




The Case for Elastic Stack on HCI
Tue, 08 Dec 2020 17:45:45 -0000
|Read Time: 0 minutes
The Elastic Stack, also known as the “ELK Stack”, is a widely used, collection of software products based on open source used for search, analysis, and visualization of data. The Elastic Stack is useful for a wide range of applications including observability (logging, metrics, APM), security, and general-purpose enterprise search. Dell Technologies is an Elastic Technology Partner1 This blog covers some basics of hyper-converged infrastructure (HCI), some Elastic Stack fundamentals, and the benefits of deploying Elastic Stack on HCI.
HCI Overview
HCI integrates the compute and storage resources from a cluster of servers using virtualization software for both CPU and disk resources to deliver flexible, scalable performance and capacity on demand. The breadth of server offerings in the Dell PowerEdge portfolio gives system architects many options for designing the right blend of compute and storage resources. Local resources from each server in the cluster are combined to create virtual pools of compute and storage with multiple performance tiers.
VxFlex is a Dell Technologies developed, hypervisor agnostic, HCI platform integrated with high-performance, software-defined block storage. VxFlex OS is the software that creates a server and IP-based SAN from direct-attached storage as an alternative to a traditional SAN infrastructure. Dell Technologies also offers the VxRail HCI platform for VMware-centric environments. VxRail is the only fully integrated, pre-configured, and pre-tested VMware HCI system powered with VMware vSAN. We show below why both HCI offerings are highly efficient and effective platforms for a truly scalable Elastic Stack deployment.
Elastic Stack Overview
The Elastic Stack is a collection of four open-source projects: Elasticsearch, Logstash, Kibana, and Beats. Elasticsearch is an open-source, distributed, scalable, enterprise-grade search engine based on Lucene. Elasticsearch is an end-to-end solution for searching, analyzing, and visualizing machine data from diverse source formats. With the Elastic Stack, organizations can collect data from across the enterprise, normalize the format, and enrich the data as desired. Platforms designed for scale-out performance running the Elastic Stack provides the ability to analyze and correlate data in near real-time.
Elastic Stack on HCI
In March 2020, Dell Technologies validated the Elastic Stack running on our VxFlex family of HCI2. It will be shown how the features of HCI provide distinct benefits and cost savings as an integrated solution for the Elastic Stack. The Elastic Stack, and Elasticsearch specifically, is designed for scale-out. Data nodes can be added to an Elasticsearch cluster to provide additional compute and storage resources. HCI also uses a scale-out deployment model that allows for easy, seamless scalability horizontally by adding additional nodes to the cluster(s). However, unlike bare-metal deployments, HCI also scales vertically by adding resources dynamically to Elasticsearch data nodes or any other Elastic Stack roles through virtualization. VxFlex admins use their preferred hypervisor and VxFLEX OS and for VxRail it is done with VMware ESX and vSAN. Additionally, the Elastic Stack can be deployed on Kubernetes clusters, therefor admins can also choose to leverage VMware Tanzu for Kubernetes management.
Virtualization has long been a strategy for achieving more efficient resource utilization and data center density. Elasticsearch data nodes tend to have average allocations of 8-16 cores and 64GB of RAM. With the current ability to support up to 112 cores and 6TB of RAM in a single 2RU Dell server, Elasticsearch is an attractive application for virtualization. Additionally, the Elastic Stack is also significantly more CPU efficient than some alternative products improving the cost-effectiveness of deploying Elastic with VMware or other virtualization technologies. We would recommend sizing for 1 physical CPU to 1 virtual CPU (vCPU) for Elasticsearch Hot Tier along with the management and control plane resources. While this is admittedly like the VMware guidance for some similar analytics platforms, these VMs tend to consume a significantly smaller CPU footprint per data node. The Elastic Stack tends to take advantage of hyperthreading and resource overcommitment more effectively. While needs will vary by customer use case, our experience shows the efficiencies in the Elastic Stack and Elastic data lifecycle management allow the Elasticsearch Warm Tier, Kibana, and Proxy servers can be supported by 1 physical CPU to 2 vCPUs and the Cold Tier can be upwards of 4 vCPUs to a physical CPU.
