




Next-Generation Dell PowerEdge XR Server CPU Improvements
Download PDFFri, 03 Mar 2023 19:57:24 -0000
|Read Time: 0 minutes
Summary
Dell Technologies has recently introduced the next generation of Dell PowerEdge XR servers. Powered by 4th Gen Intel® Xeon® Scalable processors with the MCC SKU stack, these servers deliver advanced performance in an energy-efficient design. Dell continues to provide scalability and flexibility with its latest portfolio of short-depth XR servers. These servers integrate technologies such as 4th Gen Intel CPUs, PCIe Gen5, DDR5, NVMe drives, and GPU slots, and they are compliance-tested for NEBS and MIL-STD.
This tech note discusses our CPU performance benchmark testing of the next-generation PowerEdge XR server portfolio and the test results that show improvements over previous PowerEdge XR servers powered by 3rd Gen Intel Xeon Scalable processors and Xeon D processors.
Benchmarks
4th Gen Intel Xeon Scalable processors with the MCC SKU stack were tested using the STREAM and HPL benchmarks and compared with the CPU of the previous generation of XR servers.
STREAM
The STREAM benchmark is a simple, synthetic benchmark designed to measure sustainable memory bandwidth (in MB/s) and a corresponding computation rate for four simple vector kernels: Copy, Scale, Add, and Triad. The STREAM benchmark is designed to work with datasets much larger than the available cache on any system so that the results are (presumably) more indicative of the performance of very large, vector-style applications. Ultimately, we get a reference for compute performance.
HPL
HPL is a high-performance LINPACK benchmark implementation. The code solves a uniformly random system of linear equations and reports time and floating-point operations per second using a standard formula for operation count. It also helps to provide a reference for a system’s compute speed performance.
Performance results
Benchmark testing showed significant performance increases with the 4th Gen Intel Xeon Scalable MCC SKU stack when it was compared with both the Intel Xeon D SKU and the 3rd Gen Intel Xeon Scalable MCC SKU.
Comparison of 4th Gen Intel Xeon Scalable MCC SKU with Intel Xeon D SKU
In our tests, the single-socket PowerEdge XR servers with the 4th Gen Intel Xeon Scalable CPU (32 core) MCC SKU stack delivered a 253 percent increase in HPL performance and a 182 percent increase in STREAM performance. Thus, these servers are faster at the network edge or enterprise edge than the previous-generation PowerEdge XR servers powered by the Intel Xeon D (16 core) SKU.
Figure 1 and Figure 2 show the results of the benchmark tests that compared the performance of the 4th Gen Intel Xeon Scalable processor MCC SKU stack with the Intel Xeon D SKU.
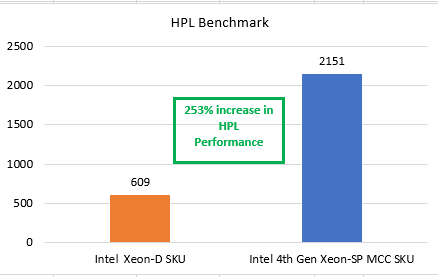
Figure 1. HPL performance comparison: Intel Xeon D SKU and 4th Gen Intel Xeon Scalable MCC SKU
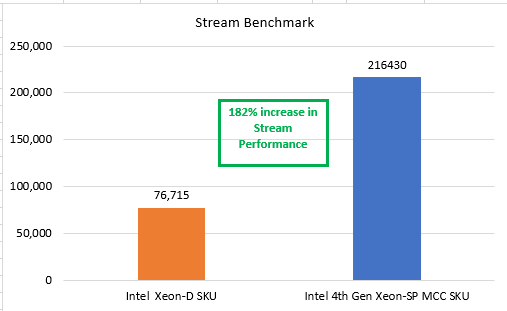
Figure 2. STREAM performance comparison: Intel Xeon D SKU and 4th Gen Intel Xeon Scalable MCC SKU
Comparison of 4th Gen and 3rd Gen Intel Xeon Scalable MCC SKU
In our tests, the single-socket PowerEdge XR servers with the 4th Gen Intel Scalable CPU (32 core) MCC stack delivered a 52 percent increase in STREAM performance and a 72 percent increase in CPU FP rate base performance (floating point performance for the CPU). Thus, these servers are faster for compute at the network edge or enterprise edge than the previous generation of PowerEdge XR servers powered by the 3rd Gen Intel Xeon Scalable MCC SKU.
