



Scaling Up VxRail: Managing an Ecosystem
Tue, 08 Nov 2022 20:13:27 -0000
|Read Time: 0 minutes
This is the sixth article in a series introducing VxRail concepts.
The engineering team behind VxRail has done a fantastic job building cluster and life cycle management tools into our software. The cluster update process is an excellent example of one of these software enhancements. However, we need to go further. The value of these enhancements decays a bit as you have more and more clusters, resulting in more and more actions required to manage an environment. This end result is antithetical to the entire idea behind VxRail. However, this complexity reintroduction never occurs, thanks to the features and functionality of the VxRail API and CloudIQ. The API scales out management operations by providing access to many of the same software calls that VxRail makes. Then we have CloudIQ. CloudIQ is a cloud-based management utility that can interface with various Dell infrastructures that VxRail uses to improve cluster management as environments scale out.
Expanding and automating your VxRail environment
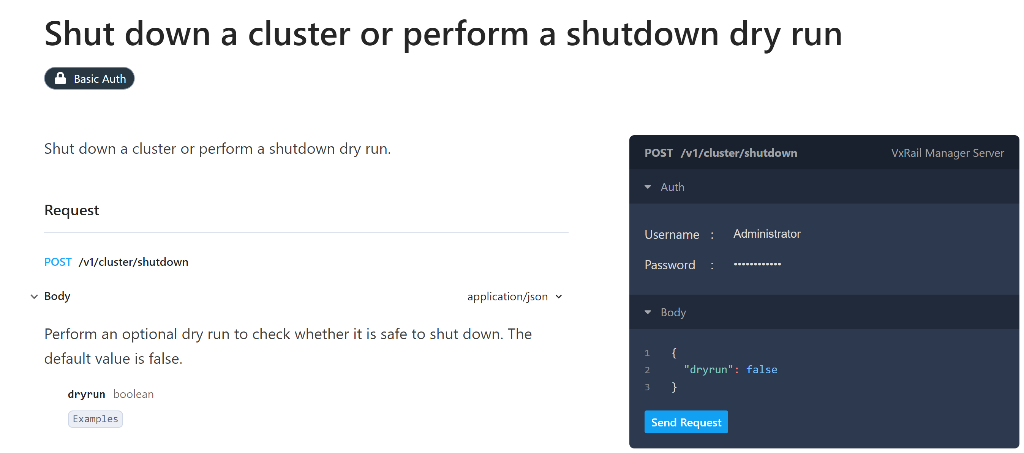 For readers that aren’t familiar with what APIs are, the acronym stands for “Application Programming Interface.” APIs exist to help two, or sometimes more, pieces of software communicate with each other. VxRail has its own API that works in conjunction with VMware APIs and the Redfish API for the iDRAC and hardware. This enables the management of hardware and both VMware and VxRail software at scale. The VxRail API Guide shows the full range of calls available to developers. There are dozens of them; the last number I saw was over 70 individual calls. Now, there’s more to the API than its comprehensive nature. It also brings with it the simplicity of use. The API can be taken advantage of using the Swagger web interface and a PowerShell module to provide simple command line interfaces that IT staff are familiar with.
For readers that aren’t familiar with what APIs are, the acronym stands for “Application Programming Interface.” APIs exist to help two, or sometimes more, pieces of software communicate with each other. VxRail has its own API that works in conjunction with VMware APIs and the Redfish API for the iDRAC and hardware. This enables the management of hardware and both VMware and VxRail software at scale. The VxRail API Guide shows the full range of calls available to developers. There are dozens of them; the last number I saw was over 70 individual calls. Now, there’s more to the API than its comprehensive nature. It also brings with it the simplicity of use. The API can be taken advantage of using the Swagger web interface and a PowerShell module to provide simple command line interfaces that IT staff are familiar with.