Because Elasticsearch tiers data on independent data nodes versus multiple mount points on a single data node or indexer, the multiple types and classes of software-defined storage defined for independent HCI clusters can be easily leveraged between Elasticsearch clusters to address data temperatures. It should be noted that currently Elastic does not currently recommend any non-block storage (S3, NFS, etc.) as a target for Elasticsearch except as a target for Elasticsearch Snapshot and Restore. (It is possible to use S3 or NFS on Isilon or ECS as an example as a retrieval target for Logstash, but that is a subject for a later blog.) For example, vSAN in VxRail provides Optane, NVMe, SSD, and HDD storage options. A user can deploy their primary Elastic Stack environment with its Hot Elasticsearch data nodes, Kibana, and the Elastic Stack management and control plane on an all-flash VxRail cluster, and then leverage a storage dense hybrid vSAN cluster for Elasticsearch cold data.
Image 1. Example Logical Elastic Stack Architecture on HCI
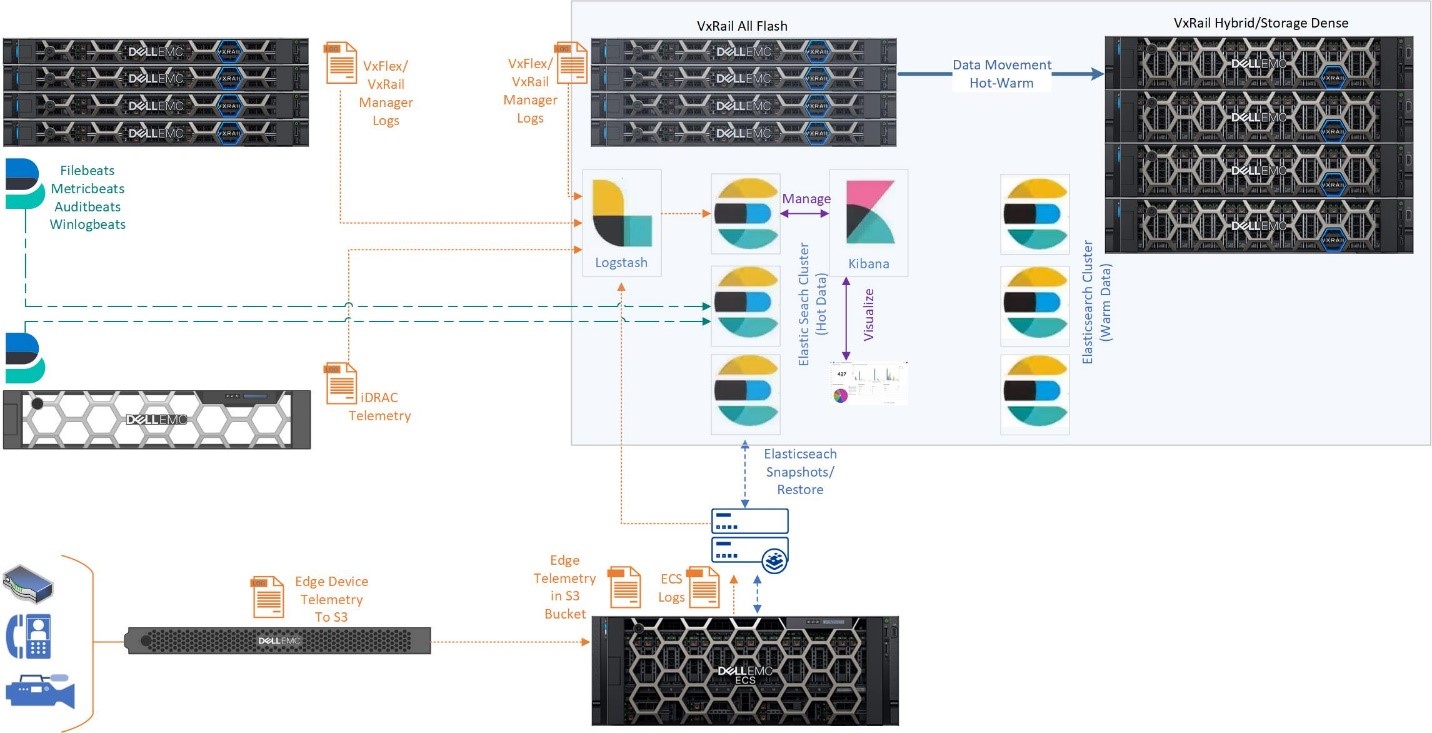
Software-defined storage in HCI provides native enterprise capabilities including data encryption and data protection. Because FlexOS and vSAN provide HA via the software-defined storage, Replica Shards in Elastic for data protection are not required. Elastic will shard an index into 5 shards by default for processing, but Replica Shards for data protection are optional. Because we have data protection at the storage layer we did not use Replicas in our validation of VxFlex and we saw no impact on performance.
