




Next Generation Dell PowerEdge XR7620 Server Machine Learning (ML) Performance
Download PDFFri, 03 Mar 2023 19:57:26 -0000
|Read Time: 0 minutes
Summary
Dell Technologies has recently announced the launch of next-generation Dell PowerEdge servers that deliver advanced performance and energy efficient design.
This Direct from Development (DfD) tech note describes the new capabilities you can expect from the next-generation Dell PowerEdge servers powered by Intel 4th Gen Intel® Xeon® Scalable processors MCC SKU stack. This document covers the test and results for ML performance of Dell’s next generation PowerEdge XR 7620 using the industry standard MLPerf Inference v2.1 benchmarking suite. XR7620 has target workloads in manufacturing, retail, defense, and telecom - all key workloads requiring AI/ML inferencing capabilities at the edge.
With up to 2x300W accelerator cards for GPUs to handle your most demanding edge workloads, XR7620 provides a 45% faster image classification workload as compared to the previous generation Dell XR 12 server with just one 300W GPU accelerator for the ML/AI scenarios at the enterprise edge. The combination of low latency and high processing power allows for faster and more efficient analysis of data, enabling organizations to make real-time decisions for more opportunities.
Edge computing
Edge computing, in a nutshell, brings computing power close to the source of the data. As the Internet of Things (IoT) endpoints and other devices generate more and more time-sensitive data, edge computing becomes increasingly important. Machine Learning (ML) and Artificial Intelligence (AI) applications are particularly suitable for edge computing deployments. The environmental conditions for edge computing are typically vastly different than those at centralized data centers. Edge computing sites might, at best, consist of little more than a telecommunications closet with minimal or no HVAC. Rugged, purpose-built, compact, and accelerated edge servers are therefore ideal for such deployments. The Dell PowerEdge XR7620 server checks all of those boxes. It is a high-performance, high-capacity server for the most demanding workloads, certified to operate in rugged, dusty environments ranging from -5C to 55C (23F to 131F), all within a short-depth 450mm (from ear-to-rack) form factor.
MLPerf Inference workload summary
MLPerf is a multi-faceted benchmark suite that benchmarks different workload types and different processing scenarios. There are five workloads and three processing scenarios. The workloads are:
- Image classification
- Object detection
- Medical image segmentation
- Speech-to-text
- Language processing
The scenarios are single-stream (SS), multi-stream (MS), and Offline.
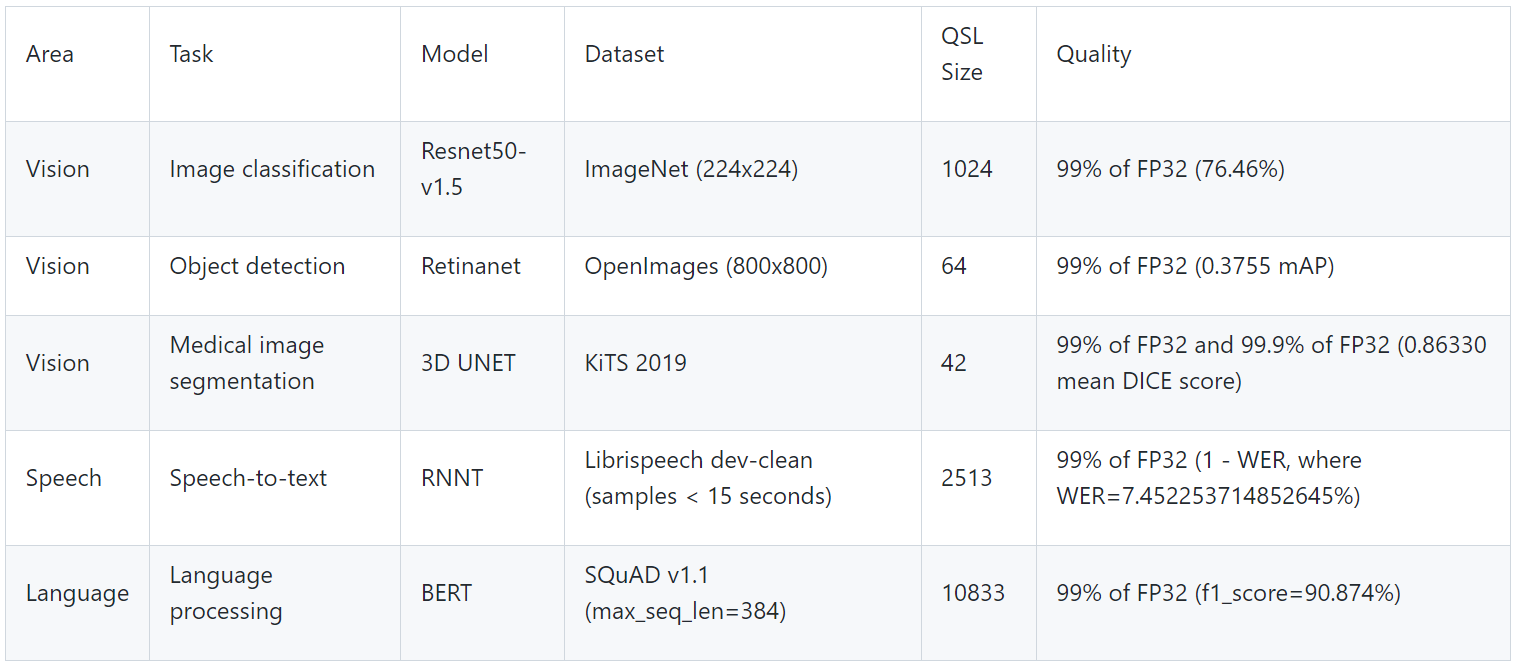
The tasks are self-explanatory and are listed in the following table below, along with the dataset used, the ML model used, and descriptions. The single-stream tests reported results at the 90th percentile; multi-stream tests reported results at the 99th percentile.