Figure 3 and Figure 4 show the results of the benchmark tests that compared the performance of the 4th Gen and 3rd Gen Intel Xeon Scalable processor MCC SKU stacks.
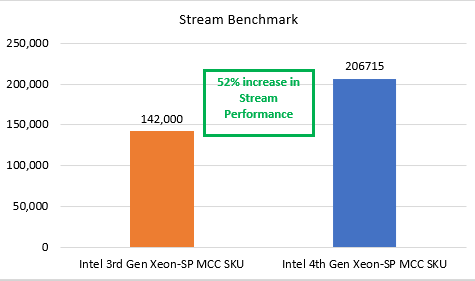
Figure 3. STREAM performance for 4th and 3rd Gen Intel Xeon Scalable processors
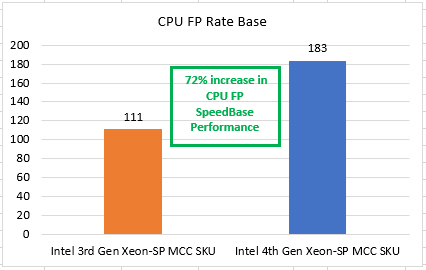
Figure 4. CPU FP rate base performance for 4th and 3rd Gen Intel Xeon Scalable processors
Conclusion
The Dell PowerEdge XR portfolio continues to provide CPU-based improvements and a streamlined approach for various edge and telecom deployment options. The XR portfolio provides a solution to the challenge of needing a small form factor at the edge with industry-standard rugged certifications (NEBS). It provides a compact solution for scalability along with flexibility for operating in temperatures ranging from –5°C to +55°C.
References
Related Documents

BIOS Settings for Optimized Performance on Next-Generation Dell PowerEdge Servers
Thu, 02 Nov 2023 17:45:05 -0000
|Read Time: 0 minutes
Summary
Dell PowerEdge servers provide a wide range of tunable parameters to allow customers to achieve top performance. The information in this paper outlines the tunable parameters available in the latest generation of PowerEdge servers (for example, R660, R760, MX760, and C6620) and provides recommended settings for different workloads.
 Figure 1. PowerEdge R660
Figure 1. PowerEdge R660

Figure 2. PowerEdge R760
The following tables provide the BIOS setting recommendations for the latest generation of PowerEdge servers.
Table 1. BIOS setting recommendations—System profile settings
System setup screen | Setting | Default | Recommended setting for performance | Recommended setting for low latency, Stream, and MLC environments | Recommended | |
System profile settings | System Profile | Performance Per Watt [1] | Performance Optimized | First select Performance Optimized and then select Custom [1] | Custom
| |
System profile settings | CPU Power Management | System DBPM | Maximum Performance | Maximum Performance | Maximum Performance | |
System profile settings | Memory Frequency | Maximum Performance | Maximum Performance | Maximum Performance | Maximum Performance | |
System profile settings | Turbo Boost [2] | Enabled | Enabled | Enabled | Enabled | |
System profile settings | C1E | Enabled | Disabled | Disabled | Disabled | |
System profile settings | C States | Enabled | Disabled | Disabled | Autonomous or Disabled [6] | |
System profile settings | Monitor/Mwait | Enabled | Enabled | Disabled [3] | Enabled | |
System profile settings | Memory Patrol Scrub | Standard | Standard [4] | Standard/Disabled [4] | Disabled | |
System profile settings | Memory Refresh Rate | 1x | 1x | 1x | 1x | |
System profile settings | Uncore Frequency | Dynamic | Maximum [5] | Maximum [5] | Dynamic | |
System profile settings | Energy Efficient Policy | Balanced Performance | Performance | Performance | Performance | |
System profile settings | CPU Interconnect Bus Link Power Management | Enabled | Disabled | Disabled | Disabled | |
System profile settings | PCI ASPM L1 Link Power Management | Enabled | Disabled | Disabled | Disabled | |
[1] Depends on how system was ordered. Other System Profile defaults are driven by this choice and may be different than the examples listed. Select Performance Profile first, and then select Custom to load optimal profile defaults for further modification
[2] SST Turbo Boost Technology is substantially better than previous generations for latency-sensitive environments, but specific Turbo residency cannot be guaranteed under all workload conditions. Evaluate Turbo Boost Technology in your own environment to choose which setting is most appropriate for your workload, and consider the Dell Controlled Turbo option in parallel.