HCI enables customers to expand and efficiently manage the rapid adoption of an Elastic environment with dynamic resource expansion and improved infrastructure management tools. This allows for the rapid adoption of new use cases and new insights. HCI reduces datacenter sprawl and associated costs and inefficiencies related to the adoption of Elastic on bare metal. Ultimately HCI can deliver a turnkey experience that enables our customers to continuously innovate through insights derived by the Elastic Stack.
References
- Elastic Technology and Cloud Partners - https://www.elastic.co/about/partners/technology
- Elastic Stack Solution on Dell EMC VxFlex Family - https://www.dellemc.com/en-in/collaterals/unauth/white-papers/products/converged-infrastructure/elastic-on-vxflex.pdf
- Elasticsearch Sizing and Capacity Planning Webinar - https://www.elastic.co/webinars/elasticsearch-sizing-and-capacity-planning
About the Author
Keith Quebodeaux is an Advisory Systems Engineer and analytics specialist with Dell Technologies Advanced Technology Solutions (ATS) organization. He has worked in various capacities with Dell Technologies for over 20 years including managed services, converged and hyper-converged infrastructure, and business applications and analytics. Keith is a graduate of the University of Oregon and Southern Methodist University.
Acknowledgments
I would like to gratefully acknowledge the input and assistance of Craig G., Rakshith V., and Chidambara S. for their input and review of this blog. I would like to especially thank Phil H., Principal Engineer with Dell Technologies whose detailed and extensive advice and assistance provided clarity and focus to my meandering evangelism. Your support was invaluable. As with anything the faults are all my own.
Related Blog Posts

Elastic 7.12 Frozen Data and Dell Technologies ECS Enterprise Object Storage
Tue, 22 Jun 2021 12:28:53 -0000
|Read Time: 0 minutes
Many of us who work with Elastic are excited by the announcement of Elasticsearch 7.12 and the introduction of leveraging S3 for searchable frozen data in Elasticsearch Index Lifecycle Management (ILM). Dell Technologies’ customers were already able to take advantage of ECS Enterprise Object Storage for Elasticsearch snapshots. Now with the introduction of frozen data to S3 for Elasticsearch, customers can reduce the total cost of ownership of historic data in Elasticsearch while maintaining data value and accessibility on Dell ECS.
Elasticsearch is part of the Elastic Stack, also known as the “ELK Stack”, a widely used collection of software products based on open source that is used for search, analysis, and visualization of data by Elastic.co. The Elastic Stack is useful for a wide range of applications, including observability, security, and general-purpose enterprise search. Dell Technologies is an Elastic Technology Partner, OEM Partner, and Elastic customer. Dell Technologies uses the Elastic Stack internally for several use cases, including observability of Kubernetes and text document search.
Dell Technologies ECS Enterprise Object Storage is the leading object storage platform from Dell EMC and boasts unmatched scalability, performance, resilience, and economics. Dell ECS delivers rich S3-compatibility on a globally distributed architecture, empowering organizations to support enterprise workloads such as cloud-native, archive, IoT, AI, and big data analytics applications at scale. Dell ECS is being used by many customers as a globally distributed, object storage platform for machine data and analytics.