Table 1. MLPerf Inference benchmark scenarios
Scenario | Performance metric | Example use cases |
Single-stream | 90% percentile latency | Google voice search: Waits until the query is asked and returns the search results. |
Offline | Measured throughput | Batch processing aka Offline processing. Google photos identifies pictures, tags people, and generates an album with specific people and locations/events Offline. |
Multi-stream | 99% percentile latency | Example 1: Multicamera monitoring and quick decisions. MultiStream is more like a CCTV backend system that processes multiple real-time streams on identifying suspicious behaviors. Example 2: Self driving cameras merge all multiple camera inputs and make drive decisions in real time. |
Table 2. MLPerf EdgeSuite for inferencing benchmarks
Industry reports about the future of edge computing
According to Forrester’s report (“Five technology elements make workload affinity possible across the four business scenarios”), most systems today are designed to run software in a single place. This creates performance limitations as conditions change, such as when more sensors are installed in a factory, as more people gather for an event, or as cameras receive more video feed. Workload affinity is the concept of using distributed applications to deploy software automatically where it runs best: in a data center, in the cloud, or across a growing set of connected assets. Innovative AI/ML, analytics, IoT, and container solutions enable new applications, deployment options, and software design strategies. In the future, systems will choose where to run software across a spectrum of possible locations, depending on the needs of the moment.
ML/AI inference performance
Table 3. Dell PowerEdge XR7620 key specifications
MLPerf system suite type | Edge |
Operating System | CentOS 8.2.2004 |
CPU | 4th Gen Intel® Xeon® Scalable processors MCC SKU |
Memory | 512GB |
GPU | NVIDIA A2 |
GPU Count | 1 |
Networking | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software Stack | TensorRT 8.4.2 CUDA 11.6 cuDNN 8.4.1 Driver 510.73.08 DALI 0.31.0 |

Figure 1. Dell PowerEdge XR7620: 2U 2S
Table 4. NVIDIA GPUs Tested:
Brand | GPU | GPU memory | Max power consumption | Form factor | 2-way bridge | Recommended workloads |
PCIe Adapter Form Factor | ||||||
NVIDIA | A2 | 16 GB GDDR6 | 60W | SW, HHHL or FHHL | n/a | AI Inferencing, Edge, VDI |
NVIDIA | A30 | 24 GB HBM2 | 165W | DW, FHFL | Y | AI Inferencing, AI Training |
NVIDIA | A100 | 80 GB HBM2e | 300W | DW, FHFL | Y, Y | AI Training, HPC, AI Inferencing |
The edge server offloads the image processing to the GPU. And just as servers have different price/performance levels to suit different requirements, so do GPUs. XR7620 supports up to 2xDW 300W GPUs or 4xSW 150W GPUs, part of the constantly evolving scalability and flexibility offered by the Dell PowerEdge server portfolio. In comparison, the previous gen XR11 could support up to 2xSW GPUs.