The API can help customers of any size, but who I see that benefits the most from using an API is a large customer that might have tens to hundreds of nodes in many clusters. The scale of these environments creates a need for further automation that can link VxRail clusters with management tools and practices. Some use-case examples include items like node discovery to see what various hardware is available and the versions running on that hardware; another example would be something like examining node and cluster health throughout the data center. The API can also enable infrastructure-as-code projects, such as automatically spinning up and winding down clusters as needed. Even automating simple tasks, like the shutdown of clusters in a way that maintains data consistency, provides a massive value to VxRail customers.
CloudIQ: Helping Manage Your Ecosystem
VxRail has more than the API to aid in managing large environments. As great as the API is, it takes a bit of preparation to use, whereas CloudIQ is ready for use as soon as Secure Connect Gateway is enabled and clusters are enrolled. If you haven’t heard of CloudIQ, I recommend checking out the CloudIQ simulator. The simulator doesn’t provide access to the complete feature set of CloudIQ but makes for an excellent introduction to what the product can do.
 CloudIQ is a cloud-based application that monitors and resolves problems with Dell storage, server, data protection, networking, HCI, and CI products, and APEX services. You might see CloudIQ referred to as an AIOps application. This is short for artificial intelligence for IT operations. In the case of VxRail, this data is sent in by customers’ clusters using Secure Connect Gateway, where CloudIQ can then perform analytics functions. The output of this analytics can be used to create custom reports, create various estimates on storage utilization, reduce IT risk, and recover from problems faster. Beginning in May and continuing into June, Dell ran a survey of CloudIQ users. These users were able to accelerate IT recovery as little as 2x to as much as 10x faster, which saved them about an entire workday per week, on average. CloudIQ provides all this to customers with no financial or IT overhead due to it being freely available for use by Dell customers connecting to the Dell cloud.
CloudIQ is a cloud-based application that monitors and resolves problems with Dell storage, server, data protection, networking, HCI, and CI products, and APEX services. You might see CloudIQ referred to as an AIOps application. This is short for artificial intelligence for IT operations. In the case of VxRail, this data is sent in by customers’ clusters using Secure Connect Gateway, where CloudIQ can then perform analytics functions. The output of this analytics can be used to create custom reports, create various estimates on storage utilization, reduce IT risk, and recover from problems faster. Beginning in May and continuing into June, Dell ran a survey of CloudIQ users. These users were able to accelerate IT recovery as little as 2x to as much as 10x faster, which saved them about an entire workday per week, on average. CloudIQ provides all this to customers with no financial or IT overhead due to it being freely available for use by Dell customers connecting to the Dell cloud.
Conclusion
Growth is exciting, but it comes with new challenges, and old ones don’t go away—they get bigger. VxRail provides customers with an API designed to work with the iDRAC and VMware APIs to provide automation throughout the entire cluster stack. This helps customers reduce repetitive labor tasks and create infrastructure-as-code projects. Then with CloudIQ, IT staff can get a view of their Dell infrastructure equipment from one pane of glass. For VxRail, this would include software versions, cluster health scores, the ability to initiate updates, and other functionality. While the API offers most of its value to customers with very large VxRail footprints, most all customers can also benefit from CloudIQ to view multiple clusters as well as the remainder of their Dell infrastructure equipment.
Related Blog Posts

A Closer Look at New Features Brought with VxRail 7.0.480
Sat, 17 Feb 2024 23:57:31 -0000
|Read Time: 0 minutes
The landscape of VxRail software is ever-evolving. As software releases become available, so too do new features and functions. These new features and functions create a more robust ecosystem, focusing on simplifying regular tasks that appear mundane but are critical to maintaining a secure, up-to-date, and healthy IT environment. VxRail 7.0.480 brought several new and enhanced capabilities to administrators, continuing to build on the streamlined infrastructure management experience that VxRail offers. Many of these improvements are part of the LCM experience. Let’s take a moment to discuss some of these new software improvements and what they can do for infrastructure staff. These include expanded storage of update advisor reports from one report to thirty reports, the ability to export compliance reports to preservable files, automated node reboots for clusters, and extended ADC bundle and installer metadata upload functionality for improved prechecking and update advisor reporting.