In July 2019 Dell Technologies published “Dell EMC ECS: Backing Up Elasticsearch Snapshot Data”. That document illustrates how to configure Elasticsearch to use the backup and restore API to store data in ECS. Snapshots in Elasticsearch are the only reliable and supported method to back up an Elasticsearch cluster. There are no Elastic-supported methods to restore data from a file system backup. You can take snapshots of an entire cluster, or only specific indices in the cluster. In addition to object storage on Dell ECS, Elasticsearch can be backed up to other shared file system such as Isilon or PowerScale. Backing up the data to Dell EMC storage allows customers to have peace of mind that their Elasticsearch data is protected. With Elasticsearch 7.12 and Cold and Frozen data, those snapshots take on even greater significance.
Elasticsearch 7.12 and Frozen Data
The frozen tier in Elasticsearch was introduced recently in Elastic 7.12. Index Lifecycle Management with hot, warm, and cold tiers in addition to the capability to search snapshots was already available in previous versions of Elasticsearch. The addition of the frozen tier allows object stores like Dell ECS to be fully searchable. The addition of the frozen tier in Elasticsearch decouples compute from long-term storage. This feature will help customers reduce costs and resources for historic data while maintaining or expanding the accessibility and value of historic data. Dell Technologies has numerous customers, especially in regulated industries such as healthcare or financial services, who keep or want to keep machine data anywhere from one to seven years to facilitate security investigations, trend analysis, predictive analytics, or audit and regulatory compliance. For many this can be cost-prohibitive, leading customers to choose to delete valuable data or store it in a format that is not easily accessible. Elastic has released the repository test kit to test and validate any S3-compatible object store to work with searchable snapshots and the frozen tier.
Dell Technologies Elasticsearch 7.12 Architecture with ILM and Frozen Data
So how might deployments of Elasticsearch with full data life cycle management look with the Dell Technologies portfolio? Elastic data life cycle management should leverage higher performance block storage for hot and warm data, hot on high speed and warm on lower cost and performance. This could be NVMe or lower density SSD on Dell PowerEdge, VxRail, PowerFlex or PowerStore for hot and higher density SSD or HDD for warm. In 2020, Dell Technologies validated the Elastic Stack running on our VxFlex family of HCI with both VMware and ECK. Because Elasticsearch tiers data on independent data nodes compared to multiple mount points on a single data node or indexer, the multiple types and classes of software defined storage that is presented to independent HCI clusters can be easily leveraged between Elasticsearch clusters to address data temperatures.
Once data is moved to the cold tier Elastic will single-instance your data if you have enabled replica shards. This allows the storing of up to twice the amount of data on the same amount of hardware over the warm tier by eliminating the need to store redundant copies locally. However, this also increases the value of snapshots as the indices in the cold tier are backed up to your object store for redundancy. As mentioned previously, snapshots would be to Dell Technologies ECS.
With the introduction of the frozen tier, Elasticsearch removes the need to store data on locally accessible block storage and uses searchable snapshots to directly search data stored in the object store without the need to rehydrate. As data migrates from warm or cold to frozen based on your ILM policy, indices on local nodes are migrated to your object store. A local cache, typically sized to 10 percent of your frozen data, stores recently queried data for optimal performance on repeat searches. This greatly reduces storage costs for large volumes of data.
Elasticsearch data nodes tend to have average allocations of 8 to 16 cores and 32 to 64 GB of RAM. With the current ability to support up to 112 cores and 6 TB of RAM in a single 2RU Dell server, Elasticsearch is an attractive application for virtualization or containerization. Per guidance from Elastic, if your typical warm tier node with 64 GB of RAM manages 10 TB of data, a cold tier node can handle about twice as much data, and a frozen tier node will jump up to approximately ten times as much data. We would recommend sizing for one physical CPU to one virtual CPU (vCPU) for Elasticsearch Hot Tier along with the management and control plane resources. While this is admittedly like the VMware guidance for some similar analytics platforms, these virtual machines tend to consume a significantly smaller CPU footprint per data node.