[3] Monitor/Mwait should only be disabled in parallel with disabling Logical Processor. This will prevent the Linux intel_idle driver from enforcing C-states.
[4] You can test your own environment to determine whether disabling Memory Patrol Scrub is helpful.
[5] Dynamic selection can provide more TDP headroom at the expense of dynamic uncore frequency. Optimal setting is workload dependent.
[6] Autonomous on Air Cooled system or Disabled on Liquid Cooled Systems
Table 2. BIOS setting recommendations—Memory, processor, and iDRAC settings
System setup screen | Setting | Default | Recommended setting for performance | Recommended setting for low latency, Stream, and MLC environments | Recommended |
Memory settings | Memory Operating Mode | Optimizer | Optimizer [1] | Optimizer [1] | Optimizer [1] |
Memory settings | Memory Node Interleave | Disabled | Disabled | Disabled | Disabled |
Memory settings | DIMM Self Healing | Enabled | Disabled | Disabled | Disabled |
Memory settings | ADDDC setting | Disabled [2] | Disabled [2] | Disabled [2] | Disabled [2] |
Memory settings | Memory Training | Fast | Fast | Fast | Fast |
Memory settings | Correctable Error Logging | Enabled | Disabled | Disabled | Disabled |
Processor settings | Logical Processor | Enabled | Disabled [3] | Disabled [3] | Enabled |
Processor settings | Virtualization Technology | Enabled | Disabled | Disabled | Disabled |
Processor settings | CPU Interconnect Speed | Maximum Data Rate | Maximum Data Rate | Maximum Data Rate | Maximum Data Rate |
Processor settings | Adjacent Cache Line Prefetch | Enabled | Enabled | Enabled | Enabled |
Processor settings | Hardware Prefetcher | Enabled | Enabled | Enabled | Enabled |
Processor settings | DCU Streamer Prefetcher | Enabled | Enabled | Disabled | Disabled |
Processor settings | DCU IP Prefetcher | Enabled | Enabled | Enabled | Enabled |
Processor settings | Sub NUMA Cluster | Disabled | SNC 2 | SNC 4 on XCC SNC 2 on MCC | SNC 4 on XCC SNC 2 on MCC |
Processor settings | Dell Controlled Turbo | Disabled | Disabled | Enabled [4] | Disabled |
Processor settings | Dell Controlled Turbo Optimizer mode | Disabled | Enabled [5] | Enabled [5] | Enabled [5] |
Processor settings | XPT Prefetch | Enabled | Disabled | Disabled | Enabled |
Processor settings | UPI Prefetch | Enabled | Disabled | Disabled | Enabled |
Processor settings | LLC Prefetch | Disabled | Enabled | Disabled | Disabled |
Processor settings | DeadLine LLC Alloc | Enabled | Enabled | Enabled | Disabled |
Processor settings | Directory AtoS | Disabled | Disabled | Disabled | Disabled |
Processor settings | Dynamic SST Perf Profile | Disabled | Disabled | Enabled | Disabled |
Processor settings | SST-Perf- profile | Operating Point 1 | Operating Point 1 | Operating Point ? [6] | Operating Point 1 |
iDRAC settings | Thermal Profile | Default | Maximum Performance | Maximum Performance | Maximum Performance |
[1] Use Optimizer Mode when Memory Bandwidth Sensitive, up to 33% BW reduction with Fault Resilient Mode.
[2] Only available when x4 DIMMS installed in the system.
[3] Logical Processor (Hyper Threading) tends to benefit throughput-oriented workloads such as SPEC CPU2017 INT and FP_RATE. Many HPC workloads disable this option. This only benefits SPEC FP_rate if the thread count scales to the total logical processor count.