Edge server vs data center server comparison[1]
When testing with NVIDIA A100 GPU for the Offline scenario, the Dell XR7620 delivered a performance with less than 1% difference, as compared to the prior generation Dell PowerEdge rack server. The XR7620 edge server with a depth of 430mm is capable of providing similar performance for an AI inferencing scenario as a rack server. See Figure 2.
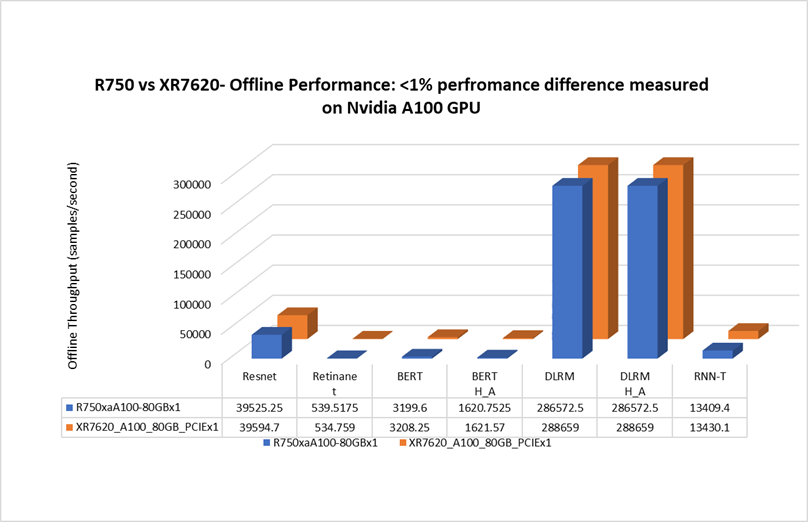
Figure 2. Rack vs edge server MLPerf Offline performance
XR7620 performance with NVIDIA A2 GPU
XR7620 was also tested with NVIDIA A2 GPU for the entire range of MLPerf workloads in the Offline scenario. For the results, see Figure 3.
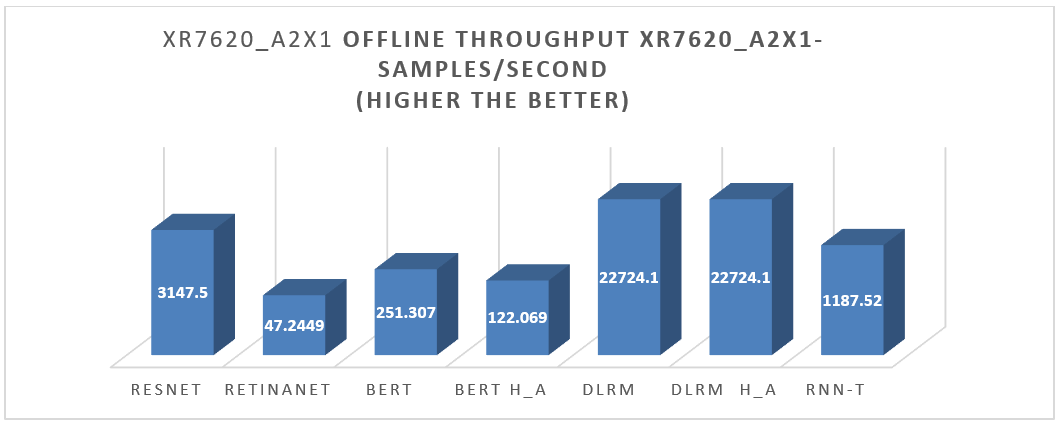
Figure 3. XR7620 Offline performance results
XR7620 was also tested with NVIDIA A2 GPU for the entire range of MLPerf workloads in the Single Stream scenario. See Figure 4.