Figure 1: Logical Elastic Stack Architecture on HCI example
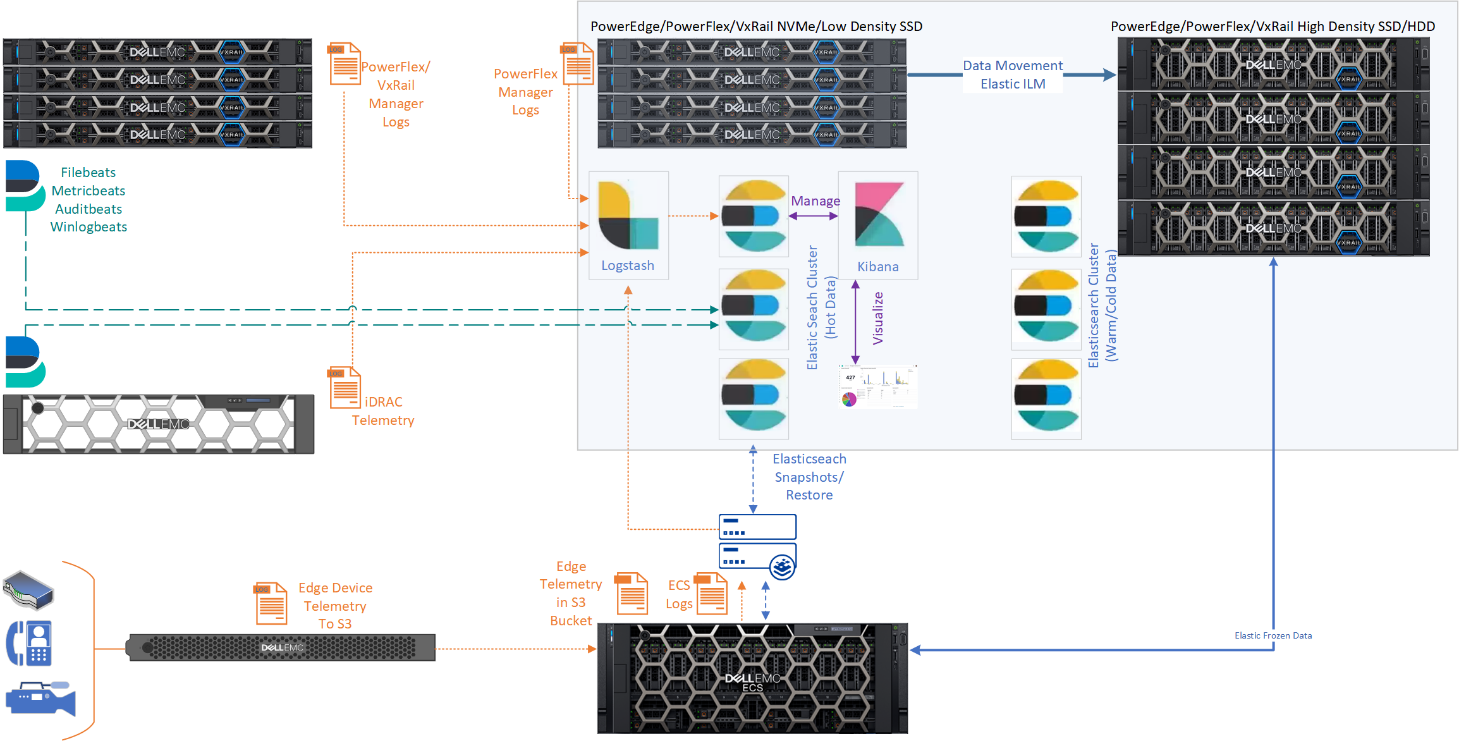
Conclusion
Dell Technologies ECS Enterprise Object Storage is the leading object storage platform from Dell EMC and boasts unmatched scalability, performance, resilience, and economics. Dell Technologies’ customers can take advantage of ECS Enterprise Object Storage for Elasticsearch snapshots, and now with the introduction of frozen data for S3 for Elasticsearch, customers can reduce the total cost of ownership of historic data in Elasticsearch while maintaining data value and accessibility on Dell ECS. Snapshots are the only reliable and supported method to back up an Elasticsearch cluster, and with the introduction of the cold and frozen tier, Elasticsearch snapshots become a critical component of Elasticsearch ILM. ILM with frozen data greatly reduces storage costs for large volumes of data, and Dell Technologies provides a portfolio capable of addressing the entire Elastic data lifecycle and compute requirements with multiple deployment options.