Extended update advisor report availability
Administrative teams have likely seen various update advisor reports. These reports have been part of the VxRail LCM experience for the past few releases and present a look at the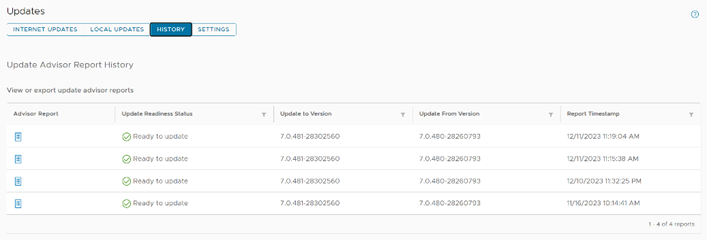 Figure 1. A view of the pane showing multiple update advisor reports available for review cluster as it is at the moment. That said, storing multiple reports helps provide a documented history of the cluster. VxRail 7.0.480 has taken these singular reports and extended their storage to hold up to thirty reports, granting administrators the information and reporting to review up to the last thirty updates.
Figure 1. A view of the pane showing multiple update advisor reports available for review cluster as it is at the moment. That said, storing multiple reports helps provide a documented history of the cluster. VxRail 7.0.480 has taken these singular reports and extended their storage to hold up to thirty reports, granting administrators the information and reporting to review up to the last thirty updates.
Imagine that you have a large cluster. Different nodes could need different remediating actions. The ability to maintain multiple reports would enable administrators to address issues raised in a report while also creating a documentation trail for when corrective actions take multiple administrative cycles spanning extended lengths of time, possibly exceeding a day.
Export of compliance drift reports
Compliance drift reports are another reporting element of the LCM process, helping administrators to ensure that clusters conform with a Continuously Validated State (CVS) on a daily basis. This frees up administrators to attend to business-specific tasks, while ensuring that the more mundane work of gathering software versions for review is automated. This is a critical task that helps prevent time-intensive infrastructure issues that IT teams need to dedicate resources to correcting. Additionally, these reports ensure that LCM updates are successful by identifying any components that may have drifted from what is defined by the current Continuously 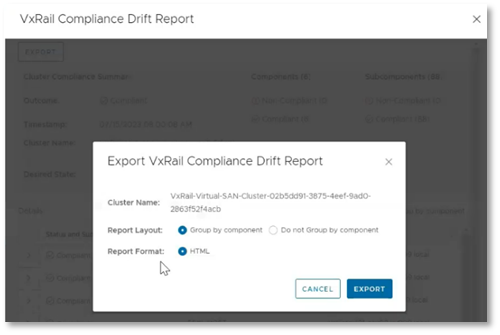 Figure 2. The option to export a drift report to a local HTML fileValidated State.
Figure 2. The option to export a drift report to a local HTML fileValidated State.
These compliance drift reports, demonstrated to the right, can now be exported, aiding administrators in creating and maintaining a documented history of their clusters' adherence to Continuously Validated States. Each report can be grouped by components and is saved to an HTML file, preserving the original view that VxRail administrators have come to know.
Sequential node reboot
Our next new feature automates the sequential reboot of nodes within a cluster, a task that many customers engage in manually. The automatic node reboot function is found within the Hosts submenu in the Configure tab. As shown in the following demonstration, administrators simply select the nodes they want to reboot, click the reboot button, and then complete the wizard. The wizard offers the options to begin rebooting immediately or schedule them for a later time. Once this selection is made, the wizard will run a precheck, and the reboot cycles can begin. While this feature most benefits larger clusters, clusters of any size are advantaged by automating infrastructure tasks. Node reboots can help further improve update cycle success rates by clearing issues like memory utilization or restarting any potentially hung processes.