[4] Dell Controlled Turbo helps to keep core frequency at the maximum all-cores Turbo frequency, which reduces jitter. Disable if Turbo disabled.
[5] Option is available on liquid cooled systems only.
[6] Depends on if your program is affected by Base and Turbo frequency. Will reduce CPU core count and give higher Base and Turbo frequencies.
iDRAC recommendations
- Thermally challenged environments should increase fan speed through iDRAC Thermal section.
- All Power Capping should be removed in performance-sensitive environments.
BIOS settings glossary
- System Profile: (Default=Performance Per Watt)—It can be difficult to set each individual power/performance feature for a specific environment. Because of this, a menu option is provided that can help a customer optimize the system for things such as minimum power usage/acoustic levels, maximum efficiency, Energy Star optimization, or maximum performance.
- Performance Per Watt DAPC (Dell Advanced Power Control)—This mode uses Dell presets to maximize the performance/watt efficiency with a bias towards power savings. It provides the best features for reducing power and increasing performance in applications where maximum bus speeds are not critical. It is expected that this will be the favored mode for SPECpower testing. "Efficiency–Favor Power" mode maintains backwards compatibility with systems that included the preset operating modes before Energy Star for servers was released.
- Performance Per Watt OS—This mode optimizes the performance/watt efficiency with a bias towards performance. It is the favored mode for Energy Star. Note that this mode is slightly different than "Performance Per Watt DAPC" mode. In this mode, no bus speeds are derated as they are in the Performance Per Watt DAPC mode, leaving the operating system in control of those changes.
- Performance—This mode maximizes the absolute performance of the system without regard for power. In this mode, power consumption is not considered. Things like fan speed and heat output of the system, in addition to power consumption, might increase. Efficiency of the system might go down in this mode, but the absolute performance might increase depending on the workload that is running.
- Custom—Custom mode allows the user to individually modify any of the low-level settings that are preset and unchangeable in any of the other four preset modes.
- C-States—C-states reduce CPU idle power. There are three options in this mode:
- Enabled: When “Enabled” is selected, the operating system initiates the C-state transitions. Some operating system software might defeat the ACPI mapping (for example, intel_idle driver).
- Autonomous: When "Autonomous" is selected, HALT and C1 requests get converted to C6 requests in hardware.
- Disable: When "Disable" is selected, only C0 and C1 are used by the operating system. C1 gets enabled automatically when an OS auto-halts.
- C1 Enhanced Mode—Enabling C1E (C1 enhanced) state can save power by halting CPU cores that are idle.
- Turbo Mode—Enabling turbo mode can boost the overall CPU performance when all CPU cores are not being fully utilized. A CPU core can run above its rated frequency for a short period of time when it is in turbo mode.
- Hyper-Threading—Enabling Hyper-Threading lets the operating system address two virtual or logical cores for a physical presented core. Workloads can be shared between virtual or logical cores when possible. The main function of hyper-threading is to increase the number of independent instructions in the pipeline for using the processor resources more efficiently.
- Execute Disable Bit—The execute disable bit allows memory to be marked as executable or non-executable when used with a supporting operating system. This can improve system security by configuring the processor to raise an error to the operating system when code attempts to run in non-executable memory.
- DCA—DCA capable I/O devices such as network controllers can place data directly into the CPU cache, which improves response time.
- Power/Performance Bias—Power/performance bias determines how aggressively the CPU will be power managed and placed into turbo. With "Platform Controlled," the system controls the setting. Selecting "OS Controlled" allows the operating system to control it.
- Per Core P-state—When per-core P-states are enabled, each physical CPU core can operate at separate frequencies. If disabled, all cores in a package will operate at the highest resolved frequency of all active threads.
- CPU Frequency Limits—The maximum turbo frequency can be restricted with turbo limiting to a frequency that is between the maximum turbo frequency and the rated frequency for the CPU installed.
- Energy Efficient Turbo—When energy efficient turbo is enabled, the CPU's optimal turbo frequency will be tuned dynamically based on CPU utilization.
- Uncore Frequency Scaling—When enabled, the CPU uncore will dynamically change speed based on the workload.
- MONITOR/MWAIT—MONITOR/MWAIT instructions are used to engage C-states.