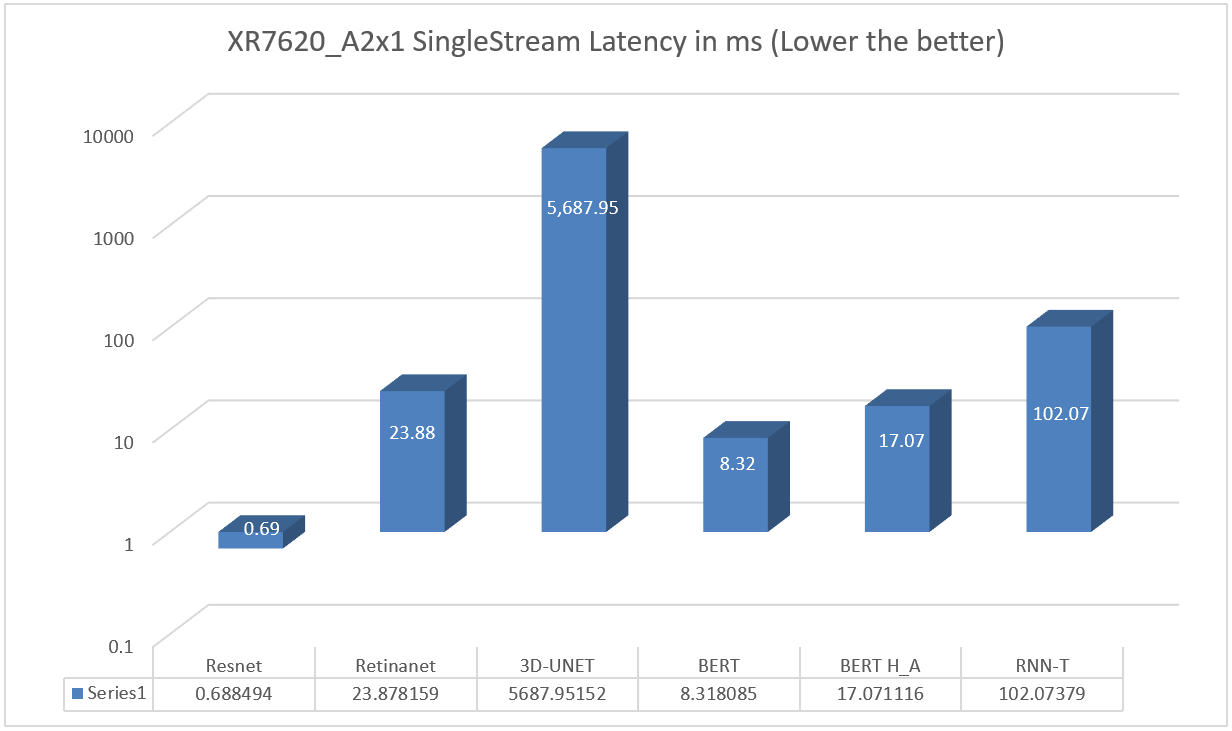
Figure 4. XR7620 Single Stream Performance results
XR7620 was also tested with NVIDIA A30 GPU for the entire range of MLPerf workloads in the Offline Scenario. See Figure 5.
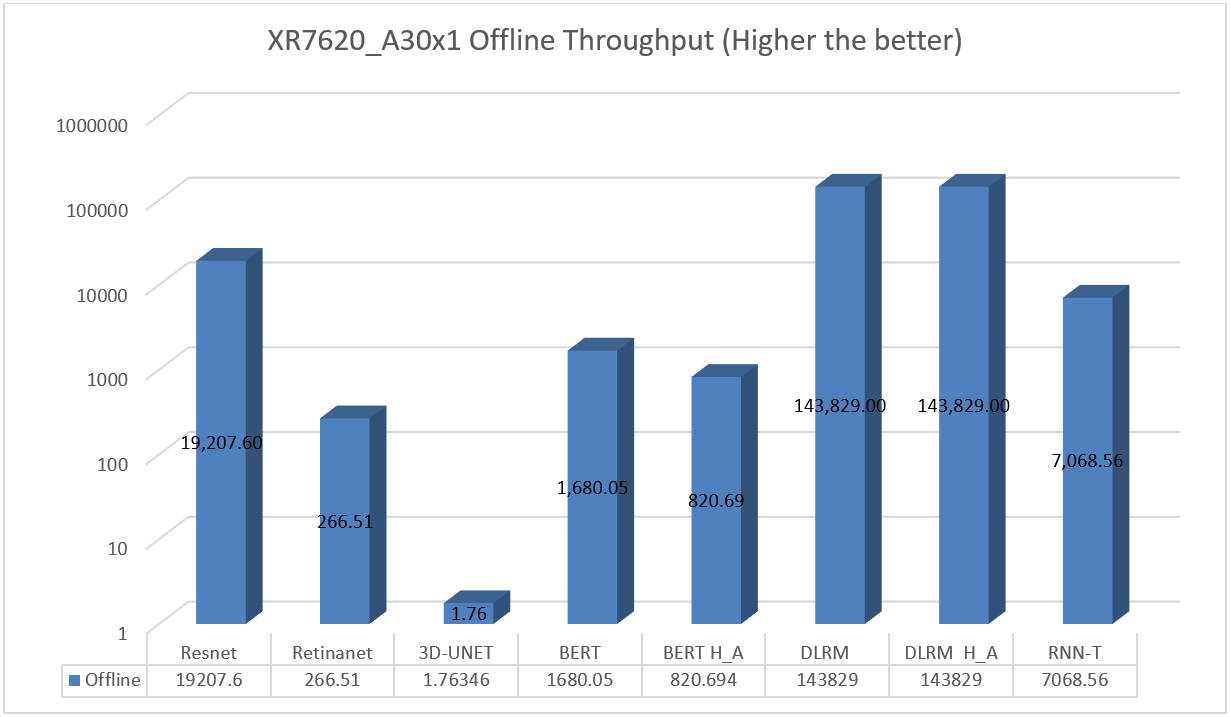
Figure 5. XR7620 Offline Performance results on A30 GPU