About the Authors
Keith Quebodeaux, Greg Galvan, Steve Meilinger, and Mark Thomas are Systems Engineers and Sales Specialists with Dell Technologies Data Centric Workloads and Solutions (DCWS), working with customers and prospective customers on their data analytics, artificial intelligence, and machine learning initiatives.
Reference Links:
- https://www.delltechnologies.com/resources/en-us/asset/white-papers/products/storage/h17847-dell-emc-ecs-backing-up-elasticsearch-data-wp.pdf
- https://www.delltechnologies.com/resources/en-us/asset/white-papers/products/storage/h18274-backup-elasticsearch-data-to-dell-emc-isilon.pdf
- https://www.elastic.co/about/partners/technology
- https://www.dellemc.com/en-in/collaterals/unauth/white-papers/products/converged-infrastructure/elastic-on-vxflex.pdf
- https://www.elastic.co/webinars/elasticsearch-sizing-and-capacity-planning

Navigating the modern data landscape: the need for an all-in-one solution

Mon, 18 Mar 2024 19:56:59 -0000
|Read Time: 0 minutes
There are two revolutions brewing inside every enterprise. We are all very familiar with the first one - the frenzied rush to expand an organization's AI capabilities, which leads to an exponential growth in data creation, a rise in availability of high-performance computing systems with multi-threaded GPUs, and the rapid advancement of AI models. The situation creates a perfect storm that is reshaping the way enterprises operate. Then, there is a second revolution that makes the first one a reality – the ability to harness this awesome power and gain a competitive advantage to drive innovation. Enterprises are racing towards a modern data architecture that seeks to bring order to their chaotic data environment.
The Need For An All-In-One Solution
Data platforms are constantly evolving, despite a plethora of options such as data lakes, data warehouses, cloud data warehouses and even cloud data lakehouses, enterprise are still struggling. This is because the choices available today are suboptimal.
Cloud native solutions offer simplicity and scalability, but migrating all data to the cloud can be a daunting task and can end up being significantly more expensive over the long term. Moreover, concerns about the loss of control over proprietary data, particularly in the realm of AI, is a major cause for concern, as well. On the other hand, traditional on-premises solutions require significantly more expertise and resources to build and maintain. Many organizations simply lack the skills and capabilities needed to construct a robust data platform in-house.
A customer once told me – “We’ve heard from so many vendors but ultimately there is no easy button for us.”
When Dell Technologies set out to build that easy button, we started with what enterprises needed most: infrastructure, software, and services all seamlessly integrated. We created a tailor-made solution with right-sized compute and a highly performant query engine that is pre-integrated and pre-optimized to perfectly streamline IT operations. We incorporated built-in enterprise-grade security that also can seamlessly integrate with 3rd party security tools. To enable rapid support, we staffed a bench of experts, offering end-to-end maintenance and deployment services. We also knew the solution needed to be future proof – not only anticipating future innovations but also accommodating the diverse needs of users today. To support this idea, we made the choice to use open data formats, which means an organization’s data is no longer locked-in to a proprietary format or vendor. To make the transition easier, the solution makes use of built-in enterprise-ready connectors that ensures business continuity. Ultimately, our goal was to deliver an experience that is easy to install, easy to use, easy to manage, easy to scale, and easy to future-proof.
