




PowerEdge Servers and Deep Learning Domains: The Impact of Scaling Accelerators
Download PDFMon, 16 Jan 2023 13:44:28 -0000
|Read Time: 0 minutes
Summary
With deep learning principles becoming a widely accepted practice, customers are keen to understand how to select the most optimized server, based on GPU count, to accommodate varying machine and deep learning workloads. This tech note delivers test results that portray how scaling NVIDIA GPU’s on PowerEdge server configurations will impact performance for various deep learning domains, and how these results outline general guidelines for constructing an optimized deep learning platform.
Evaluating Performance Using MLPerf Benchmark
To accurately harvest Artificial Intelligence (AI) performance data it is critical to select a benchmark that is qualified to accurately test multiple domain types. MLPerf is a new and broad Machine Learning (ML) and Deep Learning (DL) benchmark suite that is gaining popularity and adoption for its multi-domain capabilities and representative models. The current version (v0.5) covers five domains associated with AI subsets, as seen in Figure 1: image classification, object detection, language translation, reinforcement learning and recommendation.
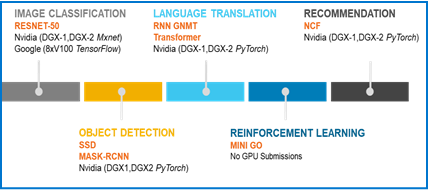
Figure 1: Domains covered within the MLPerf v0.5 benchmark
For each given domain, MLPerf will measure performance by assessing and comparing total training times; the amount of time that it takes to train a neural net model for a given domain to reach target accuracy. Dell EMC team benchmarked various PowerEdge servers that have GPU compatibility to help customers pick the appropriate GPU infrastructure that will achieve their requirements. We used multi-GPU training to highlight the shortest amount of training time needed to reach target accuracy the fastest for the MLPerf.
Server | # of CPU's | # of GPU's | GPU Type | GPU Interconnect |
DSS 8440 | 2 | 8 | V100 (16GB) | PCIe |
PE T640 | 2 | 4 | V100 (32GB) | PCIe |
PE R740 | 2 | 3 | V100 (16GB) | PCIe |
Precision 5820 | 1 | 2 | GV100 (32GB) | PCIe |
Every benchmark ran on single node PowerEdge servers, as seen in Figure 2. Each server was loaded with either 2, 3, 4 or 8 Tesla V100 PCIe GPU’s, and these configurations ran until the unique domain being tested reached the target accuracy. By comparing these configurations, we can deduce the performance increase per domain when additional GPU’s are included.
MLPerf scores were calculated by exhibiting the total training times of each configuration relative to the reference accelerator, one NVIDIA Pascal P100. Each score indicates that the Tesla GV/V100 server is that many times faster than the Pascal P100. This methodology ensure consistency amongst each platform so that each scaled score remains accurate.
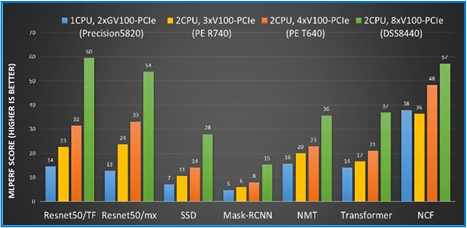
Figure 3: MLPerf benchmark scores calculated against the reference accelerator (one NVIDIA Pascal P100)
The first notable observation is the variance in training times for each domain. Recommendation, Reinforcement Learning and Language Translation DL consistently require the most training time for completion, while Object Detection and Image Classification appear to take half as long. This illustrates the varying learning difficulties associated with each DL domain. Furthermore, we learn from observing Figure 3 that Image Recognition (Resnet50) and Object Detection (Mask-RCNN) domains scale linearly; we can assume that when the GPU count increases than the speedup times decrease at a linear rate. Translation (NMT) and Recommendation (NCF) domains, on the other hand, were not as predictable. The bar graphs for Translation scores almost seems to scale quadratically and the Recommendation scores appear to not scale beyond 2 GPU’s (it is an artifact of the dataset being too small which is being fixed in a later version of MLPerf).