XR7620 was also tested with NVIDIA A30 GPU for the entire range of MLPerf workloads in the Single Scenario. See Figure 6.
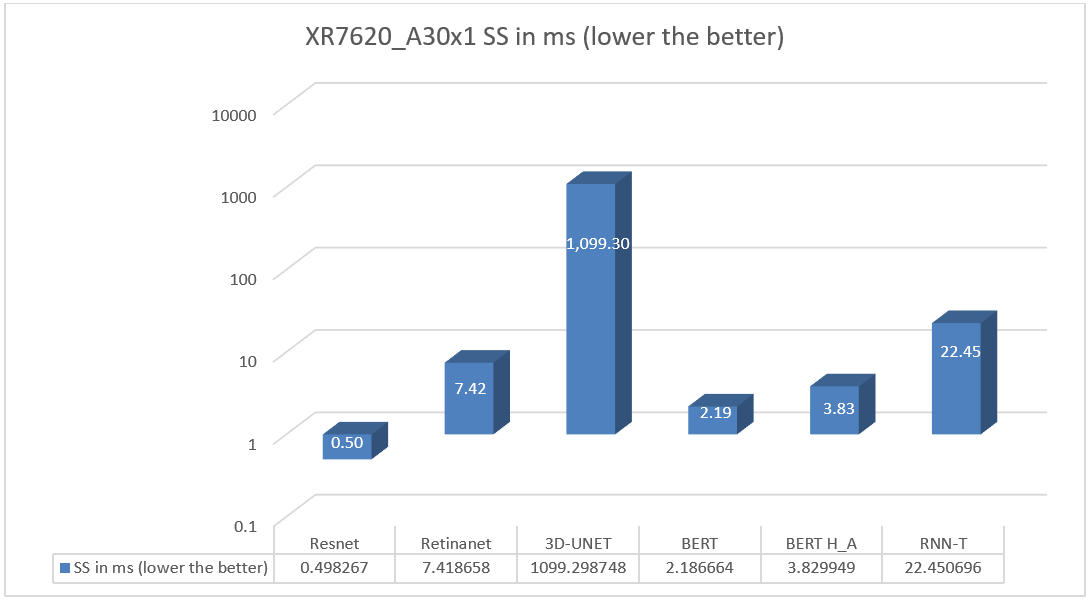
Figure 6. XR7620 SS Performance results on A30 GPU
In some scenarios, next generation Dell PowerEdge servers showed improvement over previous generations, due to the integration of the latest technologies such as PCIe Gen 5.