- Sub-NUMA Cluster (SNC)—SNC breaks up the last level cache (LLC) into disjoint clusters based on address range, with each cluster bound to a subset of the memory controllers in the system. SNC improves average latency to the LLC and memory. SNC is a replacement for the cluster on die (COD) feature found in previous processor families. For a multi-socketed system, all SNC clusters are mapped to unique NUMA domains. (See also IMC interleaving.) Values for this BIOS option can be:
- Disabled: The LLC is treated as one cluster when this option is disabled.
- Enabled: Uses LLC capacity more efficiently and reduces latency due to core/IMC proximity. This might provide performance improvement on NUMA-aware operating systems.
- Snoop Preference—Select the appropriate snoop mode based on the workload. There are two snoop modes:
- HS w. Directory + OSB + HitME cache: Best overall for most workloads (default setting)
- Home Snoop: Best for BW sensitive workloads
- XPT Prefetcher—XPT prefetch is a mechanism that enables a read request that is being sent to the last level cache to speculatively issue a copy of that read to the memory controller prefetcher.
- UPI Prefetcher—UPI prefetch is a mechanism to get the memory read started early on DDR bus. The UPI receive path will spawn a memory read to the memory controller prefetcher.
- Patrol Scrub—Patrol scrub is a memory RAS feature that runs a background memory scrub against all DIMMs. This feature can negatively affect performance.
- DCU Streamer Prefetcher—DCU (Level 1 Data Cache) streamer prefetcher is an L1 data cache prefetcher. Lightly threaded applications and some benchmarks can benefit from having the DCU streamer prefetcher enabled. Default setting is Enabled.
- LLC Dead Line Allocation—In some Intel CPU caching schemes, mid-level cache (MLC) evictions are filled into the last level cache (LLC). If a line is evicted from the MLC to the LLC, the core can flag the evicted MLC lines as "dead." This means that the lines are not likely to be read again. This option allows dead lines to be dropped and never fill the LLC if the option is disabled. Values for this BIOS option can be:
- Disabled: Disabling this option can save space in the LLC by never filling MLC dead lines into the LLC.
- Enabled: Opportunistically fill MLC dead lines in LLC, if space is available.
- Adjacent Cache Prefetch—Lightly threaded applications and some benchmarks can benefit from having the adjacent cache line prefetch enabled. Default is Enabled.
- Intel Virtualization Technology—Intel Virtualization Technology allows a platform to run multiple operating systems and applications in independent partitions, so that one computer system can function as multiple virtual systems. Default is Enabled.
- Hardware Prefetcher—Lightly threaded applications and some benchmarks can benefit from having the hardware prefetcher enabled. Default is Enabled.
- Trusted Execution Technology—Enable Intel Trusted Execution Technology (Intel TXT). Default is Disabled.

Intel 4th Gen Xeon featuring QAT 2.0 Technology Delivers Massive Performance Uplift in Common Cipher Suites
Sat, 27 Apr 2024 15:07:09 -0000
|Read Time: 0 minutes
Intel QAT Hardware v2.0 acceleration running on 16G PowerEdge delivers on performance for ISPs - Lab Tested and Proven
Introduction
The Internet as we know it would simply not be possible without encryption technologies. This technology lets us perform secure communication and information exchange over public networks. If you buy a pair of shoes from an online retailer, the payment information you provide is encrypted with such a high level of security that extracting your credit card information from ciphertext would be nearly an impossible task for even a supercomputer. The shoes might not end up fitting, but if the requisite encryption and secure communication tech is properly implemented, your payment information remains a secret known only to you and the entity receiving payment.
This domain of security requires hardware that is up to the task of performing handshakes, key exchanges, and other algorithmic tasks at an expeditious speed.
As we’ll demonstrate through extensive testing and proven results in our lab, Intel’s QAT 2.0 Hardware Accelerator featured on Gen4 Xeon processors is a performant and dev friendly choice to supercharge your encryption workloads. This feature is readily available on our current products across the PowerEdge Server portfolio.
What is QAT?