Recommendations
The training times and scaling behavior vary between different domains and models
- Using superior accelerators would be advantageous for the domains that require the most time
- In order to pick the appropriate server and number of GPU’s, it is useful to understand the models and domains being used.
Increasing GPU’s scales performance at a near linear rate for Image Recognition and Object Detection domains
- Servers with higher GPU counts will linearly reduce training time for these domains. Scaling to 4 GPUs using NVLink appears to be the sweet spot from an efficiency stand point.
Increasing GPU’s does not scale performance at a linear rate for Translation and Recommendation domains
- Servers with higher GPU counts will not linearly reduce training times for these domains due to data set or computation/communication ratios. However, using larger GPU counts is still useful to meet time to solution as the training time is reduced across these models.
Conclusion
Optimizing a platform for ML/DL workloads goes far beyond scaling the accelerators; every variable must be considered and there are a plethora of them. Fortunately, Dell EMC is committed to designing PowerEdge servers with GPU counts that cater to specific ML/DL domains, thereby reducing these variables for a smooth and simple customer experience. This tech note provided insight on how the accelerator model, accelerator count, and domain type are influenced by unique PowerEdge server models, and more importantly how customers can make the best decisions to perform their required ML/DL workloads at full throttle.
Related Documents

Understanding the Value of AMDs Socket to Socket Infinity Fabric
Tue, 17 Jan 2023 00:43:22 -0000
|Read Time: 0 minutes
Summary
AMD socket-to-socket Infinity Fabric increases CPU-to-CPU transactional speeds by allowing multiple sockets to communicate directly to one another through these dedicated lanes. This DfD will explain what the socket-to-socket Infinity Fabric interconnect is, how it functions and provides value, as well as how users can gain additional value by dedicating one of the x16 lanes to be used as a PCIe bus for NVMe or GPU use.
Introduction
Prior to socket-to-socket Infinity Fabric (IF) interconnect, CPU-to-CPU communications generally took place on the HyperTransport (HT) bus for AMD platforms. Using this pathway for multi-socket servers worked well during the lifespan of HT, but developing technologies pushed for the development of a solution that would increase data transfer speeds, as well as allow for combo links.
AMD released socket-to-socket Infinity Fabric (also known as xGMI) to resolve these bottlenecks. Having dedicated IF links for direct CPU-to- CPU communications allowed for greater data-transfer speeds, so multi-socket server users could do more work in the same amount of time as before.
How Socket-to-Socket Infinity Fabric Works
IF is the external socket-to-socket interface for 2-socket servers. The architecture used for IF links is a combo of serializer/deserializer (SERDES) that can be both PCIe and xGMI, allowing for sixteen lanes per link and a lot of platform flexibility. xGMI2 is the current generation available and it has speeds that reach up to 18Gbps; which is faster than the PCIe Gen4 speed of 16Gbps. Two CPUs can be supported by these IF links. Each IF lane connects from one CPU IO die to the next, and they are interwoven in a similar fashion, directly connecting the CPUs to one- another. Most dual-socket servers have three to four IF links dedicated for CPU connections. Figure 1 depicts a high- level illustration of how socket to socket IF links connect across CPUs.