Speech to text
The Dell XR7620 delivered better throughput by 16%, as compared to the prior generation Dell server. See Figure 7
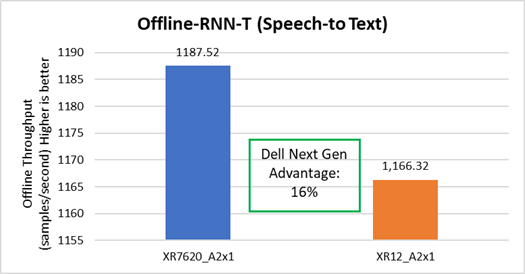
Figure 7. Offline Speech to Text performance improvement on XR7620
Image Classification
The Dell XR7620 delivered better latency by 45%, as compared to the prior generation Dell server. See Figure 8.
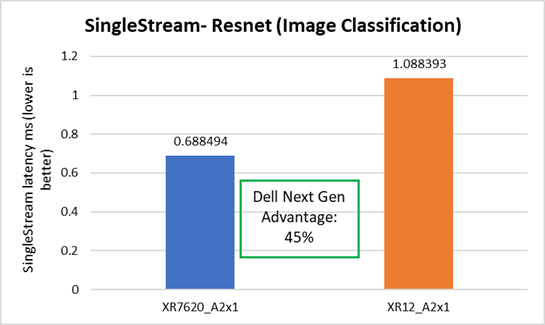
Figure 8. SS Image Classification performance improvement on XR7620
Conclusion
The Dell XR portfolio continues to provide a streamlined approach for various edge and telecom deployment options based on various use cases. It provides a solution to the challenge of small form factors at the edge with industry-standard rugged certifications (NEBS), with a compact solution for scalability and flexibility in a temperature range of -5 to +55°C. The MLPerf results provide a real-life scenario on edge inferencing for servers on AI inferencing. Based on the results in this document, Dell servers continue to provide a complete solution.
References
Notes:
- Based on testing conducted in Dell Cloud and Emerging Technology lab, January 2023. Results to be submitted to MLPerf in Q2,FY24.
- Unverified MLPerf v2.1 Inference. Results not verified by MLCommons Association. MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
[1] Based on testing conducted in Dell Cloud and Emerging Technology lab, January 2023.
Related Documents

Unlocking Machine Learning with Dell PowerEdge XE9680: Insights into MLPerf 2.1 Training Performance
Tue, 28 Mar 2023 23:05:15 -0000
|Read Time: 0 minutes
Executive Summary
The Dell PowerEdge XE9680 is a high-performance server designed and optimized to enable uncompromising performance for artificial intelligence, machine learning, and high-performance computing workloads. Dell PowerEdge is launching our innovative 8-way GPU platform with advanced features and capabilities.

- 8x NVIDIA H100 80GB 700W SXM GPUs or 8x NVIDIA A100 80GB 500W SXM GPUs
- 2x Fourth Generation Intel® Xeon® Scalable Processors
- 32x DDR5 DIMMs at 4800MT/s
- 10x PCIe Gen 5 x16 FH Slots
- 8x SAS/NVMe SSD Slots (U.2) and BOSS-N1 with NVMe RAID
This tech note, Direct from Development (DfD), offers valuable insights into the performance of the PowerEdge XE9680 using MLPerf 2.1 benchmarks from MLCommons.
Testing
MLPerf is a suite of benchmarks that assess the performance of machine learning (ML) workloads, with a focus on two crucial aspects of the ML life cycle: training and inference. This tech note specifically delves into the training aspect of MLPerf.
The Dell CET AI Performance and the Dell HPC & AI Innovation Lab conducted MLPerf 2.1 Training benchmarks using the latest PowerEdge XE9680 equipped with 8x NVIDIA A100 80GB SXM GPUs. For comparison, we also ran these tests on the previous generation PowerEdge XE8545, equipped with 4x NVIDIA A100 80GB SXM GPUs. The following section presents the results of our tests. Please note that in the figure below, a lower number indicates better performance and the results have not been verified by MLCommons.