As an example, let’s consider memory utilization again. If there were an issue with the balloon driver making memory available, the update precheck would detect it, however rebooting the node would restart the service and force the memory to be made available once again. We’ve also observed cases where larger clusters are updated less often compared to smaller clusters due to longer maintenance windows. This can lead to longer times between reboots for larger clusters. The sequential reboot of nodes within a cluster eases the difficulty in restarting larger clusters through automation and orchestration, leading to restarts with minimal administrator activity. This can clear a variety of issues that could halt an upgrade.
That said, manually rebooting each node within a cluster can require a significant time investment. Imagine for a moment that we have a 20-node cluster. If it took just 10 minutes per node to migrate workloads away from a node, restart the host, bring it back online physically and relaunch software services, and finally bring workload back, cycling through all 20 nodes would still take over three hours of an administrator's undivided attention and time. In reality, this reboot cycle would likely take longer. Automating these actions allows clusters to benefit from these actions while freeing IT staff up to focus on other critical business tasks.
ADC bundle and installer metadata upload
VxRail 7.0.480 brings the ability to use the adaptive data collector (ADC) bundle and installer metadata, shown being uploaded in the following demonstration, to update the LCM precheck and update advisor functions VxRail Manager provides. This is helpful because the precheck routinely welcomes new developments, leading to a more robust precheck and more successful LCM update cycles. For example, one of the more recent precheck developments involves an additional check on memory utilization. The LCM precheck examines CPU and memory utilization of the vCenter Server appliance. If either CPU or memory utilization exceeds an 80% threshold, a warning will appear in the precheck report. If the check occurs as part of an upgrade cycle, then the warning appears in the update progress dashboard. The update advisor metadata file includes all the version information related to the target VxRail release version. This allows the update advisor to create reports showing the current, expected, and target software versions for each LCM cycle. These packages are pulled by VxRail Manager automatically over the network for clusters using a Secure Connect Gateway connection and are also available to offline dark sites using the Local Updates tab.
Conclusion
The VxRail engineering team routinely delivers new features and functions to our customers. In this blog, we reviewed the enhancements for expanded update advisor report storage, the ability to export drift reports to local HTML files, automated cluster node reboot cycles, and the enhanced LCM precheck and update advisor with the ADC bundle and installer metadata file uploads. As we move forward, we continue to enhance LCM operations and minimize the time required to manage VxRail. As such, VxRail is a fantastic choice to run your virtualized workloads and will continue to become a more robust and administration-friendly platform.
Author: Dylan Jackson, Engineering Technologist

Empowering Cloud-based Multi-cluster Management Using VxRail with CloudIQ
Fri, 18 Aug 2023 23:01:25 -0000
|Read Time: 0 minutes
Introduction
In today's digital landscape, organizations across various industries are generating and accumulating amazing sums of data. To harness the potential of this explosive data growth, businesses heavily rely on cluster computing. Managing these clusters effectively is critical to optimizing performance and ensuring continuous operations. VxRail clusters provide massive amounts of automation right out-of-the-box, which helps administrators accomplish significantly more.
But as the number of clusters grows, a centralized management interface becomes more and more valuable. That’s why I wanted to talk to you about CloudIQ today and introduce three exciting new features:
- Support for 2-node and stretched vSAN clusters
- DPU monitoring
- Performance anomaly detection with historical seasonality
These advancements revolutionize cluster management because they offer enhanced efficiency, flexibility, and performance to meet the evolving needs of modern enterprises.
The evolution of cloud-based cluster management
Traditional on-premises cluster management frequently presents challenges with hardware maintenance, scalability issues, and costly infrastructure investments. Cluster management with CloudIQ has proved to be a game-changer, allowing businesses to centralize the management of hardware and infrastructure to a single cloud-based tool.
By combining VxRail automation with CloudIQ, enterprises can focus on optimizing their applications and workflows while more easily handling cluster provisioning, scaling, and maintenance. This paradigm shift not only improves resource allocation and utilization. It also enables organizations to adapt more quickly to dynamic workloads.
2-Node and stretched vSAN cluster support for CloudIQ
In response to diverse business needs, CloudIQ now supports two additional cluster deployment types: the 2-node and stretched vSAN clusters.