QAT, or “Quick Assist Technology” is an Intel technology that accelerates two common use cases: encryption acceleration and compression/decompression acceleration. In this tech note, we look at the encryption side of the QAT Accelerator feature set and explore leveraging QAT to speed up cipher suites used in deployments of OpenSSL–a common software library used by a vast array of websites and applications to secure their communications.
But before we start, let’s briefly touch on the lineage and history of QAT. QAT was introduced back in 2007, initially available as a discrete add-in PCIe card. A little further on in its evolution, QAT found a home in Intel Chipsets. Now, with the introduction of the 4th Gen Xeon processor, the silicon required to enable QAT acceleration has been added to the SOC. The hardware being this close to the processor has increased performance and reduced the logistical complexity of having to source and manage an external device.
For a complete list of the QAT Hardware v2.0’s cryptosystem and algorithms support, see: https://github.com/intel/QAT_Engine/blob/master/docs/features.md#qat_hw-features
QAT hardware acceleration may not be the fastest method to accelerate all ciphers or algorithms. With this in mind, QAT Hardware Acceleration (also called QAT_HW) can peacefully co-exist with QAT Software Acceleration (or QAT_SW). This configuration, while somewhat complex, is well supported by clear documentation. Fundamentally, this configuration relies on a method to ensure that the maximum performance is extracted for all inputs given what resources are available on the system. Allowing for use of an algorithm bitmap to dynamically choose between and prioritize the use of QAT_HW and QAT_SW based on hardware availability and which method offers the best performance.
Next we'll look at setting up QATlib and see what the performance looks like using OpenSSL Speed and a few common cipher suites.
Lab Test Setup and Notes
For this test we use a Dell PowerEdge R760. This is Dell’s mainstream 2U dual socket 4th Gen Xeon offering and features support for nearly all of Intel’s QAT enabled CPUs. Xeon gen4 CPUs that feature on-chip QAT HW 2.0 will have 1, 2 or 4 QAT endpoints per socket. We selected the Intel(R) Xeon(R) Gold 5420+ CPU that features 1 QAT endpoint for our testing. All else being equal, more endpoints allow for more QAT Hardware acceleration work to be done and allow greater performance in QAT HW accelerated use cases per socket.
As this is not a deployment guide, we’re going to use a RHEL 9.2 install as our operating system and run bare metal for our tests. Our primary resource for setting up QAT Hardware Version 2.0 Acceleration is the excellent QAT documentation found on Intel’s github here: https://intel.github.io/quickassist/index.html
Following the guide, we can simply install from RPM sources, ensure kernel drivers are loaded and we’re about ready to go.
Performance
First up, we’ll take a look at probably the most common public key asymmetric cipher suite, RSA. On the Internet RSA finds its home as a key exchange and signature method used to secure communication and confirm identities. In these graphs we’re comparing the speed of the RSA Sign and Verify algorithm using symmetric QAT_HW vs symmetric QAT off (using OpenSSLs default engine).
