smoothly, you must make certain that the application you will manage with GitOps complies with these principles.
This article describes how to use the Microsoft Azure Arc GitOps solution to deploy the Dell CSI driver for Dell PowerMax and affiliated Container Storage Modules (CSMs).
The platform we will use to implement the GitOps workflow is Azure Arc with GitHub. Still, other solutions are possible using Kubernetes agents such as Argo CD, Flux CD, and GitLab.
Azure GitOps itself is built on top of Flux CD.
Install Azure Arc
The first step is to onboard your existing Kubernetes cluster within the Azure portal.
Obviously, the Azure agent will connect to the Internet. In my case, the installation of the Arc agent fails from the Dell network with the error described here: https://docs.microsoft.com/en-us/answers/questions/734383/connect-openshift-cluster-to-azure-arc-secret-34ku.html
Certain URLs (even when bypassing the corporate proxy) don't play well when communicating with Azure. I have seen some services get a self-signed certificate, causing the issue.
The solution for me was to put an intermediate transparent proxy between the Kubernetes cluster and the corporate cluster. That way, we can have better control over the responses given by the proxy.

In this example, we install Squid on a dedicated box with the help of Docker. To make it work, I used the Squid image by Ubuntu and made sure that Kubernetes requests were direct with the help of always_direct:
docker run -d --name squid-container ubuntu/squid:5.2-22.04_beta ; docker cp squid-container:/etc/squid/squid.conf ./ ; egrep -v '^#' squid.conf > my_squid.conf docker rm -f squid-container
Then add the following section:
acl k8s port 6443 # k8s https always_direct allow k8s
You can now install the agent per the following instructions: https://docs.microsoft.com/en-us/azure/azure-arc/kubernetes/quickstart-connect-cluster?tabs=azure-cli#connect-using-an-outbound-proxy-server.
export HTTP_PROXY=http://mysquid-proxy.dell.com:3128 export HTTPS_PROXY=http://mysquid-proxy.dell.com:3128 export NO_PROXY=https://kubernetes.local:6443 az connectedk8s connect --name AzureArcCorkDevCluster \ --resource-group AzureArcTestFlorian \ --proxy-https http://mysquid-proxy.dell.com:3128 \ --proxy-http http://mysquid-proxy.dell.com:3128 \ --proxy-skip-range 10.0.0.0/8,kubernetes.default.svc,.svc.cluster.local,.svc \ --proxy-cert /etc/ssl/certs/ca-bundle.crt
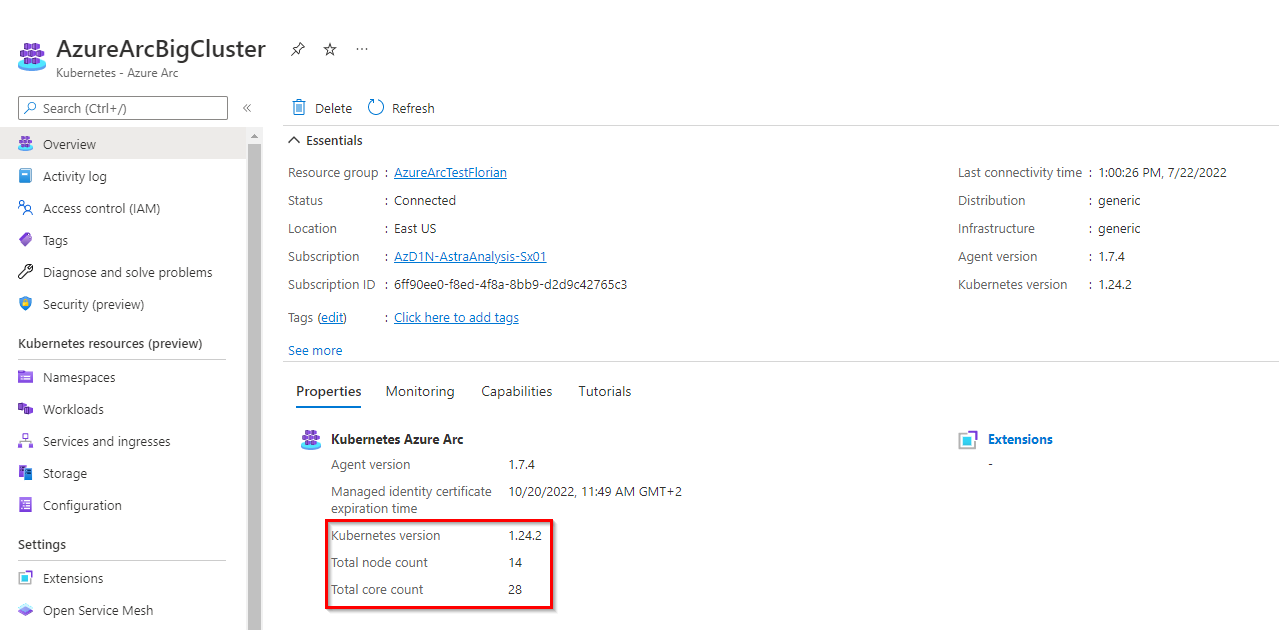
If everything worked well, you should see the cluster with detailed info from the Azure portal:
Add a service account for more visibility in Azure portal
To benefit from all the features that Azure Arc offers, give the agent the privileges to access the cluster.
The first step is to create a service account:
kubectl create serviceaccount azure-user kubectl create clusterrolebinding demo-user-binding --clusterrole cluster-admin --serviceaccount default:azure-user kubectl apply -f - <<EOF apiVersion: v1 kind: Secret metadata: name: azure-user-secret annotations: kubernetes.io/service-account.name: azure-user type: kubernetes.io/service-account-token EOF
Then, from the Azure UI, when you are prompted to give a token, you can obtain it as follows:
kubectl get secret azure-user-secret -o jsonpath='{$.data.token}' | base64 -d | sed $'s/$/\\\n/g'Then paste the token in the Azure UI.
Install the GitOps agent
The GitOps agent installation can be done with a CLI or in the Azure portal.
As of now, the Microsoft documentation presents in detail the deployment that uses the CLI; so let's see how it works with the Azure portal:
Organize the repository
The Git repository organization is a crucial part of the GitOps architecture. It hugely depends on how internal teams are organized, the level of information you want to expose and share, the location of the different clusters, and so on.
In our case, the requirement is to connect multiple Kubernetes clusters owned by different teams to a couple of PowerMax systems using only the latest and greatest CSI driver and affiliated CSM for PowerMax.
Therefore, the monorepo approach is suited.
The organization follows this structure:
.
├── apps
│ ├── base
│ └── overlays
│ ├── cork-development
│ │ ├── dev-ns
│ │ └── prod-ns
│ └── cork-production
│ └── prod-ns
├── clusters
│ ├── cork-development
│ └── cork-production
└── infrastructure
├── cert-manager
├── csm-replication
├── external-snapshotter
└── powermax
- apps: Contains the applications to be deployed on the clusters.
- We have different overlays per cluster.
- cluster: Usually contains the cluster-specific Flux CD main configuration; using Azure Arc, none is needed.
- Infrastructure: Contains the deployments that are used to run the infrastructure services; they are common to every cluster.
- cert-manager: Is a dependency of powermax reverse-proxy
- csm-replication: Is a dependency of powermax to support SRDF replication
- external-snapshotter: Is a dependency of powermax to snapshot
- powermax: Contains the driver installation
You can see all files in https://github.com/coulof/fluxcd-csm-powermax.
Note: The GitOps agent comes with multi-tenancy support; therefore, we cannot cross-reference objects between namespaces. The Kustomization and HelmRelease must be created in the same namespace as the agent (here, flux-system) and have a corresponding targetNamespace to the resource to be installed.
Conclusion
This article is the first of a series exploring the GitOps workflow. Next, we will see how to manage application and persistent storage with the GitOps workflow, how to upgrade the modules, and so on.