2-Node Clusters
Traditionally, clusters required a minimum of three nodes to maintain high availability, because having an odd number of nodes helped avoid split-brain scenarios. However, 2-node clusters can also address this challenge and ensure fault tolerance and high availability.
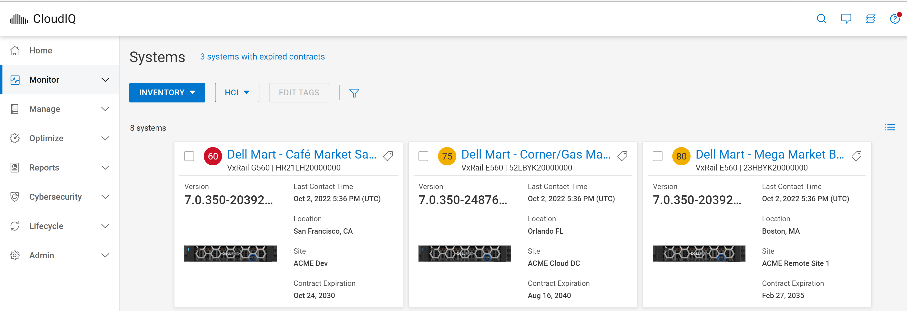
2-node clusters use advanced quorum mechanisms, allowing them to make decisions efficiently despite the lack of a third node. The nodes in the cluster communicate with each other and decide on quorum, based on various factors like network connectivity, storage health, and other cluster components. This setup significantly reduces infrastructure costs and is ideal for small to medium-sized businesses that require robust cluster management without the expense of additional nodes. 2-node clusters populate in the same location in CloudIQ as the rest of your clusters. They can be found by selecting the Systems option under the Monitor tab. After you select Systems, select the HCI inventory option and your enrolled VxRail clusters will populate there.
Stretched vSAN clusters
Businesses often want to deploy clusters across multiple geographically distributed data centers to improve disaster recovery and enhance business continuity. Stretched VxRail clusters with vSAN provide an excellent solution by extending vSAN technology across multiple data centers.
Key benefits of stretched VxRail clusters with vSAN include:
- Disaster Recovery: By replicating data between data centers, these clusters protect against site-wide outages, ensuring that operations continue seamlessly in case of a data center failure.
- Load Balancing: Stretched clusters intelligently distribute workloads across different data centers, based on demand, to optimize resource utilization and performance.
- Data Locality: Organizations can maintain data locality to comply with regional data regulations and reduce data access latency for end-users across different geographical regions.
Data Processing Unit Reporting
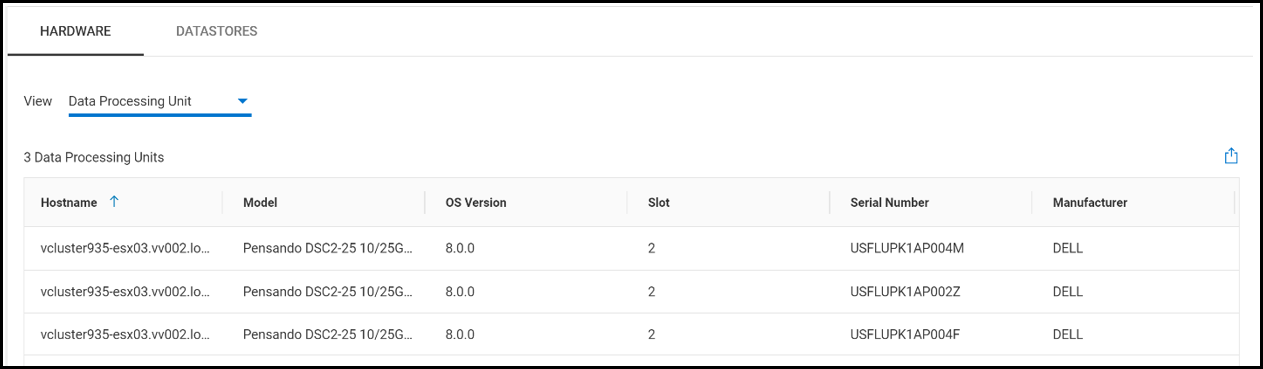
In a clustered environment, data processing units (DPUs) can become critical for efficient resource management. DPUs are hardware accelerators designed to handle specific data processing tasks, like NSX and other tasks handled by the vSphere Distributed Services Engine, to enhance overall cluster performance for specific workloads.