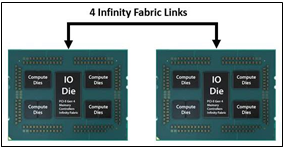
Figure 1 – 4 socket to socket IF links connect two CPUs
The Value of Infinity Fabric Interconnect
Socket to socket IF interconnect creates several advantages for PowerEdge customers:
- Dedicated IF lanes are routed directly from one CPU to the other CPU, ensuring inter-socket communications travel the shortest distance possible
- xGMI2 speeds (18Gbps) exceed the speeds of PCIe Gen4, allowing for extremely fast inter-socket data transfer speeds
Furthermore, if customers require additional PCIe lanes for peripheral components, such as NVMe or GPU drives, one of the four IF links are a cable with a connector that can be repurposed as a PCIe lane. AMD’s highly optimized and flexible link topologies enable sixteen lanes per socket of Infinity Fabric to be repurposed. This means that 2S AMD servers, such as the PowerEdge R7525, have thirty-two additional lanes giving a total of 160 PCIe lanes for peripherals. Figure 2 below illustrates what this would look like:
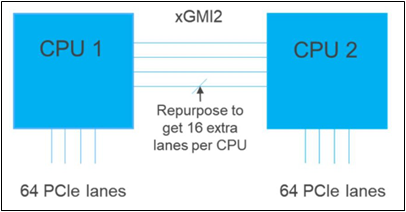
Figure 2 – Diagram showing additional PCIe lanes available in a 2S configuration
Conclusion
AMDs socket-to-socket Infinity Fabric interconnect replaced the former HyperTransport interconnect in order to allow massive amounts of data to travel fast enough to avoid speed bottlenecks. Furthermore, customers needing additional PCIe lanes can repurpose one of the four IF links for peripheral support. These advantages allow AMD PowerEdge servers, such as the R7525, to meet our server customer needs.

The Future of Server Cooling- Part 1. The History of Server and Data Center Cooling Technologies
Mon, 16 Jan 2023 18:15:45 -0000
|Read Time: 0 minutes
Summary
Today’s servers require more power than ever before. While this spike in power has led to more capable servers, it has coincidentally pushed legacy thermal hardware to its limit. The inability to support top- performance servers without liquid cooling will soon become an industry-wide challenge. We hope that by preparing our PowerEdge customers for this transition ahead of time, and explaining in detail why and when liquid cooling is necessary, they can easily adapt and get excited for the performance gains liquid cooling will enable.
Part 1 of this three part series, titled The Future of Server Cooling, covers the history of server and data center thermal technologies - which cooling methods are most commonly used, and how they evolved to enable the industry growth seen today.
The Future of Server Cooling was written because the next-generation of PowerEdge servers (and succeeding generations) may require liquid cooling assistance to enable certain (dense) configurations. Our intent is to educate customers about why the transition to liquid cooling is inevitable, and to prepare them for these changes.
Integrating liquid cooling solutions on future PowerEdge servers will allow for significant performance gains from new technologies, such as next-generation Intel® Xeon® and AMD EPYC™ CPUs, DDR5 memory, PCIe Gen5, DPUs, and more.
Part 1 of this three part series reviews some major historical cooling milestones to help explain why change has always been necessary. It also describes which technologies have evolved over time to advance to where they are today - the historical evolution of thermal technologies for both the server and the data center.
Data centers cannot exist without sufficient cooling
A data center comprises many individual pieces of technology equipment that work together collectively to support continuously running servers within a functional facility. Most of this equipment requires power to operate, which converts electrical energy into heat energy as it is used. If the heat generated grows too large, it can create undesirable thermal conditions, which can cause component and server shutdown, or even failure, if not managed properly.
Cooling technologies are implemented to manage heat build-up by moving heat away from the source (because heat cannot magically be erased) and towards a location where it is safely dispersed. This allows technology equipment within the data center to continue to work reliably and uninterrupted from the threat of shutdown from overheating. Servers from Dell Technologies can automatically adjust power consumption, but without an effective cooling solution the heat buildup within the data center would eventually exceed the capability of the server to operate, creating enormous financial losses for business.
Two areas of coverage
Cooling technologies are typically designated to two areas of coverage - directly inside of the server and at the data center floor. Most modern data centers strategically use cooling for both areas of coverage in unison.
- Cooling technologies located directly inside of the server focus on moving heat away from dense electronics that generate the bulk of it, including components such as CPUs, GPUs, memory, and more.
- Cooling technologies located at the data center floor focus on keeping the ambient room temperature cool. This ensures that the air being circulated around and within the servers is colder than the hot air they are generating, effectively cooling the racks and servers through convection.