Performance
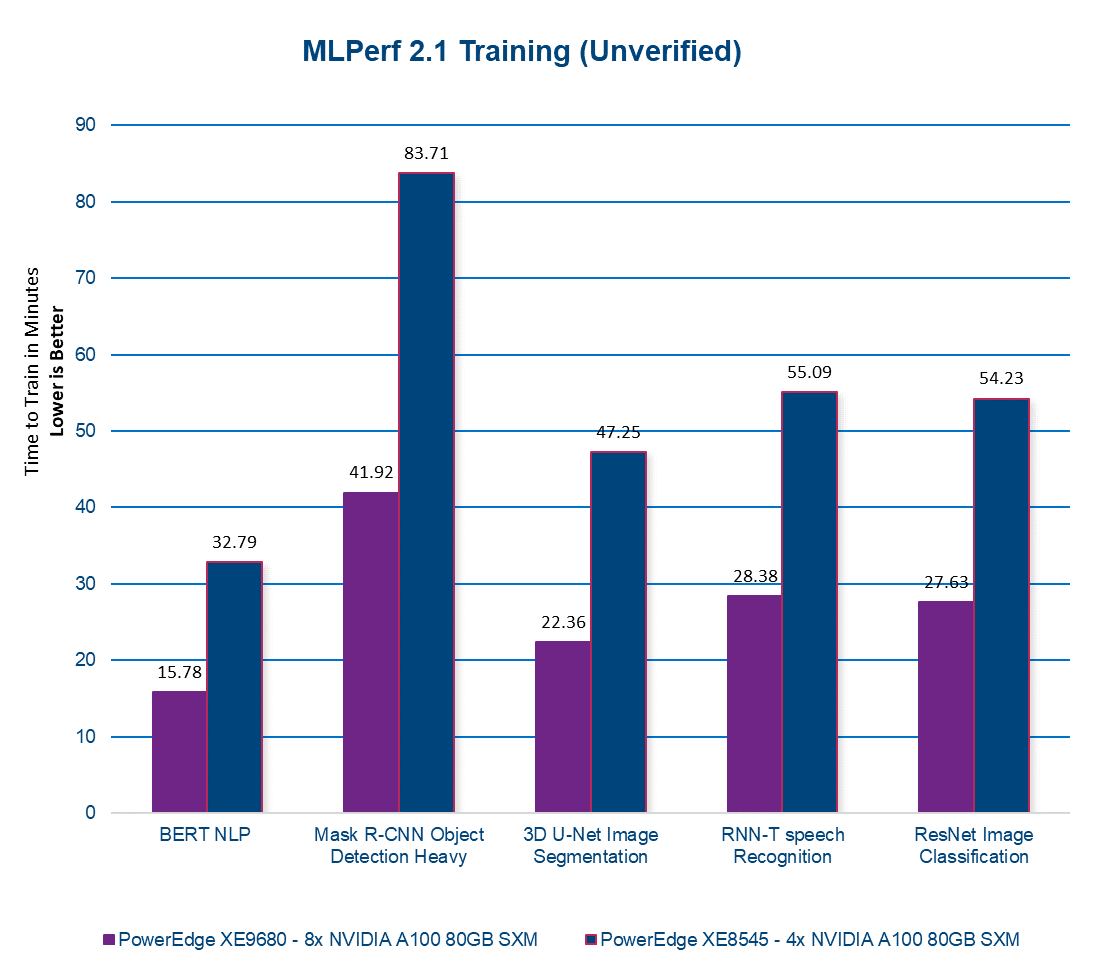
Figure 1. MLPERF 2.1 Training
Our latest server, the PowerEdge XE9680 with 8x NVIDIA A100 80GB SXM GPUs, delivers on average twice the performance of our previous-generation server. This translates to faster AI model training, enabling models to be trained in half the time! With the PowerEdge XE9680, you can accelerate your AI workloads and achieve better results, faster than ever before. Contact your account executive or visit www.dell.com to learn more.
Table 1. Server configuration

(1) Testing conducted by Dell in March of 2023. Performed on PowerEdge XE9680 with 8x NVIDIA A100 SXM4-80GB and PowerEdge XE8545 with 4x NVIDIA A100-SXM-80GB. Unverified MLPerf v2.1 BERT NLP v2.1, Mask R-CNN object detection, heavy-weight v2.1 COCO 2017, 3D U-Net image segmentation v2.1 KiTS19, RNN-T speech recognition v2.1 rnnt Training. Result not verified by MLCommons Association. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.” Actual results will vary.

AI-related Performance Testing of PowerEdge MX760c vs. PowerEdge MX750c

Thu, 14 Mar 2024 16:52:36 -0000
|Read Time: 0 minutes
Trust the numbers: Dell PowerEdge MX760c using 4th generation Intel® Xeon® Scalable Processors performs better machine learning.