Dell Data Lakehouse’s Core Capabilities
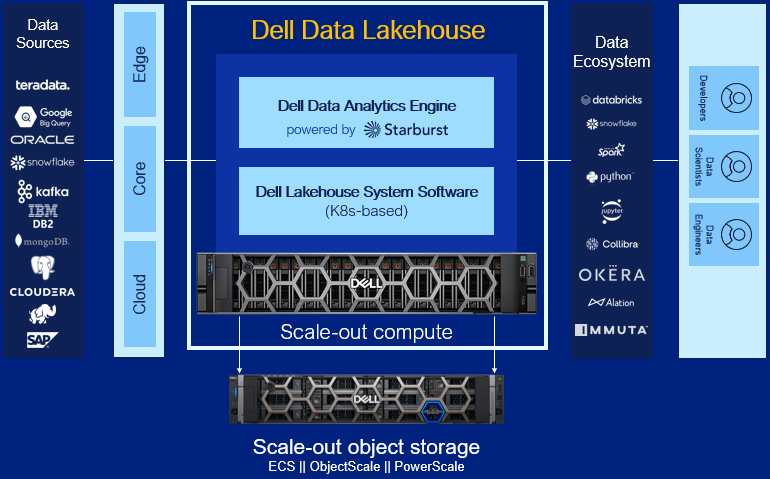
Let’s dig into each component of the solution.
- Data Analytics Engine, powered by Starburst: A high performance distributed SQL query engine, built on top of Starburst, based on Trino, which can run fast analytic queries against data lakes, lakehouses and distributed data sources at internet-scale. It integrates global security with fine-grained access controls, supports ad-hoc and long-running ELT workloads and is a gateway to building high quality data products and power AI and Analytics workloads. Dell’s Data Analytics Engine also includes exclusive features that help dramatically improve performance when querying data lakes. Stay tuned for more info!
- Data Lakehouse System Software: This new system software is the central nervous system of the Dell Data Lakehouse. It simplifies lifecycle management of the entire stack, drives down IT OpEx with pre-built automation and integrated user management, provides visibility into the cluster health and ensures high availability, enables easy upgrades and patches and lets admins control all aspects of the cluster from one convenient control center. Based on Kubernetes, it’s what converts a data lakehouse into an easy button for enterprises of all sizes.
- Scale-out Lakehouse Compute: Purpose-built Dell Compute and Networking hardware perfectly matched for compute-intensive data lakehouse workloads come pre-integrated into the solution. Independently scale from storage by seamlessly adding more compute as needs grow.
- Scale-out Object Storage: Dell ECS, ObjectScale and PowerScale deliver cyber-secure, multi-protocol, resilient and scale-out storage for storing and processing massive amounts of data. Native support for Delta Lake and Iceberg ensures read / write consistency within and across sites for handling concurrent, atomic transactions.
- Dell Services: Accelerate AI outcomes with help at every stage from trusted experts. Align a winning strategy, validate data sets, quickly implement your data platform and maintain secure, optimized operations.
- ProSupport: Comprehensive, enterprise-class support on the entire Dell Data Lakehouse stack from hardware to software delivered by highly trained experts around the clock and around the globe.
- ProDeploy: Expert delivery and configuration assure that you are getting the most from the Dell Data Lakehouse on day one. With 35 years of experience building best-in-class deployment practices and tools, backed by elite professionals, we can deploy 3x faster1 than in-house administrators.
- Advisory Services Subscription for Data Analytics Engine: Receive a pro-active, dedicated expert to maximize value of your Dell Data Analytics Engine environment, guiding your team through design and rollout of new use cases to optimize and scale your environment.
- Accelerator Services for Dell Data Lakehouse: Fast track ROI with guided implementation of the Dell Data Lakehouse platform to accelerate AI and data analytics.
Learn More
With the combination of these capabilities, Dell continues to innovate alongside our customers to help them exceed their goals in the face of data challenges. We aim to allow our customers to take advantage of the revolution brewing that is AI and this rapid change in the market to harness the power of their data and gain a competitive advantage and drive innovation. Enterprises are racing towards a modern data architecture – it's critical they don’t get stuck at the starting line.
For detailed information on this exciting product, refer to our technical guide. For other information, visit Dell.com/datamanagement.
Source
1 Based on a May 2023 Principled Technologies study “Using Dell ProDeploy Plus Infrastructure can improve deployment times for Dell Technology”