Legacy Server Cooling Techniques
Four approaches have built upon each other over time to cool the inside of a server: conduction, convection, layout, and automation, in chronological order. Despite the advancements made to these approaches over time, the increasing thermal design power (TDP) requirements have made it commonplace to see them all working together in unison.
Conduction was the first step in server cooling evolution that allowed the earliest servers to run without overheating. Conduction directly transfers heat through surface contact. Historically, conduction cooling technologies, such as heat spreaders and heat sinks, have moved heat away from server hot spots and stored it in isolated regions where it can either reside permanently, or be transferred outside of the box through an air or liquid medium. Because heat spreaders have limited capabilities, they were rapidly replaced by heat sinks, which are the industry standard today. The most effective heat sinks are mounted directly to heat producing components with a flush base plate. As development advanced, fins of varying designs (each having unique value) were soldered to the base plate to maximize the surface area available. The base plate manufacturing process has shifted from extrusion to machine or die-cast, which reduces production time and wasted material. Material changed from solely aluminum to include copper for use cases that require its ~40% higher thermal conductivity. The following figure provides an example:

Figure 1. Heat sink base plate uses copper to support higher power
Convection cooling technologies were introduced to server architecture when conduction cooling methods could no longer solely support growing power loads. Convection transfers heat outside of the server through a medium, such as air or liquid. Convection is more efficient than conduction. When the two are used together, they form an effective system - conduction stores heat in a remote location and then convection pushes that heat out of the server.
Technologies such as fans and heat pipes are commonly used in this process. The evolution of fan technology has been extraordinary. Through significant research and development, fan manufacturers have optimized the fan depth, blade radius, blade design, and material, to present dozens of offerings for unique use cases. Factors such as the required airflow (CFM) and power/acoustic/space/cost constraints then point designers to the most appropriate fan. Variable speed fans were also introduced to control fan speeds based on internal temperatures, thereby reducing power usage. Heat pipes have also undergone various design changes to optimize efficiency. The most popular type has a copper enclosure, sintered copper wick, and cooling fluid. Today they are often embedded in the CPU heatsink base, making direct contact with the CPU, and routing that collected heat to the top of the fins in a remote heatsink.
Layout refers to the placement and positioning of the components within the server. As component power requirements increased at a faster rate than conduction and convection technologies were advancing, mechanical architects were pressed to innovate new system layout designs that would maximize the efficiency of existing cooling technologies. Some key tenets about layout design optimization have evolved over time:
- Removing obstructions in the airflow pathway
- Forming airflow channels to target heat generating components
- Balancing airflow within the server by arranging the system layout in a symmetrical fashion
Automation is a newer software approach used to enable a finer control over the server infrastructure. An autonomous infrastructure ensures that both the server components and cooling technologies are working only as hard as needed, based on workload requirements. This lowers power usage, which reduces heat output, and ultimately optimizes the intensity of surrounding cooling technologies. As previously mentioned, variable fan speeds were a cornerstone for this movement, and have been followed by some interesting innovations. Adaptive closed loop controllers have evolved to control fan speed based on thermal sensor inputs and power management inputs. Power capping capabilities ensure thermal compliance with minimum performance impact in challenging thermal conditions. For Dell PowerEdge servers, iDRAC enables users to remotely monitor and tackle thermal challenges with built-in features such as system airflow consumption, custom delta-T, custom PCIe inlet temperature, exhaust temperature control, and adjustment of PCIe airflow settings. The following figure illustrates the flow of these iDRAC automations:
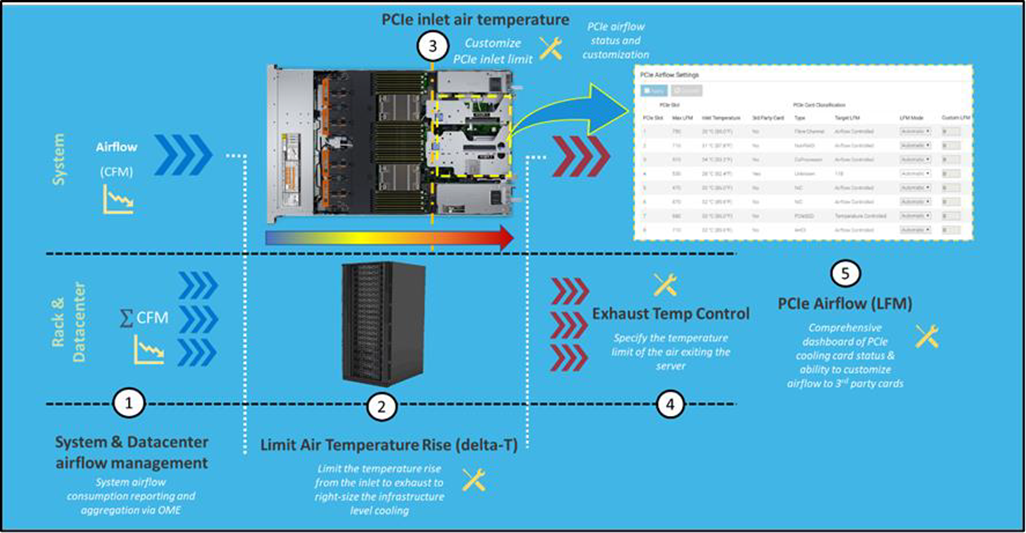
Figure 2. Thermal automations enabled by Dell proprietary iDRAC systems management
Legacy data center cooling techniques
Heat transfer through convection is rendered useless if the intake air being moved by fans is not colder than the heated air within the server. For this reason, cooling the data center room is as important as cooling the server: the two methods depend on one another. Three main approaches to data center cooling have evolved over time – raised floors, hot and cold aisles, and containment, in chronological order. Raised floors were the first approach to cooling the data center. At the very beginning, chillers, and computer room air conditioning (CRAC) units were used to push large volumes of cooled air into the datacenter, and that was enough.
However, the air distribution was wildly unorganized and chaotic, having no dedicated paths for hot or cold airflow, causing many inefficiencies such as recirculation and air stratification. Because adjustments were required to accommodate increasing power demands, the data center floor plan was redesigned to have raised floor systems with perforated tiles replacing solid tiles. This provided a secure path for the cold air created by CRAC units to stay chilled as it traveled beneath the floor until being pulled up the rack by server fans.
Hot and cold aisle rack arrangements were then implemented to assist the raised floor system when the demands of increasing heat density and efficiency could not be met. This configuration has cool air intakes and warm air exhausts facing each other at each end of a server row. Convection currents are then generated, which helped to improve airflow. However, this configuration was still unable to meet the demands of growing data center requirements, as airflow above the raised floors remained chaotic. Something else was needed to maximize efficiency.
Containment cooling ideas propagated to resolve the turbulent nature of cool and hot air mixing above raised floors. By using a physical barrier to separate cool server intake air from heated server exhaust air, operators were finally able to maintain tighter control over the airstreams. Several variants of containment exist, such as cold aisle containment and hot aisle containment, but the premise remains the same – to block cold air from mixing with hot air. Containment cooling successfully increased data center cooling efficiency, lowered energy consumption, and even created more flexibility within the data center layout (as opposed to hot and cold aisle rack arrangements, which require the racks to be aligned in a certain position). Containment cooling is commonly used today in conjunction with raised floor systems. The following figure illustrates what a hot aisle containment configuration might look like:

Figure 3. Hot aisle containment enclosure diagram, sourced from Uptime Institute
What’s Next?
Clearly the historical evolution of these thermal techniques has aided the progression of server and data center technology, enabling opportunities for innovation and business growth. Our next-generation of PowerEdge servers will see technological capabilities jump at an unprecedented magnitude, and Dell will be prepared to get our customers there with the help of our new and existing liquid cooling technologies. Part 2 of this three part series will discuss why power requirements will be rising so aggressively in our next generation PowerEdge servers, what benefits this will yield, and which liquid cooling solutions Dell will provide to keep our customers’ infrastructure cool and safe.