Grid Dynamics set out to review whether taking a CPU-only (non-GPU) approach is effective in training and inference tasks for small and medium-sized machine learning models (up to ten million parameters), and whether it is a good solution for running larger models (with hundreds of millions of parameters) effectively in inference mode. They also wanted to review improvement in server performance, generation to generation.
To understand how the MX760c model series handles significant artificial intelligence/machine learning workloads as compared to the MX750c model series, Grid Dynamics developed four use cases that simulate the computational needs of retail, industrial, and IT infrastructure:
1. A recommendation system for analyzing user preferences and creating personalized recommendations.
2. A sales forecasting and inventory decision support tool for store managers for keeping the inventory optimized against actual and forecasted demand, and for planning for stock replenishment.
3. Anomaly detection for industrial timeseries for analyzing anomalies in telemetry data and detecting failure probability in industrial hardware.
4. Popular machine learning for evaluating server performance through a series of standardized tests.
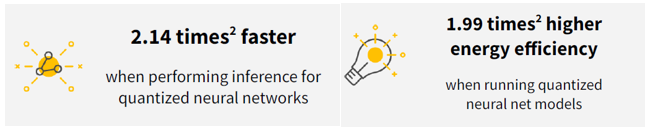
(2) Based on testing performed by Grid Dynamics, February 2023.
The tests team concluded that Dell PowerEdge MX760c – leveraging Intel® Xeon® Gold 6430 (2.10 / 32 core) CPUs – performs better in machine learning than MX750c leveraging Intel® Xeon® Platinum 8368 (2.40 GHz /38 core) CPUs. The MX760C used Intel® Xeon® Gold 6430 that supports the Advanced Matrix Extensions accelerator that improves the performance of deep-learning training and inference. The Gold 6430 also supports faster DDR5 memory.
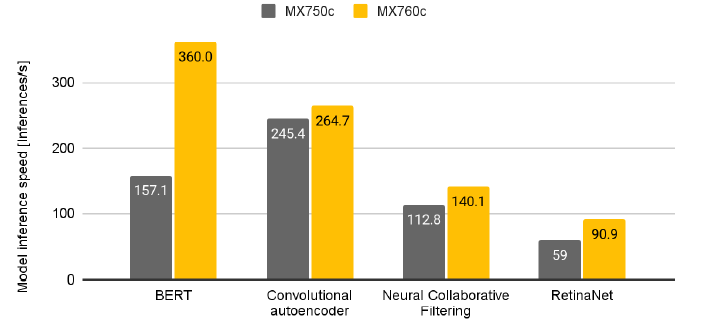
Figure 1. Inference speed (neural ML models – Inferences per Second (higher is better)
Advanced Matrix Extensions (AMX) technology implemented in “Sapphire Rapids” 4th generation of Intel® Xeon® Scalable Processors CPUs allows these servers to perform matrix operations for quantized (Int8 and Bf16) ML models much faster.
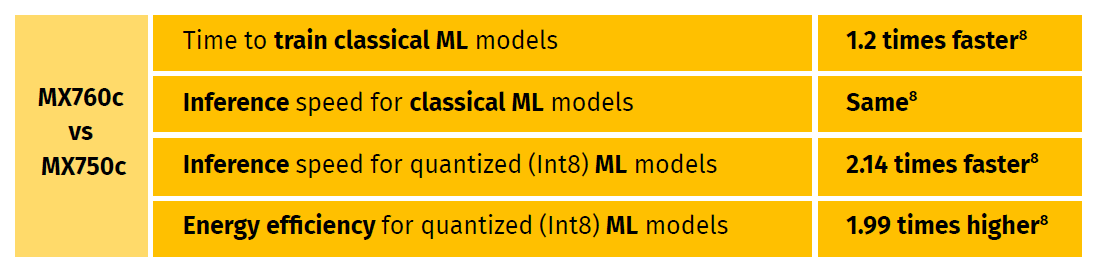
(8) Based on testing performed by Grid Dynamics, February 2023.
To summarize, Dell PowerEdge MX760c has proven itself to be a faster and a more capable solution than the previous generation MX750c server for the studied use cases. For more details, see the benchmark and testing results in these documents:

Executive Summary - Performance Comparison of Dell PowerEdge MX760c and MX750c Server Models
Technical Paper - Performance Comparison of Dell PowerEdge MX760c and MX750c Server Models