The Data Processing Unit Reporting feature provides insight into the details of DPUs within the cluster. Cluster administrators can view the hardware information for each DPU, including: the host name of each server with a DPU, the model, the OS version running on the host, the slot the DPU is installed in, each DPU’s serial number, and their manufacturer.
Performance Anomaly Detection
Unanticipated performance fluctuations can significantly impact application responsiveness and overall user experience. To address this concern, CloudIQ now integrates Performance Anomaly Detection—an intelligent monitoring feature that proactively identifies performance issues as they develop.
How does Performance Anomaly Detection work?
This feature uses machine learning algorithms to establish baseline performance patterns for various cluster metrics, including CPU utilization, memory utilization, power consumption, and networking.
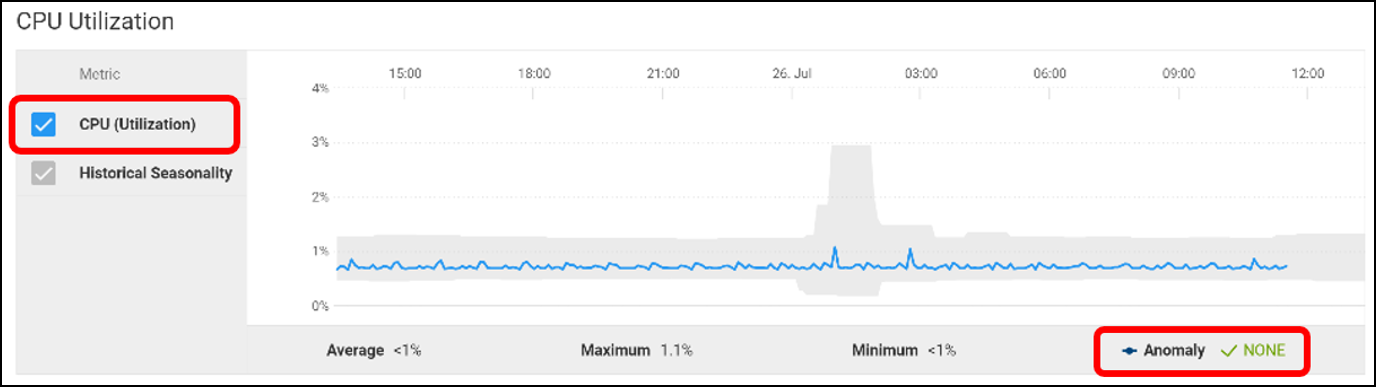
When configured, the system continuously monitors real-time performance metrics and compares them to the baseline.
When CloudIQ detects any deviations from the expected behavior, it can raise alerts, enabling administrators to investigate and rectify potential problems immediately. This proactive approach ensures that performance issues are addressed before they affect critical operations, reducing downtime and enhancing user satisfaction.
Conclusion
As the demand for efficient data processing and storage continues to grow, cloud-based cluster management becomes vital for modern enterprises. The introduction of 2-node and stretched vSAN cluster support, data processing unit reporting, and performance anomaly detection takes cluster management to new heights. By leveraging the cutting-edge features of CloudIQ with VxRail, business organizations can unlock unparalleled efficiency, scalability, and performance, gaining a competitive advantage in today's fast-paced digital landscape. Embracing cloud-based cluster management with CloudIQ and its new features will undoubtedly pave the way for a bright and productive future for organizations and industries of all sizes.
Author: Dylan Jackson