The following graphic shows a representation of a TLS handshake. This provides a bit of context concerning the role of the server in key exchange and handshakes.
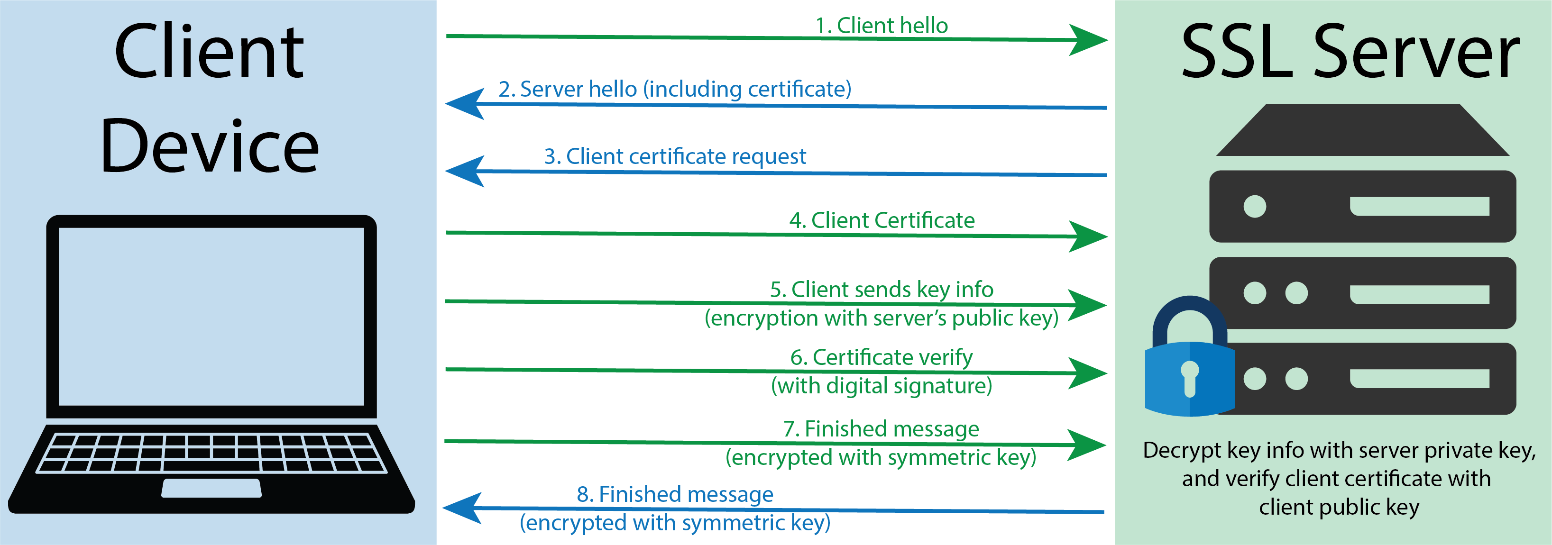 TLS handshake representation
TLS handshake representation
 OpenSSL Speen RSA2048 Verify comparison
OpenSSL Speen RSA2048 Verify comparison
 OpenSSL Speed RSA2048 Sign comparison
OpenSSL Speed RSA2048 Sign comparison
 Greater than 240% performance increase in OpenSSL RSA Verify using QAT Hardware Acceleration Engine vs Default Open SSL Engine.(1)
Greater than 240% performance increase in OpenSSL RSA Verify using QAT Hardware Acceleration Engine vs Default Open SSL Engine.(1)
Testing in our labs shows that enabling QAT offers 240% greater algorithmic operations. The result for this performance improvement could be the implementation of greater security capacity per node without the risk of negative impact on QoS.
Next we’ll look at the industry standard elliptical curve digital signature algorithm (ECDSA), specifically P-384. QAT HW supports both P-256 and P-384, with both offering exceptional performance vs the default OpenSSL engine. ECDSA is a commonly used as a key agreement protocol by many Internet messaging apps.
ECDSA example
 OpenSSL Speed ECDSA P384 Verify comparison
OpenSSL Speed ECDSA P384 Verify comparison OpenSSL Speed ECDSA P384 Sign comparison
OpenSSL Speed ECDSA P384 Sign comparison Over 30x improvement in ECDSA P384 Sign-in OpenSSL using QAT Hardware Acceleration Engine vs Default OpenSSL Engine(2)
Over 30x improvement in ECDSA P384 Sign-in OpenSSL using QAT Hardware Acceleration Engine vs Default OpenSSL Engine(2)
Both of these algorithms provide the level of protection that today’s server security specialists require. However, both are quite different in many aspects.
This vast performance improvement in secure key exchange offers more secure and uncompromised communication without degrading performance.
Conclusion
Intel’s QAT 2.0 Hardware acceleration offers substantial performance improvements for algorithms found in commonly used cipher suites. Also, QAT’s ample documentation and long history of use coupled with these new findings on performance should remove any reservations that a customer might have in deploying these security accelerators. Security at the server silicon level is critical to a modern and uncompromised data center. There is definite value in deploying QAT and a clear path towards realizing accelerated performance in their data center environments.
Legal disclosures
- Based on August 2023 Dell labs testing subjecting the PowerEdge R760 to OpenSSL Speed test running synchronously with default engine vs asynchronous with QAT Hardware Engine. Actual results will vary.
- Based on August 2023 Dell labs testing subjecting the PowerEdge R760 to OpenSSL Speed test running synchronously with default engine vs asynchronous with QAT Hardware Engine. Actual results will vary.